一、预训练语言模型概述
预训练语言模型在自然语言处理领域占据着至关重要的地位。它以其卓越的语言理解和生成能力,成为众多自然语言处理任务的关键工具。
预训练语言模型的发展历程丰富而曲折。从早期的神经网络语言模型开始,逐渐发展到如今的大规模预训练语言模型。例如,Bengio 等人开发的最早期的神经语言模型(NLMs),可以与传统的 n-gram 模型相媲美。随后,Mikolov 发布了 RNNLM,极大地推广了 NLMs 的应用。基于循环神经网络(RNN)及其变体,如长短期记忆网络(LSTM)和门控循环单元(GRU)的 NLMs,被广泛应用于多种自然语言处理任务。
Transformer 架构的发明为预训练语言模型带来了重大突破。它通过自注意力机制,解决了 RNN 在并行化处理上的限制,显著提升了模型处理大规模数据集的能力。基于 Transformer 的预训练语言模型可以分为仅编码器、仅解码器和编码器 - 解码器模型三大类。
在应用场景方面,预训练语言模型广泛应用于自然语言处理的各个领域。例如在文本生成中,能够生成高质量的文章、对话和摘要等内容。在机器翻译领域,为翻译系统提供更准确的语义表示,改善翻译质量。在词义消歧、命名实体识别和情感分析等任务中也发挥着重要作用。
总之,预训练语言模型的发展标志着自然语言处理领域的重大进步,为人们提供了更加智能、准确和个性化的语言交互体验。
二、主要预训练语言模型

(一)ELMO
1. 模型原理介绍
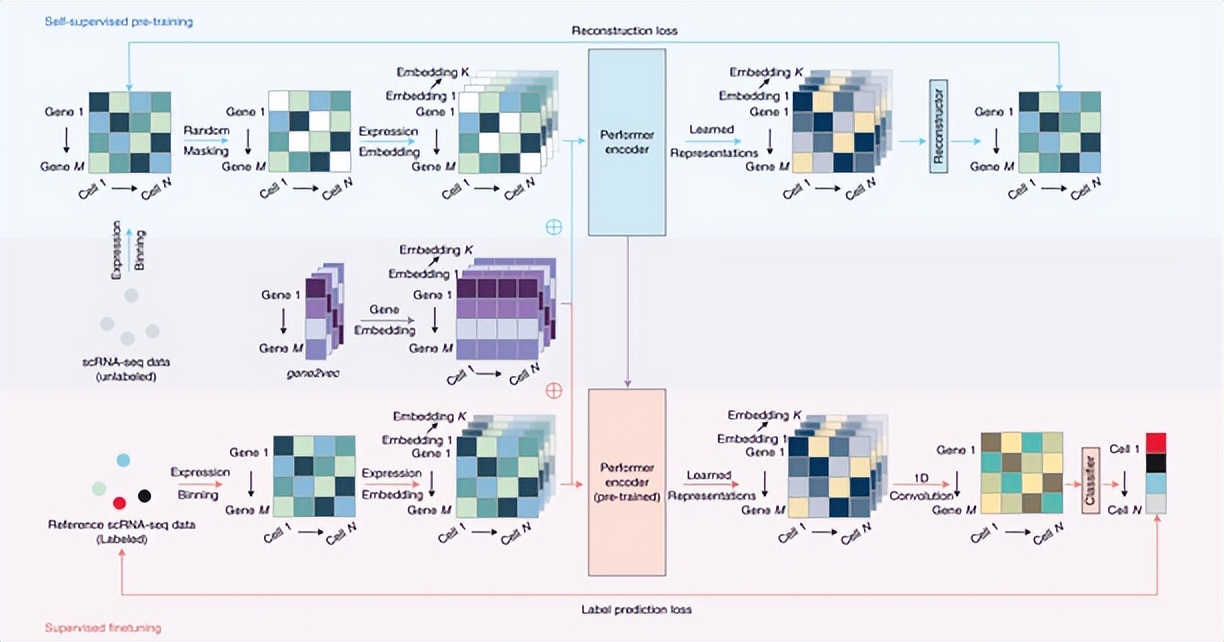
ELMo(Embeddings from Language Models)基于双向 LSTM 语言模型。它由一个前向和一个后向语言模型构成,经过一层 softmax 归一,来预测词。目标函数就是取这两个方向语言模型的最大似然。对于前向语言模型,假如要计算里面的 ,当得到 时刻的 ,与上下文矩阵 相乘,再经过 softmax 归一化得到下一个词的概率分布。ELMo 在预训练好这个语言模型之后,是把这个双向语言模型的每一中间层进行一个求和来用作词表示,还可以为每层向量加一个权重,再乘以一个权重 。
2. 特点阐述
ELMO 的特点显著。首先,它具有动态词向量,即根据当前上下文环境来产生当前词向量,而不是一个固定的外部词向量。其次,能够捕捉上下文相关的语义和语法信息,低层的 bi-LSTM 层能提取语料中的句法信息,高层的 bi-LSTM 能提取语料中的语义信息。再者,它具有层次化表示,为每个词提供一个多层的输出,下游模型可以学习这多层输出的组合。
(二)GPT
1. 优势分析
GPT(Generative Pre-trained Transformer)具有众多优势。其一,极高的语言生成能力,拥有数亿个参数和多层的神经网络结构,可以处理超过数十亿级别的语料库数据,能根据给定的上下文信息生成质量很高的语句,甚至可以生成完整的文章、故事等长文本,和人类写作风格非常接近。其二,自训练提升能力,采用自监督学习的方式进行预训练,可以利用大量的文本语料库进行训练,随着训练的深入,语言生成质量也将不断提升。其三,广泛的应用场景,在智能客服、智能翻译、自动摘要、文本生成等领域都能发挥巨大作用。
2. 缺点提及
然而,GPT 也存在一些缺点。首先,训练和部署成本高,需要强大的计算资源和训练数据,不适合小型公司或个人使用。其次,存在偏见和误解,由于是基于大数据训练的,有可能会存在偏见和误解,不能完全避免这些问题。最后,安全性问题,GPT 可以生成高度逼真的虚假信息和恶意内容,存在安全隐患。
(三)BERT
1. 模型原理讲解
BERT 是一种基于 Transformer 架构的双向编码模型。其核心结构是 Transformer,主要包括编码器部分,由多头自注意力机制、前馈神经网络和残差连接等组件构成。BERT 的预训练任务有两个,一是掩码语言模型(MLM),在输入的文本中,随机地遮盖或替换一部分词汇,并要求模型预测这些被遮盖或替换的词汇的原始内容;二是下一句预测(NSP),判断两个句子是否连续。
2. 在 AI 写作中的应用介绍
BERT 在 AI 写作中有广泛的应用。在文本分类方面,通过微调 BERT,可以实现高精度的文本分类任务。在信息检索中,利用 BERT 的强大语义理解能力,可以大幅提升文档检索的准确性。情感分析方面,BERT 通过微调,可以精确地分析用户评论、社交媒体帖子等文本的情感。问答系统中,通过微调 SQuAD 数据集,BERT 可以实现高效的问答功能。在文本生成方面,虽然 BERT 主要用于理解任务,但也可以通过变体如 GPT-2、GPT-3 进行文本生成任务。
三、预训练语言模型的优势

预训练语言模型具有诸多显著优势。
首先,在海量文本中通过预训练可以学习到一种通用语言表示,有助于完成下游任务。深度神经网络模型通常包含大量参数,而大部分 NLP 任务的标注成本高昂,构建大规模标注数据集困难。相比之下,大规模无标注数据集相对易于构建。预训练语言模型能够从这些无标注数据中学习通用语言表示,为各种下游任务提供有力支持。例如,在文本生成任务中,预训练语言模型可以利用通用语言表示生成高质量的文章、对话和摘要等内容。
其次,预训练可提供更好的模型初始化,从而具有更好的泛化性并在下游任务上更快收敛。许多研究表明,在大规模无标注语料中训练的预训练语言模型得到的表示可以使许多 NLP 任务获得显著的性能提升。这是因为预训练模型在大规模数据上学习到了丰富的语言知识和模式,为下游任务提供了一个良好的起点。例如,在机器翻译领域,基于预训练语言模型的翻译系统能够更快地收敛到较好的性能,并且在不同语言对之间具有更好的泛化能力。
最后,预训练可被看作是在小数据集上避免过拟合的一种正则化方法。当数据集较小时,模型容易过拟合,泛化能力较差。预训练语言模型通过在大规模数据上进行预训练,学习到通用的语言特征和模式,从而在小数据集上进行微调时能够更好地避免过拟合。例如,在命名实体识别任务中,当训练数据有限时,使用预训练语言模型可以显著提高模型的性能和泛化能力。
综上所述,预训练语言模型的优势在于通用语言表示、更好的模型初始化和正则化防过拟合等方面,为自然语言处理任务提供了强大的支持。
四、未来展望
(一)未来发展趋势
- 规模的不断扩大:目前,许多顶尖的预训练语言模型如 GPT-3 和 BERT 都是基于数十亿甚至上百亿的参数构建而成。未来,预训练语言模型将在更大规模的模型上进行探索。根据算力、数据量、模型规模之间关系的 scaling law,目前预训练语言模型的性能提升还没有触及天花板。这种规模的扩大将使模型能够捕捉更多的语言模式,进一步提升语言理解和生成能力。
- 语言与多模态融合:预训练语言模型将更加注重语言与多模态信息的融合。多模态预训练模拟了人类理解物理世界的多模态过程,将大语言模型比作机器的大脑,多模态则为其提供了感知物理世界的眼睛和耳朵,可以极大扩展机器的感知和理解范围。例如,通过融合图像与文本信息,预训练语言模型可以更好地理解图像背后的语义,为图像描述生成等任务提供更准确的结果。
- 领域专业化与个性化:未来,预训练语言模型可能会向更多领域进行专业化,针对特定领域的数据和任务进行优化。例如,在医疗领域,预训练语言模型可以学习医学文献和病历数据,为疾病诊断和治疗提供支持。同时,模型还可能朝着个性化方向发展,根据用户的需求和偏好进行定制,提供更加个性化的输出。
- 深化对常识的理解:虽然当前的预训练语言模型在某些任务上表现出色,但它们在理解常识和推理方面的能力仍然有限。未来的发展趋势将会集中在深化对常识的理解和推理能力上,使得模型能够更好地理解上下文、进行逻辑推理,并在更广泛的任务中展现出更强的智能。例如,在问答系统中,模型能够更好地理解问题的含义,结合常识进行推理,给出更准确的答案。
- 可解释性与透明度:随着预训练语言模型变得越来越复杂,人们对于模型的可解释性和透明度的需求也越来越迫切。未来的发展将会集中在研究如何使模型的决策过程更加可解释,帮助人们理解模型是如何做出预测和决策的,从而增强人们对模型的信任。例如,通过可视化技术展示模型的内部结构和决策过程,让用户更好地理解模型的工作原理。
(二)面临的挑战
- 计算资源的需求:大规模预训练语言模型需要大量的计算资源进行训练,这对于许多研究者和企业来说是难以承受的负担。例如,训练一个拥有数十亿参数的模型可能需要数百台高性能服务器和大量的时间。
- 数据隐私问题:预训练语言模型通常需要大量的训练数据,这可能导致数据隐私和安全问题。特别是在处理敏感数据时,如医疗记录和金融数据,数据隐私问题更加突出。
- 模型泛化能力:虽然预训练语言模型在许多任务上表现出色,但它们在一些特定领域的任务上可能表现不佳,需要进一步提高泛化能力。例如,在一些专业领域的文本处理任务中,模型可能无法准确理解专业术语和特定的语言表达方式。
- 可解释性难题:预训练语言模型的内部工作原理很复杂,很难为人们提供直观的解释,这可能导致模型的可信度受到质疑。例如,在一些关键决策场景中,用户可能需要了解模型的决策依据,而目前的预训练语言模型很难满足这一需求。
(三)解决方案
- 优化训练算法和硬件架构:研究人员可以通过优化训练算法和硬件架构来降低预训练语言模型的计算资源需求。例如,采用分布式训练技术,将模型训练任务分配到多台服务器上,提高训练效率。同时,开发新的硬件架构,如专用的人工智能芯片,以提高计算性能。
- 加强数据隐私保护:为了解决数据隐私问题,可以采用联邦学习等技术,使模型能够在分布式数据上进行训练,同时不泄露敏感信息。此外,还可以通过加密技术和数据匿名化等方法,保护训练数据的隐私。
- 提高模型的泛化能力:为了提高预训练语言模型的泛化能力,可以采用多任务学习、迁移学习等技术,让模型在不同的任务和领域中学习通用的语言知识和模式。同时,还可以通过增加训练数据的多样性和质量,提高模型的泛化能力。
- 提高模型的可解释性:为了提高预训练语言模型的可解释性,可以采用可视化技术、解释性学习等方法,让用户更好地理解模型的内部结构和决策过程。例如,通过可视化技术展示模型的注意力机制,让用户了解模型在处理文本时关注的重点区域。同时,还可以通过解释性学习方法,让模型自动生成对其预测结果的解释,提高模型的可信度。
五、经典代码案例
在编程语言领域,有许多代码量少但很牛很经典的算法或项目案例,这些案例为我们理解和应用编程技术提供了很好的参考。
(一)Python 经典代码案例
- Hello World 实例:
- 代码:
print('Hello World!') - 这是 Python 中最基础的代码案例,输出 “Hello World!”。
- 数字求和:
- 代码:
num1 = input('输入第一个数字:')num2 = input('输入第二个数字:')sum = float(num1) + float(num2)print('数字 {0} 和 {1} 相加结果为:{2}'.format(num1, num2, sum))- 用户输入两个数字,程序计算并输出它们的和。
- 平方根计算:
- 代码:
num = float(input('请输入一个数字:'))num_sqrt = num ** 0.5print(' %0.3f 的平方根为 %0.3f'%(num,num_sqrt))- 输入一个数字,计算并输出其平方根。
- 二次方程求解:
- 代码:
import cmath
a = float(input('输入 a: '))
b = float(input('输入 b: '))
c = float(input('输入 c: '))
d = (b**2) - (4*a*c)
sol1 = (-b-cmath.sqrt(d))/(2*a)
sol2 = (-b+cmath.sqrt(d))/(2*a)
print('结果为 {0} 和 {1}'.format(sol1,sol2))
- 输入二次方程的系数,求解方程的根。
- 三角形面积计算:
- 代码:
a = float(input('输入三角形第一边长: '))
b = float(input('输入三角形第二边长: '))
c = float(input('输入三角形第三边长: '))
s = (a + b + c) / 2
area = (s*(s-a)*(s-b)*(s-c)) ** 0.5
print('三角形面积为 %0.2f' %area)
- 用户输入三角形的三边长,程序计算并输出三角形的面积。
- 圆的面积计算:
- 代码:
def findArea(r):
PI = 3.142
return PI * (r*r)
print("圆的面积为 %.6f" % findArea(5))
- 定义一个方法计算圆的面积,输入半径,输出圆的面积。
- 随机数生成:
- 代码:
import random
print(random.randint(0,9))
- 生成 0 到 9 之间的随机数。
- 摄氏温度转华氏温度:
- 代码:
celsius = float(input('输入摄氏温度: '))
fahrenheit = (celsius * 1.8) + 32
print('%0.1f 摄氏温度转为华氏温度为 %0.1f ' %(celsius,fahrenheit))
- 用户输入摄氏温度,程序计算并输出华氏温度。
- 交换变量:
- 代码:
x = input('输入 x 值: ')
y = input('输入 y 值: ')
x,y = y,x
print('交换后 x 的值为: {}'.format(x))
print('交换后 y 的值为: {}'.format(y))
- 用户输入两个值,程序不使用临时变量交换这两个值。
- 判断字符串是否为数字:
-
- 相关库:可使用isnumeric()方法判断字符串是否为数字。
-
- 例如:s = "12345",s.isnumeric()返回True。
- 判断奇数偶数:
- 代码:
num = int(input("输入一个数字: "))
if (num % 2) == 0:
print("{0} 是偶数".format(num))
else:
print("{0} 是奇数".format(num))
- 用户输入一个数字,程序判断其是奇数还是偶数。
- 判断闰年:
- 代码:
year = int(input("输入一个年份: "))
if (year % 4 == 0 and year % 100!= 0) or (year % 400 == 0):
print("{0} 是闰年".format(year))
else:
print("{0} 不是闰年".format(year))
- 用户输入一个年份,程序判断其是否为闰年。
- 获取最大值函数:
- 代码:
def find_max(*args):
if not args:
return None
max_value = args[0]
for item in args:
if item > max_value:
max_value = item
return max_value
print(find_max(1, 2, 3, 4, 5))
- 定义一个函数,接受任意数量的参数,返回其中的最大值。
- 质数判断:
- 代码:
num = int(input("输入一个正整数: "))
if num < 2:
print("{0} 不是质数".format(num))
else:
for i in range(2, int(num**0.5)+1):
if num % i == 0:
print("{0} 不是质数".format(num))
break
else:
print("{0} 是质数".format(num))
- 用户输入一个正整数,程序判断其是否为质数。
- 输出指定范围内的素数:
- 代码:
lower = int(input("输入范围下限: "))
upper = int(input("输入范围上限: "))
for num in range(lower, upper + 1):
if num > 1:
for i in range(2, num):
if (num % i) == 0:
break
else:
print(num)
- 用户输入一个范围,程序输出该范围内的素数。
- 阶乘实例:
- 代码:
num = int(input("请输入一个数字: "))
factorial = 1
if num < 0:
print("抱歉,负数没有阶乘")
elif num == 0:
print("0 的阶乘为 1")
else:
for i in range(1,num + 1):
factorial = factorial*i
print("%d 的阶乘为 %d" %(num,factorial))
- 用户输入一个数字,程序计算并输出其阶乘。
- 九九乘法表:
- 代码:
for i in range(1, 10):
for j in range(1, i + 1):
print(f'{j}*{i}={i*j}\t', end='')
print()
- 输出九九乘法表。
- 斐波那契数列:
- 代码:
nterms = int(input("你需要几项?"))
n1, n2 = 0, 1
count = 0
if nterms <= 0:
print("请输入一个正整数。")
elif nterms == 1:
print("斐波那契数列:")
print(n1)
else:
print("斐波那契数列:")
while count < nterms:
print(n1)
nth = n1 + n2
n1 = n2
n2 = nth
count += 1
- 用户输入需要的项数,程序输出相应的斐波那契数列。
(二)C 语言经典代码案例
- 逆序输出字符串:
- 代码:
#include <stdio.h>#include <string.h>void reverse_string(char* str){int i, length = strlen(str);for(i = length - 1; i >= 0; i--){printf("%c", str[i]);}}int main(){char str[]="Hello, World!";reverse_string(str);return 0;}- 通过遍历字符数组,实现字符串的逆序输出。
- 求解一元二次方程:
- 代码:
#include <stdio.h>#include <math.h>void quadratic_solver(double a, double b, double c){double delta = b * b - 4 * a * c;if(delta > 0){double x1 = (-b + sqrt(delta))/(2 * a);double x2 = (-b - sqrt(delta))/(2 * a);printf("Two real roots: x1 = %lf, x2 = %lf\n", x1, x2);}else if(delta == 0){double x = -b / (2 * a);printf("One real root: x = %lf\n", x);}else{printf("No real roots.\n");}}int main(){double a = 1, b = -3, c = 2;quadratic_solver(a, b, c);return 0;}- 根据输入的一元二次方程的系数,求解方程的根。
- 找出数组中的最大值和最小值:
- 代码:
#include <stdio.h>
void find_max_min(int arr[], int size, int* max, int* min){
*max = arr[0];
*min = arr[0];
for(int i = 1; i < size; i++){
if(arr[i]>*max){
*max = arr[i];
}
if(arr[i]<*min){
*min = arr[i];
}
}
}
int main(){
int arr[]={2,5,8,1,0,-3,12};
int max, min;
int size = sizeof(arr)/sizeof(arr[0]);
find_max_min(arr, size, &max, &min);
printf("Max: %d, Min: %d\n", max, min);
return 0;
}
- 遍历数组,找出其中的最大值和最小值。
- 计算阶乘:
- 代码:
#include <stdio.h>
unsigned long long factorial(int n){
if(n == 0){
return 1;
}else{
return n * factorial(n - 1);
}
}
int main(){
int n = 10;
printf("%d! = %llu\n", n, factorial(n));
return 0;
}
- 使用递归函数计算给定数字的阶乘。
- 斐波那契数列:
- 代码:
#include <stdio.h>
int fibonacci(int n){
if(n <= 1){
return n;
}else{
return fibonacci(n - 1)+fibonacci(n - 2);
}
}
int main(){
int n = 10;
printf("The %dth Fibonacci number is: %d\n", n, fibonacci(n));
return 0;
}
- 通过递归方式计算斐波那契数列的第 n 项。
- 字符串拼接:
- 代码:
#include <stdio.h>
#include <string.h>
void string_concat(char* dest, const char* src){
int dest_len = strlen(dest);
int src_len = strlen(src);
for(int i = 0; i <= src_len; i++){
dest[dest_len + i]= src[i];
}
}
int main(){
char dest[50]="Hello, ";
const char* src = "World!";
string_concat(dest, src);
printf("Concatenated string: %s\n", dest);
return 0;
}
- 将两个字符串拼接在一起。
- 二分查找:
- 代码:
#include <stdio.h>
int binary_search(int arr[], int size, int target){
int left = 0, right = size - 1;
while(left <= right){
int mid = left + (right - left)/2;
if(arr[mid]== target){
return mid;
}else if(arr[mid]< target){
left = mid + 1;
}else{
right = mid - 1;
}
}
return -1;
}
int main(){
int arr[]={1,3,5,7,9,11,13};
int target = 7;
int size = sizeof(arr)/sizeof(arr[0]);
int index = binary_search(arr, size, target);
printf("Index of %d is: %d\n", target, index);
return 0;
}
- 在已排序的数组中使用二分查找算法查找目标元素。
- 动态内存分配:
- 代码:
#include <stdio.h>
#include <stdlib.h>
int main(){
int n = 5;
int* arr = (int*)malloc(n * sizeof(int));
if(arr == NULL){
printf("Memory allocation failed.\n");
return 1;
}
for(int i = 0; i < n; i++){
arr[i]= i * 2;
}
printf("Dynamic array: ");
for(int i = 0; i < n; i++){
printf("%d ", arr[i]);
}
printf("\n");
free(arr);
return 0;
}
- 使用动态内存分配函数实现动态数组。
(三)Java 经典代码案例
- 慎用异常:
- 代码:
import org.junit.Test;public class TestCode {@Testpublic void test11() {long start = System.currentTimeMillis();int a = 0;for(int i=0;i<1000000000;i++){try {a++;}catch (Exception e){e.printStackTrace();}}long useTime = System.currentTimeMillis()-start;System.out.println("useTime:"+useTime);}@Testpublic void test() {long start = System.currentTimeMillis();int a = 0;try {for (int i=0;i<1000000000;i++){a++;}}catch (Exception e){e.printStackTrace();}long useTime = System.currentTimeMillis()-start;System.out.println(useTime);}}- 展示了在循环体内和循环体外使用 try-catch 语句对性能的影响。
- 使用局部变量:
- 代码:
import org.junit.Test;
public class TestCode {
@Test
public void test11() {
long start = System.currentTimeMillis();
int a = 0;
for(int i=0;i<1000000000;i++){
a++;
}
long useTime = System.currentTimeMillis()-start;
System.out.println("useTime:"+useTime);
}
static int aa = 0;
@Test
public void test() {
long start = System.currentTimeMillis();
for (int i=0;i<1000000000;i++){
aa++;
}
long useTime = System.currentTimeMillis()-start;
System.out.println("useTime:"+useTime);
}
}
- 对比了使用局部变量和类的静态变量的访问速度。
- 位运算代替乘除法:
- 代码:
import org.junit.Test;
public class TestCode {
@Test
public void test11() {
long start = System.currentTimeMillis();
int a = 0;
for(int i=0;i<1000000000;i++){
## 六、文章总结
![need_search_image_by_title]()
预训练语言模型作为自然语言处理领域的重要工具,其发展历程丰富且充满变革。从早期的神经网络语言模型到如今大规模的预训练语言模型,如 ELMO、GPT 和 BERT 等,它们在自然语言处理的各个任务中发挥着关键作用。
ELMO 基于双向 LSTM 语言模型,具有动态词向量、能捕捉上下文相关信息以及层次化表示等特点。GPT 拥有极高的语言生成能力、自训练提升能力和广泛的应用场景,但也存在训练和部署成本高、可能存在偏见和误解以及安全性问题等缺点。BERT 是基于 Transformer 架构的双向编码模型,在文本分类、信息检索、情感分析和问答系统等方面有着广泛应用。
预训练语言模型具有诸多优势,如能在海量文本中学习通用语言表示、提供更好的模型初始化以及作为正则化方法避免过拟合。然而,未来的发展也面临着一些挑战,包括计算资源需求大、数据隐私问题、模型泛化能力有待提高以及可解释性难题等。针对这些挑战,可以通过优化训练算法和硬件架构、加强数据隐私保护、提高模型泛化能力以及提高模型可解释性等方法来解决。
未来,预训练语言模型的发展趋势包括规模的不断扩大、语言与多模态融合、领域专业化与个性化、深化对常识的理解以及提高可解释性与透明度。同时,文章还介绍了 Python、C 语言和 Java 等编程语言中的经典代码案例,为读者更好地理解和应用编程技术提供了参考。
总之,预训练语言模型在自然语言处理领域的重要性日益凸显,其未来的发展前景广阔,值得我们持续关注和深入研究。
## 七、学习资源分享
![need_search_image_by_title]()
### (一)在线课程平台
1. Coursera:提供来自世界顶尖大学和机构的自然语言处理课程,其中不乏关于预训练语言模型的专业课程。例如,某大学的《自然语言处理导论》课程,详细介绍了预训练语言模型的发展历程、原理和应用,通过实际案例和项目实践帮助学习者深入理解这一领域的知识。
2. edX:与全球知名高校合作,推出了一系列高质量的自然语言处理课程。其中,有课程专门针对预训练语言模型进行深入讲解,包括模型的架构、训练方法以及在不同任务中的应用。
3. 网易云课堂:国内知名的在线学习平台,有许多关于自然语言处理和预训练语言模型的课程。这些课程由行业专家授课,内容涵盖从基础知识到实际应用的各个方面,适合不同层次的学习者。
### (二)学术论文数据库
1. arXiv:一个广泛使用的预印本学术论文数据库,涵盖了自然语言处理领域的最新研究成果。在 arXiv 上,可以找到大量关于预训练语言模型的论文,包括新模型的提出、改进和应用等方面的研究。
2. ACL Anthology:计算语言学协会(ACL)的论文集,收录了该领域的重要学术论文。其中,有许多关于预训练语言模型的研究论文,为学习者提供了深入了解该领域的学术资源。
3. IEEE Xplore:电气电子工程师学会(IEEE)的数字图书馆,包含了广泛的学术文献。在 IEEE Xplore 上,可以找到与自然语言处理和预训练语言模型相关的论文,涵盖了从理论研究到实际应用的各个方面。
### (三)开源代码库
1. GitHub:全球最大的开源代码托管平台,有许多关于预训练语言模型的开源项目。例如,Hugging Face 的 Transformers 库,提供了丰富的预训练语言模型实现,包括 BERT、GPT 等。学习者可以通过研究这些开源项目,深入了解预训练语言模型的实现细节和应用方法。
2. TensorFlow Hub:由 Google 推出的开源代码库,提供了各种预训练的机器学习模型,包括自然语言处理模型。在 TensorFlow Hub 上,可以找到预训练的语言模型,以及使用这些模型的示例代码,方便学习者快速上手。
3. PyTorch Hub:PyTorch 的开源代码库,也提供了一些预训练的语言模型。与 TensorFlow Hub 类似,PyTorch Hub 为学习者提供了方便的接口,可以快速加载和使用预训练语言模型。
### (四)技术博客和论坛
1. Medium:一个流行的技术博客平台,有许多关于自然语言处理和预训练语言模型的优质文章。这些文章由行业专家和研究者撰写,内容涵盖了最新的研究成果、实践经验和技术趋势,为学习者提供了丰富的学习资源。
2. Reddit 的 r/MachineLearning 子论坛:一个活跃的机器学习社区,有许多关于预训练语言模型的讨论和分享。在这个论坛上,学习者可以与其他机器学习爱好者交流经验、提问问题,获取最新的技术信息。
3. Stack Overflow:一个广泛使用的技术问答平台,有许多关于自然语言处理和预训练语言模型的问题和解答。在 Stack Overflow 上,学习者可以找到解决实际问题的方法,同时也可以通过回答问题来加深自己对知识的理解。
六、文章总结
在本文中,我们深入探讨了预训练语言模型这一自然语言处理领域的关键技术,包括其原理、优势以及在 AI 写作中的应用。
(一)预训练语言模型概述
预训练语言模型已成为现代自然语言处理的核心,它改变了传统语言模型训练的方式。从早期简单的语言模型发展至今,经历了多次技术革新和突破。这些模型在多种自然语言处理任务中展现出卓越的性能,其应用场景涵盖了从文本生成、信息检索到情感分析等众多领域,极大地推动了自然语言处理技术的发展,使得计算机能够更好地理解和处理人类语言。
(二)主要预训练语言模型
- ELMO:基于双向 LSTM 语言模型构建,其独特的前向和后向语言模型相结合的方式,为我们带来了动态词向量。这种词向量能够依据上下文环境动态调整,有效地捕捉到丰富的语义和语法信息。ELMO 的层次化表示能力,使得它在处理复杂语言结构时更具优势,能够更好地理解文本中的多层次含义,为后续的自然语言处理任务提供更准确的信息。
- GPT:作为一种强大的预训练语言模型,它在语言生成方面展现出了极高的天赋。通过不断地自训练,GPT 能够持续提升自身能力,在各种文本生成任务中表现出色。然而,它也并非完美无缺,其高昂的训练和部署成本限制了它的广泛应用。此外,存在的偏见和误解问题可能会导致生成的内容出现偏差,同时安全性问题也需要引起重视,以防止模型被恶意利用。
- BERT:利用 Transformer 架构的双向编码模型在自然语言处理领域掀起了新的浪潮。其复杂而精巧的模型结构和精心设计的预训练任务,使得 BERT 在处理文本时能够同时考虑上下文信息,从而获得更准确的语义理解。在 AI 写作相关的各种应用场景中,如文本分类、信息检索、情感分析、问答系统和文本生成等方面,BERT 都发挥了重要作用,大大提高了这些任务的准确性和效率。
(三)预训练语言模型的优势
预训练语言模型具有诸多显著优势。其通用语言表示能力使得模型可以在多种自然语言处理任务中无需大规模重新训练即可表现良好。这种通用表示就像是一种语言知识的预存储,模型可以根据具体任务进行微调。同时,更好的模型初始化方式减少了训练时间和资源消耗,并且在一定程度上防止了过拟合问题的出现,使得模型在新数据上的泛化能力更强。这些优势共同作用,使得预训练语言模型在自然语言处理领域中成为不可或缺的工具。
(四)未来展望
展望未来,预训练语言模型仍有广阔的发展前景。随着技术的不断进步,我们可以期待模型在性能上的进一步提升,例如更准确的语义理解、更自然的语言生成等。然而,与此同时,我们也面临着一系列挑战,如模型偏见的消除、安全性的加强以及如何在资源有限的情况下进行更高效的训练等。解决这些问题需要研究人员在算法改进、数据处理和伦理规范等多个方面共同努力,以确保预训练语言模型能够持续健康地发展,为自然语言处理和 AI 写作等领域带来更多的突破和创新,推动人机交互向更自然、更智能的方向发展。

七、学习资源分享
以下是一些关于预训练语言模型的学习资源分享:
书籍
- 《Speech and Language Processing》:由 Daniel Jurafsky、James H. Martin 等人编写,是自然语言处理领域的经典综述教材。涵盖了自然语言处理的所有基础知识,写作风格引人入胜,深入技术细节又不让人感觉枯燥,可作为高等学校相关课程的教材,也是研究人员和技术人员的权威参考书 。
- 《Foundations of Statistical Natural Language Processing》:作者是 Christopher Manning 和 Hinrich Schütze。内容广泛,从数学基础到理论算法,从词法分析到语法分析均有涉及,适合不同水平的读者,能够帮助初学者快速了解自然语言处理的基本概念和任务 。
- 《Neural Network Methods in Natural Language Processing》:Yoav Goldberg 所著,着重介绍神经网络模型在自然语言数据中的应用,包括有监督的机器学习和前馈神经网络的基础知识,以及多种专门的神经网络体系结构,如一维卷积神经网络、递归神经网络等,对理解预训练语言模型的基础架构和技术有很大帮助 。
- 《Python 自然语言处理》:Steven Bird、Ewan Klein、Edward Loper 编写,教你如何用 Python 和 NLTK 库来做自然语言处理,提供了非常易学的入门介绍,涉及语料库操作、传统基于规则的方法,以及分词、词性标注、句法剖析与语义剖析等方面,实用性较强.
- 《自然语言处理综述》:全面系统地描述了自然语言处理领域的各个任务以及常用模型,第三版加入了近几年神经网络方法,是一本极全面的自然语言处理书籍,对了解预训练语言模型的发展背景和相关技术有重要参考价值.
在线课程
- CS224d: Deep Learning for Natural Language Processing:斯坦福大学自然语言小组开设的基于深度学习的自然语言处理课程,介绍了自然语言处理领域广泛应用的网络结构,如循环神经网络、卷积神经网络以及递归神经网络等,及其在自然语言处理的经典任务中的实际应用,适合初学者.
- Oxford Deep Learning for NLP Class:由 DeepMind 团队成员在牛津大学教授的基于深度学习的自然语言处理课程,内容涉及词嵌入、基于循环神经网络的语言模型、基于循环神经网络和卷积神经网络的文本分类等,以及其中的注意力机制和基于深度学习模型的自动问答等.
- UFLDL Tutorial:由 Andrew Ng 等人主讲的斯坦福早期的深度学习教程,例如讲解如何使用栈式自编码器构建深度前馈神经网络,内容精短,易于早期入门,可帮助快速上手深度学习基础.
- deeplearning.ai:近期开设的深度学习公开课,通俗易懂,适合入门,能够系统地学习深度学习的基础知识和常见技术.
学术博客
- Google AI Blog:谷歌 AI 官网博客,会介绍谷歌团队在自然语言处理等 AI 领域的最新工作和研究成果,有助于了解行业前沿动态.
- 我爱自然语言处理(52nlp):国内的自然语言处理专业博客,有丰富的 NLP 相关资源,包括技术文章、学习资料、工具介绍等,适合国内读者学习和交流.
- Sebastian Ruder:NLP 学者 Sebastian Ruder 的个人博客,他会撰写一些技术博客和参加顶会的感想总结,其整理的 nlp-progress 项目,可帮助了解 NLP 各个任务的最新研究进展.
- Colah's Blog:虽然更新频率较低,但之前的一些博客内容很经典,如 “Understanding LSTM Networks” 等文章,对初学者理解神经网络有很大帮助.
学术论文检索网站
- Google Scholar:全球广泛使用的论文检索网站,可查看每篇论文的被引情况,还能通过设置直接导入文献管理工具,如 EndNote 等,也可建立个人主页,获取根据自身研究兴趣推荐的论文.
- DBLP:计算机学科的文献集成数据库系统,可根据作者、会议、期刊等分类找到相关文献,适合调研特定的期刊、会议、作者发表的自然语言处理相关文献.
- arXiv:收录科学文献预印本的在线数据库,科研工作者可发布未正式出版的论文用于同行交流,能让学习者及时了解自然语言处理领域的最新研究进展.
- ACL Anthology:收录计算语言学研究论文的数字档案,对所有人免费开放,包括 NLP 领域的杂志以及许多相关顶会的文献,如 ACL、EMNLP、NAACL、Coling 等,是获取高质量自然语言处理学术论文的重要资源.
代码资源
- GitHub - msgi/nlp-journey:整理了自然语言处理常见任务相关的文档、论文和代码,包括预训练模型、文本生成、文本分类等领域,所有代码都在 TensorFlow 2.0 中实现,方便读者学习和实践相关技术.
本文相关文章推荐:
AI 写作(一):开启创作新纪元(1/10)
AI写作(二)NLP:开启自然语言处理的奇妙之旅(2/10)
AI写作(三)文本生成算法:创新与突破(3/10)
AI写作(四)预训练语言模型:开启 AI 写作新时代(4/10)



![超子物联网HAL库笔记:定时器[外部模式]篇](https://i-blog.csdnimg.cn/direct/52b98acfc43443ecafcea9a5120d62a9.png)