Amazon Personalize 是一个全托管式的机器学习服务,开发人员在没有机器学习背景的情况下,可以使用自己熟悉语言的 SDK 或者控制台 GUI 点击轻松地构建一个实时推荐系统任务来满足对应业务的需要。目前 Amazon Personalize 已经在个性化推荐,相似物品推荐,个性化物品排名,以及个性化促销和通知等使用场景均有比较好的使用案例。
在 2021 年 11 月 29 日,Amazon Personalize 也新推出了智能用户细分的功能。使用用户细分的这个新功能不仅可以帮助运营团队进行精细化运营,也可以帮助销售和市场团队进行客户分群来做到精准营销以提高 ROI。在电商场景下,可以针对不同的商品,对潜在用户进行划分,以便更有针对性地进行投放活动。本文将以一个广告投放的使用场景为例,使用 Python Boto3 的 SDK 介绍如何使用 Amazon Personalize 的新功能来帮助运营人员和市场人员完成一个用户细分的任务。
数据集
构建
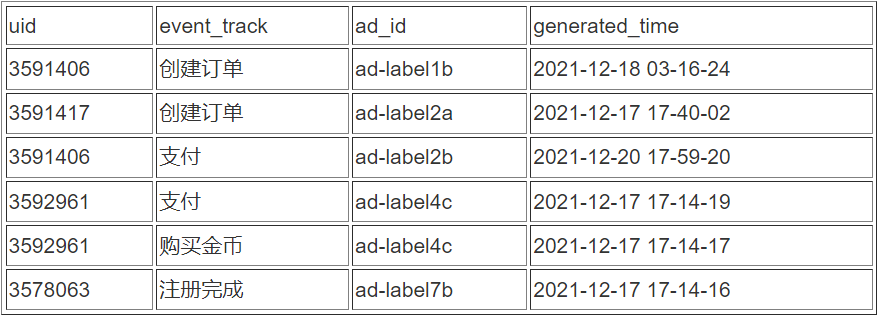
为了完成一个 Amazon Personalize 的训练任务,我们首先需要构建数据集。ETL 工程师从数仓中导出的 Raw Data 可能是以下形式。其中 uid 代表了完成广告浏览并产生交互行为的用户 ID,event_track 代表相应用户在应用内产生的用户行为,ad_id 代表影响用户的相应广告 ID(或标签),generated_time 代表用户完成用户行为时被记录的时间戳。
Amazon Personalize 支持三种数据集,分别是用户数据集,物品数据集,以及用户交互数据集。
· Users – User Dataset 用于记录用户的 metadata。例如用户的年龄,性别,会员信息等。
· Items – Item Dataset 用于记录物品的 metadata。例如商品的 SKU,价格等,在广告投放中,可以记录广告的品类以及标签。
· Interactions – Interaction Dataset 包含了 User 和 Item 的历史和实时数据。例如用户的点击, 浏览,点赞等行为。在 Amazon Personalize 中,每一次用户事件都作为一条记录会被用于作为训练数据任务。
为了完成 Amazon Personalize 的作业至少需要创建一个交互数据集来完成训练。Amazon Personalize 的交互数据集需要至少一列 USER_ID, 一列 ITEM_ID,一列 TIMESTAMP来完成训练任务,我们也可以提供 EVENT_TYPE 和 EVENT_VALUE 数据来显式地对模型部署时提高精准投放能力。
首先我们需要对数据集进行清洗和数据预处理,以满足 Amazon Personalize 的数据格式需要。这里我们将使用 Pandas 完成这个步骤。你可以使用云上的 Amazon SageMaker Notebook Instance 来运行代码,也可以使用本地的 Jupyter Notebook 来完成。
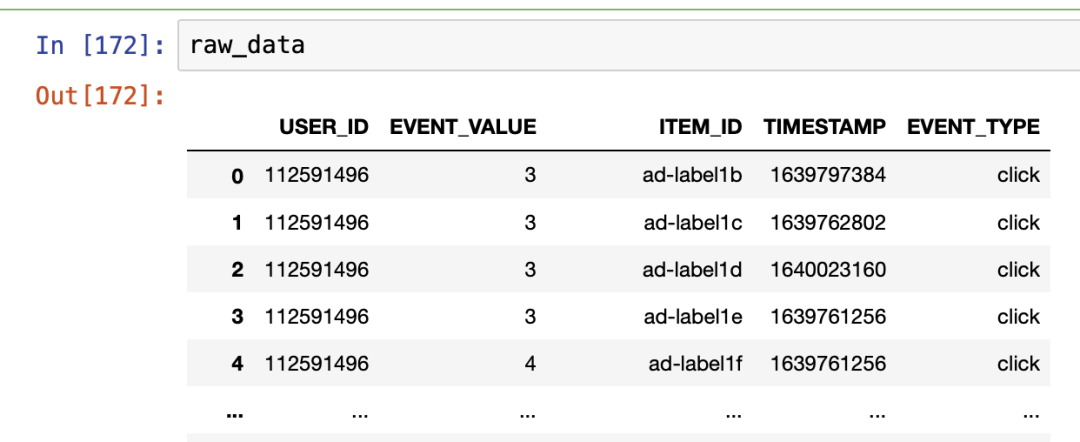
import pandas as pd
import datetime
import time
from numpy import float32, uint32def string_to_unix_time_long(date_string):casted_time = date_string[:13]+":"+date_string[14:16]+":"+date_string[17:]return uint32(time.mktime(pd.to_datetime(casted_time).timetuple())).item()raw_data["generated_time"] = raw_data["generated_time"].apply(string_to_unix_time_long)*左滑查看更多
以上代码可以将事例中 generated_time 的格式替换成为 Amazon Personalize 要求的 UNIX epoch 时间格式。为了实现精准投放,我们将 event_track 中的用户行为转化为点击事件,并对其中的各种用户行为按照各种行为的重要程度进行赋值,将 categorical data 转化为 numerical data,以便后续训练模型时进行针对训练。
event_map = {'创建订单':3, '支付':4,'加入购物车': 2,'注册完成': 1
}def event_mapping_method(event):return event_map[event]
raw_data["event_tracking"] = raw_data["event_tracking"].apply(event_mapping_method)
raw_data['EVENT_TYPE'] = "click"*左滑查看更多
以上代码对EVENT_VALUE 按照用户行为的重要性进行赋值,并追加 click事件列。
至此,我们完成了一个简易的数据集组的构建。接下来我们将对 Amazon Personalize 导入并创建数据集。
import boto3
from time import sleep
import jsonpersonalize = boto3.client('personalize')
personalize_runtime = boto3.client('personalize-runtime')
create_dataset_group_response = personalize.create_dataset_group(name = "segmentation-dataset"
)
dataset_group_arn = create_dataset_group_response['datasetGroupArn']
print(json.dumps(create_dataset_group_response, indent=2))*左滑查看更多
我们使用以下代码来监控数据集创建任务。待创建完成后,方可继续后续步骤。
max_time = time.time() + 3*60*60 # 3 hours
while time.time() < max_time:describe_dataset_group_response = personalize.describe_dataset_group(datasetGroupArn = dataset_group_arn)status = describe_dataset_group_response["datasetGroup"]["status"]print("DatasetGroup: {}".format(status))if status == "ACTIVE" or status == "CREATE FAILED":breaktime.sleep(60)*左滑查看更多
接下来,我们创建数据集的 Schema 以便 Amazon Personalize 可以完成数据集的构建。
interactions_schema = schema = {"type": "record","name": "Interactions","namespace": "com.amazonaws.personalize.schema","fields": [{"name": "USER_ID","type": "string"},{"name": "ITEM_ID","type": "string"},{ "name": "EVENT_TYPE","type": "string"},{"name": "EVENT_VALUE","type": "float"},{"name": "TIMESTAMP","type": "long"}],"version": "1.0"
}create_schema_response = personalize.create_schema(name = "segmentation-schema",schema = json.dumps(interactions_schema)
)interaction_schema_arn = create_schema_response['schemaArn']
print(json.dumps(create_schema_response, indent=2))*左滑查看更多
之后,我们将创建一个 Amazon S3 桶,以及相应的桶访问策略。用于存放 Amazon Personalize 的数据集,以及做用户细分时所需要的输入输出文件路径。请注意,Amazon S3 桶创建的地区需要和 Amazon Personalize 的地区保持一致,以便 Amazon Personalize 能够正常使用 S3 中的数据来进行作业。
s3 = boto3.client('s3')
region = "us-east-2"
bucket_name = "personalize-user-segmentation-poc-2022-1-1"
s3.create_bucket(Bucket=bucket_name,CreateBucketConfiguration={'LocationConstraint': region})
policy = {"Version": "2012-10-17","Id": "PersonalizeS3BucketAccessPolicy","Statement": [{"Sid": "PersonalizeS3BucketAccessPolicy","Effect": "Allow","Principal": {"Service": "personalize.amazonaws.com"},"Action": ["s3:*Object","s3:ListBucket"],"Resource": ["arn:aws:s3:::{}".format(bucket_name),"arn:aws:s3:::{}/*".format(bucket_name)]}]
}s3.put_bucket_policy(Bucket=bucket_name, Policy=json.dumps(policy))*左滑查看更多
接下来,我们将数据集上传到云上的 Amazon S3,以便后续使用。
raw_data.to_csv("segmentation.csv",index=False)
boto3.Session().resource('s3').Bucket(bucket_name).Object("segmentation.csv").upload_file("segmentation.csv")*左滑查看更多
我们使用以下代码创建一个 IAM 角色,并附给 Amazon Personalize 用于访问 S3 存储桶读写权限。
iam = boto3.client("iam")role_name = "Personalize-User-Segmentation-Role"
assume_role_policy_document = {"Version": "2012-10-17","Statement": [{"Effect": "Allow","Principal": {"Service": "personalize.amazonaws.com"},"Action": "sts:AssumeRole"}]
}
create_role_response = iam.create_role(RoleName = role_name,AssumeRolePolicyDocument = json.dumps(assume_role_policy_document)
)
policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonPersonalizeFullAccess"
iam.attach_role_policy(RoleName = role_name,PolicyArn = policy_arn
)
iam.attach_role_policy(PolicyArn='arn:aws:iam::aws:policy/AmazonS3FullAccess',RoleName=role_name
)
time.sleep(60) # 等待 IAM 角色附加完成role_arn = create_role_response["Role"]["Arn"]
print(role_arn)*左滑查看更多
接下来我们将创建数据集并进行数据导入作业。
dataset_type = "INTERACTIONS"
create_dataset_response = personalize.create_dataset(name = "personalize-user-segmentation-data-1",datasetType = dataset_type,datasetGroupArn = dataset_group_arn,schemaArn = interaction_schema_arn
)
# 创建数据集
interactions_dataset_arn = create_dataset_response['datasetArn']
print(json.dumps(create_dataset_response, indent=2))time.sleep(100) # 等待数据集创建完成
# 创建数据集导入任务
create_dataset_import_job_response = personalize.create_dataset_import_job(jobName = "personalize-segmentation-import-1",datasetArn = interactions_dataset_arn,dataSource = {"dataLocation": "s3://{}/{}".format(bucket_name, "segmentation.csv")},roleArn = role_arn
)dataset_import_job_arn = create_dataset_import_job_response['datasetImportJobArn']
print(json.dumps(create_dataset_import_job_response, indent=2))*左滑查看更多
至此我们完成了数据集导入的任务。接下来我们将创建用户分群的任务。
用户
分群
接下来我们将创建用户分群的任务。目前用户分群是 Amazon Personalize 的一项批处理任务,因此我们需要提前准备好需要针对分群的 Item ID,并按照如下格式创建好输入的 Json 文件,上传到 Amazon S3 中作为输入文件。
{"itemId": "ad-label1b"}
{"itemId": "ad-label1c"}本文,我们以广告 ID ad-label1b 和 ad-label1c 为例,来选取对这两个广告有兴趣的潜在用户,以便市场部门进行针对性广告投放。我们使用以下代码创建名为 ad_id_list.json 的广告 ID文件,并上传至 Amazon S3,以便后续创建分群作业使用。
!echo -e "{"itemId": "ad-label1b"}\n{"itemId": "ad-label1c"}" > ad_id_list.json
boto3.Session().resource('s3').Bucket(bucket_name).Object("ad_id_list.json").upload_file("ad_id_list.json")*左滑查看更多
接下来我们将创建用户分群的解决方案以及方案版本,此方案创建中,我们定义 eventValue 值大于 2 的行为用于训练。即,对本例中广告投放的用户行为中至少点击了 “加入购物车” 的行为来进行精准地训练。
user_segmentation_recipe_arn ="arn:aws:personalize:::recipe/aws-item-affinity"
user_personalization_create_solution_response = personalize.create_solution(name = "personalize-user-segmentation",datasetGroupArn = dataset_group_arn,recipeArn = user_segmentation_recipe_arn,eventType = "click",solutionConfig ={"eventValueThreshold":"2"}
)
user_segmentation_solution_arn = user_personalization_create_solution_response['solutionArn']
print(json.dumps(user_segmentation_solution_arn, indent=2))time.sleep(60) # 等待方案创建完成后创建版本
user_segmentation_create_solution_version_response = personalize.create_solution_version(solutionArn = user_segmentation_solution_arn
)
solution_version_arn = user_segmentation_create_solution_version_response["solutionVersionArn"]
print(json.dumps(solution_version_arn, indent=2))# 以下代码会轮训方案创建状态,待方案创建完成后方可进行作业任务
max_time = time.time() + 10*60*60 # 10 hours
while time.time() < max_time:version_response = personalize.describe_solution_version(solutionVersionArn = solution_version_arn)status = version_response["solutionVersion"]["status"]if status == "ACTIVE" or status == "CREATE FAILED":breaktime.sleep(60)*左滑查看更多
接下来我们将进行用户分群作业,并输入先前创建的广告 ID 文件,以针对每个广告投放生成的潜在用户数。分群的输出结果将写入 Amazon S3 output 文件夹中。
batch_job_arn = personalize.create_batch_segment_job (solutionVersionArn = solution_version_arn,jobName = "personalize-user-segmentation-job-6",numResults = 25, # 生成 1 and 5,000,000 个对投放广告对象的潜在用户数roleArn = role_arn,jobInput = {"s3DataSource": {"path": "s3://personalize-user-segmentation-poc-2022-1-1/ad_id_list.json"}},jobOutput = {"s3DataDestination": {"path": "s3://personalize-user-segmentation-poc-2022-1-1/output/"}}
)["batchSegmentJobArn"]*左滑查看更多
接下来我们会轮训地监控任务状态,任务完成后会在Amazon S3 目录中生成 ad_id_list.json.out 文件,等待任务完成后拉去并展示结果。
# 以下代码会轮训任务作业创建状态,待作业完成后方可取回结果
max_time = time.time() + 10*60*60 # 10 hours
while time.time() < max_time:job_response = personalize.describe_batch_segment_job(batchSegmentJobArn= batch_job_arn)print(job_status) job_status = job_response["batchSegmentJob"]["status"]if job_status == "ACTIVE" or job_status == "CREATE FAILED":breaktime.sleep(60)
s3.download_file('personalize-user-segmentation-poc-2022-1-1', 'output/ad_id_list.json.out', 'potential_user.json')
!cat potential_user.json*左滑查看更多
至此我们完成了用户行为数据集的数据清洗和预处理,数据集的构建,用户分群方案和方案版本的构建,以及针对广告 ID 的用户分群的批处理以及潜在用户的结果生成。用户分群的使用场景非常广泛,在电商场景中的数据应用本方案,可以将电商中的商品对应本文中的广告 ID,寻找对潜在商品感兴趣的用户进行针对推荐,也可以导入 ITEM 数据集,轻松构建商品的品类和属性,创建针对不同品类/SKU 的商品的推荐用户列表。取得的用户 ID ,可以进行针对性推送通知推荐和优惠活动,进行用户激活,引导潜在用户的购买行为。
除此之外,Amazon Personalize 也可以支持增量的数据训练,以满足不同场景的用户需要。
本篇作者

Aonan Guan
解决方案架构师
负责基于亚马逊云科技云计算方案架构的咨询和设计,推广亚马逊云科技云平台技术和各种解决方案。专注 Builder Expereience 和效率工程。

听说,点完下面4个按钮
就不会碰到bug了!