转载自 Nature
点击上方“迈微AI研习社”,选择“星标★”公众号
原作者: Douglas Heaven
关注公众号阅读原文,这个排版太差。
人工智能专家正在想办法修复神经网络的缺陷。
一辆自动驾驶汽车正在靠近一个停车让行标志,它非但没有停下,反而加速冲入了繁忙的十字路口。后续的事故调查发现,停车让行的标志上贴了几张方形标签,正是这些标签让汽车的人工智能(AI)系统将停车标志错误识别为“限速45”。
插图:Edgar Bąk
这一场景没有真实发生,但AI被蓄意破坏和恶意攻击的危险却一直存在。研究人员已经证实,通过在特定位置放置贴纸,就能让AI误读停车标志1;如果将特定印刷图案贴在眼镜或帽子上,就能骗过人脸识别系统;不仅如此,研究人员还尝试在音频中加入一定模式的白噪声,成功让语音识别系统产生了幻听。
上面只是简单几例,说明要破坏AI的先进模式识别技术有多么容易。这种模式识别技术也被称为深度神经网络(deep neural networks,DNN),它对图像、语音和消费者数据等各种类型的输入具有强大的分类能力。从自动电话系统到流媒体网站的用户推荐,深度神经网络早已融入了我们的日常生活。然而,只要对输入做一些微小改变,即使变化小到人类无法辨识,也能使最先进的AI系统懵圈。
加州大学伯克利分校计算机科学博士生Dan Hendrycks表示,对于一项还不完美的技术来说,这些问题比特异性怪异模式更值得警惕。和许多研究人员一样,他认为这种问题凸显出了深度神经网络根本上的脆弱性——纵使在擅长的工作上表现出色,一旦进入陌生领域,它们将以无法预测的方式崩溃。
来源:停止标志:参考文献1;企鹅:参考文献5
而这绝不是小问题。随着深度学习不断从实验室走向真实世界,从自动驾驶汽车到罪犯搜索再到疾病诊断无处不在。但正如今年的一项研究指出2,只要在医学扫描影像中恶意增加几个像素,深度神经网络就会将其误诊为癌症。此外,黑客还能利用这些弱点劫持在线的AI系统,让它执行自己的算法3。
在搞清楚深度神经网络为什么会失败的过程中,研究人员已经找到了很多原因。谷歌AI工程师François Chollet称,“对于深度神经网络的这种根本脆弱性,目前没有修复方法”。想要弥补这些缺陷,他与其他人都认为需要用额外的能力来“增强”善于模式匹配的深度神经网络,比如让AI自主探索世界、自主编写代码并保留记忆。一些专家认为,这样的系统将塑造今后10年的AI研究。
实践的检验
2011年,谷歌发布的一套系统可以识别YouTube视频中的猫,随之掀起了一股深度神经网络分类系统的热潮。怀俄明大学的Jeff Clune也是Uber旧金山AI实验室的高级研究经理,据他回忆,“那时候每个人都在说,‘太厉害了,计算机终于可以理解世界了’”。
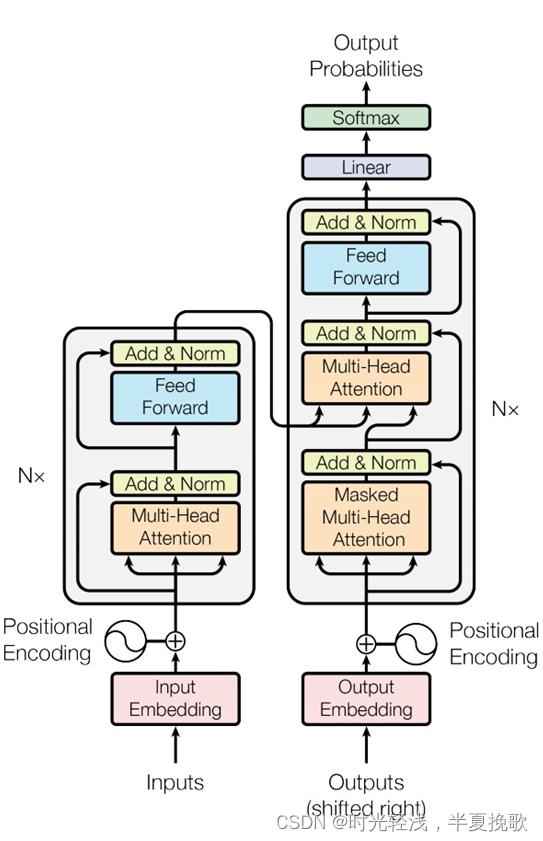
但AI研究人员明白,深度神经网络并没有真正地理解世界。通过对大脑结构的粗略建模,大量的数字神经元被部署在多层结构,这构成了深度神经网络的基本软件结构,其中每个神经元都与前后层的神经元相连。
深度学习网络的基本概念是,底层输入的图像或像素等原始特征会激发这些神经元,通过简单的数学规则产生信号并传递给更高层级。训练深度神经网络需要使用大量样本,不断调节神经元之间的连接方式,直到顶层神经元输出期望的答案——比如将狮子的图片识别成狮子,即使之前从未见过这张图片。
第一次大型实践检验发生在2013年。谷歌研究员Christian Szegedy和同事发表了一篇题为《论神经网络的有趣特性》的预印本论文4。研究人员只改变了少量像素,就让深度神经网络得出了完全不同的结果,比如把狮子识别成图书馆。团队把这种更改过的图像称为“对抗样本”。
一年后,Clune和他当时带的博士生Anh Nguyen与康奈尔大学的Jason Yosinki合作,共同演示了什么叫做“睁眼说瞎话”,比如让深度神经网络将曲线条纹识别成企鹅5。深度学习领域的先驱、来自加拿大蒙特利尔大学的Yoshua Bengio说:“和机器学习打过交道的人都知道它们经常会犯低级错误。但这种错误是研究人员意料之外的,我们无法想象这种错误会发生。”
新的错误纷至沓来。目前就职于美国奥本大学的Nguyen发现,只要将图像中的物体稍微转个方向,就足以把一些最好的图像分类器搞得团团转6。今年,Hendrycks和同事还报道称,即使是未经更改的自然图像也能让先进的分类器给出不可预测的错误答案,例如将蘑菇识别成了扭结饼,将蜻蜓识别成了井盖7。
这一问题不仅出现在物体识别技术上,任何利用深度神经网络为输入(如语音)进行分类的AI都很容易受骗上当。会玩游戏的AI也很容易遭到暗算。2017年,加州大学伯克利分校的计算机科学博士生Sandy Huang和同事让经过训练的深度神经网络通过“强化学习”的过程打一个名为Atari的电子游戏8。研究人员会先给AI一个目标,再看它对一系列输入的响应,通过试错的方式让它达到目标。
这种技术成就了具有超人能力的游戏AI,包括著名的AlphaZero和扑克机器人Pluribus。即便如此,Huang的团队还是可以通过在屏幕上添加一两个随机像素,让AI输掉整场比赛。
今年早些时候,加州大学伯克利分校的AI博士生Adam Gleave和同事的研究表明,将一个主体引入一个AI环境,就能让其做出混淆视听的“对抗策略”9。举例来说,一个AI足球运动员的训练目标是让球越过守门员,但在仿真环境中,当守门员表现出无法预料的行为时,如倒在地上,AI足球运动员也会失去进球的能力。
一个AI足球运动员在模拟的点球大战中被AI守门员的“对抗策略”(倒在地上)迷惑(右)。| 来源:Adam Gleave/参考文献9
看透深度神经网络的弱点所在,甚至能让黑客掌控强大的AI。去年谷歌的一个团队就展示了他们不仅可以利用对抗样本让深度神经网络犯下特定错误,还能对它进行重新编程,让经过训练的AI去执行其他不相关的任务3。
原则上,许多学习语言的神经网络可以用于编码任何其他的计算机程序。Clune表示:“理论上你可以将聊天机器人的程序转换成任何你想要的程序,而这只是震惊的开始。”他认为在不远的未来,黑客会劫持云端的神经网络,运行自己的垃圾邮件算法。
对于加州大学伯克利分校的计算机科学家Dawn Song来说,深度神经网络就像活靶子。她说:“攻击系统的方法太多了,防御非常非常困难。”
越强大越脆弱
深度神经网络的强大之处在于它们的多层结构,可以从一个输入的不同特征上提取模式来进行分类。对于一个被训练用于识别飞机的AI来说,色彩、纹理和背景一类的特征对它们而言,就像我们眼中的显著特征——机翼一样。这也意味着输入的微小改变会让AI的预测结果大相径庭。
一个解决办法是给AI更多数据,让AI反复暴露在有问题的例子下,不断地纠正它的错误。在这种“对抗训练”的方式下,其中一个网络会学习识别物体,另一个网络则尝试改变前一个网络的输入来使它出错。这样就能把对抗样本变成深度神经网络训练数据的一部分。
Hendrycks和同事建议用大规模对抗样本来测试深度神经网络的表现,量化深度神经网络抵抗错误的鲁棒性。但他们也表示,在训练网络抵抗某种攻击的同时也会弱化网络对于其他攻击的抵抗力。谷歌DeepMind伦敦办公室的一个研究团队在Pushmeet Kohli的领导下尝试为深度神经网络“接种”抵抗出错的“疫苗”。
很多对抗攻击都是通过对输入进行微调来让深度神经网络产生误分类的,例如稍微改变图像像素的颜色,一直到能让深度神经网络出错为止。Kohli团队认为,一个鲁棒的深度神经网络其输出不会因为输入的微小变化而改变,而这一特性可用数学的方式整合进整个网络,通过限制它学习的方式来实现。
但目前还没有人能够从整体上修复AI这一脆弱性的问题。Bengio说,问题的根源在于深度神经网络没有一个好的模型来指导它们如何从数据中挑选重要的部分。虽然AI会把修改后的狮子图片看成图书馆,但人是不会看错的,因为人类脑中对于狮子的概念是由耳朵、尾巴以及狮鬃等一系列高级特征构成的,这让人类能从一些低级属性或次要细节中抽离出来。Bengio说:“我们的经验告诉我们哪些特征才是重要的,而这来自于我们对世界结构的深入理解。”
想要解决这一问题,一种尝试是将深度神经网络和符号学AI相结合——符号学在机器学习之前曾经统治AI领域。利用符号学AI,机器学习可以通过世界运行的硬编码规则来进行推理,例如不同离散物体间的不同相互作用方式。很多研究人员和纽约大学的心理学家Gary Marcus一样,认为混合AI是未来前进的方向。Marcus一直是当前深度学习方式的批评者,他说:“深度学习在短期内的用场使得人们失去了长远的眼光。”今年5月,他在加州帕罗奥图联合创立了名为Robust AI的初创公司,致力于结合深度学习与基于规则的AI技术来开发机器人,这种机器人可以与人安全地协作。公司从事的具体业务目前还处于保密状态。
即使能将规则嵌入深度神经网络,它们的能力也无法超越其学习的数据。Bengio认为AI智能体需要在更复杂的环境中进行学习和自我探索。大多数计算机视觉系统都无法识别出一听圆柱形的啤酒,因为它们是通过二维图像训练的。这也是为何Nguyen和同事只消让物体换一个角度,就能骗过深度神经网络了。而在三维环境中学习,无论是真实环境还是模拟环境,都能帮助解决这一问题。
另一方面,AI学习的方式也需要改变。Bengio说:“学会因果推理需要让主体在真实世界中进行活动,让他们自由实验和探索。”另一位深度学习先驱、来自瑞士Dalle Molle人工智能研究所的Jürgen Schmidhuber也抱有同样的想法。他认为模式识别太强大了,强大到把阿里巴巴、腾讯、亚马逊、脸书和谷歌送上了全球最值钱企业的宝座。但紧随其后的将是更大的浪潮,这次浪潮将以机器为中心,这些机器不但可以操纵世界,还能用自己的行为创造它们自己的数据。
从某种意义上来说,利用强化学习称霸电子游戏的AI已经在人工环境中这么做了:通过不断试错,它们以被允许的方式操作屏幕上的像素直到目标达成。不过,相较于目前用于训练深度神经网络的仿真环境或整理好的数据来说,现实环境的复杂程度更甚。
即兴机器人
在加州大学伯克利分校的一间实验室里,一条机械臂正在翻找着什么。它捡起一个红色的碗,并用碗把一个蓝色的烤箱手套往右轻推了几厘米。它扔掉了碗,捡起了一个空的塑料喷瓶,随后又掂量了一番一本书的质量和外形。在连续多天不休不眠的训练后,这个机器人开始熟悉这些陌生物品,以及怎么和它们“玩”。
这条机械臂利用深度学习教会自己如何使用工具。给它一堆物体,它会一个个捡起来,看看移动它们或用一个物体碰触另一个物体会发生什么。
机器人利用深度学习探索三维(形状)工具的用途。| 来源:Annie Xie。
当研究人员给机器人设定一个目标,例如给它呈现一张接近空托盘的图片,并让机器人整理托盘中的物品以匹配图片中的状态,机器人就会开始自己的表演,利用没有见过的物品来进行操作,例如它会用一块海绵将所有的东西扫下桌面。它还会发现利用塑料水瓶推开物品比直接拾取这些物品来得更快。“与其他机器学习技术相比,它完成任务的通用性给我留下了十分深刻的印象。” 曾在伯克利实验室工作、目前在斯坦福大学继续相关研究的Chelsea Finn说。
Finn认为,这种学习方式增进了AI对于物体和世界的普遍理解。如果你只在照片中见到过水瓶或者海绵,你也许可以在其他图像中识别出它们,但你不知道它们到底是什么、有什么用。她说:“如果不能与世界进行实际交互,你对世界的认识就只能停留在粗浅的表面。”
但是,这种学习是一个缓慢的过程。在仿真环境中,AI能以光速遍历样本。2017年,DeepMind出品的自主学习游戏软件AlphaZero被训练成了超人大师,仅仅一天就精通了从围棋到国际象棋再到日本象棋的多个游戏。当时,对于每一项比赛,AI都在虚拟环境中进行了超过2000万次的训练。
AI机器人无法如此快速地学习。几乎所有主流的深度学习方法都极度依赖大量的数据,Ambidextrous(一家位于加利福尼亚伯克利的AI和机器人公司)的联合创始人Jeff Mahler说道,"在单个机器人上收集几千万数据点将耗费数年时间。”同时,由于传感器的标定会随时间变化,硬件也在老化,得到的数据也不一定可靠。
因此,大多数基于深度学习的机器人工作依然利用仿真环境来加速训练。“你能学习到的内容取决于你构建仿真环境的质量。”来自佐治亚理工的机器人学博士生David Kent说。
仿真器不断在改进,研究人员也越来越擅长于将虚拟环境中学习到的知识迁移到真实环境中去。不过仿真环境目前还无法与复杂的真实世界相媲美。
Finn认为,利用机器人学习最终肯定比利用人工数据学习更具扩展性。她的“工具使用”机器人在几天内学会了相对简单的任务而无需密集的监督。她说:“你只需要运行机器人,一段时间检查一次就好。”她期待未来有一天可以有很多机器人,给它们工具夜以继日的学习。这不是没有可能,毕竟这也是人类认识世界的方式。Schmidhuber说:“婴儿不是通过从Facebook上下载数据来学习的。”
减少学习数据
婴儿可以从很少的数据点中学会识别新样本:即使他们从未见过长颈鹿,却能在见过一两次后认出它们。婴儿学习如此迅速的部分原因在于,它们还见过长颈鹿之外许多其他生物,所以对于物体的显著特征也较为熟悉。
迁移学习为AI提供了类似的能力:其基本概念是将其他任务训练得到的知识进行迁移。当训练一个新的任务时,通过复用部分或整体的预训练网络来作为训练的起始点,从而实现迁移学习。例如,对一个已经能够识别一种动物的深度神经网络的一部分加以重复利用,比如那些能识别基本动物体形的层,就能为学习识别长颈鹿的新网络提供更多优势。
迁移学习的一种极端形式是仅仅通过几个样本甚至是一个样本就训练出新的网络。这种称为少样本学习或单样本学习的方法极度依赖于预训练的深度神经网络。想象一下,你想要构建一个能在刑事数据库中识别罪犯的人脸识别系统。一个快捷方法是利用一个已经看过数百万张人脸(无需为新数据库的人脸)的深度神经网络,因为它已经很好地理解了人脸的显著特征,如鼻子和下巴的形状等。当这个网络扫描一张新的人脸时,就能从图片中精确提取有用的特征集,随后再与罪犯数据库中的图像进行相似度比对,找到匹配度最高的对象。
拥有这样的预训练记忆可以帮助AI在无需观察大量模式的情况下识别新样本,加速机器人的学习速度。但这样的深度神经网络在面对与先前经验相差太远的实例时也会陷入差错。目前还不清楚这样的网络有多强的通用性。
即便像DeepMind的AlphaZero这样最为成功的AI,都只局限于非常狭窄的领域。AlphaZero的算法在训练后可以下围棋或国际象棋,但却无法同时下两种棋。重新训练一个模型的连接和反应,让它打赢国际象棋比赛,这种操作会重置其之前在围棋上的所有经验。Finn说:“从人类的角度看,这种学习方式很荒唐。”人类根本不会这么容易就忘记他们曾经学会的东西。
学会学习
AlphaZero在游戏方面的成功不仅仅来源于有效的强化学习,还要归功于一种算法(利用了一种类似于蒙特卡洛树搜索的技术),这种算法帮它减少了后续步骤的搜索空间10。换句话说,AI是被引导着如何从它所处的环境中最好地学习。Chollet认为,AI接下来最重要的一步是赋予深度学习网络自己写算法能力,而不用人类提供的代码。
他认为,在基础的模式匹配能力之余赋予AI推理能力,有利于AI应对它们不熟悉的输入数据。让计算机自动生成代码的合成技术已经被研究了很多年,Chollet相信,通过与深度学习技术的结合可以让基于深度神经网络的系统更接近人类的抽象智力模型。
在机器人领域,脸书AI研究院的计算机科学家、德克萨斯大学奥斯丁分校教授Kristen Grauman正在教机器人如何更好地自主探索世界,包括在新场景中应该观察哪里,如何操作物体才能更好地掌握它的形状或用途。这么做的初衷是让AI可以预测出哪些新视角可以提供最有利学习的新数据。
该领域的研究人员表示,他们正在逐步解决深度学习的缺陷,同时也在不断探寻新的技术提高这一过程的稳定性。目前深度学习还没有太多的理论支撑,Song说,“如果某个地方不灵了,我们很难找到原因。整个领域依然有赖于经验,不断尝试就对了。”
目前来说,虽然科学家意识到深度神经网络的脆弱性,以及它们对大量数据的依赖性,但大部分人依然认为这一技术已经建立了起来。研究人员在这十年中,通过巨量的计算资源训练神经网络,实现了如此优异的模式识别,给我们留下了深刻的启示。“但没有人知道如何让它变得更好。”Clune说。
参考文献:
1. Eykholt, K. et al.IEEE/CVF Conf. Comp. Vision Pattern Recog. 2018, 1625–1634 (2018).
2. Finlayson, S. G. et al.Science 363, 1287–1289 (2019). PubMedArticle G
3. Elsayed, G. F., Goodfellow, I. & Sohl-Dickstein, J. Preprint at https://arxiv.org/abs/1806.11146 (2018).
4. Szegedy, C. et al. Preprint at https://arxiv.org/abs/1312.6199v1 (2013).
5. Nguyen, A., Yosinski, J. & Clune, J. IEEE Conf. Comp. Vision Pattern Recog. 2015, 427–436 (2015).
6. Alcorn, M. A. et al. IEEE Conf. Comp. Vision Pattern Recog.2019, 4845–4854 (2019).
7. Hendrycks, D., Zhao, K., Basart, S., Steinhardt, J. & Song, D. Preprint at https://arxiv.org/abs/1907.07174 (2019).
8. Huang, S., Papernot, N., Goodfellow, I., Duan, Y. & Abbeel, P. Preprint at https://arxiv.org/abs/1702.02284 (2017).
9. Gleave, A. et al. Preprint at https://arxiv.org/abs/1905.10615 (2019).
10. Silver, D. et al.Science 362, 1140–1144 (2018).
原文以Why deep-learning AIs are so easy to fool为标题发表在2019年10月9日的《自然》新闻特写上,点击阅读原文直接跳转
© nature
Nature|doi:10.1038/d41586-019-03013-5
版权声明:
本文由施普林格·自然上海办公室负责翻译。中文内容仅供参考,一切内容以英文原版为准。欢迎转发至朋友圈,如需转载,请邮件China@nature.com。未经授权的翻译是侵权行为,版权方将保留追究法律责任的权利。
© 2020 Springer Nature Limited. All Rights Reserved
推荐阅读
(点击标题可跳转阅读)
-
【TKDE2020-南洋理工】深度学习命名实体识别最新版,207篇参考文献
-
如何显著提升小目标检测精度?深度解读Stitcher:简洁实用、高效涨点
-
表情识别FER | 基于深度学习的人脸表情识别系统(Keras)
-
GitHub标星23k+,从零开始的深度学习实用教程 | PyTorch官方推荐
△微信扫一扫关注「迈微电子研发社」公众号
知识星球:社群旨在分享AI算法岗的秋招/春招准备攻略(含刷题)、面经和内推机会、学习路线、知识题库等。
△扫码加入「迈微AI研习社」学习辅导群
点击“阅读原文”直接跳转英文原文阅读