文章目录
- 1.1 CTFN: Hierarchical Learning for Multimodal Sentiment Analysis Using Coupled-Translation Fusion Network
- Jiajia Tang, Kang Li, Xuanyu Jin, Andrzej Cichocki, Qibin Zhao and Wanzeng Kong
- 1.2 Multimodal Sentiment Detection Based on Multi-channel Graph Neural Networks
- Xiaocui Yang, Shi Feng, Yifei Zhang and Daling Wang
- 1.3 Hate Speech Detection Based on Sentiment Knowledge Sharing
- 1.4 An Adaptive Hybrid Framework for Cross-Domain Aspect-Based Sentiment Analysis (AHF)
- 1.5 Are Vision-Language Transformers Learning Multimodal
- **论文动机**
- **方法**
- **探索任务(Probing Tasks)**
- 实验设定及结果
- **【CVPR2022】三元组对比学习的视觉-语言预训练**
- **2.1 RST**
- 2.2 FinerFact
- 2.3 Twitter User Representation
- 2.4 ProSLU
- 2.5 The King is Naked
- ACL 2022
- 01机器翻译
- 02预训练模型
- 03机器阅读理解
1.1 CTFN: Hierarchical Learning for Multimodal Sentiment Analysis Using Coupled-Translation Fusion Network
Jiajia Tang, Kang Li, Xuanyu Jin, Andrzej Cichocki, Qibin Zhao and Wanzeng Kong
1.2 Multimodal Sentiment Detection Based on Multi-channel Graph Neural Networks
Xiaocui Yang, Shi Feng, Yifei Zhang and Daling Wang
1.3 Hate Speech Detection Based on Sentiment Knowledge Sharing
1.4 An Adaptive Hybrid Framework for Cross-Domain Aspect-Based Sentiment Analysis (AHF)
1.5 Are Vision-Language Transformers Learning Multimodal
Representations? A Probing Perspective

论文链接
近年来,由于基于Transformer的视觉-语言模型的发展,联合文本-图像嵌入得到了显著的改善。尽管有这些进步,我们仍然需要更好地理解这些模型产生的表示。在本文中,我们在视觉、语言和多模态水平上比较了预训练和微调的表征。为此,我们使用了一组探测任务来评估最先进的视觉语言模型的性能,并引入了专门用于多模态探测的新数据集。这些数据集经过精心设计,以处理一系列多模态功能,同时最大限度地减少模型依赖偏差的可能性。虽然结果证实了视觉语言模型在多模态水平上理解颜色的能力,但模型似乎更倾向于依赖文本数据中物体的位置和大小的偏差。在语义对抗的例子中,我们发现这些模型能够精确地指出细粒度的多模态差异。最后,我们还注意到,在多模态任务上对视觉-语言模型进行微调并不一定能提高其多模态能力。我们提供所有的数据集和代码来复制实验。
论文动机
视觉语言任务(如视觉问题回答、跨模态检索或生成)非常困难,因为模型需要建立合理的多模态表征将文本和图片的细粒度元素联系起来。在BERT等基于transformer的语言模型成功后,各种基于transformer的多模态预训练模型(如LXMERT、OSCAR、ViTL等)被提出用于得到文本-图片的多模态表征,并且在多模态任务上达到SOTA。但重要的是要了解多模态信息是如何在这些模型学到的表征中编码的,以及它们是如何受到其训练数据的各种bias和属性影响的。Hendricks & Nematzadeh依靠探索任务来研究多模态预训练模型对动词的理解,并确定模型对动词相关的多模态概念的学习少于主语和宾语的学习。在本文中,作者通过特定的一组探索任务来探究VLM的多模态表征能力以及对单模态信息的偏向性。
方法
文章的研究框架如下:
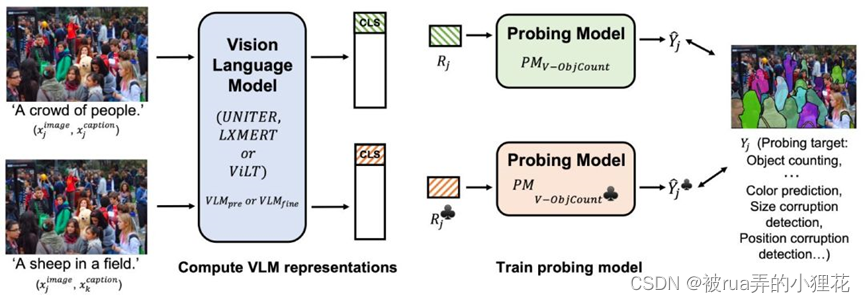
首先将图文匹配和图文不匹配的图文对分别输入到预训练的视觉语言预训练模型或是fine-tune后的模型,得到数据对应的模型最后一层表征;将得到的[CLS]或是WORD级别的token表征输入到一个未在数据集上训练的线性探测模型(只能依赖模型在预训练或是fine-tune阶段已经提取到的线性可分离信息)用于反应VLM提取到探索任务p所需信息的能力。
如果p是一个面向语言的任务,其输入数据集为:{()};则相关任务的输入则为与文本不匹配的数据:{()}。如果的性能与的性能相似,则说明VLM得到的表征不受视觉bias的影响。如果p是一个面向视觉的任务,则相关任务的输入则为与图片不匹配的数据:{()}。如果的性能与的性能相似,则说明VLM得到的表征不受语言bias的影响。对于多模态探索任务p,作者想研究在模型决策阶段语言是否比视觉信息更被模型重视,相关任务的输入为{()};如果VLM提取到多模态信息,那么的信息应该比的性能更优。
探索任务(Probing Tasks)
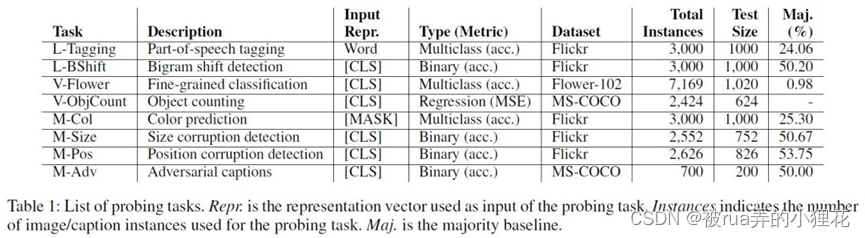
探索任务主要分语言、视觉以及多模态三部分进行:语言探索任务包括Part of Speech Tagging(对token进行语义分类,数据集通过en core web sm SpaCy tagger进行构建)、Bigram Shift(确定一个句子中连续的两个词是否被调换);视觉探索任务为Flower identification和Object Counting;在多模态探索任务上,作者主要在描述对象的概念属性方面进行,设计了颜色、大小、位置识别以及Adversarial captions任务并构建了相应的数据集进行评估,以下是“Two men standing behind a tall black fence”在各任务上修改后的caption负例展示。

各探索任务的相关信息如下图所示:
实验设定及结果
作者选择了三种不同架构且已经预训练好的视觉语言模型:UNITER,LXMERT,ViLT在不同的探索任务上与单模态的SOTA模型进行对比:

Pre-trained
单模态:

在语言任务上,可以注意到与文本不匹配的图片输入会对UNITER造成负面影响。
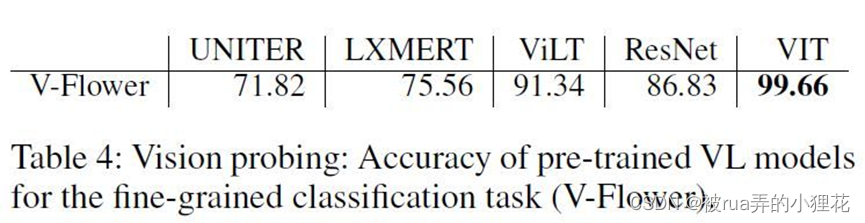

在视觉计数任务上(使用RMSE作为评价标准,越小越好),可以发现正确的语言线索可以显著的提高模型的性能。
Pre-trained 多模态:

在M-Col和M-Adv任务上,VLM模型达到了比单模态的baseline好得多的性能,多模态信息得到了有效的提取;而在M-Size和M-Pos任务上,VLM的性能并没有得到提升,大小和位置的信息在多模态层次上并没有得到很好的提取。
Fine-tuned单模态:模型经过VQA和NLVR任务上进行fine-tuning后,模型在探索任务上的表现如下。
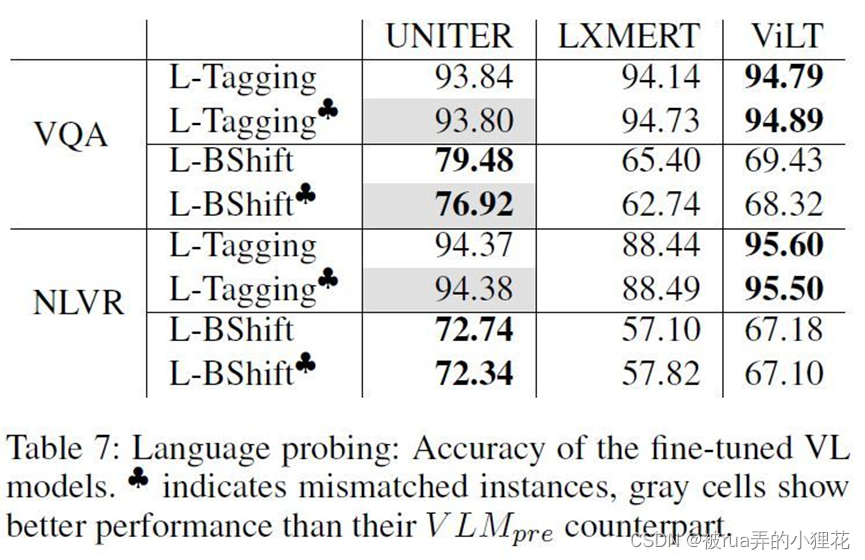
在语言任务上,唯一有提升的是UNITER在负例上的表现,作者将其归结于该模型预训练协议的特殊性。而在NLVR任务上fine-tuned的模型表现出更低的性能可能是因为NLVR任务使用两张图片作为输入,和预训练、探索任务不同;LXMERT经过fine-tuned的性能体现出该模型更容易忘记在预训练阶段学习到的语义知识。


Fine-tuning改善了UMITER和LXMERT的视觉性能。这似乎表明VQA和NLVR依赖视觉信息,而这些信息在预训练模型中不容易获取,同时也表现出两个模型在提取视觉信息上的不足;另一方面Fine-tune并没有提高ViLT提取视觉信息的能力。
Fine-tuned 多模态:

可以发现在M-Size和M-Pos任务上,各模型在fine-tuned后都有了一定的提升,这可能是因为VQA和NLVR任务比预训练更加注重对Size和Position的理解;在M-Col和M-Adv任务上,Fine-tuned的LXMERT模型有了较大的提升。
【CVPR2022】三元组对比学习的视觉-语言预训练
2.1 RST

论文标题:
Predicting Above-Sentence Discourse Structure using Distant Supervision from Topic Segmentation
论文链接:
https://arxiv.org/abs/2112.06196
RST(Rhetorical Structure Theory, 修辞结构理论)风格的话语解析在许多 NLP 任务中发挥着至关重要的作用,揭示了潜在复杂和多样化文档的潜在语义/语用结构。尽管它很重要,但现代话语解析中最普遍的限制之一是缺乏大规模数据集。为了克服数据稀疏性问题,最近提出了来自情绪分析和总结等任务的远程监督方法。
这篇文字的作者通过利用来自主题分割的远程监督来扩展这一研究方向,这可以为高级话语结构提供强大且互补的信号。在两个人工注释的话语树库上的实验证实,本文的提议在句子和段落级别上生成了准确的树结构,在句子到文档的任务上始终优于以前的远程监督模型,并且偶尔在句子到文档的任务上达到更高的分数。

上图是本文提出的从远程主题分割监督生成句子到文档级别的高级话语结构的方法示意图。在顶部,我们可视化了一个自然组织的文档,其中单词被聚合成从句(或 EDU),这些子句又被连接成句子。然后将句子进一步组合成段落,形成完整的文档。在这里,我们将句子聚合为原子单元以获得高级话语树。作者使用自上而下的贪婪方法来生成树。

上图是实验结果,可以看出,使用监督的 RST 风格 parser 取得了较好的结果。
2.2 FinerFact

论文标题:
Towards Fine-Grained Reasoning for Fake News Detection
论文链接:
https://arxiv.org/abs/2110.15064
在这篇文章中,作者通过遵循人类的信息处理模型提出了一个细粒度的推理框架,引入了一种基于相互强化的方法来整合人类关于哪些证据更重要的知识,并设计了一个先验感知的双通道核图网络对证据之间的细微差异进行建模。大量实验表明,本文的模型优于最先进的方法,作者还证明了方法的可解释性。

当人类对一篇新闻文章的真实性进行推理时,他们有能力进行细粒度分析以识别细微的线索,并且可以将不同类型的线索联系起来得出结论。如上图所示,尽管四组证据在语义上不同,但人类可以根据“property”一词等微妙线索在逻辑上将它们联系起来,从而得出更自信的结论。现有方法缺乏这种细粒度推理的能力:它们要么不对不同类型证据之间的交互进行建模,要么在粗粒度(例如,句子或帖子)级别对它们进行建模。
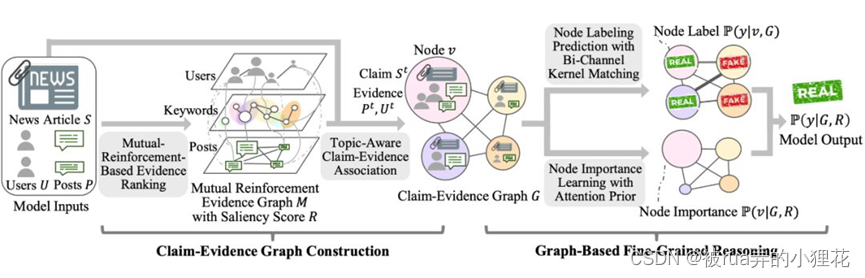
作者提出了一个用于假新闻检测的细粒度推理框架(Fine-grained reasoning framework for Fake news detection,
FinerFact)。如上图所示,框架由两个主要模块组成:
第一个模块,断言证据图构建,对应于人类信息处理模型的存储子过程。在这个过程中,人们选择最重要的信息片段并建立它们之间的关联以将它们存储在内存中。至于假新闻检测,它对应于人们搜索关键信息的过程,例如主要观点、意见领袖和最重要的帖子,这使他们能够了解关键主张及其作为——相关证据(例如,支持的帖子和用户)。这一步对于过滤噪声、组织事实和加速后期的细粒度推理过程至关重要。它还使我们能够整合关于哪些信息很重要的人类知识。
第二个模块,基于图的细粒度推理,对应于人类信息处理模型的检索子过程,其中人们根据他们的关联重新激活特定的信息以进行决策。在假新闻检测中,该模块通过考虑细微的线索来实现证据关系的细粒度建模。
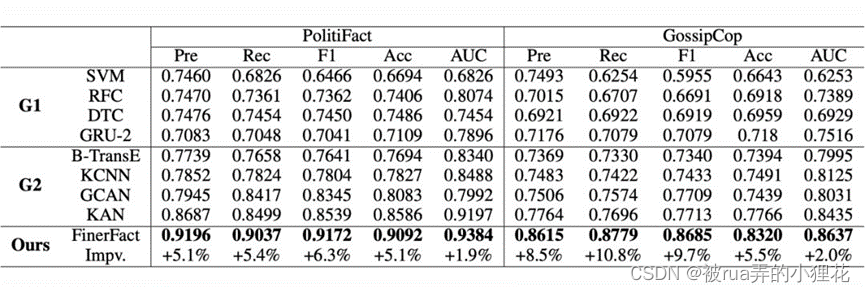
实验结果如上图所示,可以看出,FinerFact 在各方面都实现了较好的性能。
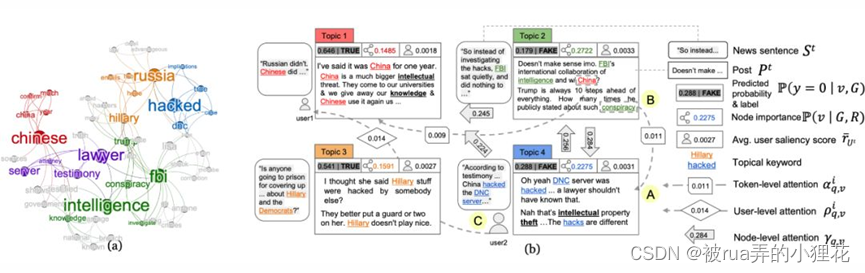
上图是用 FinerFact 推理的示意图。(a)互强化图 M 的关键词层,显著性 R 由字体大小表示;(b)对断言证据图 G 的细粒度推理。每种颜色编码一个主题。
2.3 Twitter User Representation

论文标题:
Twitter User Representation using Weakly Supervised Graph Embedding
论文链接:
https://arxiv.org/abs/2108.08988
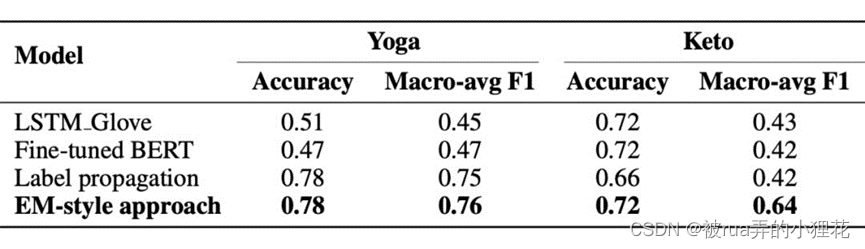
这篇文章的作者提出了一种基于弱监督图嵌入的框架来理解用户类型。作者评估使用对来自 Twitter 的健康相关推文的弱监督学习的用户嵌入,重点是“瑜伽”、“生酮饮食”。在真实世界数据集上的实验表明,所提出的框架在检测用户类型方面优于 baseline。最后,作者从数据集中说明了对不同类型用户(例如,从业者与促销者)的数据分析,便于本文的方法推广到其他领域。

上图显示了两个不同的 Twitter 用户的个人资料描述和关注酮饮食的推文。尽管用户 susan 和 keto collab 都发布了关于生酮饮食的推文,但他们有不同的意图。用户 susan 是一位“keto 爱好者”,而 keto collab 专注于从各种酮渠道收集信息,并每天推广酮食谱和生酮饮食。除了推文的内容外,苏珊的个人资料描述表明她是一名从业者。另一方面,keto collab 的个人资料描述和推文表明它是一个促销帐户。我们的目标是从相关的推文中自动分类用户类型并分析他们的文本内容。

上图表示用户、描述、用户类型之间的关系。为了通过信息图捕获更多表征用户类型的隐藏关系,作者建议迭代应用推理函数。用户 u1 和 u3 具有弱标签,分别通过使用特定关键字的标签映射从他们的个人资料描述 d1 和 d3 中获得。u2 的配置文件描述最初没有标签。推理函数推断用户 u2 和 u2 的描述标签,d2 为“从业者”,因为 u1 和 u2 具有相似的推文。
从技术角度来看,我们将用户类型检测定义为信息图上的推理问题,该问题创建由图结构上下文化的节点的分布式表示,允许我们将信息从观察到的节点传输到未知节点。我们使用基于学习图嵌入定义的相似性度量的推理函数来增加连接两种节点类型的边数。我们建议使用期望最大化(EM)方法来完成这两个步骤。
上图是实验结果。作者构建用户信息图的方法值得参考。
2.4 ProSLU

论文标题:
Text is no more Enough! A Benchmark for Profile-based Spoken Language Understanding
论文链接:
https://arxiv.org/abs/2112.11953
项目地址:
https://github.com/LooperXX/ProSLU
当前对又语理解(spoken language understanding, SLU)的研究局限于一个简单的设置:基于纯文本的 SLU,它将用户话语作为输入并生成其相应的语义框架(例如意图和槽)。不幸的是,当话语在语义上模棱两可时,这种简单
的设置可能无法在复杂的现实世界场景中工作,而基于文本的 SLU 模型无法实现这一点。
这篇文章来自车万翔老师的团队,作者首先介绍了一项新的重要任务,即基于配置文件的又语理解(Profile-based
Spoken Language Understanding, PROSLU),它要求模型不仅依赖纯文本,还需要支持配置文件信息来预测正确的意图和槽。为此,作者进一步引入了一个具有超过 5K 话语的大规模人工注释中文数据集及其相应的支持配置文件信息(知识图(Knowledge Graph, KG)、用户配置文件(User Profile, UP)、上下文感知(Context
Awareness, CA))。
此外,作者评估了几个最先进的 baseline 模型,并探索了一个多层次的知识适配器,以有效地整合个人资料信息。实验结果表明,当话语在语义上不明确时,所有现有的基于文本的 SLU 模型都无法工作,作者提出的框架可以有效地融合句子级意图检测和 token 级槽填充的支持信息。
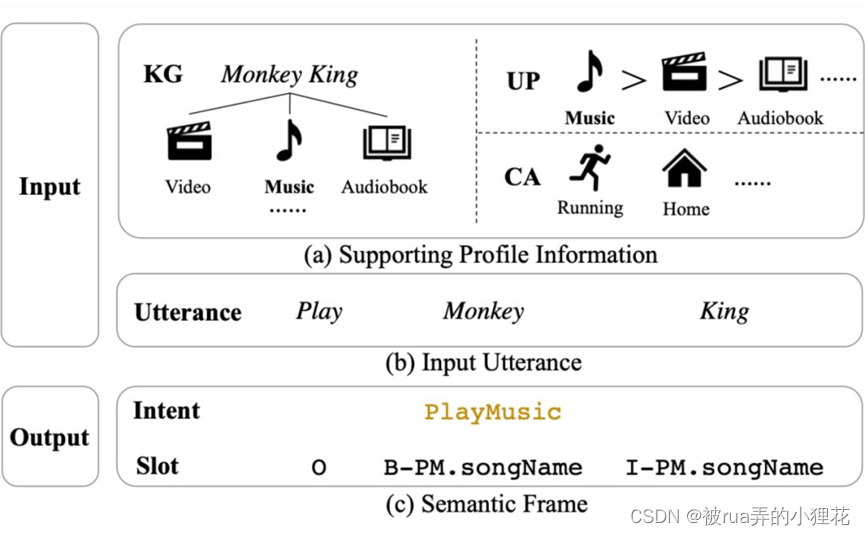

上图是 PROSLU 的任务以及数据集的示例。
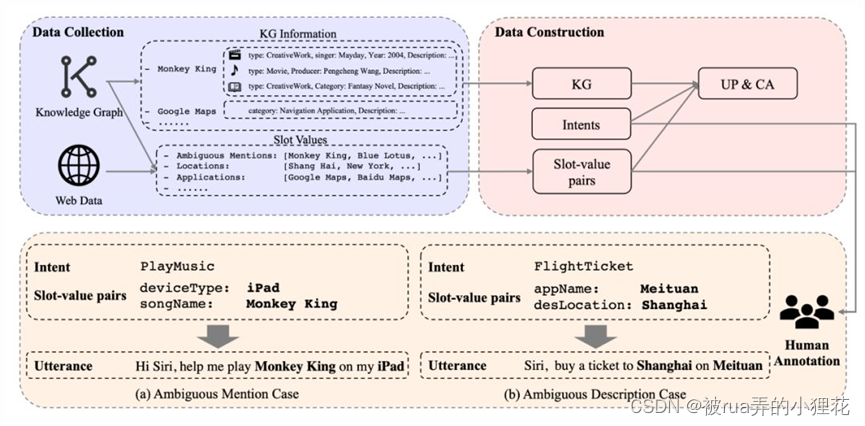
上图是数据、构建以及人工标注的流程。

上图是通用 SLU 模型和多级知识适配器的示意图,可分别用于句子级意图检测和单词级槽填充。
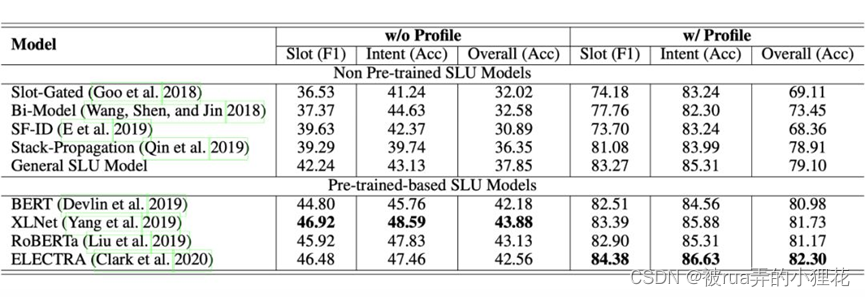
上图是作者在 PROSLU 数据集上意图检测和槽填充的实验结果。
作者在附录中还详细介绍了通用 SLU 模型的细节以及消融实验的结果,值得进一步阅读。
2.5 The King is Naked

论文标题:
The King is Naked: on the Notion of Robustness for Natural Language Processing
论文链接:
https://arxiv.org/abs/2112.07605
项目地址:
https://github.com/EmanueleLM/the-king-is-naked
这篇文章的作者认为,最初为图像引入的鲁棒性标准并不适用于 NLP。因此,作者提出了(局部)语义鲁棒性——根据预测在模型中引起的偏差来表征,通过测量语言规则的鲁棒性而不是单词替换或删除。 作者使用基于模板的生成测试研究了一系列原版和经过稳健训练的架构的语义鲁棒性。作者得出结论:语义鲁棒性可以提高模型对于复杂语言现象的性能,尽管相对于对抗性鲁棒性更难计算。
对比局部连续鲁棒性与局部离散鲁棒性:
• 连续鲁棒性:广泛用于图像,是基于嵌入向量进行操作的。但由于自然语言是离散的,在连续鲁棒性的定义中,ε 有界鲁棒性意味着这个 ε 有界区域中的任何向量都是安全的。这种假设与语言本身特性是不一致的,因为网络可能会呈现一个决策边界,其中不是正确单词的对抗性攻击会限制验证或严重减少安全区域。如下图所示:
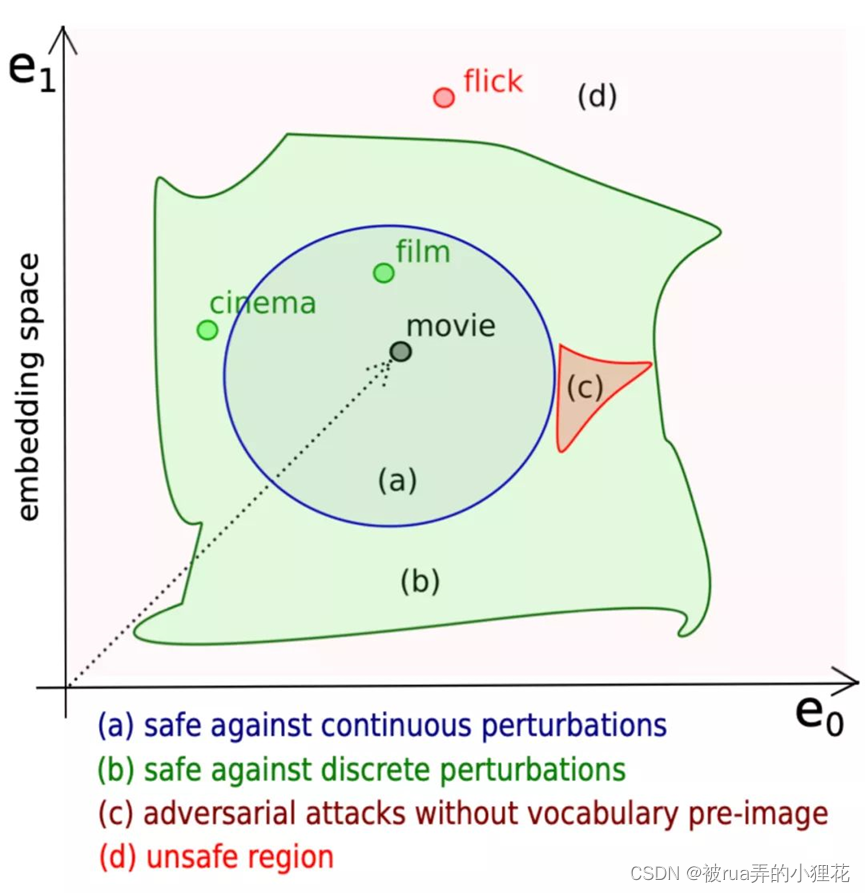
o 离散鲁棒性:是基于符号进行操作的,且局部连续鲁棒性以为只局部离散鲁棒性,反之则不成立。
这两种鲁棒性公式都只允许对符号替换或删除进行鲁棒性测试。而将一个词局部替换为其他词很难对释义测试鲁棒性。从语言学的角度来看,这个问题的出现是因为自然语言中单词的频率遵循 Zipf 定律 ,其中罕见的术语和结构——因此是边缘情况——比其他自然现象更频繁地出现。且我们不能保证离散和连续设置中的扰动不会违反所考虑的任务。由于实现离散和连续鲁棒性的方法允许在选择替代品时进行弱监督,因此扰动可能会偏离正在考虑的任务。
作者因此提出语义鲁棒性,并进一步定义了语义鲁棒性的有界不变条件并证明局部语义鲁棒性可以推广到全局语义鲁棒性。
作者进行了针对以下问题进行了实验:(i)经典意义上的鲁棒模型是否在语义上也是鲁棒的; (ii) 对特定语言现象的鲁棒性是否是训练准确的 NLP 分类器的副产品; (iii) 对于不同的架构,增强监督训练(使用包含特定语言现象的文本)是否会在包含相同现象的未见测试样本上诱导泛化; (iv) 是否有可能训练出既准确又具有语义鲁棒性的模型,以及 (v) 无监督学习在多大程度上有助于语义鲁棒性。
作者在斯坦福情感树库数据集 (SST-2)和 Barnes 收集的数据集上使用充分训练并微调过的模型进行实验。结果如下图:
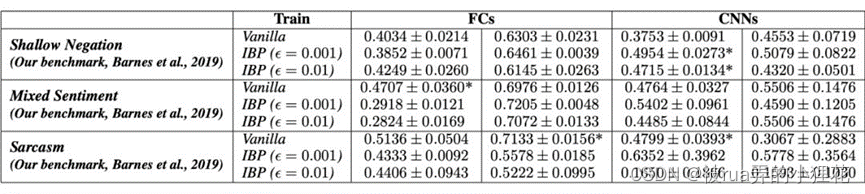
本文提出的语义鲁棒性虽然很难实现,但对传统鲁棒性难以解决的复杂问题具有更好的效果,这对于解决其他 NLP 任务可能有帮助。
ACL 2022
01机器翻译
3.1 CSANMT:文本数据增强(连续语义增强)
3.2 PCKMT:更有效的k- 最近邻机器翻译
02预训练模型
3.1 XDBERT:从预训练的多模态 transformer 中提取视觉信息到预训练的语言编码器。Pretraining 阶段对 BERT 和 CLIP-T 进行预训练,然后将两者用于 Adaption 阶段并与跨模态编码器连接,仅在语言编码器上执行 Finetuning。
3.2 ExplagraphGen:分析Seq2Seq模型学习此类图的结构约束和语义的能力
3.3 PERFECT:手工Prompt->任务特定的adapter,实现样本高效微调,训练推理速度up,且sota
3.4 RL-Guided MTL:注释了一个针对“刻板印象检测(Stereotype Detection)”的重点评估集,通过解构文本中刻板印象表现的各种方式来解决这些缺陷。
03机器阅读理解
3.1 S2DM:连体语义分离模型(Siamese Semantic Disentanglement Model, S2DM),以在多语言预训练模型学习的表示中将语义与语法分离。
3.2 POI-Net:轻量级的 POS-Enhanced Iterative Co-Attention Network(POI-Net),作为具有针对性的多选择和抽取式MRC统一建模的首次尝试