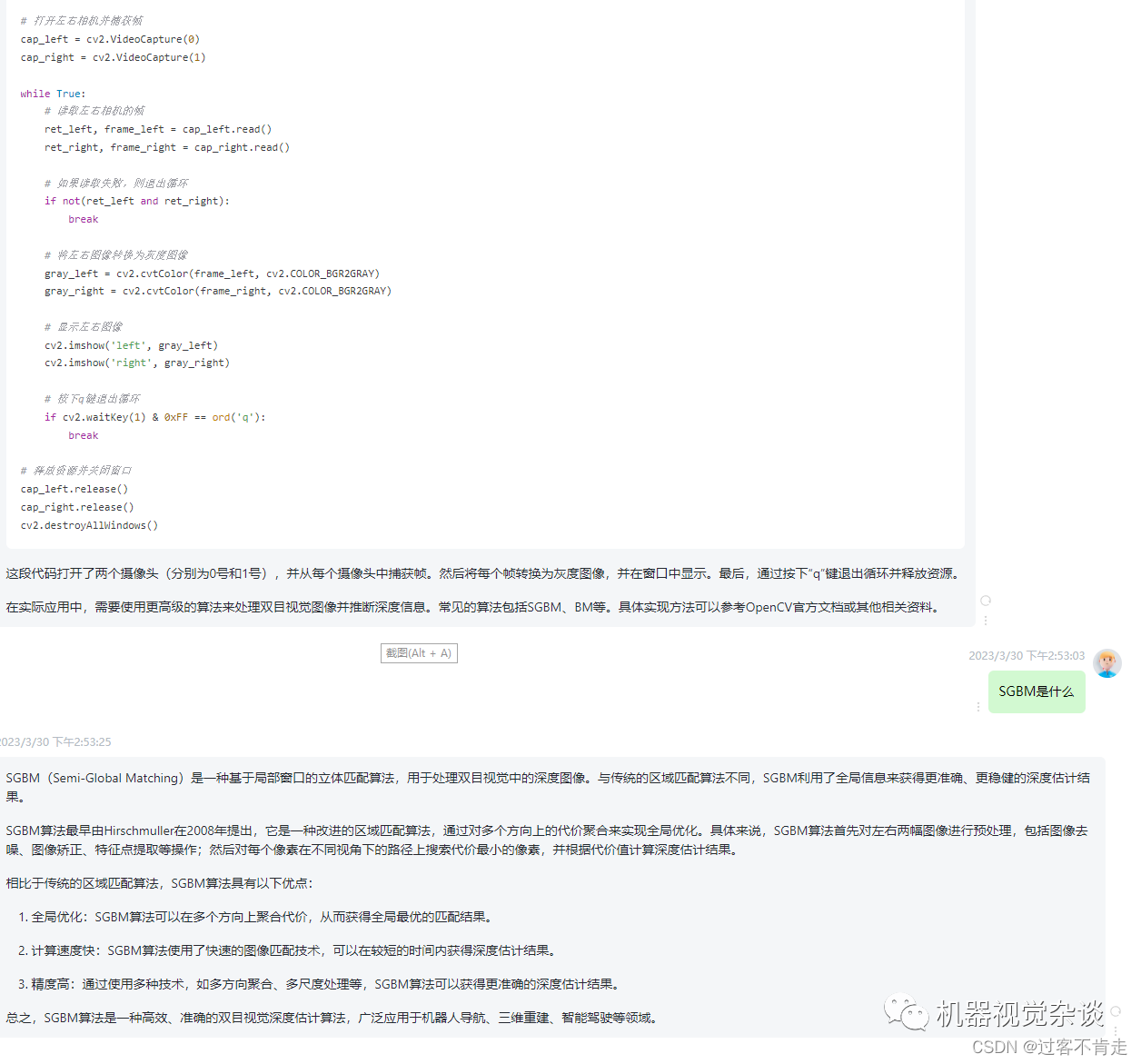
文章目录
- 模型训练
- 步骤
- 参数含义
- 名词解释
- 欠拟合
- 泛化能力
- 收敛性
- 梯度爆炸
- 初步结论
- 小结
模型训练
首先说明一下训练的目的:提供本地问答知识文件,训练之后可以按接近原文语义进行回答,类似一个问答机器人。
步骤
- 安装微调需要的依赖:
pip install rouge_chinese nltk jieba datasets
- 准备训练数据集:
数据集需要jsonline的格式,如果是单轮对话,需要设置输入输出两个字段(字段名可自定义,在训练脚本中通过参数指定即可),如果是多轮对话,需要额外指定历史字段。
以单轮对话为例:
{"question":"南京未来菁英训练营的报名年龄?","answer":"9-15岁,向下浮动2岁,向上浮动3岁。"}
{"question":"南京未来菁英训练营的接待标准是?","answer":"住宿:211高校、正餐餐标45元/人(5荤5素1汤1主食)。"}
- 准备训练脚本:tran.sh
PRE_SEQ_LEN=64
LR=2e-2CUDA_VISIBLE_DEVICES=0 python main.py \--do_train \--train_file qa-all.json \--validation_file qa-dev.json \--prompt_column question \--response_column answer \--overwrite_cache \--model_name_or_path 'D:\\ChatGLM-6B\\ChatGLM-6B\\THUDM\\chatglm-6b-int4' \--output_dir output\\qa-chatglm-6b-int4-pt-v2 \--overwrite_output_dir \--max_source_length 64 \--max_target_length 128 \--per_device_train_batch_size 1 \--per_device_eval_batch_size 1 \--gradient_accumulation_steps 16 \--predict_with_generate \--max_steps 3000 \--logging_steps 10 \--save_steps 1000 \--learning_rate $LR \--pre_seq_len $PRE_SEQ_LEN \
执行完成后,会在output目录生成相关checkpoint文件夹,以及训练生成的模型文件、配置文件:
-
验证:
PRE_SEQ_LEN=64CUDA_VISIBLE_DEVICES=0 python web_demo.py \--model_name_or_path "D:\\ChatGLM-6B\\ChatGLM-6B\\THUDM\\chatglm-6b-int4" \--ptuning_checkpoint "D:\\ChatGLM-6B\\ChatGLM-6B\\ptuning\\output\\qa-chatglm-6b-int4-pt-v2\\checkpoint-3000" \--pre_seq_len $PRE_SEQ_LEN
注意:
-
pre_seq_len的值,需要和训练时设置的一致;
-
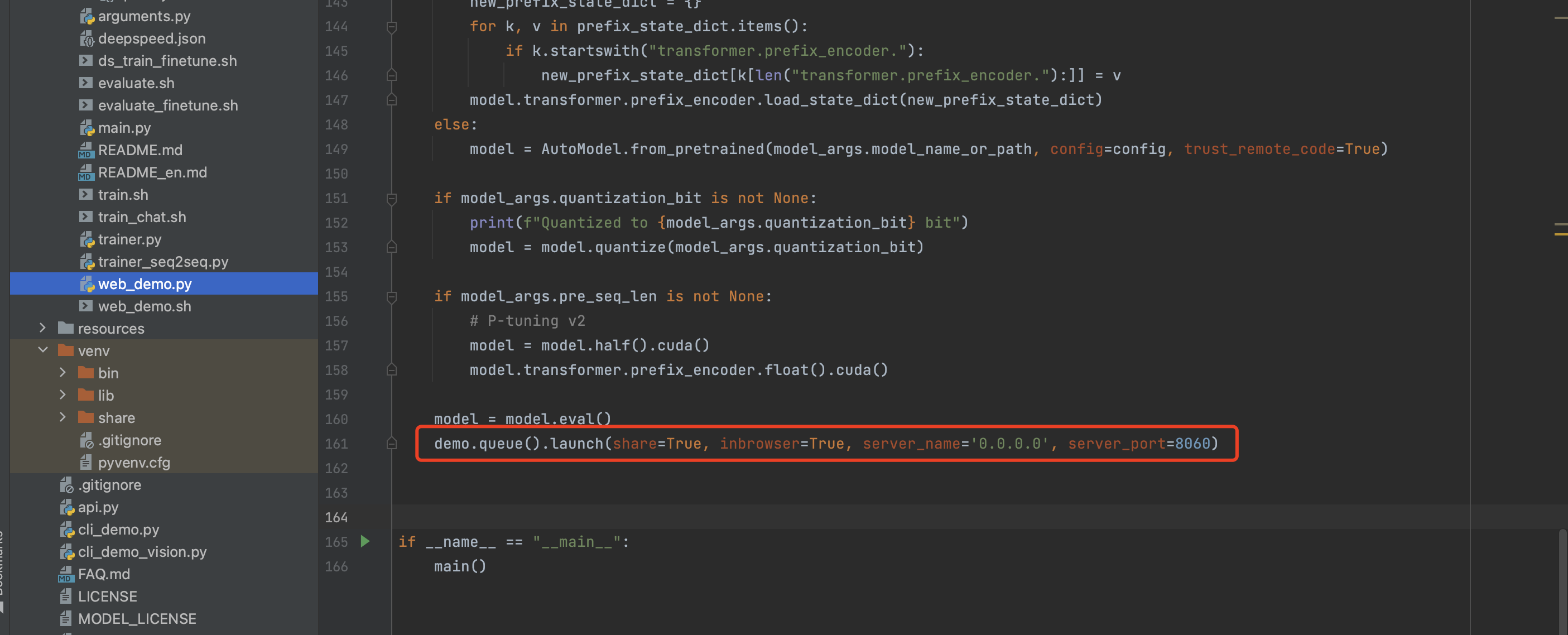
默认web_demo.py启动的web服务只能本地访问,需要设置share=True,还可以自定义端口:
参数含义
ChatGLM-6B 训练脚本 train.sh 的各个参数含义如下:
-
–do_train:表示进行训练。
-
–train_file:表示训练数据集的路径,需要是 JSON 格式的文件。
-
–validation_file:表示验证数据集的路径,需要是 JSON 格式的文件。
-
–prompt_column:表示 JSON 文件中输入文本对应的 KEY。
-
–response_column:表示 JSON 文件中输出文本对应的 KEY。
-
–overwrite_cache:表示是否覆盖缓存文件。
-
–model_name_or_path:表示预训练模型的名称或路径。
-
–output_dir:表示输出目录,用于保存模型和日志等文件。
-
–overwrite_output_dir:表示是否覆盖输出目录。
-
–max_source_length:表示输入文本的最大长度,单位是 token。
-
–max_target_length:表示输出文本的最大长度,单位是 token。输入文本和输出文本的最大长度是影响模型处理能力的重要参数,一般建议根据任务和数据集的特点选择合适的值,但不要超过 ChatGLM-6B 的序列长度限制(2048)。
-
–per_device_train_batch_size:这个参数是指每个设备上的训练批次大小,即每个 GPU / TPU 内核/ CPU 上用于训练的数据量。这个参数会影响显存的占用和训练的速度,一般来说,批次大小越大,显存占用越高,训练速度越快,但是也可能导致梯度爆炸或者欠拟合。因此,需要根据具体的任务和数据集来调整这个参数,以达到最佳的效果。
-
–per_device_eval_batch_size:表示每个设备的评估批处理大小。
-
–gradient_accumulation_steps:这个参数是指梯度累积的次数,即在进行一次梯度更新之前,需要累积多少个小批量的梯度。这个参数可以用来解决显存不足的问题,通过减小每个小批量的大小,但是增加梯度累积的次数,来保持总的有效批量大小不变。gradient_accumulation_steps 和 per_device_train_batch_size 的关系是:它们都可以影响训练过程中的有效批次大小。有效批次大小是指每次梯度更新时使用的数据量,它等于 per_device_train_batch_size 乘以 gradient_accumulation_steps 乘以 设备数。有效批次大小会影响模型的训练速度和效果,一般来说,批次大小越大,训练速度越快,但是也可能导致梯度爆炸或者欠拟合。
怎么结合这两个参数使用呢?一种常见的做法是,当显存不足以支持较大的 per_device_train_batch_size 时,可以通过增加 gradient_accumulation_steps 来实现梯度累积,相当于用更多的小批次来模拟一个大批次。这样可以在不牺牲有效批次大小的情况下,节省显存和提高训练效率。但是也要注意不要设置过大的 gradient_accumulation_steps ,否则可能会导致梯度更新不及时或者内存溢出。
-
–predict_with_generate:表示是否使用生成模式进行预测。
-
–max_steps:表示最大训练步数,即模型在训练集上的迭代次数,可以理解为训练多少轮。
-
–logging_steps:表示记录日志的步数间隔。
-
–save_steps:表示保存模型的步数间隔,即训练多少轮保存一次训练结果(checkpoint)。
-
–learning_rate:表示训练的学习率,可以进行调节以取得最佳效果。用于控制模型训练的速度和效果。它的取值范围可以根据具体的任务和数据集进行调节,以取得最佳的效果。一般来说,learning_rate 越大,模型训练的速度越快,但也可能导致过拟合或不收敛。learning_rate 越小,模型训练的速度越慢,但也可能获得更好的泛化能力或收敛性。
值范围在 0 到 1 之间,但也可以超过 1 或小于 0。不过,如果 learning_rate 太大或太小,都可能导致模型训练失败或效果不佳。因此,建议您从一个较小的值开始,比如 0.01 (1e-2)或 0.001 (1e-3),然后逐渐增大或减小,观察模型的表现,找到一个合适的值。
-
–pre_seq_len:pre_seq_len的取值范围一般是1到512,它表示自然语言指令的长度,即输入序列中的前pre_seq_len个token,具体的值需要根据自然语言指令的长度和复杂度来确定。一般来说,指令越长越复杂,pre_seq_len就需要越大,以便模型能够充分理解指令的含义。但是,pre_seq_len也不能太大,否则会占用过多的输入序列长度,导致生成内容过于单一或重复。因此,pre_seq_len的取值需要在保证指令完整性和生成多样性之间进行权衡。一种可能的方法是,根据不同的指令类型设置不同的pre_seq_len值,例如,对于简单的指令,如“生成一个笑话”,可以设置pre_seq_len为4;对于复杂的指令,如“生成一个关于环保主题的故事”,可以设置pre_seq_len为16。当然,这些值也需要根据实际的效果进行调整和优化。
-
–quantization_bit:表示模型参数的量化位数,用于降低显存需求。
pre_seq_len和max_source_length的含义是差不多的,或者取值是可以参照的?
不完全是的,pre_seq_len和max_source_length的含义是不同的,但是它们之间有一定的关系。pre_seq_len是指自然语言指令的长度,而max_source_length是指整个输入序列的最大长度。一般来说,pre_seq_len应该小于或等于max_source_length,因为输入序列除了包含指令之外,还可能包含其他内容,例如上下文信息或对话历史。如果pre_seq_len大于max_source_length,那么模型就无法接收到完整的指令,也就无法正确地生成输出内容。因此,pre_seq_len和max_source_length的取值需要协调一致,以保证模型能够有效地利用输入信息。
名词解释
欠拟合
欠拟合是指模型在训练集上获得的误差太高,不能很好地学习到数据背后的规律。欠拟合的原因可能有以下几种:
-
模型复杂度太低,不能捕捉到数据的特征和变化。
-
训练数据量太少,不能代表真实的数据分布。
-
训练数据质量差,包含噪声或异常值,影响模型的学习效果。
欠拟合的解决办法可能有以下几种:
- 增加模型的复杂度,比如增加网络的层数或神经元的个数。
- 增加训练数据的数量和多样性,尽可能覆盖不同的数据类型和场景。
- 清洗和预处理训练数据,去除噪声和异常值,进行归一化或标准化等操作。
泛化能力
泛化能力是指模型在未知数据上的表现能力,也就是模型能否从训练数据中学习到普遍的规律,而不是过度拟合训练数据的特殊性。泛化能力越高,说明模型越能适应不同的数据分布,越具有实际应用价值。泛化能力通常通过在测试集上计算模型的准确率、损失值、查准率、查全率等指标来衡量。
收敛性
收敛性是指模型在训练过程中是否能够达到一个稳定的状态,也就是模型的参数是否能够收敛到一个最优或者次优的解。收敛性越好,说明模型越容易找到一个合适的参数配置,越能提高训练效率和效果。收敛性通常通过观察训练集和验证集上的损失值随着迭代次数的变化曲线来判断。
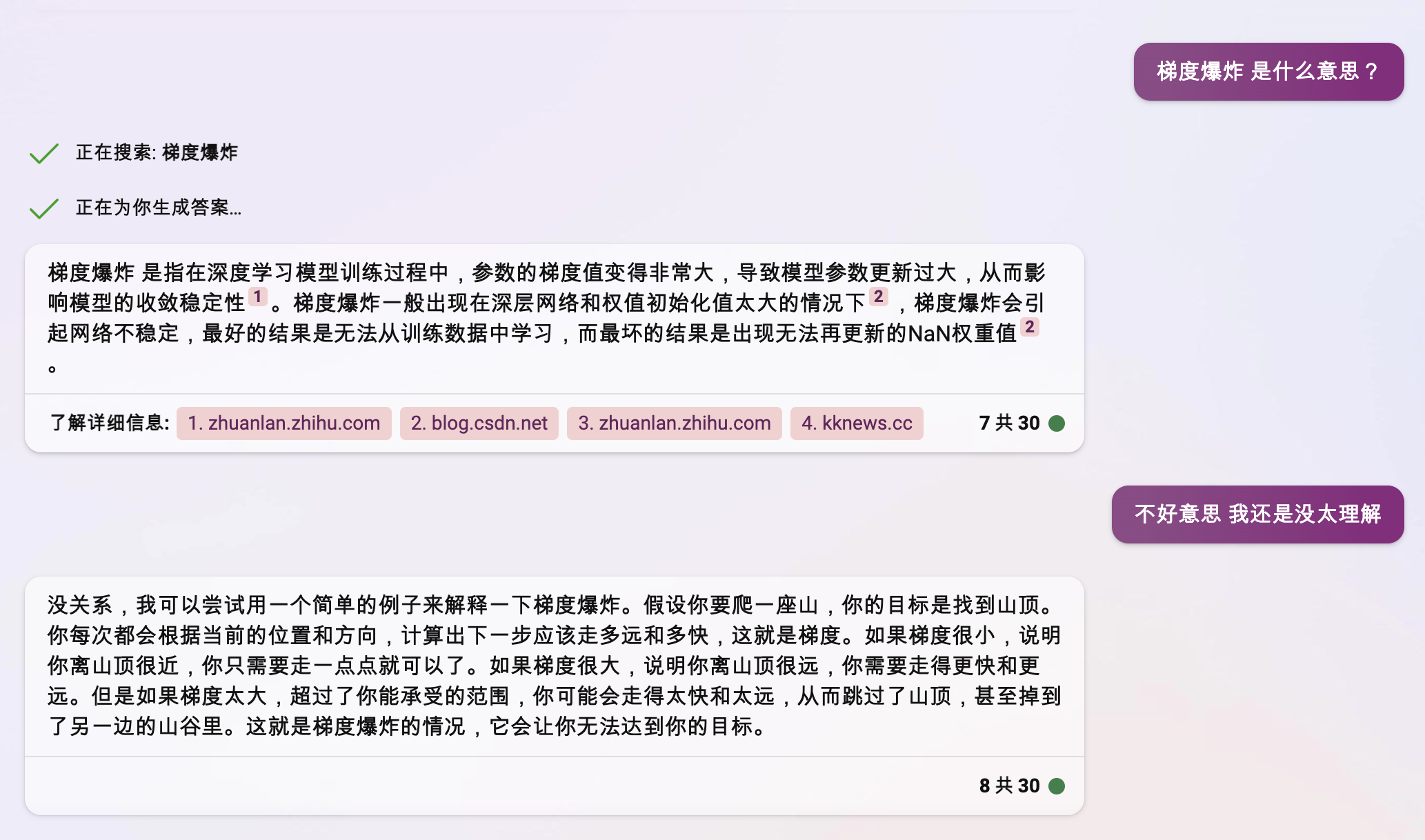
梯度爆炸
初步结论
每次单独提问,可以得到正确的答案,多个问题之后,后面的回答就可能受到之前问题的干扰,导致回答混乱,每次clear history之后再提问,可以避免这种情况。
提问需要有一个Prompt,指明问题的一个上下文信息或者分类信息。
将代码中每次推理中带的history参数置空,可以避免多个问题间干扰的问题:
修改为:
def predict(input, chatbot, max_length, top_p, temperature, history):chatbot.append((parse_text(input), ""))for response, history in model.stream_chat(tokenizer, input, [], max_length=max_length, top_p=top_p,temperature=temperature):chatbot[-1] = (parse_text(input), parse_text(response)) yield chatbot, history
这只能解决问答类、不依赖上下文的使用场景,对于希望从上下文中获取到辅助信息的场景,这显然是不可取的。
小结
-
当前训练效果
- 预期内:
- 能够完成自定义知识文件的训练,并可以正常使用训练出来的模型。
- 对训练数据的优化,比如增加问题的前缀,对提升训练结果的准确性是有效的。
- 预期外:
- 会“遗忘”原本的数据,对训练数据集之外的提问,会回答不上来,甚至出现乱回答、卡死的情况
- 历史问答会影响后面提问的回答,导致后面的回答语义混乱、或者答非所问。
- 预期内:
-
模型部署效果
- 训练前:可以正常组织语言进行回答、但是很多知识缺失,比如一些文学类的问题,会乱答一通;
- 训练后:会出现灾难性遗忘,回答不了训练数据集之外的问题
-
准备进行的尝试:
- 训练文件中增加历史问答内容,设置不管历史问题是什么,当前问题的答案都相同,让当前问答不受其他问答的干扰。
- prompt 的调教
-
模型种类
- 6B、10B、130B:训练的参数不一样,分别代表60亿、100亿、1300亿
- 量化(INT4、INT8):量化是一种模型压缩技术,可以减少模型的存储空间和计算资源,提高模型的部署效率。INT4和INT8分别使用了4位和8位的整数来表示模型参数,相比于原始的跟高位浮点数,可以节省大量的显存。就可以在消费级的显卡上运行。不过,量化也会带来一定的性能损失,可能会影响模型的生成质量。
-
部署方法
- 不同模型的部署方法都差不多,需要下载好模型文件和配套的配置文件,使用时指定好对应的文件夹即可。
-
训练方法
- P-Tunning:P-Tuning是指在预训练模型的输入层插入一些可训练的连续向量(Prompt),作为任务相关的信息,然后只对这些向量进行微调,而冻结预训练模型的其他参数。这种方法可以减少微调的参数量和数据量,提高微调的效率和泛化能力,但也可能会降低模型的交互性和生成质量。
- LoRA:LoRA是指在预训练模型的每一层注入一些可训练的低秩矩阵(Low-Rank Adaptation),用于捕捉下游任务的低秩变化,然后只对这些矩阵进行微调,而冻结预训练模型的其他参数。这种方法可以减少微调的参数量和计算量,提高微调的效率和推理速度,同时保持模型的生成质量。
- Finetune:Finetune是指对预训练模型的所有参数进行微调,以适应下游任务。这种方法可以充分利用预训练模型的知识,但也需要较多的计算资源和数据量,可能会导致过拟合或灾难性遗忘。
-
主要的训练参数
- 见 Part 1.2
-
目前遇到的主要问题
- 模型质量:模型本身不具备较强的理解能力,大部分Prompt是不生效的
- 训练耗时:每次训练,少量数据(36条)也需要7、8个小时。
- 硬件资源:强依赖GPU资源,对GPU显存有很高的要求。