Intorduction:
跑深度学习需要用到GPU,而CUDA就是GPU和程序(如python)之间的桥梁。CUDA的环境依赖错综复杂,环境配置成为深度学习初学者的拦路虎。
同时网上教程大多为解决某个具体环境配置报错,或者分别讲解CUDA、CUDA toolkit(CUDA工具包)、CUDNN、NVCC等概念,并没有从计算机体系结构的角度将其层次化。故做此文,旨在帮助深度学习入门者从宏观上建立一个CUDA体系,而不是仅仅停留在报错才去了解的摸黑阶段。
本文尽可能采用自顶向下的金字塔式讲解,使得文章抓住主干,逻辑层次清晰。
概念介绍
先介绍CUDA是什么:
官方定义:CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。 开发人员可以使用C语言来为CUDA™架构编写程序,所编写出的程序可以在支持CUDA™的处理器上以超高性能运行。
https://baike.baidu.com/item/CUDA/1186262?fr=aladdin
通俗解释:CUDA就是让python等程序语言可以同时在CPU和GPU上跑的一个平台。
首先通过图来感受CUDA在体系结构中所在的层次。
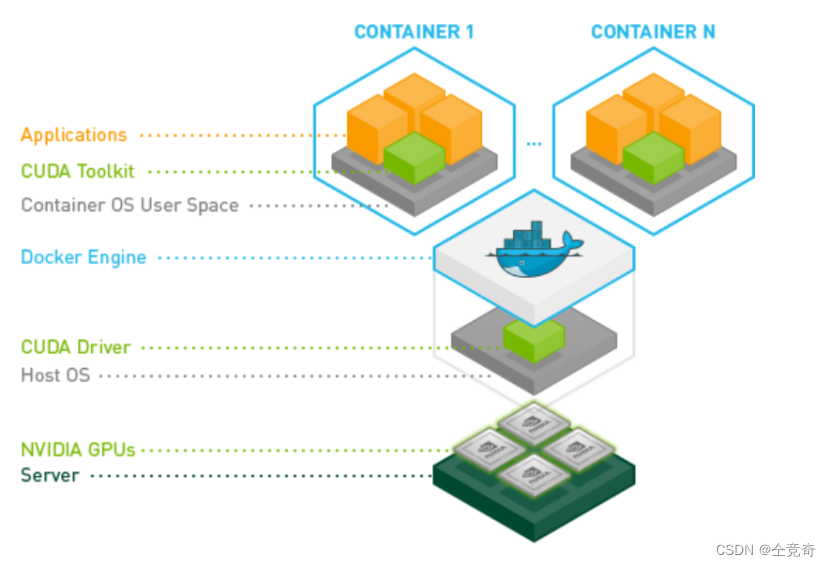 图一
图一
https://github.com/NVIDIA/nvidia-container-toolkit
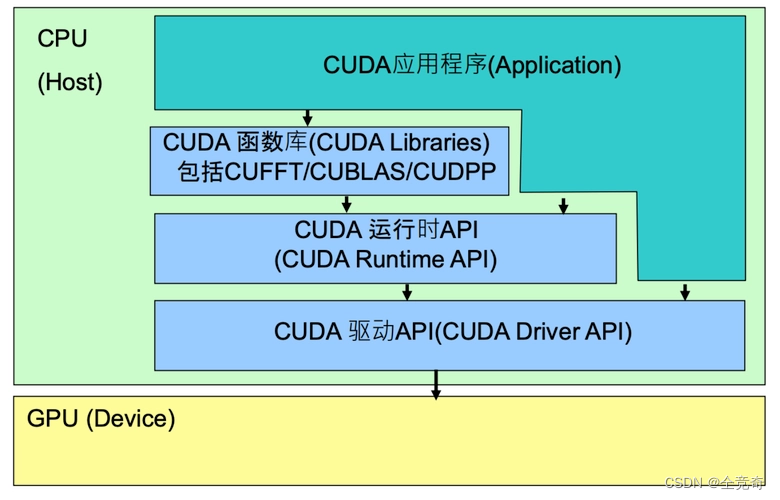
我们可以清晰看到,绿色部分的CUDA,就是起了承上启下的作用。CUDA就是由CUDA驱动和CUDA工具包组成。
CUDA Toolkit在容器内部,而CUDA Driver在操作系统层。
CUDA Toolkit (nvidia): CUDA完整的工具安装包,其中提供了 Nvidia 驱动程序、开发 CUDA 程序相关的开发工具包等可供安装的选项。包括 CUDA 程序的编译器、IDE、调试器等,CUDA 程序所对应的各式库文件以及它们的头文件。
注意:这里的CUDA Toolkit指的是CUDA官网下载的完整版,不是指Pytorch附带下载的CUDA不完整版,后文有详细说明。
CUDA Driver: 运行CUDA应用程序需要系统至少有一个具有CUDA功能的GPU和与CUDA工具包兼容的驱动程序。每个版本的CUDA工具包都对应一个最低版本的CUDA Driver,也就是说如果你安装的CUDA Driver版本比官方推荐的还低,那么很可能会无法正常运行。CUDA Driver是向后兼容的,这意味着根据CUDA的特定版本编译的应用程序将继续在后续发布的Driver上也能继续工作。通常为了方便,在安装CUDA Toolkit的时候会默认安装CUDA Driver。在开发阶段可以选择默认安装Driver,但是对于像Tesla GPU这样的商用情况时,建议在官方安装最新版本的Driver。
原文链接:https://blog.csdn.net/zjy1175044232/article/details/120887377
我们单独拿出CUDA的结构:
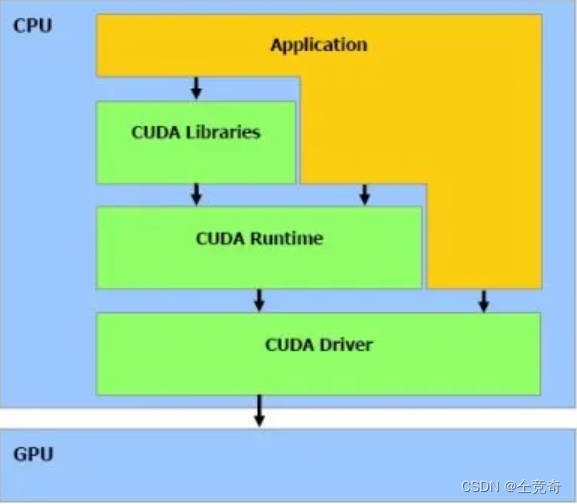 图二
图二
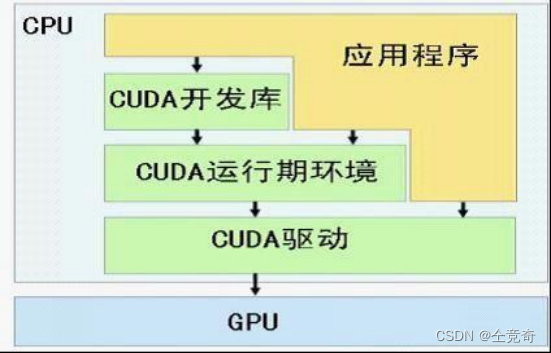 图三
图三
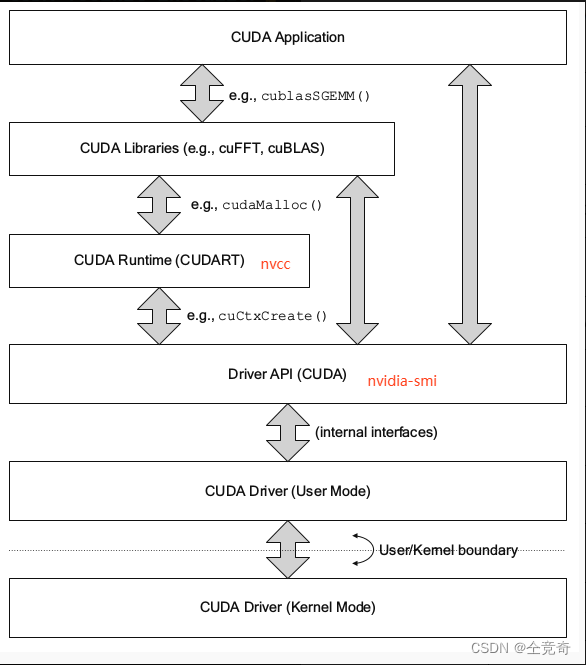
图二图三将CUDA划分成三部分结构,最底层依然是CUDA Driver,而驱动之上的是CUDA Runtime和CUDA Libraries,则我们结合图一可以推断出,CUDA toolkit由CUDA Runtime和CUDA Libraries组成。
图二和图三还说明程序可以直接调用CUDA开发库、CUDA runtime ,CUDA驱动三部分。图四就是表达应用程序通过调用API来进行GPU上的计算。
 https://cloud.tencent.com/developer/article/1496697
https://cloud.tencent.com/developer/article/1496697
 https://www.cnblogs.com/marsggbo/p/11838823.html
https://www.cnblogs.com/marsggbo/p/11838823.html
NVCC:NVCC是CUDA的编译器,属于runtime层,当然也属于CUDA toolkit。
cuDNN:cuDNN的全称为NVIDIA CUDA® Deep Neural Network library,是NVIDIA专门针对深度神经网络中的基础操作而设计基于GPU的加速库。cuDNN为深度神经网络中的标准流程提供了高度优化的实现方式,例如convolution、pooling、normalization以及activation layers的前向以及后向过程。
CUDA这个平台一开始并没有安装cuDNN库,当开发者们需要用到深度学习GPU加速时才安装cuDNN库,工作速度相较CPU快很多。
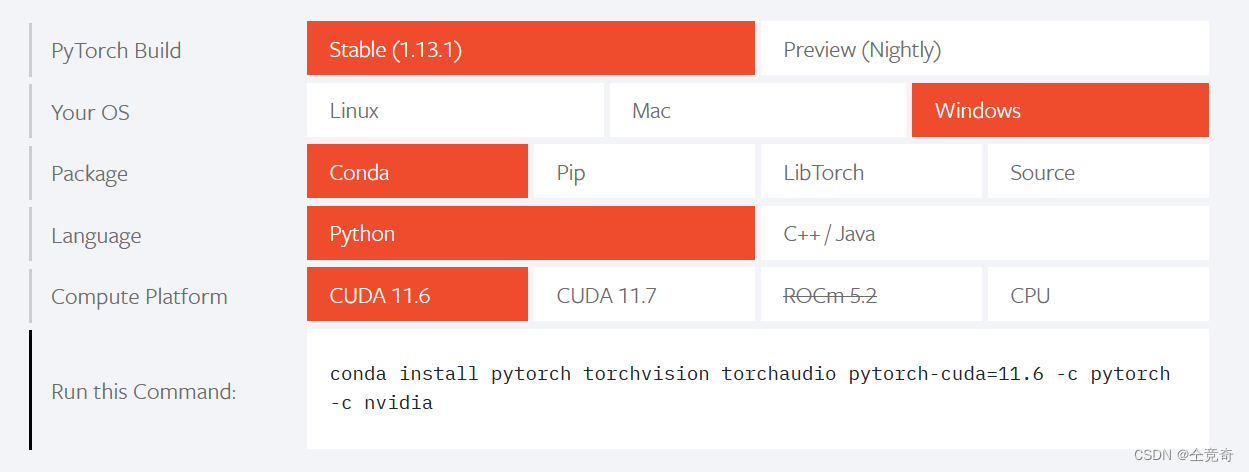 安装pytorch时会选择Compute platfrom,这里的如果选择CUDA系列,会安装cuDNN和不完整的CUDA Toolkit。
安装pytorch时会选择Compute platfrom,这里的如果选择CUDA系列,会安装cuDNN和不完整的CUDA Toolkit。
CUDA Toolkit (nvidia): CUDA完整的工具安装包,其中提供了 Nvidia 驱动程序、开发 CUDA 程序相关的开发工具包等可供安装的选项。包括 CUDA 程序的编译器、IDE、调试器等,CUDA 程序所对应的各式库文件以及它们的头文件。
CUDA Toolkit (Pytorch): CUDA不完整的工具安装包,其主要包含在使用 CUDA 相关的功能时所依赖的动态链接库。不会安装驱动程序,也不会安装编译工具(nvcc)。
(NVCC 是CUDA的编译器,只是 CUDA Toolkit 中的一部分)
注:CUDA Toolkit 完整和不完整的区别:在安装了CUDA Toolkit (Pytorch)后,只要系统上存在与当前的 cudatoolkit 所兼容的 Nvidia 驱动,则已经编译好的 CUDA 相关的程序就可以直接运行,不需要重新进行编译过程。如需要为 Pytorch 框架添加 CUDA 相关的拓展时(Custom C++ and CUDA Extensions),需要对编写的 CUDA 相关的程序进行编译等操作,则需安装完整的 Nvidia 官方提供的 CUDA Toolkit。
https://zhuanlan.zhihu.com/p/542319274
也就是说,pytorch带的CUDA不会安装runtime层和以下的层,包括nvcc和CUDA driver。
 https://developer.nvidia.com/zh-cn/blog/gpu-containers-runtime/
https://developer.nvidia.com/zh-cn/blog/gpu-containers-runtime/
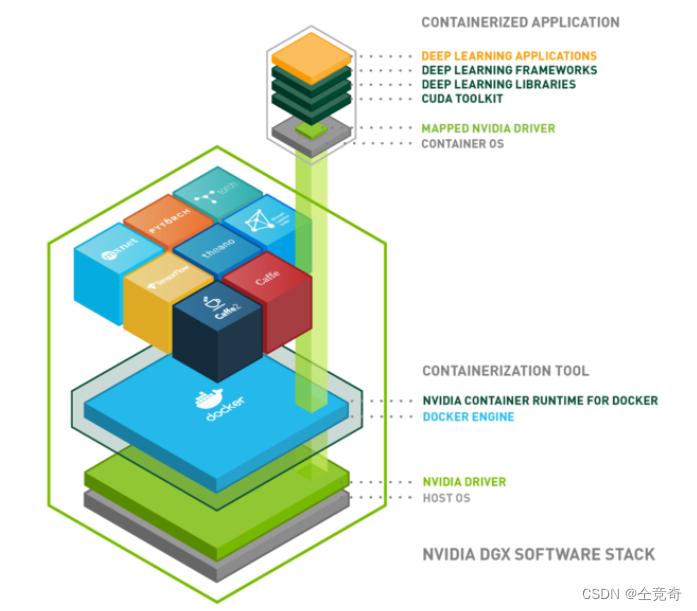
这个图是在容器内部搭建操作系统,创造一个从CUDA Driver到应用程序都完全独立的容器。说明我们可以唉不同的层次进行容器的封装,可以从runtime以上封装容器(通常虚拟环境是runtime以上的),也可以直接从操作系统开始封装。
在这里区分一下Docker和虚拟环境的区别:
虚拟环境只是隔离了Python程序的依赖项,即在一个虚拟环境中,包含了特定版本的Python解释器和Python库,当激活该虚拟环境时,会屏蔽掉虚拟环境以外Python解释器和Python库。
而docker可以隔离整个系统,更接近虚拟机。同时docker可以有不同层次的封装。
https://www.saoniuhuo.com/question/detail-2432744.html
虚拟环境的隔离类似于图1,多个虚拟环境共用CUDA Driver,也可以共用CUDA runtime。因此在一个虚拟环境中安装附带CUDA的pytorch时,不会安装CUDA runtime以及CUDA驱动,只会安装已经编译好的CUDA函数库。因此如果缺少CUDA runtime(缺少nvcc),Pytorch依然可能可以正常在GPU上运行,在有CUDA驱动的前提下。
但是如果有python setup.py build develop等需要nvcc的命令,则必须保证有和CUDA函数库相同版本的CUDA runtime(包括nvcc),否则会报错。之后的版本兼容性会进一步说明。
版本兼容性问题:
首先是CUDA版本要和GPU算力相匹配,如A100的算力是8.0,需要CUDA版本大于11.0
查看GPU与算力对应:https://en.wikipedia.org/wiki/CUDA
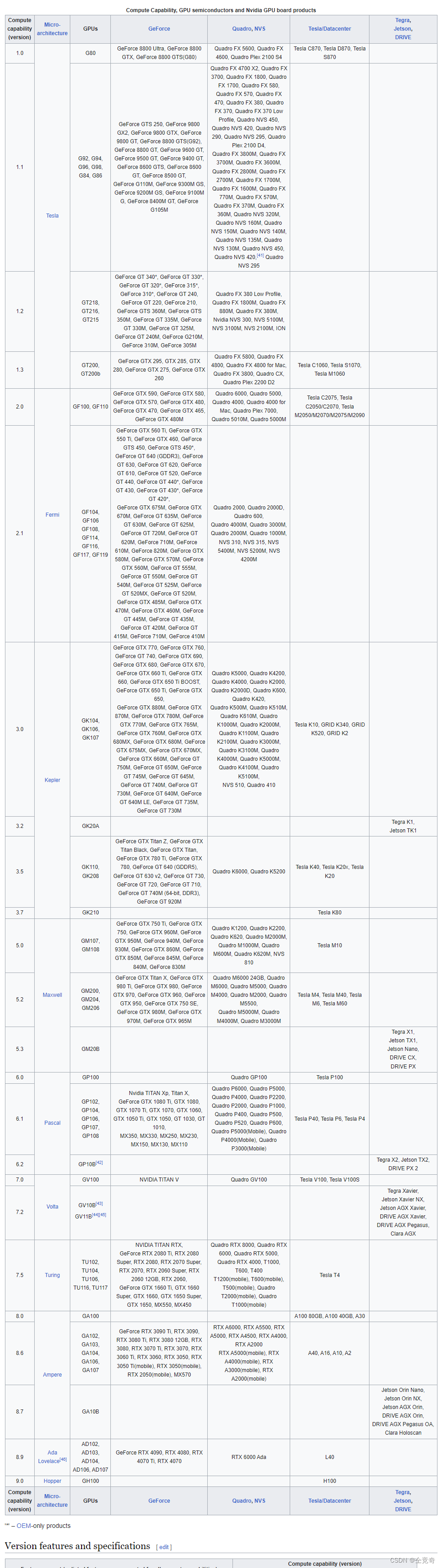
查看算力对应的CUDA版本:原链接未找到,但是bilibiliup主"我是土堆"在视频中提到过,图片如下:
 之后是CUDA driver版本和CUDA runtime版本的对应关系:
之后是CUDA driver版本和CUDA runtime版本的对应关系:
CUDA driver版本需要大于等于CUDA runtime版本
CUDA driver版本通过nvidia-smi命令查看:
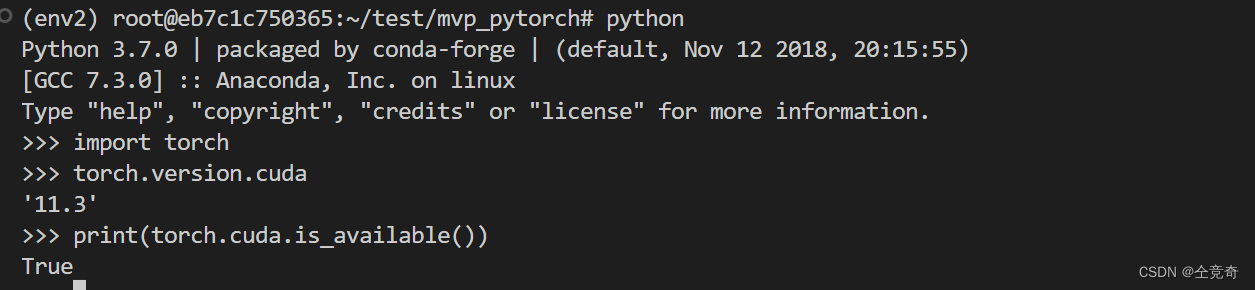
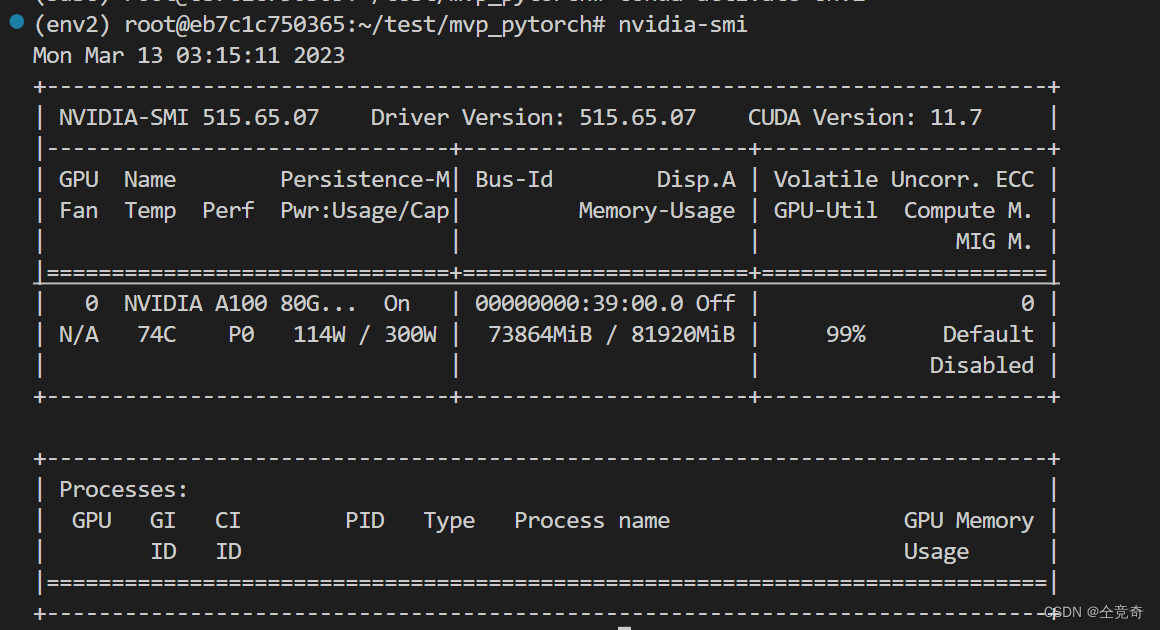 可以看到,我的CUDA Driver版本是11.7
可以看到,我的CUDA Driver版本是11.7
CUDA runtime版本通过 nvcc --version查看,如果报错,可能是因为没有下载CUDA runtime,也有可能是没有将CUDA rumtime添加到环境依赖中。报错的具体解决方案在此不再赘述,直接问百度或者谷歌或者chatGPT报错信息即可。

可以看到我的nvcc版本是11.4,即runtime版本是11.4<=11.7的CUDA Driver版本,因此适配。
之后是CUDA runtime版本需要和CUDA Libraries版本适配。
CUDA Libraries如果是如果pytorch附带下载的CUDA toolkit(不完整版),需要选择小于等于nvcc --version的版本下载。我的nvcc是11.4,因此我需要下载小于等于11.4版本的CUDA toolkit(不完整版)。可以看到官网页面只有11.6和11.7的版本,因此需要找历史版本:https://pytorch.org/get-started/previous-versions/
 找到了pytorch附带小于等于11.4的CUDA toolkit(不完整版)
找到了pytorch附带小于等于11.4的CUDA toolkit(不完整版)
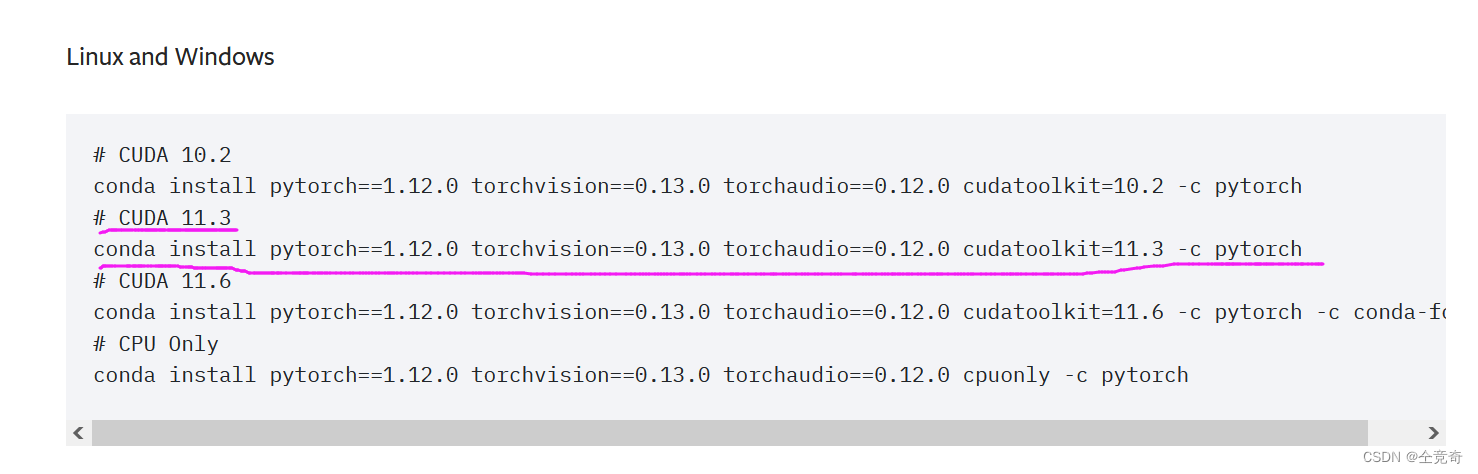
再次说明:Pytorch 接口输出的 cuda 的版本并不一定是 Pytorch 在实际系统上运行时使用的 cuda 版本,而是编译该 Pytorch release 版本时使用的 cuda 版本。也就是说,我pytorch下载的CUDA是已经编译好的版本,编译时使用的是11.3的nvcc
注意:之前查阅资料时,并没有博客提出需要让pytorch 附带的CUDA toolkit(不完整版)小于等于CUDA runtime版本。但是在我复现论文时,在使用pytorch1.13.0 pytorch-cuda=11.7时遇到了RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)的错误,通过降低Pytorch和CUDA toolkit(不完整版)的版本,即conda install pytorch1.12.1 torchvision0.13.1 torchaudio0.12.1 cudatoolkit=11.3 -c pytorch,解决了这个问题。
我复现的论文因为有python setup.py build develop命令,因此需要使用nvcc编译,如果nvcc版本小于CUDA toolkit(不完整版),则很可能出错。因此我推测是因为pytorch附带的CUDA toolkit版本过高导致。
(挖个坑:之后可以通过控制变量法实验进一步验证该结论,具体方式是安装pytorch==1.12.1和cuda11.6的版本,若报相同错误则说明确实是CUDA的问题而非pytorch的问题。)
遇到相同问题的博客:
https://blog.csdn.net/Chemist_Dong/article/details/128012131
最终是cuDNN要和CUDA libraries版本要适配,pytorch等框架的版本也要和cuDNN版本适配,应用程序要和pytorch框架适配。
这三个适配具体实现方法很简单,对与pytorch来说,在官网下载CUDA版本的pytorch,会自动下载适配的cuDNN,CUDA libraries以及适配的Pytorch。
旧版本的pytorch程序通常能够在新版本的pytorch框架内正常运行(当然python2不能在python3环境中运行)。
最后再回过头看该图,会清晰很多。总结兼容性问题:高版本底层通常兼容低版本的上层,反之通常不行。在某博客上看到一个解释:上层可能加入一个新的功能,如果底层没有对应的实现则报错。但是底层通常会保证之前的软件可以移植过来。
因此底层通常向后兼容(backward)。因为中文的前后有歧义,所以我喜欢翻译成向过去兼容。
确定了GPU的型号就确定了算力,高算力需要匹配高版本CUDA。
CUDA Driver版本(nvidia-smi命令查看)需要大于等于CUDA runtime版本(nvcc --version命令查看)
CUDA runtime版本需要大于等于CUDA libraries版本(Pytorch附带下载的CUDA toolkit版本)
因此从头配置完整的深度学习CUDA环境的操作为:
1.保证系统至少存在一块GPU
2.在虚拟环境中查看nvidia-smi和nvcc --version,若nvcc --version小于nvidia-smi,则适配。
2.若确认不存在nvcc和CUDA驱动,官网安装CUDA Driver和完整版的CUDA toolkit(部分博客说安装CUDA toolkit时会同时安装CUDA Driver,未验证)
3.创建虚拟环境,具体流程请自行百度。
5.下载CUDA版本小于等于nvcc --version的pytorch及其附带的CUDA toolkit(不完整版)
大部分深度学习并不需要完整的CUDA toolkit 因此简化版的操作为:
1.保证系统存在至少一块GPU
2.查看nvidia-smi,确认有驱动
3.若无驱动需要官网安装
4.创建虚拟环境
5.安装附带CUDA toolkit(不完整版)pytorch
如果没有GPU,或者想要快速跑通简单的深度学习程序,可以用CPU版本的pytorch,则不需要安装驱动。直接在用conda创建虚拟环境然后安装pytorch即可。







![[科研神器]如何让ChatPDF帮你日读文献300篇](https://img-blog.csdnimg.cn/66e83634e6ed40cb8dd7df2cdd5dd77f.png)