LLM | AMD | Intel | NVIDIA
GLM | ARM | AIGC | Chiplet
随着深度学习、高性能计算、NLP、AIGC、GLM、AGI的快速发展,大模型得到快速发展。2023年科创圈的顶尖技术无疑是大模型,据科技部新一代人工智能发展研究中心发布的《中国人工智能大模型地图研究报告》显示,我国已发布79个参数规模超过10亿的大模型,几乎形成了百模大战的局面。在大模型研发方面,中国14个省区市都在积极开展工作,其中北京拥有38个项目,广东拥有20个项目。
目前,自然语言处理是大模型研发最活跃的领域,其次是多模态领域,而在计算机视觉和智能语音等领域大模型相对较少。大学、科研机构和企业等不同创新主体都参与了大模型的研发,但学术界和产业界之间的合作研发仍有待加强。
随着人工智能大模型参数量从亿级增长到万亿级,人们对支撑大模型训练所需的超大规模算力和网络连接的重要性越来越关注。大模型的训练任务需要庞大的GPU服务器集群提供计算能力,并通过网络进行海量数据交换。然而,即使单个GPU性能强大,如果网络性能跟不上,整个算力集群的计算能力也会大幅下降。因此,大集群并不意味着大算力,相反,GPU集群越大,额外的通信损耗也越多。本文将详细介绍CPU和GPU的复杂性比较,多元算力的结合(CPU+GPU),算存互连和算力互连的重要性。

多元算力:CPU+GPU
ChatGPT广受欢迎使得智算中心的关注度再次上升,GPU同时也成为各大公司争相争夺的对象。GPU不仅是智算中心的核心,也在超算领域得到广泛的应用。根据最新一届TOP500榜单(于2023年5月下旬公布)显示:
-
使用加速器或协处理器的系统从上一届的179个增加到185个,其中150个系统采用英伟达(NVIDIA)的Volta(如V100)或Ampere(如A100)GPU。
-
在榜单的前10名中,有7个系统使用GPU,在前5名中,只有第二名没有使用GPU。
 超大规模数据中心架构及光模块升级路径
超大规模数据中心架构及光模块升级路径
当然,CPU仍然是不可或缺的。以榜单前10名为例,AMC EPYC家族处理器占据4个位置,英特尔至强家族处理器和IBM的POWER9各占据2个位置,而Arm也有1个位置(富士通A64FX)位居第二位。
通用算力和智能算力相辅相成,可以满足多样化的计算需求。以欧洲高性能计算联合事业(EuroHPC JU)正在部署的MareNostrum 5为例:基于第四代英特尔至强可扩展处理器的通用算力计划将于2023年6月开放服务,而基于NVIDIA Grace CPU的"下一代"通用算力以及由第四代英特尔至强可扩展处理器和NVIDIA Hopper GPU(如H100)组成的加速算力,则计划于2023年下半年投入使用。
一、GPU:大芯片与小芯片
尽管英伟达在GPU市场上占据着统治地位,但AMD和英特尔并未放弃竞争。以最新的TOP500榜单前10名为例,其中4个基于AMC EPYC家族处理器的系统中,有2个搭配AMD Instinct MI250X和NVIDIA A100,前者排名较高,分别位居第一和第三位。
然而,在人工智能应用方面,英伟达GPU的优势显著。在GTC 2022上发布的NVIDIA H100 Tensor Core GPU进一步巩固其领先地位。H100 GPU基于英伟达Hopper架构,采用台积电(TSMC)N4制程,拥有高达800亿个晶体管,并在计算、存储和连接方面全面提升:
-
132个SM(流式多处理器)和第四代Tensor Core使性能翻倍;
-
比前一代更大的50MB L2缓存和升级到HBM3的显存构成新的内存子系统;
-
第四代NVLink总带宽达到900GB/s,支持NVLink网络,PCIe也升级到5.0。
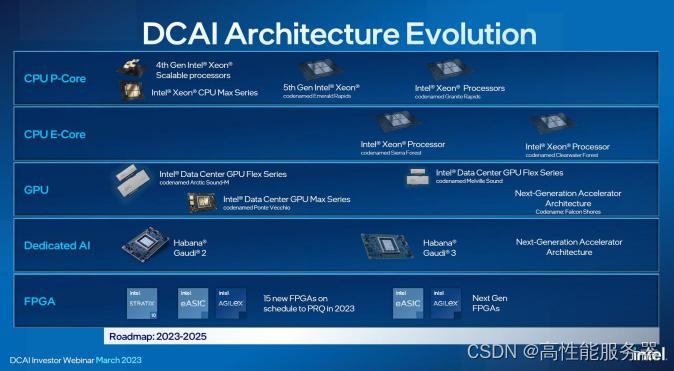
在2023年1月,英特尔也推出代号为Ponte Vecchio的英特尔数据中心GPU Max系列,与第四代英特尔至强可扩展处理器和英特尔至强CPU Max系列一起发布。英特尔数据中心GPU Max系列利用英特尔的Foveros和EMIB技术,在单个产品上整合47个小芯片,集成超过1000亿个晶体管,拥有高达408MB的L2缓存和128GB的HBM2e显存,充分体现芯片模块化的理念。
可插拔光模块与 CPO 对比
二、CPU:性能核与能效核
通用算力的发展趋势是多元化的,以满足不同应用场景的需求。在手机、PC和其他终端产品中,经过验证的"大小核"架构逐渐成为主流,而在服务器CPU市场也开始流行起来。然而,服务器的特点是集群作战,并不迫切需要在同一款CPU内部实现大小核的组合。主流厂商正通过提供全是大核或全是小核的CPU来满足不同客户的需求,其中大核注重单核性能,适合纵向扩展,而小核注重核数密度,适合横向扩展。
作为big.LITTLE技术的发明者,Arm将异构核的理念引入服务器CPU市场,并已经有一段时间。Arm的Neoverse平台分为三个系列:
-
Neoverse V系列用于构建高性能CPU,提供高每核心性能,适用于高性能计算、人工智能机器学习加速等工作负载;
-
Neoverse N系列注重横向扩展性能,提供经过优化的平衡CPU设计,以提供理想的每瓦性能,适用于横向扩展云、企业网络、智能网卡DPU、定制ASIC加速器、5G基础设施以及电源和空间受限的边缘场景;
-
Neoverse E系列旨在以最小的功耗支持高数据吞吐量,面向网络数据平面处理器、低功耗网关的5G部署。
这些系列的设计旨在满足不同领域和应用的需求。
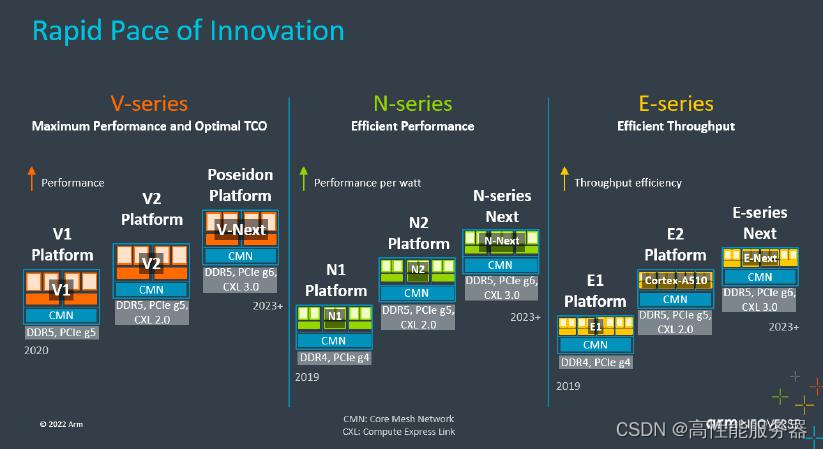
在规模较大的云计算中心、智算中心和超级计算中心等应用场景中,可以将大小核架构在数据中心市场上的实践归纳为两个系列:V系列侧重单核性能的纵向扩展(Scale-up)而N系列侧重多核性能的横向扩展(Scale-out)。
在这些应用场景中,V系列产品的代表包括64核的AWS Graviton3(猜测为V1)和72核的NVIDIA Grace CPU(V2)而N系列产品除阿里云的128核倚天710(猜测为N2)外,还在DPU领域得到广泛应用。最近发布的AmpereOne采用Ampere Computing公司自研的A1核,最多拥有192个核心,更接近Neoverse N系列的设计风格。英特尔在面向投资者的会议上也公布类似的规划。

英特尔在面向投资者的会议上也公布类似的规划:
-
2023年第四季度推出第五代英特尔至强可扩展处理器(代号Emerald Rapids)
-
2024年推出的代号为Granite Rapids的下一代产品。这些处理器将延续目前的性能核(P-Core)路线。另外,2024年上半年推出的代号为Sierra Forest的CPU将是第一代能效核(E-Core)至强处理器,拥有144个核心。
第五代英特尔至强可扩展处理器与第四代共享平台易于迁移而Granite Rapids和Sierra Forest将采用英特尔的3纳米制程。P-Core和E-Core的组合已经在英特尔的客户端CPU上得到验证,两者之间的一个重要区别是否支持超线程。E-Core每个核心只有一个线程注重能效,适用于追求更高物理核密度的云原生应用。
AMD 的策略大同小异。
-
2022年11月发布代号为Genoa的第四代EPYC处理器,采用5纳米的Zen 4核心,最高可达96个核心。
-
2023年中,AMD还将推出代号为Bergamo的“云原生”处理器,据传拥有多达128个核心,通过缩小核心和缓存来提供更高的核心密度。
虽然性能核和能效核这两条路线之间存在着核心数量的差异,但增加核心数是共识。随着CPU核心数量的持续增长,对内存带宽的要求也越来越高,仅仅升级到DDR5内存是不够的。AMD的第四代EPYC处理器(Genoa)已将每个CPU的DDR通道数量从8条扩展到12条,Ampere Computing也有类似的规划。
然而,拥有超过100个核心的CPU已经超出了一些企业用户的实际需求,而每个CPU的12条内存通道在双路配置下也给服务器主板设计带来新的挑战。在多种因素的影响下,单路服务器在数据中心市场的份额是否会有显著增长,这仍然需要拭目以待。
AMD 第四代 EPYC 处理器拥有 12 个 DDR5 内存通道,但单路(2DPC)和双路(1DPC)配置都不超 过 24 个内存槽,比 8 内存通道 CPU 的双路配置(32 个内存槽)还要少。换言之,单 CPU 的内存通 道数增加了,双路配置的内存槽数反而减少
三、GPU和CPU芯片相比谁更复杂
在大规模并行计算方面,高端GPU(如NVIDIA的A100或AMD的Radeon Instinct MI100)和高端CPU(如Intel的Xeon系列或AMD的EPYC系列)都具有各自的复杂性。GPU拥有大量的CUDA核心或流处理器,专注于并行计算,以支持高性能的并行任务。而高端CPU则具有更多的核心、更高的频率和复杂的超线程技术,以提供强大的通用计算能力。我们从应用场景、晶体管数量、架构设计几个维度来看看。
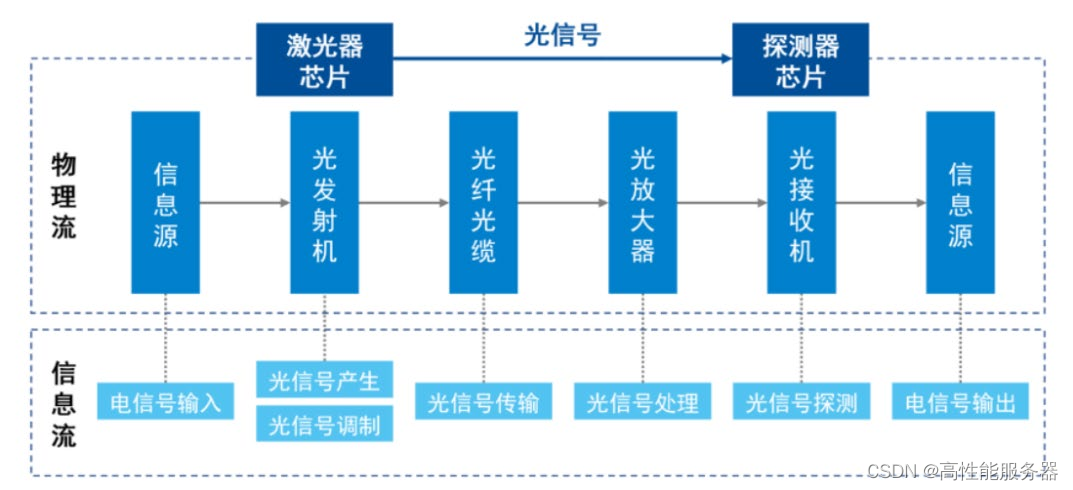 光芯片是光通信系统中的核心元件
光芯片是光通信系统中的核心元件
1、应用场景
GPU拥有大量的计算核心、专用存储器和高速数据传输通道,其设计注重于满足图形渲染和计算密集型应用的需求,强调大规模并行计算、内存访问和图形数据流处理。GPU的核心理念是并行处理,通过拥有更多的处理单元,能够同时执行大量并行任务。这使得GPU在处理可并行化的工作负载(如图形渲染、科学计算和深度学习)时表现出色。相比之下,CPU专注于通用计算和广泛的应用领域,通常具有多个处理核心、高速缓存层次和复杂的指令集体系结构。
2、晶体管数量
顶级的GPU通常拥有更多的晶体管,这是因为它们需要大量的并行处理单元来支持高性能计算。举例来说,NVIDIA的A100 GPU拥有约540亿个晶体管,而AMD的EPYC 7742 CPU则包含约390亿个晶体管。晶体管数量的差异反映了GPU在并行计算方面的重要性和专注度。
3、架构设计
从架构和设计的角度来看,CPU通常被认为更复杂。CPU需要处理各种不同类型的任务,并且需要优化以尽可能快地执行这些任务。为了实现这一目标,CPU采用了许多复杂的技术,如流水线、乱序执行、分支预测和超线程等。这些技术旨在提高CPU的性能和效率。
相比之下,顶级的GPU可能在硬件规模(如晶体管数量)上更大,但在架构和设计上可能相对简化。GPU的设计注重于大规模并行计算和图形数据流处理,因此其架构更加专注和优化于这些特定的任务。
1)GPU架构
GPU具有一些关键的架构特性。
首先,它拥有大量的并行处理单元(核心),每个处理单元可以同时执行指令。如NVIDIA的Turing架构具有数千个并行处理单元,也称为CUDA核心。其次,GPU采用分层的内存架构,包括全局内存、共享内存、本地内存和常量内存等。这些内存类型用于缓存数据,以减少对全局内存的访问延迟。另外,GPU利用硬件进行线程调度和执行,保持高效率。在NVIDIA的GPU中,线程以warp(32个线程)的形式进行调度和执行。此外,还拥有一些特殊的功能单元,如纹理单元和光栅化单元,这些单元专为图形渲染而设计。最新的GPU还具有为深度学习和人工智能设计的特殊单元,如张量核心和RT核心。此外,GPU采用了流多处理器和SIMD(单指令多数据流)架构,使得一条指令可以在多个数据上并行执行。
具体的GPU架构设计因制造商和产品线而异,例如NVIDIA的Turing和Ampere架构与AMD的RDNA架构存在一些关键差异。然而,所有的GPU架构都遵循并行处理的基本理念。
2)CPU架构
CPU(中央处理单元)的架构设计涉及多个领域,包括硬件设计、微体系结构和指令集设计等。
指令集架构(ISA)是CPU的基础,它定义了CPU可以执行的操作以及如何编码这些操作。常见的ISA包括x86(Intel和AMD)、ARM和RISC-V。现代CPU采用流水线技术,将指令分解为多个阶段,以提高指令的吞吐量。CPU还包含缓存和内存层次结构,以减少访问内存的延迟。乱序执行和寄存器重命名是现代CPU的关键优化手段,可以提高指令的并行执行能力和解决数据冒险问题。分支预测是一种优化技术,用于预测条件跳转指令的结果,以避免因等待跳转结果而产生的停顿。现代CPU通常具有多个处理核心,每个核心可以独立执行指令,并且一些CPU还支持多线程技术,可以提高核心的利用率。
CPU架构设计是一个极其复杂的过程,需要考虑性能、能耗、面积、成本和可靠性等多个因素。
四、Chiplet 与芯片布局
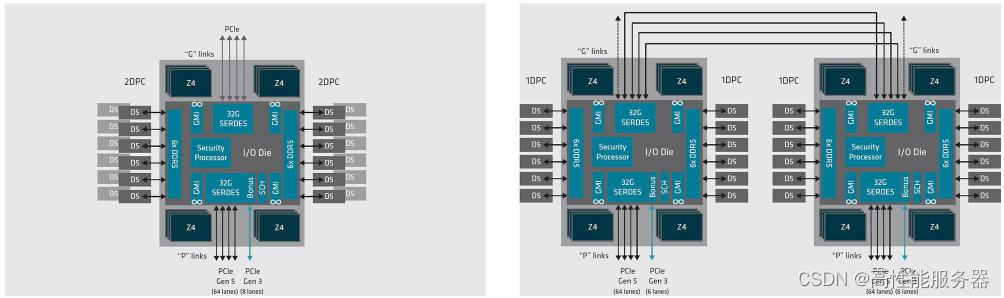
在CPU的Chiplet实现上,AMD和英特尔有一些不同。从代号为罗马(Rome)的第二代EPYC开始,AMD将DDR内存控制器、Infinity Fabric和PCIe控制器等I/O器件从CCD中分离出来,集中到一个独立的芯片(IOD)中,充当交换机的角色。这部分芯片仍然采用成熟的14纳米制程,而CCD内部的8个核心和L3缓存的占比从56%提高到86%,从7纳米制程中获得更大的收益。通过分离制造IOD和CCD,并按需组合,带来了许多优点:
1、独立优化
根据I/O、运算和存储(SRAM)的不同需求,选择适合成本的制程。例如,代号为Genoa的第四代EPYC处理器将使用5纳米制程的CCD搭配6纳米制程的IOD。
2、高度灵活
一个IOD可以搭配不同数量的CCD,以提供不同核心数的CPU。例如,代号为罗马的第二代EPYC处理器最多支持8个CCD,但也可以减少到6个、4个或2个,因此可以轻松提供8至64个核心。将CCD视为8核CPU,IOD视为原来服务器中的北桥或MCH(内存控制器中心),第二代EPYC相当于一套微型化的八路服务器。采用这种方法构建64核的CPU比在单个芯片上提供64核要简化许多,并具有良率和灵活性的优势。
3、扩大规模更容易
通过增加CCD的数量,在IOD的支持下,可以轻松获得更多的CPU核心。例如,第四代EPYC处理器通过使用12个CCD将核心数量扩展到96个。这种Chiplet实现方式为AMD带来许多优势,并且在制程选择、灵活性和扩展性方面更具有竞争力。

AMD 第四代 EPYC 处理器,12 颗 CCD 环绕 1 颗 IOD
第二至四代EPYC处理器采用星形拓扑结构,以IOD为中心连接多个较小规模的CCD。这种架构的优势在于可以灵活增加PCIe和内存控制器的数量,降低成本。然而,劣势在于任意核心与其他资源的距离较远,可能会限制带宽和增加时延。
在过去,AMD凭借制程优势和较高的核数,使得EPYC处理器在多核性能上表现出色。然而,随着竞争对手如英特尔和Arm的制造工艺改进以及大核心性能提升,AMD的核数优势可能会减弱,多核性能优势难以持续。同时,其他厂商的多核CPU采用网格化布局,通过快速互联来减小核心与其他资源的访问距离,更有效地控制时延。
五、Arm 新升:NVIDIA Grace 与 AmpereOne
Arm一直希望在服务器市场上占有一席之地。亚马逊、高通、华为等企业都推出基于Arm指令集的服务器CPU。随着亚马逊的Graviton、Ampere Altra等产品在市场上站稳脚跟,Arm在服务器CPU市场上的地位逐渐增强。同时,随着异构计算的兴起,Arm在高性能计算和AI/ML算力基础设施中的影响力也在扩大。
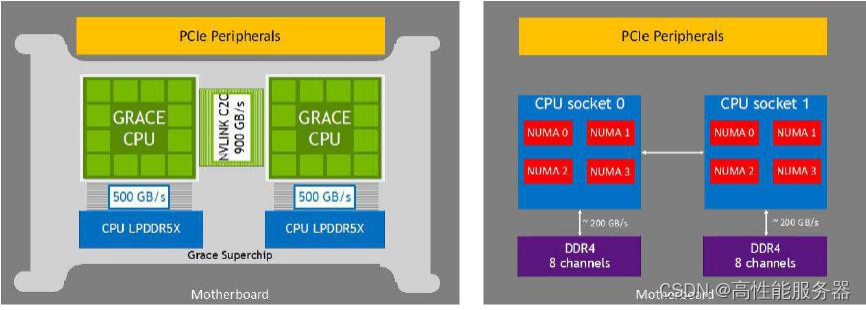
英伟达推出的基于Arm Neoverse架构的数据中心专用CPU即NVIDIA Grace,具有72个核心。Grace CPU超级芯片由两个Grace芯片组成,通过NVLink-C2C连接在一起,在单插座内提供144个核心和1TB LPDDR5X内存。此外NVIDIA还宣称Grace可以通过NVLink-C2C与Hopper GPU连接,组成Grace Hopper超级芯片。
NVIDIA Grace是基于Arm Neoverse V2 IP的重要产品。目前尚未公布NVIDIA Grace的晶体管规模,但可以参考基于Arm Neoverse V1的AWS Graviton 3和阿里云倚天710的数据。根据推测,基于Arm Neoverse V1的AWS Graviton 3约有550亿晶体管,对应64核和8通道DDR5内存;基于Arm Neoverse N2的阿里云倚天710约有600亿晶体管,对应128核、8通道DDR5内存和96通道PCIe 5.0。从NVIDIA Grace Hopper超级芯片的渲染图来看,Grace的芯片面积与Hopper接近,已知后者为800亿晶体管,因此推测72核的Grace芯片的晶体管规模大于Graviton 3和倚天710是合理的,并与Grace基于Neoverse V2(支持Arm V9指令集、SVE2)的情况相符。
Arm Neoverse V2配套的互连方案是CMN-700,在NVIDIA Grace中称为SCF(Scalable Coherency Fabric可扩展一致性结构)。英伟达声称Grace的网格支持超过72个CPU核心的扩展,实际上在英伟达白皮书的配图中可以数出80个CPU核心。每个核心有1MB L2缓存,整个CPU有高达117MB的L3缓存(平均每个核心1.625MB),明显高于其他同级别的Arm处理器。
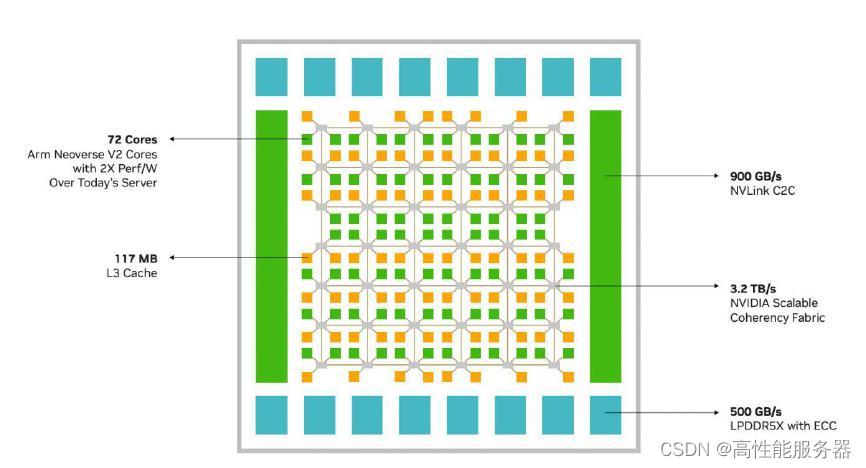
NVIDIA Grace CPU 的网格布局
NVIDIA Grace芯片内的SCF提供3.2 TB/s的分段带宽,连接CPU核心、内存控制器和NVLink等系统I/O控制器。网格中的节点称为CSN通常每个CSN连接2个核心和2个SCC(SCF缓存分区)。然而,从示意图可以看出,位于网格角落的4个CSN连接了2个核心和1个SCC,而位于中部两侧的4个CSN连接了1个核心和2个SCC。总体而言,Grace的网格内应该有80个核心和76个SCC,其中8个核心可能由于良率等因素而被屏蔽。而网格外围缺失的4个核心和8个SCC的位置被用于连接NVLink、NVLink-C2C、PCIe和LPDDR5X内存控制器等。
NVIDIA Grace支持Arm的许多管理特性,如服务器基础系统架构(SBSA)、服务器基础启动要求(SBBR)、内存分区与监控(MPAM)和性能监控单元(PMU)。通过Arm的内存分区和监控功能,可以解决由于共享资源竞争而导致的CPU访问缓存过程中性能下降的问题。高优先级的任务可以优先占用L3缓存,或者根据虚拟机预先划分资源,实现业务之间的性能隔离。
 NVIDIA Grace CPU 超级芯片
NVIDIA Grace CPU 超级芯片
作为最新、最强版本的Arm架构核心(Neoverse V2)的代表,NVIDIA Grace引起业界的高度关注,尤其是考虑到它将受益于NVIDIA强大的GPGPU技术。人们在GTC 2023上终于有机会亲眼目睹Grace的实物,但实际市场表现还需要一段时间来验证。大家对Grace在超级计算和机器学习等领域的表现抱有很高的期待。

GTC2023 演讲中展示的 Grace 超级芯片实物
六、网格架构的两类 Chiplet
Ampere One采用流行的Chiplet技术,拥有多达192个核心和384MB L2缓存,这并不令人意外。目前普遍的推测是,它的设计类似于AWS Graviton3即将CPU和缓存单独放置在一个die上,DDR控制器的die位于其两侧,而PCIe控制器的die位于其下方。将CPU核心和缓存与负责外部I/O的控制器分离在不同的die上,是实现服务器CPU的Chiplet的主流做法。

IOD 居 中 的 AMD 第 二 代 EPYC 处 理 器, 与 核 心 die 居 中 的 AWS Graviton3 处理器
正如之前提到的AMD EPYC家族处理器采用星形拓扑结构,将I/O部分集中放置在一个IOD上,而CPU核心和缓存(CCD)则环绕在周围。这是由网格架构的特性所决定的,要求CPU核心和缓存必须位于中央,而I/O部分则分散在外围。因此,当进行拆分时,布局会相反,中央的die会更大,而周围的die会更小。
与EPYC家族的架构相比,网格架构具有更强的整体性,天生具有单体式(Monolithic)结构不太适合拆分。在网格架构中,必须考虑交叉点(节点)的利用率问题,如果有太多的空置交叉点,会导致资源浪费,因此缩小网格规模可能更为有效。
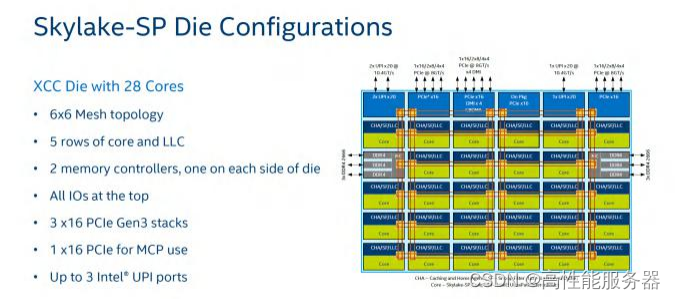
以初代英特尔至强可扩展处理器为例,为了满足核数(Core Count,CC)从4到28的范围变化提供三种不同构型的die(die chop)。其中,6×6的XCC(eXtreme CC,最多核或极多核)支持最多28个核心;6×4的HCC(High CC,高核数)支持最多18个核心;4×4的LCC(Low CC,低核数)支持最多10个核心。
从这个角度来看,Ampere One不支持128核及以下是合理的,除非增加die的构型,但这涉及到公司规模和出货量的支持需要量产来解决。而第四代英特尔至强可扩展处理器提供了两种构型的die。
其中,MCC(Medium CC中等核数)主要满足32核及以下的需求,比代号Ice Lake的第三代英特尔至强可扩展处理器的40核要低,因此网格规模比后者的7×8少了1列为7×7,最多可以安置34个核心及其缓存。而36到60个核心的需求则必须由XCC来满足,它是前面提到的Chiplet版本,将网格架构从中间切割成4等分,非常独特。
XCC版本的第四代英特尔至强可扩展处理器由两种互为镜像的die拼成2×2的大矩阵,因此整体具有高度对称性上下和左右都对称,而前三代产品和同代的MCC版本则没有如此对称。
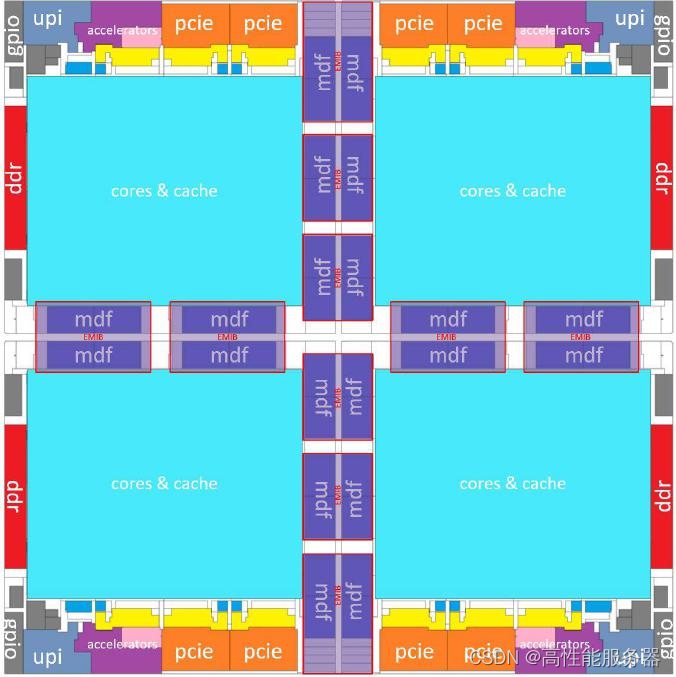
英特尔认为,第四代英特尔至强可扩展处理器(XCC版本)由4个die拼接而成,形成了一个准单体式(quasi-monolithic)的die。单体式的概念比较容易理解常见的网格架构就是这样的。在第四代英特尔至强可扩展处理器中外圈左右是DDR内存控制器,上下是PCIe控制器和集成的加速器(DSA/QAT/DLB/IAA),而UPI位于四个角落,这是典型的网格架构布局。

第四代英特尔至强可扩展处理器的 EMIB 连接
算存互连
Chiplet 与 CXL
“东数西存”是“东数西算”的基础和前奏,而不是子集。其涉及到数据、存储和计算之间的关系。数据通常在人口密集的东部产生,而存储则在地广人稀的西部进行。其中主要难点在于如何以较低的成本完成数据传输。计算需要频繁地访问数据,而在跨地域的情况下,网络的带宽和时延成为难以克服的障碍。
与数据传输和计算相比,存储并不消耗太多能源,但占用大量空间。核心区域始终是稀缺资源,就像核心城市的核心地段不会被用来建设超大规模的数据中心一样,CPU的核心区域也只能留给存储器的硅片面积有限。
实现“东数西算”并非一蹴而就的事情,超大规模的数据中心与核心城市也逐渐疏远而且并不是越远越好。同样围绕CPU已经建立一套分层的存储体系,尽管从高速缓存到内存都属于易失性存储器(内存)但通常那些处于中间状态的数据对访问时延的要求更高,因此需要更靠近核心。如果是需要长期保存的数据,离核心远一些也没有关系,而访问频率较低的数据可以存储在较远的位置(西存)。
距离CPU核心最近的存储器是各级缓存(Cache),除了基于SRAM的各级Cache之外。即使在缓存中也存在远近之分。在现代CPU中,L1和L2缓存已经成为核心的一部分则需要考虑占用面积的主要是L3缓存。
一、SRAM 的面积律
现在是2023年制造工艺正在向3纳米迈进。台积电公布其N3制程的SRAM单元面积为0.0199平方微米,相比N5制程的面积为0.021平方微米,仅缩小了5%。更为困扰的是由于良率和成本问题,预计N3并不会成为台积电的主力工艺客户们更关注第二代3纳米工艺N3E。而N3E的SRAM单元面积为0.021平方微米与N5工艺完全相同。
就成本而言据传N3一片晶圆的成本为2万美元而N5的报价为1.6万美元,这意味着N3的SRAM比N5贵25%。作为参考Intel的7纳米制程(10纳米)的SRAM面积为0.0312平方微米Intel的4纳米制程(7纳米)的SRAM面积为0.024平方微米与台积电的N5和N3E工艺相当。
尽管半导体制造商的报价是商业机密但SRAM的价格越来越高,密度也难以再提高。因此将SRAM单独制造并与先进封装技术结合,以实现高带宽和低时延成为一种合理的选择。

二、向上堆叠,翻越内存墙
当前,AMD的架构面临内存性能落后的问题。其中原因包括核心数量较多导致平均每个核心的内存带宽偏小、核心与内存的距离较远导致延迟较大以及跨CCD的带宽过小等。为了弥补访问内存的劣势,AMD需要使用较大规模的L3缓存。
然而,从Zen 2到Zen 4架构,AMD每个CCD的L3缓存仍然保持32MB的容量并没有与时俱进。为了解决SRAM规模滞后的问题,AMD决定将扩容SRAM的机会独立于CPU之外。在代号为Milan-X的EPYC 7003X系列处理器上,AMD应用了第一代3D V-Cache技术。这些处理器采用Zen 3架构核心,每个缓存(L3缓存芯片,简称L3D)的容量为64MB,面积约为41mm²采用7纳米工艺制造。
缓存芯片通过混合键合、TSV(Through Silicon Vias,硅通孔)工艺与CCD(背面)垂直连接。该单元包含4个组成部分:最底层的CCD、上层中间部分L3D、以及上层两侧的支撑结构,采用硅材质以在垂直方向上平衡整个结构并将下方CCX(Core Complex,核心复合体)部分的热量传导到顶盖。

Zen4 CCD 的布局,请感受一下 L3 Cache 的面积
在Zen 3架构核心设计之初AMD就预留了必要的逻辑电路和TSV电路,相关部分大约使CCD的面积增加4%。L3D的堆叠位置恰好位于CCD的L2/L3缓存区域上方。这一设计既符合双向环形总线内CCD中缓存居中、CPU核心分布在两侧的布局。又考虑到(L3)缓存的功率密度相对较低于CPU核心,有利于控制整个缓存区域的发热量。

3D V-Cache 结构示意图
Zen 3架构的L3缓存由8个切片组成每片4MB;而L3D设计为8个切片每片8MB。两组缓存的每个切片之间有1024个TSV连接,总共有8192个连接。AMD声称这额外的L3缓存只会增加4个周期的延迟。
随着Zen 4架构处理器的推出,第二代3D V-Cache也登场了。它的带宽从上一代的2TB/s提升到2.5TB/s容量仍然为64MB,制程仍然是7纳米,但面积缩减到了36mm²。这个面积的缩减主要来自TSV部分,AMD声称在TSV的最小间距没有缩小的情况下,相关区域的面积缩小了50%。代号为Genoa-X的EPYC系列产品预计将于2023年中发布。
增加SRAM容量可以大幅提高缓存命中率,减少内存延迟对性能的影响。AMD的3D V-Cache以相对合理的成本实现了缓存容量的巨大提升(在CCD内L3缓存的基础上增加了2倍),对性能的改进也非常明显。

应用 3D V-Cache 的 AMD EPYC 7003X 处理器
三、HBM 崛起:从 GPU 到 CPU
HBM(High Bandwidth Memory)是一种由AMD和SK海力士于2014年共同发布的技术,它使用TSV技术将多个DRAM芯片堆叠在一起,大幅提高容量和数据传输速率。随后三星、美光、NVIDIA、Synopsys等公司也积极参与这一技术路线。标准化组织JEDEC也将HBM2列入了标准(JESD235A)并陆续推出了HBM2e(JESD235B)和HBM3(JESD235C)。主要得益于堆叠封装和巨大的位宽(单封装1024位),HBM提供远远超过其他常见内存形式(如DDR DRAM、LPDDR、GDDR等)的带宽和容量。
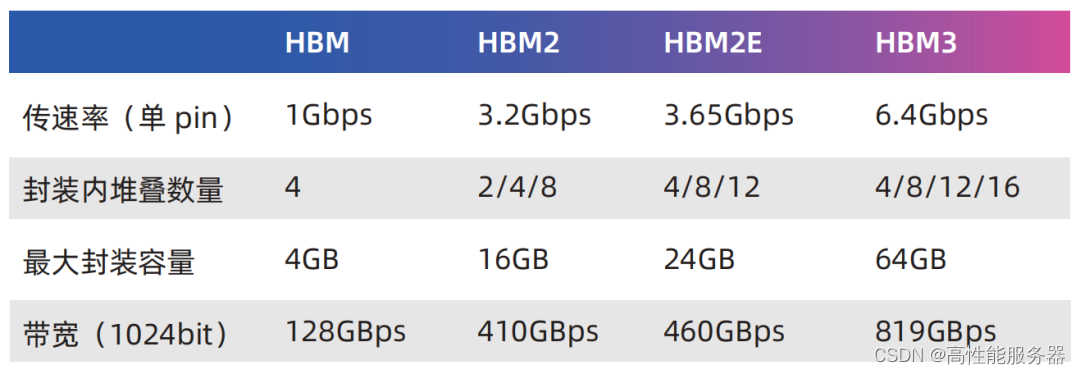
典型的实现方式是通过2.5D封装与处理器核心连接,在CPU、GPU等产品中广泛应用。早期有人将HBM视为L4缓存,从TB/s级别的带宽来看这个观点也是合理的。而从容量的角度来看HBM比SRAM或eDRAM要大得多。
因此,HBM既可以胜任(一部分)缓存的工作也可以作为高性能内存使用。AMD是HBM的早期采用者,目前AMD Instinct MI250X计算卡在单一封装内集成了2颗计算核心和8颗HBM2e,总容量为128GB,带宽达到3276.8GB/s。NVIDIA主要在专业卡中应用HBM其2016年的TESLA P100 HBM版配备了16GB HBM2,随后的V100则配备了32GB HBM2。目前热门的A100和H100也都有HBM版,前者最大提供80GB HBM2e,带宽约为2TB/s;后者升级到HBM3,带宽约为3.9TB/s。华为的昇腾910处理器也集成了4颗HBM。
对于计算卡、智能网卡、高速FPGA等产品来说,HBM作为GDDR的替代品,应用已非常成熟。CPU也已经开始集成HBM,其中最突出的案例是曾经问鼎超算TOP500的富岳(Fugaku),它采用富士通研发的A64FX处理器。A64FX基于Armv8.2-A架构,采用7纳米制程,在每个封装中集成了4颗HBM2,总容量为32GB,带宽为1TB/s。

富士通 A64FX CPU
四、向下发展:基础层加持
英特尔数据中心Max GPU系列引入了Base Tile的概念,可以将其看作是基础芯片。相对于中介层的概念,我们也可以将基础芯片视为基础层。表面上看基础层和硅中介层的功能类似,都用于承载计算核心和高速I/O(如HBM),但实际上基础层的功能更加丰富。
硅中介层主要利用成熟的半导体光刻、沉积等工艺(如65纳米级别),在硅上形成高密度的电气连接。而基础层更进一步:既然已经在加工多层图案,为什么不将逻辑电路等功能也整合进去呢?

英特尔数据中心 Max GPU
在ISSCC 2022上,英特尔展示了英特尔数据中心Max GPU的Chiplet(小芯片)架构。其中基础芯片的面积为640mm²,采用了英特尔7纳米制程,这是目前英特尔用于主流处理器的先进制程。为什么在"基础"芯片上需要使用先进制程呢?这是因为英特尔将高速I/O的SerDes都集成在基础芯片中,类似于AMD的IOD。这些高速I/O包括HBM PHY、Xe Link PHY、PCIe 5.0以及缓存等。这些电路都更适合使用5纳米及以上的工艺制造,将它们与计算核心解耦后重新打包在同一制程内是一个相当合理的选择。
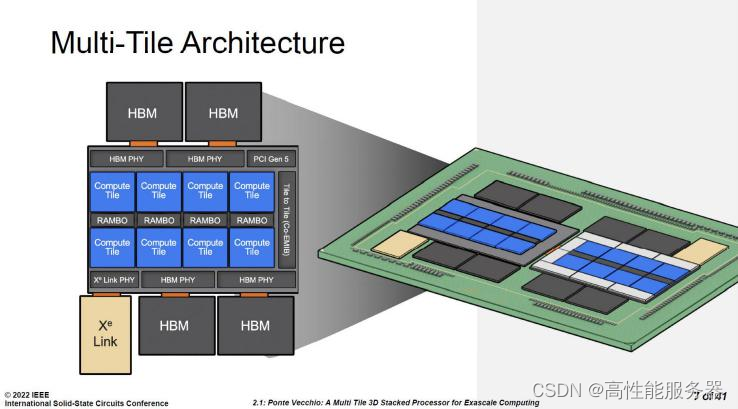
英特尔数据中心 Max GPU 的 Chiplet 架构
英特尔数据中心Max GPU系列通过Foveros封装技术,在基础芯片上方叠加了8颗计算芯片(Compute Tile)和4颗RAMBO芯片(RAMBO Tile)。计算芯片采用台积电N5工艺制造,每颗芯片拥有4MB的L1 Cache。RAMBO是"Random Access Memory Bandwidth Optimized"的缩写,即带宽优化的随机访问存储器。独立的RAMBO芯片基于英特尔7纳米制程,每颗芯片有4个3.75MB的Bank,总共提供15MB的容量。每组4颗RAMBO芯片共提供了60MB的L3 Cache。此外,在基础芯片中还有一个容量为144MB的RAMBO,以及L3 Cache的交换网络(Switch Fabric)。
因此,在英特尔数据中心Max GPU中,基础芯片通过Cache交换网络将基础层内的144MB Cache与8颗计算芯片和4颗RAMBO芯片的60MB Cache组织在一起,总共提供了204MB的L2/L3 Cache。整个封装由两组组成,即总共408MB的L2/L3 Cache。每组处理单元通过Xe Link Tile与其他7组进行连接。Xe Link芯片采用台积电N7工艺制造。

X HPC 的逻辑架构
前面已经提到,I/O 芯片独立是大势所趋,共享 Cache 与 I/O 拉近也是趋势。英特尔数据中心 Max GPU 将 Cache 与各种高 速 I/O 的 PHY 集成在同一芯片内,正是前述趋势的集大成者。 至于 HBM、Xe Link 芯片,以及同一封装内相邻的基础芯片,则 通过 EMIB(爆炸图中的橙色部分)连接在一起。

英特尔数据中心 Max GPU 爆炸图
根据英特尔在 HotChips 上公布的数据,英特尔数据中心 Max GPU 的 L2 Cache 总带宽可以达到 13TB/s。考虑到封装了两组基础芯片和计算芯片给带宽打个对折,基础芯片和 4 颗 RAMBO 芯片的带宽是 6.5TB/s,依旧远远超过目前至强和 EPYC 的 L2、L3 Cache 的带宽。其实之前 AMD 已经通过指甲盖大小的 3D V-Cache 证明 3D 封装的性能,那就更不用说英特尔数据中心 Max GPU 的 RAMBO 及基础芯片的面积。

回顾一下3D V-Cache的一个弱点即散热不良。我们还发现将Cache集成到基础芯片中有一个优点:将高功耗的计算核心安排在整个封装的上层,更有利于散热。进一步观察在网格化的处理器架构中L3 Cache并不是简单的几个块(切片),而是分成数十甚至上百个单元分别连接到网格节点上。基础芯片在垂直方向上可以完全覆盖或容纳处理器芯片,其中的SRAM可以分成相等数量的单元与处理器的网格节点相连接。
目前已经成熟的3D封装技术中,凸点间距在30到50微米的范围内足以满足每平方毫米内数百至数千个连接的需求,可以满足当前网格节点带宽的需求。当然更高密度的连接也是可行的,10微米甚至亚微米的技术正在不断推进中,但优先考虑的场景是HBM、3D NAND等高度定制化的内部堆栈混合键合,可能并不适合Chiplet对灵活性的需求。
五、标准化:Chiplet 与 UCIe
为了实现这一愿景,2022年3月,通用处理器市场的核心参与者,包括Intel、AMD、Arm等,共同发布新的互联标准UCIe(Universal Chiplet Interconnect Express通用小芯片互连通道),旨在解决Chiplet的行业标准化问题。这一标准的推出将有助于推动Chiplet技术的发展和应用。

由于标准的主导者与PCIe和CXL(Compute Express Link)已经有密切的关系,因此UCIe非常强调与PCIe/CXL的协同,提供在协议层本地端进行PCIe和CXL协议映射的功能。与CXL的协同说明UCIe的目标不仅仅是解决芯片制造中的互联互通问题,而是希望芯片与设备、设备与设备之间的交互是无缝的。
在UCIe 1.0标准中展现两种层面的应用:Chiplet(封装内)和Rack space(封装外)。这意味着UCIe可以在芯片内部实现Chiplet之间的互联,同时也可以在封装外部实现芯片与设备之间的互联。这种灵活性使得UCIe能够适应不同的应用场景。
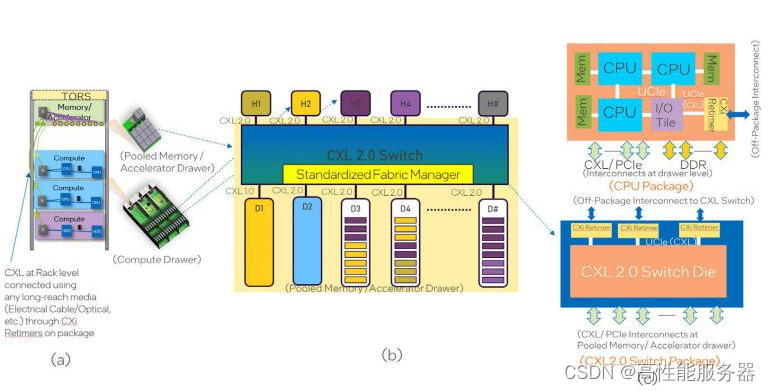
UCIe 规划的机架连接交给了 CXL
1、CXL:内存的解耦与扩展
相对于PCIe,CXL最重要的价值在于减少各子系统内存的访问延迟(理论上PCIe的延迟为100纳秒级别而CXL为10纳秒级别)。例如GPU访问系统内存时,这对于设备之间的大容量数据交换至关重要。这种改进主要源于两个方面:
首先,PCIe在设计之初并没有考虑缓存一致性问题。当通过PCIe进行跨设备的DMA读写数据时,在操作延迟期间,内存数据可能已经发生变化,因此需要额外的验证过程,这增加了指令复杂度和延迟。而CXL通过CXL.cache和CXL.memory协议解决缓存一致性问题,简化操作也减少延迟。
其次,PCIe的初衷是针对大流量进行优化,针对大数据块(512字节、1KB、2KB、4KB)进行优化,希望减少指令开销。而CXL则针对64字节传输进行优化,对于固定大小的数据块而言操作延迟较低。换句话说,PCIe的协议特点更适合用于以NVMe SSD为代表的块存储设备,而对于注重字节级寻址能力的计算型设备CXL更为适合。
除充分释放异构计算的算力,CXL还让内存池化的愿景看到了标准化的希望。CXL Type 3设备的用途是内存缓冲,利用CXL.io和CXL.memory的协议实现扩展远端内存。在扩展后,系统内存的带宽和容量即为本地内存和CXL内存模块的叠加。
在新一代CPU普遍支持的CXL 1.0/1.1中,CXL内存模块首先实现主机级的内存扩展,试图突破传统CPU内存控制器的发展瓶颈。CPU核心数量增长的速度远远快于内存通道的增加速度是其中的原因。
在过去的十年间CPU的核心数量从8到12个增长到了60甚至96个核心,而每个插槽CPU的内存通道数仅从4通道增加到8或12通道。每个通道的内存在此期间也经历三次大的迭代,带宽大约增加1.5到2倍,存储密度大约增加4倍。从发展趋势来看,每个CPU核心所能分配到的内存通道数量在明显下降,每个核心可以分配的内存容量和内存带宽也有所下降。这是内存墙的一种表现形式,导致CPU核心无法充分获取数据以处于满负荷的运行状态,从而导致整体计算效率下降。

2、UCIe 与异构算力
随着人工智能时代的到来,异构计算已经成为常态。原则上只要功率密度允许,这些异构计算单元的高密度集成可以由UCIe完成。除集成度的考虑,标准化的Chiplet还带来功能和成本的灵活性。对于不需要的单元,在制造时可以不参与封装,而对于传统处理器而言,无用的单元常常成为无用的"暗硅",意味着成本的浪费。一个典型的例子是DSA,如英特尔第四代可扩展至强处理器中的若干加速器,用户可以付费开启,但是如果用户不付费,这些DSA其实已经制造出来。

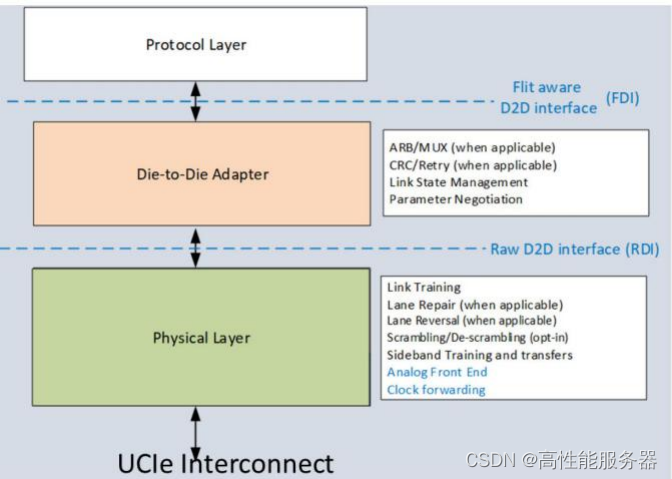
UCIe包括协议层(Protocol Layer)、适配层(Adapter Layer)和物理层(Physical Layer)。协议层支持PCIe 6.0、CXL 2.0和CXL 3.0同时也支持用户自定义的协议。根据不同的封装等级,UCIe还提供不同的Package模块。通过使用UCIe的适配层和PHY替换PCIe/CXL的PHY和数据包可以实现更低功耗和性能更优的Die-to-Die互连接口。
UCIe考虑了两种不同等级的封装:标准封装(Standard Package)和先进封装(Advanced Package)。这两种封装在凸块间距、传输距离和能耗方面存在数量级的差异。例如,对于先进封装,凸块间距(Bump Pitch)为25~55μm,代表采用硅中介层的2.5D封装技术特点。以英特尔的EMIB为例,当前的凸块间距约为50μm,未来将演进至25μm甚至10μm。台积电的InFO、CoWoS等也具有类似的规格和演进趋势。而标准封装(2D)的规格则对应目前应用最广泛的有机载板。

不同封装的信号密度也存在本质差异。标准封装模块对应的是16对数据线(TX、RX),而高级封装模块则包含64对数据线。每32个数据管脚还额外提供2个用于Lane修复的管脚。如果需要更大的带宽,可以扩展更多的模块并且这些模块的频率是可以独立设置的。
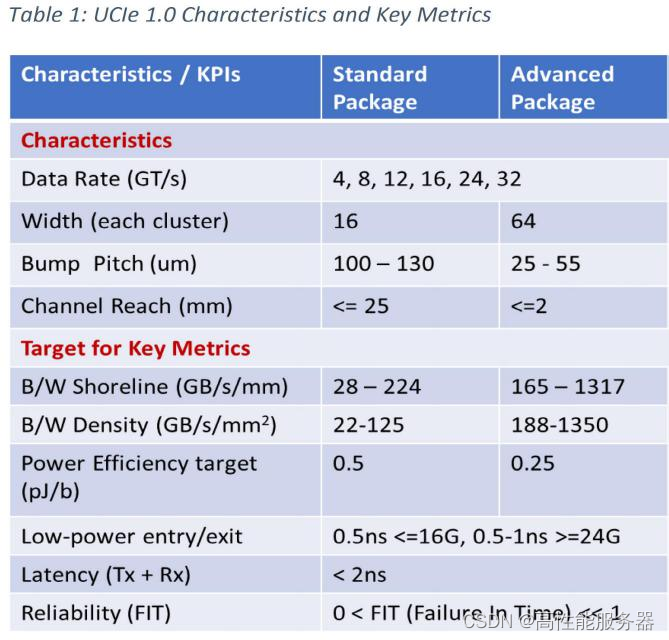
需要特别提到的是,UCIe与高速PCIe的深度集成使其更适合高性能应用。实际上,SoC(片上系统)是一个广义的概念而UCIe面向的是宏观系统级的集成。传统观念中适合低成本、高密度的SoC可能需要集成大量的收发器、传感器、块存储设备等。例如,一些面向边缘场景的推理应用和视频流处理的IP设计企业非常活跃,这些IP可能需要更灵活的商品化落地方式。由于UCIe不考虑相对低速设备的集成,低速、低成本接口的标准化仍然有空间。
算力互连
由内及外,由小渐大
随着"东数西算"工程的推进,出现了细分场景如"东数西渲"和"东数西训"。视频渲染和人工智能(AI)/机器学习(ML)的训练任务本质上都是离线计算或批处理,可以在"东数西存"的基础上进行。即原始素材或历史数据传输到西部地区的数据中心后,在该地区独立完成计算过程,与东部地区的数据中心交互较少,因此不会受到跨地域时延的影响。换句话说,"东数西渲"和"东数西训"的业务逻辑成立是因为计算与存储仍然就近耦合,不需要面对跨地域的"存算分离"挑战。
在服务器内部,CPU和GPU之间存在类似但不同的关系。对于当前热门的大模型来说,对计算性能和内存容量都有很高的要求。然而,CPU和GPU之间存在一种"错配"现象:GPU的AI算力明显高于CPU,但直接的内存(显存)容量通常不超过100GB,与CPU的TB级内存容量相比相差一个数量级。幸运的是CPU和GPU之间的距离可以缩短,带宽可以提升。通过消除互连瓶颈,可以大大减少不必要的数据移动,提高GPU的利用率。
一、为GPU而生的CPU
NVIDIA Grace CPU的核心基于Arm Neoverse V2架构,其互连架构SCF(可扩展一致性结构)可以看作是定制版的Arm CMN-700网格。然而在外部I/O方面,NVIDIA Grace CPU与其他Arm和x86服务器有很大不同,这体现NVIDIA开发这款CPU的主要意图,即为需要高速访问大内存的GPU提供服务。
在内存方面,Grace CPU具有16个LPDDR5X内存控制器,这些内存控制器对应着封装在一起的8个LPDDR5X芯片,总容量为512GB。经过ECC开销后,可用容量为480GB。因此可以推断有一个内存控制器及其对应的LPDDR5X内存die用于ECC。根据NVIDIA官方资料,与512GB内存容量同时出现的内存带宽参数是546GB/s而与480GB(带ECC)同时出现的是约500GB/s,实际的内存带宽应该在512GB/s左右。
PCIe控制器是必不可少的Arm CPU的惯例是将部分PCIe通道与CCIX复用,但这样的CCIX互连带宽相对较弱,不如英特尔专用于CPU间互连的QPI/UPI。
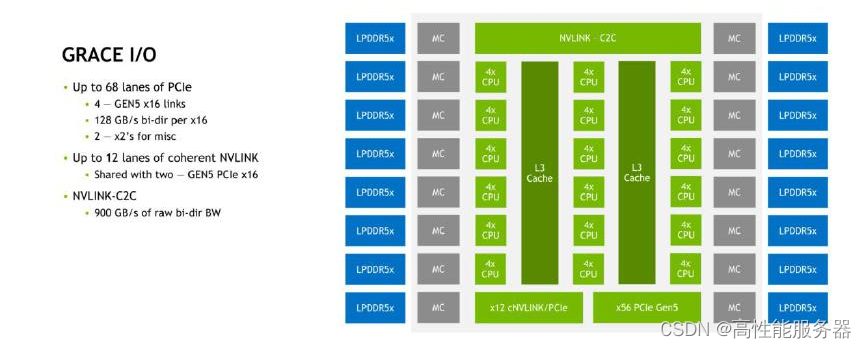
NVIDIA Grace CPU提供68个PCIe 5.0通道,其中有2个x16通道可以用作12通道一致性NVLink(cNVLINK)。真正用于芯片(CPU/GPU)之间互连的是cNVLINK/PCIe隔"核"相望的NVLink-C2C接口,其带宽高达900GB/s。
NVLink-C2C中的C2C代表芯片到芯片之间的连接。根据NVIDIA在ISSCC 2023论文中的描述,NVLink-C2C由10组连接组成(每组9对信号和1对时钟),采用NRZ调制,工作频率为20GHz,总带宽为900GB/s。每个封装内的传输距离为30mm,PCB上的传输距离为60mm。对于NVIDIA Grace CPU超级芯片,使用NVLink-C2C连接两个CPU可以构成一个144核的模块;而对于NVIDIA Grace Hopper超级芯片,即将Grace CPU和Hopper GPU进行互联。
NVLink-C2C的900GB/s带宽是非常惊人的数据。作为参考,Intel代号为Sapphire Rapids的第四代至强可扩展处理器包含3或4组x24 UPI 2.0(@16GT/s)多个处理器之间的总带宽接近200GB/s;而AMD第四代EPYC处理器使用的GMI3接口用于CCD与IOD之间的互联带宽为36GB/s,而CPU之间的Infinity Fabric相当于16通道PCIe 5.0,带宽为32GB/s。在双路EPYC 9004之间可以选择使用3或4组Infinity Fabric互联,4组的总带宽为128GB/s。

通过巨大的带宽,两颗Grace CPU可以被紧密联系在一起,其"紧密"程度远超传统的多路处理器系统,已经足以与基于有机载板的大多数芯片封装方案(2D封装)相匹敌。要超越这个带宽,需要引入硅中介层(2.5D封装)的技术。例如,苹果M1 Ultra的Ultra Fusion架构利用硅中介层连接两颗M1 Max芯粒。苹果声称Ultra Fusion可以同时传输超过10,000个信号,实现高达2.5TB/s的低延迟处理器互联带宽。Intel的EMIB也是一种2.5D封装技术,其芯粒间的互联带宽也应当达到TB级别。
NVLink-C2C的另一个重要应用案例是GH200 Grace Hopper超级芯片,它将一颗Grace CPU与一颗Hopper GPU进行互联。Grace Hopper是世界上第一位著名的女性程序员,也是"bug"术语的发明者。因此,NVIDIA将这一代CPU和GPU分别命名为Grace和Hopper,这个命名实际上有着深刻的意义,充分说明在早期规划中,它们就是紧密结合的关系。

NVIDIA Grace Hopper 超级芯片主要规格
CPU和GPU之间的数据交换效率(带宽、延迟)在超大机器学习模型时代尤为重要。NVIDIA为Hopper GPU配备了大容量高速显存,全开启6组显存控制器,容量达到96GB,带宽达到3TB/s。
相比之下,独立的GPU卡H100的显存配置为80GB,而H100 NVL的双卡组合则为188GB。Grace CPU搭载了480GB的LPDDR5X内存,带宽略超过500GB/s。尽管Grace的内存带宽与使用DDR5内存的竞品相当,但CPU与GPU之间的互连才是决定性因素。典型的x86 CPU只能通过PCIe与GPU通信而NVLink-C2C的带宽远超PCIe并具有缓存一致性的优势。
通过NVLink-C2C Hopper GPU可以顺畅地访问CPU内存超过H100 PCIe和H100 SXM。此外,高带宽的直接寻址还可以转化为容量优势,使Hopper GPU能够寻址576GB的本地内存。
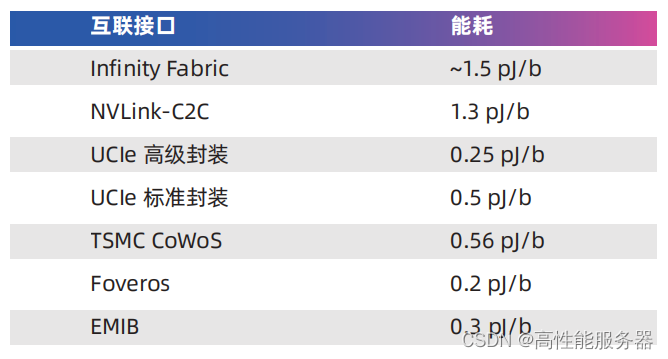
CPU拥有的内存容量是GPU无法比拟的,而GPU到CPU之间的互连(PCIe)是瓶颈。NVLink-C2C的带宽和能效比优势是GH200 Grace Hopper超级芯片相对于x86+GPU方案的核心优势之一。NVLink-C2C每传输1比特数据仅消耗1.3皮焦耳能量大约是PCIe 5.0的五分之一具有25倍的能效差异。需要注意的是这种比较并不完全公平,因为PCIe是板间通信,与NVLink-C2C的传输距离有本质区别。
NVLink最初是为了实现高速GPU之间的数据交换而设计的,通过NVSwitch的帮助,可以将服务器内部的多个GPU连接在一起,形成一个容量成倍增加的显存池。
二、NVLink 之 GPU 互连
NVLink的目标是突破PCIe接口的带宽瓶颈,提高GPU之间交换数据的效率。2016年发布的P100搭载了第一代NVLink,提供160GB/s的带宽,相当于当时PCIe 3.0 x16带宽的5倍。V100搭载的NVLink2将带宽提升到300GB/s 接近PCIe 4.0 x16的5倍。A100搭载了NVLink3带宽为600GB/s。
H100搭载的是NVLink4,相对于NVLink3,NVLink4不仅增加了链接数量,内涵也有比较重大的变化。NVLink3中,每个链接通道使用4个50Gb/s差分对,每通道单向25GB/s,双向50GB/s。A100使用12个NVLink3链接,总共构成了600GB/s的带宽。NVLink4则改为每链接通道使用2个100Gb/s差分对,每通道双向带宽依旧为50GB/s,但线路数量减少了。
在H100上可以提供18个NVLink4链接总共900GB/s带宽。NVIDIA的GPU大多提供NVLink接口,其中PCIe版本可以通过NVLink Bridge互联,但规模有限。更大规模的互联还是得通过主板/基板上的NVLink进行组织,与之对应的GPU有NVIDIA私有的规格SXM。
SXM规格的NVIDIA GPU主要应用于数据中心场景其基本形态为长方形,正面看不到金手指属于一种mezzanine卡,采用类似CPU插座的水平安装方式"扣"在主板上,通常是4-GPU或8-GPU一组。其中4-GPU的系统可以不通过NVSwitch即可彼此直连,而8-GPU系统需要使用NVSwitch。
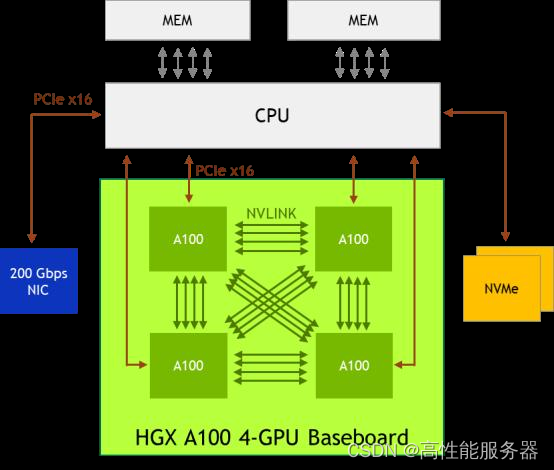
NVIDIA HGX A100 4-GPU 系 统 的 组 织 结 构。 每 个 A100 的 12 条 NVLink 被均分为 3 组,分别与其他 3 个 A100 直联
经过多代发展,NVLink已经日趋成熟,并开始应用于GPU服务器之间的互连,进一步扩大GPU(以及其显存)集群的规模。

NVIDIA HGX H100 8-GPU 系 统 的 组 织 结 构。 每 个 H100 的 18 条 NVLink 被分为 4 组,分别与 4 个 NVSwitch 互联。
三、NVLink 组网超级集群
在2023年5月底召开的COMPUTEX上,英伟达宣布了由256个Grace Hopper超级芯片组成的集群,总共拥有144TB的GPU内存。大语言模型(LLM)如GPT对显存容量的需求非常迫切,巨大的显存容量符合大模型的发展趋势。那么,这个前所未见的容量是如何实现的呢?
其中一个重大创新是NVLink4 Networks,它使得NVLink可以扩展到节点之外。通过DGX A100和DGX H100构建的256-GPU SuperPOD的架构图,可以直观地感受到NVLink4 Networks的特点。在DGX A100 SuperPOD中,每个DGX节点的8个GPU通过NVLink3互联,而32个节点则需要通过HDR InfiniBand 200G网卡和Quantum QM8790交换机互联。在DGX H100 SuperPOD中,节点内部采用NVLink4互联8个GPU,节点之间通过NVLink4 Network互联,各节点接入了称为NVLink Switch的设备。
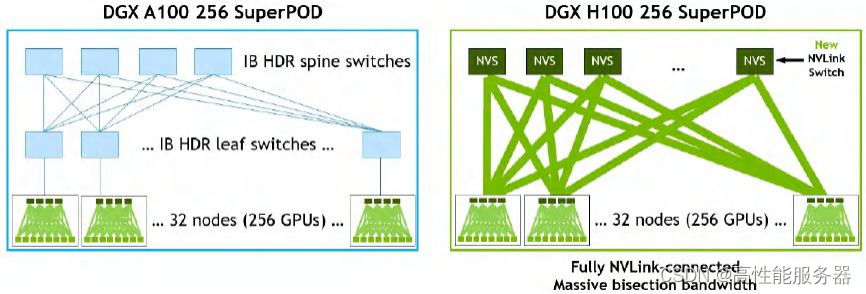
DGX A100 和 DGX H100 256 SuperPOD 架构
根据NVIDIA提供的架构信息NVLink Network支持OSFP(Octal Small Form Factor Pluggable)光口,这也符合NVIDIA声称的线缆长度从5米增加到20米的说法。DGX H100 SuperPOD使用的NVLink Switch规格为:端口数量为128个,有32个OSFP笼(cage),总带宽为6.4TB/s。
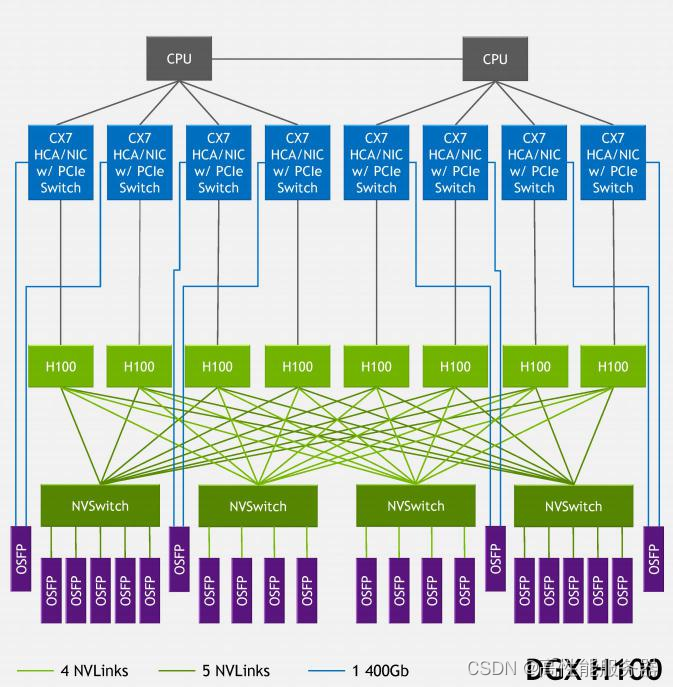 DGX H100 SuperPOD 节点内部的网络架构
DGX H100 SuperPOD 节点内部的网络架构
每个8-GPU节点内部有4个NVSwitch,对于DGX H100 SuperPOD每个NVSwitch都通过4或5条NVLink对外连接。每条NVLink的带宽为50GB/s,对应一个OSFP口相当于400Gb/s,非常成熟。每个节点总共需要连接18个OSFP接口,32个节点共需要576个连接,对应18台NVLink Switch。
DGX H100也可以(仅)通过InfiniBand互联,参考DGX H100 BasePOD的配置,其中的DGX H100系统配置了8个H100、双路56核第四代英特尔至强可扩展处理器、2TB DDR5内存,搭配了4块ConnectX-7网卡——其中3块双端口卡用于管理和存储服务,还有一块4个OSFP口的用于计算网络。
回到Grace Hopper超级芯片,NVIDIA提供了一个简化的示意图其中的Hopper GPU上的18条NVLink4与NVLink Switch相连。NVLink Switch连接了"两组"Grace Hopper超级芯片。任何GPU都可以通过NVLink-C2C和NVLink Switch访问网络内其他CPU、GPU的内存。
NVLink4 Networks的规模是256个GPU,注意是GPU而不是超级芯片,因为NVLink4连接是通过H100 GPU提供的。对于Grace Hopper超级芯片,这个集群的内存上限就是:(480GB内存+96GB显存)×256节点=147456GB,即144TB的规模。假如NVIDIA推出了GTC2022中提到的Grace + 2Hopper,那么按照NVLink Switch的接入能力,那就是128个Grace和256个Hopper,整个集群的内存容量将下降至约80TB的量级。
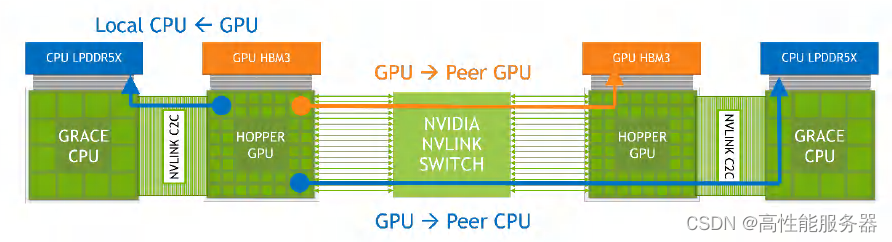
Grace Hooper 超级芯片之间的互联
在COMPUTEX 2023期间,NVIDIA宣布Grace Hopper超级芯片已经量产,并发布了基于此的DGX GH200超级计算机。NVIDIA DGX GH200使用了256组Grace Hopper超级芯片,以及NVLink互联,整个集群提供高达144TB的可共享的"显存",以满足超大模型的需求。以下是一些数字,让我们感受一下NVIDIA打造的E级超算系统的规模:
-
算力:1 exa Flops (FP8)
-
光纤总长度:150英里
-
风扇数量:2112个(60mm)
-
风量:7万立方英尺/分钟(CFM)
-
重量:4万磅
-
显存:144TB NVLink
-
带宽:230TB/s
从150英里的光纤长度,我们可以感受到其网络的复杂性。这个集群的整体网络资源如下:

由于Grace Hopper芯片上只有一个CPU和一个GPU,与DGX H100相比GPU的数量要少得多。要达到256个GPU所需的节点数大大增加,这导致NVLink Network的架构变得更加复杂。
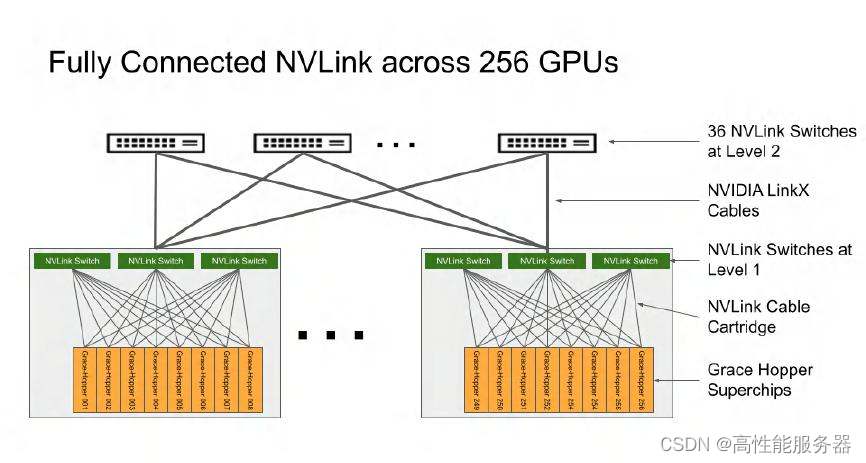
NVIDIA DGX GH200 集群内的 NVLink 网络架构
DGX GH200的每个节点有3组NVLink对外连接,每个NVLink Switch连接8个节点。256个节点总共分为32组,每组8个节点搭配3台L1 NVLink Switch,共需要使用96台交换机。这32组网络还要通过36台L2 NVLink Switch组织在一起。
与DGX H100 SuperPOD相比GH200的节点数量大幅增加,NVLink Network的复杂度明显提高了。以下是二者的对比:

三、InfiniBand 扩大规模
如果需要更大规模(超过256个GPU)的集群就需要引入InfiniBand交换机。对于Grace Hopper超级芯片的大规模集群NVIDIA建议采用Quantum-2交换机组网提供NDR 400 Gb/s端口。每个节点配置BlueField-3 DPU(已集成ConnectX-7),每个DPU提供2个400Gb/s端口,总带宽达到100GB/s。理论上使用以太网连接也可以达到类似的带宽水平,但考虑到NVIDIA收购Mellanox,倾向于使用InfiniBand是可以理解的。

NVIDIA BlueField-3 DPU
基于InfiniBand NDR400组织的Grace Hopper超级芯片集群有两种架构。一种是完全采用InfiniBand连接,另一种是混合配置NVLink Switch和InfiniBand连接。这两种架构的共同点是每个节点都通过双端口(总共800Gbps)连接InfiniBand交换机,DPU占用x32的PCIe 5.0并由Grace CPU提供PCIe连接。它们的区别在于后者每个节点还通过GPU接入NVLink Switch连接,形成若干NVLink子集群。
很显然混合配置InfiniBand和NVLink Switch的方案性能更好,因为部分GPU之间具有更大的带宽以及对内存的原子操作。例如,NVIDIA计划打造超级计算机Helios,它将由4个DGX GH200系统组成,并通过Quantum-2 InfiniBand 400 Gb/s网络组织起来。

四、从 H100 NVL 的角度再看 NVLink
在GTC 2023上,NVIDIA发布了专为大型语言模型部署的NVIDIA H100 NVL。与H100家族的其他两个版本(SXM和PCIe)相比,它具有两个特点:首先,H100 NVL相当于将两张H100 PCIe通过3块NVLink桥接连接在一起;其次,每张卡都具有接近完整的94GB显存,甚至比H100 SXM5还要多。
根据NVIDIA官方文档的介绍H100 PCIe的双插槽NVLink桥接延续了上一代的A100 PCIe,因此H100 NVL的NVLink互连带宽为600GB/s仍然比通过PCIe 5.0互连(128GB/s)高出4倍以上。H100 NVL由两张H100 PCIe卡组合而成,适用于推理应用高速NVLink连接使得显存容量高达188GB以满足大型语言模型的(推理)需求。如果将H100 NVL的NVLink互连视为缩水版的NVLink-C2C,这有助于理解NVLink通过算力单元加速内存访问的原理。
蓝海大脑高性能大模型训练平台利用工作流体作为中间热量传输的媒介,将热量由热区传递到远处再进行冷却。支持多种硬件加速器,包括CPU、GPU、FPGA和AI等,能够满足大规模数据处理和复杂计算任务的需求。采用分布式计算架构,高效地处理大规模数据和复杂计算任务,为深度学习、高性能计算、大模型训练、大型语言模型(LLM)算法的研究和开发提供强大的算力支持。具有高度的灵活性和可扩展性,能够根据不同的应用场景和需求进行定制化配置。可以快速部署和管理各种计算任务,提高了计算资源的利用率和效率。

总结
在计算领域,CPU和GPU是两个关键的组件其在处理数据和执行任务时具有不同的特点和复杂性。随着计算需求的增加,单一的CPU或GPU已经无法满足高性能计算的要求。因此,多元算力的结合和算存互连、算力互连的重要性日益凸显。
作为计算机系统的核心,CPU具有高度灵活性和通用性,适用于广泛的计算任务。它通过复杂的指令集和优化的单线程性能,执行各种指令和处理复杂的逻辑运算。然而随着计算需求的增加,单一的CPU在并行计算方面的能力有限,无法满足高性能计算的要求。
GPU最初设计用于图形渲染和图像处理,但随着时间的推移,其计算能力得到了极大的提升,成为了高性能计算的重要组成部分。GPU具有大规模的并行处理单元和高带宽的内存,能够同时执行大量的计算任务。然而,GPU的复杂性主要体现在其并行计算架构和专业化的指令集,这使得编程和优化GPU应用程序更具挑战性。
为了充分利用CPU和GPU的优势,多元算力的结合变得至关重要。通过将CPU和GPU结合在一起,可以实现任务的并行处理和分工协作。CPU负责处理串行任务和控制流,而GPU则专注于大规模的并行计算。这种多元算力的结合可以提高整体的计算性能和效率,并满足不同应用场景的需求。
算存互连是指计算单元和存储单元之间的高速互联,而算力互连是指计算单元之间的高速互联。在高性能计算中,数据的传输和访问速度对整体性能至关重要。通过优化算存互连和算力互连,可以减少数据传输的延迟和瓶颈,提高计算效率和吞吐量。高效的算存互连和算力互连可以确保数据的快速传输和协同计算,从而提高系统的整体性能。
CPU和GPU在计算领域扮演着重要的角色,但单一的CPU或GPU已经无法满足高性能计算的需求。多元算力的结合、算存互连和算力互连成为了提高计算性能和效率的关键。通过充分利用CPU和GPU的优势,并优化算存互连和算力互连,可以实现更高水平的计算能力和应用性能,推动计算技术的发展和创新。