在一次Java Web应用程序的优化升级过程中,从Tomcat 7.0.109版本升级至8.5.93版本后,尽管在预发布环境中验证无误,但在灰度环境中却发现了一个令人困惑的问题:新日志记录神秘“失踪”。本文深入探讨了这一问题的排查与解决过程,揭示了由Tomcat升级引发的不寻常日志记录故障背后的技术细节。

问题现象
在最近的一次优化需求中,对一个Java的Web应用做如下变更:
1. tomcat升级:7.0.109 => 8.5.93
2. pom中的部分依赖版本更新
本次变更在预发环境验证没问题,而在部署到灰度环境后,发现灰度机器上没有新的日志记录产生了。
问题排查▐ 排查思路
对于没有日志记录的问题有以下排查方向:
1. 看启动日志是否有明显报错,通过分析报错来定位原因
2. 看还有没有请求流量,判断是否由于没有流量导致的
3. 排查机器是否还有足够的存储空间,判断是否因为磁盘空间不足导致写不进去
4. 检测日志记录的代码是否正确执行
1-3经过验证可以排除掉了,所以现在登上问题机器,通过Arthas来对代码执行逻辑进行排查。
▐ 排查代码
首先检查logger实例是否生成
通过arthas的watch命令(推荐安装arthas idea插件来快速生成命令),可以看见日志类(org.slf4j.impl.Log4jLoggerAdapter)是存在的,所以可以排除由于缺少logger实例导致没打印日志的可能。
日志打印逻辑是否被执行
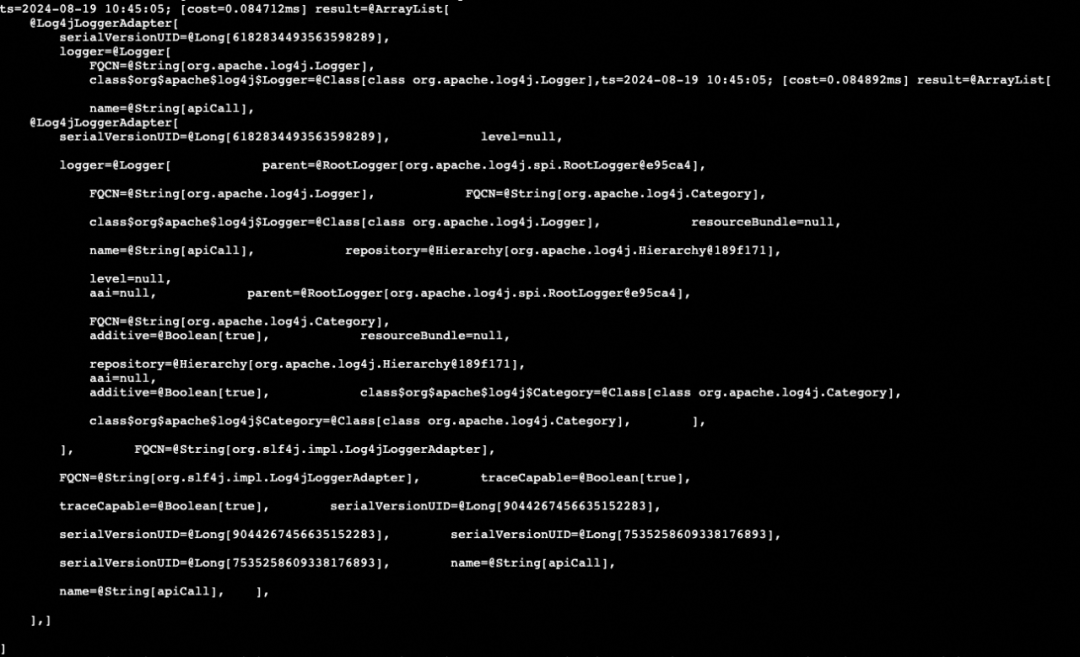
因为并不是调用log方法就一定会打印,比如日志等级的设置、执行异常等原因都会导致不打日志,所以要检查日志组件的log方法是否被正确执行。
通过arthas的trace命令可以看见(下图所示),确实执行了日志组件org.apache.log4j.log()方法且没有报错。(注意这里ClassLoader是ParallelWebappClassLoader,即Tomcat的自定义的ClassLoader)

由于应用中引入的log4j是1.4编译的jar包,trace命令是基于javaagent技术重新编译字节码, 而Instrumentation只对1.6以上编译的类支持字节码操作,所以报错UnsupportedClassVersionError,导致无法继续下钻了。

上面看似一切正常,其实到这里问题原因已经浮现:第一步Logger对象Log4jLoggerAdapter和第二步的org.apache.log4j.Logger, 都在表明现在用的日志组件是log4j,而此应用上只有logback的配置文件。
那么Log4jLoggerAdapter日志对象是怎么生成的了?
通过对生成的Logger对象的LoggerFactory.getLogger()方法进行分析,最终定位Log4jLoggerAdapter是由org.slf4j.impl.StaticLoggerBinder生成。
通过arthas sc -d <classname> 命令,我们查找StaticLoggerBinder是从那个jar包引入的。通过上面排查信息我们最终定位classLoader为ParallelWebappClassLoader一项。
在问题机器上StaticLoggerBinder类属于slfj-log4j12-1.7.7jar包,而正常机器如下图所示是属于logback-classic-1.2.3.jar
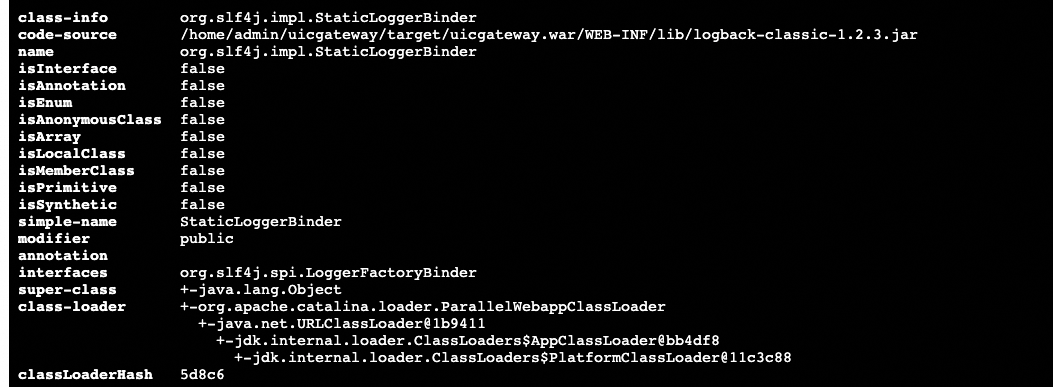
也就是说正常机器使用的logback-classic-1.2.3.jar提供的StaticLoggerBinder,问题机器使用的slfj-log4j12-1.7.7提供的StaticLoggerBinder。最终导致生成的日志组件不同。
总结
问题机器上存在log4j和logback两个jar包,同时两个jar包都存在org.slf4j.impl.StaticLoggerBinder类,基于某种原因最终加载了log4j(预期logback)的StaticLoggerBinder类,从而使用了log4j日志组件,而应用没有log4j相关的配置,最终导致没有日志输出。
接下来需要对这个某种原因进行分析,找出问题的本质。
根因分析▐ 问题拆解
想要完全回答是什么原因导致最终加载log4j日志组件,可以基于时间顺序提出3个关键问题:
1. 哪些jar包在什么时候会被导入到web应用中?
2. 什么时候由谁去加载类文件?
3. 加载类时如何选择从那个jar包读取?
Jar包如何被导入
我们知道java程序,首先要编写java文件,然后javac编译成class字节码文件(或再打成jar包),然后由jvm的类加载器基于双亲委派机制导入到内存中。
对于tomcat的web应用来说, 并不是通过java直接运行一个jar包,而是会先打成war包,然后将war包部署到机器的webapp目录下,最后tomcat运行时会读取和运行webapp目录下的文件。war包结构如下:
WEB-INF:
-lib // 依赖的jar包
-class //本项目代码编译后的.class文件
-web.xml // 全局配置文件
index.html //静态资源
在maven项目,可以通过在pom文件中定义依赖,然后由maven打包插件maven-war-plugin来生成war包,依赖的jar包也就在此时打进war包的lib目录下。
是不是所有pom定义的jar包都会被打进去lib文件夹里面?
并不是,比如pom中主动排掉的包或者由于冲突被maven仲裁掉的包,打包时都会被过滤掉。而本次涉及两个日志组件依赖即没有冲突,也没有被显示排除,所以都会被打到lib目录中。
<dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.2.3</version>
</dependency><dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.7</version>
</dependency>总结:由于两个日志组件jar包坐标不一样,不会被因为版本冲突被仲裁,都会被maven打包插件打进到war包中,供tomcat后续使用。
类如何被加载
从类的加载机制可知,在new、getstatic、putstatic、invokestatic等字节码命令或反射调用都会触发类的加载,此时会由类加载器找到class文件并导入到jvm内存中,再经过验证、准备、解析和初始化等阶段,最终完成类的加载。此过程两个关键知识点:
1. 每个类加载器都有自己独立的存储空间,所以类加载器+类全限定名才能确定唯一的类。
2. 类加载默认遵循双亲委派机制,这样可以避免类重复加载,也可以避免一些核心类被篡改。
但是在tomcat,由于可以部署多个应用,每个应用可能会存在jar包冲突。所以需要打破双亲委派机制,来达到基于应用的jar包隔离。
所以tomcat会为每个webApp创建一个ParallelWebappClassLoader实例,此实例会优先进行类加载,查找不到再委派给父类查找。
总结:一些特殊命令(如new创建实例、调用反射方法)会触发类的加载,而在tomcat应用中,类会由tomcat自定义的ClassLoader优先进行加载。
类加载时的Jar包选择
上面分析知道机器上会存在两个不同的日志组件jar包,同时类是由tomcat优先加载的,所以可以合理怀疑新老机器使用不同的日志组件问题,是因为tomcat7和tomcat8类加载机制不一致导致的。
下面对Tomcat的ParallelWebappClassLoader源码进行分析,找出类如何被加载的。以下是用于排查问题的快速分析方法,并没有逐行分析源码,所以只列出关键代码片段解释分析思路。
Tomcat7
从ParallelWebappClassLoader中直接找类查找方法, 即WebappClassLoaderBase#findClass方法,再定位到其内部findClassInternal方法。
我们主要关心Class是怎么生成,所以这个方法会先找到片段2和片段3,知道当entry.loadedClass存在直接返回,不存在则基于entry进行初始化,留意下初始化时的关键属性entry.codeBase。
所以下一步找entry从哪来的,定位到片段1,接下来看findResourceInternal方法。
// name为类的全限定名
protected Class<?> findClassInternal(String name) throws ClassNotFoundException {// 片段1ResourceEntry entry = findResourceInternal(name, path, true);// 片段2Class<?> clazz = entry.loadedClass;if (clazz != null)return clazz;// 片段3try {clazz = defineClass(name, entry.binaryContent, 0,entry.binaryContent.length,new CodeSource(entry.codeBase, entry.certificates));} catch (UnsupportedClassVersionError ucve) {throw new UnsupportedClassVersionError(ucve.getLocalizedMessage() + " " +sm.getString("webappClassLoader.wrongVersion",name));}entry.loadedClass = clazz;entry.binaryContent = null;entry.codeBase = null;entry.manifest = null;entry.certificates = null;}WebappClassLoaderBase#findResourceInternal
同样主要关心ResourceEntry是怎么生成的。
片段1可知先从resourceEntries这个本地缓存取,那么我们要看的就是缓存何时写的,也就是找put方法,定位片段3,即是在本方法完成了写入,所以往上找entry初始化位置,即片段2。
前面提到过类的初始定义关键是codeBase(jar包的物理绝对路径),所以我们要看jarRealFiles这个数组的数据从哪来,从而定位到addJar方法,以及调用addJar的setRepositories方法。
protected ResourceEntry findResourceInternal(final String name, final String path, final boolean manifestRequired) {// 片段1ResourceEntry entry = resourceEntries.get(path);if (entry != null) {return entry;}// 片段2try {entry.codeBase = getURI(jarRealFiles[i]);entry.source =UriUtil.buildJarUrl(entry.codeBase.toString(), jarEntryPath);entry.lastModified = jarRealFiles[i].lastModified();} catch (MalformedURLException e) {return null;}// 片段3synchronized (resourceEntries) {// Ensures that all the threads which may be in a race to load// a particular class all end up with the same ResourceEntry// instanceResourceEntry entry2 = resourceEntries.get(path);if (entry2 == null) {resourceEntries.put(path, entry);} else {entry = entry2;}}}WebappLoader#setRepositories
我们从片段3中addJar方法往上找,可以看见addJar的关键参数destFile是来源片段2中libDir.list(""),同时片段1中libPath就是我们存放jar包的位置。
所以看libDir.list中怎么实现。
private void setRepositories() throws IOException {// 片段1String libPath = "/WEB-INF/lib";classLoader.setJarPath(libPath);DirContext libDir = null;// Looking up directory /WEB-INF/lib in the contexttry {Object object = resources.lookup(libPath);if (object instanceof DirContext)libDir = (DirContext) object;} catch (NamingException e) {// Silent catch: it's valid that no /WEB-INF/lib collection// exists}// 片段2enumeration = libDir.list("");while (enumeration.hasMoreElements()) {NameClassPair ncPair = enumeration.nextElement();File destFile = new File(destDir, ncPair.getName());// 片段3try {JarFile jarFile = JreCompat.getInstance().jarFileNewInstance(destFile);classLoader.addJar(filename, jarFile, destFile);} catch (Exception ex) {// Catch the exception if there is an empty jar file// Should ignore and continue loading other jar files// in the dir}}}FileDirContext#list
最终定位方法中,片段1是查找出当前目录下所有文件名,而在片段2中做了一次名称排序,最后片段3中构造并返回。
所以可以得出结论,tomact7中的jar包会按照名称排序。
protected List<NamingEntry> list(File file) {List<NamingEntry> entries = new ArrayList<NamingEntry>();if (!file.isDirectory())return entries;// 片段1String[] names = file.list();if (names==null) {/* Some IO error occurred such as bad file permissions.Prevent a NPE with Arrays.sort(names) */log.warn(sm.getString("fileResources.listingNull",file.getAbsolutePath()));return entries;}// 片段2Arrays.sort(names); // Sort alphabeticallyNamingEntry entry = null;// 片段3for (int i = 0; i < names.length; i++) {File currentFile = new File(file, names[i]);Object object = null;if (currentFile.isDirectory()) {FileDirContext tempContext = new FileDirContext(env);tempContext.setDocBase(currentFile.getPath());tempContext.setAllowLinking(getAllowLinking());object = tempContext;} else {object = new FileResource(currentFile);}entry = new NamingEntry(names[i], object, NamingEntry.ENTRY);entries.add(entry);}return entries;}Tomcat8
WebappClassLoaderBase#findClassInternal
和tomcat7一样,首先来分析findClassInternal方法,此方法中关键是ResourceEntry是如何获取。
如片段1所示,tomcat8中ResourceEntry获取调用的是resources.getClassLoaderResource()
protected Class<?> findClassInternal(String name) {checkStateForResourceLoading(name);if (name == null) {return null;}String path = binaryNameToPath(name, true);ResourceEntry entry = resourceEntries.get(path);WebResource resource = null;if (entry == null) {// 片段1resource = resources.getClassLoaderResource(path);if (!resource.exists()) {return null;}entry = new ResourceEntry();entry.lastModified = resource.getLastModified();// Add the entry in the local resource repositorysynchronized (resourceEntries) {// Ensures that all the threads which may be in a race to load// a particular class all end up with the same ResourceEntry// instanceResourceEntry entry2 = resourceEntries.get(path);if (entry2 == null) {resourceEntries.put(path, entry);} else {entry = entry2;}}}StandardRoot#getClassLoaderResource
这一步很奇怪,jar包存放路径是/WEB-INF/lib,而这里是/WEB-INF/classes,分析错了?继续下钻!
@Override
public WebResource getClassLoaderResource(String path) {return getResource("/WEB-INF/classes" + path, true, true);
}StandardRoot#getResourceInternal
返回对象WebResource是由webResourceSet的getResource方法生成。而getResource方法在根据path路径查找文件了。显然现在需要从webResourceSet着手分析,看看这个allResources和webResourceSet是怎么来的。
protected final WebResource getResourceInternal(String path,boolean useClassLoaderResources) {WebResource result = null;WebResource virtual = null;WebResource mainEmpty = null;for (List<WebResourceSet> list : allResources) {for (WebResourceSet webResourceSet : list) {if (!useClassLoaderResources && !webResourceSet.getClassLoaderOnly() ||useClassLoaderResources && !webResourceSet.getStaticOnly()) {result = webResourceSet.getResource(path);if (result.exists()) {return result;}if (virtual == null) {if (result.isVirtual()) {virtual = result;} else if (main.equals(webResourceSet)) {mainEmpty = result;}}}}}// Use the first virtual result if no real result was foundif (virtual != null) {return virtual;}// Default is empty resource in main resourcesreturn mainEmpty;}StandardRoot中WebResourceSet的初始化如下
可以看到初始都是空数组,而allResources数组第一个元素是preResources,意味上面查找中会先在preResources中查询、其次是mainResources。
接下来要找什么时候往这些Resources添加数据。
private final List<WebResourceSet> preResources = new ArrayList<>();
private final List<WebResourceSet> classResources = new ArrayList<>();
private final List<WebResourceSet> jarResources = new ArrayList<>();
private final List<WebResourceSet> postResources = new ArrayList<>();
private final List<WebResourceSet> mainResources = new ArrayList<>();
private WebResourceSet main;
private final List<List<WebResourceSet>> allResources =new ArrayList<>();{allResources.add(preResources);allResources.add(mainResources);allResources.add(classResources);allResources.add(jarResources);allResources.add(postResources);}StandardRoot#createWebResourceSet
通过全局搜索preResources,定位createWebResourceSet方法,这里WebResourceSet创建依赖入参,所以找此方法调用来源。
public void createWebResourceSet(ResourceSetType type, String webAppMount,String base, String archivePath, String internalPath) {List<WebResourceSet> resourceList;WebResourceSet resourceSet;switch (type) {case PRE:resourceList = preResources;break;case CLASSES_JAR:resourceList = classResources;break;case RESOURCE_JAR:resourceList = jarResources;break;case POST:resourceList = postResources;break;default:throw new IllegalArgumentException(sm.getString("standardRoot.createUnknownType", type));}resourceSet = new JarWarResourceSet(this, webAppMount, base, archivePath, internalPath);resourceList.add(resourceSet);StandardRoot#processWebInfLib
定位到createWebResourceSet方法的调用方,终于看到"/WEB-INF/lib",同时入参webAppMount被设置为"/WEB-INF/classes",这是一个挂载路径(类似虚拟目录),实际物理路径是possibleJar.getURL()。
在分析listResources方法之前,有必要看下processWebInfLib方法又是什么时候被调用。
private void processWebInfLib() {WebResource[] possibleJars = listResources("/WEB-INF/lib", false);for (WebResource possibleJar : possibleJars) {if (possibleJar.isFile() && possibleJar.getName().endsWith(".jar")) {createWebResourceSet(ResourceSetType.CLASSES_JAR,"/WEB-INF/classes", possibleJar.getURL(), "/");}}}StandardRoot#startInternal
可以看见processWebInfLib在一个启动方法中被调用, 注意片段1 mainResources添加一个main对象, main为DirResourceSet类实例,也就是说现在allResources非空了。
@Overrideprotected void startInternal() throws LifecycleException {mainResources.clear();//片段1main = createMainResourceSet();mainResources.add(main);for (List<WebResourceSet> list : allResources) {// Skip class resources since they are started belowif (list != classResources) {for (WebResourceSet webResourceSet : list) {webResourceSet.start();}}}// This has to be called after the other resources have been started// else it won't find all the matching resourcesprocessWebInfLib();// Need to start the newly found resourcesfor (WebResourceSet classResource : classResources) {classResource.start();}cache.enforceObjectMaxSizeLimit();setState(LifecycleState.STARTING);}回头继续分析listResources方法
从上面我们知道allResources中mainResurces数组下有一个DirContenxtSet实例。所以webResourceSet.list(path) 可以定位到DirResourceSet类。
private String[] list(String path, boolean validate) {if (validate) {path = validate(path);}// Set because we don't want duplicates// LinkedHashSet to retain the order. It is the order of the// WebResourceSet that matters but it is simpler to retain the order// over all of the JARs.HashSet<String> result = new LinkedHashSet<>();for (List<WebResourceSet> list : allResources) {for (WebResourceSet webResourceSet : list) {if (!webResourceSet.getClassLoaderOnly()) {String[] entries = webResourceSet.list(path);for (String entry : entries) {result.add(entry);}}}}return result.toArray(new String[result.size()]);
}DirResourceSet#list
最终定位到这里,DirResourceSet的webAppMout是"/", 所以进入片段1逻辑, file.list()方法直接返回了/WEB-INF/lib下的所有jar包路径(并没有像Tomcat7那样再用Arrays.sort进行排序)。
tomcat8在web应用启动时就把lib目录下所有的文件路径都导入到WebResourceSet中,后续进行类查找直接从WebResourceSet中查找,避免每次都调用系统file.list方法。
public String[] list(String path) {checkPath(path);String webAppMount = getWebAppMount();if (path.startsWith(webAppMount)) {File f = file(path.substring(webAppMount.length()), true);if (f == null) {return EMPTY_STRING_ARRAY;}// 片段1String[] result = f.list();if (result == null) {return EMPTY_STRING_ARRAY;} else {return result;}} else {if (!path.endsWith("/")) {path = path + "/";}if (webAppMount.startsWith(path)) {int i = webAppMount.indexOf('/', path.length());if (i == -1) {return new String[] {webAppMount.substring(path.length())};} else {return new String[] {webAppMount.substring(path.length(), i)};}}return EMPTY_STRING_ARRAY;}}总结:tomcat7中导入jar包列表会按照jar包名称进行字典排序,而tomcat8获取jar包列表未经过排序,所以tomcat7在不同机器上进行类加载时,每次都能定位到同一个的jar包,而在tomcat8中无法保证。
▐ 预发环境为什么没触发
由上面可知tomcat8是直接调用file.list()获取文件列表, 而list是一个本地方法, 可以上github看openJdk8源码,(如果对C语言不太了解,可以结合chatGPT来理解此次代码逻辑)。
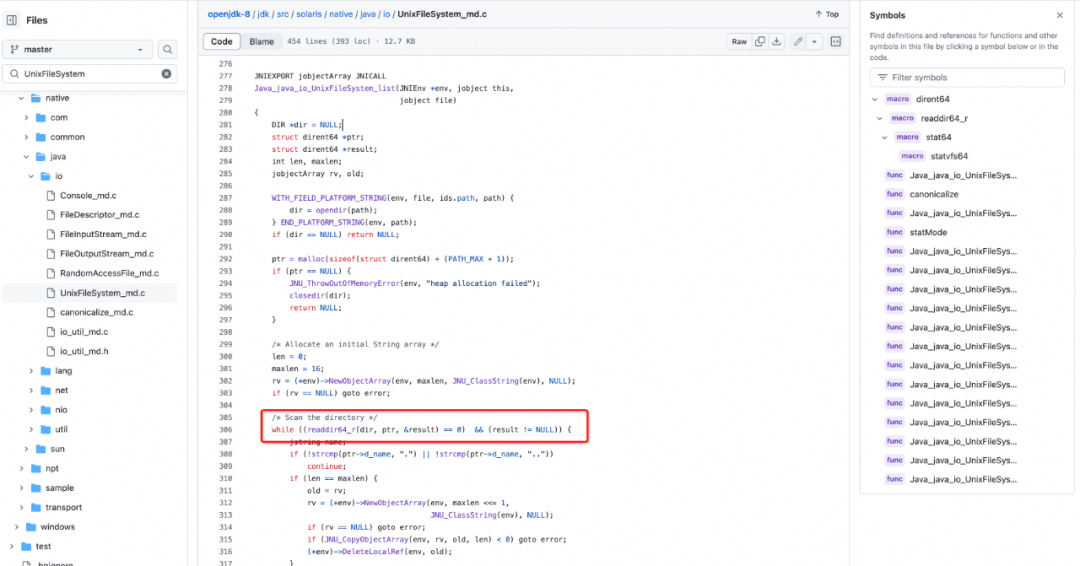
可以看见是通过readdir64_r遍历目录,而readdir64_r实现与系统有关,比如ext4文件系统通过hashTree来缓存目录文件,此时不保证文件列表是有序的。
▐ 总结
通过上面分析可知,由于log4j和logback的坐标不同(但都存在org.slf4j.impl.StaticLoggerBinder类),所以这两个的jar包都会打进到webapp目录中。
tomact7在对org.slf4j.impl.StaticLoggerBinder类加载时,会先对jar包按照名称排序后再查找(logback按名称会排在前面),所以每次都能从logback中加载此类。
而在tomcat8并不会主动排序,完全取决文件系统返回的jar包列表,此时不保证有序,最终而tomca8下无法确保了每次都从logback中加载。

解决方法
在根因分析中拆解出的三个关键问题,其实也是对应解决方案的切入点。
▐ 1. Jar包导入阶段
一个重要原因是由于不同jar包存在相同的类,产生隐式冲突。所以可以手动排包来解决冲突。
可以用manven-enforcer插件来扫描出所有jar包冲突以及有重复类的jar包。
▐ 2. 类的加载阶段
如上分析问题的直接原因是不同版本tomcat的ClassLoader逻辑差异,所以我们可以重写或自定义ClassLoader来定制我们类加载逻辑。
▐ 3. 类加载时Jar包选择阶段
如果不希望像2对整个ClassLoader做改造,那么可以在关键Jar包选择时找下解决办法:
第一种:回退到tomcat7,基于tomcat7有序加载jar包机制,保证所有机器表现是一样,线下环境发现问题再按需排包。
第二种:tomcat8是可以支持类加载时指定优先使用的Jar包:在Tomcat的Context.xml中定义PreSources(如根因分析中对tomcat8的分析可知,类查找时会先遍历PreResources)。
<Resources><PreResources base="D:\Projects\lib\library1.jar"className="org.apache.catalina.webresources.JarWarResourceSet"webAppMount="/WEB-INF/classes"/>
</Resources>
结语
本文详细记录了一次由升级Tomcat引起的日志记录故障的排查与解决过程,深入分析了问题发生的背景、具体现象、排查步骤、根本原因及解决方案,为遇到类似问题的开发者提供了宝贵的参考和解决思路。通过这次经历,不仅揭示了软件升级过程中可能遇到的兼容性问题,还强调了理解应用程序底层技术栈,如类加载机制、日志框架工作原理的重要性。

参考资料
[1] 《JVM字节码详解》:https://blog.csdn.net/jifashihan/article/details/141420420
[2] 《JavaAgent技术原理》:
https://www.jianshu.com/p/4b5b533385f7
[3] 《双亲委派模式》:
https://www.jianshu.com/p/5e0441cd2d4c
[4] 《maven的仲裁机制》:
https://baijiahao.baidu.com/s?id=1745192284330030901&wfr=spider&for=pc
[5] 《一文搞懂Java类加载机制》:
https://blog.csdn.net/BarackYoung/article/details/137060856
[6] 《Tomcat 的类加载机制》:
https://cloud.tencent.com/developer/article/2089600
[7] 《tomcat7 与 tomcat8 加载 jar包的顺序》:https://www.cnblogs.com/zjdxr-up/p/17139374.html
[8] 《一文读懂常用日志框架(Log4j、SLF4J、Logback)有啥区别》:https://cloud.tencent.com/developer/article/1400334
团队介绍我们是淘天集团-技术线-会员技术团队,团队中既有88VIP、淘宝省钱卡、天猫积分等淘天集团的重点业务,也有提供亿级QPS为全淘宝业务提供底座支持的淘宝账号与会话、淘宝收货地址等基础产品平台。我们肩负着会员增长和大盘成交的使命,以数智化的手段和多种增长策略撬动会员业务增长。在文化上我们倡导追求卓越和责任担当,在技术上我们坚持技术创新与突破。在这里你可以了解到会员基础交易体系、权益履约体系、积分营销玩法体系。一起做大规模、服务好电商高价值用户。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法