1. KBinsDiscretizer的定义
KBinsDiscretizer是 scikit-learn 库中的一个类,用于将连续数据离散化成区间(bins)。这个类通过将特征值分配到 k 个等宽的区间(bins)来实现离散化,并且可以配置不同的编码方式来输出结果。
2. 主要参数
主要参数:
• n_bins:指定每个特征要产生的区间(bins)数量。如果是一个整数,则应用于所有特征;如果是一个数组,则每个元素对应一个特征的 bins 数量。
• encode:指定编码方式,可以是onehot、onehot-dense或ordinal。onehot会将结果用 one-hot 编码并返回稀疏矩阵;onehot-dense会返回密集数组;ordinal会返回整数形式的 bin 标识符。
• strategy:定义 bins 宽度的策略,可以是uniform、quantile或kmeans。uniform表示所有 bins 在每个特征中具有相同的宽度;quantile表示所有 bins 在每个特征中包含相同数量的点;kmeans基于每个特征上独立执行的 k-means 聚类过程定义 bins。
• dtype:输出的数据类型,支持 np.float32 和 np.float64。
• subsample:为了计算效率,最大样本数用于拟合模型。如果设置为 None,则使用所有训练样本来计算确定 binning 阈值的分位数。
• random_state:用于 subsampling 的随机数生成。
3. 属性
属性:
• bin_edges:每个 bin 的边界,包含不同形状的数组。
• n_bins:每个特征的 bins 数量,如果 bins 宽度太小(即,=1e-8),则会被移除并发出警告。
• n_features_in:在拟合过程中看到的特征数量。
• feature_names_in:在拟合过程中看到的特征名称,仅当 X 有全部为字符串的特征名称时定义。
功能:KBinsDiscretizer可以将连续特征转换为离散特征,这对于某些模型(如线性模型)可能有益,因为它们可能无法很好地处理连续数据。离散化后的数据可以用于引入非线性,增强模型的表现力和可解释性。
4. 示例
示例1:
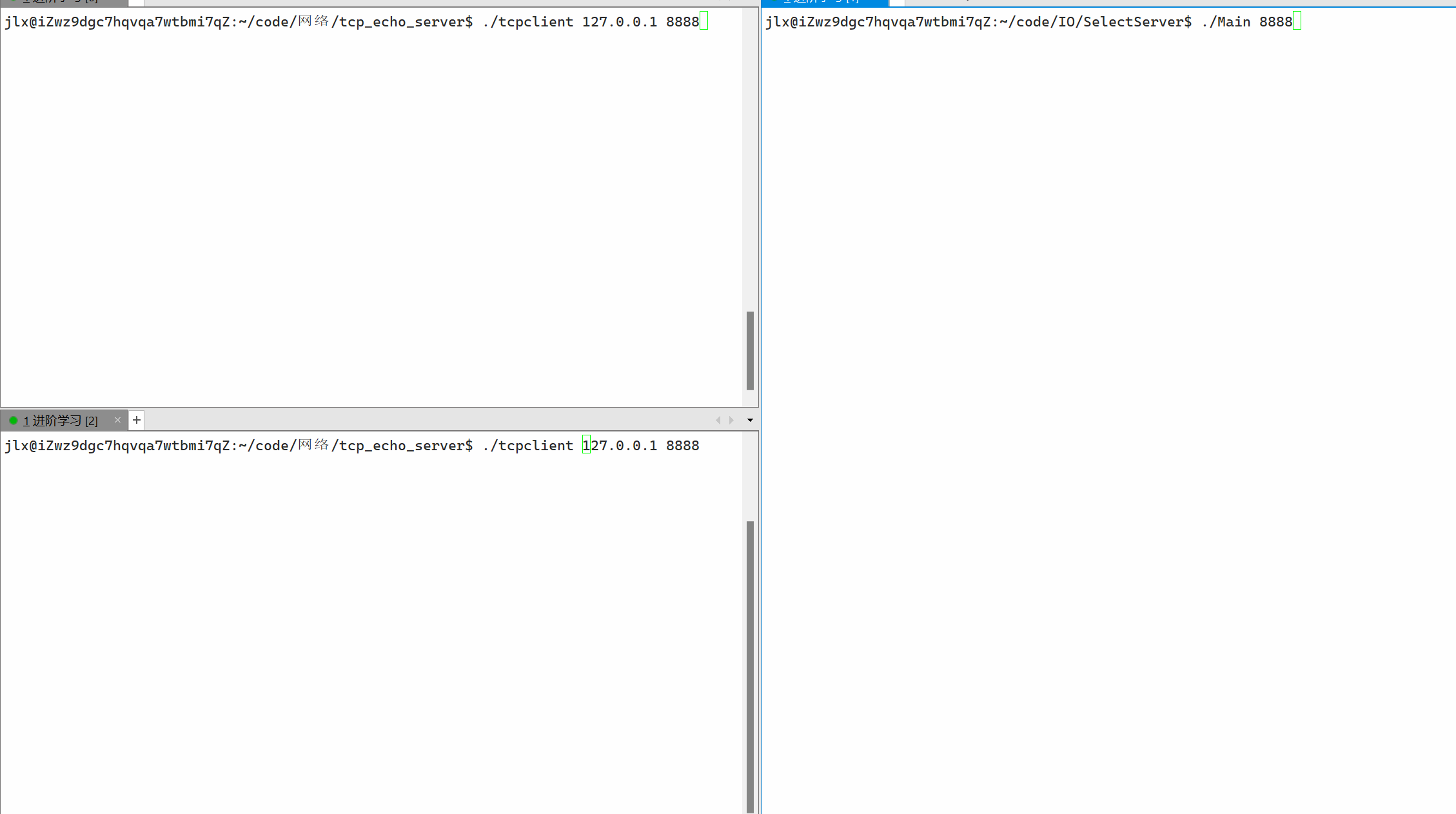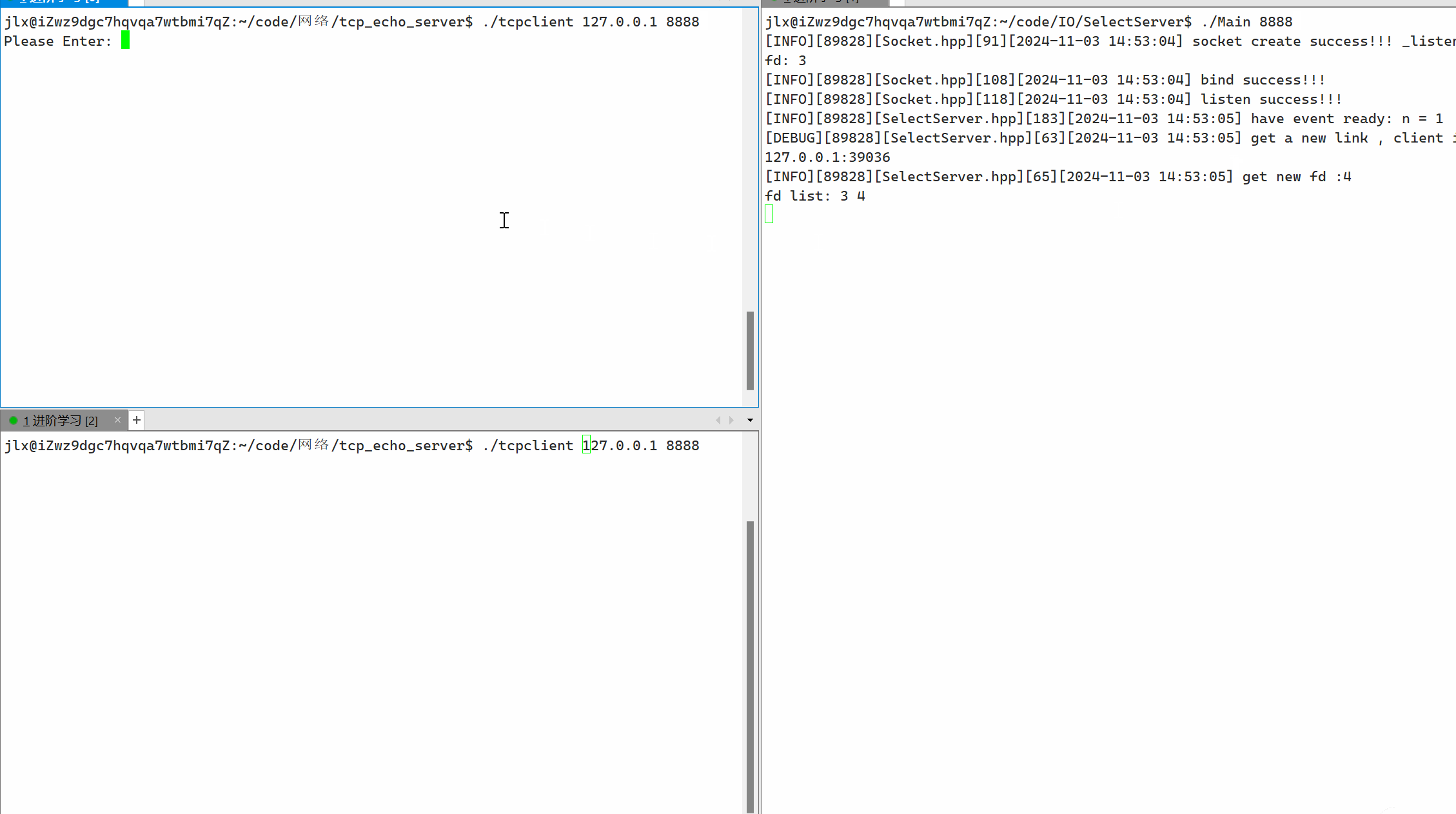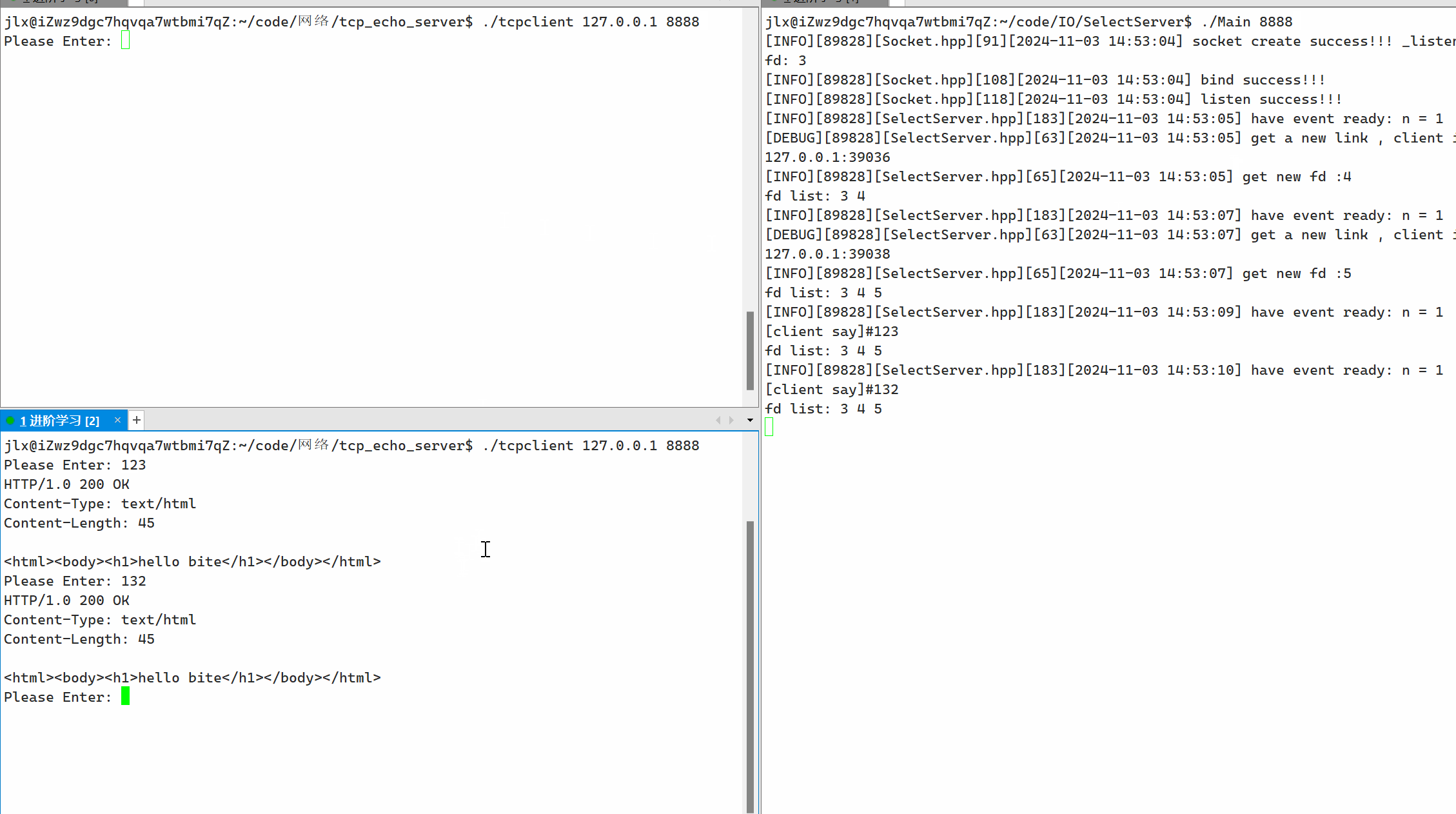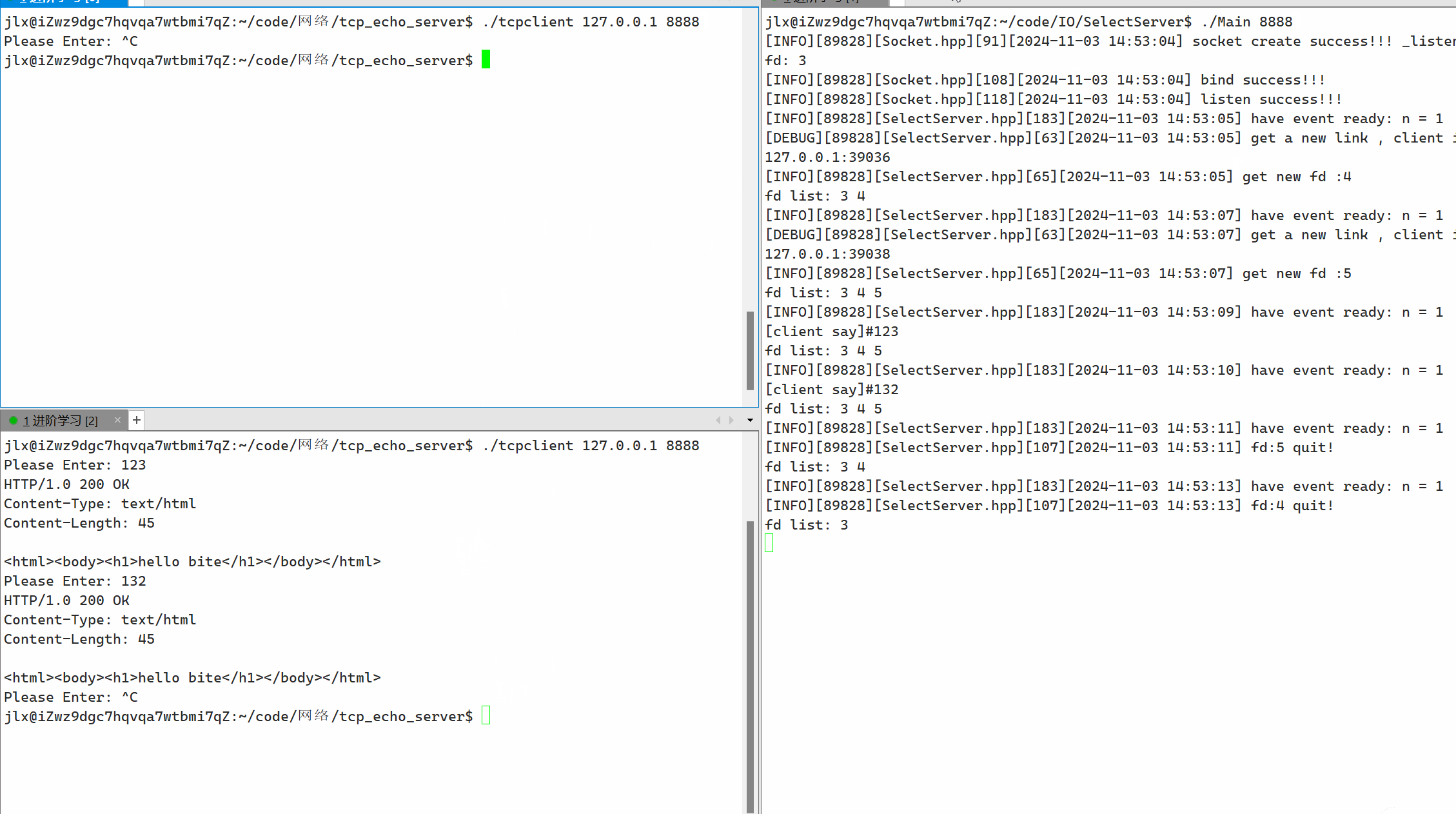
from sklearn.preprocessing import KBinsDiscretizer
X = [[-2, 1, -4, -1],[-1, 2, -3, -0.5],[0, 3, -2, 0.5],[1, 4, -1, 2]]
est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform')
est.fit(X)
Xt = est.transform(X)
print(Xt)
输出结果:

示例2:
import numpy as np
from sklearn.preprocessing import KBinsDiscretizer
X = np.array([[ -3., 5., 15 ],[ 0., 6., 14 ],[ 6., 3., 11 ]])
est =KBinsDiscretizer(n_bins=[3, 2, 2], encode='ordinal').fit(X)
Xs=est.transform(X)
print(Xs)
n_bins=[3, 2, 2] 表示:
- 第一个特征(X 的第一列)被分成了3个箱子。
- 第二个特征(X 的第二列)被分成了2个箱子。
- 第三个特征(X 的第三列)也被分成了2个箱子。
输出结果:

这个类提供了一种灵活的方式来处理连续数据,使其适应于需要离散特征的机器学习算法。