Kaggle是开发商和数据科学家提供举办机器学习竞赛、托管数据库、编写和分享代码的平台,本节是对于初次接触的伙伴们一个快速了解和参与比赛的例子,快速熟悉这个平台。当然提交预测结果需要注册,这个可能需要科学上网了。
我们选择一个预测的入门的例子:https://www.kaggle.com/competitions/titanic
目的是使用机器学习创建一个模型,预测哪些乘客在泰坦尼克号沉船事故中幸存了下来。
对于泰坦尼克号沉船事故大家都不陌生,很多都是通过电影了解到的,那由于船上没有足够的救生艇,导致2224名乘客和船员中有1502人死亡,也就是幸存者只有722人。虽然存活下来有一定的运气成分,但似乎有些群体的人比其他人更有可能存活下来。
那什么样的人更有可能生存下来呢?其中乘客的数据包括姓名、年龄、性别、社会经济阶层等,在机器学习领域,我们把这些叫做特征值,根据这些特征值来预测乘客是否是生还者。
数据集
先把数据集下载下来熟悉下,点击"Data",下载下来是三个csv文件,这里我把它们放入dataset目录:

训练集train.csv:12列,包含891位乘客的详细介绍,关系着能否幸存的因素
PassengerId:乘客编号、Pclass:票的类型(1、2、3舱位可表示经济实力)、Name:姓名、Sex:性别、Age:年龄、SibSp:兄弟姐妹与配偶在船上的人数、Parch:父母与小孩在船上的人数、Ticket:票号、Fare:票价、Cabin 船舱号码、Embarked 港口(C:瑟堡、Q:皇后镇、S:南安普顿)
测试集test.csv:11列,除了Survived这列,481位乘客的信息,预测的是Survived是否幸存
预测结果gender_submission.csv:展示了应该如何组织预测。它预测所有的女性乘客都活下来了,所有的男性乘客都死了。
熟悉了数据集之后我们就开始构建模型进行训练,看下官方的示例:https://www.kaggle.com/code/alexisbcook/titanic-tutorial
先读取数据集,对于这种行列数据表格式的形式,一般都会用到pandas模块,能够非常方便的读取。
import pandas as pd
train_data = pd.read_csv("dataset/train.csv")
test_data = pd.read_csv("dataset/test.csv")
print(train_data.head(6))
'''PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
5 6 0 3 ... 8.4583 NaN Q[6 rows x 12 columns]
'''显示的是前6个样本,就是6位乘客的相关资料。
我们回到那个gender_submission.csv,猜测的是女性全部幸存,看下占比怎么样?
print(len(train_data.loc[train_data.Sex=='female']))#314
print(sum(train_data.loc[train_data.Sex=='female']["Survived"]))#233第一个就是查看有多少女性,总共有314位女性,再看下女性生还者的数量,将Survived为1的累加之后结果是233,也就是说生还的女性有233个,那看下比例:
rate_women = sum(women)/len(women)
print(rate_women)得出结果是0.7420382165605095,预测结果约等于74.2%的准确率,也就是说女性生还率很高,其Sex性别是一个权重很高的特征值,这个我们在电影中也知道,先让妇女和小孩上船。
当然这种属于简单的预测,还有其他的影响因素都没有考虑进来是吧。
训练模型
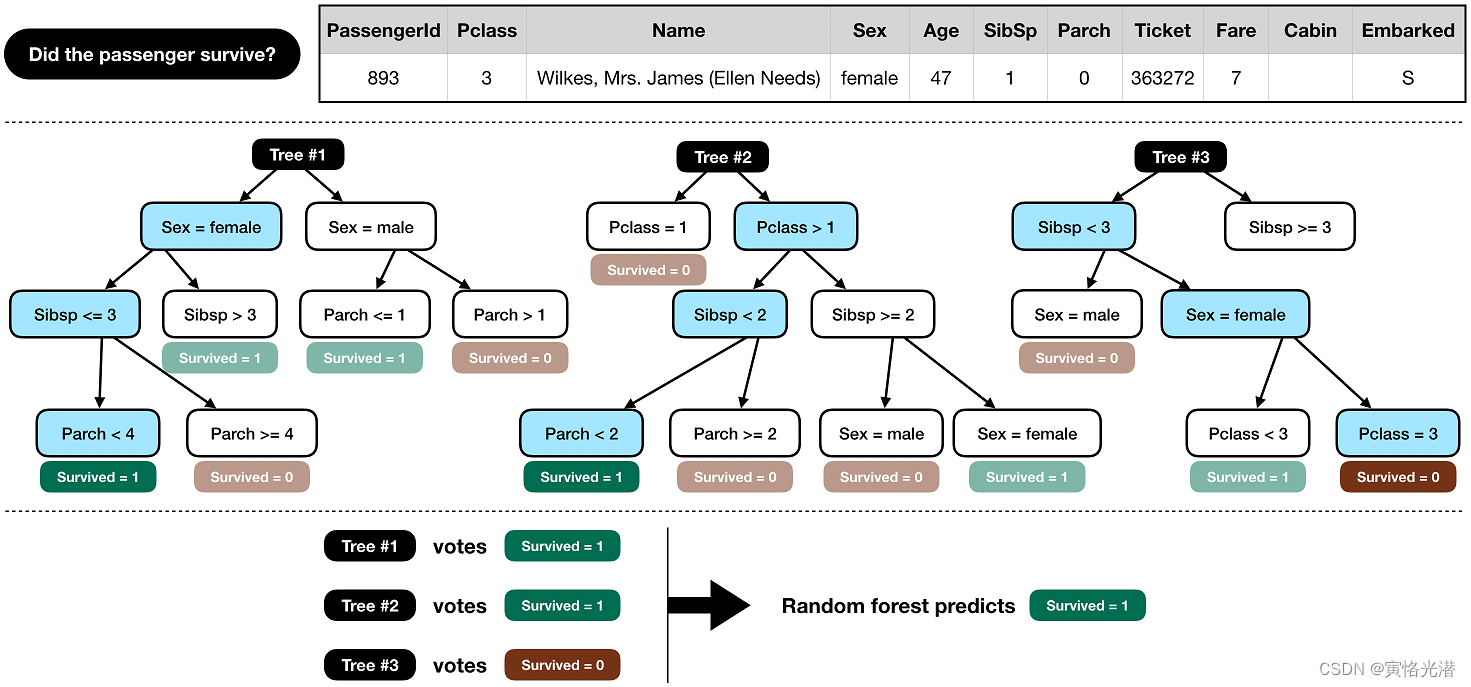
这里我们看下官方示例使用的模型,一种叫做random forest model随机森林模型。这个模型由几棵“树”组成(下图中有三棵树,但我们将构建100棵!),它们将分别考虑每位乘客的数据,并投票决定该乘客是否幸存。然后,随机森林模型做出一个民主的决定:得票最多的结果获胜,如图:
from sklearn.ensemble import RandomForestClassifier
如果没有安装这模块,就会报错:
Import "sklearn.ensemble" could not be resolved
或
Traceback (most recent call last):
File "test.py", line 17, in <module>
from sklearn.ensemble import RandomForestClassifier
ModuleNotFoundError: No module named 'sklearn'
安装:pip install scikit-learn -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
训练并生成预测结果文件submission.csv
from sklearn.ensemble import RandomForestClassifiery = train_data["Survived"]
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
predictions = model.predict(X_test)output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('submission.csv', index=False)
print("Your submission was successfully saved!")其中特征值我们选用了features = ["Pclass", "Sex", "SibSp", "Parch"]这四个,比如Ticket这个票号其实对于幸存者来说基本是没什么影响,所以也不需要将一些不要的因素给添加进来。
get_dummies的用法
我们转到定义来看下,解释为将分类变量转换为虚拟/指示变量。这句话是什么意思呢,简单来说就是一些分类使用了非数字这些类型,我们将其转换成0与1这样的数字,且进行单独分类列出,类似以前介绍过的独热编码One-Hot
比如在示例中的Sex性别这栏,使用get_dummies处理之后,Sex中的female与male将分成两列,Sex_female和Sex_male,里面是0或1的值。单独拎出来看个例子就明白了,例子都来自官方源码示例:
s = pd.Series(list('abca'))
>>> pd.get_dummies(s)a b c
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0可以看到第一个a和第四个a为1,其余为0,b和c也是一样的,所在位置为1,其余位置为0
对于缺失数据NaN的处理:
s1 = ['a', 'b', np.nan]
>>> pd.get_dummies(s1)a b
0 1 0
1 0 1
2 0 0
>>> pd.get_dummies(s1, dummy_na=True)a b NaN
0 1 0 0
1 0 1 0
2 0 0 1一个是忽略一个是保留缺失
df = pd.DataFrame({'A': ['a', 'b', 'a'], 'B': ['b', 'a', 'c'], 'C': [1, 2, 3]})
>>> pd.get_dummies(df)C A_a A_b B_a B_b B_c
0 1 1 0 0 1 0
1 2 0 1 1 0 0
2 3 1 0 0 0 1这个列名前缀就是列名_值,跟前面的Sex_femal一样。
当然也可以自己指定列名前缀
pd.get_dummies(df, prefix=['col1', 'col2'])
>>> pd.get_dummies(df, prefix=['col1', 'col2'])C col1_a col1_b col2_a col2_b col2_c
0 1 1 0 0 1 0
1 2 0 1 1 0 0
2 3 1 0 0 0 1其他参数比如drop_first=True删除第一列,指定值类型dtype=float等,基本上就是上述用法为主,更多详情可以参看其定义
Submit Predictions
最后就是将你自己预测的结果提交即可,点击“Submit Predictions”,提交的文件格式:
包含418个条目和一个标题行的csv文件。如果您有额外的列(除了PassengerId和)或行,则提交将显示错误。
该文件应该有2列:
PassengerId(乘客编号,按任意顺序排序)
Survived(幸存为1,死亡为0)
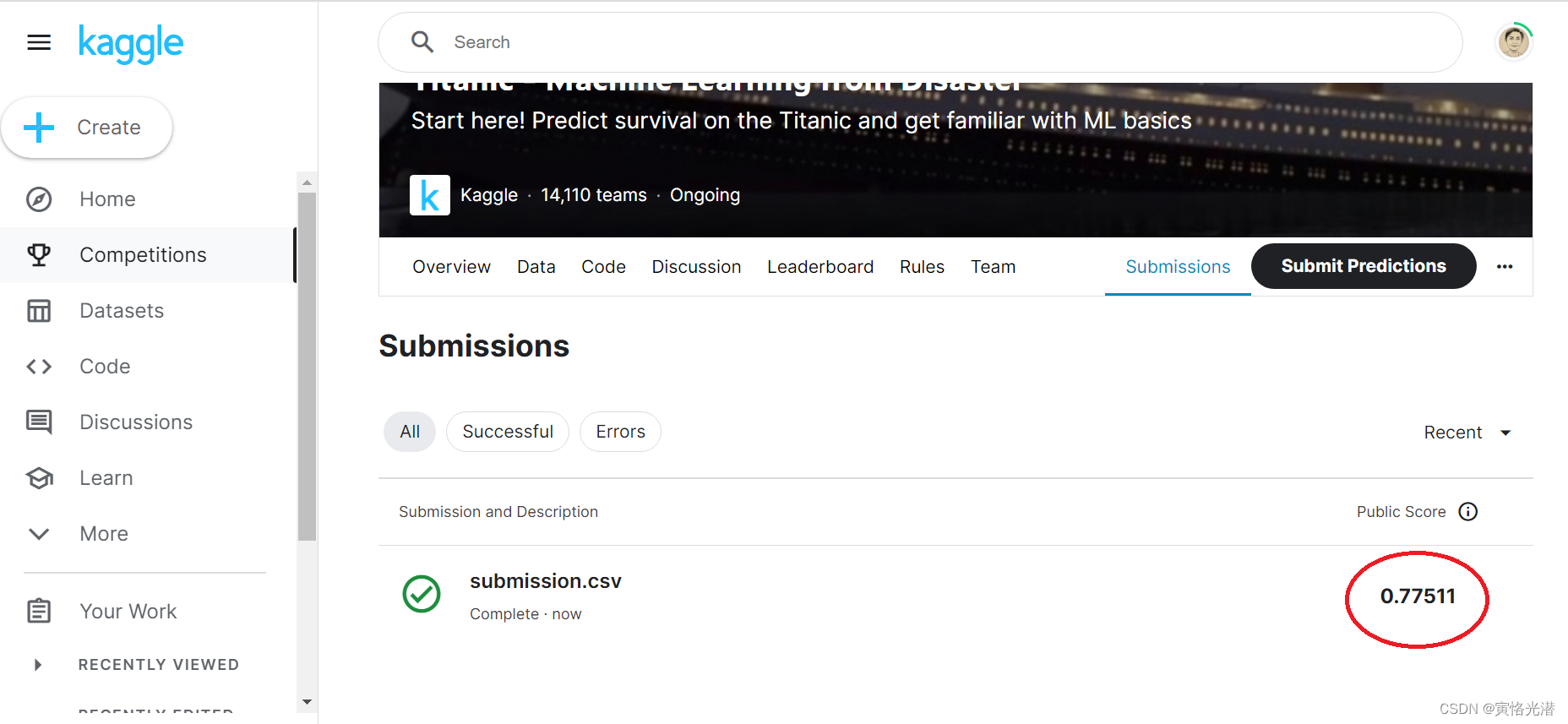
提交直接的结果如下,0.77511,也就是说准确率在77.5%左右。
提高分数的延展
我们做下修改,让分数提高点看能不能做到,因为我知道年龄对于逃生也是一个很关键的因素,所以我将年龄也添加进来试下,看是什么样的效果,而且我把它放到仅次于性别之后:
features = ["Pclass", "Sex","Age", "SibSp", "Parch"]
当然这样直接运行会报错:
type_err, msg_dtype if msg_dtype is not None else X.dtype
ValueError: Input contains NaN, infinity or a value too large for dtype('float32').
因为在Age列里面有缺失的数据,也就是说有的人年龄是未知的,于是我将缺失的使用一个平均年龄来填充X=X.fillna(24):
完整代码如下:
from sklearn.ensemble import RandomForestClassifiery = train_data["Survived"]
features = ["Pclass", "Sex","Age", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X=X.fillna(24)
X_test = pd.get_dummies(test_data[features])
X_test=X_test.fillna(24)
#print(train_data["Age"].sum()/len(train_data["Age"]))#23.79model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
predictions = model.predict(X_test)output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('submission.csv', index=False)
print("Your submission was successfully saved!")提交之后分数有提高,达到了0.7799
Kaggle房价预测的练习(K折交叉验证)
有兴趣的也可以去熟悉下,通过现有的数据集,来预测不同位置面积等房子的售价。
好了,Kaggle的使用就这么愉快的搞定了,多看大神的源码和参加比赛,对于能力的提高是很有帮助的。欢迎大家留言交流,有不正确的地方欢迎指正。