前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
python开发环境
python 3.6
pycharm
requests
parsel
pdfkit
time
相关模块pip安装即可
目标网页分析
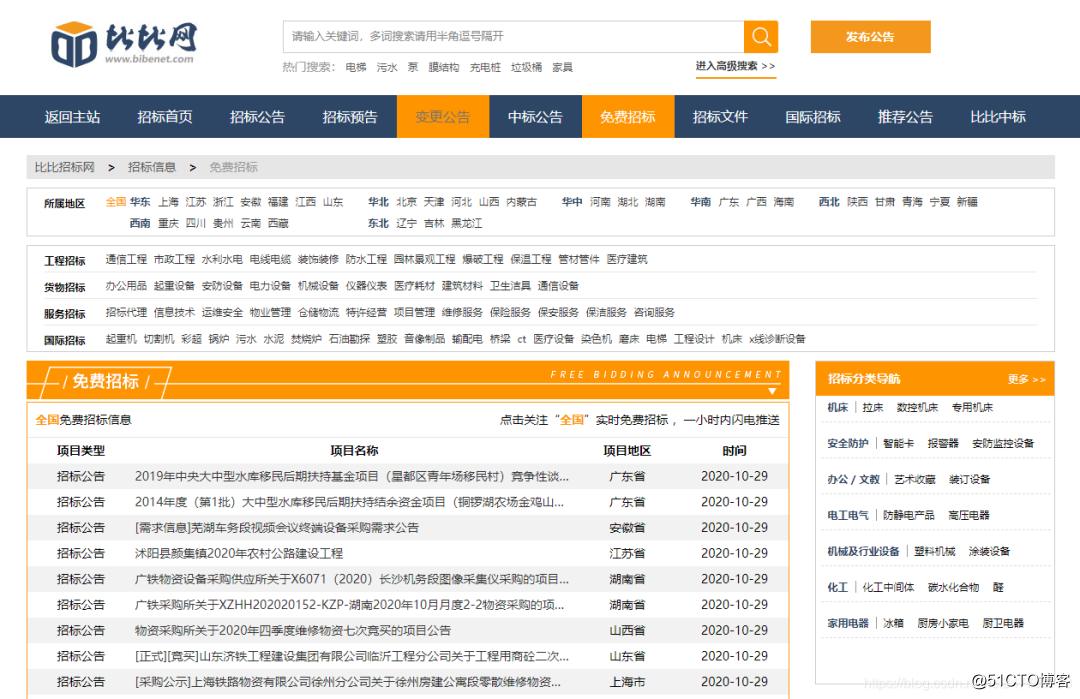
1、先从列表页中获取详情页的URL地址
是静态网站,可以直接请求网页获取数据
for page in range(1, 31):
url = 'https://www.bibenet.com/mfzbu{}.html'.format(page)
headers = {
'Referer': 'https://www.bibenet.com/mianfei/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.3