一、大语言模型
自去年十一月份来,LLM(Large Language Model)如雨后春笋涌现。从最开始的ChatGPT到文心一言,现在已经有几十上百个LLM。而LLM本身还在继续发展,其应用场景也在不断发掘。现阶段如同AI的文艺复兴时期,LLM每天都在推出各种新的应用,关于AGI(通用人工智能)的设想也越发接近可能。
本文我们将讨论Prompt技巧、模型Fine-tuning等内容,并完成LLM的二次开发,将LLM接入应用。
二、文心千帆
现在有许多大模型平台,可以直接调用API的有ChatGPT、Claude、文心千帆等。相比之下文心千帆的接口更易获得,因此本文选择文心千帆。
2.1 平台介绍
文心千帆大模型平台是百度智能云推出的全球首个一站式企业级大模型平台,为企业提供大模型训练及推理的全流程工具链和整套环境,让企业以最简单最高效的方式用上大模型、用好大模型。在文心千帆上,企业不但可以直接调用文心一言服务,也可以开发、部署和调用自己的大模型服务,是企业拥抱大模型的最佳选择。
简单来说就是文心一言是提供给普通用户的应用,而文心千帆则是提供了企业开发者的开发平台。在平台中内置了从数据集构建、数据标注、数据处理、模型训练、模型部署整个流程的功能。同时提供了Prompt模板、插件、在线测试、WebAPI等功能。使用文心千帆可以构建各种复杂应用,并可以根据企业自身需求对模型进行调优。
文心千帆大模型平台公有版测试服务(官方申请地址:https://cloud.baidu.com/survey/qianfan.html),读者可以自行申请。
申请通过后,可以进入控制台,创建应用。点击创建应用->填写信息、勾选服务->立即创建即可完成应用创建。创建完成后,进入创建的应用。
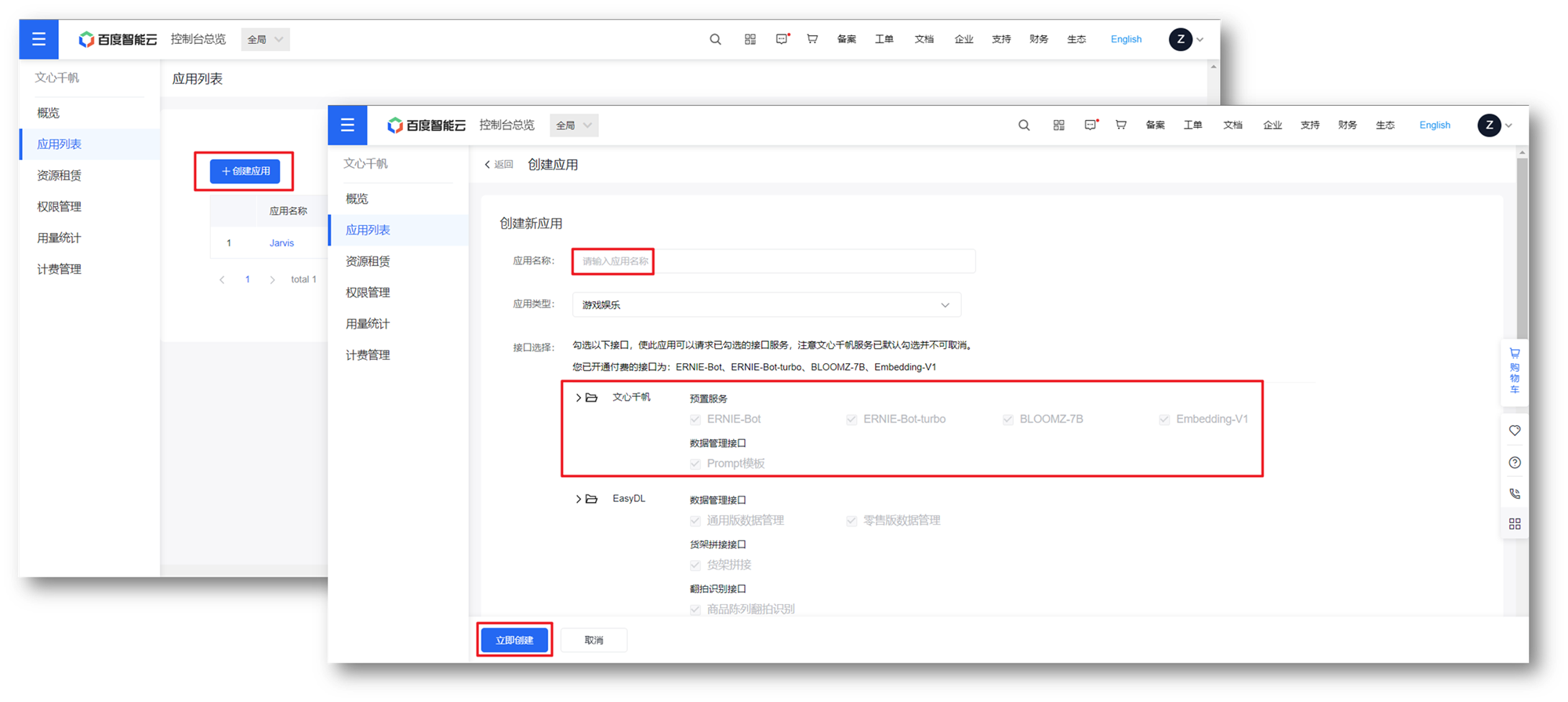
可以进入文心千帆大模型平台管理应用:https://ai.baidu.com/wenxinworkshop/app/ais/console/onlineTest
2.2 在线测试
进入平台后,选择左侧在线测试即可直接使用对应模型,这里需要选择对应应用以及具体服务,此处和创建应用时勾选的服务对应,本文使用ERNIE-Bot-turbo。

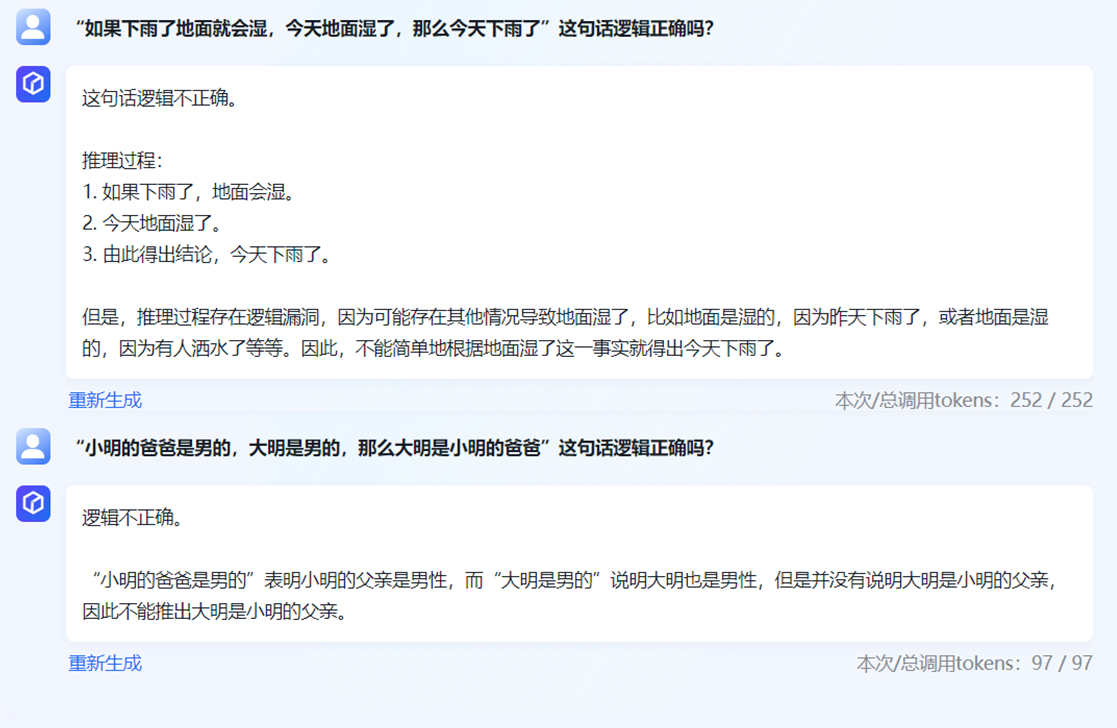
ERNIE-Bot-turbo具备强大的中文理解能力,具备多轮对话、逻辑推理、代码、艺术创作等能力。
这里测试一下文心千帆的逻辑推理能力,这里选择了几个典型的问题,回答效果整体还不错。文心千帆能够判断一个命题是否是逻辑自洽的,同时能够给出理由。比如“小明的爸爸是男的,大明是男的,那么大明是小明的爸爸”、“如果下雨了地面就会湿,今天地面湿了,那么今天下雨了”都是有明显逻辑错误的命题,下面是文心千帆的回答:
除了判断正误,还可以直接让它推理,比如下面的例子:
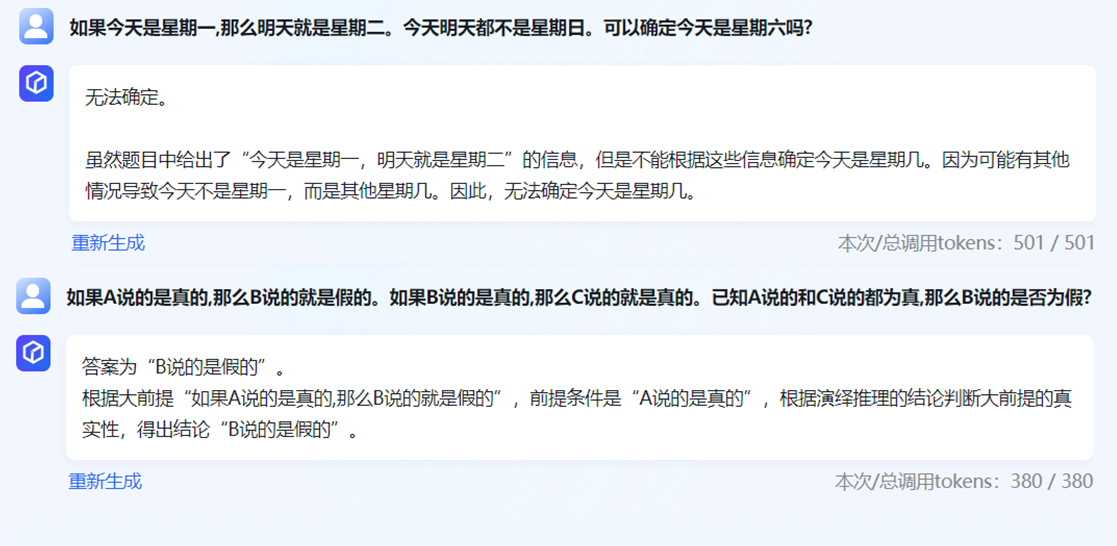
由于语言模型的回答具有概率性,在逻辑推理时并不能保证每次结果一样,甚至有时候会推理错误。读者可以自己具体体验一下。
三、应用接入LLM
文心千帆中提供了API接口,可以让我们在应用内接入大模型能力。API文档参考:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/flfmc9do2
当应用接入大模型后,相当于有了大脑。可以完成许多神奇的操作。
3.1 API接口
API提供了单论、多轮对话的访问方式,以ERNIE-Bot-turbo为例,下面是单轮访问的Python代码:
import requests
import jsonapikey = ""
secret_key = ""def get_access_token():url = f"https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={apikey}&client_secret={secret_key}"payload = json.dumps("")headers = {'Content-Type': 'application/json','Accept': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload)return response.json().get("access_token")def chat(prompt):url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/eb-instant?access_token=" + get_access_token()payload = json.dumps({"messages": [{"role": "user","content": prompt}]})headers = {'Content-Type': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload)return response.json()if __name__ == '__main__':chat("介绍一下你自己")
这里需要传入创建应用时对应的API Key,Secret Key。输出结果如下:
{"id":"as-ib219jgf9b","object":"chat.completion","created":1689750505,"result":"您好,我是文心一言,英文名是ERNIE Bot。我能够与人对话互动,回答问题,协助创作,高效便捷地帮助人们获取信息、知识和灵感。","is_truncated":false,"need_clear_history":false,"usage":{"prompt_tokens":7,"completion_tokens":49,"total_tokens":56}}
其余模型API的调用也是大同小异。
3.2 Prompt技巧
对于LLM来说,Prompt对结果的影响是非常大的,很多时候并非模型不具备某种能力,而是选取的Prompt不合适。因此我们还需要知道一些Prompt的书写技巧。
3.2.1 Prompt模板
对于LLM来说,许多Prompt是通用的,应对一类需求我们可以使用一个固定格式的Prompt来实现。在文心千帆中,提供了Prompt模板的功能,我们可以在下图位置创建模板。创建后可以在测试时直接使用该模板。一些通用的Prompt都可以添加到模板。

3.2.2 善用分隔
LLM具备非常强的语言能力,以往需要单独训练的NLP模型已经内置在LLM内了。比如情感分析、命名实体识别、语法分析、翻译等。
传统的模型都是输入输出模式,做情感分析,输入一句话,输出只能是“积极、消极、中性”。我们可以很确定在判断那一句话,但是对于LLM来说却不是这样的。比如:
我不开心。这句话是积极还是消极的?
上面的Prompt可以得到正确答案,但是并不总是奏效。如果我们使用明显的分割符则会减少误解,比如:
"我不开心。",引号中这句话是积极还是消极的?
在命名实体识别、文章摘要中尤其如此。
3.2.3 样本提示
样本提示是一种让模型玩文字接龙游戏的一种方式,其做法就是说半句话,让模型进行输出。比如:
任务:情感分析
句子:这部电影真的太好看了!
情感:
而我们预期的输出则是:
积极
另一种则是给一些已有例子,然后再让模型做文字接龙的Prompt,比如:
这部电影真好看 //positive
这部电影真难看 //negative
这部电影真不错 //positive
我很喜欢这部电影 //
此时我们预期的输出为:
positive
2.2.4 结构化输出
对话能力并不是在所有应用中都有实际用处,但是通过一些Prompt技巧,可以让LLM能够具备程序的确定性。可以理解为用自然语言完成编程操作。
对应一般的应用接口,其返回的数据是确定的json或xml,我们可以使用固定的程序来处理。而LLM返回的内容(回答)则是不确定的,是非结构化的,这种数据给程序带来不确定性,因此需要Prompt技巧。
比如我想完成一个通过自然语言操控电脑程序的代码,我们可以把所有操作归结为:
{"app": "chrome","action": "搜索","value": "文心千帆"
}
这种固定格式,比如”打开PyCharm“可以表示为:
{"app": "pycharm","action": "打开","value": "空"
}
现在我们要做的就是使用Prompt完成这一功能,具体如下:
``````分析三引号中内容,以json数据形式返回,包含app、action、value三个键。
app表示应用程序,action表示动作、操作,value表示时间、url、文件名等有意义的内容。
我们只需要在三引号内传入特定内容即可,比如:

现在我们要做的就是根据返回的json完成对电脑的操作。
3.3 接入应用
首先编写一个用于控制电脑的类,代码如下:
class Jarvis:def __init__(self):self.template = "```%s ```分析三引号中内容,以json数据形式返回,包含app、action、value三个键。app表示应用程序,action表示动作、操作,value表示时间、url、文件名等有意义的内容。"def search(self, app, value):os.system(f"{app} https://www.baidu.com/s?wd={value}")def open(self, app):os.system(f"{app}")def run(self):print("Ernie Bot: 你好先生,有什么需要帮助的吗?")while True:prompt = input("User: ")resp = chat(self.template % (prompt,))operation = json.loads(resp['result'].replace("`", "").replace("json", "").strip())print(operation)if __name__ == '__main__':jarvis = Jarvis()jarvis.run()
这里内置了搜索和打开应用的操作,只需创建Jarvis运行run即可。当输入“用chrome搜索海贼王”时,应用返回如下结果:
Ernie Bot: 你好先生,有什么需要帮助的吗?
User: 用chrome打开海贼王
{'app': '海贼王', 'action': '搜索', 'value': '海贼王'}
下面只需要根据返回结果调用指定函数即可,具体代码如下:
if operation['action'] == "搜索":self.search(operation['app'], operation['value'])
else:self.open(operation['app'])
不过这种做法有一些问题,即action可能不是搜索或打开。另外如果功能多需要编写比较复杂的if else语句,为了改进这点,可以对prompt进行一些修改。
class Jarvis:def __init__(self):self.actions = {"search": self.search,"open": self.open}self.template = "```%s ```分析三引号中内容,以json数据形式返回,包含app、action、value三个键。app表示应用程序,action表示动作、操作,value表示时间、url、文件名等有意义的内容。"self.template2 = f"""```%s ```分析三引号中内容,以json数据形式返回,必须包含app、action、value三个键,默认为未知。app表示应用程序,action表示动作,value表示时间、url、文件名等有意义的内容。且action只能是{",".join(self.actions.keys().__reversed__())}中的一个。"""....def run(self):print("Ernie Bot: 你好先生,有什么需要帮助的吗?")while True:prompt = input("User: ")resp = chat(self.template2 % (prompt,))operation = json.loads(resp['result'].replace("`", "").replace("json", "").strip())print(operation)self.actions[operation['action']](operation['app'],operation['value'])if __name__ == '__main__':jarvis = Jarvis()jarvis.run()
这里做了两个修改,第一个是prompt改为了:
self.template2 = f"""
```%s ```分析三引号中内容,以json数据形式返回,包含app、action、value三个键。
app表示应用程序,action表示动作、操作,value表示时间、url、文件名等有意义的内容。
且action只能是```{"、".join(self.actions.keys())} ```中的一个。
这样就可以保证不会出现不可预期的action,第二个则是用字典存储了所有功能,这样就减少了if else判断。修改后,使用”用chrome查找海贼王“、”用chrome找海贼王“、“用chrome搜海贼王”都可以正常工作。下面是运行效果:
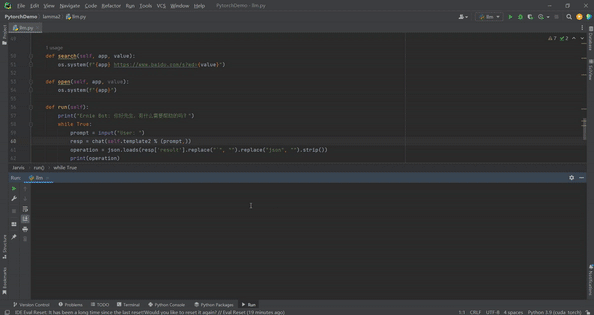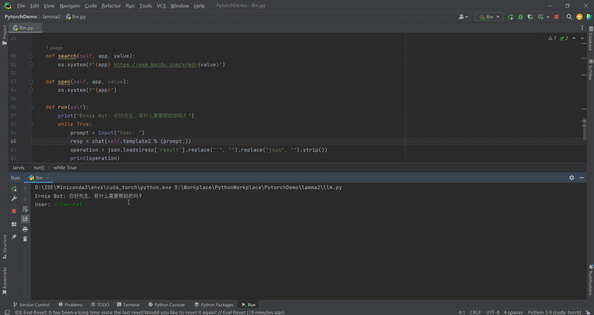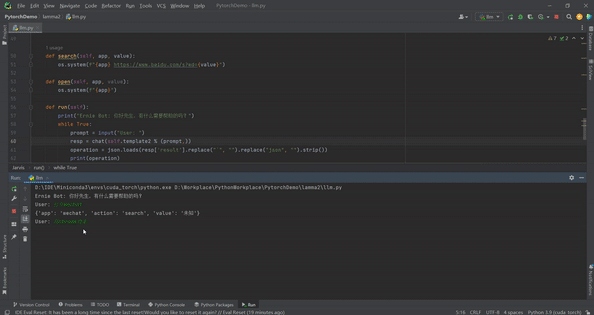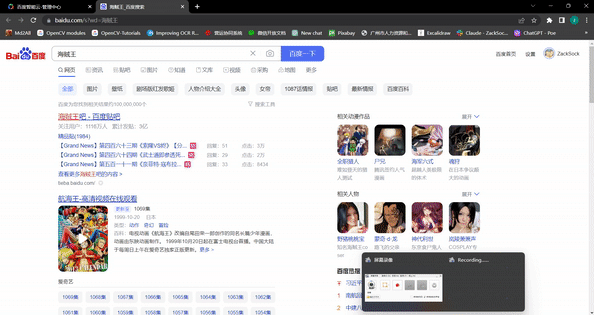
通过上面简单的代码就实现了简易版PC Siri。读者可以继续扩展器功能,比如接入语音识别、添加更丰富的功能。
四、模型训练
由于参数量巨大,大模型的部署本身就是一个非常高门槛的事情。而预先提供的大模型可能并不适合自己需要应用的场景,因此需要对模型做一些定制化处理。这就包括接入知识库或者进行fine-tuning了,在文心千帆中提供了模型fine-tuning的功能,我们只需要导入数据即可。
4.1 数据集
首先需要创建自己的数据集,这里可以先创建两个数据库,一个为原始数据库,一个为清洗后的数据库,创建操作如下:

以文本对话/含排序为例,创建完成后可以使用jsonl文件导入对话数据,可以选择导入问题或者问题对话一起导入。导入文件示例如下:
[{"prompt": "你多大了?"}]
[{"prompt": "你喜欢什么?"}]
[{"prompt": "你身高多少?"}]
[{"prompt": "你是男的女的?"}]
[{"prompt": "你几岁了?"}]
[{"prompt": "你喜欢爸爸还是喜欢妈妈?"}]
...
4.2 在线标注
导入的数据库可以选择已标注的或者未标注的,如果未标注则可以使用文心千帆的标注功能对数据库进行标注。在进行标注时我们可以直接人为编写回答,亦或者自动生成,在生成的基础上进行修改,这样可以大大节约标注的时间。

4.3 数据处理
在标注完成后,可以对数据做一些标注化的处理。比如去除emoji、大小写转换、繁体简体转换等。这些操作都可以自动完成,选择数据处理、创建任务、选择需要做的清洗操作:
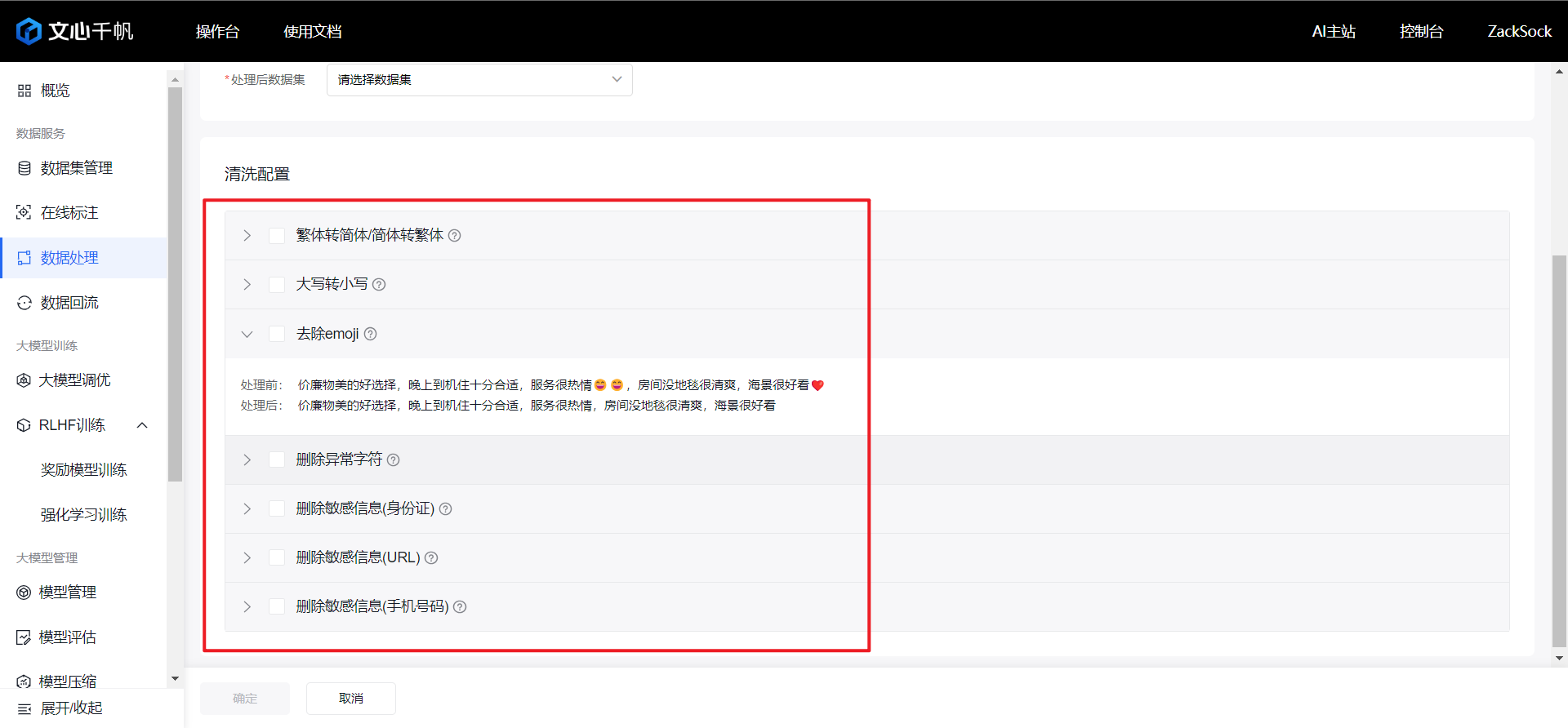
请求完成后得到的结果会作为新数据集输出。我们就可以利用这个新数据集完成模型的训练了。
4.4 RLHF训练
训练分为奖励模型训练和强化学习训练,两者是递进关系。我们可以按照如下流程完成训练部署操作:

这里我们一样创建训练任务、然后选择前面创建好的数据库即可。首先进行奖励模型训练,创建训练任务填写相关信息,具体如下:

而后选择需要训练的数据库,就是前面创建的数据库。这里我使用与前面应用相关的数据集:
[{"prompt": "```用chrome搜索海贼王 ```分析三引号中内容,以json数据形式返回,包含app、action、value三个键。app表示应用程序,action表示动作、操作,value表示时间、url、文件名等有意义的内容。"}]
[{"prompt": "```打开wechat ```分析三引号中内容,以json数据形式返回,包含app、action、value三个键。app表示应用程序,action表示动作、操作,value表示时间、url、文件名等有意义的内容。"}]
[{"prompt": "```用kugou播放dear friends ```分析三引号中内容,以json数据形式返回,包含app、action、value三个键。app表示应用程序,action表示动作、操作,value表示时间、url、文件名等有意义的内容。"}]
[{"prompt": "```用edge搜索海贼王 ```分析三引号中内容,以json数据形式返回,包含app、action、value三个键。app表示应用程序,action表示动作、操作,value表示时间、url、文件名等有意义的内容。"}]
[{"prompt": "```帮我用chrome搜索海贼王 ```分析三引号中内容,以json数据形式返回,包含app、action、value三个键。app表示应用程序,action表示动作、操作,value表示时间、url、文件名等有意义的内容。"}]
...
在前面的例子中,结果有时会出现一些意想不到的问题。为了减少这种不确定性,我们进行二次训练。
在完成奖励模型训练后,需要使用query问题集数据集进行强化学习训练。在强化学习训练一栏,选择数据库、大模型以及超参数:

完成训练后,我们的模型可以在前面的应用中得到更稳定的效果。
四、总结
今天介绍了LLM的相关内容,主要以文心千帆为例介绍了平台为大模型提供的种种功能。包括对其对话能力的测试、数据库导入、标注、数据清洗、模型fine-tuning的介绍。
在文章的结尾,使用文心千帆的API,将LLM接入到自己编写的应用程序中。并实现了基于自然语言的PC端助手,这里用一个非常简单的例子介绍了Prompt在LLM中的重要性。通过修改Prompt,我们可以完成自由度极高的应用,这部分读者可以自行扩展。