作者:David Hope

ChatGPT 现在很火,它打破了互联网。 作为 ChatGPT 的狂热用户和 ChatGPT 应用程序的开发者,我对这项技术的可能性感到无比兴奋。 我看到的情况是,基于 ChatGPT 的解决方案将呈指数级增长,人们将需要监控这些解决方案。
由于这是一项非常新的技术,我们不想让我们闪亮的新代码负担专有技术,对吗? 不,我们不会,这就是为什么我们要使用 OpenTelemetry 来监控本博客中的 ChatGPT 代码。 这对我来说尤其重要,因为我最近创建了一项服务,可以从 Zoom 通话中生成会议记录。 如果我要将其发布到外面,我要花多少钱?我如何确保它可用?
OpenAI API 来拯救
毫无疑问,OpenAI API 非常棒。 它还会在对每个 API 调用的每个响应中为我们提供如下所示的信息,这可以帮助我们了解我们被收取的费用。 通过使用 OpenAI 在其网站上发布的代币数量、模型和定价,我们可以计算成本。 问题是,我们如何将这些信息输入到我们的监控工具中?
{"choices": [{"finish_reason": "length","index": 0,"logprobs": null,"text": "\n\nElastic is an amazing observability tool because it provides a comprehensive set of features for monitoring"}],"created": 1680281710,"id": "cmpl-70CJq07gibupTcSM8xOWekOTV5FRF","model": "text-davinci-003","object": "text_completion","usage": {"completion_tokens": 20,"prompt_tokens": 9,"total_tokens": 29}
}
OpenTelemetry 来拯救
OpenTelemetry 确实是一项了不起的工作。 多年来,它得到了如此多的采用和致力于它的工作,它似乎真的到了我们可以称之为 Linux of Observability 的地步。 我们可以使用它来记录日志、指标和跟踪,并以供应商中立的方式将它们放入我们最喜欢的可观察性工具 —— 在本例中为 Elastic 可观察性。
借助 Python 中最新最好的 otel 库,我们可以自动检测外部调用,这将帮助我们了解 OpenAI 调用的执行情况。 让我们先看看我们的示例 Python 应用程序,它实现了 Flask 和 ChatGPT API,并且还具有 OpenTelemetry。 如果你想自己尝试,请查看本博客末尾的 GitHub 链接并按照以下步骤操作。
设置 Elastic Cloud 帐户(如果你还没有)
- 在 https://www.elastic.co/cloud/elasticsearch-service/signup 注册为期两周的免费试用。
- 创建部署。
登录后,单击 Add integrations。
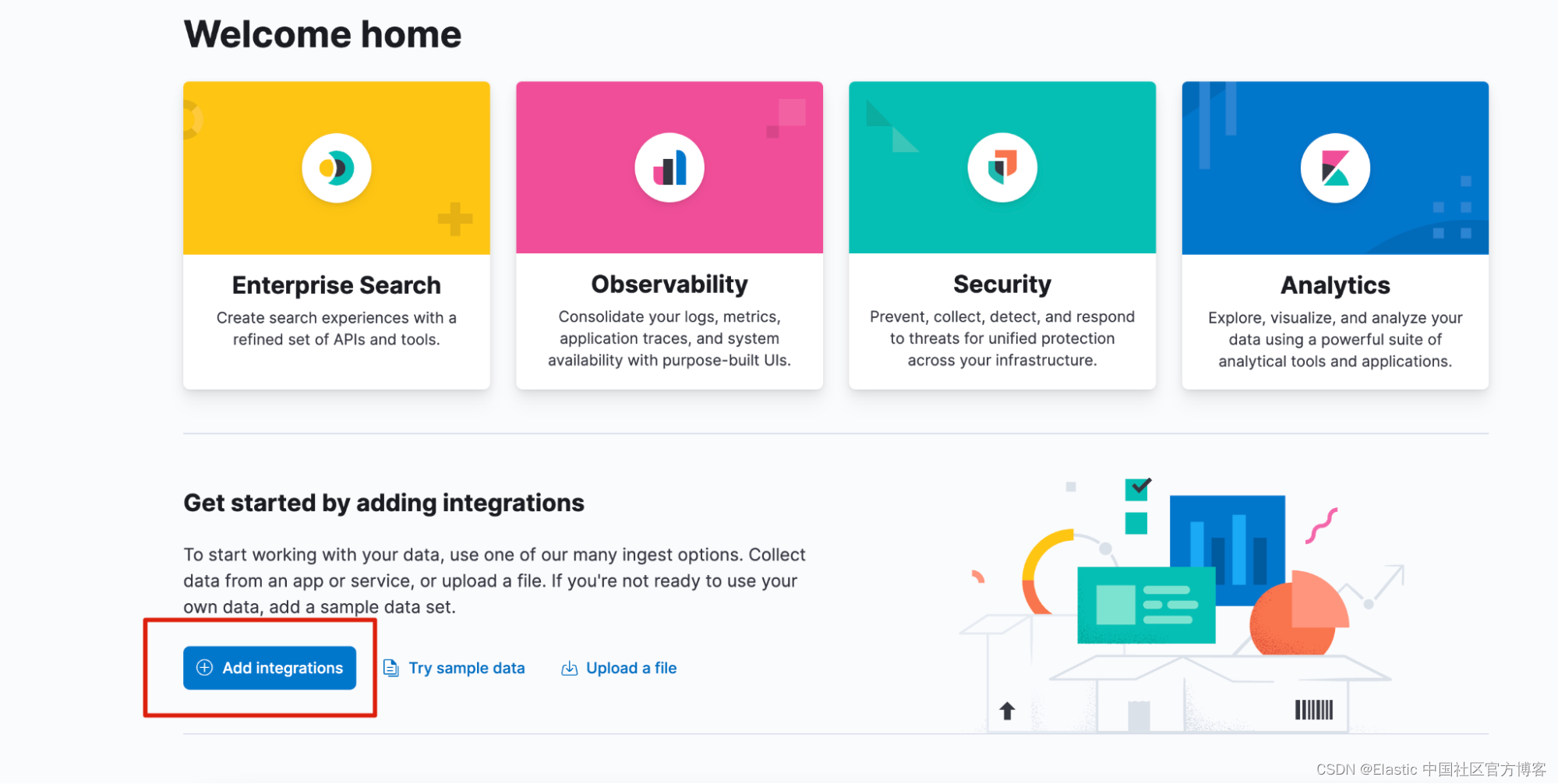
点击 APM Integration:

然后向下滚动以获取此博客所需的详细信息:

请务必设置以下环境变量,将变量替换为你从上面的 Elastic 和此处的 OpenAI 获取的数据,然后在命令行上运行这些导出命令。
export OPEN_AI_KEY=sk-abcdefgh5ijk2l173mnop3qrstuvwxyzab2cde47fP2g9jij
export OTEL_EXPORTER_OTLP_AUTH_HEADER=abc9ldeofghij3klmn
export OTEL_EXPORTER_OTLP_ENDPOINT=https://123456abcdef.apm.us-west2.gcp.elastic-cloud.com:443并安装以下 Python 库:
pip3 install opentelemetry-api
pip3 install opentelemetry-sdk
pip3 install opentelemetry-exporter-otlp
pip3 install opentelemetry-instrumentation
pip3 install opentelemetry-instrumentation-requests
pip3 install openai
pip3 install flask下面是我们用于示例应用程序的代码。 在现实世界中,这将是你自己的代码。 这一切所做的就是使用以下消息调用 OpenAI API:“Why is Elastic an amazing observability tool?(为什么 Elastic 是一个了不起的可观察性工具?)”
import openai
from flask import Flask
import monitor # Import the module
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
import urllib
import os
from opentelemetry import trace
from opentelemetry.sdk.resources import SERVICE_NAME, Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.instrumentation.requests import RequestsInstrumentor# OpenTelemetry setup up code here, feel free to replace the “your-service-name” attribute here.
resource = Resource(attributes={SERVICE_NAME: "your-service-name"
})
provider = TracerProvider(resource=resource)
processor = BatchSpanProcessor(OTLPSpanExporter(endpoint=os.getenv('OTEL_EXPORTER_OTLP_ENDPOINT'),headers="Authorization=Bearer%20"+os.getenv('OTEL_EXPORTER_OTLP_AUTH_HEADER')))
provider.add_span_processor(processor)
trace.set_tracer_provider(provider)
tracer = trace.get_tracer(__name__)
RequestsInstrumentor().instrument()# Initialize Flask app and instrument itapp = Flask(__name__)
# Set OpenAI API key
openai.api_key = os.getenv('OPEN_AI_KEY')@app.route("/completion")
@tracer.start_as_current_span("do_work")
def completion():response = openai.Completion.create(model="text-davinci-003",prompt="Why is Elastic an amazing observability tool?",max_tokens=20,temperature=0)return response.choices[0].text.strip()if __name__ == "__main__":app.run()此处使用 Python 实现 OpenTelemetry 的任何人都应该相当熟悉此代码 — 没有特定的魔法。 魔法发生在 “监控” 代码中,你可以自由使用它来检测你自己的 OpenAI 应用程序。
摆弄 Monkey
在 monitor.py 代码中,你会看到我们做了一些叫做 “Monkey Patching” 的事情。 Monkey patching 是 Python 中的一种技术,你可以在运行时通过修改类或模块的属性或方法来动态修改类或模块的行为。 Monkey patching 允许你更改类或模块的功能,而无需修改其源代码。 当你需要修改你无法控制或无法直接修改的现有类或模块的行为时,它会很有用。
我们在这里要做的是修改 “Completion” 调用的行为,以便我们可以窃取响应指标并将它们添加到我们的 OpenTelemetry 跨度中。 你可以在下面看到我们是如何做到的:
def count_completion_requests_and_tokens(func):@wraps(func)def wrapper(*args, **kwargs):counters['completion_count'] += 1response = func(*args, **kwargs)token_count = response.usage.total_tokensprompt_tokens = response.usage.prompt_tokenscompletion_tokens = response.usage.completion_tokenscost = calculate_cost(response)strResponse = json.dumps(response)# Set OpenTelemetry attributesspan = trace.get_current_span()if span:span.set_attribute("completion_count", counters['completion_count'])span.set_attribute("token_count", token_count)span.set_attribute("prompt_tokens", prompt_tokens)span.set_attribute("completion_tokens", completion_tokens)span.set_attribute("model", response.model)span.set_attribute("cost", cost)span.set_attribute("response", strResponse)return responsereturn wrapper
# Monkey-patch the openai.Completion.create function
openai.Completion.create = count_completion_requests_and_tokens(openai.Completion.create)通过将所有这些数据添加到我们的 Span,我们实际上可以将其发送到我们的 OpenTelemetry OTLP 端点(在本例中它将是 Elastic)。 这样做的好处是你可以轻松地使用数据进行搜索或构建仪表板和可视化。 在最后一步,我们还要计算成本。 我们通过实现以下函数来实现这一点,该函数将计算对 OpenAI API 的单个请求的成本。
def calculate_cost(response):if response.model in ['gpt-4', 'gpt-4-0314']:cost = (response.usage.prompt_tokens * 0.03 + response.usage.completion_tokens * 0.06) / 1000elif response.model in ['gpt-4-32k', 'gpt-4-32k-0314']:cost = (response.usage.prompt_tokens * 0.06 + response.usage.completion_tokens * 0.12) / 1000elif 'gpt-3.5-turbo' in response.model:cost = response.usage.total_tokens * 0.002 / 1000elif 'davinci' in response.model:cost = response.usage.total_tokens * 0.02 / 1000elif 'curie' in response.model:cost = response.usage.total_tokens * 0.002 / 1000elif 'babbage' in response.model:cost = response.usage.total_tokens * 0.0005 / 1000elif 'ada' in response.model:cost = response.usage.total_tokens * 0.0004 / 1000else:cost = 0return costElastic 来拯救
一旦我们捕获了所有这些数据,就可以在 Elastic 中玩得开心了。 在 Discover 中,我们可以看到我们使用 OpenTelemetry 库发送的所有数据点:

有了这些标签,构建仪表板就非常容易了。 看看我之前构建的这个(它也已提交到我的 GitHub 存储库):

我们还可以看到 OpenAI 服务的 transactions、延迟以及与我们的 ChatGPT 服务调用相关的所有跨度(span)。



在事务视图中,我们还可以看到特定的 OpenAI 调用花费了多长时间:
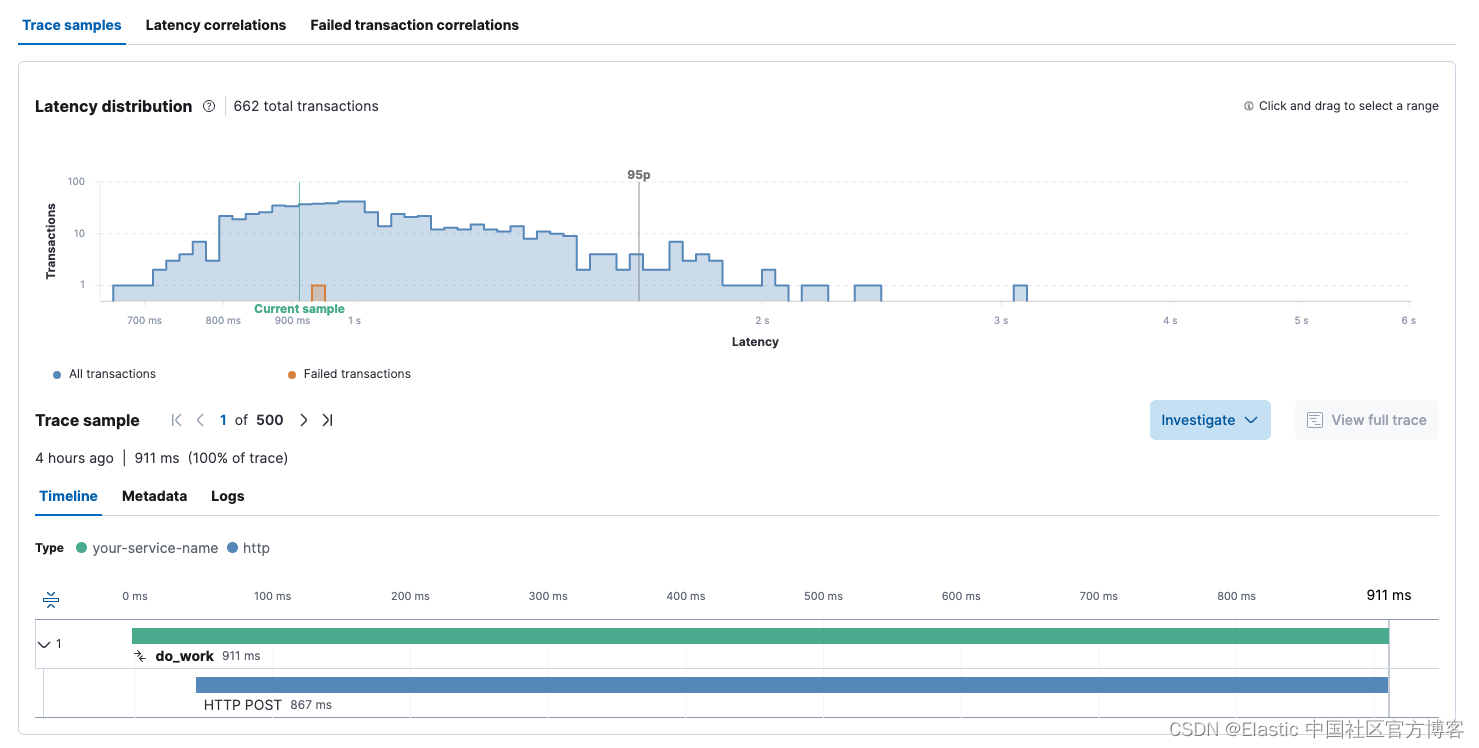
此处对 OpenAI 的一些请求已超过 3 秒。 ChatGPT 可能会非常慢,因此了解它有多慢以及用户是否感到沮丧对我们来说很重要。
总结
我们研究了使用 OpenTelemetry 和 Elastic 监控 ChatGPT。 ChatGPT 是一种全球现象,毫无疑问,它会不断发展壮大,很快每个人都会使用它。 因为获得响应可能很慢,所以人们能够理解使用此服务的任何代码的性能至关重要。
还有成本问题,因为了解这项服务是否正在侵蚀你的利润以及你所要求的是否对你的业务有利可图非常重要。 在当前的经济环境下,我们必须密切关注盈利能力。
在此处查看此解决方案的代码。 请随意使用 “monitor” 库来检测你自己的 OpenAI 代码。
有兴趣了解有关 Elastic 可观察性的更多信息吗? 查看以下资源:
- Elastic 可观察性简介
- 可观察性基础培训
- 观看 Elastic 可观察性演示
- 2023 年的可观测性预测和趋势
并报名参加我们以 AWS 和 Forrester 为特色的 Elastic 可观察性趋势网络研讨会,不容错过!
原文:Monitor OpenAI API and GPT models with OpenTelemetry and Elastic | Elastic Blog