ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
1.工具&框架

预训练模型:YaLM 100B - 100B参数预训练语言模型
tags: [预训练,语言模型,大模型]
大型模型用于文本生成和处理的类GPT开源预训练神经网络
'YaLM 100B - Pretrained language model with 100B parameters,a GPT-like neural network for generating and processing text’ by Yandex
GitHub: https://github.com/yandex/YaLM-100B

工具框架:NFShmServer - 用C++开发的共享内存的插件开发框架
tags: [内存共享,插件]
轻量级、敏捷型、弹性的、分布式支持,让你更快更简单的开发服务端应用
GitHub: https://github.com/yigao/NFShmServer


工具:Nocturne - 数据驱动的快速2D多智能体驾驶模拟器
tags: [多智能体,驾驶模拟,模拟器]
‘Nocturne - A data-driven, fast driving simulator for multi-agent coordination under partial observability.’ by Meta Research
GitHub: https://github.com/facebookresearch/nocturne


工具框架:FidelityFX Super Resolution(FSR) - FidelityFX超分辨率框架
tags: [超分辨率,工具]
‘FidelityFX Super Resolution 2.0.1 (FSR 2.0) - FidelityFX Super Resolution 2’ by GPUOpen Effects
GitHub: https://github.com/GPUOpen-Effects/FidelityFX-FSR2


工具库:NNCF - 神经网络压缩框架
tags: [神经网络,网络压缩]
‘Neural Network Compression Framework (NNCF) - Neural Network Compression Framework for enhanced OpenVINO inference’ by OpenVINO Toolkit
GitHub: https://github.com/openvinotoolkit/nncf

2.项目&代码

代码实现:Recommend-System-TF2.0 - 推荐算法实现
‘于记录在学习推荐系统过程中的知识产出,主要是对经典推荐算法的原理解析及代码实现’ by jc_Lee
GitHub: https://github.com/jc-LeeHub/Recommend-System-tf2.0

3.博文&分享

博文:Transformer前向传播能有多快?
《How fast can we perform a forward pass?》by Jacob Steinhardt
Link: https://bounded-regret.ghost.io/how-fast-can-we-perform-a-forward-pass/


4.数据&资源

资源列表:Rolling-shutter-Effects - 图像畸变校正(滚动快门/径向失真/文字失真等)相关文献资源列表
tags: [图像畸变,图像校正,资源列表]
‘Rolling-shutter-Effects - A curated list of resources on handling Rolling Shutter effects and Radial Distortions’ by Subeesh Vasu
GitHub: https://github.com/subeeshvasu/Awesome-Image-Distortion-Correction

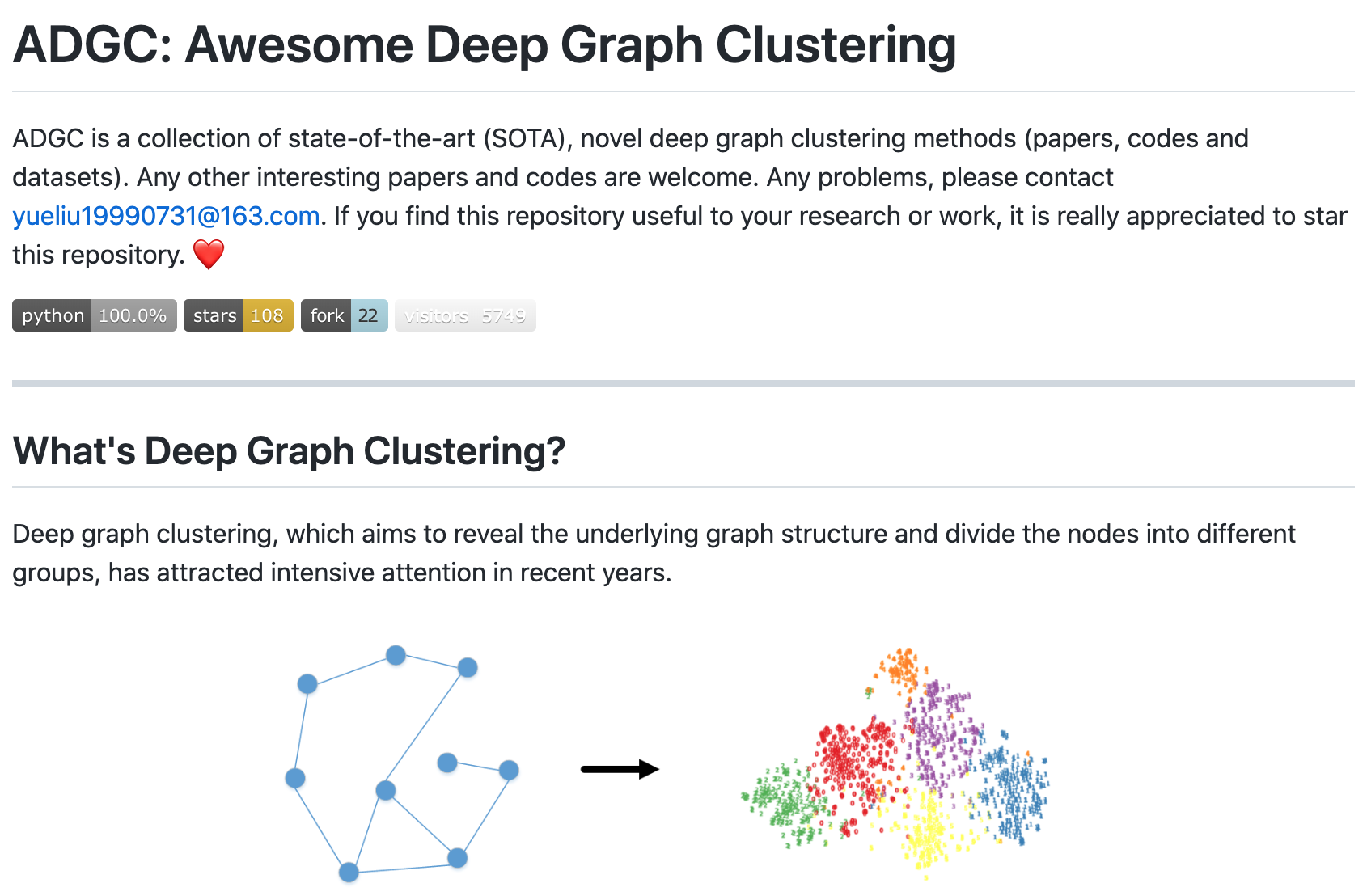
资源列表:ADGC - 深度图聚类相关文献资源大列表
‘ADGC: Awesome Deep Graph Clustering - Awesome Deep Graph Clustering is a collection of SOTA, novel deep graph clustering methods (papers, codes, and datasets).’ by yueliu1999
GitHub: https://github.com/yueliu1999/Awesome-Deep-Graph-Clustering
5.研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的6月论文合辑。
论文:Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
论文标题:Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
论文时间:22 Jun 2022
所属领域:计算机视觉,自然语言处理
对应任务:Image Generation,Machine Translation,Text to image generation,Text-to-Image Generation,图像生成,机器翻译,文本到图像生成
论文地址:https://arxiv.org/abs/2206.10789
代码实现:https://github.com/lucidrains/parti-pytorch
论文作者:Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, ZiRui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, Ben Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge, Yonghui Wu
论文简介:We present the Pathways Autoregressive Text-to-Image (Parti) model, which generates high-fidelity photorealistic images and supports content-rich synthesis involving complex compositions and world knowledge./我们提出了Pathways Autoregressive Text-to-Image (Parti)模型,它能生成高保真的逼真图像,并支持涉及复杂构图和世界知识的内容丰富的合成。
论文摘要:We present the Pathways Autoregressive Text-to-Image (Parti) model, which generates high-fidelity photorealistic images and supports content-rich synthesis involving complex compositions and world knowledge. Parti treats text-to-image generation as a sequence-to-sequence modeling problem, akin to machine translation, with sequences of image tokens as the target outputs rather than text tokens in another language. This strategy can naturally tap into the rich body of prior work on large language models, which have seen continued advances in capabilities and performance through scaling data and model sizes. Our approach is simple: First, Parti uses a Transformer-based image tokenizer, ViT-VQGAN, to encode images as sequences of discrete tokens. Second, we achieve consistent quality improvements by scaling the encoder-decoder Transformer model up to 20B parameters, with a new state-of-the-art zero-shot FID score of 7.23 and finetuned FID score of 3.22 on MS-COCO. Our detailed analysis on Localized Narratives as well as PartiPrompts (P2), a new holistic benchmark of over 1600 English prompts, demonstrate the effectiveness of Parti across a wide variety of categories and difficulty aspects. We also explore and highlight limitations of our models in order to define and exemplify key areas of focus for further improvements. See https://parti.research.google/ for high-resolution images
我们提出了Pathways Autoregressive Text-to-Image (Parti)模型,它能生成高保真的逼真图像,并支持涉及复杂构图和世界知识的内容丰富的合成。Parti将文本到图像的生成视为一个序列到序列的建模问题,类似于机器翻译,将图像标记的序列作为目标输出,而不是另一种语言的文本标记。这种策略可以自然而然地利用先前关于大型语言模型的丰富工作,通过扩大数据和模型的规模,这些模型的能力和性能都有了持续的进步。我们的方法很简单。首先,Parti使用基于Transformer的图像标记器ViT-VQGAN,将图像编码为离散的标记序列。其次,我们通过将编码器-解码器Transformer模型扩展到20B的参数,实现了质量的持续改进,在MS-COCO上,新的最先进的零拍FID得分为7.23,微调的FID得分为3.22。我们对Localized Narratives以及PartiPrompts(P2)的详细分析,这是一个由1600多个英语提示语组成的新的整体基准,证明了Parti在各种类别和难度方面的有效性。我们还探讨并强调了我们的模型的局限性,以确定和示范进一步改进的重点领域。高分辨率图片见 https://parti.research.google/


论文:The ArtBench Dataset: Benchmarking Generative Models with Artworks
论文标题:The ArtBench Dataset: Benchmarking Generative Models with Artworks
论文时间:22 Jun 2022
所属领域:计算机视觉
对应任务:Conditional Image Generation,Image Generation,Unconditional Image Generation,条件性图像生成,图像生成,无条件性图像生成
论文地址:https://arxiv.org/abs/2206.11404
代码实现:https://github.com/liaopeiyuan/artbench
论文作者:Peiyuan Liao, Xiuyu Li, Xihui Liu, Kurt Keutzer
论文简介:We introduce ArtBench-10, the first class-balanced, high-quality, cleanly annotated, and standardized dataset for benchmarking artwork generation./我们推出了ArtBench-10,它是第一个类平衡的、高质量的、干净注释的和标准化的数据集,用于对艺术品生成进行基准测试。
论文摘要:We introduce ArtBench-10, the first class-balanced, high-quality, cleanly annotated, and standardized dataset for benchmarking artwork generation. It comprises 60,000 images of artwork from 10 distinctive artistic styles, with 5,000 training images and 1,000 testing images per style. ArtBench-10 has several advantages over previous artwork datasets. Firstly, it is class-balanced while most previous artwork datasets suffer from the long tail class distributions. Secondly, the images are of high quality with clean annotations. Thirdly, ArtBench-10 is created with standardized data collection, annotation, filtering, and preprocessing procedures. We provide three versions of the dataset with different resolutions (32×32, 256×256, and original image size), formatted in a way that is easy to be incorporated by popular machine learning frameworks. We also conduct extensive benchmarking experiments using representative image synthesis models with ArtBench-10 and present in-depth analysis. The dataset is available at https://github.com/liaopeiyuan/artbench under a Fair Use license.
我们推出ArtBench-10,它是第一个类平衡的、高质量的、干净注释的、标准化的艺术品生成基准数据集。它包括来自10种独特艺术风格的60,000张艺术品图像,每种风格有5,000张训练图像和1,000张测试图像。与以前的艺术品数据集相比,ArtBench-10有几个优点。首先,它是类平衡的,而以前的大多数艺术品数据集都有长尾类分布的问题。第二,图像质量高,注释干净。第三,ArtBench-10是通过标准化的数据收集、注释、过滤和预处理程序创建的。我们提供了三个不同分辨率的数据集版本(32×32、256×256和原始图像大小),其格式化的方式很容易被流行的机器学习框架所采纳。我们还使用ArtBench-10的代表性图像合成模型进行了广泛的基准实验,并进行了深入的分析。该数据集在Fair Use license下可在 https://github.com/liaopeiyuan/artbench 获取使用。

论文:Remote Sensing Change Detection (Segmentation) using Denoising Diffusion Probabilistic Models
论文标题:Remote Sensing Change Detection (Segmentation) using Denoising Diffusion Probabilistic Models
论文时间:23 Jun 2022
所属领域:计算机视觉
对应任务:Change Detection,Denoising,改变检测,去噪
论文地址:https://arxiv.org/abs/2206.11892
代码实现:https://github.com/wgcban/ddpm-cd
论文作者:Wele Gedara Chaminda Bandara, Nithin Gopalakrishnan Nair, Vishal M. Patel
论文简介:Human civilization has an increasingly powerful influence on the earth system, and earth observations are an invaluable tool for assessing and mitigating the negative impacts./人类文明对地球系统的影响越来越大,而对地观测是评估和减轻负面影响的宝贵工具。
论文摘要:Human civilization has an increasingly powerful influence on the earth system, and earth observations are an invaluable tool for assessing and mitigating the negative impacts. To this end, observing precisely defined changes on Earth’s surface is essential, and we propose an effective way to achieve this goal. Notably, our change detection (CD)/ segmentation method proposes a novel way to incorporate the millions of off-the-shelf, unlabeled, remote sensing images available through different earth observation programs into the training process through denoising diffusion probabilistic models. We first leverage the information from these off-the-shelf, uncurated, and unlabeled remote sensing images by using a pre-trained denoising diffusion probabilistic model and then employ the multi-scale feature representations from the diffusion model decoder to train a lightweight CD classifier to detect precise changes. The experiments performed on four publically available CD datasets show that the proposed approach achieves remarkably better results than the state-of-the-art methods in F1, IoU, and overall accuracy. Code and pre-trained models are available at: https://github.com/wgcban/ddpm-cd
人类文明对地球系统的影响越来越大,而地球观测是评估和减轻负面影响的宝贵工具。为此,观察地球表面精确定义的变化是至关重要的,我们提出了一个有效的方法来实现这一目标。值得注意的是,我们的变化检测(CD)/分割方法提出了一种新的方法,通过去噪扩散概率模型,将数以百万计的现成的、未标记的、可通过不同地球观测项目获得的遥感图像纳入训练过程。我们首先通过使用预先训练好的去噪扩散概率模型来利用这些现成的、未经整理的和未标记的遥感图像的信息,然后采用来自扩散模型解码器的多尺度特征表示来训练一个轻量级的CD分类器来检测精确的变化。在四个公开的CD数据集上进行的实验表明,所提出的方法在F1、IoU和总体准确率方面取得了明显优于最先进方法的结果。代码和预训练的模型可在以下网站获得 https://github.com/wgcban/ddpm-cd


论文:Gender Classification and Bias Mitigation in Facial Images
论文标题:Gender Classification and Bias Mitigation in Facial Images
论文时间:13 Jul 2020
所属领域:计算机视觉
对应任务:Classification,General Classification,分类,通用分类
论文地址:https://arxiv.org/abs/2007.06141
代码实现:https://github.com/Developer-Y/cs-video-courses
论文作者:Wenying Wu, Pavlos Protopapas, Zheng Yang, Panagiotis Michalatos
论文简介:We worked to increase classification accuracy and mitigate algorithmic biases on our baseline model trained on the augmented benchmark database./我们努力提高分类精度,并减轻我们在增强的基准数据库上训练的基线模型的算法偏差。
论文摘要:Gender classification algorithms have important applications in many domains today such as demographic research, law enforcement, as well as human-computer interaction. Recent research showed that algorithms trained on biased benchmark databases could result in algorithmic bias. However, to date, little research has been carried out on gender classification algorithms’ bias towards gender minorities subgroups, such as the LGBTQ and the non-binary population, who have distinct characteristics in gender expression. In this paper, we began by conducting surveys on existing benchmark databases for facial recognition and gender classification tasks. We discovered that the current benchmark databases lack representation of gender minority subgroups. We worked on extending the current binary gender classifier to include a non-binary gender class. We did that by assembling two new facial image databases: 1) a racially balanced inclusive database with a subset of LGBTQ population 2) an inclusive-gender database that consists of people with non-binary gender. We worked to increase classification accuracy and mitigate algorithmic biases on our baseline model trained on the augmented benchmark database. Our ensemble model has achieved an overall accuracy score of 90.39%, which is a 38.72% increase from the baseline binary gender classifier trained on Adience. While this is an initial attempt towards mitigating bias in gender classification, more work is needed in modeling gender as a continuum by assembling more inclusive databases.
性别分类算法在当今许多领域都有重要的应用,如人口统计研究、执法以及人机交互。最近的研究表明,在有偏见的基准数据库上训练的算法可能导致算法的偏见。然而,到目前为止,关于性别分类算法对性别少数群体的偏见的研究还很少,比如LGBTQ和非二元人口,他们在性别表达上有明显的特征。在本文中,我们首先对现有的面部识别和性别分类任务的基准数据库进行了调查。我们发现,目前的基准数据库缺乏对性别少数群体的代表。我们致力于扩展当前的二元性别分类器,以包括非二元性别类。我们通过组装两个新的面部图像数据库来做到这一点。1)一个具有LGBTQ人口子集的种族平衡的包容性数据库 2)一个由非二元性别的人组成的包容性性别数据库。我们努力提高分类精度,并减轻在增强的基准数据库上训练的基线模型的算法偏差。我们的组合模型取得了90.39%的总体准确率,比在Adience上训练的基线二元性别分类器提高了38.72%。虽然这是减轻性别分类偏见的初步尝试,但在通过组建更具包容性的数据库将性别作为一个连续体进行建模方面还需要做更多的工作。



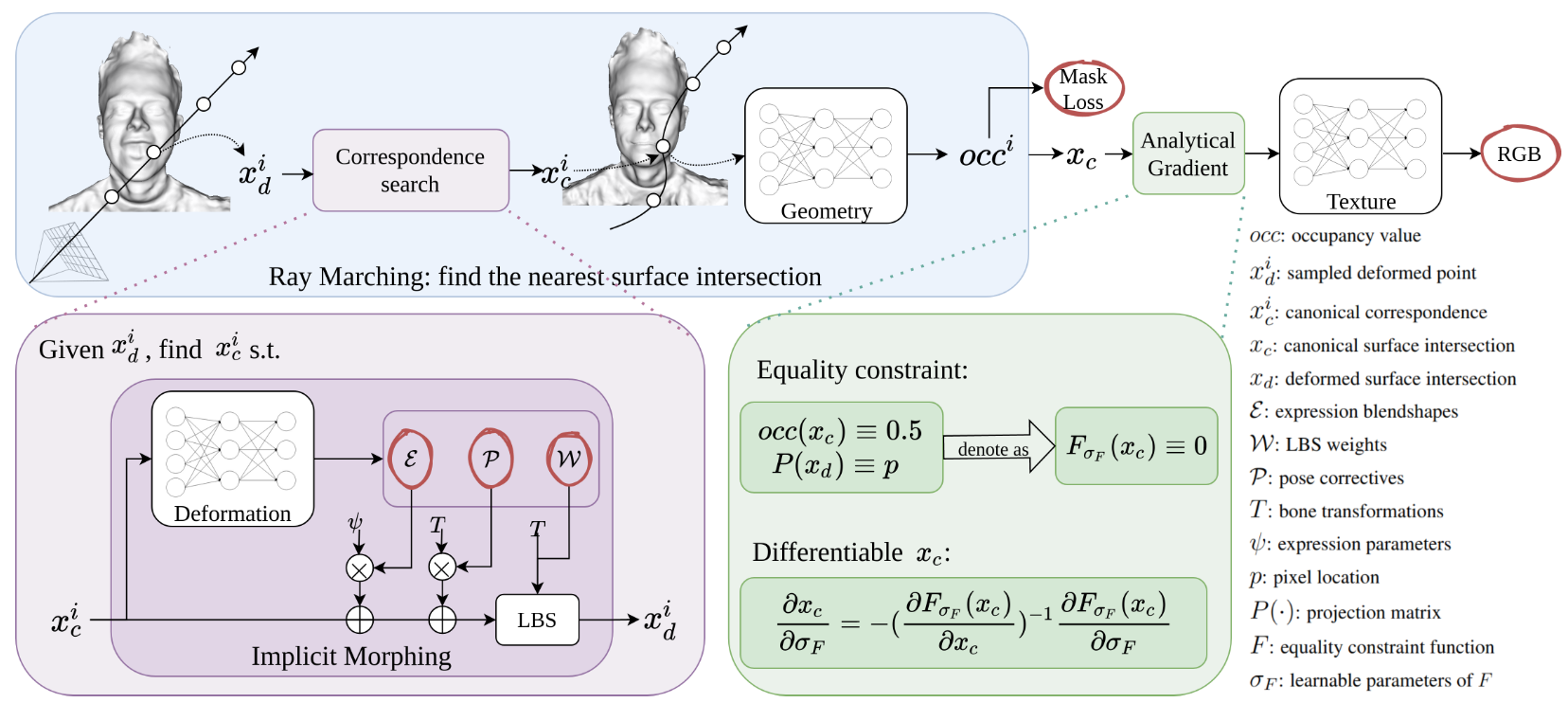
论文:I M Avatar: Implicit Morphable Head Avatars from Videos
论文标题:I M Avatar: Implicit Morphable Head Avatars from Videos
论文时间:CVPR 2022
所属领域:计算机视觉
论文地址:https://arxiv.org/abs/2112.07471
代码实现:https://github.com/zhengyuf/imavatar
论文作者:Yufeng Zheng, Victoria Fernández Abrevaya, Marcel C. Bühler, Xu Chen, Michael J. Black, Otmar Hilliges
论文简介:Traditional 3D morphable face models (3DMMs) provide fine-grained control over expression but cannot easily capture geometric and appearance details./传统的三维可变形脸部模型(3DMMs)提供了对表情的细粒度控制,但不能轻易捕捉几何和外观细节。
论文摘要:Traditional 3D morphable face models (3DMMs) provide fine-grained control over expression but cannot easily capture geometric and appearance details. Neural volumetric representations approach photorealism but are hard to animate and do not generalize well to unseen expressions. To tackle this problem, we propose IMavatar (Implicit Morphable avatar), a novel method for learning implicit head avatars from monocular videos. Inspired by the fine-grained control mechanisms afforded by conventional 3DMMs, we represent the expression- and pose- related deformations via learned blendshapes and skinning fields. These attributes are pose-independent and can be used to morph the canonical geometry and texture fields given novel expression and pose parameters. We employ ray marching and iterative root-finding to locate the canonical surface intersection for each pixel. A key contribution is our novel analytical gradient formulation that enables end-to-end training of IMavatars from videos. We show quantitatively and qualitatively that our method improves geometry and covers a more complete expression space compared to state-of-the-art methods.
传统的3D可变形脸部模型(3DMMs)提供了对表情的精细控制,但不能轻易捕捉几何和外观细节。神经体积表征接近逼真,但很难制作成动画,也不能很好地概括未见过的表情。为了解决这个问题,我们提出了IMavatar(Implicit Morphable avatar),一种从单眼视频中学习隐性头部头像的新方法。受传统3DMMs提供的细粒度控制机制的启发,我们通过学习的混合形状和皮肤场来表示表情和姿势相关的变形。这些属性是与姿势无关的,并可用于在给定新的表情和姿势参数的情况下对典型的几何和纹理场进行变形。我们采用射线行进法和迭代寻根法来定位每个像素的典型表面交点。我们的一个关键贡献是我们新颖的分析性梯度公式,能够从视频中进行端到端的IMavatars训练。我们从数量和质量上表明,与最先进的方法相比,我们的方法改善了几何学,并覆盖了更完整的表达空间。


论文:A Conversational Paradigm for Program Synthesis
论文标题:A Conversational Paradigm for Program Synthesis
论文时间:25 Mar 2022
所属领域:自然语言处理
对应任务:Language Modelling,Program Synthesis,语言模型,代码生成
论文地址:https://arxiv.org/abs/2203.13474
代码实现:https://github.com/salesforce/CodeGen
论文作者:Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong
论文简介:We train a family of large language models, called CodeGen, on natural language and programming language data./我们在自然语言和编程语言数据上训练一个大型语言模型系列,称为CodeGen。
论文摘要:Program synthesis strives to generate a computer program as a solution to a given problem specification. We propose a conversational program synthesis approach via large language models, which addresses the challenges of searching over a vast program space and user intent specification faced in prior approaches. Our new approach casts the process of writing a specification and program as a multi-turn conversation between a user and a system. It treats program synthesis as a sequence prediction problem, in which the specification is expressed in natural language and the desired program is conditionally sampled. We train a family of large language models, called CodeGen, on natural language and programming language data. With weak supervision in the data and the scaling up of data size and model size, conversational capacities emerge from the simple autoregressive language modeling. To study the model behavior on conversational program synthesis, we develop a multi-turn programming benchmark (MTPB), where solving each problem requires multi-step synthesis via multi-turn conversation between the user and the model. Our findings show the emergence of conversational capabilities and the effectiveness of the proposed conversational program synthesis paradigm. In addition, our model CodeGen (with up to 16B parameters trained on TPU-v4) outperforms OpenAI’s Codex on the HumanEval benchmark. We make the training library JaxFormer including checkpoints available as open source contribution: https://github.com/salesforce/CodeGen
代码生成旨在生成一个计算机程序作为给定问题规格的解决方案。我们提出了一种通过大型语言模型进行对话式程序合成的方法,该方法解决了之前的方法所面临的在巨大的程序空间和用户意图规范上进行搜索的挑战。我们的新方法将编写规范和程序的过程描述为用户和系统之间的多轮对话。它将代码生成视为一个序列预测问题,其中规范是用自然语言表达的,所需的程序是有条件采样的。我们在自然语言和编程语言数据上训练一个大型语言模型系列,称为CodeGen。随着数据中的弱监督以及数据规模和模型规模的扩大,对话能力从简单的自回归语言建模中出现。为了研究对话式程序合成的模型行为,我们开发了一个多轮编程基准(MTPB),其中解决每个问题需要通过用户和模型之间的多轮对话进行多步骤合成。我们的发现显示了对话能力的出现和所提出的对话式程序合成范式的有效性。此外,我们的模型CodeGen(在TPU-v4上训练了多达16B的参数)在HumanEval基准上超过了OpenAI的Codex。我们将包括检查点在内的训练库JaxFormer作为开放源码贡献 https://github.com/salesforce/CodeGen


论文:Elucidating the Design Space of Diffusion-Based Generative Models
论文标题:Elucidating the Design Space of Diffusion-Based Generative Models
论文时间:1 Jun 2022
所属领域:计算机视觉
对应任务:Image Generation,图像生成
论文地址:https://arxiv.org/abs/2206.00364
代码实现:https://github.com/crowsonkb/k-diffusion
论文作者:Tero Karras, Miika Aittala, Timo Aila, Samuli Laine
论文简介:We argue that the theory and practice of diffusion-based generative models are currently unnecessarily convoluted and seek to remedy the situation by presenting a design space that clearly separates the concrete design choices./我们认为,基于扩散的生成模型的理论和实践目前的错综复杂有一些是不必要的,并试图通过提出一个明确区分具体设计选择的设计空间来纠正这种情况。
论文摘要:We argue that the theory and practice of diffusion-based generative models are currently unnecessarily convoluted and seek to remedy the situation by presenting a design space that clearly separates the concrete design choices. This lets us identify several changes to both the sampling and training processes, as well as preconditioning of the score networks. Together, our improvements yield new state-of-the-art FID of 1.79 for CIFAR-10 in a class-conditional setting and 1.97 in an unconditional setting, with much faster sampling (35 network evaluations per image) than prior designs. To further demonstrate their modular nature, we show that our design changes dramatically improve both the efficiency and quality obtainable with pre-trained score networks from previous work, including improving the FID of an existing ImageNet-64 model from 2.07 to near-SOTA 1.55.
我们认为,基于扩散的生成模型的理论和实践目前的错综复杂有一些是不必要的,并试图通过提出一个明确区分具体设计选择的设计空间来纠正这种情况。这让我们确定了采样和训练过程的一些变化,以及得分网络的预处理。我们的改进一起产生了新的最先进的FID,CIFAR-10在类别条件设置中为1.79,在无条件设置中为1.97,采样速度比以前的设计快得多(每幅图像35次网络评估)。为了进一步证明它们的模块化性质,我们表明我们的设计变化极大地提高了以前工作中预训练的评分网络的效率和质量,包括将现有ImageNet-64模型的FID从2.07提高到接近SOTA的1.55。


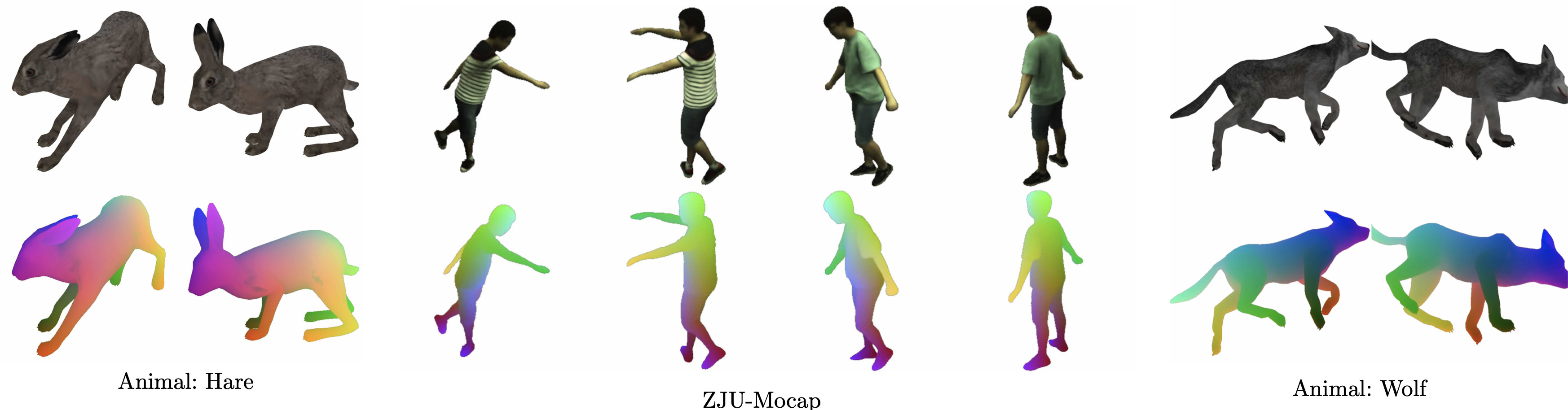
论文:TAVA: Template-free Animatable Volumetric Actors
论文标题:TAVA: Template-free Animatable Volumetric Actors
论文时间:17 Jun 2022
所属领域:计算机视觉
论文地址:https://arxiv.org/abs/2206.08929
代码实现:https://github.com/facebookresearch/tava
论文作者:RuiLong Li, Julian Tanke, Minh Vo, Michael Zollhofer, Jurgen Gall, Angjoo Kanazawa, Christoph Lassner
论文简介:Since TAVA does not require a body template, it is applicable to humans as well as other creatures such as animals./由于 TAVA 不需要身体模板,因此它适用于人类以及动物等其他生物。
论文摘要:Coordinate-based volumetric representations have the potential to generate photo-realistic virtual avatars from images. However, virtual avatars also need to be controllable even to a novel pose that may not have been observed. Traditional techniques, such as LBS, provide such a function; yet it usually requires a hand-designed body template, 3D scan data, and limited appearance models. On the other hand, neural representation has been shown to be powerful in representing visual details, but are under explored on deforming dynamic articulated actors. In this paper, we propose TAVA, a method to create T emplate-free Animatable Volumetric Actors, based on neural representations. We rely solely on multi-view data and a tracked skeleton to create a volumetric model of an actor, which can be animated at the test time given novel pose. Since TAVA does not require a body template, it is applicable to humans as well as other creatures such as animals. Furthermore, TAVA is designed such that it can recover accurate dense correspondences, making it amenable to content-creation and editing tasks. Through extensive experiments, we demonstrate that the proposed method generalizes well to novel poses as well as unseen views and showcase basic editing capabilities.
基于坐标的体积表示法有可能从图像中生成照片般真实的虚拟化身。然而,虚拟头像也需要可控,即使是一个可能没有被观察到的新姿势。传统的技术,如LBS,提供了这样的功能;但它通常需要手工设计的身体模板、3D扫描数据和有限的外观模型。另一方面,神经表征已被证明在代表视觉细节方面非常强大,但在动态铰接演员的变形方面还没有得到充分的探索。在本文中,我们提出了TAVA,一种基于神经表征的、创建无模板的可动画化体积演员的方法。我们仅仅依靠多视图数据和跟踪的骨架来创建演员的体积模型,该模型可以在给定新姿势的测试时间内被动画化。由于TAVA不需要身体模板,它适用于人类和其他生物,如动物。此外,TAVA的设计使其能够恢复准确的密集对应关系,使其适用于内容创建和编辑任务。通过广泛的实验,我们证明了所提出的方法能够很好地概括新的姿势以及未见过的视图,并展示了基本的编辑能力。


我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。

- 作者:韩信子@ShowMeAI
- 历史文章列表
- 专题合辑&电子月刊
- 声明:版权所有,转载请联系平台与作者并注明出处
- 欢迎回复,拜托点赞,留言推荐中有价值的文章、工具或建议,我们都会尽快回复哒~