本文介绍ChatGLM-6B的模型结构,代码来自https://huggingface.co/THUDM/chatglm-6b/blob/main/modeling_chatglm.py。
相关博客
【自然语言处理】【大模型】ChatGLM-6B模型结构代码解析(单机版)
【自然语言处理】【大模型】BLOOM模型结构源码解析(单机版)
【自然语言处理】【大模型】极低资源微调大模型方法LoRA以及BLOOM-LORA实现代码
【深度学习】【分布式训练】Collective通信操作及Pytorch示例
【自然语言处理】【大模型】Chinchilla:训练计算利用率最优的大语言模型
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
【自然语言处理】【ChatGPT系列】大模型的涌现能力
一、激活函数
ChatGLM-6B使用的激活函数为GELU,其可以近似实现为:
GELU ( x ) ≈ 0.5 x ( 1 + tanh ( 2 π ( x + 0.044715 x 3 ) ) ) \text{GELU}(x)\approx 0.5x(1+\tanh(\sqrt{\frac{2}{\pi}}(x+0.044715x^3))) \\ GELU(x)≈0.5x(1+tanh(π2(x+0.044715x3)))
@torch.jit.script
def gelu_impl(x):"""OpenAI's gelu implementation."""return 0.5 * x * (1.0 + torch.tanh(0.7978845608028654 * x *(1.0 + 0.044715 * x * x)))def gelu(x):return gelu_impl(x)
二、GLU层
虽然在实现代码中命名为GLU,但这里实现的还是MLP层:
GLU ( X ) = GELU ( X W 1 ) W 2 \text{GLU}(X)=\text{GELU}(XW_1)W_2 GLU(X)=GELU(XW1)W2
class GLU(torch.nn.Module):def __init__(self, hidden_size, inner_hidden_size=None,layer_id=None, bias=True, activation_func=gelu, params_dtype=torch.float, empty_init=True):super(GLU, self).__init__()if empty_init:init_method = skip_initelse:init_method = default_initself.layer_id = layer_idself.activation_func = activation_func# Project to 4h.self.hidden_size = hidden_sizeif inner_hidden_size is None:inner_hidden_size = 4 * hidden_sizeself.inner_hidden_size = inner_hidden_sizeself.dense_h_to_4h = init_method(torch.nn.Linear,self.hidden_size,self.inner_hidden_size,bias=bias,dtype=params_dtype,)# Project back to h.self.dense_4h_to_h = init_method(torch.nn.Linear,self.inner_hidden_size,self.hidden_size,bias=bias,dtype=params_dtype,)def forward(self, hidden_states):"""hidden_states: [seq_len, batch, hidden_size]"""# [seq_len, batch, inner_hidden_size]# 投影intermediate_parallel = self.dense_h_to_4h(hidden_states)# 激活intermediate_parallel = self.activation_func(intermediate_parallel)# 投影output = self.dense_4h_to_h(intermediate_parallel)return output
三、位置编码:RoPE
1. 原理
位置编码采用RoPE,推导过程很有启发性,建议去看原文:Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间。本文仅介绍其实现:
总的来说,RoPE的目标是构建一个位置相关的投影矩阵,使得
( R m q ) ⊤ ( R n k ) = q ⊤ R m ⊤ R n k = q ⊤ R n − m k (\textbf{R}_m\textbf{q})^\top(\textbf{R}_n\textbf{k})=\textbf{q}^\top\textbf{R}_m^\top\textbf{R}_n\textbf{k}=\textbf{q}^\top\textbf{R}_{n-m}\textbf{k} \\ (Rmq)⊤(Rnk)=q⊤Rm⊤Rnk=q⊤Rn−mk
其中, q \textbf{q} q和 k \textbf{k} k分别对应注意力机制中的query和key向量, m m m和 n n n代表两个位置, R i \textbf{R}_i Ri表示位置 i i i处的投影矩阵。下面是作者建议 R \textbf{R} R的形式:
R θ , m d = [ cos m θ 1 − sin m θ 1 0 0 … 0 0 sin m θ 1 cos m θ 1 0 0 … 0 0 0 0 cos m θ 2 − sin m θ 2 … 0 0 0 0 sin m θ 2 cos m θ 2 … 0 0 ⋮ ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 0 0 0 0 … cos m θ d / 2 − sin m θ d / 2 0 0 0 0 … sin m θ d / 2 cos m θ d / 2 ] \textbf{R}^{d}_{\theta,m}= \begin{bmatrix} \cos m\theta_1 & -\sin m\theta_1 & 0 & 0 & \dots & 0 & 0 \\ \sin m\theta_1 & \cos m\theta_1 & 0 & 0 & \dots & 0 & 0 \\ 0 & 0 & \cos m\theta_2 & -\sin m\theta_2 & \dots & 0 & 0 \\ 0 & 0 & \sin m\theta_2 & \cos m\theta_2 & \dots & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots & \\ 0 & 0 & 0 & 0 & \dots & \cos m\theta_{d/2} & -\sin m\theta_{d/2} \\ 0 & 0 & 0 & 0 & \dots & \sin m\theta_{d/2} & \cos m\theta_{d/2} \end{bmatrix} Rθ,md= cosmθ1sinmθ100⋮00−sinmθ1cosmθ100⋮0000cosmθ2sinmθ2⋮0000−sinmθ2cosmθ2⋮00…………⋱……0000⋮cosmθd/2sinmθd/20000⋮−sinmθd/2cosmθd/2
其中, d d d是query和key的维度, θ \theta θ是一个超参数。
通常, θ \theta θ会设置为
θ = { θ i = 1000 0 − 2 ( i − 1 ) d , i ∈ [ 1 , 2 , … , d 2 ] } \theta=\Big\{\theta_i=10000^{\frac{-2(i-1)}{d}},i\in[1,2,\dots,\frac{d}{2}]\Big\} θ={θi=10000d−2(i−1),i∈[1,2,…,2d]}
由于矩阵 R \textbf{R} R非常稀疏,为了提供运算速度,作者也给出了实现方式,以query向量 q \textbf{q} q为例:
[ q 0 q 1 q 2 q 3 ⋮ q d − 2 q d − 1 ] ⊗ [ cos m θ 0 cos m θ 0 cos m θ 1 cos m θ 1 ⋮ cos m θ d / 2 − 1 cos m θ d / 2 − 1 ] + [ − q 1 q 0 − q 3 q 2 ⋮ − q d − 1 q d − 2 ] ⊗ [ sin m θ 0 sin m θ 0 sin m θ 1 sin m θ 1 ⋮ sin m θ d / 2 − 1 sin m θ d / 2 − 1 ] \begin{bmatrix} q_0 \\ q_1 \\ q_2 \\ q_3 \\ \vdots \\ q_{d-2} \\ q_{d-1} \end{bmatrix} \otimes \begin{bmatrix} \cos m\theta_0 \\ \cos m\theta_0 \\ \cos m\theta_1 \\ \cos m\theta_1 \\ \vdots \\ \cos m\theta_{d/2-1} \\ \cos m\theta_{d/2-1} \end{bmatrix} + \begin{bmatrix} -q_1 \\ q_0 \\ -q_3 \\ q_2 \\ \vdots \\ -q_{d-1} \\ q_{d-2} \end{bmatrix} \otimes \begin{bmatrix} \sin m\theta_0 \\ \sin m\theta_0 \\ \sin m\theta_1 \\ \sin m\theta_1 \\ \vdots \\ \sin m\theta_{d/2-1} \\ \sin m\theta_{d/2-1} \end{bmatrix} \\ q0q1q2q3⋮qd−2qd−1 ⊗ cosmθ0cosmθ0cosmθ1cosmθ1⋮cosmθd/2−1cosmθd/2−1 + −q1q0−q3q2⋮−qd−1qd−2 ⊗ sinmθ0sinmθ0sinmθ1sinmθ1⋮sinmθd/2−1sinmθd/2−1
2. 实现
ChatGLM-6B实现采用了PaLM的实现方式,不同于上面的公式:
[ q 0 ⋮ q d / 2 − 1 q d / 2 ⋮ q d − 1 ] ⊗ [ cos m θ 0 ⋮ cos m θ d / 2 − 1 cos m θ 0 ⋮ cos m θ d / 2 − 1 ] + [ − q d / 2 ⋮ − q d − 1 q 0 ⋮ q d / 2 − 1 ] ⊗ [ sin m θ 0 ⋮ sin m θ d / 2 − 1 sin m θ 0 ⋮ sin m θ d / 2 − 1 ] \begin{bmatrix} q_0 \\ \vdots \\ q_{d/2-1} \\ q_{d/2} \\ \vdots \\ q_{d-1}\end{bmatrix} \otimes \begin{bmatrix} \cos m\theta_0 \\ \vdots \\ \cos m\theta_{d/2-1} \\ \cos m\theta_0 \\ \vdots \\ \cos m\theta_{d/2-1} \end{bmatrix} + \begin{bmatrix} -q_{d/2} \\ \vdots \\ -q_{d-1} \\ q_0 \\ \vdots \\ q_{d/2-1}\end{bmatrix} \otimes \begin{bmatrix} \sin m\theta_0 \\ \vdots \\ \sin m\theta_{d/2-1} \\ \sin m\theta_0 \\ \vdots \\ \sin m\theta_{d/2-1} \end{bmatrix} q0⋮qd/2−1qd/2⋮qd−1 ⊗ cosmθ0⋮cosmθd/2−1cosmθ0⋮cosmθd/2−1 + −qd/2⋮−qd−1q0⋮qd/2−1 ⊗ sinmθ0⋮sinmθd/2−1sinmθ0⋮sinmθd/2−1
方便验证,该位置编码仍然满足对称性 ( R m q ) ⊤ ( R n k ) = q ⊤ R n − m k (\textbf{R}_m\textbf{q})^\top(\textbf{R}_n\textbf{k})=\textbf{q}^\top\textbf{R}_{n-m}\textbf{k} (Rmq)⊤(Rnk)=q⊤Rn−mk。但是其是如何推导而来的,暂时还没想清楚。
在代码中,RotaryEmbedding负责预先计算sin和cos;rotate_half负责上式第二项中,互换向量的奇偶位以及取负操作;apply_rotary_pos_emb_index则是对输入的query和key注入RoPE。
class RotaryEmbedding(torch.nn.Module):def __init__(self, dim, base=10000, precision=torch.half, learnable=False):super().__init__()# 预先计算好上面的thetainv_freq = 1. / (base ** (torch.arange(0, dim, 2).float() / dim))inv_freq = inv_freq.half()# learnable的效果并没有更好,通常learnable为Falseself.learnable = learnableif learnable:self.inv_freq = torch.nn.Parameter(inv_freq)self.max_seq_len_cached = Noneelse:self.register_buffer('inv_freq', inv_freq)self.max_seq_len_cached = Noneself.cos_cached = Noneself.sin_cached = Noneself.precision = precisiondef _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys,error_msgs):passdef forward(self, x, seq_dim=1, seq_len=None):if seq_len is None:seq_len = x.shape[seq_dim]if self.max_seq_len_cached is None or (seq_len > self.max_seq_len_cached):self.max_seq_len_cached = None if self.learnable else seq_lent = torch.arange(seq_len, device=x.device, dtype=self.inv_freq.dtype)# 这里使用了爱因斯坦求和约定,该操作就是t和self.inv_freq的外积# freqs中保存了所有的m\theta。e.g. 第一列是0\theta、第二列是1\thetafreqs = torch.einsum('i,j->ij', t, self.inv_freq)# 根据上面的公式,每个\theta都需要两份,所以这里将两个freqs拼接起来emb = torch.cat((freqs, freqs), dim=-1).to(x.device)if self.precision == torch.bfloat16:emb = emb.float()# [seq_length, 1 (b * np), hn]# 计算cos和sincos_cached = emb.cos()[:, None, :]sin_cached = emb.sin()[:, None, :]if self.precision == torch.bfloat16:cos_cached = cos_cached.bfloat16()sin_cached = sin_cached.bfloat16()if self.learnable:return cos_cached, sin_cached# 缓存结果,方便重复利用self.cos_cached, self.sin_cached = cos_cached, sin_cachedreturn self.cos_cached[:seq_len, ...], self.sin_cached[:seq_len, ...]def _apply(self, fn):if self.cos_cached is not None:self.cos_cached = fn(self.cos_cached)if self.sin_cached is not None:self.sin_cached = fn(self.sin_cached)return super()._apply(fn)def rotate_half(x):# x1是x的前半部分,x2是x的后半部分x1, x2 = x[..., :x.shape[-1] // 2], x[..., x.shape[-1] // 2:]# 前后互换,且后半部分取负return torch.cat((-x2, x1), dim=x1.ndim - 1)@torch.jit.script
def apply_rotary_pos_emb_index(q, k, cos, sin, position_id):cos, sin = F.embedding(position_id, cos.squeeze(1)).unsqueeze(2), \F.embedding(position_id, sin.squeeze(1)).unsqueeze(2)q, k = (q * cos) + (rotate_half(q) * sin), (k * cos) + (rotate_half(k) * sin)return q, k
四、注意力层
1. 原理
二维位置编码。这里仍然采用了GLM-10B的二维位置编码,如下图所示:

输入的样本是 x 1 , x 2 , x 3 , x 4 , x 5 , x 6 x_1,x_2,x_3,x_4,x_5,x_6 x1,x2,x3,x4,x5,x6,片段 x 3 x_3 x3和 x 5 , x 6 x_5,x_6 x5,x6被随机挑选遮蔽掉,原始的输入样本变为 x 1 , x 2 , [ M ] , x 4 , [ M ] x_1,x_2,[M],x_4,[M] x1,x2,[M],x4,[M],这个过程如上图(a)和(b)所示。将三个片段拼接在一起得到模型的输入 x 1 , x 2 , [ M ] , x 4 , [ M ] , [ S ] , x 5 , x 6 , [ S ] , x 3 x_1,x_2,[M],x_4,[M],[S],x_5,x_6,[S],x_3 x1,x2,[M],x4,[M],[S],x5,x6,[S],x3,模型的输出则是被遮蔽掉的片段,如上图©所示。这里使用了2种位置编码:第一种编码为整个输入注入位置信息,能够表示遮蔽片段在原始输入中的位置;第二种位置编码则是为遮蔽片段内的tokens输入位置信息。
自注意力机制。标准的自注意力机制为:
Q = W q X K = W k X V = W v X Attention ( Q , K , V , A ) = softmax ( Q K T d k ) V \begin{align} Q &= W_q X \\ K &= W_k X \\ V &= W_v X \\ \text{Attention}(Q,K,V,A) &= \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V \end{align} \\ QKVAttention(Q,K,V,A)=WqX=WkX=WvX=softmax(dkQKT)V
其中,X是输入, W q , W k , W v W_q,W_k,W_v Wq,Wk,Wv 分别是query、key、value的投影矩阵。相比于标准的注意力机制,ChatGLM-6B在 Q Q Q和 K K K中注意力了RoPE位置信息。多头注意力就是将多个单头注意力的结果拼接起来。
head i = Attention ( Q i , K i , V i , A i ) MultiHead ( Q , K , V , A ) = Concat ( head 1 , … , head h ) W o \begin{align} \text{head}_i&=\text{Attention}(Q_i,K_i,V_i,A_i) \\ \text{MultiHead}(Q,K,V,A)&=\text{Concat}(\text{head}_1,\dots,\text{head}_h)W_o \end{align} \\ headiMultiHead(Q,K,V,A)=Attention(Qi,Ki,Vi,Ai)=Concat(head1,…,headh)Wo
2. 实现
- 函数
attention_fn实现了标准的自注意力机制。
def attention_fn(self,query_layer,key_layer,value_layer,attention_mask,hidden_size_per_partition,layer_id,layer_past=None,scaling_attention_score=True,use_cache=False,
):# 将传递来的key和value合并至当前的Q和K上(推理场景)if layer_past is not None:past_key, past_value = layer_past[0], layer_past[1]key_layer = torch.cat((past_key, key_layer), dim=0)value_layer = torch.cat((past_value, value_layer), dim=0)# seqlen, batch, num_attention_heads, hidden_size_per_attention_headseq_len, b, nh, hidden_size = key_layer.shapeif use_cache:present = (key_layer, value_layer)else:present = None# 对query层进行scalingquery_key_layer_scaling_coeff = float(layer_id + 1)if scaling_attention_score:query_layer = query_layer / (math.sqrt(hidden_size) * query_key_layer_scaling_coeff)# 注意力分数的输出形状: [batch_size, num_heads, seq_length, seq_length]output_size = (query_layer.size(1), query_layer.size(2), query_layer.size(0), key_layer.size(0))# 形状重塑:[seq_length, batch_size, num_heads, head_dim] -># [seq_length, batch_size*num_heads, head_dim]query_layer = query_layer.view(output_size[2], output_size[0] * output_size[1], -1)key_layer = key_layer.view(output_size[3], output_size[0] * output_size[1], -1)matmul_result = torch.zeros(1, 1, 1,dtype=query_layer.dtype,device=query_layer.device,)# 计算非规范化的注意力分数,matmul_result形状为[batch_size*num_head, seq_length,seq_length]matmul_result = torch.baddbmm(matmul_result,query_layer.transpose(0, 1), # [b * np, sq, hn]key_layer.transpose(0, 1).transpose(1, 2), # [b * np, hn, sk]beta=0.0,alpha=1.0,)# 重塑形状为:[batch_size,num_head,seq_length,seq_length]attention_scores = matmul_result.view(*output_size)# 对注意分数进行缩放和规范化if self.scale_mask_softmax:self.scale_mask_softmax.scale = query_key_layer_scaling_coeffattention_probs = self.scale_mask_softmax(attention_scores, attention_mask.contiguous())else:# 对注意力分数进行maskif not (attention_mask == 0).all():attention_scores.masked_fill_(attention_mask, -10000.0)dtype = attention_scores.dtypeattention_scores = attention_scores.float()attention_scores = attention_scores * query_key_layer_scaling_coeffattention_probs = F.softmax(attention_scores, dim=-1)attention_probs = attention_probs.type(dtype)### 使用注意力分数对value进行加权求和output_size = (value_layer.size(1), value_layer.size(2), query_layer.size(0), value_layer.size(3))# 重塑value的形状value_layer = value_layer.view(value_layer.size(0), output_size[0] * output_size[1], -1)# 重塑注意力分数的形状attention_probs = attention_probs.view(output_size[0] * output_size[1], output_size[2], -1)# 注意力分数乘以value,得到最终的输出contextcontext_layer = torch.bmm(attention_probs, value_layer.transpose(0, 1))context_layer = context_layer.view(*output_size)context_layer = context_layer.permute(2, 0, 1, 3).contiguous()new_context_layer_shape = context_layer.size()[:-2] + (hidden_size_per_partition,)context_layer = context_layer.view(*new_context_layer_shape)outputs = (context_layer, present, attention_probs)return outputs
SelfAttention则是为query和key注入RoPE,然后调用attention_fn实现注意力机制。
class SelfAttention(torch.nn.Module):def __init__(self, hidden_size, num_attention_heads,layer_id, hidden_size_per_attention_head=None, bias=True,params_dtype=torch.float, position_encoding_2d=True, empty_init=True):if empty_init:init_method = skip_initelse:init_method = default_initsuper(SelfAttention, self).__init__()self.layer_id = layer_idself.hidden_size = hidden_sizeself.hidden_size_per_partition = hidden_sizeself.num_attention_heads = num_attention_headsself.num_attention_heads_per_partition = num_attention_heads# position_encoding_2d:是否使用2维的位置编码self.position_encoding_2d = position_encoding_2d# RoPEself.rotary_emb = RotaryEmbedding(self.hidden_size // (self.num_attention_heads * 2)if position_encoding_2delse self.hidden_size // self.num_attention_heads,base=10000,precision=torch.half,learnable=False,)self.scale_mask_softmax = Noneif hidden_size_per_attention_head is None:self.hidden_size_per_attention_head = hidden_size // num_attention_headselse:self.hidden_size_per_attention_head = hidden_size_per_attention_headself.inner_hidden_size = num_attention_heads * self.hidden_size_per_attention_head# query、key、value的投影层self.query_key_value = init_method(torch.nn.Linear,hidden_size,3 * self.inner_hidden_size,bias=bias,dtype=params_dtype,)self.dense = init_method(torch.nn.Linear,self.inner_hidden_size,hidden_size,bias=bias,dtype=params_dtype,)@staticmethoddef attention_mask_func(attention_scores, attention_mask):attention_scores.masked_fill_(attention_mask, -10000.0)return attention_scoresdef split_tensor_along_last_dim(self, tensor, num_partitions,contiguous_split_chunks=False):"""沿最后一个维度切分tensor参数:tensor: 输入tensor;num_partitions: 切分tensor的数量;contiguous_split_chunks: 若为True,切分的块在内存中连续;"""last_dim = tensor.dim() - 1last_dim_size = tensor.size()[last_dim] // num_partitionstensor_list = torch.split(tensor, last_dim_size, dim=last_dim)# torch.split并不会默认创建连续的tensorif contiguous_split_chunks:return tuple(chunk.contiguous() for chunk in tensor_list)return tensor_listdef forward(self,hidden_states: torch.Tensor,position_ids,attention_mask: torch.Tensor,layer_id,layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,use_cache: bool = False,output_attentions: bool = False,):"""hidden_states: [seq_len, batch, hidden_size]attention_mask: [(1, 1), seq_len, seq_len]"""# 一次性得到投影的Q、K、V,减少执行矩阵乘法的次数# [seq_len, batch, 3 * hidden_size]mixed_raw_layer = self.query_key_value(hidden_states)# 拆分出多头# [seq_len, batch, 3 * hidden_size] --> [seq_len, batch, num_attention_heads, 3 * hidden_size_per_attention_head]new_tensor_shape = mixed_raw_layer.size()[:-1] + (self.num_attention_heads_per_partition,3 * self.hidden_size_per_attention_head,)mixed_raw_layer = mixed_raw_layer.view(*new_tensor_shape)# [seq_len, batch, num_attention_heads, hidden_size_per_attention_head]# 此时的query_layer、key_layer、value_layer已经是拆分出多头的Q、K、V(query_layer, key_layer, value_layer) = self.split_tensor_along_last_dim(mixed_raw_layer, 3)if self.position_encoding_2d:## 这里将query和key拆分为两份,分别注入不同的位置信息,然后再拼接在一起# 拆分q1, q2 = query_layer.chunk(2, dim=(query_layer.ndim - 1))k1, k2 = key_layer.chunk(2, dim=(key_layer.ndim - 1))# 计算cos和sin值cos, sin = self.rotary_emb(q1, seq_len=position_ids.max() + 1)position_ids, block_position_ids = position_ids[:, 0, :].transpose(0, 1).contiguous(), \position_ids[:, 1, :].transpose(0, 1).contiguous()# 将两种位置编码输入到不同的query和key上q1, k1 = apply_rotary_pos_emb_index(q1, k1, cos, sin, position_ids)q2, k2 = apply_rotary_pos_emb_index(q2, k2, cos, sin, block_position_ids)# 拼接注入不同位置信息的query和key,这样query和key中包含了两种位置信息query_layer = torch.concat([q1, q2], dim=(q1.ndim - 1))key_layer = torch.concat([k1, k2], dim=(k1.ndim - 1))else:# 普通的RoPEposition_ids = position_ids.transpose(0, 1)cos, sin = self.rotary_emb(value_layer, seq_len=position_ids.max() + 1)# [seq_len, batch, num_attention_heads, hidden_size_per_attention_head]query_layer, key_layer = apply_rotary_pos_emb_index(query_layer, key_layer, cos, sin, position_ids)# [seq_len, batch, hidden_size]context_layer, present, attention_probs = attention_fn(self=self,query_layer=query_layer,key_layer=key_layer,value_layer=value_layer,attention_mask=attention_mask,hidden_size_per_partition=self.hidden_size_per_partition,layer_id=layer_id,layer_past=layer_past,use_cache=use_cache)output = self.dense(context_layer)outputs = (output, present)if output_attentions:outputs += (attention_probs,)return outputs # output, present, attention_probs
五、GLMBlock
GLMBlock的基本结构为:Layer Norm、Self Attention(输入和输出残差连接)、Layer Norm、GLU(输入和输出残差连接)。
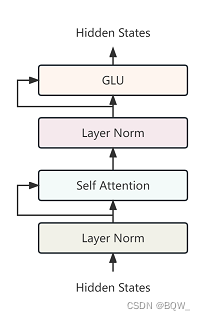
class GLMBlock(torch.nn.Module):def __init__(self,hidden_size,num_attention_heads,layernorm_epsilon,layer_id,inner_hidden_size=None,hidden_size_per_attention_head=None,layernorm=LayerNorm,use_bias=True,params_dtype=torch.float,num_layers=28,position_encoding_2d=True,empty_init=True):super(GLMBlock, self).__init__()# Set output layer initialization if not provided.self.layer_id = layer_id# LayerNorm层self.input_layernorm = layernorm(hidden_size, eps=layernorm_epsilon)# 是否使用2维位置编码self.position_encoding_2d = position_encoding_2d# 自注意力层self.attention = SelfAttention(hidden_size,num_attention_heads,layer_id,hidden_size_per_attention_head=hidden_size_per_attention_head,bias=use_bias,params_dtype=params_dtype,position_encoding_2d=self.position_encoding_2d,empty_init=empty_init)# Post Layer Norm层self.post_attention_layernorm = layernorm(hidden_size, eps=layernorm_epsilon)self.num_layers = num_layers# GLU层self.mlp = GLU(hidden_size,inner_hidden_size=inner_hidden_size,bias=use_bias,layer_id=layer_id,params_dtype=params_dtype,empty_init=empty_init)def forward(self,hidden_states: torch.Tensor,position_ids,attention_mask: torch.Tensor,layer_id,layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,use_cache: bool = False,output_attentions: bool = False,):"""hidden_states: [seq_len, batch, hidden_size]attention_mask: [(1, 1), seq_len, seq_len]"""# 对输入进行Layer Norm# [seq_len, batch, hidden_size]attention_input = self.input_layernorm(hidden_states)# 自注意力attention_outputs = self.attention(attention_input,position_ids,attention_mask=attention_mask,layer_id=layer_id,layer_past=layer_past,use_cache=use_cache,output_attentions=output_attentions)attention_output = attention_outputs[0]outputs = attention_outputs[1:]# 自注意力的输出和输入残差连接alpha = (2 * self.num_layers) ** 0.5hidden_states = attention_input * alpha + attention_output# Layer Normmlp_input = self.post_attention_layernorm(hidden_states)# 全连接层投影mlp_output = self.mlp(mlp_input)# MLP层的输出和输入残差连接output = mlp_input * alpha + mlp_outputif use_cache:outputs = (output,) + outputselse:outputs = (output,) + outputs[1:]return outputs # hidden_states, present, attentions
六、ChatGLMPreTrainedModel
ChatGLMPreTrainedModel是ChatGLMModel和ChatGLMForConditionalGeneration,其提供获取注意力mask和position ids。
1. Mask
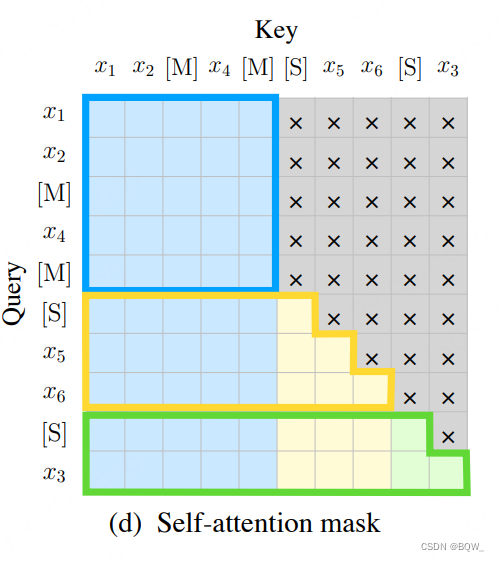
ChatGLM-6B使用的Mask仍然是prefix-LM的Mask,其对于输入的前缀使用双向注意力,对于后续的生成部分则是Causal Mask。下面是ChatGLMPreTrainedModel中的get_masks函数实现:
def get_masks(self, input_ids, device):batch_size, seq_length = input_ids.shape# context_lengths记录了batch中每个样本的真实长度context_lengths = [seq.tolist().index(self.config.bos_token_id) for seq in input_ids]# 生成causal mask,即下三角以及对角线为1,上三角为0attention_mask = torch.ones((batch_size, seq_length, seq_length), device=device)attention_mask.tril_()# 将前缀部分的注意力改为双向for i, context_length in enumerate(context_lengths):attention_mask[i, :, :context_length] = 1attention_mask.unsqueeze_(1)attention_mask = (attention_mask < 0.5).bool()return attention_mask
2. Position_ids
在介绍注意力层的时候,已经介绍过2维的postion_ids了。代码实现中,position_ids就是GLM论文中的Position 1,block_position_ids则是论文中的Position 2。
def get_position_ids(self, input_ids, mask_positions, device, use_gmasks=None):"""input_ids: [batch_size, seq_length]mask_positions: [batch_size],由于GLM系列中会使用[Mask]或[gMask]标志,mask_positions就是指这些标注的具体位置"""batch_size, seq_length = input_ids.shapeif use_gmasks is None:use_gmasks = [False] * batch_size# context_lengths:未被padding前,batch中各个样本的长度context_lengths = [seq.tolist().index(self.config.bos_token_id) for seq in input_ids]# 2维位置编码if self.position_encoding_2d:# [0,1,2,...,seq_length-1]position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)# 将原始输入后所有位置的postion id都设置为[Mask]或者[gMask]的位置id# (该操作见注意力层对位置编码的介绍)for i, context_length in enumerate(context_lengths):position_ids[i, context_length:] = mask_positions[i]# 原始输入的位置编码全部设置为0,待生成的位置添加顺序的位置id# 例如:[0,0,0,0,1,2,3,4,5]block_position_ids = [torch.cat((torch.zeros(context_length, dtype=torch.long, device=device),torch.arange(seq_length - context_length, dtype=torch.long, device=device) + 1)) for context_length in context_lengths]block_position_ids = torch.stack(block_position_ids, dim=0)# 将postion_ids和block_position_ids堆叠在一起,用于后续的参数传入;# 在注意力层中,还有将这个position_ids拆分为两部分position_ids = torch.stack((position_ids, block_position_ids), dim=1)else:position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)for i, context_length in enumerate(context_lengths):if not use_gmasks[i]:position_ids[i, context_length:] = mask_positions[i]return position_ids
七、ChatGLMModel
ChatGLMModel基本就是通过上面介绍的各个组件构造最终的模型。原理没什么可介绍了,直接来看代码。下面的代码会将不易于理解模型结构的部分删除掉,因此与原始版本略有不同。
class ChatGLMModel(ChatGLMPreTrainedModel):def __init__(self, config: ChatGLMConfig, empty_init=True):super().__init__(config)if empty_init:init_method = skip_initelse:init_method = default_init# 保存各类参数self.max_sequence_length = config.max_sequence_lengthself.hidden_size = config.hidden_sizeself.params_dtype = torch.halfself.num_attention_heads = config.num_attention_headsself.vocab_size = config.vocab_sizeself.num_layers = config.num_layersself.layernorm_epsilon = config.layernorm_epsilonself.inner_hidden_size = config.inner_hidden_sizeself.hidden_size_per_attention_head = self.hidden_size // self.num_attention_headsself.position_encoding_2d = config.position_encoding_2dself.pre_seq_len = config.pre_seq_lenself.prefix_projection = config.prefix_projection# 初始化embedding层self.word_embeddings = init_method(torch.nn.Embedding,num_embeddings=self.vocab_size, embedding_dim=self.hidden_size,dtype=self.params_dtype)self.gradient_checkpointing = Falsedef get_layer(layer_id):return GLMBlock(self.hidden_size,self.num_attention_heads,self.layernorm_epsilon,layer_id,inner_hidden_size=self.inner_hidden_size,hidden_size_per_attention_head=self.hidden_size_per_attention_head,layernorm=LayerNorm,use_bias=True,params_dtype=self.params_dtype,position_encoding_2d=self.position_encoding_2d,empty_init=empty_init)# 堆叠GLMBlockself.layers = torch.nn.ModuleList([get_layer(layer_id) for layer_id in range(self.num_layers)])# 最后的Layer Norm层self.final_layernorm = LayerNorm(self.hidden_size, eps=self.layernorm_epsilon)def get_input_embeddings(self):return self.word_embeddingsdef set_input_embeddings(self, new_embeddings: torch.Tensor):self.word_embeddings = new_embeddings@add_start_docstrings_to_model_forward(CHATGLM_6B_INPUTS_DOCSTRING.format("batch_size, sequence_length"))@add_code_sample_docstrings(checkpoint=_CHECKPOINT_FOR_DOC,output_type=BaseModelOutputWithPastAndCrossAttentions,config_class=_CONFIG_FOR_DOC,)def forward(self,input_ids: Optional[torch.LongTensor] = None,position_ids: Optional[torch.LongTensor] = None,attention_mask: Optional[torch.Tensor] = None,past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,inputs_embeds: Optional[torch.LongTensor] = None,use_cache: Optional[bool] = None,output_attentions: Optional[bool] = None,output_hidden_states: Optional[bool] = None,return_dict: Optional[bool] = None,) -> Union[Tuple[torch.Tensor, ...], BaseModelOutputWithPast]:### (开始)一些输入输入和参数设置,可以忽略output_attentions = output_attentions if output_attentions is not None else self.config.output_attentionsoutput_hidden_states = (output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states)use_cache = use_cache if use_cache is not None else self.config.use_cachereturn_dict = return_dict if return_dict is not None else self.config.use_return_dictif self.gradient_checkpointing and self.training:if use_cache:logger.warning_once("`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")use_cache = Falseif input_ids is not None and inputs_embeds is not None:raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")elif input_ids is not None:batch_size, seq_length = input_ids.shape[:2]elif inputs_embeds is not None:batch_size, seq_length = inputs_embeds.shape[:2]else:raise ValueError("You have to specify either input_ids or inputs_embeds")### (结束)一些输入输出和参数设置,可以忽略# embedding层if inputs_embeds is None:inputs_embeds = self.word_embeddings(input_ids)if past_key_values is None:past_key_values = tuple([None] * len(self.layers))# 获得注意力mask,该功能继承自ChatGLMPreTrainedModelif attention_mask is None:attention_mask = self.get_masks(input_ids,device=input_ids.device)if position_ids is None:MASK, gMASK = self.config.mask_token_id, self.config.gmask_token_idseqs = input_ids.tolist()# 记录input_ids中是否使用了mask以及mask的位置# mask_positions记录每个样本中mask的位置# use_gmasks记录是否使用了gMaskmask_positions, use_gmasks = [], []for seq in seqs:mask_token = gMASK if gMASK in seq else MASKuse_gmask = mask_token == gMASKmask_positions.append(seq.index(mask_token))use_gmasks.append(use_gmask)# 获得position_ids,该功能继承自ChatGLMPreTrainedModelposition_ids = self.get_position_ids(input_ids,mask_positions=mask_positions,device=input_ids.device,use_gmasks=use_gmasks)# [seq_len, batch, hidden_size]hidden_states = inputs_embeds.transpose(0, 1)presents = () if use_cache else Noneall_self_attentions = () if output_attentions else Noneall_hidden_states = () if output_hidden_states else Noneif attention_mask is None:attention_mask = torch.zeros(1, 1, device=input_ids.device).bool()else:attention_mask = attention_mask.to(hidden_states.device)# 模型的前向传播for i, layer in enumerate(self.layers):if output_hidden_states:all_hidden_states = all_hidden_states + (hidden_states,)layer_past = past_key_values[i]if self.gradient_checkpointing and self.training:layer_ret = torch.utils.checkpoint.checkpoint(layer,hidden_states,position_ids,attention_mask,torch.tensor(i),layer_past,use_cache,output_attentions)else:layer_ret = layer(hidden_states,position_ids=position_ids,attention_mask=attention_mask,layer_id=torch.tensor(i),layer_past=layer_past,use_cache=use_cache,output_attentions=output_attentions)hidden_states = layer_ret[0]if use_cache:presents = presents + (layer_ret[1],)if output_attentions:all_self_attentions = all_self_attentions + (layer_ret[2 if use_cache else 1],)# 最终的Layer Normhidden_states = self.final_layernorm(hidden_states)if output_hidden_states:all_hidden_states = all_hidden_states + (hidden_states,)if not return_dict:return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)return BaseModelOutputWithPast(last_hidden_state=hidden_states,past_key_values=presents,hidden_states=all_hidden_states,attentions=all_self_attentions,)