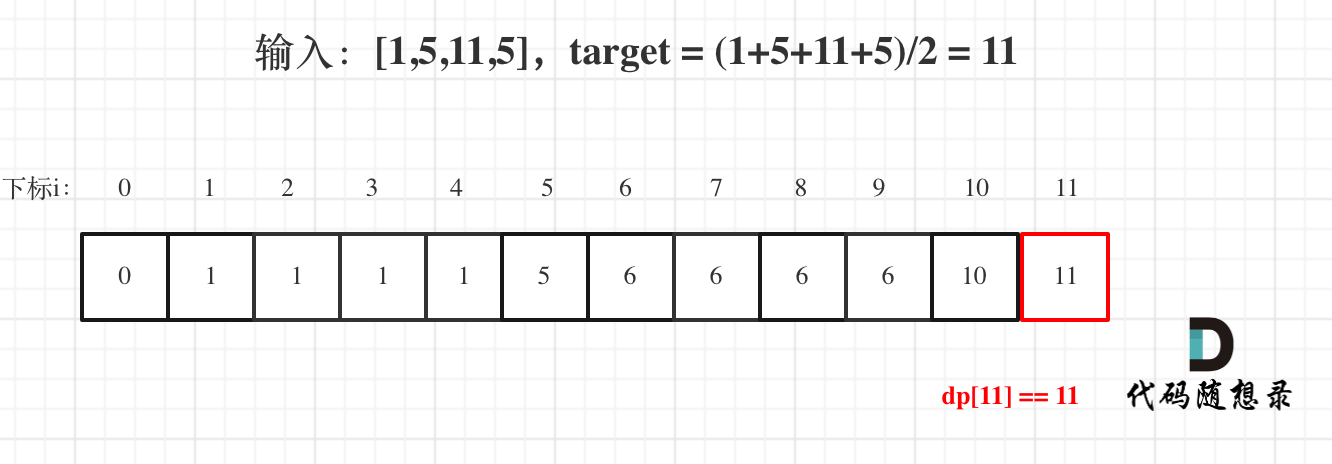
自然语言处理 (NLP) 是数据科学的一个分支,主要处理文本数据。除了数值数据外,文本数据也广泛可用,用于分析和解决业务问题。然而,在使用数据进行分析或预测之前,处理数据非常重要。
我们执行文本预处理来准备用于模型构建的文本数据。这是 NLP 项目的第一步。一些预处理步骤如下:
- 删除标点符号,如 .、! $( ) * % @
- 删除 URL
- 删除停用词
- 小写化
- 标记化
- 词干提取
- 词形还原
进行文本预处理的原因

自然语言处理 (NLP) 是数据科学的一个分支,主要处理文本数据。除了数值数据外,文本数据也广泛可用,用于分析和解决业务问题。然而,在使用数据进行分析或预测之前,处理数据非常重要。
我们执行文本预处理来准备用于模型构建的文本数据。这是 NLP 项目的第一步。一些预处理步骤如下:
进行文本预处理的原因
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/457167.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!