提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、原理、流程
- 二、制作预料库
- 三、制作问答功能
- 总结
如果有问题可以联系我**:https://gitee.com/xiaoyuren/gpt3
前言
在当今信息爆炸的时代,构建高效、个性化的知识服务成为了企业和组织的迫切需求。为满足这一需求,基于OpenAI ChatGPT和Embeddings的私有知识库聊天机器人正在崭露头角。
OpenAI ChatGPT是一种基于深度学习的自然语言处理模型,通过对大量文本数据进行训练,能够理解和生成人类语言。而Embeddings则是将文本数据映射到低维向量空间的技术,捕捉了文本之间的语义和语法关系。
结合这两者的优势,私有知识库聊天机器人能够像人类专家一样回答用户的问题,并提供准确、针对性的信息。它将私有知识库的内容与ChatGPT模型和Embeddings技术相结合,为用户提供个性化、实时的知识服务。
本文将深入探讨基于OpenAI ChatGPT和Embeddings的私有知识库聊天机器人的制作方法。我们将探讨如何建立私有知识库,集成ChatGPT模型,并借助Embeddings技术提升聊天机器人的准确性和效率。私有知识库聊天机器人在客户服务、技术支持和在线教育等领域具有广泛应用前景。
让我们一起探索这一引人注目的技术,揭示私有知识库聊天机器人在知识服务领域的潜力和可能性。
一、原理、流程
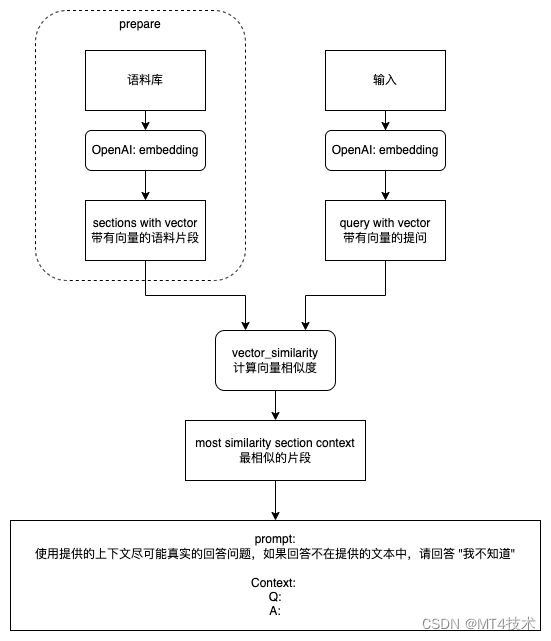
上面的图可以清晰得看到其中得流程:
我们首先要准备自己的语料库,如果你是制作像chatpdf、chatdoc这种程序 需要先读取其中的内容,然后把内容转为向量数据。当用户输入问题时,也需要把用户问题转为向量数据,拿用户的向量问题去我们语料库的向量数据查找,计算问题和语料库中内容的相似度,最高相似度的内容就是我们需要的答案。
为了让回答更智能让方便我们阅读,我们还需要让chatgpt配合。我们需要把上面计算的几条最符合的答案交给chatgpt,让chatgpt通过我们给他的内容回答我们。
这就是我们本篇的原理和流程。下面看下具体如何实现。
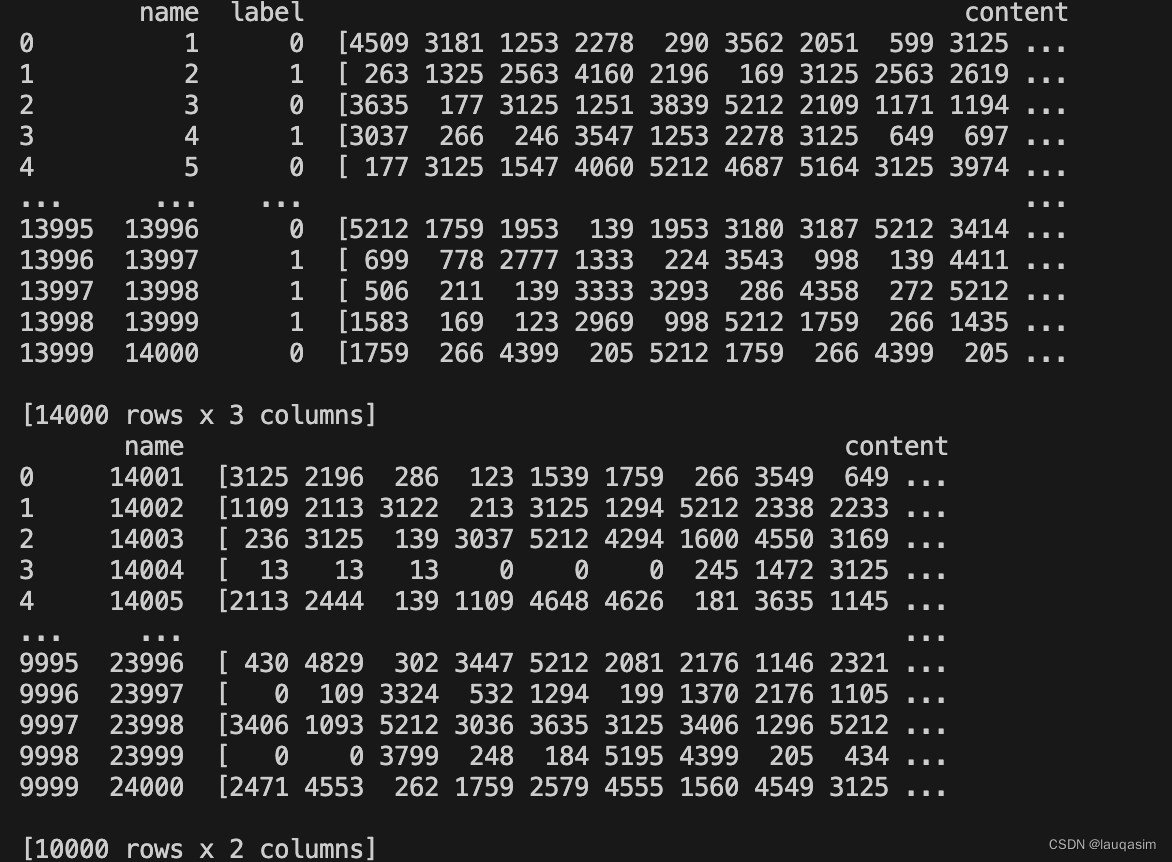
二、制作预料库
我们首先需要把我们语料库分句,让语料库是一段一段的而不是一整篇文章,可以用标点作为分隔符。例如句号、感叹号、分号、省略号等,注意:中英文的符号不一样,如果是英文的内容需要按照英文的符合去分割。
if any('\u4e00' <= char <= '\u9fff' for char in book_text):print("中文")pattern = r'(?:\.|\!|\?|。|!|?|;|;|\.{6})'# 使用正则表达式进行分句cn_sentences = re.split(pattern, book_text)# 去除空字符串和空格cn_sentences = [s.strip() for s in cn_sentences if s.strip()]print('中书籍分句结果:', cn_sentences)ln_sentences=cn_sentences
else:print("英文")en_sentences = sent_tokenize(book_text)ln_sentences = en_sentencesprint('英文书籍分句结果:', en_sentences)为了方便后续的处理我们需要把数据在处理一下:、
如果有问题可以联系我**:https://gitee.com/xiaoyuren/gpt3
def split_token(sentences, min_tokens=min_tokens, max_tokens=max_tokens):# Split the text into sentences# Get the number of tokens for each sentencen_tokens = [len(tokenizer.encode(" " + sentence)) for sentence in sentences]chunks = []tokens_so_far = 0chunk = []for sentence, token in zip(sentences, n_tokens):if token<=1:continueprint(sentence)print(token)# Check if adding this sentence would exceed the token limitif tokens_so_far + token > min_tokens:# If so, add the current chunk to the list of chunks and start a new chunkchunk.append(sentence)chunks.append(" ".join(chunk))chunk = []tokens_so_far = 0continue# Add the current sentence to the current chunkchunk.append(sentence)tokens_so_far += tokenif len(chunk)>1:chunks.append(" ".join(chunk))print("1-----------------------------")# 用于存放分割后的字符串的临时列表temp_list = []# 遍历原列表中的元素for item in chunks:# 使用tokenizer计算当前字符串的token数目tokens = tokenizer.encode(item)# 如果当前字符串的token数目不超过20,则直接将其添加到临时列表中if len(tokens) <= max_tokens:temp_list.append(item)else:# 否则,将当前字符串切分成若干个token数目不超过20的子串for sub_item in tokenize_string(item, min_tokens):temp_list.append(sub_item)# 将临时列表中的元素赋值给原列表my_list = temp_listreturn my_listdf = pd.DataFrame(ln_sentences, columns=['text'])
#移除换行 空格
df['text'] = remove_newlines(df.text)r=split_token(df['text'])
print(r)
df = pd.DataFrame(r, columns = ['text'])
df['n_tokens'] = df.text.apply(lambda x: len(tokenizer.encode(x)))
df.n_tokens.hist()
print(df)
其中关键在于split_token:此方法可让计算每句话的token长度,不足min_tokens的可以用下一句补充,大于max_tokens的给截断,这样就保证每段话都是我们要的范围长度的内容。
最后也就是最关键的就是把数据量化处理了:
df['embeddings'] = df.text.apply(lambda text: openai.Embedding.create(input=text, engine='text-embedding-ada-002')['data'][0]['embedding'])df.to_csv('processed/embeddings.csv')
df.head()
上面代码如果因速率限制返回错误:可以使用df.text.apply(get_embedding_with_delay)去增加延迟。
至此语料的向量化已经完成了。
三、制作问答功能
看下如何把用户问题量化 并且在语料中查找:
def create_context(question, df, max_len=1800):print("\n\n")print("questionSTART:\n" + question)print("\n\n")print("questionEND:\n")"""Create a context for a question by finding the most similar context from the dataframe"""# Get the embeddings for the questionq_embeddings = openai.Embedding.create(input=question, engine='text-embedding-ada-002')['data'][0]['embedding']# Get the distances from the embeddingsdf['distances'] = distances_from_embeddings(q_embeddings, df['embeddings'].values, distance_metric='cosine')returns = []cur_len = 0# Sort by distance and add the text to the context until the context is too longfor i, row in df.sort_values('distances', ascending=True).iterrows():# Add the length of the text to the current lengthcur_len += row['n_tokens'] + 4# If the context is too long, breakif cur_len > max_len:break# Else add it to the text that is being returnedreturns.append(row["text"])# Return the contextreturn "\n\n###\n\n".join(returns)上面方法返回的内容就是我们的问题在语料库中查找的结果最接近的内容
然后把上面返回的内容交给chatgpt处理:
response = openai.ChatCompletion.create(model="gpt-3.5-turbo",temperature=0,max_tokens=max_tokens,top_p=1,frequency_penalty=0,presence_penalty=0,stop=stop_sequence,messages=[{"role": "system", "content": "你现在充当一个人工智能客服,你的回答要表现的像一个人工客服。如果问你是不是人工客服,回答是人工客服。回答完毕在后面加上:亲~ 。 不要在回答中带有根据XXX"},{"role": "user", "content": f"Answer the question based on the context below with Chinese, and if the question can't be answered based on the context, say \"亲~ 我这边只负责产品相关咨询,其他问题我可以帮你转接一下相关客服\"\n\nContext: {context}\n\n---\n\nQuestion: {question}\nAnswer:"},])result = ''for choice in response.choices:result += choice.message.contentreturn result
上面的system和user内容可根据自己情况自定义。context是上面返回的内容,question是用户提问的内容。通过以上代码我们就实现了基于自己知识库的聊天机器人
总结
本篇讲述了基于openai chatgpt和embeddings制作私有知识库聊天机器人的原理和流程和代码实现。如果你对上面的内容有什么不明白的或者疑问可以私信或者下方联系我。
如果有问题可以联系我**:https://gitee.com/xiaoyuren/gpt3