目录
一、缓冲区对象概念
二、分类
三、顶点缓冲区对象VBO
1、概念
2、为什么使用VBO
3、如何使用VBO
生成缓冲区对象
绑定缓冲区对象
输入缓冲区数据
更新缓冲区中的数据
删除缓冲区
4、VBO应用
四、顶点数组对象VAO
1、概念
2、为什么使用VAO
3、如何使用VAO
生成VAO
绑定VAO
解绑VAO
删除VAO
4、VAO应用
五、索引缓冲区对象EBO/IBO
1、概念
2、为什么使用IBO/EBO
3、如何使用EBO
生成EBO
绑定EBO
输入数据到缓冲区
链接属性
绘制
4、EBO应用
5、绘制过程
六、帧缓冲区FBO
1、概念
2、为什么使用FBO
3、FBO和DFBO区别
4、如何使用FBO
生成FBO
绑定FBO
创建附件
纹理附件
RBO附件
纹理和RBO区别
检查FBO完整性
激活默认FBO
删除FBO
5、FBO应用
举例1:纹理附件
举例2:纹理附件
举例3:RBO 附件
七、离屏渲染
八、总结
1、常用各类缓冲区分析
2、无法删除缓冲区
九、源码下载
一、缓冲区对象概念
缓冲区对象(Buffer Object)是OpenGL中用于在GPU内存中存储数据的一种机制,它们使得数据传输和渲染更加高效。
二、分类
常用的缓冲区分类如下:
VAO(Vertex Array Object): 顶点数组对象,用于存储顶点数据
VBO(Vertex Buffer Object): 顶点缓冲对象,用于存储顶点数据
EBO(Element Buffer Object): 元素缓冲对象,用于存储顶点的索引数据
IBO(Index Buffer Object): 索引缓冲对象,用于存储索引数据
FBO(Index Buffer Object):帧缓冲对象,用于渲染到纹理或离屏渲染。
PBO(Pixel Buffer Object):像素缓冲区对象
GL_ARRAY_BUFFER标志指定的数组缓冲区对象用于创建保存顶点数据的缓冲区对象。GL_ELEMENT_ARRAY_BUFFER标志指定的元素数组缓冲区对象用于创建保存图元索引的缓冲区对象。
应用程序对顶点属性数据和元素索引使用顶点缓冲区对象。
三、顶点缓冲区对象VBO
1、概念
VBO(Vertex Buffer Object)顶点缓冲对象,是在显卡存储空间(即,GPU内存)中开辟的一块区域,在显卡存储空间中开辟一块区域,用于存放顶点的各类属性信息。如顶点坐标、纹理坐标、顶点颜色等数据。
在渲染时直接从显VBO去取数据而不必与CPU进行数据交换。
2、为什么使用VBO
什么是顶点缓冲区对象,为什么要使用它们
解释1:
将对象数据存储在客户端内存中,只有在渲染时将其传输到GPU内存(即,显存)中。没有大量数据传输时,这很好,但随着我们的场景越来越复杂,会有更多的物体和三角形,这会给CPU和内存增加额外的成本。
我们能做些什么呢?我们可以使用顶点缓冲对象,而不是每帧从客户端内存传输顶点信息,信息将被传输一次,然后渲染器将从该图形存储器缓存中得到数据。
解释2:
直接只用顶点数组来绘图,在客户端制定顶点数据,每次绘制时从先从内存中加载这些数据,这样会带来绘制延时,因此我们想着在显存中开辟一块区域,在每次绘制间隔就将顶点数据加载过来,这样绘制时直接读取显存中的数据就可以了,明显提高渲染速度。于是,我们需要引入顶点缓冲区。
一般在两种不同处理速度的物理组件之间进行数据传输时都要用到缓冲区,OpenGL由于需要处理内存与GPU的数据传输,也要用到一系列缓冲区对象,顶点缓冲区只是其中之一。在顶点数组的基础上使用定点缓冲区可以提高渲染速率。
解释3:
VBO允许开发者将大量顶点数据从CPU传输到GPU,减少每帧的CPU-GPU通信量,提高渲染效率。缓冲区对象通过在 GPU 上存储数据,提高了数据传输和渲染的效率。
使用顶点数组指定的顶点数据保存在客户内存中。在进行 glDrawArrays或者
glLDrawElements 等绘图调用时,这些数据必须从客户内存复制到图形内存。但是,如果我们没有必要在每次绘图调用时都复制顶点数据,而是在图形内存中缓存这些数据,那就好得多了。这种方法可以显著地改进渲染性能,也会降低内存带宽和电力消耗需求,对于手持设备相当重要。这是顶点缓冲区对象发挥作用的地方。
顶点组冲区对象使应用程序可以在高性能的图形内存中分配和缓存顶点数据,并从这个内存进行泻染,从而避免在每次绘制图元的时候重新发送数据。不仅是项点数据,描述图元顶点索引、作为 glDrawElements 参数传递的元素索引也可以缓存。
解释4:
通过顶点缓冲对象(Vertex Buffer Objects, VBO)管理这个内存,它会在GPU内存(通常被称为显存)中储存大量顶点。使用这些缓冲对象的好处是我们可以一次性的发送一大批数据到显卡上,而不是每个顶点发送一次。
从CPU把数据发送到显卡相对较慢,所以只要可能我们都要尝试尽量一次性发送尽可能多的数据。当数据发送至显卡的内存中后,顶点着色器几乎能立即访问顶点,这是个非常快的过程。
解释5:
为什么需要使用VBO
将顶点数据保存在内存中,在调用glDrawArrays或者glDrawElements等绘制方法前需要调用相应的方法将数据送入显存,I/O开销大,性能不够好。
若采用顶点缓冲区对象存放顶点数据,则不需要在每次绘制前都将顶点数据复制进显存,而是在初始化顶点缓冲区对象时一次性将顶点数据送入显存,
每次绘制时直接使用显存中的数据,可以大大提高渲染性能。
3、如何使用VBO
顶点缓冲区的使用需要经历一下步骤:

生成缓冲区对象
glGenBuffers(GLsizei n, GLuint* buffers);分配n个缓冲区对象标识符,返回的标识符存储在buffers数组中。每一个标识符表示一个已经开始使用的缓冲区对象。具体如何分配有OpenGL内部决定,与调用者无关。此外,该方法调用之后在buffers中存储的标识符并不一定是连续的数字,而且0作为一个被保留的缓冲区对象名称,该方法从来不会返回0标识符。
绑定缓冲区对象
glBindBuffer(GLenum target, GLuint buffer);绑定缓冲区对象。OpenGL有很多缓冲对象类型,顶点缓冲对象的缓冲类型是GL_ARRAY_BUFFER。buffer是glGenBuffers()返回的标识符数组的一个值,target表示改缓冲区应该绑定为什么类型的缓冲区对象,有GL_ARRAY_BUFFER(顶点数组缓冲区)、GL_ELEMENT_ARRAY_BUFFER(索引数组缓冲区)等。需要注意的是(以GL_ARRAY_BUFFER为例):
- 如果buffer为0,则停用顶点数组缓冲区;
- 如果buffer为非零整数,且buffer代表的缓冲区之前未绑定过,则创建一个新的缓冲区对象和buffer相对应;
- 如果buffer之前绑定过,则激活buffer对应的缓冲区。
OpenGL有很多缓冲对象类型,顶点缓冲对象的缓冲类型是GL_ARRAY_BUFFER。OpenGL允许我们同时绑定多个缓冲,只要它们是不同的缓冲类型。我们可以使用glBindBuffer函数把新创建的缓冲绑定到GL_ARRAY_BUFFER目标上。
输入缓冲区数据
glBufferData(GLenum target, GLsizeiptr size, const void* data, GLenum usage);初始化缓冲区对象,并指定缓冲区数据。target和glBindBuffer()中的target一样,data表示要写入到缓冲区的数据数组头指针,size表示data数组的字节数,usage表示数据在分配到缓冲区之后如何进行读取和写入,主要用来提供性能,指定了我们希望显卡如何管理给定的数据。其值为“GL_频率_操作”格式,有
GL_STREAM_DRAW、
GL_STREAM_READ、
GL_STREAM_COPY、
GL_STATIC_*、
GL_DYNAMIC_*。
其中,“频率”指缓冲区数据的读取或者渲染速率,有流模式、静态模式,动态模式:
- STREAM:流模式,当缓冲区中的数据更新频率高,但使用频率低时使用;
- STATIC:静态模式,当缓冲区中的数据只需制定一次,但使用频率比较高时使用;
- DYNAMIC:动态模式,当缓冲区中的数据更新频率高,并且使用频率高时使用。
“操作”有绘制 、读取和拷贝:
- DRAW:绘制,缓冲区中的数据直接用于渲染,也就是内存中的数据直接作为渲染数据;
- READ:读取,缓冲区中的数据主要用于应用程序的计算,而不是直接作用于渲染;
- COPY:拷贝,缓冲区中的数据对渲染来说是只读数据,需要拷贝后将拷贝数据作为渲染数据。
例如,如下三种形式的含义:
- GL_STATIC_DRAW 数据不会或几乎不会改变。仅在显存上进行读取,不进行写入,适用于静态数据。
- GL_DYNAMIC_DRAW数据会被改变很多。仅在显存上进行读取,并允许写入,数据经常改变。
- GL_STREAM_DRAW 数据每次绘制时都会改变。仅在显存上进行读取,不进行写入,数据每次绘制都改变。
一般情况下,位置数据不会改变,每次渲染调用时都保持原样,所以它的使用类型最好是GL_STATIC_DRAW。如果,比如说一个缓冲中的数据将频繁被改变,那么使用的类型就是GL_DYNAMIC_DRAW或GL_STREAM_DRAW,这样就能确保显卡把数据放在能够高速写入的内存部分。现在我们已经把顶点数据储存在显卡的内存中,用VBO这个顶点缓冲对象管理。
更新缓冲区中的数据
glBufferSubData(GLenum target, GLintptr offset, GLsizeiptr size, const void* data);更新缓冲区中的数据。target和之前两个方法的参数一样,data指写入缓冲区的数据所在数组头指针,size指data数组中要写入缓冲区的数据的字节数,offset指要写入缓冲区的第一个数据在data数组的位置。也即将data数组中从offset(字节为单位)开始的size个字节写入缓冲区。
删除缓冲区
glDeleteBuffers(GLsizei n, const GLuint* buffers);删除buffers中前n个缓冲区对象,他们的名称就是buffers数组中的元素。
4、VBO应用
创建VBO四步:
val buffers = IntArray(1)
//1.生成一个VBO,并ID存储在VBO中,此时VBO拥有了其唯一的id
GLES20.glGenBuffers(buffers.size, buffers, 0)
if (buffers[0] == 0) {Log.d(TAG, "can not create a new vertex buffer object.")
}
bufferId = buffers[0]
//2.绑定缓冲区
GLES20.glBindBuffer(GLES20.GL_ARRAY_BUFFER, buffers[0])
val vertexArray = ByteBuffer.allocateDirect(indexData.size * BYTES_PER_SHORT).order(ByteOrder.nativeOrder()).asShortBuffer().put(indexData)
vertexArray.position(0)
//3.将顶点数据复制到缓冲中,并指定数据用以静态访问,
将顶点数据上传到GPU内存中,以便后续的渲染操作。
GLES20.glBufferData(GLES20.GL_ARRAY_BUFFER,vertexArray.capacity() * BYTES_PER_SHORT,vertexArray,GLES20.GL_STATIC_DRAW
)
//4.将buffer id设置为0,解绑缓冲区
GLES20.glBindBuffer(GLES20.GL_ARRAY_BUFFER, 0)四、顶点数组对象VAO
1、概念
VAO(vertex Array Object):顶点数组对象。
注意: VAO是OpenGL ES 3.0之后才推出的新特性, 所以在使用VAO前需要确定OpenGL ES的版本是否是3.0之后的版本。
顶点数组对象可以像顶点缓冲对象那样被绑定,任何随后的顶点属性调用都会储存在这个VAO中。这样的好处就是,当配置顶点属性指针时,你只需要将那些调用执行一次,之后再绘制物体的时候只需要绑定相应的VAO就行了。这使在不同顶点数据和属性配置之间切换变得非常简单,只需要绑定不同的VAO就行了。刚刚设置的所有状态都将存储在VAO中。
VAO用于保存顶点属性数组的状态,包括与VBO的绑定以及顶点属性的配置。
2、为什么使用VAO
解释1:
顶点属性存储有2种方式:客户端顶点数组和顶点缓冲区对象。VAO使得客户端顶点数组的数据传入VBO的速度加快。
通过VAO,开发者可以一次性配置好顶点数组的所有状态,在后续的绘制中快速恢复这些状态,减少OpenGL函数调用次数,提升效率。
解释2:
在上面VBO的介绍中我们知道每次在绘制的时候都需要频繁地绑定与解绑VBO,每次绘制还需要取出VBO中的数据进行赋值之后才能进行绘制渲染。当数据量大的时候,重复这些操作就会变得很繁琐。通过VAO就可以简化这个过程,因此VAO可以简单理解成VBO的管理者,避免在帧绘制时再去手动操纵VBO,VAO不能单独使用,
需要搭配VBO使用。
对于GPU来说VBO就是一堆数据,但是这堆数据怎么解析使用,需要glEnableVertexAttribArray等相关函数在每次绘制的时候告诉GPU,那么VAO的作用就是简化这个过程的,只需要在初始化的时候将这些解析逻辑与VAO绑定一次即可,
然后每次在绘制的时候只需绑定对应的VAO,而不必每次再绑定VBO,然后去告诉GPU如何解析相关数据了,可以说是一个性能的优化了。

解释3:
当我们再绘制不同的顶点数据或者是其他数据时,我们需要重新进行一遍绑定设置等等操作来完成绘制不同,这时候就引出顶点数组对象。
在OpenGL中,顶点数组对象(Vertex Array Object,VAO)是一种OpenGL对象,用于存储顶点数据的状态信息,包括顶点坐标、法线、纹理坐标等。VAO可以看作是一种包含了多个顶点属性配置的容器,使得你可以在绘制时轻松地切换和使用不同的顶点数据。
顶点数组对象的使用可以帮助你更有效地组织和管理顶点数据,特别是在绘制多个物体或者在渲染循环中多次切换不同的顶点数据时。
其实可能还不太明白,其实使用的时候确实都是要走绑定顶点缓冲区,然后设置顶点的布局等等,但是我们现在把上面一套流程放进了一个叫VAO的对象中,也就是生成绑定它就相当于走完了内部的一套流程,在换顶点数据或者顶点布局的时候,就不需要再写一遍这么麻烦了,相当于是封装了一层,我们后续可以看看其实也是真的要封装一层的,我们可以通过在换顶点布局或者顶点数据的时候体现流程:
老一套的流程是:
| 1.解绑并重新绑定新的着色器程序 | glUseProgram(0); glUseProgram(shaderID); |
| 2.解绑和重新绑定顶点缓冲区 | glBindBuffer(GL_ARRAY_BUFFER, 0); glBindBuffer(GL_ARRAY_BUFFER, buffer)); |
| 3.重新设置顶点的布局 | glEnableVertexAttribArray(0); glVertexAttribPointer(0, 2, GL_FLOAT, GL_FALSE, sizeof(float) * 2, 0); |
| 4.绑定我们的索引缓冲区 | glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, ibo)); |
| 5.绘制调用 | glDrawElements |
引入VAO之后,我们要更改数据就变成了这样:
| 1.解绑并重新绑定新的着色器程序 | glUseProgram(0); glUseProgram(shaderID); |
| 2.绑定顶点数组(包含了绑定顶点缓冲区,设置顶点的布局,方便直接绑定别的,可以切换) | glBindVertexArray(vao); |
| 3.绑定索引缓冲 | glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, ibo); |
| 4.绘制调用 | glDrawElements |
另外这个顶点数组对象对于OpenGL是强制性的,因为即使我们没有创建它,还是走的老一套流程,其实状态还是由顶点数组对象来维护的。
3、如何使用VAO
生成VAO
unsigned int VAO;
glGenVertexArrays(1, &VAO);绑定VAO
glBindVertexArray(VAO)解绑VAO
glBindVertexArray(0)删除VAO
glDeleteVertexArrays4、VAO应用
// 生成VAO和VBO
GLuint vao;
glGenVertexArrays(1, &vao);
GLuint vbo;
glGenBuffers(1, &vbo);// 绑定VAO
glBindVertexArray(vao);// 绑定VBO并设置顶点数据
glBindBuffer(GL_ARRAY_BUFFER, vbo);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);// 配置顶点属性,用于将当前的顶点属性与顶点缓冲对象(VBO)关联起来
//配置顶点属性指针: 使用 glVertexAttribPointer 函数配置顶点属性指针,告诉OpenGL如何解释顶点数据。
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);// 解绑VAO和VBO
glBindBuffer(GL_ARRAY_BUFFER, 0);
glBindVertexArray(0);五、索引缓冲区对象EBO/IBO
1、概念
IBO/EBO, Element Buffer Objec,索引缓冲区对象。EBO用于存储顶点的索引数据,允许通过索引引用顶点,避免重复存储相同的顶点数据。
索引缓冲区和顶点缓冲区类似,也是显存上的一段内存,只不过上面的数据用处不同,索引缓冲区故名思义里面的数据是用于索引,主要作用是用于复用顶点缓冲区里的数据。
使用的GL_ELEMENT_ARRAY_BUFFER表示索引缓冲区。
2、为什么使用IBO/EBO
解释1:
EBO提高了渲染效率,减少了顶点数据的冗余,尤其在渲染复杂网格时,通过索引复用顶点能够显著节省内存。
解释2:
OpenGL渲染都是渲染三角形,如果我们想渲染一个正方形,就要通过渲染两个三角形,拼接成一个正方形,那么这两个三角形有两个顶点是重合的,如果没有索引缓冲区,两个三角形则需要六个顶点,而实际上一个正方形只有四个顶点,这里有两个顶点时数据冗余。仅仅一个正方形就有这么多冗余,那么一个复杂的游戏场景就会浪费非常多的内存。
解释3:
为什么使用EBO
正常画一个立方体,需要8个顶点,合计6个面。

但实际我们是用了4*6=24个点来画的,因为4个点组成一个面,我们能看出来,有很多重复点,为了能节省内存空间,我们想只用8个点描画立方体,这需要用到EBO
VertexData vc[] = {//正面{QVector3D(-0.5f, 0.0f, 0.5f), QVector3D(1.0f, 0.0f, 0.0f)}, //1{QVector3D(0.5f, 0.0f, 0.5f), QVector3D(0.0f, 1.0f, 0.0f)}, //2{QVector3D(0.5f, 1.0f, 0.5f), QVector3D(0.0f, 0.0f, 1.0f)}, //3{QVector3D(-0.5f, 1.0f, 0.5f), QVector3D(1.0f, 1.0f, 1.0f)}, //4//右面{QVector3D(0.5f, 0.0f, 0.5f), QVector3D(0.0f, 1.0f, 0.0f)}, //2{QVector3D(0.5f, 0.0f, -0.5f), QVector3D(1.0f, 1.0f, 0.0f)}, //5{QVector3D(0.5f, 1.0f, -0.5f), QVector3D(0.0f, 1.0f, 1.0f)}, //6{QVector3D(0.5f, 1.0f, 0.5f), QVector3D(0.0f, 0.0f, 1.0f)}, //3//左面{QVector3D(-0.5f, 0.0f, 0.5f), QVector3D(1.0f, 0.0f, 0.0f)}, //1{QVector3D(-0.5f, 0.0f, -0.5f),QVector3D(1.0f, 0.0f, 1.0f)}, //8{QVector3D(-0.5f, 1.0f, -0.5f),QVector3D(1.0f, 0.6f, 0.0f)}, //7{QVector3D(-0.5f, 1.0f, 0.5f), QVector3D(1.0f, 1.0f, 1.0f)}, //4//背面{QVector3D(0.5f, 0.0f, -0.5f), QVector3D(1.0f, 1.0f, 0.0f)}, //5{QVector3D(0.5f, 1.0f, -0.5f), QVector3D(0.0f, 1.0f, 1.0f)}, //6{QVector3D(-0.5f, 1.0f, -0.5f), QVector3D(1.0f, 0.6f, 0.0f)}, //7{QVector3D(-0.5f, 0.0f, -0.5f), QVector3D(1.0f, 0.0f, 1.0f)}, //8//顶面{QVector3D(0.5f, 1.0f, 0.5f), QVector3D(0.0f, 0.0f, 1.0f)}, //3{QVector3D(0.5f, 1.0f, -0.5f), QVector3D(0.0f, 1.0f, 1.0f)}, //6{QVector3D(-0.5f, 1.0f, -0.5f), QVector3D(1.0f, 0.6f, 0.0f)}, //7{QVector3D(-0.5f, 1.0f, 0.5f), QVector3D(1.0f, 1.0f, 1.0f)}, //4//底面{QVector3D(0.5f, 0.0f, 0.5f), QVector3D(0.0f, 1.0f, 0.0f)}, //2{QVector3D(0.5f, 0.0f, -0.5f), QVector3D(1.0f, 1.0f, 0.0f)}, //5{QVector3D(-0.5f, 0.0f, -0.5f), QVector3D(1.0f, 0.0f, 1.0f)}, //8{QVector3D(-0.5f, 0.0f, 0.5f), QVector3D(1.0f, 0.0f, 0.0f)}, //1};
EBO原理
//顶点有8个
VertexData vcs[] = {//正面{QVector3D(-0.5f, 0.0f, 0.5f), QVector3D(1.0f, 0.0f, 0.0f)}, //1{QVector3D(0.5f, 0.0f, 0.5f), QVector3D(0.0f, 1.0f, 0.0f)}, //2{QVector3D(0.5f, 1.0f, 0.5f), QVector3D(0.0f, 0.0f, 1.0f)}, //3{QVector3D(-0.5f, 1.0f, 0.5f), QVector3D(1.0f, 1.0f, 1.0f)}, //4{QVector3D(0.5f, 0.0f, -0.5f), QVector3D(1.0f, 1.0f, 0.0f)}, //5{QVector3D(0.5f, 1.0f, -0.5f), QVector3D(0.0f, 1.0f, 1.0f)}, //6{QVector3D(-0.5f, 1.0f, -0.5f),QVector3D(1.0f, 0.6f, 0.0f)}, //7{QVector3D(-0.5f, 0.0f, -0.5f),QVector3D(1.0f, 0.0f, 1.0f)}, //8};
//索引 对应8个面,每个面说明使用哪4个顶点GLuint indices[] = { // 起始于0!0, 1, 2, 3, // face 11, 4, 5, 2, // face 20, 7, 6, 3, // face 34, 5, 6, 7, // face 42, 5, 6, 3, // face 51, 4, 7, 0, // face 6};
3、如何使用EBO
生成EBO
glGenBuffers(1, &EBO);绑定EBO
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO);输入数据到缓冲区
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);链接属性
glVertexAttribPointer(m_posAttr, 3, GL_FLOAT, GL_FALSE, sizeof(VertexData), (GLvoid*)0);
glVertexAttribPointer(m_colAttr, 3, GL_FLOAT, GL_FALSE, sizeof(VertexData), (GLvoid*)sizeof(QVector3D));绘制
/*
glDrawElements是用于渲染索引缓冲区,
第一个和其他DrawCall一样,
第二个参数是count,表示有多少顶点需要渲染,
第三个参数是索引缓冲区参数类型,必须是GLES30.GL_UNSIGNED_SHORT或者GL_UNSIGNED_BYTE,
第四个参数是offset。
*/
GLES30.glDrawElements(GLES30.GL_TRIANGLES, count, type, offset)
PS: 绑定和解绑的顺序很重要,勿更改,另外EBO不用解绑,就算要解绑,也要在VAO解绑后。
4、EBO应用
//1 使用glGenBuffers函数生成一个缓冲ID
glGenVertexArrays(1, &VAO);
glGenBuffers(1, &VBO);
glGenBuffers(1, &EBO);
//2 绑定vao
glBindVertexArray(VAO);
//3 使用glBindBuffer函数把新创建的缓冲绑定到GL_ARRAY_BUFFER缓冲类型上
glBindBuffer(GL_ARRAY_BUFFER, VBO); //(绑定和解绑的顺序很重要,勿更改)
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO);
//4 把用户定的义数据复制到当前绑定缓冲的函数
glBufferData(GL_ARRAY_BUFFER, sizeof(vcs), vcs, GL_STATIC_DRAW);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);
//5 链接顶点属性//indx: 属性名//size: 顶点大小//type: 数据类型//normalized:数据被标准化//stride: 步长//ptr: 数据在缓冲中起始位置的偏移量
glVertexAttribPointer(m_posAttr, 3, GL_FLOAT, GL_FALSE, sizeof(VertexData), (GLvoid*)0);
glVertexAttribPointer(m_colAttr, 3, GL_FLOAT, GL_FALSE, sizeof(VertexData), (GLvoid*)sizeof(QVector3D));
//6 解绑缓存(绑定和解绑的顺序很重要,勿更改)
glBindBuffer(GL_ARRAY_BUFFER, 0);
//7 解绑VAO
glBindVertexArray(0);5、绘制过程
//1 绑定vao
glBindVertexArray(VAO);
//2 开启顶点属性
glEnableVertexAttribArray(0);
//颜色值
glEnableVertexAttribArray(1);
//3 绘制四边形,24个索引值
glDrawElements(GL_QUADS, 24, GL_UNSIGNED_INT, (GLvoid*)0);
//4 停用对应的顶点属性数组
glDisableVertexAttribArray(1);
glDisableVertexAttribArray(0);
//5 解绑VAO
glBindVertexArray(0);六、帧缓冲区FBO
1、概念
FBO(Frame Buffer Object)帧缓冲区对象
OpenGL作为图形API,可以看做是画笔,帧缓冲区可以比作画布。我们使用OpenGL在帧缓冲区上“作画”(渲染)。
帧缓冲区是一个容器,包含用于显示的颜色缓冲区、深度缓冲区和模板缓冲区。默认情况下,OpenGL渲染的结果会输出到帧缓冲区中。
用于写入颜色值的颜色缓冲、用于写入深度信息的深度缓冲和允许我们根据一些条件丢弃特定片段的模板缓冲,这些缓冲结合起来叫做帧缓冲(Framebuffer),它被储存在内存中。
我们目前所做的所有操作都是在默认帧缓冲的渲染缓冲上进行的。默认的帧缓冲是在你创建窗口的时候生成和配置的。
OpenGL允许我们定义我们自己的帧缓冲,也就是说我们能够定义我们自己的颜色缓冲,甚至是深度缓冲和模板缓冲。
帧缓冲,即是允许开发将渲染内容绘制到另一个缓冲上,不影响当前屏幕显示,需要显示上述帧缓冲时再取出显示即可。
OpenGL 允许我们定义自己的帧缓冲 FBO染采样的结果,等处理完再显示到窗口上。它可以在不影响默认帧缓冲的情况,来存储我们几次不同的渲染采样结果,比如摄像头拿到流之后,进行美颜效果,再显示出来。
优势
这样做的好处有:
- 提高渲染效率(后台绘制)
- 避免卡顿闪屏
- 实现纹理共享 (fbo 的纹理id)
FBO实际上是一个可添加缓冲区的容器,可以为其添加纹理或渲染缓冲区对象(RBO)。
FBO 本身不能用于渲染,只有添加了纹理或者渲染缓冲区之后才能作为渲染目标,它仅且提供了3种附着(Attachment),分别是颜色附着、深度附着和模板附着。
RBO(Render Buffer Object)即渲染缓冲区对象,是一个由应用程序分配的 2D 图像缓冲区。渲染缓冲区可以用于分配和存储颜色、深度或者模板值,可以用作 FBO 中的颜色、深度或者模板附着。
使用 FBO 作为渲染目标时,首先需要为 FBO 的附着添加连接对象,如颜色附着需要连接 纹理Q或者渲染缓冲区对象的颜色缓冲区。
FBO 虽然也叫缓冲区对象,但是它并不是一个真正的缓冲区,因为 OpenGL 并没有为它分配存储空间去存储渲染所需的几何、像素数据,我们可以认为它是一个指针的集合,这些指针指向了颜色缓冲区、深度缓冲区、模板缓冲区、累积缓冲区等这些真正的缓冲区对象,我们把这里的『指向关系』叫做附着,而 FBO 中的附着点类型有:颜色附着、深度附着和模板附着。这些附着点指向的缓冲区通常包含在某些对象里,我们把这些对象叫做附件,附件的类型有:纹理(Texture)或渲染缓冲区对象(Render Buffer Object,RBO)。

FBO 的附件和附着点
- 纹理(Texture)是一个可以往上绘制细节的 2D 图片(甚至也有 1D 和 3D 的纹理),你可以想象纹理是一张绘有砖块的纸,无缝折叠贴合到你的 3D 的房子上,这样你的房子看起来就像有砖墙外表一样了。除了图像以外,纹理也可以被用来储存大量的数据,这些数据可以发送到着色器上进行计算和处理。
- 渲染缓冲区对象(Render Buffer Object,RBO)则是一个由应用程序分配的 2D 图像缓冲区,可以分配和存储颜色、深度或者模板值,可以用作 FBO 中的颜色、深度或者模板附着。
FBO 是 OpenGL 渲染管线的最终目标,但其实 FBO 本身不直接用于渲染,而是要为其绑定好附件后才能作为渲染目标。所以,建构一个完整的 FBO 需要满足下列条件:
- 必须往 FBO 里面加入至少一个附件(颜色、深度、模板缓冲);
- 其中至少有一个是颜色附件;
- 所有的附件都应该是已经完全做好的(已经存储在内存之中);
- 每个缓冲都应该有同样数目的样本。
从上面的条件知道,帧缓冲至少需要附着一个颜附件,才能正常工作
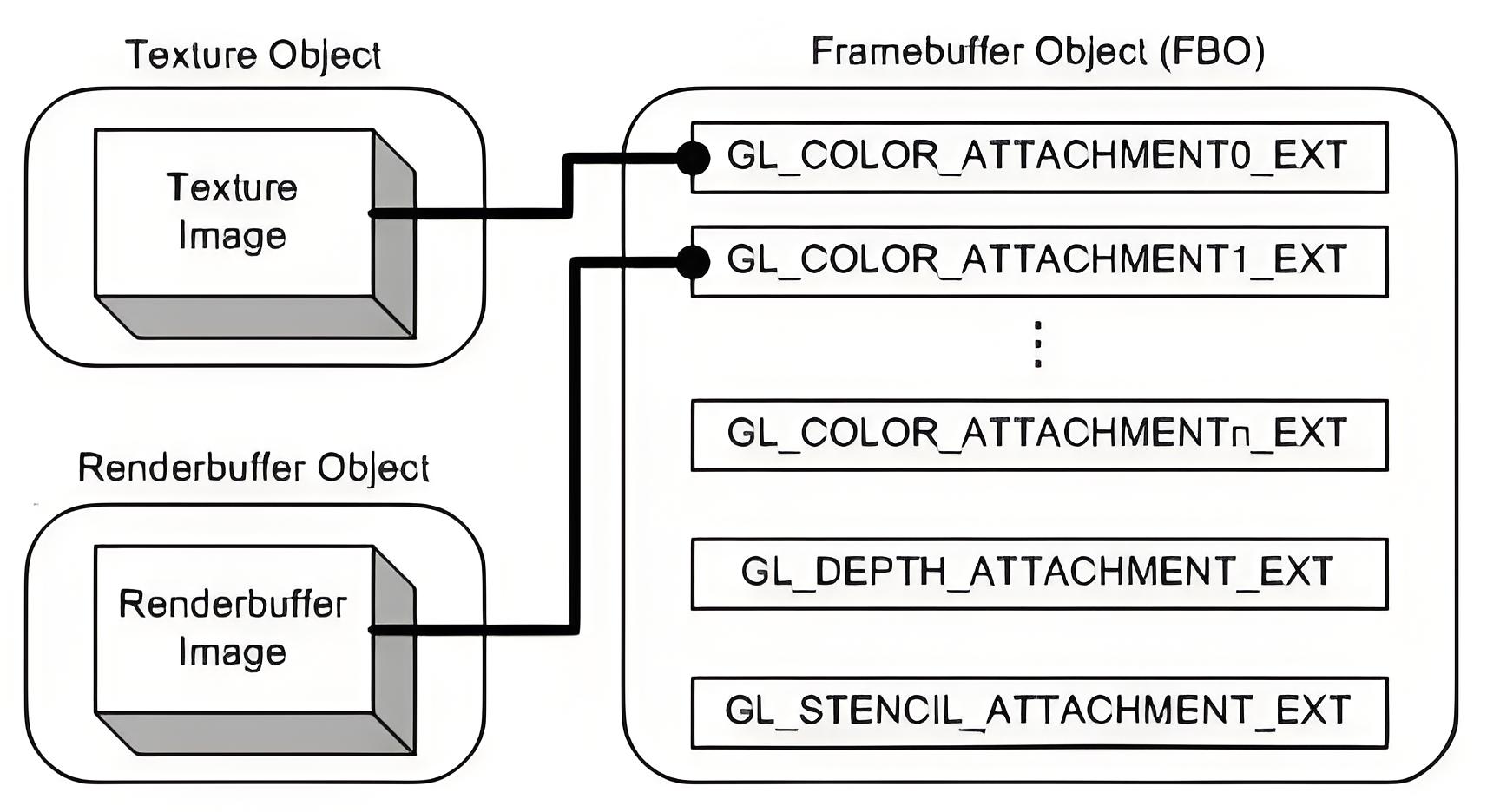
如上图,帧缓冲由以下三种缓冲组成:
- 颜色缓冲,可以有多个颜色缓冲
- 深度缓冲,只有一个
- 模板缓冲,只有一个
从上图看,这些缓冲并不是由帧缓冲创建提供,需要其它来attach。一般来说,颜色缓冲由纹理附件提供,而深度缓冲、模板缓冲由渲染缓冲对象RBO提供。
使用了几种不同类型的屏幕缓冲:用于写入颜色值的颜色缓冲,用于写入深度信息的深度缓冲,以及允许我们基于一些条件丢弃指定片段的模板缓冲。把这几种缓冲结合起来叫做帧缓冲(Framebuffer),它被储存于内存中。OpenGL给了我们自己定义帧缓冲的自由,我们可以选择性的定义自己的颜色缓冲、深度和模板缓冲。
我们目前所做的渲染操作都是是在默认的帧缓冲之上进行的。当你创建了你的窗口的时候默认帧缓冲就被创建和配置好了(GLFW为我们做了这件事)。通过创建我们自己的帧缓冲我们能够获得一种额外的渲染方式。
你也许不能立刻理解应用程序的帧缓冲的含义,通过帧缓冲可以将你的场景渲染到一个不同的帧缓冲中,可以使我们能够在场景中创建镜子这样的效果,或者做出一些炫酷的特效。首先我们会讨论它们是如何工作的,然后我们将利用帧缓冲来实现一些炫酷的效果。
在建立了OpenGL渲染环境之后,相当于获得了一只画笔,而此时我们有一块默认的画布,即我们的屏幕,default framebuffer。我们渲染的目的地就是我们的屏幕,我们画出来的东西,会显示在屏幕上。这个default framebuffer 是与一系列缓冲区相关联的(具体有哪些缓冲区,多少位的缓冲区,是建立OpenGL Context的时候用户自定义的。一般来讲,必要的是颜色缓冲区,深度缓冲区。模板缓冲区、累加缓冲区这俩哥们儿可选。)。我们需要颜色缓冲区来存储我们渲染物体的颜色,需要深度缓冲区来进行深度测试,等等。具体的渲染过程是如何进行的,就是OpenGL Render Pipeline的东西了。在此不细表。
2、为什么使用FBO
解释1:
帧缓冲区保存最终的渲染结果,显示在屏幕上。通过使用自定义帧缓冲对象(FBO),可以将渲染结果存储到纹理或进行离屏渲染。
解释2:
FBO(Framebuffer Object)就是OpenGL模拟default framebuffer的功能和结构创建的一种可以作为“画布”使用的Object。也就是说,你生成一个FBO,根据你的渲染需要,把你想渲染的东西渲染到你刚生成的这个FBO里面,而不是直接渲染到屏幕上,就是这个样子。Default framebuffer 有很多支撑渲染行为的缓冲区,FBO也可以有,但是要你手动去生成、设置和绑定。
值得注意的是FBO的角色更像是一个管理者,管理着所有支撑渲染的RenderBuffers和Textures,OpenGL没有为FBO分配内存空间去存储渲染所需的几何、像素数据等。但是,FBO有很多Attachment Point,顾名思义,我们把真正起作用的、具有实际内存空间占用的Renderbuffer和Texutures依附在FBO上,FBO起到管理的作用。这点跟VAO有点类似,是一批量“状态”的集合。
3、FBO和DFBO区别
DFBO(Default Framebuffer Object)
即屏幕,创建OpenGL Context时,准确的说是在ChoosePixelFormat的时候设定了该default framebufer有什么缓冲区,有多少位。
OpenGL Context创建完成时,默认的染目标就是屏幕,当然也可以调用glBindFramebuffer(GL FRAMEBUFFER,0)来手动地绑定屏幕为当前的渲染目标。(渲染目标:我们想把物体渲染到的地方)。注意glBindFramebuffer的第二个参数0,代表的就是default framebuffer的Handle.
通常,我们在进行一些简单的渲染时,直接染到屏幕(即default framebuffer)就足够可以了。但是有时候需要使用一些比较高阶的渲染技术时、例如FXAA、deferred shading、Shadow Map等等Mutiple Pass Rendering时,就需要进行Offscreen Render(离线渲染)。此时我们需要先把物体绘制到一个临时的framebuffer上,而不是直接绘制到屏幕上,这就需要我们采用FBO(Framebufer Object)来达到目标。
FBO(Framebufer Object )
FBO是由OpenGL创建的Framebuffer,是OpenGL模拟Default framebuffer而创建的。跟VBO,VAO等OpenGL Object一样,FBO也有Gen,Bind,Delete老三样操作。既然是模拟default framebuffer,那么就应该有为渲染所用的各种缓冲区。这些缓冲区是需要我们自己去生成的(又一大波Gen、Bind、Delete操作袭来)。这些缓冲区即所谓的RenderBuffer。那什么又是RenderBuffer呢?我也是理解了好久。其实FBO里的Renderbuffer都可以理解成一幅图片(image)。不同格式的图片有不同的用途。例如GL_RGBA的格式可以与FBO的GL_COLOR_ATTACHMENTi绑定用作颜色缓冲区。GL_DEPTH_COMPONENT格式的图片可以与GL_DEPTH_ATTACHMENT绑定作为深度缓冲区。等等。除了与RenderBuffer绑定,也可以与一幅纹理绑定。纹理也是一幅图片,与Color RenderBuffer的区别是:我们渲染到绑定了纹理的FBO,渲染的结果直接在纹理中,可以直接用下一个pass的纹理操作。
4、如何使用FBO
生成FBO
GLuint fbo;
glGenFramebuffers(1, &fbo);这里不得不提一句时机问题,android中创建帧缓冲如果时机不对,会失败。
GLSurfaceView.Render有三个接口:
-
onSurfaceCreated,suface刚创建,此时创建帧缓冲会失败
-
onSurfaceChanged,可以创建帧缓冲
-
onDrawFrame,可以创建帧缓冲,不过这个接口可能会被调用很多次,导致会重复创建很多次帧缓冲,冗余调用,于性能有损,不建议在此时操作
首先我们要创建一个帧缓冲对象,把它绑定到当前帧缓冲,做一些操作,然后解绑帧缓冲。
绑定FBO
glBindFramebuffer(GL_FRAMEBUFFER, fbo);绑定到GL_FRAMEBUFFER目标后,接下来所有的读、写帧缓冲的操作都会影响到当前绑定的帧缓冲。也可以把帧缓冲分开绑定到读或写目标上,分别使用GL_READ_FRAMEBUFFER或GL_DRAW_FRAMEBUFFER来做这件事。如果绑定到了GL_READ_FRAMEBUFFER,就能执行所有读取操作,像glReadPixels这样的函数使用了;绑定到GL_DRAW_FRAMEBUFFER上,就允许进行渲染、清空和其他的写入操作。大多数时候你不必分开用,通常把两个都绑定到GL_FRAMEBUFFER上就行。
很遗憾,现在我们还不能使用自己的帧缓冲,因为还没做完呢。建构一个完整的帧缓冲必须满足以下条件:
-
我们必须往里面加入至少一个附件(颜色、深度、模板缓冲)。
-
其中至少有一个是颜色附件。
-
所有的附件都应该是已经完全做好的(已经存储在内存之中)。
-
每个缓冲都应该有同样数目的样本。
从上面的需求中你可以看到,我们需要为帧缓冲创建一些附件(Attachment),还需要把这些附件附加到帧缓冲上。当我们做完所有上面提到的条件的时候我们就可以用 glCheckFramebufferStatus 带上 GL_FRAMEBUFFER 这个参数来检查是否真的成功做到了。然后检查当前绑定的帧缓冲,返回了这些规范中的哪个值。如果返回的是 GL_FRAMEBUFFER_COMPLETE就对了。
创建附件
需要给帧缓冲附加一个附件。附件是一个内存位置,它能够作为帧缓冲的一个缓冲,可以将它想象为一个图像。当创建一个附件的时候我们有两个选项:纹理或渲染缓冲对象(Renderbuffer Object)。之后所有的渲染操作将会渲染到当前绑定帧缓冲的附件中。由于我们的帧缓冲不是默认帧缓冲,渲染指令将不会对窗口的视觉输出有任何影响。出于这个原因,渲染到一个不同的帧缓冲被叫做离屏渲染(0ff-screen Rendering)。
创建附件有2种方式:纹理和渲染缓冲对象RBO
现在在执行完成检测前,我们需要把一个或更多的附件附加到帧缓冲上。一个附件就是一个内存地址,这个内存地址里面包含一个为帧缓冲准备的缓冲,它可以是个图像。当创建一个附件的时候我们有两种方式可以采用:纹理或渲染缓冲(renderbuffer)对象。
-
纹理附件
当把一个纹理附加到帧缓冲的时候,所有的渲染指令将会写入到这个纹理中,就像它是一个普通的颜色/深度或模板缓冲一样。使用纹理的优点是,所有渲染操作的结果将会被储存在一个纹理图像中,我们之后可以在着色器中很方便地使用它。
这样,当我们用 fbo 渲染完成后,可以拿到这个 纹理 的id,去做特效或者显示。
创建一个帧缓冲的纹理和创建普通纹理差不多:
GLuint texture;
glGenTextures(1, &texture);
glBindTexture(GL_TEXTURE_2D, texture);glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, 800, 600, 0, GL_RGB, GL_UNSIGNED_BYTE, NULL);glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);为什么纹理赋值的buf为null呢?
因为当我们往当前帧缓冲上渲染时,渲染的一切数据就会自动填充到帧缓冲关联的纹理上了,有点类似于android中的bitmap和canvas之间的关系,如果canvas关联了一个bitmap,调用canvas绘制的任何东西都会保存在bitmap中。
所以如何利用帧缓冲绘制呢?通常是渲染到帧缓冲结束时,拿与帧缓冲关联的纹理来绘制即可。且由于帧缓冲也有深度和模板测试,所以再次绘制纹理时,需要关闭深度测试、模板测试。
而且我们拿到这个纹理,可以改动片段着色器,实现很多不一样的效果,比如反相、灰度等。
这里主要的区别是我们把纹理的维度设置为屏幕大小(尽管不是必须的),我们还传递NULL作为纹理的data参数。对于这个纹理,我们只分配内存,而不去填充它。纹理填充会在渲染到帧缓冲的时候去做。同样,要注意,我们不用关心环绕方式或者Mipmap,因为在大多数时候都不会需要它们的。
如果你打算把整个屏幕渲染到一个或大或小的纹理上,你需要用新的纹理的尺寸作为参数再次调用glViewport(要在渲染到你的帧缓冲之前做好),否则只有一小部分纹理或屏幕能够绘制到纹理上。
现在我们已经创建了一个纹理,最后一件要做的事情是把它附加到帧缓冲上:
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0,GL_TEXTURE_2D, texture, 0);
glFramebufferTexture2D函数需要传入下列参数:
- target:我们所创建的帧缓冲类型的目标(绘制、读取或两者都有)。
- attachment:我们所附加的附件的类型。现在我们附加的是一个颜色附件。需要注意,最后的那个0是暗示我们可以附加1个以上颜色的附件。我们会在后面的教程中谈到。
- textarget:你希望附加的纹理类型。
- texture:附加的实际纹理。
- level:Mipmap level。我们设置为0
除颜色附件以外,我们还可以附加一个深度和一个模板纹理到帧缓冲对象上。为了附加一个深度缓冲,我们可以知道那个GL_DEPTH_ATTACHMENT作为附件类型。记住,这时纹理格式和内部格式类型(internalformat)就成了 GL_DEPTH_COMPONENT去反应深度缓冲的存储格式。附加一个模板缓冲,你要使用 GL_STENCIL_ATTACHMENT作为第二个参数,把纹理格式指定为 GL_STENCIL_INDEX。
也可以同时附加一个深度缓冲和一个模板缓冲为一个单独的纹理。这样纹理的每32位数值就包含了24位的深度信息和8位的模板信息。为了把一个深度和模板缓冲附加到一个单独纹理上,我们使用GL_DEPTH_STENCIL_ATTACHMENT类型配置纹理格式以包含深度值和模板值的结合物。下面是一个附加了深度和模板缓冲为单一纹理的例子:
-
RBO附件
定义1:
使用纹理来存储颜色缓存附件、深度缓存附件、模板缓存附件,但纹理并不是唯一的选择。尤其是针对深度缓存附件、模板缓存附件这类不需要在着色器中读取的缓存数据,OpenGL 还提供了另一种更加高效的缓存区附件——渲染缓冲对象(Renderbuffer Object, RBO)附件,用于存储渲染结果。
渲染缓冲对象(RBO)是 OpenGL 提供的一种存储渲染结果的帧缓冲对象(FrameBuffer Object,FBO)附件,与帧缓冲对象(FBO)配合使用。
与可以在着色器中采样的纹理附件不同,渲染缓冲对象的不能被直接读取。由于其不可被直接读取的特性,给了OpenGL很多优化空间:RBO直接存储渲染数据,无需进行额外的向纹理特定格式的转换,从而减少了内存带宽的占用。而深度缓冲区和模板缓冲区这类不需要在后续的着色器阶段中被读取和处理的数据,正是RBO的绝佳应用场景。
由于RBO不能被直接读取,所以无法像操作纹理一样从 RBO 中直接获取(采样)数据。但这并不意味着不可以读取RBO中缓存数据,可以借助 glReadPixels接口获得指定区域内的数据,该接口的详细叙述如下:
//从帧缓冲区中读取像素数据//x: 从帧缓冲区读取的像素的左下角 x 坐标//y: 从帧缓冲区读取的像素的左下角 y 坐标//width: 从帧缓冲区读取的像素的宽度//height: 从帧缓冲区读取的像素的高度//format: 像素数据的格式,GL_STENCIL_INDEX, // GL_DEPTH_COMPONENT, GL_DEPTH_STENCIL, // GL_BGR, GL_RGBA, and GL_BGRA, etc//type: 像素数据的类型,GL_UNSIGNED_BYTE, GL_BYTE, // GL_UNSIGNED_SHORT, GL_SHORT, GL_UNSIGNED_INT, // GL_INT,
void glReadPixels(GLint x, GLint y, GLsizei width, GLsizei height, GLenum format, GLenum type, void *pixels);定义2:
在介绍了帧缓冲的可行附件类型——纹理后,OpenGL引进了渲染缓冲对象(Renderbuffer objects),所以在过去那些美好时光里纹理是附件的唯一可用的类型。和纹理图像一样,渲染缓冲对象也是一个缓冲,它可以是一堆字节、整数、像素或者其他东西。渲染缓冲对象的一大优点是,它以OpenGL原生渲染格式储存它的数据,因此在离屏渲染到帧缓冲的时候,这些数据就相当于被优化过的了。
渲染缓冲对象将所有渲染数据直接储存到它们的缓冲里,而不会进行针对特定纹理格式的任何转换,这样它们就成了一种快速可写的存储介质了。然而,渲染缓冲对象通常是只写的,不能修改它们(就像获取纹理,不能写入纹理一样)。可以用glReadPixels函数去读取,函数返回一个当前绑定的帧缓冲的特定像素区域,而不是直接返回附件本身。
因为它们的数据已经是原生格式了,在写入或把它们的数据简单地到其他缓冲的时候非常快。当使用渲染缓冲对象时,像切换缓冲这种操作变得异常高速。我们在每个渲染迭代末尾使用的那个glfwSwapBuffers函数,同样以渲染缓冲对象实现:我们简单地写入到一个渲染缓冲图像,最后交换到另一个里。渲染缓冲对象对于这种操作来说很完美。
创建一个渲染缓冲对象和创建帧缓冲代码差不多:
// 创建渲染缓冲对象
// n: 要创建的 RBO 数量
// renderbuffers: 返回的 RBO ID 数组
void glGenRenderbuffers(GLsizei n, GLuint *renderbuffers);相似地,我们打算把渲染缓冲对象绑定,这样所有后续渲染缓冲操作都会影响到当前的渲染缓冲对象:
// 绑定渲染缓冲对象
// target: 要绑定的目标,必须是 GL_RENDERBUFFER
// renderbuffer: 要绑定的 RBO ID
void glBindRenderbuffer(GLenum target, GLuint renderbuffer);由于渲染缓冲对象通常是只写的,它们经常作为深度和模板附件来使用,由于大多数时候,我们不需要从深度和模板缓冲中读取数据,但仍关心深度和模板测试。我们就需要有深度和模板值提供给测试,但不需要对这些值进行采样(sample),所以深度缓冲对象是完全符合的。当我们不去从这些缓冲中采样的时候,渲染缓冲对象通常很合适,因为它们等于是被优化过的。
调用glRenderbufferStorage函数可以创建一个深度和模板渲染缓冲对象:
// 为 RBO 分配存储空间// target: 要绑定的目标,必须是 GL_RENDERBUFFER// internalformat: RBO 的内部格式,例如 GL_DEPTH_COMPONENT, // GL_DEPTH24_STENCIL8, GL_RGBA8 等// width: RBO 的宽度// height: RBO 的高度
void glRenderbufferStorage(GLenum target, GLenum internalformat, GLsizei width, GLsizei height);创建一个渲染缓冲对象与创建纹理对象相似,不同之处在于这个对象是专门被设计用于图像的,而不是通用目的的数据缓冲,比如纹理。这里我们选择GL_DEPTH24_STENCIL8作为内部格式,它同时代表24位的深度和8位的模板缓冲。
最后一件还要做的事情是把帧缓冲对象附加上:
// 将 RBO 附加到帧缓冲对象// target: 要绑定的目标,必须是 GL_FRAMEBUFFER// attachment: 要附加的附件类型,例如 GL_DEPTH_ATTACHMENT, GL_STENCIL_ATTACHMENT, GL_DEPTH_STENCIL_ATTACHMENT 等// renderbuffertarget: RBO 的目标类型,必须是 GL_RENDERBUFFER// renderbuffer: 要附加的 RBO IDvoid glFramebufferRenderbuffer(GLenum target, GLenum attachment, GLenum renderbuffertarget, GLuint renderbuffer);在帧缓冲项目中,渲染缓冲对象可以提供一些优化,但更重要的是知道何时使用渲染缓冲对象,何时使用纹理。通常的规则是,如果你永远都不需要从特定的缓冲中进行采样,渲染缓冲对象对特定缓冲是更明智的选择。如果哪天需要从比如颜色或深度值这样的特定缓冲采样数据的话,你最好还是使用纹理附件。从执行效率角度考虑,它不会对效率有太大影响。
删除RBO
// 删除渲染缓冲对象
// n: 要删除的 RBO 数量
// renderbuffers: 要删除的 RBO ID 数组
void glDeleteRenderbuffers(GLsizei n, const GLuint *renderbuffers);纹理和RBO区别
尽管渲染缓冲对象和纹理都能作为 FBO 的附件,用于存储渲染结果,但它们的功能和性能有所不同。
- 功能差异:纹理可以被采样,可以在着色器中读取和操作;而 RBO 则只能用于渲染,无法直接读取。这使得 RBO通常用于那些只需要存储但不需要处理的缓冲数据。
- 性能差异:由于 RBO 不需要执行采样和读取操作,因此在存储如深度缓冲或模板缓冲等临时渲染数据时,它能提供比纹理更好的性能表现。这种性能提升对于实时渲染(如游戏或图形应用程序)尤其重要,因为减少内存带宽占用能够使渲染管线更流畅。
- 内存占用:RBO 的内存占用通常比纹理要少,因为它们不需要存储额外的纹理元数据(如 mipmap 层级、纹理坐标等)。这对于内存资源有限的设备(如移动设备)来说是一个重要的优势。
- 应用场景:RBO 通常用于存储深度缓冲和模板缓冲等不需要在后续阶段中被读取和处理的数据。而纹理则更适合用于存储需要被采样的颜色缓冲数据,或者需要被多次使用的图像数据。纹理也能用来存储深度缓冲和模板缓冲。所以RBO的应用场景相对局限。
总结:如果你不需要从一个缓冲中采样数据,那么对这个缓冲使用渲染缓冲对象会是明智的选择。如果你需要从缓冲中采样颜色或深度值等数据,那么你应该选择纹理附件。性能方面它不会产生非常大的影响的。通俗来说,深度及模板缓冲用渲染缓冲对象,颜色缓冲用纹理附件。
检查FBO完整性
if(glCheckFramebufferStatus(GL_FRAMEBUFFER) == GL_FRAMEBUFFER_COMPLETE){}后续所有渲染操作将渲染到当前绑定的帧缓冲的附加缓冲中,由于我们的帧缓冲不是默认的帧缓冲,渲染命令对窗口的视频输出不会产生任何影响。出于这个原因,它被称为离屏渲染(off-screen rendering),就是渲染到一个另外的缓冲中。为了让所有的渲染操作对主窗口产生影响我们必须通过绑定为0来使默认帧缓冲被激活。
激活默认FBO
glBindFramebuffer(GL_FRAMEBUFFER, 0);删除FBO
glDeleteFramebuffers(1, &fbo);5、FBO应用
举例1:纹理附件
当把一个纹理(Texture)附加到 FBO 上的时候,所有渲染命令会写入到纹理上,就像它是一个普通的颜色/深度或者模板缓冲一样。使用纹理的好处是,所有渲染操作的结果都会被储存为一个纹理图像,这样我们就可以简单的在着色器中使用了。
// 创建和绑定 FBO:
GLuint fbo;
glGenFramebuffers(1, &fbo); // 创建 FBO
glBindFramebuffer(GL_FRAMEBUFFER, fbo); // 绑定 FBO,注意:如果这里用 glBindFramebuffer(GL_FRAMEBUFFER, 0) 则是激活默认的帧缓冲区// 创建纹理:
GLuint texture;
glGenTextures(1, &texture);
glBindTexture(GL_TEXTURE_2D, texture);
// 创建纹理和分配存储空间。传入 NULL 作为纹理的 data 参数,不填充数据,填充纹理数据会在渲染到 FBO 时去做。
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, m_width, m_height, 0, GL_RGBA, GL_UNSIGNED_BYTE, NULL);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR );
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glBindTexture(GL_TEXTURE_2D, 0);// 将纹理添加为 FBO 的附件,连接在颜色附着点:
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, texture, 0);// 检测 FBO:
GLenum status = glCheckFramebufferStatus(GL_FRAMEBUFFER);
if (status != GL_FRAMEBUFFER_COMPLETE)printf("Frame buffer incomplete!\n");
elseprintf("Frame buffer complete!\n");举例2:纹理附件
现在我们知道了(一些)帧缓冲如何工作的,是时候把它们用起来了。我们会把场景渲染到一个颜色纹理上,这个纹理附加到一个我们创建的帧缓冲上,然后把纹理绘制到一个简单的四边形上,这个四边形铺满整个屏幕。输出的图像看似和没用帧缓冲一样,但是这次,它其实是直接打印到了一个单独的四边形上面。为什么这很有用呢?下一部分我们会看到原因。
第一件要做的事情是创建一个帧缓冲对象,并绑定它,这比较明了:
GLuint framebuffer;
glGenFramebuffers(1, &framebuffer);
glBindFramebuffer(GL_FRAMEBUFFER, framebuffer);下一步我们创建一个纹理图像,这是我们将要附加到帧缓冲的颜色附件。我们把纹理的尺寸设置为窗口的宽度和高度,并保持数据未初始化:
// Generate texture
GLuint texColorBuffer;
glGenTextures(1, &texColorBuffer);
glBindTexture(GL_TEXTURE_2D, texColorBuffer);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, 800, 600, 0, GL_RGB, GL_UNSIGNED_BYTE, NULL);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR );
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glBindTexture(GL_TEXTURE_2D, 0);// Attach it to currently bound framebuffer object
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, texColorBuffer, 0);我们同样打算要让OpenGL确定可以进行深度测试(模板测试,如果你用的话)所以我们必须还要确保向帧缓冲中添加一个深度(和模板)附件。由于我们只采样颜色缓冲,并不采样其他缓冲,我们可以创建一个渲染缓冲对象来达到这个目的。记住,当你不打算从指定缓冲采样的的时候,它们是一个不错的选择。
创建一个渲染缓冲对象不太难。唯一一件要记住的事情是,我们正在创建的是一个渲染缓冲对象的深度和模板附件。我们把它的内部给设置为GL_DEPTH24_STENCIL8,对于我们的目的来说这个精确度已经足够了。
GLuint rbo;
glGenRenderbuffers(1, &rbo);
glBindRenderbuffer(GL_RENDERBUFFER, rbo);
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH24_STENCIL8, 800, 600);
glBindRenderbuffer(GL_RENDERBUFFER, 0);我们为渲染缓冲对象分配了足够的内存空间以后,我们可以解绑渲染缓冲。
接着,在做好帧缓冲之前,还有最后一步,我们把渲染缓冲对象附加到帧缓冲的深度和模板附件上:
glFramebufferRenderbuffer(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_RENDERBUFFER, rbo);
然后我们要检查帧缓冲是否真的做好了,如果没有,我们就打印一个错误消息。
if(glCheckFramebufferStatus(GL_FRAMEBUFFER) != GL_FRAMEBUFFER_COMPLETE)cout << "ERROR::FRAMEBUFFER:: Framebuffer is not complete!" << endl;
glBindFramebuffer(GL_FRAMEBUFFER, 0);还要保证解绑帧缓冲,这样我们才不会意外渲染到错误的帧缓冲上。
现在帧缓冲做好了,我们要做的全部就是渲染到帧缓冲上,而不是绑定到帧缓冲对象的默认缓冲。余下所有命令会影响到当前绑定的帧缓冲上。所有深度和模板操作同样会从当前绑定的帧缓冲的深度和模板附件中读取,当然,得是在它们可用的情况下。如果你遗漏了比如深度缓冲,所有深度测试就不会工作,因为当前绑定的帧缓冲里没有深度缓冲。
所以,为把场景绘制到一个单独的纹理,我们必须以下面步骤来做:
- 使用新的绑定为激活帧缓冲的帧缓冲,像往常那样渲染场景。
- 绑定到默认帧缓冲。
- 绘制一个四边形,让它平铺到整个屏幕上,用新的帧缓冲的颜色缓冲作为他的纹理。
举例3:RBO 附件
//创建和绑定FBO:
GLuint fbo;
glGenFramebuffers(1, &fbo); // 创建 FBO
glBindFramebuffer(GL_FRAMEBUFFER, fbo); // 绑定 FBO,注意:如果这里用 glBindFramebuffer(GL_FRAMEBUFFER, 0) 则是激活默认的帧缓冲区//创建RBO:
GLuint rbo;
glGenRenderbuffers(1, &rbo); // 创建 RBO//绑定RBO,所有后续渲染缓冲操作都会影响到当前的渲染缓冲对象
glBindRenderbuffer(GL_RENDERBUFFER, rbo);
//为RBO的颜色缓冲区分配存储空间
glRenderbufferStorage(GL_RENDERBUFFER, GL_RGBA, m_width, m_height);
//将RBO添加为FBO的附件,连接在颜色附着点:
glFramebufferRenderbuffer(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_RENDERBUFFER, rbo);// 检测 FBO:
GLenum status = glCheckFramebufferStatus(GL_FRAMEBUFFER);
if (status != GL_FRAMEBUFFER_COMPLETE)printf("Frame buffer incomplete!\n");
elseprintf("Frame buffer complete!\n");七、离屏渲染
1、概念
随着新需求的出现和OpenGL的发展,off-screen render技术出现了,即离屏渲染(离线渲染)。off-screen render,离线渲染,其实很简单。我们把物体直接渲染到屏幕上,就是“在线渲染”。同理,我们把物体渲染到别的地方,不渲染到屏幕上,就是“离线渲染”。 那我们不渲染到屏幕,渲染到哪儿去呢?
需要给自定义的帧缓冲附加一个附件。附件是一个内存位置,它能够作为帧缓冲的一个缓冲,可以将它想象为一个图像。当创建一个附件的时候我们有两个选项:纹理或渲染缓冲对象(Renderbuffer Object)。之后所有的渲染操作将会渲染到当前绑定帧缓冲的附件中。由于我们的帧缓冲不是默认帧缓冲,渲染指令将不会对窗口的视觉输出有任何影响。出于这个原因,渲染到一个不同的帧缓冲被叫做离屏渲染(0ff-screen Rendering)。
八、总结
1、常用各类缓冲区分析
VBO: 存储大量顶点,因而可以利用VBO一次性发送大量数据到显卡
VAO: 配置并告诉了OpenGL如何使用VBO,以及使用哪个VBO
EBO/IBO:
索引缓冲区里面就是存储了一系列索引,用于复用顶点缓冲区。
有个问题,大家可能会想之前用6个顶点也不过18个数,使用了顶点缓冲区后变为12个,但是索引缓冲区还有6个,好像没有节省多少内存。
但是实际上顶点可能包含了非常多的数据,比如我们之前用它来存颜色,它还可以存纹理等额外数据,实际应用场景一个顶点可能有非常多数据,所以复用可节省的内存是非常可观的。
2、无法删除缓冲区
OpenGL并没有提供直接删除缓冲区的函数或方法。这是因为OpenGL的设计理念是尽可能地提供高性能和灵活性,而不是提供高级别的内存管理功能。因此,开发者需要手动管理缓冲区的生命周期。
要删除缓冲区,开发者需要按照以下步骤进行操作:
-
解绑缓冲区:在删除缓冲区之前,需要先解绑缓冲区。可以使用
glBindBuffer函数将当前的缓冲区绑定到一个无效的缓冲区对象上,例如glBindBuffer(GL_ARRAY_BUFFER, 0)。 -
删除缓冲区对象:使用
glDeleteBuffers函数来删除缓冲区对象。该函数接受一个整数参数,表示要删除的缓冲区对象的数量,以及一个指向缓冲区对象的指针。例如,glDeleteBuffers(1, &bufferObject)将删除名为bufferObject的缓冲区对象。
需要注意的是,删除缓冲区对象并不会自动释放缓冲区所占用的内存。开发者需要在删除缓冲区对象之前,确保已经释放了缓冲区所占用的内存,以避免内存泄漏。
九、源码下载
VAO顶点数组对象应用演示demo源码下载:
https://download.csdn.net/download/github_27263697/89915626
VBO顶点缓冲区对象应用演示demo源码下载:
https://download.csdn.net/download/github_27263697/89915617
EBO/IBO索引缓冲区对象应用演示demo源码下载:
https://download.csdn.net/download/github_27263697/89916753
推荐文章
OpenGL入门(四)顶点缓冲区_顶点缓冲器有什么用-CSDN博客
Android OpenGL ES 2.0(七)--- 顶点缓冲区对象-CSDN博客
OpenGL 入门(二)— 顶点数组对象(VAO)和顶点缓冲对象(VBO)_glvertexattribpointer-CSDN博客
你好,三角形 - LearnOpenGL CN
https://segmentfault.com/a/1190000042610598?sort=newest#item-1
OpenGL学习总结-数据缓存区(四)_opengl genbuffer-CSDN博客
一篇搞懂OpenGL uniforms变量和顶点数组对象(Vertex Array Object,VAO)_glgenvertexarrays-CSDN博客OpenGL无法删除缓冲区_OpenGL/OpenTK -多帧缓冲区_使用OpenGL内插数据缓冲区? - 腾讯云开发者社区 - 腾讯云小白学opengl 第五课 之 索引缓冲对象 - 踏月清风 - 博客园OpenGL无法删除缓冲区_OpenGL/OpenTK -多帧缓冲区_使用OpenGL内插数据缓冲区? - 腾讯云开发者社区 - 腾讯云一篇搞懂OpenGL uniforms变量和顶点数组对象(Vertex Array Object,VAO)_glgenvertexarrays-CSDN博客
OpenGL ES 索引缓冲区(4)_opengl索引缓冲区-CSDN博客
一看就懂的 OpenGL 基础概念(4):各种 O 之 FBO丨音视频基础-腾讯云开发者社区-腾讯云
https://learnopengl-cn.readthedocs.io/zh/latest/04%20Advanced%20OpenGL/05%20Framebuffers/
一看就懂的 OpenGL 基础概念(4):各种 O 之 FBO丨音视频基础-腾讯云开发者社区-腾讯云
关于FBO(FrameBuffer Object)的一些理解 - 风过枫默 - 博客园
OpenGL ES教程——帧缓冲_牛客网