★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
让OpenAI GPT3替我写数据竞赛代码!
OpenAI与ChatGPT
OpenAI是在美国成立的人工智能研究公司,核心宗旨在于实现安全的通用人工智能(AGI)。他们开发的ChatGPT是一个最先进的自然语言处理模型,可以实时生成类似人类的文本。
ChatGPT 是从 GPT-3.5 系列中的一个模型进行微调的,该模型于 2022 年初完成训练。 GPT-3.5 系列是一系列模型,从 2021 年第四季度开始就混合使用文本和代码进行训练。
由于ChatGPT暂时是没有开源,且比较适合用于对话任务。为了让读者能逐步了解GPT能做什么,本文将介绍OpenAI已经公开的GPT3使用方法,可以使用免费的API来完成NLP和代码生成任务。
GPT3介绍
生成型预训练变换模型 3 (Generative Pre-trained Transformer 3,简称GPT3)是一个自回归语言模型,目的是为了使用深度学习生成人类可以理解的自然语言。GPT3的神经网路包含1750亿个参数,是当时参数最多的神经网路模型。
- GPT3 模型拥有非常多个领域的先验知识,当用户通过自然语言向语言模型提出问题时,模型能够回答其中的大多数问题。
- GPT3 模型相比以往模型(如 BERT)的另外优势,则是对于大多数常规任务,在使用模型之前无需对其进行微调(Fine-tuning)操作。
- GPT-3 模型的优势在于,用户在使用该模型时,只需要告诉GPT3需要完成的任务即可,而不需要预先为想要完成的任务先微调一遍模型,比如:
Translate this into French:
Where can I find a bookstore? Où puis-je trouver un magasin de livres?
以GPT3为首提出是基于预训练语言模型的新的微调范式:Prompt-Tuning,其通过添加模板的方法来避免引入额外的参数,从而让语言模型可以在小样本(Few-shot)或零样本(Zero-shot)场景下达到理想的效果。
OpenAI-GPT3 API注册
API介绍
OpenAI-GPT3 API 已部署在数以千计的应用程序中,其任务范围从帮助人们学习新语言到解决复杂的分类问题。
- Github Copilot帮助更快地编写代码
- Duolingo 使用 GPT-3 进行语法更正
API价格
对于学习者而言,也可以注册免费的GPT3 API,注册页面:https://openai.com/api/
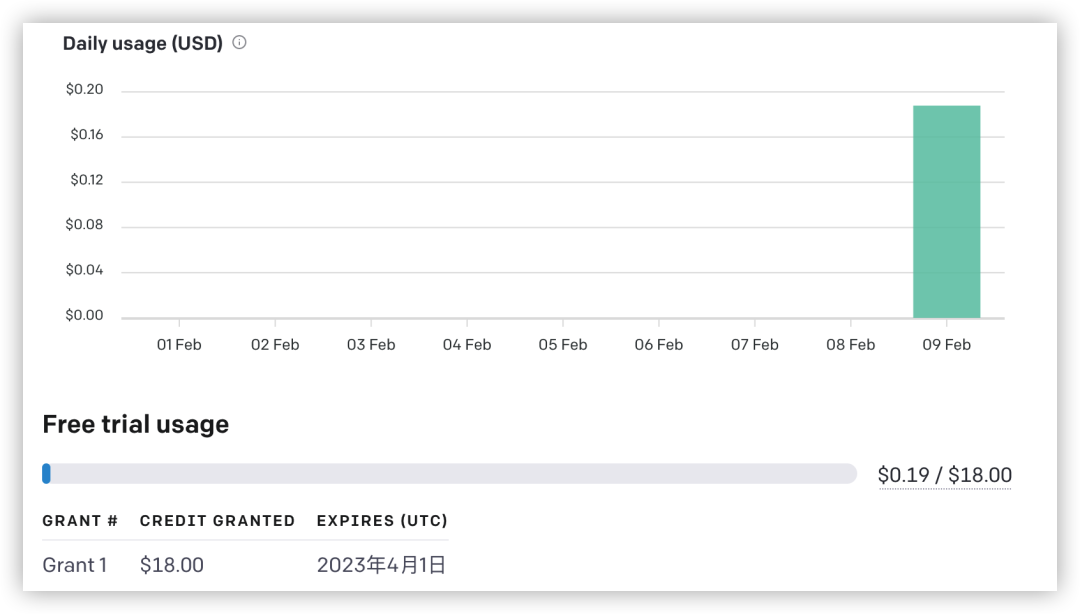
对于没有绑定信用卡的用户,可以免费使用约18美元的调用,当然不同的模型费用不同。
- Ada:$0.0004 / 1K tokens
- Babbage:$0.0005 / 1K tokens
- Curie :$0.0020 / 1K tokens
- Davinci:$0.0200 / 1K tokens
Ada 是最快的模型,而 Davinci 是最强大的。这里的token可以理解为pieces of words,整体的价格还是比较低的。
API使用
GPT3 API提供了多种语言的交互方法,最常见的Python可以参考如下代码:
安装OpenAI API库
pip3 install openai
基础使用代码:
import os
import openai# 填写你的API KEY
openai.api_key = 'XXX'response = openai.Completion.create(model="text-davinci-003", prompt="Say this is a test", temperature=0, max_tokens=7
)
更多安装指南:https://platform.openai.com/docs/libraries/community-libraries
API功能
OpenAI 训练了大量的模型,并通过API提供对这些模型的访问,可用于解决几乎任何涉及处理语言的任务。
- Content generation
- Summarization
- Classification
- Data extraction
- Translation
OpenAI-GPT3 API 模型
OpenAI API 由一系列具有不同功能和价位的模型提供支持:
- GPT-3:能够理解并生成自然语言的模型
- Codex:可以理解和生成代码的模型,包括将自然语言翻译成代码
- Content filter:检测文本是否敏感或不安全的模型
GPT-3可以理解和生成自然语言,OpenAI提供四种主要类似,分别具有不同的功率级别,可适用于不同的任务。
| Latest model | Description | Max request |
|---|---|---|
| text-davinci-003 | Most capable GPT-3 model. Can do any task the other models can do. | 4,000 tokens |
| text-curie-001 | Very capable, but faster and lower cost than Davinci. | 2,048 tokens |
| text-babbage-001 | Capable of straightforward tasks, very fast, and lower cost. | 2,048 tokens |
| text-ada-001 | Capable of very simple tasks, usually the fastest model in the GPT-3 series, and lowest cost. | 2,048 tokens |
更多模型介绍细节:https://platform.openai.com/docs/models/overview
模型论文和实现细节:https://platform.openai.com/docs/model-index-for-researchers
OpenAI-GPT3 场景案例
Text completion
https://platform.openai.com/docs/guides/completion/introduction
文本分类
- 单个文本分类Prompt
Decide whether a Tweet's sentiment is positive, neutral, or negative.Tweet: I loved the new Batman movie!
Sentiment:
- 多个文本分类Prompt
Classify the sentiment in these tweets:1. "I can't stand homework"
2. "This sucks. I'm bored 😠"
3. "I can't wait for Halloween!!!"
4. "My cat is adorable ❤️❤️"
5. "I hate chocolate"Tweet sentiment ratings:
文本生成
- 文本续写Prompt
Brainstorm some ideas combining VR and fitness:
- 文本对话Prompt
The following is a conversation with an AI assistant. The assistant is helpful, creative, clever, and very friendly.Human: Hello, who are you?
AI: I am an AI created by OpenAI. How can I help you today?
Human:
- 文本翻译Prompt
Translate this into French, Spanish and Japanese:What rooms do you have available?
代码补全
https://platform.openai.com/docs/guides/code/best-practices
- 写Python代码
"""
1. Create a list of first names
2. Create a list of last names
3. Combine them randomly into a list of 100 full names
"""
- 写MySQL代码
"""
Table customers, columns = [CustomerId, FirstName, LastName, Company, Address, City, State, Country, PostalCode, Phone, Fax, Email, SupportRepId]
Create a MySQL query for all customers in Texas named Jane
"""
query =
实践案例:飞桨学习赛吃鸡排名预测
赛题背景
《绝地求生》(PUBG) 是一款战术竞技型射击类沙盒游戏。在游戏中,玩家需要在游戏地图上收集各种资源,并在不断缩小的安全区域内对抗其他玩家,让自己生存到最后。当选手在本局游戏中取得第一名后,会有一段台词出现:“大吉大利,晚上吃鸡!”。
我们提供了PUBG游戏数据中玩家的行为数据,希望参赛选手能够构建模型对玩家每局最终排名进行预测。
赛题任务
本次任务希望大家构建吃鸡排名预测模型。通过每位玩家的统计信息、队友统计信息、本局其他玩家的统计信息等,预测最终的游戏排名。注意排名是按照队伍排名,若多位玩家在PUBG一局游戏中组队,则最终排名相同。
数据简介
赛题训练集案例如下:
- 训练集5万数据,共150w行
- 测试集共5000条数据,共50w行
赛题数据文件总大小150MB,数据均为csv格式,列使用逗号分割。
测试集中label字段team_placement为空,需要选手预测。完整的数据字段含义如下:
- match_id:本局游戏的id
- team_id:本局游戏中队伍id,表示在每局游戏中队伍信息
- game_size:本局队伍数量
- party_size:本局游戏中队伍人数
- player_assists:玩家助攻数
- player_dbno:玩家击倒数
- player_dist_ride:玩家车辆行驶距离
- player_dist_walk:玩家不幸距离
- player_dmg:输出伤害值
- player_kills:玩家击杀数
- player_name:玩家名称,在训练集和测试集中全局唯一
- kill_distance_x_min:击杀另一位选手时最小的x坐标间隔
- kill_distance_x_max:击杀另一位选手时最大的x坐标间隔
- kill_distance_y_min:击杀另一位选手时最小的y坐标间隔
- kill_distance_y_max:击杀另一位选手时最大的x坐标间隔
- team_placement:队伍排名
GPT3生成代码
!pip install openai
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting openaiDownloading https://pypi.tuna.tsinghua.edu.cn/packages/35/41/eefdec12990436f746e39a16ccfcfbd8693cd8a5762014f27ec216d2487d/openai-0.26.5.tar.gz (55 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m55.5/55.5 kB[0m [31m2.1 MB/s[0m eta [36m0:00:00[0m
[?25h Installing build dependencies ... [?25ldone
[?25h Getting requirements to build wheel ... [?25ldone
[?25h Installing backend dependencies ... [?25ldone
[?25h Preparing metadata (pyproject.toml) ... [?25ldone
[?25hRequirement already satisfied: tqdm in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from openai) (4.64.1)
Requirement already satisfied: requests>=2.20 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from openai) (2.24.0)
Requirement already satisfied: aiohttp in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from openai) (3.8.3)
Requirement already satisfied: typing-extensions in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from openai) (4.3.0)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests>=2.20->openai) (1.25.11)
Requirement already satisfied: chardet<4,>=3.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests>=2.20->openai) (3.0.4)
Requirement already satisfied: certifi>=2017.4.17 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests>=2.20->openai) (2019.9.11)
Requirement already satisfied: idna<3,>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests>=2.20->openai) (2.8)
Requirement already satisfied: charset-normalizer<3.0,>=2.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from aiohttp->openai) (2.1.1)
Requirement already satisfied: async-timeout<5.0,>=4.0.0a3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from aiohttp->openai) (4.0.2)
Requirement already satisfied: yarl<2.0,>=1.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from aiohttp->openai) (1.7.2)
Requirement already satisfied: asynctest==0.13.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from aiohttp->openai) (0.13.0)
Requirement already satisfied: multidict<7.0,>=4.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from aiohttp->openai) (6.0.2)
Requirement already satisfied: frozenlist>=1.1.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from aiohttp->openai) (1.3.0)
Requirement already satisfied: aiosignal>=1.1.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from aiohttp->openai) (1.2.0)
Requirement already satisfied: attrs>=17.3.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from aiohttp->openai) (22.1.0)
Building wheels for collected packages: openaiBuilding wheel for openai (pyproject.toml) ... [?25ldone
[?25h Created wheel for openai: filename=openai-0.26.5-py3-none-any.whl size=67596 sha256=d03f1e4f9b857f39e62f014a1135847e908f3d2178bda927052181272e02e408Stored in directory: /home/aistudio/.cache/pip/wheels/8e/3c/49/ad5b4f26d8477b5d8ccb236dd655af6098c9e1a38d624e4549
Successfully built openai
Installing collected packages: openai
Successfully installed openai-0.26.5[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip available: [0m[31;49m22.1.2[0m[39;49m -> [0m[32;49m23.0.1[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpip install --upgrade pip[0m
注意下面的api_key需要同学自己申请,有18美元免费额度
import os
import openai# https://platform.openai.com/account/api-keys
# 这里需要填写你自己的Key,有18美元免费额度
openai.api_key = "sk-dTF"
- 读取数据集
response = openai.Completion.create(model="text-davinci-003",prompt = '''
Write python code to do fellowing task.
1. import pandas package as pd
2. read /home/aistudio/data/data137263/pubg_train.csv.zip to dataframe, name train_data.
3. read /home/aistudio/data/data137263/pubg_test.csv.zip to dataframe, name test_data.
4. show the data shape of train_data and test_data.
''',max_tokens=512,frequency_penalty=0.0,presence_penalty=0.0
)print(response['choices'][0]['text'].strip())
import pandas as pdtrain_data = pd.read_csv('/home/aistudio/data/data137263/pubg_train.csv.zip')
test_data = pd.read_csv('/home/aistudio/data/data137263/pubg_test.csv.zip')print(f'train_data shape is {train_data.shape}, test_data shape is {test_data.shape} ')
import pandas as pdtrain_data = pd.read_csv('/home/aistudio/data/data137263/pubg_train.csv.zip')
test_data = pd.read_csv('/home/aistudio/data/data137263/pubg_test.csv.zip')print(f'train_data shape is {train_data.shape}, test_data shape is {test_data.shape} ')
train_data shape is (1500000, 16), test_data shape is (500000, 15)
- 进行数据分析
response = openai.Completion.create(model="text-davinci-003",prompt = '''
Write python code to do fellowing task, there have dataframe train_data and test_data.
1. import package of matplotlib and snsborn
2. use box plot to show the distribuation of player_dmg columns for train and test.
''',max_tokens=512,frequency_penalty=0.0,presence_penalty=0.0
)print(response['choices'][0]['text'].strip())
import matplotlib.pyplot as plt #import package of matplotlib
import seaborn as sns #import package of snsbornf,axs = plt.subplots(1,2,figsize=(15,7)) #set the size of figuresns.boxplot(train_data.player_dmg, orient="v", ax=axs[0]) #box plot for training data
axs[0].set_title('Player Dmg Distribution in Train') #set title for training data
sns.boxplot(test_data.player_dmg, orient="v",ax=axs[1]) #box plot for test data
axs[1].set_title('Player Dmg Distribution in Test') #set title for test data
f.show() #show the figure
import matplotlib.pyplot as plt #import package of matplotlib
import seaborn as sns #import package of snsborn
%pylab inlinef,axs = plt.subplots(1,2,figsize=(10,5)) #set the size of figuresns.boxplot(train_data.player_dmg, orient="v", ax=axs[0]) #box plot for training data
axs[0].set_title('Player Dmg Distribution in Train') #set title for training data
sns.boxplot(test_data.player_dmg, orient="v",ax=axs[1]) #box plot for test data
axs[1].set_title('Player Dmg Distribution in Test') #set title for test data
f.show() #show the figure
Populating the interactive namespace from numpy and matplotlib/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/IPython/core/magics/pylab.py:160: UserWarning: pylab import has clobbered these variables: ['f']
`%matplotlib` prevents importing * from pylab and numpy"\n`%matplotlib` prevents importing * from pylab and numpy"
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/figure.py:457: UserWarning: matplotlib is currently using a non-GUI backend, so cannot show the figure"matplotlib is currently using a non-GUI backend, "
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nAnLnlvL-1677392241003)(output_10_2.png)]
- 训练模型
response = openai.Completion.create(model="text-davinci-003",prompt = '''
Write python code to do fellowing task, there have dataframe train_data and test_data, do not need read it.
1. drop match_id and team_id columns for train_data test_data and fill missing value
2. use LR in sklearn to train the model, team_placement is the target column.
3. use LR to predict the test_data (team_placement do not show in test_data), and save prediction in lr_pred
''',max_tokens=512,frequency_penalty=0.0,presence_penalty=0.0
)print(response['choices'][0]['text'].strip())
import pandas as pd
from sklearn.linear_model import LinearRegression# drop columns
train_data = train_data.drop(columns=['match_id', 'team_id'])
test_data = test_data.drop(columns=['match_id', 'team_id'])# fill missing values
train_data = train_data.fillna(train_data.mean())
test_data = test_data.fillna(test_data.mean())# fit LR
X = train_data.drop(columns='team_placement')
y = train_data['team_placement']lr_model = LinearRegression()
lr_model.fit(X, y)# predict and save result
lr_pred = lr_model.predict(test_data)
lr_pred_final = pd.DataFrame(lr_pred, columns=['team_placement'])
# drop columns
train_data = train_data.drop(columns=['match_id', 'team_id'])
test_data = test_data.drop(columns=['match_id', 'team_id'])# fill missing values
train_data = train_data.fillna(train_data.mean())
test_data = test_data.fillna(test_data.mean())# fit LR
X = train_data.drop(columns='team_placement')
y = train_data['team_placement']lr_model = LinearRegression()
lr_model.fit(X, y)# predict and save result
lr_pred = lr_model.predict(test_data)
lr_pred_final = pd.DataFrame(lr_pred, columns=['team_placement'])
OpenAI-GPT3 使用感受
在申请了免费的API后,笔者使用了多个例子,并尝试使用GPT3来编写一些竞赛代码。GPT3的功能比较多,确实比较强大,但也有一些缺点和注意事项。
- OpenAI-GPT3对英文支持比较好,将英文转换为代码 的效果优于 将中文转换为代码的效果。
- OpenAI-GPT3的结果效果取决于:
- prompt文本
- 给模型的提示或案例
- 选择的模型版权
- OpenAI-GPT3对对话支持的效果不如ChatGPT,但在完成特定任务上,效果比ChatGPT更好。