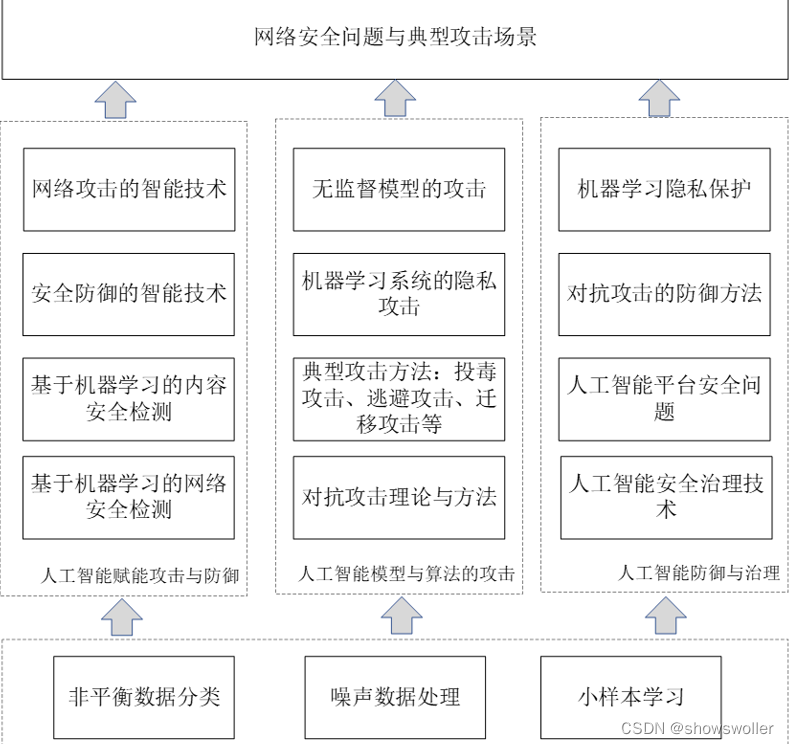
1.分类
 2.研究方向
2.研究方向
说话人识别研究方向主要有三个:
语音信号参数化:即提取音频特征spectral features,目前主流研究都采用MFCCs系数,以及其Δ和ΔΔ系数(即时间上的一阶导数和二阶导数)。什么是MFCC系数以及如何提取可以看这个博客:语音特征提取: 看懂梅尔语谱图(Mel-spectrogram)、梅尔倒频系数(MFCCs)的原理
模式匹配: 即从上一步得到的语音参数中提取出该说话人的固有特征,通俗点讲,就是从输入数据中提取出一个固定长度的向量来表示该speaker的特征,又称speaker embedding。所谓embedding可以理解为在一个固定维度下的表达形式。
算分方法: 即在进行识别的时候,将待测speaker的embedding和训练阶段得到的embedding进行比较,算分方法以一个特定公式去计算两者的相似度,从而达到识别的效果。

3. 模式识别的发展历史
可以分为三类:
模板匹配、概率模型和神经网络。
Vector Quantization 的介绍可以看这个博客:说话人识别 speaker identification发展历史
1980s主流方法即为向量量化(K-means)或NN。效果不好,因为算法简单。
1990s神经网络面世,TDNN即为CNN的前身。但此时还没有深度学习的概念。
2010s以概率模型为代表的i-vector取得了良好的效果,但是最近几年被由深度神经网络发展而来的x-vector超越。

3.1 GMM高斯混合模型
将不同参数的高斯分布以合计概率为1进行叠加,得到的分布可以模拟非常复杂的分布。该模型利用GMM的参数来表示每个speaker的模式。但问题是想要效果比较好,则需要非常多数量的高斯分布进行混合,随之而来的参数计算也会很多,但是一个speaker的数据往往比较少,例如短短一句话得到的feature是非常少的,完全不足以训练GMM。所以,后来提出了一个GMM-UBM的方法,所谓UBM通用背景模型是一个提前训练好的模型,该模型 本身是一个很复杂的GMM,但是他用了大量不同speaker的数据进行训练,得到的是一个可以表达很多人的GMM。利用UBM和我们想要训练的speaker数据,将UBM的参数向当前speaker靠拢。
GMM的模型如下,了解EM算法的人应该很熟悉:

用大量无关的、我们已有的数据,利用EM算法训练UBM,再利用MAP和当前speaker的数据进行调整参数。

M表示当前speaker的分布,m表示UBM的分布,z表示标准正态分布,矩阵D来调整m。