文章目的
本人目前是应用统计专业大二(2021/5/20)的本科生,上学期上过Python课,但说实话讲的不深,过了一个学期也基本上忘光了。
最近深刻地觉得计算机专业真是好啊,以后我也要当程序员.JPG ,最近开始和老板参加点小项目,打算重新把Python捡起来,不过其实和新入门没什么差别。最近老板给我们布置了个练习做做,便想通过CSDN来记录自己打代码的经历,也可以给同为刚入门的萌新提供点自己的思路,如果能帮上忙的话。
先来看题目:
数据框的操作1
数据来源:2018年“泰迪杯”数据分析职业技能大赛B题
数据说明:某商场在不同地点安放了5台自动售货机,编号分别为A、B、C、D、E。attachment1.csv提供了从2017年1月1日至2017年12月31日每台自动售货机的商品销售数据,附件2提供了商品的分类。
(注:这里我并没有收到附件2,仅有一个attachment1.csv文件,以下题目也不需要附件2。)
读取数据
- attachment1.csv
转换变量
有一条记录日期非法(
2017/2/29),在做数据转换前先剔除它。
订单号是唯一的,仍使用字符型变量;设备ID、商品、地点、状态和提现是分类变量,化为因子变量。应付金额和实际金额为数值变量,无需改变。支付时间为字符型,将其转化为时间日期型。统计不同地点的销售额,按销售额从大到小排序
销售量最大的前10种商品,销售额最大的前10种商品
统计不同地点的销售额最多的3类商品,然后按销售额从大到小排序
统计地点E在不同时间的销售额
- 按月分组统计
- 按小时分组统计
- 按一星期的第几天分组统计
说实话,刚开始看到这个题目我人就麻了,这玩意我们学过吗?我使劲儿回忆上学期只讲到了字典就结课的Python知识,发现这玩意儿是我解决不了的。回头看看群,经老板提点,我开始了边百度边打代码的痛苦之旅。
首先上最终代码:
import pandas as pd
import os
if os.path.exists('attachment1.csv') == False:print('未找到attachment1.csv!','请将attachment1.csv文件放入以下目录:',os.getcwd())
else:am = pd.read_csv('attachment1.csv',encoding='gb2312')#2.去除日期非法数据#先直接转换:am['支付时间'] = pd.to_datetime(am['支付时间'], format='%Y/%m/%d %H:%M')#提示错误:"ValueError: time data 2017/2/29 3:44:00 PM doesn't match format specified"#于是:am1 = am[~am['支付时间'].isin(['2017/2/29 3:44:00 PM'])]#2.将如下分类变量改为因子变量cols = ['设备ID','商品','地点','状态','提现']for col in cols:am[col] = am[col].astype('category')#2.将支付时间改成时间日期型变量am1['支付时间'] = pd.to_datetime(am1['支付时间'],format='%Y/%m/%d %H:%M')#3.统计不同地点的销售额,按销售额从大到小排序am_SalesTotal = am1.groupby('地点')[['实际金额']].sum()\.sort_values(by='实际金额',ascending=False)\.rename(columns={'实际金额':'销售额'})#4.销售量最大的前10种商品,销售额最大的前10种商品am_SalesVolumeMax10 = am1.groupby('商品')['订单号']\.count().reset_index(name='销售量')\.sort_values(by='销售量',ascending=False)\.head(10)am_SalesMax10 = am1.groupby('商品')['实际金额'].sum()\.reset_index(name='销售额')\.sort_values(by='销售额',ascending=False)\.head(10)#4.或者am_SalesBothMax10 = am1.groupby('商品')\.agg(销售量 = pd.NamedAgg(column = '订单号',aggfunc = 'count'),销售额 = pd.NamedAgg(column = '实际金额',aggfunc = 'sum'))\.sort_values(by=['销售量','销售额'],ascending=False)\.head(10)#5.统计不同地点销售额最多的3类商品并按销售额降序排序am_SalesLoc = am1.groupby(['地点','商品'])\.agg(销售额 = pd.NamedAgg(column = '实际金额',aggfunc = 'sum'))\.sort_values(by=['地点','销售额'],ascending=[True,False])\.reset_index().groupby('地点')\.head(3)#6.地点E按月份统计销售额am_SalesMonth = am1.loc[am1.地点=='E']\.groupby(['地点',am1['支付时间'].apply(lambda x:x.month)])\.agg(销售额 = pd.NamedAgg(column = '实际金额',aggfunc = 'sum'))\.reset_index().set_index('地点')\.rename(columns={'支付时间':'月份'})#6.地点E按小时统计销售额am_SalesHour = am1.loc[am1.地点=='E']\.groupby(['地点',am1['支付时间'].apply(lambda x:x.hour)])\.agg(销售额 = pd.NamedAgg(column = '实际金额',aggfunc = 'sum'))\.reset_index().set_index('地点')\.rename(columns={'支付时间':'时'})#6.地点E按一星期的第几天统计销售额am2 = am1[:]am2['支付时间'] = am1['支付时间'].dt.weekdayam_SalesDay = am2.loc[am2.地点=='E']\.groupby(['地点','支付时间'])['实际金额']\.sum().reset_index(name='销售额')\.set_index('地点')\.rename(columns={'支付时间':'第几天(从星期天开始)'})#输出EXCEL报表writer = pd.ExcelWriter('Output.xlsx')am_SalesTotal.to_excel(writer,'各地区销售额')am_SalesBothMax10.to_excel(writer,'商品销售量与销售额前十')am_SalesLoc.to_excel(writer,'各地区销售额最多的三类商品')am_SalesMonth.to_excel(writer,'地点E按月份统计销售额')am_SalesHour.to_excel(writer,'地点E按小时统计销售额')am_SalesDay.to_excel(writer,'地点E按星期统计销售额')writer.save()print('统计报告已输出至:',os.getcwd(),'目录下的Output.xlsx,请注意查看。')input('Press Enter to exit')第一题
读取数据
- attachment1.csv
代码:
import pandas as pd
import numpy as np
import os
if os.path.exists('attachment1.csv') == False:print('未找到attachment1.csv!','请将attachment1.csv文件放入以下目录:',os.getcwd())
else:am = pd.read_csv('attachment1.csv',encoding='gb2312')
导入所需要的库,然后检测attachment1.csv文件在不在工作目录下,随后读取。由于存在中文项,我直接读取会乱码,就使用encoding = 'gb2312'编码打开。
文件检测(若attachment1.csv不在工作目录下):
未找到attachment1.csv! 请将attachment1.csv文件放入以下目录: C:\Users\Administrator\AppData\Local\Programs\Python\Python39
若存在则继续运行。
第二题
转换变量
有一条记录日期非法(
2017/2/29),在做数据转换前先剔除它。
日期非法,源文件的日期并没有用时间日期型格式,于是使用
am['支付时间'] = pd.to_datetime(am['支付时间'], format='%Y/%m/%d %H:%M')
出现报错:ValueError: time data 2017/2/29 3:44:00 PM doesn't match format specified,与题目的非法日期相同,于是删除:
am1 = am[~am['支付时间'].isin(['2017/2/29 3:44:00 PM'])]
由于只有一条非法记录,便可以使用~来反选。
订单号是唯一的,仍使用字符型变量;设备ID、商品、地点、状态和提现是分类变量,化为因子变量。应付金额和实际金额为数值变量,无需改变。支付时间为字符型,将其转化为时间日期型。
使用print (am.dtypes),发现订单号已经是Object类型了,不做改变,其他四项需要改变。
订单号 object
设备ID object
应付金额 float64
实际金额 float64
商品 object
支付时间 object
地点 object
状态 object
提现 object
dtype: object
代码:
cols = ['设备ID','商品','地点','状态','提现']
for col in cols:am[col] = am[col].astype('category')
am1['支付时间'] = pd.to_datetime(am1['支付时间'], format='%Y/%m/%d %H:%M')
一个简单的循环,然后将日期变成如YYYY/MM/DD HH:MM的格式。
(PS:因为之前我修改的是am的数据类型而不是am1,且只修改了am1的支付时间数据类型,导致后面代码都是在am1除了支付时间外其他数据类型还是初始状态进行的,打完代码才发现,懒得改了,了解方法就行)
结果:
print(am.info())
<class 'pandas.core.frame.DataFrame'>
Int64Index: 70679 entries, 0 to 70678
Data columns (total 9 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 订单号 70679 non-null object 1 设备ID 70679 non-null category 2 应付金额 70679 non-null float64 3 实际金额 70679 non-null float64 4 商品 70679 non-null category 5 支付时间 70679 non-null datetime64[ns]6 地点 70679 non-null category 7 状态 70679 non-null category 8 提现 70679 non-null category
dtypes: category(5), datetime64[ns](1), float64(2), object(1)
memory usage: 3.1+ MB
None
第三题
- 统计不同地点的销售额,按销售额从大到小排序。
想起百度先生的教导,使用分组聚合。
代码:
am_SalesTotal = am1.groupby('地点')[['实际金额']].sum() \.sort_values(by='实际金额',ascending=False) \.rename(columns={'实际金额':'销售额'})
先将地点分组,随后计算实际金额的总和即销售额,并将其重命名为销售额,降序排列。
结果:
销售额
地点
E 95655.4
C 61568.1
B 53970.3
A 42542.6
D 33243.3
第四题
- 销售量最大的前10种商品,销售额最大的前10种商品
同样是分组聚合,只是有两个数据需要计算。这里我用了两种方法,可以分开计算,也可以合成一个表计算,由于我需要导出到Excel表,使用同一个表计算而不需要再后期合成表,显然更方便些。
代码:
#分开计算
am_SalesVolumeMax10 = am1.groupby('商品')['订单号'].count() \.reset_index(name='销售量') \.sort_values(by='销售量',ascending=False) \.head(10)am_SalesMax10 = am1.groupby('商品')['实际金额'].sum() \.reset_index(name='销售额') \.sort_values(by='销售额',ascending=False) \.head(10)#4.合并
am_SalesBothMax10 = am1.groupby('商品') \.agg(销售量 = pd.NamedAgg(column = '订单号',aggfunc = 'count'),销售额 = pd.NamedAgg(column = '实际金额',aggfunc = 'sum')) \.sort_values(by=['销售量','销售额'],ascending=False) \.head(10)
总体思想还是和第三题一样,先按商品分组,后计算销售量与销售额,然后降序排列,由于有两个变量,就销售量优先排序,所以销售额会有些乱序。最后显示前10位。
结果:
销售量 销售额
商品
怡宝纯净水 4964 12563.5
脉动 2778 12255.0
东鹏特饮 2581 9293.0
阿萨姆奶茶 2396 10149.0
营养快线 2239 9572.5
统一冰红茶 1891 6250.0
果粒橙 1356 4737.5
30g无穷农场盐_鸡蛋 1315 4336.5
统一绿茶 1284 4231.0
王老吉(罐) 1258 4730.5
第五题
- 统计不同地点的销售额最多的3类商品,然后按销售额从大到小排序
代码:
am_SalesLoc = am1.groupby(['地点','商品']) \.agg(销售额 = pd.NamedAgg(column = '实际金额',aggfunc = 'sum')) \.sort_values(by=['地点','销售额'],ascending=[True,False]) \.reset_index() \.groupby('地点') \.head(3)
同样分组就完了,和前两题差不多,稍微要注意的地方就是有两个引索,形成了二元表,需要重设一下引索,注意重设后需要再次分组.groupby('地点'),否则只会显示总排名的前三行,而不会将每个地点的前三行显示出来。
结果:
#重设后分组:groupby('地点')地点 商品 销售额
0 A 东鹏特饮 1583.5
1 A 阿萨姆奶茶 1307.5
2 A 脉动 1272.5
274 B 怡宝纯净水 3478.5
275 B 阿萨姆奶茶 1931.0
276 B 脉动 1872.0
535 C 脉动 3447.5
536 C 怡宝纯净水 2617.5
537 C 阿萨姆奶茶 1963.5
801 D 阿萨姆奶茶 1461.5
802 D 东鹏特饮 1443.5
803 D 营养快线 1285.5
1036 E 怡宝纯净水 4619.5
1037 E 脉动 4510.5
1038 E 营养快线 3532.5#不分组:地点 商品 销售额
0 A 东鹏特饮 1583.5
1 A 阿萨姆奶茶 1307.5
2 A 脉动 1272.5
第六题
统计地点E在不同时间的销售额
- 按月分组统计
- 按小时分组统计
- 按一星期的第几天分组统计
- 按月分组统计:
代码:
am_SalesMonth = am1.loc[am1.地点=='E'] \.groupby(['地点',am1['支付时间'] \.apply(lambda x:x.month)]) \.agg(销售额 = pd.NamedAgg(column = '实际金额',aggfunc = 'sum')) \.reset_index() \.set_index('地点') \.rename(columns={'支付时间':'月份'})
结果:
月份 销售额
地点
E 1 1656.8
E 2 938.7
E 3 1507.0
E 4 3723.1
E 5 5699.0
E 6 9899.7
E 7 3186.4
E 8 6722.5
E 9 17054.3
E 10 10208.6
E 11 21501.8
E 12 13557.5
由于只要分析地点E,那么先筛选出地点E的数据,随后将其按地点分组,实际上只剩地点E的那一组了。然后将支付时间的时间日期型转换成月份,计算销售额并将列名实际金额改成销售额,之后重设引索后,将地点设为引索(非必要),将列名支付时间重命名成月份。
- 按小时分组统计
代码:
am_SalesHour = am1.loc[am1.地点=='E'] \.groupby(['地点',am1['支付时间'] \.apply(lambda x:x.hour)]) \.agg(销售额 = pd.NamedAgg(column = '实际金额',aggfunc = 'sum')) \.reset_index().set_index('地点') \.rename(columns={'支付时间':'时'})
和第一小问大同小异,这里就不赘述。
- 按一星期的第几天分组统计
代码:
am2 = am1[:]
am2['支付时间'] = am1['支付时间'].dt.weekday
am_SalesDay = am2.loc[am2.地点=='E'] \.groupby(['地点','支付时间'])['实际金额'].sum() \.reset_index(name='销售额') \.set_index('地点') \.rename(columns={'支付时间':'第几天(从星期天开始)'})
这里为什么和上面两问不同了?因为我把lambda x:x.hour改成lambda x:x.weekday或lambda x:x.dt.weekday都会报错,而且我不知道怎么修(滑稽 ,所以另辟蹊径。
新建一个am2 = am1[:],这里注意要使用am2 = am1[:]而非am2 = am1,否则修改am2时也会修改am1。随后将am2的支付时间列改成星期显示。
结果:
第几天(从星期天开始) 销售额
地点
E 0 15041.1
E 1 11484.0
E 2 14029.1
E 3 12497.5
E 4 12958.3
E 5 14379.1
E 6 15266.3
从星期天开始,星期天为第0天,星期一为第1天,以此类推。
END
附加:输出报表于Excel
到上面这篇练习就算完成了,但本着面向实际解决问题的精神,还是输出一个报表,并优化一下代码使之用起来更舒适。
所以开头添加了attachment1.csv文件的检测。
代码:
writer = pd.ExcelWriter('Output.xlsx')
am_SalesTotal.to_excel(writer,'各地区销售额')
am_SalesBothMax10.to_excel(writer,'商品销售量与销售额前十')
am_SalesLoc.to_excel(writer,'各地区销售额最多的三类商品')
am_SalesMonth.to_excel(writer,'地点E按月份统计销售额')
am_SalesHour.to_excel(writer,'地点E按小时统计销售额')
am_SalesDay.to_excel(writer,'地点E按星期统计销售额')
writer.save()
没有指定路径,所以Output.xlsx默认生成在工作目录下,鉴于甲方通常计算机基础不强,还是需要文件路径提示。
代码:
print('统计报告已输出至:',os.getcwd(),'目录下的Output.xlsx,请注意查看。')
最后加一个按ENTER退出,这样就方便直接双击.py文件使用了。
代码:
input('Press Enter to exit')
结果:
统计报告已输出至: C:\Users\Administrator\AppData\Local\Programs\Python\Python39 目录下的Output.xlsx,请注意查看。
Press Enter to exit
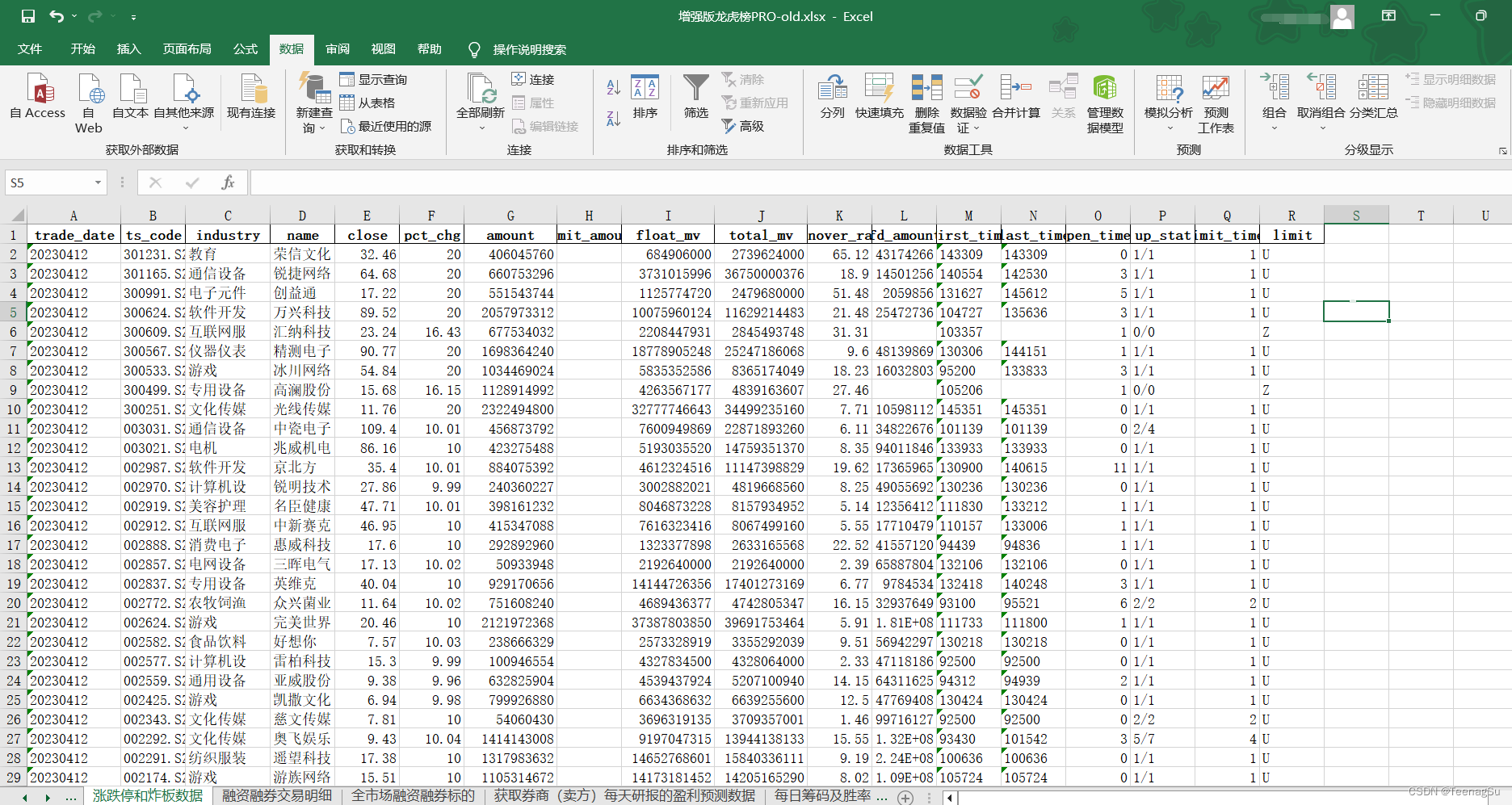
Output.xlsx如图:






注意
由于开头使用了if,所以要注意如上单个题目的代码都是在else之下,注意缩进对齐。