文章目录
- 前言
- 一、论文内容简述
- 创新点(特点,与DQN的区别):
- 可借鉴参数:
- 细节补充:
- 二、细节1:weight_decay
- 原理
- 代码
- 三、细节2:OUNoise
- 原理
- 代码
- 四、细节3:ObsNorm
- 原理
- 代码
- 改进
- 五、细节4:net_init
- 原理
- 代码
- 六、细节全部加入后
- 环境Pendulum-v1下测试
- 环境MountainCarContinuous-v0下测试
- 关于sigma这个参数如何调节
- 总结
- 1.
- 2.
前言
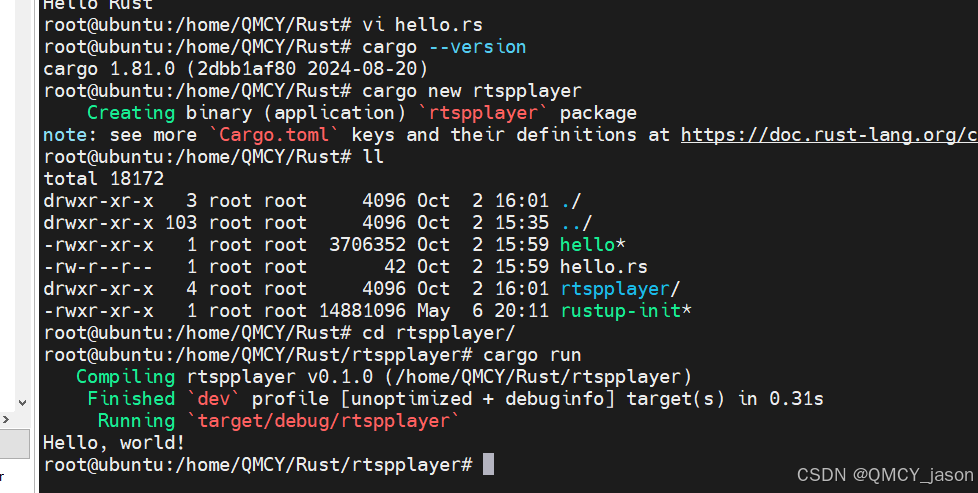
这里为复现论文ddpg时,遇到的4个细节,及如何将它实现。
论文:CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING 链接:https://arxiv.org/pdf/1509.02971
参考复现代码:
参考1:https://github.com/songrotek/DDPG
参考2:https://github.com/shariqiqbal2810/maddpg-pytorch/
等等(其余相关参考会细节处体现)
适用于:已经知道ddpg原理,但发现借用的代码不work时,来寻求更符合原论文代码的人群。
Talk is cheap. Show me the code.
代码实现在:FreeRL (欢迎star)
ddpg在原论文是针对continue环境提出的,这里仅实现了continue形式的ddpg,后续有空会再补写一个离散域环境的ddpg。
一、论文内容简述
创新点(特点,与DQN的区别):
1.提出一种a model-free, off-policy actor-critic 算法 ,并证实了即使使用原始像素的obs,也能使用continue action spaces 稳健解决各种问题。
2.不需要更改环境的情况下,可以进行稳定的学习。
3.比DQN需要更少的经验步就可以收敛。
可借鉴参数:
hidden:400 -300
actor_lr = 1e-4
critic_lr = 1e-3
buffer_size = 1e6
gamma = 0.99
tau = 0.001
std = 0.2 #高斯标准差
细节补充:
1.weight_decay:对Q使用了正则项l2进行1e-2来权重衰减
2.OUNoise:使用时间相关噪声来进行探索used an Ornstein-Uhlenbeck process theta=0.15 std=0.2
3.ObsNorm:使用批量归一化状态值
4.net_init:对于低维环境 对actor和critic的全连接层的最后一层使用uniform distribution[-3e-3,3e-3],其余层为[-1/sqrt(f),1/sqrt(f)],f为输入的维度;对于pixel case 最后一层-3e-4,3e-4,其余层[-1/sqrt(f),1/sqrt(f)]
论文原文:

为了区分原论文的ddpg和一般github上给出的大部分的ddpg的区别,这里先实现了下简单的大部分的ddpg。(以TD3作者给出的他们的ddpg为参考)命名为DDPG_simple
代码:DDPG_simple.py
二、细节1:weight_decay
操作:对Q使用了正则项l2进行1e-2来权重衰减
原理
原理:使用L2正则项来防止过拟合。
关于L2正则项的解释:机器学习:L2正则项(权重衰减)和梯度的理解
这里说道:L2正则项能防止过拟合的原因是可以让权重变小。
为什么权重变小可以用来防止过拟合:
一个所谓“显而易见”的解释就是:更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合刚刚好(这个法则也叫做奥卡姆剃刀),而在实际应用中,也验证了这一点,L2正则化的效果往往好于未经正则化的效果。
稍微数学一点的解释是:过拟合的时候,拟合函数的系数往往非常大,为什么?如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。

代码
Adam(pytorch官方)
'''补充 weight_decay 实现上均不相同 这里选择参考1参考1:https://github.com/sfujim/TD3/blob/master/DDPG.py#L55 # adam内部实现参考2:https://github.com/shariqiqbal2810/maddpg-pytorch/blob/master/algorithms/maddpg.py#L161 # 手动实现 weight_decay = 1e-3参考3:https://github.com/openai/baselines/blob/master/baselines/ddpg/ddpg_learner.py#L187 # tf内部实现 weight_decay = 0'''if supplement['weight_decay']: self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr,weight_decay=1e-3) #原论文值: 1e-2else:self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)
在Pendulum1的环境下,seed = 0的情况下测试了3次,结果如下:
紫色为=1e-2的情况,黄色为1e-3的情况,绿色为不加此参数的情况。
可以看到加入此参数可能会造成学习曲线的波动,这是可以预测的,因为它会防止学习曲线过于拟合。
最终选择参数为weight_decay=1e-3。

三、细节2:OUNoise
操作:使用时间相关噪声来进行探索used an Ornstein-Uhlenbeck process
原理
原理:使用OUNoise对比于高斯噪声,有了时间上的维度,可以使噪声沿着一个方向上多探索几步,而高斯噪声的前后两次噪声不相关。
关于OUNoise的解释:
参考1.强化学习中Ornstein-Uhlenbeck噪声是鸡肋吗?
参考2.强化学习笔记 Ornstein-Uhlenbeck 噪声和DDPG
OUNoise中的参数theta(θ),sigma(σ),dt(时间离散粒度),
高斯噪声无时间离散粒度,也就是默认为1
结论:
1.dt(时间离散粒度参数)在=1(比较大)的情况下,几乎和高斯噪声一致。(–参考2),
2.sigma参数和高斯的sigma参数一致,根据代码self.sigma * np.random.randn(self.action_dim)可见,此参数的含义是一致的,此参数越大,扰动越大。(randn为给出N(0,1)的数)
3.theta值越大,向均值的考虑更多一些。
4.OUNoise更适合于惯性系统。(控制机械臂,汽车刹车)
代码
'''
补充 OUNoise 两者仅区别在采样时间的有无 OUNoise 适用于时间离散粒度小的环境/惯性环境/需要动量的环境 优势:就像物价和利率的波动一样,这有利于在一个方向上探索。
这里根据参考1,修改加入参考2、3
参考1: https://github.com/songrotek/DDPG/blob/master/ou_noise.py
参考2: https://github.com/openai/baselines/blob/master/baselines/ddpg/noise.py#L49
根据博客:https://zhuanlan.zhihu.com/p/96720878 选择参考2 加入采样时间系数
参考3: https://github.com/shariqiqbal2810/maddpg-pytorch/blob/master/utils/noise.py # maddpg中加入了一个scale参数
'''
class OUNoise:def __init__(self, action_dim, mu=0, theta=0.15, sigma=0.1, dt=1e-2, scale= None):self.action_dim = action_dimself.mu = muself.theta = thetaself.sigma = sigmaself.dt = dt # 参考1 相当于默认这里是1self.state = np.ones(self.action_dim) * self.muself.reset()self.scale = scale # 参考3def reset(self):self.state = np.ones(self.action_dim) * self.mudef noise(self):x = self.statedx = self.theta * (self.mu - x) + np.sqrt(self.dt) * self.sigma * np.random.randn(self.action_dim)self.state = x + dxif self.scale is None:return self.state else:return self.state * self.scaleif args.supplement['OUNoise']:ou_noise = OUNoise(action_dim, sigma = args.ou_sigma, scale = args.init_scale) #
while(探索):# 获取动作 区分动作action_为环境中的动作 action为要训练的动作if step < args.random_steps:action_ = env.action_space.sample() # [-max_action , max_action]action = action_ / max_action # -> [-1,1]else:action = policy.select_action(obs) # (-1,1)if args.supplement['OUNoise']:action_ = np.clip(action * max_action + ou_noise.noise()* max_action, -max_action, max_action)else: # 高斯噪声action_ = np.clip(action * max_action + np.random.normal(scale = args.gauss_sigma * max_action, size = action_dim), -max_action, max_action)...# episode 结束if done:if args.supplement['OUNoise']:ou_noise.reset()## OUNoise scale若有 scale衰减 参考:https://github.com/shariqiqbal2810/maddpg-pytorch/blob/master/main.py#L71if args.init_scale is not None:explr_pct_remaining = max(0, args.max_episodes + 1) / args.max_episodes # 剩余探索百分比ou_noise.scale = args.final_scale + (args.init_scale - args.final_scale) * explr_pct_remaining
这里还另外加了一个在maddpg代码中出现的scale参数。
蓝色为不加sacla参数,sigma参数=0.1的情况
紫色为加入scale参数=0.3(随时间衰减为0.0),sigma参数=0.1的情况
对比如下:

这里选择蓝色的情况,也更符合原论文。
四、细节3:ObsNorm
操作:使用批量归一化状态值
原理
原理:将状态标准化,使之在一定范围内,加速收敛。
方法1:若是提前知道所有状态,即有模型的强化学习(所有状态转移已知),则可以直接算出所有状态的mean,std,在训练开始前进行标准化。
方法2:若是无模型的强化学习,则每次将得到的状态存入,并增量式计算均值和方差,然后进行标准化。
方法2应该就是常见的RunningMeanStd的方法。
对于此,原论文的描述为:此技术将小批量中样本的每个维度标准化为具有单位均值和方差。此外,它还维护平均值和方差的运行平均值。
个人感觉是上述的方法2的意思,在openai的baseline中用的也是这个方法。
原论文描述:

关于此,知乎上有很多讨论:强化学习需要批归一化(Batch Norm) 或归一化吗?
上述博客也有一段ddpg原论文的截图,但是上述将ddpg归为用了batchnorm。
但是结论一致:
1.batchnorm(加入nn.BatchNorm1d(input_dim))的方法,对于DRL并不是必须的,可能还会造成性能的下降。
2.但是使用RunningMeanStd的方法确实可以提高性能。
(个人之前实验maac时的结果和上述两者一致)
在该博客的最后,大佬提出了自己归一的另一个思路(个人感觉,ddpg原作者的意思也是如此。)

此方法在该小雅库的这里写出:https://github.com/AI4Finance-Foundation/ElegantRL/blob/master/elegantrl/agents/AgentPPO.py#L226
注:训练前期,算出来的mean和std不稳定在简单任务导致的影响,在我的实验中也发现了这点,见下面代码部分的图。
代码
'''
补充:ObsNorm 根据原论文的描述:此技术将小批量中样本的每个维度标准化为具有单位均值和方差,此外,它还维护平均值和方差的运行平均值。这个trick更像是RunningMeanStd
这里选用参考3
参考1:https://github.com/shariqiqbal2810/maddpg-pytorch/blob/master/utils/networks.py#L19 # 直接使用batchnorm 不符合原论文
参考2:https://github.com/openai/baselines/blob/master/baselines/ddpg/ddpg_learner.py#L103 # √
参考3:https://github.com/Lizhi-sjtu/DRL-code-pytorch/blob/main/5.PPO-continuous/normalization.py#L4
参考4:https://github.com/zhangchuheng123/Reinforcement-Implementation/blob/master/code/ppo.py#L62 与参考3类似
'''
class RunningMeanStd:# Dynamically calculate mean and stddef __init__(self, shape): # shape:the dimension of input dataself.n = 0self.mean = np.zeros(shape)self.S = np.zeros(shape)self.std = np.sqrt(self.S)def update(self, x):x = np.array(x)self.n += 1if self.n == 1:self.mean = xself.std = xelse:old_mean = self.mean.copy()self.mean = old_mean + (x - old_mean) / self.nself.S = self.S + (x - old_mean) * (x - self.mean)self.std = np.sqrt(self.S / self.n)class Normalization:def __init__(self, shape):self.running_ms = RunningMeanStd(shape=shape)def __call__(self, x, update=True):# Whether to update the mean and std,during the evaluating,update=False #是否更新均值和方差,在评估时,update=Falseif update:self.running_ms.update(x)x = (x - self.running_ms.mean) / (self.running_ms.std + 1e-8)return xobs,info = env.reset(seed=args.seed)
if args.supplement['ObsNorm']:obs_norm = Normalization(shape = obs_dim)obs = obs_norm(obs)
while(探索):if args.supplement['ObsNorm']:next_obs = obs_norm(next_obs)# episode 结束if done:obs,info = env.reset(seed=args.seed)if args.supplement['ObsNorm']:obs = obs_norm(obs)
if args.supplement['ObsNorm']:np.save(os.path.join(model_dir,f"{args.policy_name}_running_mean_std.npy"),np.array([obs_norm.running_ms.mean,obs_norm.running_ms.std]))
使用上述RunningMeanstd的结果如下:
使用的结果为黄色线,意外的耗时并不是很多,但是确实训练前期会导致不稳定的情况。

x = (x - self.running_ms.mean) / (self.running_ms.std + 1e-8) 对于这里的1e-8值,进行了1e-9,1e-7,1e-5的修改,发现均不如1e-8值来的稳定。(紫:1e-5,灰:1e-7,蓝: 1e-9)

改进
根据上述RuningMeanStd的方法和ddpg原论文的描述,将RuningMeanStd的方法(一个state一个state的更新)改进成ddpg原论文描述的(一个batch_size的state一个batch_size的state的更新)
代码:
### modify
class RunningMeanStd_batch_size:# Dynamically calculate mean and stddef __init__(self, shape): # shape:the dimension of input dataself.n = 0self.mean = torch.zeros(shape)self.S = torch.zeros(shape)self.std = torch.sqrt(self.S)def update(self, x):x = x.mean(dim=0,keepdim=True)self.n += 1if self.n == 1:self.mean = xself.std = xelse:old_mean = self.mean self.mean = old_mean + (x - old_mean) / self.nself.S = self.S + (x - old_mean) * (x - self.mean)self.std = torch.sqrt(self.S / self.n)class Normalization_batch_size:def __init__(self, shape):self.running_ms = RunningMeanStd_batch_size(shape=shape)def __call__(self, x, update=True):# Whether to update the mean and std,during the evaluating,update=False #是否更新均值和方差,在评估时,update=Falseif update:self.running_ms.update(x)x = (x - self.running_ms.mean) / (self.running_ms.std + 1e-8)return xclass DDPG: def __init__(self, dim_info, is_continue, actor_lr, critic_lr, buffer_size, device, trick = None,supplement = None):obs_dim, action_dim = dim_infoself.agent = Agent(obs_dim, action_dim, dim_info, actor_lr, critic_lr, device, trick, supplement)self.buffer = Buffer(buffer_size, obs_dim, act_dim = action_dim if is_continue else 1, device = device) #Buffer中说明了act_dim和action_dim的区别self.device = deviceself.is_continue = is_continueself.trick = trickself.supplement = supplementif self.supplement['Batch_ObsNorm']:self.batch_size_obs_norm = Normalization_batch_size(shape = obs_dim)def select_action(self, obs):obs = torch.as_tensor(obs,dtype=torch.float32).reshape(1, -1).to(self.device) # 1xobs_dimif self.supplement['Batch_ObsNorm']:obs = self.batch_size_obs_norm(obs,update=False)# 先实现连续域下的ddpgif self.is_continue: # dqn 无此项action = self.agent.actor(obs).detach().cpu().numpy().squeeze(0) # 1xaction_dim -> action_dimelse:action = self.agent.argmax(dim = 1).detach().cpu().numpy()[0] # []标量return actiondef evaluate_action(self, obs):'''确定性策略ddpg,在main中去掉noise'''return self.select_action(obs)## buffer相关def add(self, obs, action, reward, next_obs, done):self.buffer.add(obs, action, reward, next_obs, done)def sample(self, batch_size):total_size = len(self.buffer)batch_size = min(total_size, batch_size) # 防止batch_size比start_steps大, 一般可去掉indices = np.random.choice(total_size, batch_size, replace=False) #默认True 重复采样 obs, actions, rewards, next_obs, dones = self.buffer.sample(indices)if self.supplement['Batch_ObsNorm']:obs = self.batch_size_obs_norm(obs)next_obs = self.batch_size_obs_norm(next_obs,update=False) #只对输入obs进行更新return obs, actions, rewards, next_obs, dones
改进后效果如下:对比原来的和上述RunningMeanStd方法,效果好上不少。

五、细节4:net_init
操作:对于低维环境 对actor和critic的全连接层的最后一层使用uniform distribution[-3e-3,3e-3],其余层为[-1/sqrt(f),1/sqrt(f)],f为输入的维度;对于pixel case 最后一层-3e-4,3e-4,其余层[-1/sqrt(f),1/sqrt(f)]
原理
原理:使得初始化的价值估计更接近于0。
一般来说,uniform(low,high)的意思为使得生成的数在对应的 low 和 high 范围之间均匀分布。
对于 np.random.uniform和nn.init.uniform_都是如此。
代码
'''
补充 net_init
参考:https://github.com/floodsung/DDPG/blob/master/actor_network.py#L96
'''
def other_net_init(layer):if isinstance(layer, nn.Linear):fan_in = layer.weight.data.size(0)limit = 1.0 / (fan_in ** 0.5)nn.init.uniform_(layer.weight, -limit, limit)nn.init.uniform_(layer.bias, -limit, limit)def final_net_init(layer,low,high):if isinstance(layer, nn.Linear):nn.init.uniform_(layer.weight, low, high)nn.init.uniform_(layer.bias, low, high)class Actor(nn.Module):def __init__(self, obs_dim, action_dim, hidden_1=128, hidden_2=128,supplement=None,pixel_case=False):super(Actor, self).__init__()self.l1 = nn.Linear(obs_dim, hidden_1)self.l2 = nn.Linear(hidden_1, hidden_2)self.l3 = nn.Linear(hidden_2, action_dim)if supplement['net_init']:other_net_init(self.l1)other_net_init(self.l2)if pixel_case:final_net_init(self.l3, low=-3e-4, high=3e-4)else:final_net_init(self.l3, low=-3e-3, high=3e-3)def forward(self, x):x = F.relu(self.l1(x))x = F.relu(self.l2(x))x = F.tanh(self.l3(x))return xclass Critic(nn.Module):def __init__(self, dim_info:list, hidden_1=128 , hidden_2=128,supplement=None,pixel_case=False):super(Critic, self).__init__()obs_act_dim = sum(dim_info) self.l1 = nn.Linear(obs_act_dim, hidden_1)self.l2 = nn.Linear(hidden_1, hidden_2)self.l3 = nn.Linear(hidden_2, 1)if supplement['net_init']:other_net_init(self.l1)other_net_init(self.l2)if pixel_case:final_net_init(self.l3, low=-3e-4, high=3e-4)else:final_net_init(self.l3, low=-3e-3, high=3e-3)def forward(self, o, a): # 传入观测和动作oa = torch.cat([o,a], dim = 1)q = F.relu(self.l1(oa))q = F.relu(self.l2(q))q = self.l3(q)return q
实验效果如下:

六、细节全部加入后
其中选择的细节3为改进后的代码,更符合原论文。
环境Pendulum-v1下测试
在Pendulum-v1的环境下seed=0的情况下的结果如下:(这里的标准差sigma为0.1,batch_size=256)

环境MountainCarContinuous-v0下测试
在MountainCarContinuous-v0环境下seed=0的情况,sigma=1,batch_size=64 时,(DDPG的OUNoise参数dt=1时,默认dt=0.01会不收敛)
实验如下:黄色是不加细节的,橙色是加入细节的,可以看出后期橙色还是容易抖动,而黄色趋于平稳了。

后,我又将OUNoise改成maddpg的scale衰减的方法:init_scale=1
效果为如图紫色:

使用此技巧后,后期的振荡明显趋于平缓,效果明显优于上两种。
不过这并不能凸显出OUNoise的优势,因为高斯噪音也可以加入此技巧
加入此技巧后,如下图的粉色曲线,效果也依旧很好。

关于sigma这个参数如何调节
DDPG算法参数如何调节?(此链接有很详细的解答)
如下所示:

其中这里说说的策略噪声的方差是TD3中的技巧,这里DDPG并不涉及这个。
展示一下区别:
Pendulum-v1的环境
橙色为sigma=0.1时
绿色为sigma= 1时。
确实如上述链接大佬所言。(batch_size均为256)

在上述的简单环境下,差异都还不是特别明显,两者都能够收敛。
不过在MountainCarContinuous-v0环境下,两者区别就十分明显了。
黄色:sigma=1
紫色:sigma=0.1
batch_size均为64
可以看出在探索小的情况下,很容易找到一个次优解并不动了,在探索较大的情况下,可以对Q值进行正确的估计,从而找到最优解。

总结
1.
即使有了一个好的框架和算法,DDPG还是会对超参数比较敏感。
比如sigma,batch_size。(batch_size的影响没sigma大,64和256都能在两个环境中收敛,下图论证)
其他参数暂未验证,不在本博客讨论的范围内,可参考:DDPG算法参数如何调节?(写的很细致,个人认为可直接参考使用)
下图黑色为sigma=1,batch_size为256时的情况。

2.
这些细节加入后,对原算法的性质并未发生改变(即:该敏感的参数还是敏感),只是加快了收敛作用。















![[C++11] lambda表达式](https://img-blog.csdnimg.cn/img_convert/1e536d26fae266d6530f1296553703b2.png)

