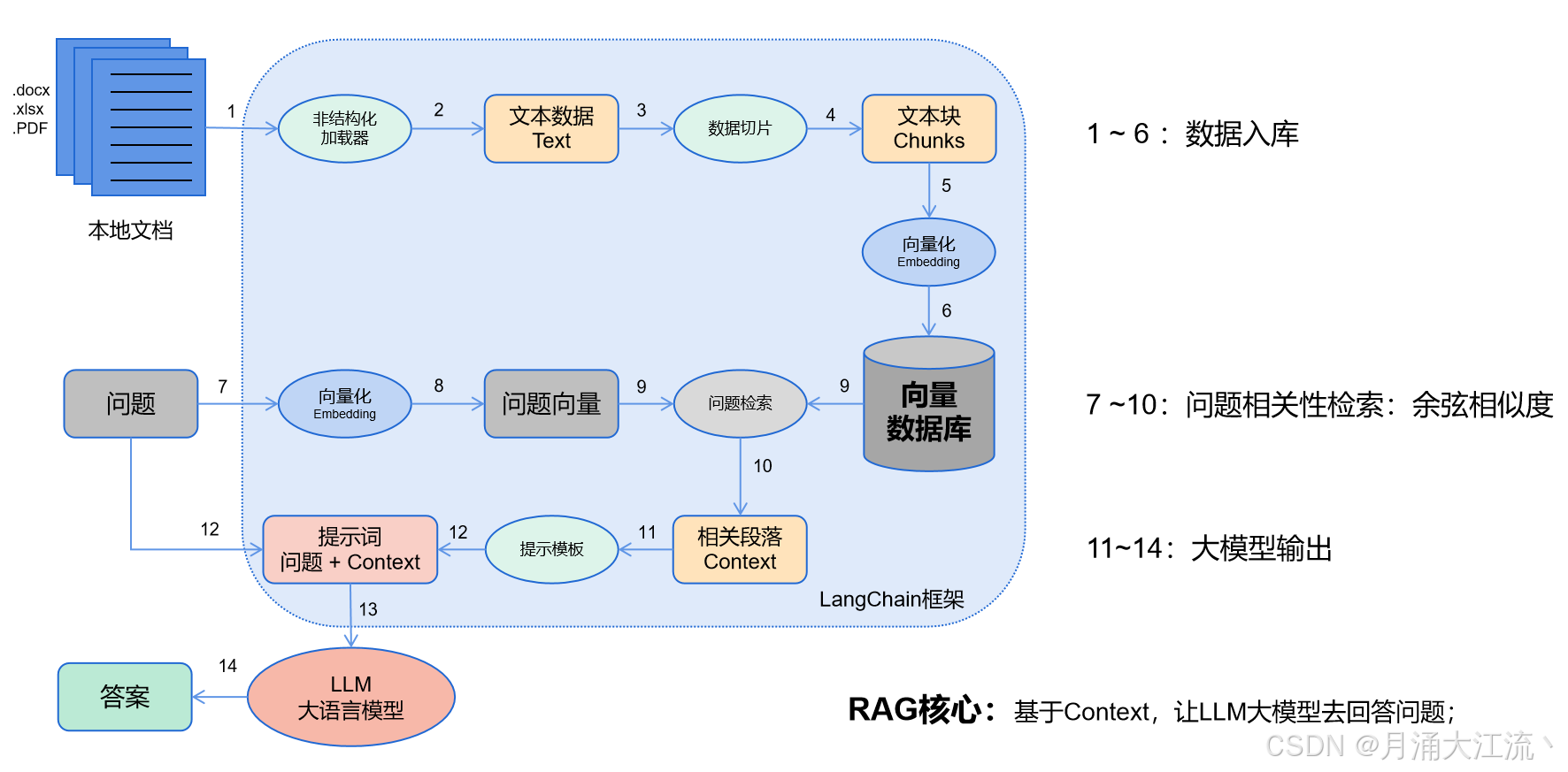
Python日常练习
题目:
试题文件夹下的文本文件sentences.txt中,每行对应一个句子,该句子包含了多个
单词,单词之间以空格隔开。每个单词仅包含英文字母。我们希望能够将文件中的
每个句子转换为“山羊语”。句子的每个单词首先按照下述规则转换:
如果该单词以小写或者大写的元音字母(a, e, i, o, u)开头,则在单词尾部添
加"ma"。比如单词"apple"变为"applema"。
如果该单词以非元音字母开始,则去掉该单词的第一个字母,将该字母附加到单词
尾部,然后附加"ma"。比如"goat"变为"oatgma"。
对于每个句子中的单词,首先按照上述规则转换,然后在该单词之后添加多个字
母'a'。每个单词添加的字母'a'的个数等于其在句子中的序数,即第1个单词后
附加1个'a',第2个单词附加2个'a'... 最后的输出由转换后的单词组成,单词之
间以一个空格隔开。
sentences.txt文本文件中的前两行为:
I speak Goat Latin
The quick brown fox jumped over the lazy dog
程序的输出中前面两行为:
Imaa peaksmaaa oatGmaaaa atinLmaaaaa
heTmaa uickqmaaa rownbmaaaa oxfmaaaaa umpedjmaaaaaa overmaaaaaaa
hetmaaaaaaaa azylmaaaaaaaaa ogdmaaaaaaaaaa
代码实现
########## code start ##########
filenameczj='sentences.txt'
def createfileczj():tt='''I speak Goat Latin. The quick brown fox jumped over the lazy dog '''fczj=open(filenameczj,"w")fczj.write(tt)fczj.close()
def convert(word):if word[0] not in 'aeiouAEIOU':word = word[1:] + word[:1]return word + 'ma'createfileczj()
with open('sentences.txt') as f:while True:line = f.readline()if not line:breakwords = line.split()convert_words = []for i, word in enumerate(words, 1):convert_words.append(convert(word) + 'a' * i)print(' '.join(convert_words))
########## code end ##########代码效果


有趣的代码需要多加练习!