1.线程的基本概念
2.线程和进程的区别
线程安全
*线程的同步
线程的调度
线程的通信编程思想之多线程与多进程(1)——以操作系统的角度述说线程与进程_阳光日志-CSDN博客_多线程和多进程编程线程是什么?要理解这个概念,须要先了解一下操作系统的一些相关概念。大部分操作系统(如Windows、Linux)的任务调度是采用时间片轮转的抢占式调度方式,也就是说一个任务执行一小段时间后强制暂停去执行下一个任务,每个任务轮流执行。任务执行的一小段时间叫做时间片,任务正在执行时的状态叫运行状态,任务执行一段时间后强制暂停去执行下一个任务,被暂停的任务就处于就绪状态等待下一个属于它的时间片的到来。这样每个任务都能得到执行,由于CPU的执行效率非常高,时间片非常短,在各个任务之间快速地切换,给人的感觉就是多个任https://sunlogging.blog.csdn.net/article/details/46595285
进程和线程之间有什么根本性的区别? - 知乎我画了 30 多张图,万字长文,一起来深入理解进程和线程!进程我们编写的代码只是一个存储在硬盘的静态文…![]() https://www.zhihu.com/question/44087187/answer/2062919643
https://www.zhihu.com/question/44087187/answer/2062919643
学习线程前需要知道的知识——并行和并发的区别
1. 并发(concurrency):在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行。其中两种并发关系分别是同步和互斥。(并发是指同一时刻只能有一条指令执行,但多个进程指令被快速轮换执行,使得在宏观上有多个进程被同时执行的效果--宏观上并行,针对单核处理器)
互斥:进程间相互排斥的使用临界资源的现象,就叫互斥。
同步(synchronous):进程之间的关系不是相互排斥临界资源的关系,而是相互依赖的关系。进一步的说明:就是前一个进程的输出作为后一个进程的输入,当第一个进程没有输出时第二个进程必须等待。具有同步关系的一组并发进程相互发送的信息称为消息或事件。(彼此有依赖关系的调用不应该同时发生,而同步就是阻止那些“同时发生”的事情)
其中并发又有伪并发和真并发,伪并发是指单核处理器的并发,真并发是指多核处理器的并发。
2.并行(parallelism):在单处理器中多道程序设计系统中,进程被交替执行,表现出一种并发的外部特种;在多处理器系统中,进程不仅可以交替执行,而且可以重叠执行。在多处理器上的程序才可实现并行处理。从而可知,并行是针对多处理器而言的。并行是同时发生的多个并发事件,具有并发的含义,但并发不一定并行,也亦是说并发事件之间不一定要同一时刻发生。(同一时刻,有多条指令在多个处理器上同时执行--针对多核处理器)
一、线程简介
1.为什么使用线程?
我们举个例子,假设你要编写一个视频播放器软件,那么该软件功能的核心模块有三个:
- 从视频文件当中读取数据;
- 对读取的数据进行解压缩;
- 把解压缩后的视频数据播放出来;
对于单进程的实现方式,我想大家都会是以下这个方式:
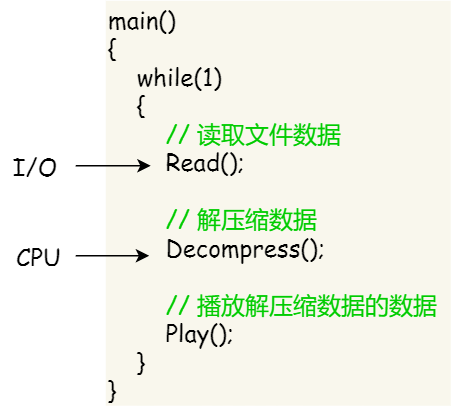
对于单进程的这种方式,存在以下问题:
- 播放出来的画面和声音会不连贯,因为当 CPU 能力不够强的时候,
Read的时候可能进程就等在这了,这样就会导致等半天才进行数据解压和播放; - 各个函数之间不是并发执行,影响资源的使用效率;
那改进成多进程的方式:

对于多进程的这种方式,依然会存在问题:
- 进程之间如何通信,共享数据?
- 维护进程的系统开销较大,如创建进程时,分配资源、建立 PCB;终止进程时,回收资源、撤销 PCB;进程切换时,保存当前进程的状态信息;
那到底如何解决呢?需要有一种新的实体,满足以下特性:
- 实体之间可以并发运行;
- 实体之间共享相同的地址空间;
这个新的实体,就是线程( Thread ),线程之间可以并发运行且共享相同的地址空间。
2.线程的实现
线程是操作系统能够调度和执行的基本单位,在Linux内核中线程也被称之为轻量级进程。从定义中可以看出,线程它是操作系统的概念,在不同的操作系统中的实现是不同的 但是作为学习 我们还是先来了解一下 线程的概念
主要有三种线程的实现方式:
- 用户线程(User Thread):在用户空间实现的线程,不是由内核管理的线程,是由用户态的线程库来完成线程的管理;
- 内核线程(Kernel Thread):在内核中实现的线程,是由内核管理的线程;
- 轻量级进程(LightWeight Process)
那么,这还需要考虑一个问题,用户线程和内核线程的对应关系。
1)用户线程和内核线程的关系:
1.首先,第一种关系是多对一的关系,也就是多个用户线程对应同一个内核线程:
多对一模型将多个用户线程映射到一个内核线程上,线程之间的切换由用户态的代码来进行,因此相对一对一模型,多对一模型的线程切换速度要快许多;此外,多对一模型对用户线程的数量几乎无限制。但多对一模型也有两个缺点:
- 如果其中一个用户线程阻塞,那么其它所有线程都将无法执行,因为此时内核线程也随之阻塞了
- 在多处理器系统上,处理器数量的增加对多对一模型的线程性能不会有明显的增加,因为所有的用户线程都映射到一个处理器上了。

2.第二种是一对一的关系,也就是一个用户线程对应一个内核线程(NPTL就是采用这种):
LinuxThreads与NPTL均采用一对一的线程模型 只不过实现形式有点不一样
内核负责每个线程的调度,可以调度到其他处理器上面。Linux 2.6默认使用NPTL线程库,一对一的线程模型。
对于一对一模型来说,一个用户线程就唯一地对应一个内核线程(反过来不一定成立,一个内核线程不一定有对应的用户线程)。这样,如果CPU没有采用超线程技术(如四核四线程的计算机),一个用户线程就唯一地映射到一个物理CPU的线程,线程之间的并发是真正的并发。一对一模型使用户线程具有与内核线程一样的优点,一个线程因某种原因阻塞时其他线程的执行不受影响;此处,一对一模型也可以让多线程程序在多处理器的系统上有更好的表现。
但一对一模型也有两个缺点:
- 许多操作系统限制了内核线程的数量,因此一对一模型会使用户线程的数量受到限制
- 许多操作系统内核线程调度时,上下文切换的开销较大,导致用户线程的执行效率下降。

3.第三种是多对多的关系,也就是多个用户线程对应到多个内核线程:
多对一线程模型是非常轻量的,问题在于多个用户线程对应到固定的一个内核线程。多对多线程模型解决了这一问题:m个用户线程对应到n个内核线程上,通常m>n。Linux由IBM主导的NGPT采用了多对多的线程模型,不过现在已废弃。
多对多模型结合了一对一模型和多对一模型的优点,将多个用户线程映射到多个内核线程上。
优点:1.一个用户线程的阻塞不会导致所有线程的阻塞,因为此时还有别的内核线程被调度来执行;2.多对多模型对用户线程的数量没有限制;3.在多处理器的操作系统中,多对多模型的线程也能得到一定的性能提升,但提升的幅度不如一对一模型的高。
缺点:
- 实现复杂
在现在流行的操作系统中,大都采用多对多的模型。

2)用户线程,内核线程,轻量级进程简介
1)用户线程如何理解?存在什么优势和缺陷?
用户线程是基于用户态的线程管理库来实现的,那么线程控制块(Thread Control Block, TCB) 也是在库里面来实现的,对于操作系统而言是看不到这个 TCB 的,它只能看到整个进程的 PCB。
所以,用户线程的整个线程管理和调度,操作系统是不直接参与的,而是由用户级线程库函数来完成线程的管理,包括线程的创建、终止、同步和调度等。
**也就是说 用户线程就是函数库实现(也就是说,不管你操作系统是不是支持线程的,我都可以在你上面用多线程编程)。
也就是说就算操作系统内核不支持线程 但是用户线程相当于我使用一个库函数 来模拟的线程
用户级线程的模型,也就类似前面提到的多对一的关系,即多个用户线程对应同一个内核线程,如下图所示:
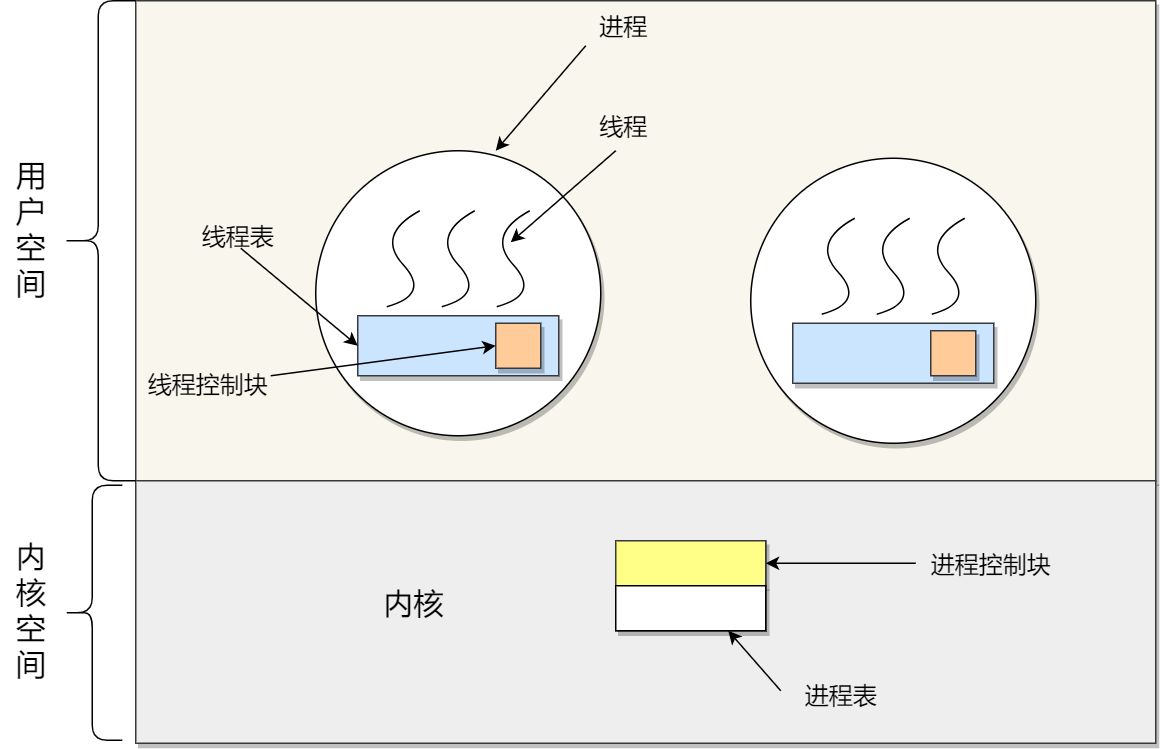
用户线程的优点:
- 每个进程都需要有它私有的线程控制块(TCB)列表,用来跟踪记录它各个线程状态信息(PC、栈指针、寄存器),TCB 由用户级线程库函数来维护,可用于不支持线程技术的操作系统;
- 用户线程的切换也是由线程库函数来完成的,无需用户态与内核态的切换,所以速度特别快;
用户线程的缺点:
- 由于操作系统不参与线程的调度,如果一个线程发起了系统调用而阻塞,那进程所包含的用户线程都不能执行了。
- 当一个线程开始运行后,除非它主动地交出 CPU 的使用权,否则它所在的进程当中的其他线程无法运行,因为用户态的线程没法打断当前运行中的线程,它没有这个特权,只有操作系统才有,但是用户线程不是由操作系统管理的。
- 由于时间片分配给进程,故与其他进程比,在多线程执行时,每个线程得到的时间片较少,执行会比较慢;
以上,就是用户线程的优缺点了。
2)那内核线程如何理解?存在什么优势和缺陷?
内核线程是由操作系统管理的,线程对应的 TCB 自然是放在操作系统里的,这样线程的创建、终止和管理都是由操作系统负责。
内核线程的模型,也就类似前面提到的一对一的关系,即一个用户线程对应一个内核线程,如下图所示:

内核线程的优点:
- 在一个进程当中,如果某个内核线程发起系统调用而被阻塞,并不会影响其他内核线程的运行;
- 分配给线程,多线程的进程获得更多的 CPU 运行时间;
内核线程的缺点:
- 在支持内核线程的操作系统中,由内核来维护进程和线程的上下问信息,如 PCB 和 TCB;
- 线程的创建、终止和切换都是通过系统调用的方式来进行,因此对于系统来说,系统开销比较大;
以上,就是内核线的优缺点了。
3)最后的轻量级进程(LWP)如何理解?。
轻量级进程(Light-weight process,LWP)。
它是基于内核线程的高级抽象,因此只有先支持内核线程,才能有LWP。每一个进程有一个或多个LWPs,每个LWP由一个内核线程支持。这种模型实际上就是恐龙书上所提到的一对一线程模型。
由于每个LWP都与一个特定的内核线程关联,因此每个LWP都是一个独立的线程调度单元。即使有一个LWP在系统调用中阻塞,也不会影响整个进程的执行。
Linux内核上没有线程的概念,CPU的调度是以进程为单位的。一个进程可有一个或多个 LWP,每个 LWP 是跟内核线程一对一映射的,也就是 LWP 都是由一个内核线程支持。
轻量级进程具有局限性。首先,大多数LWP的操作,如建立、析构以及同步,都需要进行系统调用。系统调用的代价相对较高:需要在user mode和kernel mode中切换。其次,每个LWP都需要有一个内核线程支持,因此LWP要消耗内核资源(内核线程的栈空间)。因此一个系统不能支持大量的LWP。
另外,LWP 只能由内核管理并像普通进程一样被调度,Linux 内核是支持 LWP 的典型例子。
在大多数系统中,LWP与普通进程的区别也在于它只有一个最小的执行上下文和调度程序所需的统计信息。一般来说,一个进程代表程序的一个实例,而 LWP 代表程序的执行线程,因为一个执行线程不像进程那样需要那么多状态信息,所以 LWP 也不带有这样的信息。
在 LWP 之上也是可以使用用户线程的,那么 LWP 与用户线程的对应关系就有三种:
1 : 1,即一个 LWP 对应 一个用户线程;N : 1,即一个 LWP 对应多个用户线程;N : N,即多个 LMP 对应多个用户线程;
接下来针对上面这三种对应关系说明它们优缺点。先下图的 LWP 模型:

1 : 1 模式
一个线程对应到一个 LWP 再对应到一个内核线程,如上图的进程 4,属于此模型。
- 优点:实现并行,当一个 LWP 阻塞,不会影响其他 LWP;
- 缺点:每一个用户线程,就产生一个内核线程,创建线程的开销较大。
N : 1 模式
多个用户线程对应一个 LWP 再对应一个内核线程,如上图的进程 2,线程管理是在用户空间完成的,此模式中用户的线程对操作系统不可见。
- 优点:用户线程要开几个都没问题,且上下文切换发生用户空间,切换的效率较高;
- 缺点:一个用户线程如果阻塞了,则整个进程都将会阻塞,另外在多核 CPU 中,是没办法充分利用 CPU 的。
M : N 模式
根据前面的两个模型混搭一起,就形成 M:N 模型,该模型提供了两级控制,首先多个用户线程对应到多个 LWP,LWP 再一一对应到内核线程,如上图的进程 3。
- 优点:综合了前两种优点,大部分的线程上下文发生在用户空间,且多个线程又可以充分利用多核 CPU 的资源。
组合模式
如上图的进程 5,此进程结合 1:1 模型和 M:N 模型。开发人员可以针对不同的应用特点调节内核线程的数目来达到物理并行性和逻辑并行性的最佳方案。
二.Linux中的线程
需要了解的东西:
简单的说:内核级就是操作系统内核支持,用户级就是函数库实现(也就是说,不管你操作系统是不是支持线程的,我都可以在你上面用多线程编程)。
好了,那么,我们首先明白一件事:不管Linux还是什么OS,都可以多线程编程的,怎么多线程编程呢?程序员要创建一个线程,当然需要使用xxx函数,这个函数如果是操作系统本身就提供的系统函数,当然没问题,操作系统创建的线程,自然是内核级的了。
如果操作系统没有提供“创建线程”的函数(比如Linux 2.4及以前的版本,因为Linux刚诞生那时候,还没有“线程”的概念,能处理多“进程”就不错了),当然你程序员也没办法在操作系统上创建线程。所以,Linux 2.4内核中不知道什么是“线程”,只有一个“task_struct”的数据结构,就是进程。那么,后来随着科学技术的发展,大家提出线程的概念,而且,线程有时候的确是个好东西,于是,我们希望Linux能加入“多线程”编程。
要修改一个操作系统,那是很复杂的事情,特别是当操作系统越来越庞大的时候。怎么才能让Linux支持“多线程”呢?
首先,最简单的,就是不去动操作系统的“内核”,而是写一个函数库来“模拟”线程。也就是说,我用C写一个函数,比如 create_thread,这个函数最终在Linux的内核里还是去调用了创建“进程”的函数去创建了一个进程(因为OS没变嘛,没有线程这个东西)。 如果有人要多线程编程,那么你就调用 这个create_thread 去创建线程吧,好了,这个线程,就是用库函数创建的线程,就是所谓的“用户级线程”了。等等,这是神马意思?赤裸裸的欺骗?也不是。
为什么不是?因为别人给你提供了这个线程函数,你创建了“线程”,那么,你的线程(虽然本质上还是进程)就有了“线程”的一些“特征”,比如可以共享变量啊什么的,咦?那怎么做到的?当然有一套机制,反正人家给你做好了,你用就行了。
这种欺骗自然是不“完美”的,有线程的“一些”特征,但不能完全符合理论上的“线程”的概念(POSIX的要求),比如,这种多线程不能被分配到多核上,用户创建的N个线程,对于着内核里面其实就一个“进程”,导致调度啊,管理啊麻烦.....
为什么要采用这种“模拟”的方式呢?改内核不是一天两天的事情,先将就用着吧。内核慢慢来改。
怎么干改内核这个艰苦卓越的工作?Linux是开源、免费的,谁愿意来干这个活?有两家公司参与了对LinuxThreads的改进(向他们致敬):IBM启动的NGTP(Next Generation POSIX Threads)项目,以及红帽Redhat公司的NPTL(Native POSIX Thread Library),IBM那个项目,在2003年因为种种原因放弃了,大家都转到NPTL这个项目来了。
最终,当然是成功了,在Linux 2.6的内核版本中,这个NPTL项目怎么做的呢?并不是在Linux内核中加了一个“线程”,仍然和原来一样,进程 只不过使用了轻量级进程(其实,进程线程就是个概念,对于计算机,只要能高效的实现这个概念就行,程序员能用就OK,管它究竟怎么实现的),不过,用的clone实现的轻量级进程,内核又增加了若干机制来保证线程的表现和POSIX相同,最关键的一点,用户调用pthread库创建的一个用户线程,会在内核创建一个“线程”(轻量级进程LWP),这就是所谓的1:1模型。所以,Linux下,是有“内核级”线程(轻量级进程)的,网上很多说Linux是用户级线程,都是不完整的,说的Linux很早以前的版本(现在Linux已经是4.X的版本了)。

Linux使用的线程库
使用的线程库也就是前面我们学习用户线程里面提到的 通过函数库创建用户线程 中的函数库
Linux提供两个线程库,Linux Threads 和新的原生的POSIX线程库(NPTL),linux threads在某些情况下仍然使用,但现在的发行版已经切换到NPTL,并且大部分应用已经不在加载linux threads,NPTL更轻量,更高效,也会有那些linux threads遇到的问题。
。NPTL是一个1×1的线程模型,即一个线程对于一个操作系统的调度进程,优点是非常简单。
1)LinuxThread
LinuxThreads是用户空间的线程库,所采用的是线程-进程1对1模型,将线程的调度等同于进程的调度,调度交由内核完成,而线程的创建、同步、销毁由核外线程库完成(LinuxThtreads已绑定到 GLIBC中发行)。
在LinuxThreads中,由专门的一个管理线程处理所有的线程管理工作。当进程第一次调用pthread_create()创建线程时就会先 创建(clone())并启动管理线程。后续进程pthread_create()创建线程时,都是管理线程作为pthread_create()的调用 者的子线程,通过调用clone()来创建用户线程,并记录轻量级进程号和线程id的映射关系,因此,用户线程其实是管理线程的子线程。
LinuxThreads只支持调度范围为PTHREAD_SCOPE_SYSTEM的调度,默认的调度策略是SCHED_OTHER。
用户线程调度策略也可修改成SCHED_FIFO或SCHED_RR方式,这两种方式支持优先级为0-99,而SCHED_OTHER只支持0。
- SCHED_OTHER 分时调度策略,
- SCHED_FIFO 实时调度策略,先到先服务
- SCHED_RR 实时调度策略,时间片轮转
SCHED_OTHER是普通进程的,后两个是实时进程的(一般的进程都是普通进程,系统中出现实时进程的机会很少)。SCHED_FIFO、 SCHED_RR优先级高于所有SCHED_OTHER的进程,所以只要他们能够运行,在他们运行完之前,所有SCHED_OTHER的进程的都没有得到 执行的机会。
在实现LinuxThread之前,系统内核并没有提供任何对线程的支持,实现LinuxThread时也并没有针对其做任何的改动,所以LinuxThread只能使用现有的系统调用来创建一些用户接口来尽量模仿POSIX定义的API的语义,这也就是导致了pthread之外的系统调用接口表现出来的行为跟POSIX的线程标准不一致,如最简单的在同一个进程里的不同线程里调用getpid()的结果不一致,具体原因后面详细说明。
创建线程
LinuxThread使用的是1 * 1模型,即每一个用户态线程都有一个内核的管理实体跟其对应,这个内核对应的管理实体就是进程,又称LWP(轻量级进程)。这里先说一下,系统调用clone(),大家熟知的fork()函数就是调用clone()来实现父进程拷贝的从而创建一个新进程的。系统调用clone()里有一个flag参数,这个参数有很多的标志位指定了克隆时需要拷贝的东西,其中标志位CLONE_VM就是定义拷贝时是否使用相同的内存空间。fork()调用clone()时没有设置CLONE_VM,所以在内核看来就是产生了两个拥有不同内存空间的进程。而pthread_create()里调用clone()时设置了CLONE_VM,所以在内核看来就产生了两个拥有相同内存空间的进程。所以用户态创建一个新线程,内核态就对应生成一个新进程。
从上面就可以得到问题的答案了,为什么在同一个进程里面不同线程getpid()得到的结果不一样。其他很多在pthreads(7) - Linux manual page里提到的不兼容特性都可以根据这一段的论述得到答案。
同步互斥
内核没有提供任何对线程的支持,当然也就没有可供线程同步互斥使用的系统原语,但POSIX的线程标准里要求了诸多的互斥同步接口,怎么办呢?LinuxThread使用信号来模拟同步互斥,比如互斥锁,大致过程我猜如下:新建互斥锁的时候,在内核里把所有的进程mask掉一个特定信号,然后再kill()发出一个信号,等某个线程执行锁定时,就用sigwait()查看是否有发出的信号,如果没有就等待,有则返回,相当于锁定。解锁时就再kill()发出这个信号。那么LinuxThread使用的是哪几个信号来模拟这个同步互斥的呢?有的文档说是SIGUSR1和SIGUSR2,也有的说是某几个实时信号,具体可以看对应线程库的开发手册。必须知道你所使用的线程库内部使用哪几个信号,因为如果你的多线程程序里也使用了这几个信号的话,就会导致线程API工作混乱。
从行分析就可以得出,LinuxThrea的同步互斥是用信号模拟完成的,所以效率不高且可能影响原有进程的信号处理,确实是个很大的缺陷。
信号处理
LinuxThread的信号处理的行为可以说跟POSIX的标准是完全不一致的。因为信号的投递过程是发生在内核的,而每个线程在内核都是对应一个个单独的进程(不理解请看LinuxThread的创建线程一节),所以没有内核支持,所以当你对一个进程发送一个信号后,只有拥有这个进程号的进程才有反应,而属于这个进程的线程因为拥有不同的进程号而无法做出响应,从而LinuxThread无法做到跟POSIX定义的行为一致。
线程管理
这里不得不说到LinuxThread的一个特性,当你创建第一个线程时,也就会自动创建一个管理线程,这个过程对用户是透明的。所以如果你还在使用LinuxThread线程库,当你创建一个线程后ps的结果会是有三个相同的进程而不是两个。这个管理线程的主要作用是管理线程的创建与终止,所以如果你把这个管理线程kill掉后,当你的某个线程退出后就会出现Zombie进程。另外,因为线程的创建与终止都要通过这个管理线程,在一个频繁创建与终止线程的程序这个线程很可能成为性能的瓶颈。
2)NPTL
NPTL使用了跟LinuxThread相同的办法,在内核里面线程仍然被当作是一个进程,并且仍然使用了clone()系统调用(在NPTL库里调用)。但是,NPTL需要内核级的特殊支持来实现,比如需要挂起然后再唤醒线程的线程同步原语futex.
NPTL也是一个1*1的线程库,就是说,当你在使用pthread_create()调用创建一个用户线程后,在内核里就相应创建了一个调度实体(也就是轻量级进程LWP),在linux里就是一个新进程,这个方法最大可能的简化了线程的实现。
因为没有内核支持的LinuxThread的线程实现的诸多缺陷,所以要想实现完全跟POSIX线程标准兼容的线程库,重写线程库是必然的,内核的修改也势在必行。有关NPTL实现也从线程创建,同步互斥及信号处理及线程管理几个方面来说明。
创建线程
NPTL同样使用的是1 * 1模型,但此时对应内核的管理结构不再是LWP了。为了管理进程有进程组的概念,那内核要管理线程提出线程组的概念就是很自然的了。Linux内核只是在原来的进程管理结构(task_struct结构体)新增了一个TGIP的字段,如下图。当一个线程的PID等于TGID时,这个线程就是线程组长,其PID也就是这个线程组的进程号。线程组内的所有线程的TGID字段都指向线程组长的PID,当你使用getpid返回的都是TGID字段,而线程号返回的就是PID字段。那么NPTL下线程又是如何创建线程的呢?同样是使用clone()系统调度,不过新的clone()调用的flag参数新增了一个标志位CLONE_THREAD,当这个标志位设置的时候新创建的行为就是创建一个线程,内核内部初始管理结构时把TGID指向调用者的PID,原来的PID位置填新线程号(也就是以前的进程号)。
从上,LinuxThread因为在内核是一个LWP而产生的跟POSIX标准不兼容的错误都消除了。

同步与互斥
从LinuxThread中的线程同步与互斥中可看到使用信号来模拟的缺点,所以内核增加一个新的互斥同步原语futex(fast usesapace locking system call),意为快速用户空间系统锁。因为进程内的所有线程都使用了相同的内存空间,所以这个锁可以保存在用户空间。这样对这个锁的操作不需要每次都切换到内核态,从而大大加快了存取的速度。NPTL提供的线程同步互斥机制都建立在futex上,所以无论在效率上还是咋对程序的外部影响上都比LinuxThread的方式有了很大的改进。具体futex的描述可以man futex。
信号处理
此时因为同一个进程内的线程都属于同一个进程,所以信号处理跟POSIX标准完全统一。当你发送一个SIGSTP信号给进程,这个进程的所有线程都会停止。因为所有线程内用同样的内存空间,所以对一个signal的handler都是一样的,但不同的线程有不同的管理结构所以不同的线程可以有不同的mask。后面这一段对LinuxThread也成立。
管理线程
线程创建与结束的管理都由内核负责了,由LinuxThread的管理线程机制引出的问题已不复存在了。当然系统调度上仍是一个单独的线程而不是多个线程组成一个进程为整体进行调度的。这跟POSIX的标准还是稍有不同,不过这一缺点看起来无伤大雅。
Linux中的线程概念
Linux内核中是没有线程这个概念的,而是轻量级进程的概念:LWP。一般我们所说的线程概念是C库当中的概念,也就是我们前面学的使用库函数模拟的线程 用户线程。
线程它是一种概念;操作系统的概念,在不同的操作系统中的实现是不同的
线程是操作系统能够调度和执行的基本单位。
对于Linux操作系统而言,它对Thread的实现方式比较特殊。在Linux内核中(注意是内核中,并不是用户态),其实是没有线程的概念的,它把所有的线程当做标准的进程来实现,也就是说Linux内核,并没有为线程提供任何特殊的调度语义,也没有为线程实现特定的数据结构。取而代之的是,线程的概念只是一个与其他进程共享某些资源的进程。每一个线程拥有一个唯一的task_struct结构,Linux内核它仅仅把线程当做一个正常的进程,或者说是轻量级进程,LWP(Lightweight processes)。
对于其他的操作系统而言,比如windows,线程相对于进程,只是一个提供了更加轻量、快速执行单元的抽象概念。对于Linux而言,线程只是进程间共享资源的一种方式,非常轻量。举个简单例子,假设有一个进程包含了N个线程。对于那些显示支持线程的操作系统而言,应该是存在一个进程描述符,依次轮流指向N个线程。这个进程描述符指明共享资源,包括内存空间和打开的文件,然后线程描述它们自己独享的资源。相反的是在Linux中,只有N个进程,因此有N个task_struct数据结构,只是这些数据结构的某些资源项是共享的。
这里再总结一下:Linux线程是进程资源共享的一种方式,而其他操作系统,线程则是一种实现轻量、快速执行单元的抽象概念或者实体。这里再深入的理解一下,Linux中的线程和进程的区别。这也是诸多面试题中,最常见的一个。
linux下没有真正意义的线程,因为linux下没有给线程设计专有的结构体,它的线程是用进程模拟的,而它是由多个进程共享一块地址空间而模拟得到的。可以说,Linux系统内核并不认识线程,所有的任务执行都是以进程的形式存在的
- 从Linux内核里看进程和线程是一样的,都有各自不同的PCB,但是PCB中指向内存资源的三级页表是相同的。
线程切换只能在内核态完成,如果当前用户处于用户态,则必然引起用户态与内核态的切换。
线程是怎样描述的?
什么是主线程和工作线程?
一个进程可以包含多个线程 ,主线程可以看做是进程的化身 而工作线程 顾名思义就是工作的 也就是去执行我们指定的函数 也就是我们使用线程库函数pthread_create()创建的用户线程
而所谓主线程与所属进程实际上是同一个task_struct,也能被CPU调度,因此主线程也是CPU调度的基本单位。
tgid(也就是所属进程的PID)相同的所有线程组成了概念上的“进程”,只有主线程在创建时会实际分配资源,其他线程(也既工作线程)通过浅拷贝共享主线程的资源。结合前面介绍的普通线程与轻量级进程,实现“进程是资源分配的基本单位”
上图中的tid其实指的是使用线程库创建的每个用户线程在内核对应的轻量级进程(LWP)的进程标识符PID 而用户线程的id就和线程库函数的实现有关了我们可以使用pthread_self()这个线程库函数来获取用户线程id.

每个用户线程实际上在内核中对应一个轻量级进程(LWP)也就是一个task_struct,工作线程拷贝主线程的task_struct,然后共用主线程的mm_struct。线程ID是在用task_struct中pid描述的,而task_struct中tgid是线程组ID,表示线程属于该线程组,对于主线程(也就是包含许多线程的进程)而言,其pid和tgid是相同的,我们一般看到的进程ID就是tgid。
即:

线程是CPU调度的基本单位、一个进程下可能有多个线程
linux加入了线程组的概念,让原有“进程”对应线程,“线程组”对应进程,实现“一个进程下可能有多个线程”:
- 操作系统中存在多个进程组
- 一个进程组下有多个进程(1:n)
- 一个进程对应一个线程组(1:1)
- 一个线程组下有多个线程(1:n)
task_struct(进程控制块PCB)中,使用pgid标的进程组,tgid标的线程组,pid标的进程或线程。假设目前有一个进程组,则上述概念对应如下:
- 进程组中有一个主进程(父进程),pid等于进程组的pgid;进程组下的其他进程都是父进程的子进程,pid不等于pgid
- 每个进程对应一个线程组,进程的pid等于线程组tgid。
- 线程组中有一个“主线程”(勉强称为“主线程”,为的是与主进程对应;语义上绝不能称为“父线程”),pid等于该线程组的tgid;线程组下的其他线程都是与主线程平级,pid不等于tgid
因此,调用getpgid返回pgid,调用getpid应返回tgid,调用gettid应返回pid(这个pid是内核中的轻量化进程(LWP)的pid)。使用的时候不要糊涂。
也就是说:
线程:pid :线程所属的进程的PID
tgid :线程组PID, 也就是线程所属的进程的PID
tid :其实就是 用户线程在内核对应的轻量级进程(LWP)的PID。注意要和线程库 函数pthread_self()获取的用户线程的id区别开来
进程:pid :该进程的PID
pgid :进程所属的进程组的ID
为什么要有多线程?
举个生活中的例子, 这就好比去银行办理业务。 到达银行后, 首先取一个号码, 然后坐下来安心等待。 这时候你一定希望, 办理业务的窗口越多越好。 如果把整个营业大厅当成一个进程的话, 那么每一个窗口就是一个工作线程。
Linux中的线程的资源
Linux中一个进程中的多个线程:
1)共享以下资源:
- 共享同一个进程的部分虚拟地址空间(共享区)
- 执行的命令
- 静态数据(例如全局变量等)
- 打开文件的文件描述符
- 信号处理函数
- 当前工作目录
- 用户ID(UID)
- 用户组ID(GID)
2)每个线程私有的资源有:
- 线程标识符(简称线程号,TID)
- 程序计数器(PC)与相关寄存器
- 堆栈区(局部变量、函数返回地址等)
- 错误号errno
- 信号掩码与优先级
- 执行状态与属性
PS:如果进程退出了 则这个进程的所有线程都会退出
所以就有:
因为我们使用线程库pthread_create()函数创建用户线程 内核会对应创建一个轻量化进程(LWP)也就是我们说的“内核线程” 所以这是需要时间的 即使它可能很短
又因为如果进程退出 那么这个进程所有的线程都会退出 所以我们在使用线程库创建线程去执行函数时要确保进程不会退出 不然创建的线程还没执行完函数就因为进程的退出而退出了
多线程如何避免调用栈混乱的问题?
工作线程和主线程共用一个mm_struct,如果都向栈中压栈,必然会导致调用栈出错。
实际上工作线程压栈是压了共享区,该共享区包含了许多线程独有的资源。如图:

每一个线程,默认在共享区中占有的空间为8M,可以使用ulimit -s修改。
线程带来的优势
- 线程会共享内存地址空间。
- 创建线程花费的时间要少于创建进程花费的时间。
- 终止线程花费的时间要少于终止进程花费的时间。
- 线程之间上下文切换的开销, 要小于进程之间的上下文切换。
- 线程之间数据的共享比进程之间的共享要简单。
- 充分利用多处理器的可并行数量。(线程会提高运行效率,但当线程多到一定程度后,可能会导致效率下降,因为会有线程调度切换。)
线程带来的缺点
- 健壮性降低:多个线程之中, 只要有一个线程不够健壮存在bug(如访问了非法地址引发的段错误) , 就会导致进程内的所有线程一起完蛋。
- 线程模型作为一种并发的编程模型, 效率并没有想象的那么高, 会出现复杂度高、 易出错、 难以测试和定位的问题。
注意
1.并不是只有主线程才能创建线程, 被创建出来的线程同样可以创建线程。
2.不存在类似于fork函数那样的父子关系, 大家都归属于同一个线程组, 进程ID都相等, group_leader都指向主线程, 而且各有各的线程ID。
通过group_leader指针, 每个线程都能找到主线程。 主线程存在一个链表头,后面创建的每一个线程都会链入到该双向链表中。
3.并非只有主线程才能调用pthread_join连接其他线程, 同一线程组内的任意线程都可以对某线程执行pthread_join函数。
4.并非只有主线程才能调用pthread_detach函数, 其实任意线程都可以对同一线程组内的线程执行分离操作。
线程的对等关系:

为什么Linux中的线程相比进程能减少开销?
Linux中的线程相比进程能减少开销,体现在:
- 线程的创建时间比进程快,因为进程在创建的过程中,还需要资源管理信息,比如内存管理信息、文件管理信息,而线程在创建的过程中,不会涉及这些资源管理信息,而是共享它们;
- 线程的终止时间比进程快,因为线程释放的资源相比进程少很多;
- 同一个进程内的线程切换比进程切换快,因为线程具有相同的地址空间(虚拟内存共享),这意味着同一个进程的线程都具有同一个页表,那么在切换的时候不需要切换页表。而对于进程之间的切换,切换的时候要把页表给切换掉,而页表的切换过程开销是比较大的;
- 由于同一进程的各线程间共享内存和文件资源,那么在线程之间数据传递的时候,就不需要经过内核了,这就使得线程之间的数据交互效率更高了;
所以,线程比进程不管是时间效率,还是空间效率都要高。
Linux中的线程与进程的区别
一个进程可以拥有多个线程,每个线程共享该进程内的系统资源。由于线程共享进程的内存空间,因此任何线程对内存内数据的操作都可能对其他线程产生影响,因此多线程的同步与互斥机制是十分重要的。
线程本身只占用少量的系统资源,其内存空间也只拥有堆栈区与线程控制块(Thread Control Block,简称TCB),因此对线程的调度需要的系统开销会小得多,能够更高效地提高任务的并发度。
简单总结,Linux中进程与线程的区别主要在以下几点:
1)线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位;
2)地址空间与系统资源:进程间的地址空间与系统资源互相独立,互不干扰;同一进程内各线程共享地址空间与系统资源。一个进程内的线程对其他进程是不可见(私有)的。
3)通信手段:由于进程间互相独立,因此进程间通信必须借助某些手段。进程间通信手段主要有管道、信号、共享内存、SystemV等;而线程共享进程的资源与空间,因此同一个进程的线程间可以直接读写进程的数据段(例如全局变量等)进行通信,不过需要使用同步与互斥机制保证数据一致性。
4)调度与切换:进程占用系统资源较多,因此切换进程时开销较大;而线程占用系统资源较小,因此切换进程时开销较小。
进程是资源分配的基本单位、线程共享进程的资源
普通进程需要深拷贝虚拟内存、文件描述符、信号处理等;而轻量级进程之所以“轻量”,是因为其只需要浅拷贝虚拟内存等大部分信息,多个轻量级进程共享一个进程的资源。
线程是CPU调度的基本单位、一个进程下可能有多个线程
linux加入了线程组的概念,让原有“进程”对应线程,“线程组”对应进程,实现“一个进程下可能有多个线程”:
- 操作系统中存在多个进程组
- 一个进程组下有多个进程(1:n)
- 一个进程对应一个线程组(1:1)
- 一个线程组下有多个线程(1:n)
task_struct(进程控制块PCB)中,使用pgid标的进程组,tgid标的线程组,pid标的进程或线程。假设目前有一个进程组,则上述概念对应如下:
- 进程组中有一个主进程(父进程),pid等于进程组的pgid;进程组下的其他进程都是父进程的子进程,pid不等于pgid
- 每个进程对应一个线程组,进程的pid等于线程组tgid。
- 线程组中有一个“主线程”(勉强称为“主线程”,为的是与主进程对应;语义上绝不能称为“父线程”),tid等于该线程组的tgid;线程组下的其他线程都是与主线程平级,tid不等于tgid
因此,线程 调用getpgid返回pgid(也就是线程所属的进程所属的进程组id),调用getpid应返回tgid(也就是所属进程的id),调用gettid应返回pid(这个pid是内核中的轻量化进程(LWP)的pid)。使用的时候不要糊涂。
进程下除主线程外的其他线程是CPU调度的基本单位,这很好理解。而所谓主线程与所属进程实际上是同一个task_struct,也能被CPU调度,因此主线程也是CPU调度的基本单位。
tgid相同的所有线程组成了概念上的“进程”,只有主线程在创建时会实际分配资源,其他线程通过浅拷贝共享主线程的资源。结合前面介绍的普通线程与轻量级进程,实现“进程是资源分配的基本单位”。
举个栗子

- 存在3个进程组111、112、113
- 进程组111下有1个父进程111,单独分配资源
- 进程111下有1个线程111,共享进程111的资源
- 进程组112下有1个父进程112,单独分配资源
- 进程112下有2个线程112、113,共享进程112的资源
- 进程组113下有1个父进程113,1个子进程115,各自单独分配资源
- 进程113下有2个线程113、114,共享进程113的资源
- 进程115下有3个线程115、116、117,共享进程115的资源
小结
现在再来理解linux中的进程与线程就容易多了:
- 进程是一个逻辑上的概念,用于管理资源,对应task_struct中的资源
- 每个进程至少有一个线程,用于具体的执行,对应task_struct中的任务调度信息
- 以task_struct中的pid区分线程,tgid区分进程,pgid区分进程组
Linux中的线程的上下文切换
在前面我们知道了,线程与进程最大的区别在于:线程是调度的基本单位,而进程则是资源拥有的基本单位。
所以,所谓操作系统的任务调度,实际上的调度对象是线程,而进程只是给线程提供了虚拟内存、全局变量等资源。
对于线程和进程,我们可以这么理解:
- 当进程只有一个线程时,可以认为进程就等于线程;
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源,这些资源在上下文切换时是不需要修改的;
另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
Linux中的线程 上下文切换的是什么?
这还得看线程是不是属于同一个进程:
- 当两个线程不是属于同一个进程,则切换的过程就跟进程上下文切换一样;
- 当两个线程是属于同一个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据;
所以,线程的上下文切换相比进程,开销要小很多。
用户态进程/线程的创建 fork/vfork/pthread_create_Peter的专栏-CSDN博客forkfork 函数创建子进程成功后,父进程返回子进程的 pid,子进程返回0。具体描述如下:fork返回值为-1, 代表创建子进程失败fork返回值为0,代表子进程创建成功,这个分支是...https://peter.blog.csdn.net/article/details/118004707
上面这篇博客介绍了用户态创建进程和线程的方式,以及各个方式的特点。关于其底层的实现本质,我们后面会详细讲解。这里先提供一下三者之间的关系,可见三者最终都会调用 do_fork 实现。

在Linux中使用fork创建进程,使用pthread_create创建线程。两个系统调用最终都都调用了do_dork,而do_dork完成了task_struct结构体的复制,并将新的进程加入内核调度。这也印证了Linux中的线程其实就是轻量级的进程 。内核态没有进程线程的概念,内核中只认 task_struct 结构,只要是 task_struct 结构就可以参与调度
二.Linux中的线程编程——线程的创建、控制与删除
对于线程来说,线程编程主要考虑两部分工作:第一部分是线程的创建、控制与删除;第二部分是线程的同步与互斥。二者都可以使用NPTL线程库来实现。
在Linux系统中,多线程编程是通过第三方的线程库NPTL实现的。
/**********NPTL简介******************/
本地POSIX线程库(New POSIX Thread Library,简称NPTL)是早期Linux系统内Threads模型的改进,它可以让Linux内核高效运行使用POSIX风格编写的线程程序。有测试证明,使用NPTL启动10万个线程大概只需2秒时间,而未使用NPTL则需要15分钟。
NPTL最先发布在RedHat9.0版本中(2003年),老式POSIX线程库的效率太低,因此从这个版本开始,NPTL开始取代老式Linux线程库。
NPTL有以下特性:
采用1:1线程模型
显著提高运行效率
信号处理效率更高
使用NPTL线程库,需要添加头文件#include<pthread.h>,并且在编译时添加线程库-lpthread
/**********NPTL简介end***************/
//在使用NPTL线程库编程相关函数时,需要额外注意pthread_t类型,该数据类型是线程独有的数据类型,专门用于表示线程标识符,不能使用int类型代替。如果需要输出pthread_t类型数据,使用格式控制符%u(不过可能会出现warning)。
**使用NPTL线程库编程操作的对象基本上都是用户线程
线程中使用到的数据类型:
 改变互斥量属性,条件变量属性,线程属性的步骤是类似的可以类比
改变互斥量属性,条件变量属性,线程属性的步骤是类似的可以类比
1、*创建线程函数pthread_create()
pthread_create()_DSMGUOGUO的博客-CSDN博客多线程编程C语言使用pthread_create()函数完成多线程的创建,pthread_create()函数共有四个参数。这四个参数分别为:1. pthread_t *第一个 参数负责向调用者传递子线程的线程号2. const pthread_attr_t *第二这个参数负责控制线程的各种属性,这也是线程在创建的时候,最为复杂的一个参数。下面是这个结构体的定义:线程属性结构如下:typedef struct{ int .https://blog.csdn.net/DSMGUOGUO/article/details/108100544
创建线程需要指定线程执行函数,通常使用函数pthread_create()函数来创建一个线程。
线程创建完毕后,就开始执行指定的函数。在该函数执行完毕后,该线程结束。
函数pthread_create()
所需头文件:#include<pthread.h>
函数原型:
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine) (void *), void *arg);函数参数:
thread 创建的用户线程的标识符
attr 线程属性设置,如设置成NULL则为缺省(默认)(default)属性
routine 一个函数指针指向 线程将要执行的函数(注意函数的返回值和参数都要是指针)
arg 传递给routine的参数,传给线程执行函数的参数
第一个参数为 :指向用户线程标识符的指针。
线程创建成功的话,会将分配的线程ID填入该指针指向的地址。 线程的 后续操作将使用该值作为线程的唯一标识。
第二个参数是 :指向pthread_attr_t类型(线程属性结构体)的指针, 通过该参数可以定制线程的属性, 比如可以指定新建线程栈的大小、 调度策略等。 如果创建线程无特殊的要求, 该值也可以是NULL, 表示采用默认属性。
第三个参数是 :一个指向 线程需要执行的函数的函数指针。 创建线程, 是为了让线程执行一定的任务。 线程创建成功之后, 该线程就会执行start_routine函数, 该函数之于线程, 就如同main函数之于主线程。
第四个参数是 :新建线程执行的start_routine函数的入参(注意是指针类型)。
函数返回值:
成功:0
失败:返回错误码
返回的错误码类型:
| 返回值 | 描述 |
|---|---|
| EAGAIN | 系统资源不够,或者创建线程的个数超过系统对一个进程中线程总数的限制 |
| EINVAL | 第二个参数attr值不合法 |
| EPERM | 没有合适的权限来设置调度策略或参数 |
注意:使用pthread_create()函数时,第一个参数需要指定一个pthread_t类型的变量然后使用地址传递获取线程标识符。一般是我们直接新创建一个pthread_t类型的变量来作为线程标识符
比如:
pthread_t ptid;ret=pthread_create(&ptid, NULL, thread_func, &arg);pthread_create()参数传递注意问题(参数传地址问题)_modi000的博客-CSDN博客_pthread_create 传递参数![]() https://blog.csdn.net/modi000/article/details/104728979
https://blog.csdn.net/modi000/article/details/104728979
pthread_create()第四个参数 既执行的函数 传入参数arg的选择
| 传入参数 | 分析 | 是否可行 |
|---|---|---|
| 临时变量 | 临时变量的生命周期,临时变量的值会改变,传递临时变量有可能导致越界的问题 | 不可行 |
| 结构体对象 | 和临时变量相同 | 不可行 |
| 结构体指针 | 如果要释放该指针,要在在线程不会使用该指针以后 | 可行 |
| this指针 | 可行 |
不要使用局部变量传参,使用堆上开辟的变量可以。
如果是传递参数 则不能在线程创建过程中,改变传递的参数。因为用户线程的创建需要时间 。线程避免该问题产生的方法是传递值或者使用动态申请内存的方法。如果需要传参很多 就封装成一个结构体 传结构体指针
pthread_t类型和TID和PID
/******************************************************************************************************/
pthread_t ptid;
ret=pthread_create(&ptid, NULL, thread_func, &arg);涉及到的是 pthread_t 类型的指针ptid 它指向线程的线程控制块的地址,相当于这个线程对应的task_struct结构体的地址,这是进程的虚拟地址空间的中的地址。虽然进程使用了虚拟地址空间 但是由于不同进程的物理地址不同 不同进程中的线程中的ptid的值可能相同,但是他们不是相同的线程。因此不同进程中的线程是不能使用pthread_t ptid来通信的。
而TID指的是这个线程标识符 它标识这个线程对应的TCB(线程控制块)类似于进程标识符PID和PCB()线程控制块 它在系统中是全局的 所以每一个线程都有其独有的TID。因此即使是不同进程中的线程都可以使用TID进行通信。这也是为什么我们后面说不同进程的线程通信和进程间通信是类似的原因。
/******************************************************************************************************/
用户调用pthread_create函数时, 首先要为线程分配线程栈, 而线程栈的位置就落在共享区。 调用mmap函数为线程分配栈空间。 pthread_create函数分配的pthread_t类型的用户线程ID, 不过是分配出来的空间里的一个地址, 更确切地说是一个结构体的指针。
(下图的tid不是TID不要误会了,命名的不太好。。。)
上图中的左图是进程的虚拟地址空间 主线程栈也就是进程的栈空间
- 用户线程ID是进程虚拟地址空间内的一个地址, 要在同一个线程组内进行线程之间的比较才有意义。 不同线程组内的两个线程, 哪怕两者的pthread_t值是一样的, 也不是同一个线程。
- 用户线程ID就有可能会被复用:


2、线程退出函数pthread_exit()
退出线程需要使用pthread_exit()函数,这个函数属于线程自身的主动行为。需要注意的是,不能使用exit()函数试图退出线程,因为exit()函数的作用是使当前进程终止,如果某个线程调用了exit()函数,则会使得进程退出,该进程的所有线程都会直接终止。
函数pthread_exit()
所需头文件:#include<pthread.h>
函数原型:void pthread_exit(void *retval)
函数参数:
retval : retval是返回信息,”临终遗言“,可以给可以不给(要注意这是指针变量)
retval不要指向一个局部变量
该变量不能使用临时变量。
可使用:全局变量、堆上开辟的空间、字符串常量。如果返回值很多时,就封装成一个结构体,返回结构体变量的地址即 可。
线程的分离状态(分离和可结合(非分离) )
线程的分离状态决定一个线程以什么样的方式来终止自己。
线程的分离和可结合(非分离)其实就是 线程结束时资源是由其他线程回收还是由操作系统回收。
有这种区分是为了防止内存泄露 这和我们之前学习的僵尸进程是类似的 可以类比
1)可结合(非分离)就是由其他线程回收 类似于进程中 父进程调用wait回收子进程
2)分离 就是由操作系统回收线程资源 类似于进程中 signal(SIGCHLD,SIG_IGN) 通知内核,自己对子进程的结束不感兴趣,那么子进程结束后,内核会回收, 并不再给父进程发送信号。
在任何一个时间点上,线程是 可结合的(非分离)(joinable)或者是 分离 的 ( detached)。
- 非分离状态:线程的默认属性是非分离状态,这种情况下,原有的线程等待创建的线程结束。只有当pthread_join()函数返回时,创建的线程才算终止,才能释放自己占用的系统资源。
- 分离状态:分离线程没有被其他的线程所等待,自己运行结束了,线程也就终止了,马上释放系统资源。应该根据自己的需要,选择适当的分离状态(类似于 进程忽略 SIGCHLD信号 由系统 回收子进程资源)。
- 一个可结合的线程能够被其他线程收回其资源和杀死。在被其他线程回收之前,它的存储器资源(例如栈)是不释放的。
- 相反,一个分离的线程是不能被其他线程回收或杀死的,它的存储器资源在它终止时由系统自动释放。
使用线程库函数创建出的用户线程默认属性为可结合(非分离),所以必须等待它结束以回收它的资源 否则会产生类似僵尸进程的内存泄露的情况。
若线程为可分离则不需要由其他线程回收,线程运行结束后会自动释放所有资源。
线程的分离状态决定一个线程以什么样的方式来终止自己。在上面的例子中,我们采用了线程的默认属性,即为非分离状态(即可结合的,joinable,需要回收),这种情况下,原有的线程等待创建的线程结束;只有当pthread_join()函数返回时,创建的线程才算终止,才能释放自己占用的系统资源。而分离线程不是这样子的,它没有被其他的线程所等待,自己运行结束了,线程也就终止了,马上释放系统资源。程序员应该根据自己的需要,选择适当的分离状态。
在Linux平台默认情况下,虽然各个线程之间是相互独立的,一个线程的终止不会去通知或影响其他的线程。但是已经终止的线程的资源并不会随着线程的终止而得到释放,我们需要调用 pthread_join() 来获得另一个线程的终止状态并且释放该线程所占的资源。(说明:线程处于joinable状态下)
调用该函数的线程将挂起,等待 th 所表示的线程的结束。 thread_return 是指向线程 th 返回值的指针。需要注意的是 th 所表示的线程必须是 joinable 的,即处于非 detached(游离)状态;并且只可以有唯一的一个线程对 th 调用 pthread_join() 。如果 th 处于 detached 状态,那么对 th 的 pthread_join() 调用将返回错误。
如果不关心一个线程的结束状态,那么也可以将一个线程设置为 detached 状态,从而让操作系统在该线程结束时来回收它所占的资源。将一个线程设置为detached 状态可以通过两种方式来实现。一种是调用 pthread_detach() 函数,可以将线程 th 设置为 detached 状态。另一种方法是在创建线程时就将它设置为 detached 状态,首先初始化一个线程属性变量,然后将其设置为 detached 状态,最后将它作为参数传入线程创建函数 pthread_create(),这样所创建出来的线程就直接处于 detached 状态。
*这里要注意的一点是:
如果设置一个线程为分离线程,而这个线程运行又非常快,它很可能在pthread_create函数返回之前就终止了,它终止以后就可能将线程号和系统资源移交给其他的线程使用,这样调用pthread_create的线程就得到了错误的线程号。要避免这种情况可以采取一定的同步措施,最简单的方法之一是可以在被创建的线程里调用pthread_cond_timewait函数,让这个线程等待一会儿,留出足够的时间让函数pthread_create返回。设置一段等待时间,是在多线程编程里常用的方法。但是注意不要使用诸如wait()之类的函数,它们是使整个进程睡眠,并不能解决线程同步的问题。
我们可以通过调用线程库函数pthread_detach()或者通过改变线程属性 来将可结合(非分离)线程改变为分离线程
但是要把可结合(非分离)线程改变为分离线程只能通过改变线程属性来实现
通过调用线程库函数pthread_detach()或者通过改变线程属性 来将可结合(非分离)线程改变为分离线程:
- 线程分离函数——int pthread_detach(pthread_t tid);
返回值:pthread_detach() 在调用成功完成之后返回零。其他任何返回值都表示出现了 错误。如果检测到以下任一情况,pthread_detach()将失败并返回相应的值。
EINVAL:tid是分离线程
ESRCH:tid不是当前进程中有效的为分离线程
通过修改线程属性改变线程的为分离或者可结合(非分离)的相关函数:
- 初始化线程属性——int pthread_attr_init(pthread_attr_t *attr); 成功:0;失败:错误号
- 销毁线程属性所占用的资源——int pthread_attr_destroy(pthread_attr_t *attr); 成功: 0;失败:错误号
- 设置线程属性,分离or非分离——int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);
- 获取程属性,分离or非分离——int pthread_attr_getdetachstate(pthread_attr_t *attr, int *detachstate);
参数:
attr:已初始化的线程属性
detachstate: PTHREAD_CREATE_DETACHED(分离线程);PTHREAD _CREATE_JOINABLE(非分离线程)
设置线程分离属性的步骤
- 定义线程属性变量 pthread_attr_t attr (结构体)
- 初始化attr, pthread_attr_init(&attr)
- 设置线程为分离或非分离 pthread_attr_setdetachstate(&attr,detachstate);
- 创建线程pthread_create(&tid,&attr,thread_fun,NULL); 所有的系统都会支持线程的分离状态属性,
注意:
- 以默认方式启动的线程,在线程结束后不会自动释放占有的系统资源,要在主控线程中调用pthread_join()后才会释放;
- 以分离状态启动的线程,在线程结束后会自动释放所占有的系统资源,这个时候就不需要调用pthread_join方法了;
- 分离属性在网络通讯中使用的比较多;
- 以分离状态创建的线程就不需要去调用pthread_join了,同时以分离状态去创建的线程,是不能够获取线程返回的结果。
验证分离的线程是否能被join等待
void *thread_run(void * arg)
{pthread_detach(pthread_self());printf("%s\n",(char*)arg);return NULL;
}int main()
{pthread_t id;int temp =pthread_create(&id,NULL,thread_run,"thread1 run\n");if(temp != 0){printf("create errorcode:%s\n",strerror(temp));return -1;}//一个分离的线程是不能被其他进程杀死或回收的 所以最后回收失败int ret = 0;sleep(2);if(0 == pthread_join(id,NULL)){printf("thread waitsuccess\n");ret = 0;}else {printf("thread waitfailed\n");ret = 1;}return ret;
}3、等待线程函数pthread_join()
pthread_join( ) 是调用该函数的线程 阻塞等待至指定的可结合(非分离)线程退出类似于j进程 中的wait()
进程与进程之间,父进程使用wait()函数来等待回收子进程。线程内也有类似的机制,使用pthread_join()函数将一直等待到指定的可结合(非分离)的线程结束为止。
函数pthread_join() ——调用该函数的线程 阻塞等待指定的可结合(非分离)线程退出,如果 指定的线程是分离线程则会返回错误码
所需头文件:#include<pthread.h>
函数原型:int pthread_join(pthread_t thread, void **thread_result)
函数参数:
thread 等待线程的标识符
thread_result 用户定义的指针,当不为NULL时用来接收等待线程结束时的返回值,即 pthread_exit()函数内的retval值 (可以定义一个和返回值同类型的指针变量 取它的地址作为参数thread_result)
比如:线程的返回值为字符串 char *ret;pthread_join(userid,(void **)&ret)
若返回值是一个结构体 那就定义一个结构体指针取地址作为参数thread_result
函数返回值:
成功:0
失败:返回错误码
pthread_join()错误码:
一个线程只能被其他的唯一线程等待,如果有多个线程join同一个线程则会报错
| 返回值 | 说明 |
|---|---|
| ESRCH | 传入的线程ID不存在,查无此线程 |
| EINVAL | 线程不是一个joinable线程 也就是说这个线程是分离线程 |
| EINVAL | 已有其它线程捷足先登,链接目标线程 |
| EDEADLK | 死锁,如自己链接自己 |
线程等待和进程等待的不同
- 第一点不同之处是进程之间的等待只能是父进程等待子进程, 而线程则不然。线程组内的成员是对等的关系, 只要是在一个线程组内, 就可以对另外一个线程执行连接(join) 操作。
- 第二点不同之处是进程可以等待任一子进程的退出 , 但是线程的连接操作没有类似的接口, 即不能连接线程组内的任一线程, 必须明确指明要连接的线程的线程ID。
为什么要等待退出的线程?
使用pthread_join的目的和进程等待类似,防止出现类似僵尸进程的内存泄露的情况
如果不连接已经退出的线程, 会导致资源无法释放。 所谓资源指的又是什么呢?
- 已经退出的线程, 其空间没有被释放, 仍然在进程的地址空间之内。
- 新创建的线程, 没有复用刚才退出的线程的地址空间(也就是复用用户线程ID)。
当一个可结合线程终止时,它的内存资源(线程描述符和堆栈)就不会被释放,直到另一个线程在它上执行 pthread_join。因此,为了避免内存泄露,必须为每个可连接的线程调用 pthread_join
如果不执行连接操作, 线程的资源就不能被释放, 也不能被复用, 这就造成了资源的泄漏。
纵然调用了pthread_join, 也并没有立即调用munmap来释放掉退出线程的栈, 它们是被后建的线程复用了。 释放线程资源的时候, 若进程可能再次创建线程, 而频繁地munmap和mmap会影响性能, 所以将该栈缓存起来, 放到一个链表之中, 如果有新的创建线程的请求, 会首先在栈缓存链表中寻找空间合适的栈, 有的话, 直接将该栈分配给新创建的线程。
(使用pthread_join的目的和进程等待类似,防止出现类似僵尸进程的内存泄露的情况)
4.线程分离函数pthread_detach()
将当前进程中有效的 可结合(非分离)线程 改为分离线程
所需头文件:#include<pthread.h>
函数原型:int pthread_detach(pthread_t thread)
函数参数:
thread 需要更改为分离线程的用户线程标识符
返回值:
成功:0
失败:其他任何返回值都表示出现了错误。如果检测到以下任一情况,pthread_detach()将失 败并返回相应的值。
EINVAL:thread已经是分离线程了
ESRCH:thread不是当前进程中有效的 可结合(非分离)线程
5、取消线程函数pthread_cancel()
线程取消(pthread_cancel)_sjyhsyj的专栏-CSDN博客基本概念pthread_cancel调用并不等待线程终止,它只提出请求。线程在取消请求(pthread_cancel)发出后会继续运行,直到到达某个取消点(CancellationPoint)。取消点是线程检查是否被取消并按照请求进行动作的一个位置.与线程取消相关的pthread函数int pthread_cancel(pthread_t thread)发送终止信号给thttps://blog.csdn.net/sjyhsyj/article/details/16803801
详细内容看上面的博客
pthread_cancel调用并不等待线程终止,它只提出请求。线程在取消请求(pthread_cancel)发出后会继续运行,直到到达某个取消点(CancellationPoint)。取消点是线程检查是否被取消并按照请求进行动作的一个位置.
前面提到,我们可以使用pthread_exit()函数使得线程主动结束。实际应用中,我们经常需要让一个线程去结束另一个线程,此时可以使用pthread_cancel()函数来实现这样的功能。当然,被取消的线程内部需要事先设置取消状态,
可以使用pthread_setcancel()函数或pthread_setcanceltype()函数 来设置线程被取消的状态。
函数pthread_cancel()
所需头文件:#include<pthread.h>
函数原型:int pthread_cancel(pthread_t thread)
函数参数:
thread 需要取消的线程的标识符
函数返回值:
成功:0
失败:返回错误码
被取消的线程可以(使用pthread_setcancel()函数或pthread_setcanceltype()函数)设置自己的取消状态:
-1)被取消线程接收到另一个线程的取消请求后,是接受还是忽略?
-2)如果接受,是立即结束操作还是等待某个函数调用?
线程结束函数的总结
1)pthread_exit( ) 是线程自己主动直接退出 类似与进程的exit()
2)pthread_cancel() pthread_cancel调用并不等待线程终止,它只提出请求。线程在取消请求(pthread_cancel)发出后会继续运行,直到到达某个取消点(CancellationPoint)。取消点是线程检查是否被取消并按照请求进行动作的一个位置.比较复杂具体看博客
让线程结束的办法:
1.让线程入口函数执行结束(最主要使用的结束方式)
2.pthread_exit 让本线程结束,pthread_exit参数是一个void* 表示线程结束的返回结果(很少 用到)
3.pthread_cancel 让任意一个线程结束(本进程中的线程)不太推荐使用, pthread_cancel执行后对应的线程不一定会立刻结束 比较复杂具体看博客
4.如果线程组中的任何一个线程调用了exit函数, 或者主线程在main函数中执行了return语句, 那么整个线程组内的所有线程都会终止。
6.获取当前用户线程标识符函数pthread_self()
Linux下如何使用gettid函数且和pthread_self()的区别_For_zwb的博客-CSDN博客_gettid函数gettid它被定义在<sys./types.h>头文件中,但在程序中使用时发现没有gettid函数。我们可以自己封装一下#include<sys/syscall.h>syscall(SYS_gettid); //该函数和gettid等价。在编写程序时可以使用上述函数。也可以将其封装一下。pid_t gettid(){return syscall...https://blog.csdn.net/weixin_42250655/article/details/105234980
函数pthread_self()
所需头文件:#include<pthread.h>
函数原型:pthread_t pthread_self(void)
函数参数:无
函数返回值:当前线程的线程标识符
注意:该函数返回当前线程的线程标识符,即创建线程时pthread_create()函数参数1的值。线程标识符只有在所属的进程内有效。线程标识符在整个系统内是唯一的。
函数pthread_self()和系统调用gettid()有什么区别呢?
我们注意到有一个系统调用pid_t gettid(void) 这个系统调用和我们在学习进程的时候学习的系统调用pid_t getpid(void)很像 ,pid_t getpid(void)是获取进程标识符pid 那么类比pid_t gettid(void)是不是就是获取 线程标识符tid呢?那这和线程库函数pthread_t pthread_self(void)的返回值当前线程的线程标识符有什么区别呢?
这就涉及到我们前面学习的Linux线程的实现了,我们在前面的学习中知道:
Linux NPTL采用1:1线程模型也就是我们使用NPTL线程库创建一个用户线程就会在内核中创建一个与其对应的轻量级进程LWP (类似于内核线程)所以那么就很显而易见了 我们使用线程库函数创建了一个用户线程 内核中也创建了一个轻量级进程(LWP)我们使用pthread_t pthread_self(void) 获取的实际上是用户线程的线程标识符
而我们使用系统调用pid_t gettid(void)实际上返回的就是我们在创建的轻量级进程(LWP)的标识符了 所以返回值类型是pid_t.
总结:
先谈谈pthread_self()函数
- pthread_self()函数是线程库POSIX Phtread实现函数,它返回的线程ID是由线程库封装过然后返回的。既然是线程库函数,那么该函数返回的ID也就只在进程中有意义,与操作系统的任务调度之间无法建立有效关联。
- 另外glibc的Pthreads实现实际上把pthread_t用作一个结构体指针(它的类型是unsigned long),指向一块动态分配的内存,而且这块内存是反复使用的。这就造成pthread_t的值很容易重复。Pthreads只保证同一进程内,同一时刻的各个线程的id不同;不能保证同一进程先后多个线程具有不同的id。(当前一个线程结束其生命周期,进程又新创建了一个线程,那么该线程ID可能会使用消亡线程的ID)。
gettid()
- 该函数就是Linux提供的系统调用,它返回的ID就是轻量级进程(LWP)ID,相当于内核线程ID。
**在线程执行函数中使用gettid需要注意的点
在写程序时想通过gettid()函数获取线程id,但是编译时报错,undefined reference to gettid()
原因:随内核版本的变化,会增加一些新的系统调用,但如果glibc没有跟上,则不能直接调用,这个时候可以自己包装一下。如果想知道内核是否支持某系统调用,先得知道它的系统调用ID号,下面代码即是用来检查是否支持epoll_create1:
解决办法:将gettid()函数里的实现在外面封装实现一下即可,代码如下//包含此头文件 #include <sys/syscall.h> pid_t gettid(void) {return syscall(SYS_gettid); }然后再调用gettid()函数即可。
7.比较两个线程的线程标识符是否相等pthread_equal()
函数pthread_equal()
所需头文件:#include<pthread.h>
函数原型:int pthread_equal(pthread_t t1, pthread_t t2)
函数参数:需要比较的两个用户线程标识符
函数返回值:
非0 相等
0 不相等
注意:用户线程标识符使用特殊的pthread_t类型,通常情况不能直接像整数一样比较,需要使用pthread_equal()函数才行。该函数主要用于内核移植判定两个内核的线程是否相同,因为一比一模型 一个用户线程对应一个轻量进程(LWP)。
示例1:使用pthread_create()函数与pthread_exit()函数,创建线程,并让线程执行指定的函数
#include<stdio.h>#include<stdlib.h>#include<pthread.h>pthread_t tid; //定义线程标识符,需要定义成全局变量否则子函数无法访问void *thrd_function(void *arg) //线程需要执行的函数,注意函数定义的写法{printf("New Process: PID:%d, TID:%u.\n",getpid(),tid);pthread_exit(NULL); //退出线程}int main(){if(pthread_create(&tid,NULL,thrd_function,NULL)!=0)//第二个参数,缺省设置,第四个参数表示传给第三个参数(要执行函数)的参数,创建成功:返回值:0;失败返回错误码//注意调用pthread_create()函数的方法,以及第一个参数的写法//第三个参数也可以写成&thrd_function,但注意不要写成thrd_function(){printf("Create thread error!\n");exit(0);}printf("Main Process: PID:%d, TID in pthread_create function %u.\n",getpid(),tid);sleep(1);return 0;}**这个函数如果没有sleep(1)有可能线程执行的函数不会执行 因为进程执行完就退出了 而此时线程还没执行线程函数 因为使用线程库创建用户线程内核会相应创建一个轻量化进程(LWP),而创建需要时间 即使时间很短
示例2:创建多个线程,每个线程执行不同的函数
#include<stdio.h>#include<stdlib.h>#include<pthread.h>pthread_t tid1,tid2,tid3;void *thrd_function1(void *arg)//线程1需要执行的函数:什么也不做{printf("This is 1st thread:\n");printf("1st TID:%u.\n",tid1);printf("1st thread will exit\n");pthread_exit(NULL);//退出线程}void *thrd_function2(void *arg)//线程2需要执行的函数:打印传递的字符串{printf("This is 2nd thread:\n");printf("2nd thread will print string:%s\n",(char*)arg);printf("2nd thread will exit\n");pthread_exit(NULL);}void *thrd_function3(void *arg)//线程3需要执行的函数:计算1+2+3+……+100{printf("This is 3rd thread:\n");printf("3rd thread will calculate:1+2+3+……+100\n");int i,sum;for(i=0,sum=0;i<=100;i++){sum+=i;}printf("sum is %d\n",sum);printf("3rd thread will exit\n");pthread_exit(NULL);}int main(){if(pthread_create(&tid1,NULL,thrd_function1,NULL)!=0){printf("Create thread1 error!\n");exit(0);}if(pthread_create(&tid2,NULL,thrd_function2,"helloworld")!=0){printf("Create thread2 error!\n");exit(0);}if(pthread_create(&tid3,NULL,thrd_function3,NULL)!=0){printf("Create thread3 error!\n");exit(0);}sleep(1);return 0;}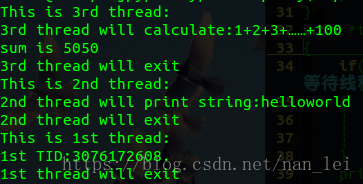
由示例2的程序我们可以看到,3个线程的执行完全是随机的,无法事先预制线程运行的顺序。
示例3:使用pthread_join()函数调整线程的运行顺序,让线程2先执行,线程1等待线程2退出后(即让线程1回收线程2的资源后)执行,线程3等待线程1退出后(即让线程3回收线程1的资源后)执行,主函数进程等待线程3退出后执行
#include<stdio.h>#include<stdlib.h>#include<pthread.h>pthread_t tid1,tid2,tid3;void *tret;void *thrd_function1(void *arg)//线程1需要执行的函数{if(pthread_join(tid2,&tret)!=0)//等待线程2结束,线程2结束的返回值存放在tret中{printf("Join thread 2 error\n");exit(0);}printf("Thread 2 exit code:%d\n",(int)tret);printf("This is 1st thread:\n");printf("1st TID:%u.\n",tid1);printf("1st thread will exit\n");pthread_exit((void*)1);//退出线程}void *thrd_function2(void *arg)//线程2需要执行的函数{printf("This is 2nd thread:\n");printf("2nd thread will print string:%s\n",(char*)arg);printf("2nd thread will exit\n");pthread_exit((void*)2);}void *thrd_function3(void *arg)//线程3需要执行的函数{if(pthread_join(tid1,&tret)!=0)//等待线程1结束,线程1结束的返回值存放在tret中{printf("Join thread 1 error\n");exit(0);}printf("Thread 1 exit code:%d\n",(int)tret);printf("This is 3rd thread:\n");printf("3rd thread will calculate:1+2+3+……+100\n");int i,sum;for(i=0,sum=0;i<=100;i++){sum+=i;}printf("sum is %d\n",sum);printf("3rd thread will exit\n");pthread_exit((void*)3);}int main(){if(pthread_create(&tid1,NULL,thrd_function1,NULL)!=0){printf("Create thread1 error!\n");exit(0);}if(pthread_create(&tid2,NULL,thrd_function2,"helloworld")!=0){printf("Create thread2 error!\n");exit(0);}if(pthread_create(&tid3,NULL,thrd_function3,NULL)!=0){printf("Create thread3 error!\n");exit(0);}if(pthread_join(tid3,&tret)!=0)//等待线程3结束,线程3结束的返回值存放在tret中{printf("Join thread 3 error\n");exit(0);}printf("Thread 3 exit code:%d\n",(int)tret);printf("This is Main Process %d\n",getpid());sleep(1);return 0;}
该程序简单地实现了排列几个线程间的执行顺序,但是该方法并不常用。更加常用的方式是采用同步与互斥机制。有关同步与互斥机制我们会在下面讲解。
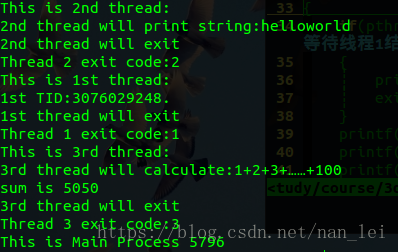
注意:一个线程只能被其他的唯一线程等待,如果有多个线程join同一个线程则会报错。因此,使用pthread_join()函数等待线程结束时需要注意第一个参数(线程标识符)是否与其他的pthread_join()函数冲突。
示例4:创建3个线程,让3个线程同时执行同一个函数,每个线程执行一个5次循环(看成执行5个小任务)。为了模拟每个任务执行时间与完成时间的随机性,每次执行循环之前都会等待1~6秒的时间。
#include<stdio.h>#include<stdlib.h>#include<pthread.h>#include<time.h>#include<math.h>#define THREAD_NUM 3 /*线程数*/#define REPEAT_NUM 5 /*每个线程执行的循环次数*/#define DELAY_TIME 6 /*每次循环的最大间隔*/void *thrd_function(void *arg){int thrd_num = (int)arg; //线程号,arg为void所以要强转为int型int delay_time = 0; //延迟时间int count = 0; //用来for循环的变量,线程的执行次数printf("Thread %d is running!\n",thrd_num);for(count=0;count<REPEAT_NUM;count++) //开始执行线程6次{delay_time = rand()%DELAY_TIME+1;//随机生成1~6,代表当次的等待时间,主函数中有srand(time(NULL))sleep(delay_time);//延时printf("\tThread %d: job %d delay=%d\n",thrd_num,count,delay_time);//显示:线程号、执行的第几次、延时的时间}printf("Thread %d finished\n",thrd_num); //表示该进程已经循环执行结束pthread_exit(NULL);}int main(){pthread_t thread[THREAD_NUM]; //线程数组,3个int no = 0; //用于循环创建3个线程void *thrd_ret; //用于接受每次线程结束时返回给主函数的值srand(time(NULL)); //随机延时用for(no=0;no<THREAD_NUM;no++) //循环创建线程{if(pthread_create(&thread[no],NULL,thrd_function,(void*)no)!=0) //创建多线程{printf("Create thread %d error!\n",no); //创建失败,会显示第几个线程创建失败exit(0);}}printf("Create all threads success, Waiting threads to finish……\n");for(no=0;no<THREAD_NUM;no++)//设定循环,主函数进程等待所有线程结束{if(pthread_join(thread[no],&thrd_ret)!=0)//等待线程结束,thrd_ret 用于接受线程退出时返回的值{printf("Join thread %d error\n",no);exit(0);}else{printf("Thread %d has been joined by MainProcess\n",no);//表示主函数进程在等待该线程结束}}return 0;}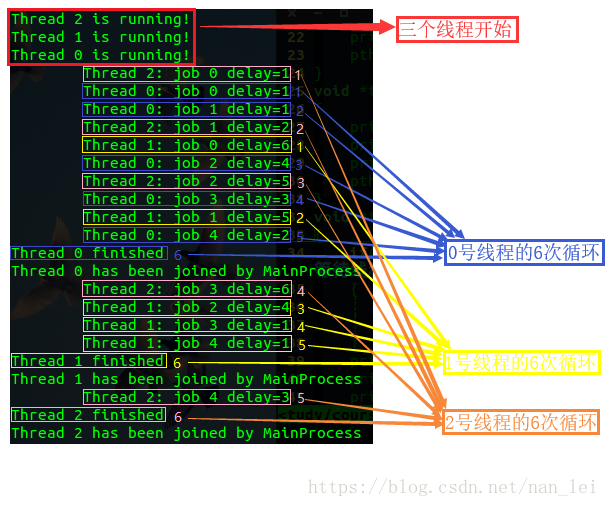
三.线程属性
linux线程属性_小虾米编程-CSDN博客_linux线程属性线程属性本节作为指引性介绍,linux下线程的属性是可以根据实际项目需要,进行设置,之前我们讨论的线程都是采用线程的默认属性,默认属性已经可以解决绝大多数开发时遇到的问题。如我们对程序的性能提出更高的要求那么需要设置线程属性,比如可以通过设置线程栈的大小来降低内存的使用,增加最大线程个数。 typedef struct{ int detachstate; //线程的分离状态 ...https://blog.csdn.net/qq_22847457/article/details/89461222
**在使用或改变线程属性前当然要先创建线程属性对象:
pthread_attr_t pthreadattr;线程属性标识符(pthread_attr_t结构体)简介
这里所指的线程都是用户线程
之前我们讨论的线程都是采用线程的默认属性,默认属性已经可以解决绝大多数开发时遇到的问题。如我们对程序的性能提出更高的要求那么需要设置线程属性,比如可以通过设置线程栈的大小来降低内存的使用,增加最大线程个数。
线程属性标识符:pthread_attr_t 包含在 pthread.h 头文件中。
每个线程的属性 也就是 线程属性标识符:pthread_attr_t 结构体 无法直接赋值设置,必须执行相关的函数进行操作!
typedef struct
{int detachstate; //线程的分离状态int schedpolicy; //线程的调度策略struct sched schedparam;//线程的调度参数int inheritsched; //线程的继承性int scope; //线程的作用域size_t guardsize; //线程栈末尾的警戒缓冲区大小int stackaddr_set; //线程栈的设置void* stackaddr; //线程栈的启始位置size_t stacksize; //线程栈大小
}pthread_attr_t;
在上面我们可以看到,关于这个结构体中的相关参数线程属性及默认值:
| 属性 | 默认值 | 说明 |
|---|---|---|
| contentionscope | PTHREAD_SCOPE_SYSTEM | 进程调度相关,线程只支持在OS范围内竞争CPU资源 |
| Detach state | PTHREAD_CREATE_DETACHED | 可分离状态 |
| Stack address | NULL | 不指定线程开辟的基地址 |
| Stack size | 8196(KB) | 默认线程栈大小为8M |
| Guard size | 0 | 警戒缓冲区 |
| Scheduling priority | 0 | 进程调度相关,优先级为0 |
| Scheduling policy | SCHED_OTHER | 进程调度相关,调度策略为SCHED_OTHER |
| Inherit scheduler | PTHREAD_EXPLICIT_SCHED | 进程调度相关,继承启动进程的调度策略 |
线程属性主要包括如下属性:作用域(scope)、栈尺寸(stack size)、栈地址(stack address)、优先级(priority)、分离的状态(detached state)、调度策略和参数(scheduling policy and parameters)。默认的属性为非绑定、非分离、缺省1M的堆栈、与父进程同样级别的优先级。
一、线程的作用域(scope)
作用域属性描述特定线程将与哪些线程竞争资源。线程可以在两种竞争域内竞争资源:
- 进程域(process scope):与同一进程内的其他线程。
- 系统域(system scope):与系统中的所有线程。一个具有系统域的线程将与整个系统中所有具有系统域的线程按照优先级竞争处理器资源,进行调度。
- Solaris系统,实际上,从 Solaris 9 发行版开始,系统就不再区分这两个范围。
二、线程的绑定状态(binding state)
关于线程的绑定,牵涉到另外一个概念:轻进程(LWP:Light Weight Process)
轻量级进程可以理解为内核线程,它位于用户层和系统层之间。系统对线程资源的分配、对线程的控制是通过轻进程来实现的,一个轻进程可以控制一个或多个线程。
1.非绑定状态:默认状况下,启动多少轻进程、哪些轻进程来控制哪些线程是由系统来控制的,这种状况即称为非绑定的。
2.绑定状态:则顾名思义,即某个线程固定的"绑"在一个轻进程之上。被绑定的线程具有较高的响应速度,这是因为CPU时间片的调度是面向轻进程的,绑定的线程可以保证在需要的时候它总有一个轻进程可用。通过设置被绑定的轻进程的优先级和调度级可以使得绑定的线程满足诸如实时反应之类的要求。
3、线程的分离状态(detached state)
线程的分离状态决定一个线程以什么样的方式来终止自己。
1.非分离状态(可结合状态):线程的默认属性是非分离状态,这种情况下,原有的线程等待创建的线程结束。只有当pthread_join()函数返回时,创建的线程才算终止,才能释放自己占用的系统资源。
2.分离状态:分离线程没有被其他的线程所等待,自己运行结束了,线程也就终止了,马上释放系统资源。应该根据自己的需要,选择适当的分离状态。
线程分离状态的函数是pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate)。第二个参数可选为 PTHREAD_CREATE_DETACHED(分离线程)和 PTHREAD_CREATE_JOINABLE(非分离线程)。
这里要注意的一点是,如果设置一个线程为分离线程,而这个线程运行又非常快,它很可能在pthread_create函数返回之前就终止了,它终止以后就可能将线程号和系统资源移交给其他的线程使用,这样调用pthread_create的线程就得到了错误的线程号。要避免这种情况可以采取一定的同步措施,最简单的方法之一是可以在被创建的线程里调用pthread_cond_timewait函数,让这个线程等待一会儿,留出足够的时间让函数pthread_create返回。设置一段等待时间,是在多线程编程里常用的方法。但是注意不要使用诸如wait()之类的函数,它们是使整个进程睡眠,并不能解决线程同步的问题。
4、线程的优先级(priority)
1.新线程的优先级为默认为0。
2.新线程不继承父线程调度优先级(PTHREAD_EXPLICIT_SCHED)
3.仅当调度策略为实时(即SCHED_RR或SCHED_FIFO)时才有效,并可以在运行时通过pthread_setschedparam()函数来改变,缺省为0
5、线程的栈地址(stack address)
POSIX.1定义了两个常量_POSIX_THREAD_ATTR_STACKADDR 和_POSIX_THREAD_ATTR_STACKSIZE检测系统是否支持栈属性。也可以给sysconf()函数传递_SC_THREAD_ATTR_STACKADDR或 _SC_THREAD_ATTR_STACKSIZE来进行检测。
当进程栈地址空间不够用时,指定新建线程使用由malloc分配的空间作为自己的栈空间。通过pthread_attr_setstackaddr和pthread_attr_getstackaddr两个函数分别设置和获取线程的栈地址。传给pthread_attr_setstackaddr函数的地址是缓冲区的低地址(不一定是栈的开始地址,栈可能从高地址往低地址增长)。
6、线程的栈大小(stack size)
当系统中有很多线程时,可能需要减小每个线程栈的默认大小,防止进程的地址空间不够用。
当线程调用的函数会分配很大的局部变量或者函数调用层次很深时,可能需要增大线程栈的默认大小。
函数pthread_attr_getstacksize和 pthread_attr_setstacksize提供设置。
7、线程的栈保护区大小(stack guard size)
保护区的作用是在线程栈顶留出一段空间,防止栈溢出。当栈指针进入这段保护区时,系统会发出错误,通常是发送信号给线程。
该属性默认值是PAGESIZE大小,该属性被设置时,系统会自动将该属性大小补齐为页大小的整数倍。当改变栈地址属性时,栈保护区大小通常清零。
8、线程的调度策略(schedpolicy)
POSIX标准指定了三种调度策略:先入先出策略 (SCHED_FIFO)、循环策略 (SCHED_RR) 和自定义策略 (SCHED_OTHER)。SCHED_FIFO 是基于队列的调度程序,对于每个优先级都会使用不同的队列。SCHED_RR 与 FIFO 相似,不同的是前者的每个线程都有一个执行时间配额。SCHED_FIFO 和 SCHED_RR 是对 POSIX Realtime 的扩展。SCHED_OTHER 是缺省的调度策略。
1.新线程默认使用 SCHED_OTHER 调度策略。线程一旦开始运行,直到被抢占或者直到线程阻塞或停止为止。
2.SCHED_FIFO:如果调用进程具有有效的用户ID 0,则争用范围为系统 (PTHREAD_SCOPE_SYSTEM) 的先入先出线程属于实时 (RT) 调度类。如果这些线程未被优先级更高的线程抢占,则会继续处理该线程,直到该线程放弃或阻塞为止。对于具有进程争用范围 (PTHREAD_SCOPE_PROCESS)) 的线程或其调用进程没有有效用户 ID 0 的线程,请使用 SCHED_FIFO,SCHED_FIFO 基于 TS 调度类。
3.SCHED_RR:如果调用进程具有有效的用户 ID 0,则争用范围为系统 (PTHREAD_SCOPE_SYSTEM)) 的循环线程属于实时 (RT) 调度类。如果这些线程未被优先级更高的线程抢占,并且这些线程没有放弃或阻塞,则在系统确定的时间段内将一直执行这些线程。对于具有进程争用范围 (PTHREAD_SCOPE_PROCESS) 的线程,请使用 SCHED_RR(基于 TS 调度类)。此外,这些线程的调用进程没有有效的用户 ID 0。
9、线程并行级别(concurrency)
应用程序使用 pthread_setconcurrency() 通知系统其所需的并发级别。
线程属性常用函数
看这篇博客:
linux线程属性_小虾米编程-CSDN博客线程属性本节作为指引性介绍,linux下线程的属性是可以根据实际项目需要,进行设置,之前我们讨论的线程都是采用线程的默认属性,默认属性已经可以解决绝大多数开发时遇到的问题。如我们对程序的性能提出更高的要求那么需要设置线程属性,比如可以通过设置线程栈的大小来降低内存的使用,增加最大线程个数。 typedef struct{ int detachstate; //线程的分离状态 ...https://blog.csdn.net/qq_22847457/article/details/89461222
- 初始化线程属性——int pthread_attr_init(pthread_attr_t *attr); 成功:0;失败:错误号
- 销毁线程属性所占用的资源——int pthread_attr_destroy(pthread_attr_t *attr); 成功: 0;失败:错误号
- 设置线程属性,分离or非分离——int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);
- 获取程属性,分离or非分离——int pthread_attr_getdetachstate(pthread_attr_t *attr, int *detachstate);
参数:
attr:已初始化的线程属性
detachstate: PTHREAD_CREATE_DETACHED(分离线程);
PTHREAD _CREATE_JOINABLE(非分离线程)
- 设置栈位置——int pthread_attr_setstack(pthread_attr_t *attr,void *stackaddr, size_t stacksize);
成功:0;失败:错误号
- 获取栈位置——int pthread_attr_getstack(pthread_attr_t *attr,void **stackaddr, size_t *stacksize);
成功:0;失败:错误号
参数stackaddr是栈的内存单元最低地址,并不一定是的栈的开始,对于一些处理器,栈的地址是从高往低的,那么stackaddr是的栈结尾位置;
参数stacksize是栈的大小;
当然也可以单独获取或者修改栈的大小,而不去修改栈的地址对于大小设置,不能小于PTHREAD_STACK_MINl(需要头文件limits.h),终端下输入ulimit -s命令可查看。
对于遵循POSIX标准的操作系统来说,并不一定要支持线程栈属性,因此必须要检查
- 编译阶段:使用_POSIX_THREAD_ATTR_STACKADDR和_POSIX_ATTR_STACKSIZE符号来检查系统是否支持线程栈属性,如果系统定义了这些符号,就说明它支持相应的线程栈属性。
- 运行阶段:把_SC_THREAD_ATTR_STACKADDR和_SC_THREAD_ATTR_STACKSIZE参数传给sysconf函数,检查系统对线程栈属性的支持情况。
线程属性guardsize控制着线程栈末尾之后用以避免栈溢出的扩展内存的大小。这个属性默认设置为PAGESIZE个字节。可以把guardsize线程属性设为0,从而不允许属性的这种特征行为发生:在这种情况下不会提供警戒缓冲区。同样地,如果对线程属性stackaddr作了修改,系统就会假设我们会自己管理栈,并使警戒栈缓冲区机制无效,等同于把guardsize属性设为0。
#include <pthread.h>int pthread_attr_getguardsize( const pthread_attr_t *restrict attr, size_t *restrict guardsize );int pthread_attr_setguardsize( pthread_attr_t *attr, size_t guardsize );两者的返回值都是:若成功则返回0,否则返回错误编号。如果guardsize线程属性被修改了,操作系统可能把它取为页大小的整数倍。如果线程的栈指针溢出到警戒区域,应用程序就可能通过信号接收到出错信息。
让我们上面提到的几种属性总结一下,请见下表:

改变线程属性一般步骤:
- 定义线程属性变量 pthread_attr_t attr (这是结构体变量)
- 初始化attr, pthread_attr_init(&attr)
- 使用改变线程属性变量 pthread_attr_t attr (结构体)成员的函数
- 使用线程库函数pthread_create()创建用户线程
实现上述步骤 我们创建的线程的线程属性就是我们希望的线程属性了
举个例子:
比如 :改变线程为分离或者非分离
- 定义线程属性变量 pthread_attr_t attr (结构体)
- 初始化attr, pthread_attr_init(&attr)
- 设置线程为分离或非分离 pthread_attr_setdetachstate(&attr,detachstate);
- 创建线程pthread_create(&tid,&attr,thread_fun,NULL); 所有的系统都会支持线程的分离状态属性,
四、线程的同步与互斥
在学习线程的同步和互斥前 要牢记一句话: “互斥保证安全,同步保证合理”
线程安全
『Linux』线程安全_叄拾叄画生-CSDN博客线程安全。常见的线程安全和不安全情况。常见的可重入和不可重入情况。可重入与线程安全的联系和区别。死锁。线程互斥。互斥锁。互斥锁实现原理。线程同步。条件变量。同步与互斥的区别。https://blog.csdn.net/sss_0916/article/details/89813900
1.线程安全中涉及到的概念:
1)
临界资源:多线程中都能访问到的资源
临界区:每个线程内部,访问临界资源的代码,就叫临界区互斥:任何时刻,互斥保证有且只有一个执行流进入临界区,访问临界资源,通常对临界资 源起保护作用。
原子性:不会被任何调度机制打断的操作,该操作只有两个状态,完成和未完成。
2)
线程安全: 多个线程同时操作临界资源而不会出现数据二义性。则认为该程序是线程安全 的。线程不安全:多个线程访问同一块临界资源,导致资源产生二义性的现象。
3)
重入:同一个函数被不同的执行流调用,当前一个流程还没有执行完,就有其他执行流再次 进入,我们称之为重入(重入也就是可以重复进入)。重入发生场景:
- 多个线程同时执行该函数
- 函数自身调用自身
可重入函数:一个函数在重入的情况下,运行结果不会出现任何不同或者任何问题
不可重入函数:反之就是不可重入函数
可重入(reentrant)函数可以由多于一个任务并发使用,而不必担心数据错误。相反, 不可重入(non-reentrant)函数不能由超过一个任务所共享,除非能确保函数的互斥 (或者使用信号量,或者在代码的关键部分禁用中断)。可重入函数可以在任意时刻被中断, 稍后再继续运行,不会丢失数据。可重入函数要么使用本地变量,要么在使用全局变量时 保护自己的数据。
一句话理解互斥: 等我用完厕所,你再用厕所。
什么是互斥?你我早起都要用厕所,谁先抢到谁先用,中途不被打扰。
伪代码如下:
void 抢厕所(void)
{
if (有人在用) 我眯一会;
用厕所;
喂,醒醒,有人要用厕所吗;
}
假设有 A、 B 两人早起抢厕所, A 先行一步占用了; B 慢了一步,于是就眯一会;当 A 用完后叫醒 B, B也就愉快地上厕所了。
在这个过程中, A、 B 是互斥地访问“厕所”,“厕所”被称之为临界资源。我们使用了“休眠-唤醒”的同步机制实现了“临界资源”的“互斥访问”。
总结:互斥锁是为了防止竞争共享资源,只有在持有锁的线程将锁解锁释放后,其它线程才能进行抢锁加锁操作。
常见情况
常见的线程安全情况:
- 每个线程对全局变量或者静态变量只有读取的权限,而没有写入的权限,一般来说这些线程都是安全的。
- 类或者接口对于线程来说都是原子操作。
- 多个线程之间的切换不会导致该接口的执行结果存在二义性。
线程不安全情况:
- 不保护共享变量的函数。
- 函数状态随着被调用,状态发生变化的函数。
- 返回指向静态变量指针的函数。
- 调用线程不安全函数的函数。
常见的可重入情况:
- 不使用全局变量或静态变量。
- 不使用malloc或者new开辟出来的空间。
- 不调用不可重入函数。
- 不返回静态或全局数据,所有数据都有函数的调用者提供。
- 使用本地数据,或者通过制作全局数据的本地拷贝来保护全局数据。
常见的不可重入情况:
- 调用了malloc/free函数,因为malloc函数是用全局链表来管理堆的。
- 调用标准I/O库函数,标准I/O库的很多实现都以不可重入的方式使用全局数据结构。
- 可重入函数体内使用了静态的数据结构。
可重入与线程安全的联系:
- 函数是可重入的,那就是线程安全的。
- 函数是不可重入的,那就不能由多个线程使用,有可能引发线程安全问题。
- 如果一个函数中有全局变量,那么这个函数既不是线程安全也不是可重入。
可重入与线程安全的区别:
- 可重入函数是线程安全函数的一种。
- 线程安全不一定是可重入的,而可重入函数则一定是线程安全的。
- 如果将对临界资源的访问加上锁,则这个函数是线程安全的,但如果这个可重入函数锁还未释放则会产生死锁,因此是不可重入的。
举一个例子:
- 假设现在有两个线程A和B,单核CPU的情况下,此时有一个int类型的全局变量为100,A和B的入口函数都要对这个全局变量进行减一操作。
- 线程A先拿到CPU资源后,对全局变量进行的减一操作并不是原子性操作,也就是意味着,A在执行减一的过程中有可能会被打断。假设A刚刚将全局变量的值读到寄存器当中,就被切换出去了,此时程序计数器保存了下一条执行的指令,上下文信息保存寄存器中的值,这两个东西是用来线程A再次拿到CPU资源后,恢复现场使用的。
- 此时,线程B拿到了CPU资源,对全局变量进行了减一操作,并且将100减为了99,回写到了内存中。
- A再次拥有了CPU资源后,恢复现场,继续往下执行,从寄存器中读到的值仍为100,减完之后为99,回写到内存中为99。
- 上述例子中,线程A和B都对全局变量进行了减一操作,全局变量的值应该变为98,但程序现在实际的结果为99,所以这就导致了线程不安全。
再举个售票的例子:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>// 一共100张票
int tickets = 10;// 售票
void* thr_start(void* arg){while(1){// 还有余票if(tickets > 0){usleep(1000);printf("%s sells ticket: %d\n", arg, tickets);--tickets;}// 票卖光了else{break;}}pthread_exit(0);
}int main(){pthread_t t1, t2, t3, t4;// 创建线程pthread_create(&t1, NULL, thr_start, (void*)"thread 1");pthread_create(&t2, NULL, thr_start, (void*)"thread 2");pthread_create(&t3, NULL, thr_start, (void*)"thread 3");pthread_create(&t4, NULL, thr_start, (void*)"thread 4");// 线程等待pthread_join(t1, NULL);pthread_join(t2, NULL);pthread_join(t3, NULL);pthread_join(t4, NULL);pthread_exit(0);
}
编译运行程序,效果如下:

可以看到结果明显不对,负数票都卖出来了。为什么会出现这种情况呢?
- if条件判断为真以后,代码可以并发的切换到其他线程。
- usleep这个漫长的过程中,可能有多个线程进入该代码段。
- − − t i c k e t s --tickets−−tickets本身不是原子操作。
我们取出tickets部分汇编代码看一下,首先使用下面命令生成汇编文件:
[sss@aliyun thread_safe]$ objdump -d tickets > tickets.objdump
1
看一下− − t i c k e t s的汇编指令:
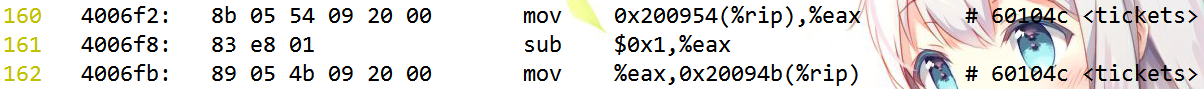
可以看到− − t i c k e t s并不是原子操作,而是通过三条汇编指令完成的:
- 将共享变量tickets从内存加载到寄存器。
- 更新寄存器里面的值,执行− 1 -1−1操作。
- 将新值,从寄存器写回到内存中。
*如何解决线程不安全现象?
解决方案只需做到下述三点即可:
- 代码必须要有互斥的行为: 当一个线程正在临界区中执行时, 不允许其他线程进入该临界区中。
- 如果多个线程同时要求执行临界区的代码, 并且当前临界区并没有线程在执行, 那么只能允许一个线程进入该临界区。
- 如果线程不在临界区中执行, 那么该线程不能阻止其他线程进入临界区。
要做到上面三点 则本质上,我们需要对该临界区加一把锁,Linux上提供的这把锁叫做互斥量。
锁是一个很普遍的需求, 当然用户可以自行实现锁来保护临界区。 但是实现一个正确并且高效的锁非常困难。 纵然抛下高效不谈, 让用户从零开始实现一个正确的锁也并不容易。 正是因为这种需求具有普遍性, 所以Linux提供了互斥量。
牢记这个图!!!!
线程访问临界资源的代码就是临界区!!!

Linux互斥锁(mutex lock)的实现,实际上就是在内核中一把锁维护了一个mutex_lock等待队列和一个引用计数器,当获取锁之前,先对引用计数器减1操作,如果为非负,则可以获取锁进入临界区。否则将该任务设为不可中断状态(uninterruptible),挂在该等待队列上。获取锁的任务从临界区退出后,计数器加1操作,唤醒(wake up)等待队列上的线程。也就是说:如果使用了pthread_mutex_lock()没获取到锁就会进入mutex_lock等待队列
用互斥锁来保护临界区 这样在多个线程执行同一个函数时只要给临界区 在使用时改变互斥索道状态为上锁使用完再改变互斥锁的状态为解锁 就可以实现互斥!
也就是说:线程在访问临界区时要申请锁 但是一般来说一把锁只能被一个线程持有
其他想访问临界区的线程只能等待(或者直接错误返回) 持有锁的线程将互斥锁 的状态改为解锁 这样才能让下一个线程获取到锁
这样下一个线程也就可以访问临界区了
但是这样有一个缺陷 就是如果临界区中的数据需要同时被多个线程读取 而不是修改 互斥锁就会阻碍多线程的数据读取 那怎么办呢 于是就有了读写锁这个概念
**对LInux锁机制的几种锁的操作都是类似的可以类比:
1.定义锁变量和锁属性变量
2.锁属性变量初始化(初始化后为属性为默认值不想用默认值需要接下来用函数修改)
3.锁初始化(创建锁)
4.设置锁状态(上锁或者销毁锁)
互斥量(互斥锁)概念
概念
互斥量(锁)默认为建议性锁

/********************************************************************************************************/
互斥锁(mutex lock)的实现,实际上就是在内核中一把锁维护了一个等待队列-mutex_lock队列和一个引用计数器,当获取锁之前,先对引用计数器减1操作,如果为非负,则可以获取锁进入临界区。否则将该任务设为不可中断状态(uninterruptible),挂在该mutex_lock等待队列上。获取锁的任务从临界区退出后,计数器加1操作,唤醒(wake up)等待队列上的线程。也就是说:如果使用了pthread_mutex_lock()没获取到锁 就会进入mutex_lock等待队列 等待唤醒抢锁
互斥量(锁)就像是锁 有两种状态:已锁定(lock)和未锁定(unlock),在初始化锁后 可以设置上锁和解锁。一般来说,至多只有一个线程可以锁定该互斥量(锁),*我们常将 某线程锁定某互斥量(锁)称为 上锁 或者 获取锁。*
比如:我们多个线程使用pthread_mutex_lock (&mutex,NULL)的含义就是多个线程试图锁定mutex这个互斥量(锁) 但由于我们使用阻塞上锁(pthread_mutex_lock)和默认属性锁(NULL)至多只有一个线程可以锁定该互斥量(锁),所以当一个线程成功锁定mutex这个互斥量(锁)后其他线程进入mutex_lock等待队列阻塞等待 锁定mutex这个互斥量(锁)的线程释放后 等待队列中的线程才会被唤醒 去竞争锁定mutex这个互斥量(锁)
试图对已经锁定的某一互斥量再次加锁,将可能阻塞线程或报错失败,也可能成功,具体取决于加锁的互斥量(锁)属性。
/********************************************************************************************************/
这很好理解,互斥量(锁)就像是我们日常生活使用的一把锁 只有锁上和没锁上两种状态。
互斥量(锁)属性就决定了我们使用的锁是什么锁
1)可能是普通的锁 只能上锁一次,如果其他人也想上锁 只能阻塞等待原来上锁的人解锁后,再上锁,或者干脆不上锁了直接返回错误退出。
2)也可能是一把可叠加的锁,前一个人上锁后就算未解锁,后一个人也可以上锁 这样就上了两个锁。一旦线程锁定(lock)互斥量(锁),随即成为该互斥量(锁)的所有者
搞清楚锁和锁的状态!!!!!
互斥量(锁)mutex是创建了多少个就有多少个的 一个互斥量(锁)同一时间只能被一个线程持有
而pthread_mutex_lock()只是是改变锁的状态为已锁定(也就是调用者申请锁定互斥量(锁))而已 并不是创建互斥量(锁) 不要混乱了!!!
在使用pthread_mutex_init()初始化互斥量(锁)后,互斥量(锁)处于未锁定状态。
可以通过函数改变锁的状态:
pthread_mutex_lock()可以将互斥量(锁)锁定 如果锁正在被其他线程持有 那么就会阻塞等待 持有锁的线程释放锁
pthread_mutex_unlock()可以将互斥量(锁)解锁(将互斥量状态改为未锁定 这样可以让其他 线程持有锁(也就是锁定该互斥量(锁)))LInux锁机制的其他锁都是类似的可以类比
互斥锁实现原理:
- 互斥锁本质就是一个0/1计数器:1表示可以加锁,加锁就是计数器减一,操作完毕之后要解锁。解锁就是计数器加一,并唤醒等待。0表示不可以加锁,不能加锁则等待。
- 经过前面的例子,我们可以知道单纯的i++或++i都不是原子操作,有可能会导致数据二义性问题。
- 为了实现互斥锁操作,大多数体系结构都提供了swap或exchange指令,该指令的作用是把寄存器和内存单元的数据互相交换,由于只有一条指令,保证了原子性。这是后对互斥量的加减就可以转化为交换命令。
互斥锁中的计数器如何保证了原子性?
获取锁资源的时候(加锁):
- 寄存器当中值直接赋值为0
- 将寄存器当中的值和计数器当中的值进行交换
- 判断寄存器当中的值,得出加锁结果
两种情况:
互斥锁公平嘛?
互斥锁是不公平的。
内核维护等待队列, 互斥量实现了大体上的公平; 由于等待线程被唤醒后, 并不自动持有互斥量, 需要和刚进入临界区的线程竞争(抢锁), 所以互斥量并没有做到先来先服务。
linux是如何通过互斥锁(量)来实现对数据的保护和维护的?
我们在之前文件锁中学到过 建议锁和强制锁 先复习一下
1、建议锁又称协同锁。对于这种类型的锁,内核只是提供加减锁以及检测是否加锁的操作,但是不提供锁的控制与协调工作。也就是说,如果应用程序对某个文件进行操作时,没有检测是否加锁或者无视加锁而直接向文件写入数据,内核是不会加以阻拦控制的。因此,建议锁,不能阻止进程对文件的操作,而只能依赖于大家自觉的去检测是否加锁然后约束自己的行为;
2、强制锁,是OS内核的文件锁。每个对文件操作时,例如执行open、read、write等操作时,OS内部检测该文件是否被加了强制锁,如果加锁导致这些文件操作失败。也就是内核强制应用程序来遵守游戏规则;
复习了文件锁的建议锁和强制锁后 就再回过头来看看 互斥量(锁):
这个问题是我要将的重点。很多刚刚接触锁机制的程序员,都会犯这种错误。比如,此时有2个线程,分别是线程A,线程B。A和B共享了资源M。为了同步A和B,使得同一时刻,同意时刻,只有一个线程对M操作。于是,很自然的会在A中对M资源先lock,等到A对M操作完毕之后,然后做一个操作unlock。如果中B线程中不使用锁,在A还没解锁时,B就直接操作M。这个时候,你会发现,B同样可以操作到M。这个是为什么呢?
我们利索当然的把检测锁的任务交给了操作系统,交给了内核。可以翻看APUE上对于所的讲解,其中一部分是这么写的:
This mutual-exclusion mechanism works only if we design our threads to follow the same data-access rules. The operating system doesn't serialize access to data for us. If we allow one thread to access a shared resource without first acquiring a lock, then inconsistencies can occur even though the rest of our threads do acquire the lock before attempting to access the shared resource.
这里This mutual-exclusion mechanism指的就是锁机制。说的很清楚,只有程序员设计线程的时候,都遵循同一种数据访问规则,锁机制才会起作用。操作系统不会为我们序列化数据访问,也就是说,操作系统不会为我们拟定任何数据访问顺序,到底是A在先还是B在先,操作系统不会为我们规定。如果我们允许一个线程在没有多的锁(lock)之前,就对共享数据进行访问操作,那么,即使我们其他的线程都在访问之前试图去先锁住资源(获取锁),同样会导致数据访问不一致,即多个线程同时在操作共享资源。
从上面文字可以看出,操作系统不会为我们去检查,此时是不是有线程已经把资源锁住了。为了使锁能够正常工作,为了保护共享资源,我们只有在设计线程的时候,所有线程都用同一种方法去访问共享数据,也就是访问数据之前,务必先获取锁,然后再操作,操作完之后要解锁(unlock)。操作系统提供锁机制,就是提供了一种所有程序员都必须遵循的规范。而不是说我们锁住资源,其他线程访问共享资源的时候,让操作系统去为我们检查数据是否有其他的线程在操作。
我们在文件IO中的文件锁中学到过 锁是分为 建议性锁 和 强制性锁 的
也就是说 我们一般使用的互斥量(锁)都是 建议性锁 。
所以这也就是为什么 线程在访问临界数据之前,务必先获取锁,然后再操作,操作完之后要解锁(unlock)。否则未执行锁操作的线程可能可以直接访问到临界数据!
举个例子:
pthread_mutex_t mutex;
int num=10;void* pthread1fun(void *arg)
{printf("上锁\n");pthread_mutex_lock(&mutex);num--;printf("%s num=%d\n",arg,num); sleep(10);printf("解锁\n");pthread_mutex_unlock(&mutex);
}
void* pthread2fun(void *arg)
{while (num>=0){num--;printf("%s num=%d\n",arg,num); }
}int main(int argc,char *argv[])
{pthread_t pthread1,pthread2;if(pthread_create(&pthread1,NULL,&pthread1fun,"这是线程1\n")<0){printf("创建线程失败!\n");}else{printf("创建线程成功!\n");}if(pthread_create(&pthread2,NULL,&pthread2fun,"这是线程2\n")<0){printf("创建线程失败!\n");}else{printf("创建线程成功!\n");}pthread_mutex_init(&mutex,NULL);pthread_join(pthread1,NULL);pthread_join(pthread2,NULL);pthread_mutex_destroy(&mutex);return 0;
} 
根据上面结果我们可以看出 线程2直接访问了临界资源num 即使线程1上了锁!!!!!
互斥量(互斥锁)接口
注意:man 3 pthread_mutex_init时提示找不到函数,说明你没有安装pthread相关的man手册。安装方法:1、虚拟机上网;2、sudo apt-get install manpages-posix-dev
互斥量(互斥锁)机制有5个函数:
pthread_mutex_init():初始化互斥锁
pthread_mutex_lock():互斥锁上锁(阻塞)
pthread_mutex_trylock():互斥锁判断上锁(非阻塞)
pthread_mutex_unlock():互斥锁解锁
pthread_mutex_destroy():删除互斥锁
*在使用互斥量(锁)之前,当然先创建一个互斥量(锁)对象:
pthread_mutex_t mutex;1)静态初始化:
功能:初始化互斥量(静态)。
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
2)动态初始化:
注意:使用5个mutex函数时,第一个参数需要指定一个pthread_mutex_t类型的变量mutex,然后使用地址传递获取mutex变量。mutex就是所需创建的互斥量(锁)
例如:
pthread_mutex_t mutex;pthread_mutex_init (&mutex,NULL);功能:初始化互斥量(动态)。
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr);
参数:restrict mutex:指向要初始化的互斥量的指针。restrict attr:指向互斥量属性的指针,互斥量属性相当于互斥锁的类型 下面会讲解,通常置NULL。返回值:成功返回0,失败返回错误码。
//其余4个函数的参数列表与返回值相同,放在一起讲解
功能:销毁互斥量(删除互斥锁)
int pthread_mutex_destroy(pthread_mutex_t *mutex);功能:***阻塞加锁***。(改变锁的状态为已锁定 既上锁不成功就阻塞等待 这是造成死锁的原因之一)
int pthread_mutex_lock(pthread_mutex_t *mutex);功能:***非阻塞加锁***。(改变锁的状态为已锁定 既上锁不成功就失败返回,这是造成活锁的原因之一)
int pthread_mutex_trylock(pthread_mutex_t *mutex);功能:解锁。(改变锁的状态为未锁定)
int pthread_mutex_unlock(pthread_mutex_t *mutex);参数:mutex:要操作的互斥量(互斥锁)。
返回值:成功返回0,失败返回错误码。/*带有超时的互斥锁*/当线程试图获取一个已加锁的互斥量是,pthread_mutex_timedlock互斥量原语允许绑定线程阻塞时间。pthread_mutex_timedlock函数与pthread_mutex_lock是基本等价的,但是在达到超时时间之后,pthread_mutex_timedlock不会对互斥量进行加锁,而是返回错误码ETIMEDOUT。超时指定愿意等待的绝对时间(与相对时间对比而言,指定在时间X之前可以阻塞等待,而不是说愿意则塞Y秒)
#include <pthread.h>
#include <time.h>
int pthread_mutex_timedlock(pthread_mutex_t *restrict mutex,const struct timespec *restrict tsptr);
返回值:若成功,返回0;否则,返回错误编号
我们发现上面的接口并没有选择互斥量(互斥锁)的类型 那我们是只能使用默认的互斥量(互斥锁)属性吗? 当然不是。我们在接下来会讲解
/* 初始化互斥量属性对象 */
int pthread_mutexattr_init (pthread_mutexattr_t *__attr);/* 销毁互斥量属性对象 */
int pthread_mutexattr_destroy (pthread_mutexattr_t *__attr);//获取类型属性
int pthread_mutexattr_gettype(const pthread_mutexattr_t *restrict attr, int *restrict type);
//修改类型属性
int pthread_mutexattr_settype(pthread_mutexattr_t *attr, int type); //返回值:成功,返回0 否则返回错误编号 使用上述接口使用默认互斥量(互斥锁)属性对 线程安全中的售票程序进行改进:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>// 一共100张票
int tickets = 10;// 互斥量
pthread_mutex_t mutex;// 售票
void* thr_start(void* arg){while(1){// 加锁pthread_mutex_lock(&mutex);// 还有余票if(tickets > 0){usleep(1000);printf("%s sells ticket: %d\n", arg, tickets);--tickets;// 解锁pthread_mutex_unlock(&mutex);}// 票卖光了else{// 解锁pthread_mutex_unlock(&mutex);break;}}pthread_exit(0);
}int main(){pthread_t t1, t2, t3, t4;// 初始化互斥量pthread_mutex_init(&mutex, NULL);// 创建线程pthread_create(&t1, NULL, thr_start, (void*)"thread 1");pthread_create(&t2, NULL, thr_start, (void*)"thread 2");pthread_create(&t3, NULL, thr_start, (void*)"thread 3");pthread_create(&t4, NULL, thr_start, (void*)"thread 4");// 线程等待pthread_join(t1, NULL);pthread_join(t2, NULL);pthread_join(t3, NULL);pthread_join(t4, NULL);// 互斥量销毁pthread_mutex_destroy(&mutex);pthread_exit(0);
}
程序编译运行,结果如下:
互斥量(互斥锁)属性
**在修改或使用互斥量(锁)属性前当然要先定义互斥量(锁)属性对象:
pthread_mutexattr_t mutexattr;互斥量(互斥锁)属性就相当于 我们给临界资源上锁的类型
在互斥量(互斥锁)中有两种常用的属性:
1.pshared(进程共享属性):互斥锁属性pshared指定是否允许跨进程共享互斥锁
2.type(类型属性):互斥锁属性type指定互斥量(互斥锁)的类型
pthread_mutexattr_t结构体定义了一套完整的互斥锁属性。线程库提供了一系列函数来操作pthread_mutexattr_t类型的变量,以方便我们获取和设置互斥锁属性。
1.pthread_mutexattr_t
这是是一个结构体类型,其中存放了互斥量的各属性字段。我们就是通过对这个结构体类型变量进行操作来确定互斥量(互斥锁)属性
2.互斥量(互斥锁)属性初始化与反始化
1)对于默认属性:
在对互斥量初始化时(pthread_mutex_t mutex 为互斥量(互斥锁))
1)可以使用PTHREAD_MUTEX_INITIALIZER常量初始化(静态初始化):
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER
2)或在互斥量的初始化函数中的第二个属性参数传递空指针(动态初始化):
pthread_mutex_t mutex ;
pthread_mutex_init(&mutex,NULL)
这样得到互斥量为默认属性。
2)对于非默认属性,可使用如下的函数对pthread_mutexattr_t结构进行初始化和反初始化。初始化后的结构为默认属性,其中每项属性的修改要交给之后介绍的相关函数。互斥锁属性pshared指定是否允许跨进程共享互斥锁,其可选值有两个:
PTHREAD_PROCESS_SHARED。互斥锁可以被跨进程共享。
PTHREAD_PROCESS_PRIVATE。互斥锁只能被和锁的初始化线程隶属于同一个进程的线程共享。
3.互斥量(互斥锁)属性
**在修改或使用互斥量(锁)属性前当然要先定义互斥量(锁)属性对象:
pthread_mutexattr_t mutexattr;a.进程共享属性(pshared)
在POSIX中是可选的,可通过检查是否定义了_POSIX_THREAD_PROCESS_SHARED符号来判断系统是否支持该属性。
多个进程可以把一个内存数据快映射到自己的地址空间中,这个数据块就可以在多个进程间共享,所以就会涉及到同步问题。如果一个在共享数据块中分配的互斥量的进程共享属性设置为PTHREAD_PROCESS_SHARED,则该互斥量就可以用于进程间的同步。
进程共享属性函数:
//获取属性
int pthread_mutexattr_getpshared(const pthread_mutexattr_t *restrict attr, int *restrict pshared);
//修改属性
int pthread_mutexattr_setpshared(pthread_mutexattr_t *attr, int pshared); //返回值:成功,返回0 否则返回错误编号 b.类型属性(type)
互斥锁的类型
- PTHREAD_MUTEX_NORMAL: 最普通的一种互斥锁。 它不具备死锁检测功能, 如线程对自己锁定的互斥量再次加锁, 则会发生死锁。
- PTHREAD_MUTEX_RECURSIVE_NP: 支持递归的一种互斥锁, 该互斥量的内部维护有互斥锁的所有者和一个锁计数器。 当线程第一次取到互斥锁时, 会将锁计数器置1, 后续同一个线程再次执行加锁操作时, 会递增该锁计数器的值。 解锁则递减该锁计数器的值, 直到降至0, 才会真正释放该互斥量, 此时其他线程才能获取到该互斥量。 解锁时, 如果互斥量的所有者不是调用解锁的线程, 则会返回EPERM。
- PTHREAD_MUTEX_ERRORCHECK_NP: 支持死锁检测的互斥锁。 互斥量的内部会记录互斥锁的当前所有者的线程ID(调度域的线程ID) 。 如果互斥量的持有线程再次调用加锁操作, 则会返回EDEADLK。 解锁时, 如果发现调用解锁操作的线程并不是互斥锁的持有者, 则会返回EPERM。
- 自旋锁,这是一种特殊的互斥锁有单独的接口供我们调用 接下来我们会讲解,自旋锁采用了和互斥量完全不同的策略, 自旋锁加锁失败, 并不会让出CPU, 而是不停地尝试加锁, 直到成功为止。 这种机制在临界区非常小且对临界区的争夺并不激烈的场景下, 效果非常好。自旋锁的效果好, 但是副作用也大, 如果使用不当, 自旋锁的持有者迟迟无法释放锁, 那么, 自旋接近于死循环, 会消耗大量的CPU资源, 造成CPU使用率飙高。 因此, 使用自旋锁时, 一定要确保临界区尽可能地小, 不要有系统调用, 不要调用sleep。 使用strcpy/memcpy等函数也需要谨慎判断操作内存的大小, 以及是否会引起缺页中断。
- PTHREAD_MUTEX_ADAPTIVE_NP:自适应锁,首先与自旋锁一样, 持续尝试获取, 但过了一定时间仍然不能申请到锁, 就放弃尝试, 让出CPU并等待。 PTHREAD_MUTEX_ADAPTIVE_NP类型的互斥量, 采用的就是这种机制。
也就是说可以使用同一个mutex上两次锁但是不一定成功要看锁的类型
“不占用时解锁”指一个线程对被另一个线程加锁的互斥量解锁的情况。“已解锁时解锁”是指对一个已经解锁的互斥量解锁的情况。

类型属性函数:
//获取类型属性
int pthread_mutexattr_gettype(const pthread_mutexattr_t *restrict attr, int *restrict type);
//修改类型属性
int pthread_mutexattr_settype(pthread_mutexattr_t *attr, int type); //返回值:成功,返回0 否则返回错误编号 4.互斥量(互斥锁)的属性设置函数
/* 初始化互斥量属性对象 */
int pthread_mutexattr_init (pthread_mutexattr_t *__attr);/* 销毁互斥量属性对象 */
int pthread_mutexattr_destroy (pthread_mutexattr_t *__attr);进程共享属性://获取属性
int pthread_mutexattr_getpshared(const pthread_mutexattr_t *restrict attr, int *restrict pshared);
//修改属性
int pthread_mutexattr_setpshared(pthread_mutexattr_t *attr, int pshared); //返回值:成功,返回0 否则返回错误编号 类型属性://获取类型属性
int pthread_mutexattr_gettype(const pthread_mutexattr_t *restrict attr, int *restrict type);
//修改类型属性
int pthread_mutexattr_settype(pthread_mutexattr_t *attr, int type); //返回值:成功,返回0 否则返回错误编号 互斥量(互斥锁)使用步骤
所以通常如果我们不想使用默认的互斥量(互斥锁)类型属性 一般是以下步骤(进程共享属性也 是类似)
1.定义互斥锁类型 pthread_mutex_t mutex;
定义互斥锁属性 pthread_mutexattr_t mutexattr;
2.初始化互斥锁属性 pthread_mutexattr_init(&mutexattr);
3.设置我们想要的互斥锁的类型 pthread_mutexattr_settype(&mutexattr,type);
4.初始化互斥锁 pthread_mutex_init(&mutex,&mutexattr);
5.上锁 pthread_mutex_lock(&mutex)
6.解锁 pthread_mutex_unlock(&mutex);
7.销毁线程的互斥锁属性 pthread_mutexattr_destroy(&mutexattr);
销毁线程的互斥锁 pthread_mutex_destroy(&mutex);
这种改变属性的步骤都是类似的 线程属性也是一样 一般都是先初始化 再调用函数改变属性
举个例子:下面代码是 使用同一个锁 在未解锁的情况下 再用这个锁上锁
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <pthread.h>
int main(int argc,char* argv[])
{//定义互斥锁类型pthread_mutex_t mutex;//判断是否有参数传来if(argc<2){printf("-usrage:[error|normal|recursive]\r\n");exit(1);}//定义互斥锁属性pthread_mutexattr_t mutexattr;//初始化互斥锁属性pthread_mutexattr_init(&mutexattr);//根据外部的输入设置互斥锁的类型if(!strcmp(argv[1],"error")){pthread_mutexattr_settype(&mutexattr,PTHREAD_MUTEX_ERRORCHECK);}else if(!strcmp(argv[1],"normal")){pthread_mutexattr_settype(&mutexattr,PTHREAD_MUTEX_NORMAL);}else if(!strcmp(argv[1],"recursive")){pthread_mutexattr_settype(&mutexattr,PTHREAD_MUTEX_RECURSIVE);}//初始化互斥锁pthread_mutex_init(&mutex,&mutexattr);//第一次上锁if(pthread_mutex_lock(&mutex)!=0){printf("Lock failure\r\n");}else{printf("Lock success\n");}//第二次上锁if(pthread_mutex_lock(&mutex)!=0){printf("Lock failure\r\n");}else{printf("Lock success\n");}//上几次锁,解几次锁pthread_mutex_unlock(&mutex);pthread_mutex_unlock(&mutex);//销毁线程的互斥锁属性以及互斥锁pthread_mutexattr_destroy(&mutexattr);pthread_mutex_destroy(&mutex);
}为什么初始化互斥量(锁)之后 可以 使用pthread_mutex_lock()两次来判断锁类型 ?这是因为互斥量(锁)mutex是创建了多少个就有多少个的 一个互斥量(锁)同一时间只能被一个线程持有 而pthread_mutex_lock()只是是改变锁的状态为已锁定而已 并不是创建互斥量(锁) 不要混乱了。
从下图的结果来看:
当互斥锁的类型是检错类型时,第一次上锁成功,第二次上锁会失败。
当互斥锁类型是标准类型时,第一次上锁成功,第二次上锁会阻塞。
当互斥锁类型是递归类型时,第一次上锁成功,第二次上锁也会成功。
这是因为PTHREAD_MUTEX_RECURSIVE_NP是支持递归的一种互斥锁
死锁,活锁,饥饿
Linux同步机制 - 基本概念(死锁,活锁,饿死,优先级反转,护航现象)_Run_Feng的博客-CSDN博客一、死锁(deadlock)是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。虽然进程在运行过程中,可能发生死锁,但死锁的发生也必须具备一定的条件,死锁的发生必须具备以下四个必要条件。1)互斥条件:指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。2)请求和保持https://blog.csdn.net/Run_Feng/article/details/109675102
并行编程中的“锁”难题_weixin_34026484的博客-CSDN博客在并行程序中,锁的使用会主要会引发两类难题:一类是诸如死锁、活锁等引起的多线程Bug;另一类是由锁竞争引起的性能瓶颈。本文将介绍并行编程中因为锁引发的这两类难题及其解决方案。1. 用锁来防止数据竞跑在进行并行编程时,我们常常需要使用锁来保护共享变量,以防止多个线程同时对该变量进行更新时产生数据竞跑(Data Race)。所谓数据竞跑,是指当两个(或多个)线程同时对某个共享变量进行操作,且这...https://blog.csdn.net/weixin_34026484/article/details/94543571
1)死锁(deadlock)
1.死锁概念
功能:***阻塞加锁***。(既上锁不成功就阻塞等待 这是造成死锁的原因之一)
int pthread_mutex_lock(pthread_mutex_t *mutex);在使用 pthread_mutex_lock()上锁时 因为这个函数是阻塞上锁 既无法上锁时就阻塞等待,所以不注意容易造成死锁。
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁。

线程1已经成功拿到了互斥量1, 正在申请互斥量2, 而同时在另一个CPU上,线程2已经拿到了互斥量2, 正在申请互斥量1。 彼此占有对方正在申请的互斥量,结局就是谁也没办法拿到想要的互斥量, 于是死锁就发生了。
举个死锁的例子:这是在使用默认(nomal)锁的情况下
查看多个线程堆栈:thread apply all bt
跳转到线程中:t 线程号
查看具体的调用堆栈:f 堆栈号
直接从pid号用gdb调试:gdb attach pid#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/syscall.h>
#define NUMBER 2pthread_mutex_t mutex1;//定义互斥锁
pthread_mutex_t mutex2;void *ThreadWork1(void *arg)
{int *p = (int*)arg;pthread_mutex_lock(&mutex1);sleep(2);pthread_mutex_lock(&mutex2);pthread_mutex_unlock(&mutex2);pthread_mutex_unlock(&mutex1);return NULL;
}void *ThreadWork2(void *arg)
{int *p = (int*)arg;pthread_mutex_lock(&mutex2);sleep(2);pthread_mutex_lock(&mutex1);pthread_mutex_unlock(&mutex1);pthread_mutex_unlock(&mutex2);return NULL;
}
int main()
{pthread_t tid[NUMBER];pthread_mutex_init(&mutex1,NULL);//互斥锁初始化pthread_mutex_init(&mutex2,NULL);//互斥锁初始化int i = 0;int ret = pthread_create(&tid[0],NULL,ThreadWork1,(void*)&i);if(ret != 0){perror("pthread_create");return -1;}ret = pthread_create(&tid[1],NULL,ThreadWork2,(void*)&i);if(ret != 0){perror("pthread_create");return -1;}//pthread_join(tid,NULL);//线程等待//pthread_join(tid,NULL);//线程等待//pthread_detach(tid);//线程分离pthread_join(tid[0],NULL);pthread_join(tid[1],NULL);pthread_mutex_destroy(&mutex1);//销毁互斥锁pthread_mutex_destroy(&mutex2);//销毁互斥锁while(1){printf("i am main work thread\n");sleep(1);}return 0;
}在上述代码中,一定会出现死锁,线程1拿到了互斥锁1,又再去申请线程2的互斥锁2,线程2拿到了互斥锁2又再去申请线程1的互斥锁1。
2.死锁的四个必要条件
1.互斥条件:一个资源只能被一个执行流使用(我操作的时候,别人不能操作。)
2.循环等待条件:若干执行流之间形成一种头尾相接的循环等待资源的关系
3.不剥夺条件:一个执行流已获得的资源,在未使用完之前,不能强行剥夺(我加的锁别人 不能解)
4.请求与保持条件:一个执行流因请求资源而阻塞时,对已获得的资源不会释放
(拿着手里的,请求其他的。其他的请求不到,手里的也不放。)
3.死锁的预防
其实,预防死锁很简单,只需要破坏上述四个条件中的其一即可。但由于互斥条件是非共享资源所必须的,不仅不能改变,还必须加以保证,所以只能改其他三个条件。1. 打破请求与保持条件
采用资源预先分配策略,即进程运行前申请全部资源,满足则运行,不然就等待。
优点:简单易实施
缺点:因为某项资源不满足,线程无法启动,而其他已经满足了的资源也不会得到利用,严重降低了资源的利用率,造成资源浪费。2. 打破不可剥夺条件
当一个线程已经占有了一份资源,再次申请另一份资源时,必须先释放原来占有的资源,等需要的时候再申请3. 打破循环等待条件
实现资源有序分配策略,对所有设备实现分类编号,所有进程只能采用按序号递增的形式申请资源。
4.如何避免死锁?
- 破坏死锁的四个必要条件任意一个
- 加锁顺序一致(按照先后顺序申请互斥锁)
- 避免未释放锁的情况
- 资源一次性分配
a. 加锁顺序一致(按照先后顺序申请互斥锁)
当多个线程需要相同的锁,同时获取,可能会获取到不同的锁,就很容易产生死锁
比如,线程A和线程B都需要锁1和锁2,如果线程A获取到了锁1,同时线程B获取到了锁2,就会死锁。
解决方法:确保所有的线程都必须按照规定的顺序来获取锁。比如,线程B想要获取到锁2,就必须先要获取锁1,这样就不会产生死锁了。b. 加锁时限
在尝试获取锁的时候加一个超时时间,这也就意味着在尝试获取锁的过程中若超过了这个时限该线程则放弃对该锁请求。若一个线程没有在给定的时限内成功获得所有需要的锁,则会进行回退并释放所有已经获得的锁,然后等待一段随机的时间再重试。
c. 银行家算法
我们可以把操作系统看作是银行家,操作系统管理的资源相当于银行家管理的资金,进程向操作系统请求分配资源相当于用户向银行家贷款。为保证资金的安全,银行家规定:
(1) 当一个顾客对资金的最大需求量不超过银行家现有的资金时就可接纳该顾客;
(2) 顾客可以分期贷款,但贷款的总数不能超过最大需求量;
(3) 当银行家现有的资金不能满足顾客尚需的贷款数额时,对顾客的贷款可推迟支付,但总能使顾客在有限的时间里得到贷款;
(4) 当顾客得到所需的全部资金后,一定能在有限的时间里归还所有的资金.操作系统按照银行家制定的规则为进程分配资源,当进程首次申请资源时,要测试该进程对资源的最大需求量,如果系统现存的资源可以满足它的最大需求量则按当前的申请量分配资源,否则就推迟分配。当进程在执行中继续申请资源时,先测试该进程本次申请的资源数是否超过了该资源所剩余的总量。若超过则拒绝分配资源,若能满足则按当前的申请量分配资源,否则也要推迟分配。
d. 死锁检测算法
每当一个线程获得了锁,会在线程和锁相关的数据结构中(map、graph等等)将其记下。除此之外,每当有线程请求锁,也需要记录在这个数据结构中。
当一个线程请求锁失败时,这个线程可以遍历锁的关系图看看是否有死锁发生。例如,线程A请求锁2,但是锁2这个时候被线程B持有,这时线程A就可以检查一下线程B是否已经请求了线程A当前所持有的锁。如果线程B确实有这样的请求,那么就是发生了死锁(线程A拥有锁1,请求锁2;线程B拥有锁2,请求锁1)。
当然,死锁一般要比两个线程互相持有对方的锁这种情况要复杂的多。线程A等待线程B,线程B等待线程C,线程C等待线程D,线程D又在等待线程A。线程A为了检测死锁,它需要递进地检测所有被B请求的锁。从线程B所请求的锁开始,线程A找到了线程C,然后又找到了线程D,发现线程D请求的锁被线程A自己持有着。这是它就知道发生了死锁。
那么该如何解决??
一种可行的方法就是释放所有的锁,简单粗暴;
另一种方法就是逐个终止进程,直到死锁的状态解除。
2)活锁(livelock)
避免死锁的另一种方式是尝试一下,如果取不到锁就返回。但是这样也容易触发活锁
int pthread_mutex_trylock(pthread_mutex_t *mutex);
int pthread_mutex_timedlock(pthread_mutex_t *restrict mutex,const struct timespec *restrict abs_timeout);
这两个函数反映了一种,不行就算了的思想。
trylock不行就回退的思想有可能会引发活锁(live lock) 。
活锁的概念
指事物1可以使用资源,但它让其他事物先使用资源;
事物2可以使用资源,但它也让其他事物先使用资源,于是两者一直谦让,都无法使用资源。
生活中也经常遇到两个人迎面走来, 双方都想给对方让路, 但是让的方向却不协调, 反而互相堵住的情况 。 活锁现象与这种场景有点类似。

线程1首先申请锁mutex_a后, 之后尝试申请mutex_b, 失败以后, 释放mutex_a进入下一轮循环, 同时线程2会因为尝试申请mutex_a失败,而释放mutex_b, 如果两个线程恰好一直保持这种节奏, 就可能在很长的时间内两者都一次次地擦肩而过。 当然这毕竟不是死锁, 终究会有一个线程同时持有两把锁而结束这种情况。 尽管如此, 活锁的确会降低性能。
如何避免活锁?
谦让时,尝试等待一个随机的时间就可以了。“等待一个随机时间”的方案虽然很简单,却非常有效,Raft 这样知名的分布式一致性算法中也用到了它。
例如上面的那个例子,路人甲走左手边发现前面有人,并不是立刻换到右手边,而是等待一个随机的时间后,再换到右手边;同样,路人乙也不是立刻切换路线,也是等待一个随机的时间再切换。由于路人甲和路人乙等待的时间是随机的,所以同时相撞后再次相撞的概率就很低了。
避免活锁的简单方法是采用先来先服务的策略。当多个事务请求封锁同一数据对象时,封锁子系统按请求封锁的先后次序对事务排队,数据对象上的锁一旦释放就批准申请队列中第一个事务获得锁。
3)饥饿(hungry)
饥饿的概念
所谓饥饿,是指如果事务T1封锁了数据R,事务T2又请求封锁R,于是T2等待。T3也请求封锁R,当T1释放了R上的封锁后,系统首先批准了T3的请求,T2仍然等待。然后T4又请求封锁R,当T3释放了R上的封锁之后,系统又批准了T4的请求…T2可能永远等待,这就是饥饿。
如何避免饥饿呢?
下面提供了三种方案
- 保证资源充足
- 公平地分配资源
- 避免持有锁的线程长时间执行
这三个方案中,方案一和方案三的适用场景比较有限,因为很多场景下,资源的稀缺性是没办法解决的,持有锁的线程执行的时间也很难缩短。倒是方案二的适用场景相对来说更多一些。
自旋锁
Linux--自旋锁(介绍及API简介)_一只青木呀-CSDN博客Linux--自旋锁(介绍及API简介)1、概念2、自旋锁的使用2.1、自旋锁 API 函数2.2、自旋锁的死锁情况1、2、2.1、解决方式1、概念何谓自旋锁?它是为实现保护共享资源而提出一种锁机制。其实,自旋锁与互斥锁比较类似,它们都是为了解决对某项资源的互斥使用。无论是互斥锁,还是自旋锁,在任何时刻,最多只能有一个保持者,也就说,在任何时刻最多只能有一个执行单元获得锁。但是两者在调度机制上略有不同。对于互斥锁,如果资源已经被占用,资源申请者只能进入睡眠状态。但是自旋锁不会引起调用者睡眠,如果自旋锁已https://qingmu.blog.csdn.net/article/details/117431191
自旋锁的概念
何谓自旋锁?可以把自旋锁看成是一种特殊的互斥锁 它是为实现保护共享资源而提出一种锁机制。其实,自旋锁与互斥锁比较类似,它们都是为了解决对某项资源的互斥使用。无论是互斥锁,还是自旋锁,在任何时刻,最多只能有一个保持者,也就说,在任何时刻最多只能有一个执行单元获得锁。但是两者在调度机制上略有不同。
1)自旋锁和互斥锁的区别
1)对于互斥锁(pthread_mutex_lock),如果资源已经被占用,资源申请者只能进入睡眠状态。
2)但是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在 那里看是否该自旋锁的保持者已经释放了锁,"自旋"一词就是因此而得名。(也就是说 不进入等待队列 而是一直尝试获取锁)
简单来说:自旋锁如果发现要使用的资源被占用就会一直查询这个资源使用的状态直到这个资源被其他线程释放。
从 实现原理上来讲,互斥锁属于sleep-waiting(睡眠等待)类型的锁。例如在一个双核的机器上有两个线程(线程A和线程B),它们分别运行在Core0和 Core1上。假设线程A想要通过pthread_mutex_lock操作去得到一个临界区的锁,而此时这个锁正被线程B所持有,那么线程A就会被阻塞 (blocking),Core0 会在此时进行上下文切换(Context Switch)将线程A置于等待队列中,此时Core0就可以运行其他的任务(例如另一个线程C)而不必进行忙等待。而自旋锁则不然,它属于busy-waiting(忙等待)类型的锁,如果线程A是使用pthread_spin_lock操作去请求锁,那么线程A就会一直在 Core0上进行忙等待并不停的进行锁请求,直到得到这个锁为止。
2)为什么需要自旋锁?
自旋锁的实现是为了保护一段短小的临界区操作代码,主要是用于在SMP上保护临界区,保证这个临界区的操作是原子的,从而避免并发的竞争冒险。在Linux内核中,自旋锁通常用于包含内核数据结构的操作,你可以看到在许多内核数据结构中都嵌入有spinlock,这些大部分就是用于保证它自身被操作的原子性,在操作这样的结构体时都经历这样的过程:上锁-操作-解锁。如果内核控制路径发现自旋锁“开着”(可以获取),就获取锁并继续自己的执行。相反,如果内核控制路径发现锁由运行在另一个CPU上的内核控制路径“锁着”,就在原地“旋转”,反复执行一条紧凑的循环检测指令,直到锁被释放。 自旋锁是循环检测“忙等”,即等待时内核无事可做(除了浪费时间),进程在CPU上保持运行,所以它保护的临界区必须小,且操作过程必须短。不过,自旋锁通常非常方便,因为很多内核资源只锁1毫秒的时间片段,所以等待自旋锁的释放不会消耗太多CPU的时间。
3)什么时候使用自旋锁?
a、低开销加锁优先使用自旋锁。
b、如果要在中断里面加锁,那么只能使用自旋锁。
c、自旋锁是忙等待锁,等待时不会进入睡眠状态,因此如果临界区的时间很短的话,使用自 旋锁会有更高的效率。
4)自旋锁的缺点
从这里我们可以看到自旋锁的一个缺点:那就等待自旋锁的线程会一直处于自旋状态,这样会浪费处理器时间,降低系统性能,所以自旋锁的持有时间不能太长。所以自旋锁适用于短时期的轻量级加锁。
自旋锁的使用
1.线程库中的自旋锁
在使用自旋锁之前,肯定要先定义一个自旋锁变量,定义方法如下所示:
pthread_spinlock_t spinlock;自旋锁的初始化有两种方式:
静态初始化
pthread_spinclok_t spinlock = SPIN_LOCK_UNLOCKED;自旋锁的宏常量初始化。动态初始化
pthread_spin_init(pthread_spinclok_t * spinlock, int pshared);spinlock是指向自旋锁变量的指针
pshared表示进程共享属性// 声明一个自旋锁变量
pthread_spinlock_t spinlock;// 初始化
pthread_spin_init(&spinlock, int pshared);第一个参数为一个指向一个自旋锁变量的指针第二个参数名为pshared(int类型)。表示的是是否能进程间共享自旋锁。这被称之为Thread Process-Shared Synchronization。互斥量的通过属性也可以把互斥量设置成进程间共享的。pshared有两个枚举值:PTHREAD_PROCESS_PRIVATE:仅同进程下读线程可以使用该自旋锁
PTHREAD_PROCESS_SHARED:不同进程下的线程可以使用该自旋锁// 自旋加锁 (既获取不到锁就一直自旋)
pthread_spin_lock(&spinlock);//非自旋加锁(获取不到锁就返回EBUSY错误)
pthread_spin_trylock(&spinlock);// 解锁
pthread_spin_unlock(&spinlock);// 销毁
pthread_spin_destroy(&spinlock);所有函数的返回值
成功:0
失败:错误编号pthread_spin_init()函数的第二个参数名为pshared(int类型)。表示的是是否能进程间共享自旋锁。这被称之为Thread Process-Shared Synchronization。互斥量的通过属性也可以把互斥量设置成进程间共享的。pshared有两个枚举值:
- PTHREAD_PROCESS_PRIVATE:仅同进程下读线程可以使用该自旋锁(枚举值为0)
- PTHREAD_PROCESS_SHARED:不同进程下的线程可以使用该自旋锁(枚举值为1)
在Linux上的glibc中这两个枚举值分别是0和1(Mac上不是)。所以通常也会看到直接传0的代码。你可能觉得不使用宏,直接用数字硬编码不是一个好习惯。的确,妥妥的Magic Number,但还有一个有趣的事实你需要了解:并不是所有实现都支持自旋锁设置两种pshared。比如[3]:
int pthread_spin_init (pthread_spinlock_t *lock, int pshared) {/* Relaxed MO is fine because this is an initializing store. */atomic_store_relaxed (lock, 0);return0;
}所以直接传0可能也无伤大雅。
2.在Linux内核中的自旋锁
Linux 内核使用结构体 spinlock_t 表示自旋锁,在内核的spinlock_types.h中定义,结构体定义如下所示:
typedef struct spinlock {union {struct raw_spinlock rlock;#ifdef CONFIG_DEBUG_LOCK_ALLOC
# define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map))struct {u8 __padding[LOCK_PADSIZE];struct lockdep_map dep_map;};
#endif};
} spinlock_t;
在使用自旋锁之前,肯定要先定义一个自旋锁变量,定义方法如下所示:
spinlock_t spinlock; //定义自旋锁
定义好自旋锁变量以后就可以使用相应的 API 函数来操作自旋锁。
Linux 内核提供了相应的 API 函数:
1、初始化spin_lock_init(x)该宏用于初始化自旋锁x。自旋锁在真正使用前必须先初始化。该宏用于动态初始化。2、加锁void spin_lock(spinlock_t *lock); 最基本得自旋锁函数,它不失效本地中断。void spin_lock_irqsave(spinlock_t *lock, unsigned long flags);在获得自旋锁之前禁用硬中断(只在本地处理器上),而先前的中断状态保存在flags中void spin_lock_irq(spinlock_t *lock);在获得自旋锁之前禁用硬中断(只在本地处理器上),不保存中断状态void spin_lock_bh(spinlock_t *lock);在获得锁前禁用软中断,保持硬中断打开状态3、解锁spin_unlock(lock);该宏释放自旋锁lock,它与spin_trylock或者spin_lock配对使用。如果spin_trylock返回假,表明 没有获得自旋锁,因此不必使用spin_unlock(lock)释放。spin_unlock_bh(lock)该宏释放自旋锁lock的同一时候,也使能本地的软中断。它与spin_lock_bh配对使用。spin_unlock_irqrestore(lock, flags)该宏释放自旋锁lock的同一时候,使能本地硬件中断并且恢复标志寄存器的值为变量flags保存的值。 它与spin_lock_irqsave配对使用。spin_unlock_irq(lock)该宏释放自旋锁lock的同一时候,也使能本地中断。它与spin_lock_irq配对使用。自旋锁的死锁情况
1、
上表中的自旋锁API函数适用于SMP或支持抢占的单CPU下线程之间的并发访问,也就是用于线程与线程之间,被自旋锁保护的临界区一定不能调用任何能够引起睡眠和阻塞的API 函数,否则的话会可能会导致死锁现象的发生。自旋锁会自动禁止抢占,也就说当线程 A得到锁以后会暂时禁止内核抢占。如果线程 A 在持有锁期间进入了休眠状态,那么线程 A 会自动放弃 CPU 使用权。线程 B 开始运行,线程 B 也想要获取锁,但是此时锁被 A 线程持有,而且内核抢占还被禁止了!线程 B 无法被调度出去,那么线程 A 就无法运行,锁也就无法释放,好了,死锁发生了!
2、
上表中的 API 函数用于线程之间的并发访问,如果此时中断也要插一脚,中断也想访问共享资源,那该怎么办呢?首先可以肯定的是,中断里面可以使用自旋锁,但是在中断里面使用自旋锁的时候,在获取锁之前一定要先禁止本地中断(也就是本 CPU 中断,对于多核 SOC来说会有多个 CPU 核),否则可能导致锁死现象的发生,如下图 所示:

在上图 中,线程 A 先运行,并且获取到了 lock 这个锁,当线程 A 运行 functionA 函数的时候中断发生了,中断抢走了 CPU 使用权。右边的中断服务函数也要获取 lock 这个锁,但是这个锁被线程 A 占有着,中断就会一直自旋,等待锁有效。但是在中断服务函数执行完之前,线程 A 是不可能执行的,线程 A 说“你先放手”,中断说“你先放手”,场面就这么僵持着,死锁发生!
解决方式
获取锁之前关闭本地中断。
使用 spin_lock_irq/spin_unlock_irq 的时候需要用户能够确定加锁之前的中断状态,但实际上内核很庞大,运行也是“千变万化”,我们是很难确定某个时刻的中断状态,因此不推荐使用spin_lock_irq/spin_unlock_irq。建议使用 spin_lock_irqsave/ spin_unlock_irqrestore,因为这一组函数会保存中断状态,在释放锁的时候会恢复中断状态。一般在线程中使用 spin_lock_irqsave/spin_unlock_irqrestore,在中断中使用 spin_lock/spin_unlock,示例代码如下所示:
DEFINE_SPINLOCK(lock) /* 定义并初始化一个锁 *//* 线程 A */void functionA (){unsigned long flags; /* 中断状态 */
spin_lock_irqsave(&lock, flags) /* 获取锁 */
/* 临界区 */
spin_unlock_irqrestore(&lock, flags) /* 释放锁 */
}/* 中断服务函数 */void irq() {
spin_lock(&lock) /* 获取锁 */
/* 临界区 */
spin_unlock(&lock) /* 释放锁 */
}
自旋锁使用注意事项
综合前面关于自旋锁的信息,我们需要在使用自旋锁的时候要注意一下几点:
①、因为在等待自旋锁的时候处于“自旋”状态,因此锁的持有时间不能太长,一定要
短,否则的话会降低系统性能。如果临界区比较大,运行时间比较长的话要选择其他的并发处
理方式
②、自旋锁保护的临界区内不能调用任何可能导致线程休眠的 API 函数,否则的话可能
导致死锁。
③、不能递归申请自旋锁,因为一旦通过递归的方式申请一个你正在持有的锁,那么你就
必须“自旋”,等待锁被释放,然而你正处于“自旋”状态,根本没法释放锁。结果就是自己
把自己锁死了!
④、在编写驱动程序的时候我们必须考虑到驱动的可移植性,因此不管你用的是单核的还
是多核的 SOC,都将其当做多核 SOC 来编写驱动程序
读写锁
1..为什么需要读写锁?
前面我们提到 如果多个线程需要同时读取临界区中的数据 而不修改数据 那么互斥锁就不适合 这个临界区了 于是乎就有了读写锁的概念
有时候,在多线程中,有一些公共数据修改的机会比较少,而读的机会却是非常多的,此公共数据的操作基本都是读,如果每次操作都给此段代码加锁,太浪费时间了而且也很浪费资源,降低程序的效率,因为读操作不会修改数据,只是做一些查询,所以在读的时候不用给此段代码加锁,可以共享的访问,只有涉及到写的时候,互斥的访问就好了
2.读写锁概念
读写锁有三种状态:1.未上锁 2.读锁 3.写锁。读写锁其实还是一种锁,是给一段临界区代码加锁,但是此加锁是在加写锁的时候才会互斥,而在加读锁的时候是可以多线程共享的进行访问临界区的 因此读写锁又叫共享互斥锁
其中 1)读写锁状态为读锁时又叫共享锁
临界区可设置多个读锁,但当临界区有一个读锁存在的时候就不能在临界区设 置写锁。临界区加了读锁就不能 再设置写锁,但仍允许其他线程在临界区再设 置读锁。(也就是当读写锁状态为读锁时允许多个上读锁的线程同时访问操作临界 区)
2)读写锁状态为写锁时又叫互斥锁
写锁一旦加上,只有上锁的线程可以操作,其他线程无论读还是写只有等待写锁 释放后才能执行,故写锁又称互斥锁,写锁与任何锁都必须互斥使用。(也就是 和我们前面学习的互斥锁一样)
总结:
1)当读写锁的状态为写锁时 上锁的线程独占整个临界区,其他线程只能等待。
2)当读写锁的状态为读锁时 多个上读锁的线程对于临界区的是任意访问操作的
3)当临界区被某一线程以读写锁状态为写锁锁定时(上写锁) 就相当于互斥锁锁定临界区
4)当临界区被多个线程以读写锁状态为读锁锁定时 (上读锁)临界区可以被多线程共享访 问
!注意!:当临界区被多个线程以读写锁状态为读锁锁定时 (上读锁)临界区的数据是可以被多线程修改的!!!!!只不过以读写锁状态为读锁锁定 (上读锁)临界区的多个线程一般都是不会修改临界区数据的。而是只读。这也是读写锁存在的意义。
读写锁和我们在文件IO中学习到的文件锁既相似 也有区别(区别在于读锁 文件锁的读锁是让文件上锁位置只读不可写 而读写锁的读锁是让多个上读锁的线程任意访问修改读取临界区的数据 ) 可以类比学习

3.读写锁相关函数
在使用读写锁之前当然要先定义读写锁对象:
pthread_rwlock_t rwlock;1)初始化读写锁
/*定义读写锁变量*/
pthread_rwlock_t rwlock;a.静态初始化:pthread_rwlock_t rwlock = PTHREAD_RWLOCK_INITIALIZER;b.动态初始化:int pthread_rwlock_init(pthread_rwlock_t *rwlock, const pthread_rwlockattr_t *attr); 第二个参数为NULL时则为默认读写锁属性返回值:成功:0,读写锁的状态将成为已初始化和已解锁。失败:非 0 错误码。2)申请读锁
/*阻塞申请读锁*/int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock ); /*非阻塞申请读锁*/int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock); 返回值:成功:0失败:非 0 错误码3)申请写锁
/*阻塞申请写锁*/int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock ); /*非阻塞申请写锁*/int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock); 返回值:成功:0失败:非 0 错误码4)解锁
/*解锁*/
int pthread_rwlock_unlock (pthread_rwlock_t *rwlock); 5)销毁读写锁
int pthread_rdlock_destroy(pthread_rdlock_t * rwlock)4.读写锁属性相关函数
在使用读写锁属性之前当然要先定义读写锁属性对象:
pthread_rwlockattr_t rwlockattr;读写锁属性支持的唯一属性就是进程共享属性,它与互斥量的进程共享属性是相同的
/*定义读写锁变量*/
pthread_rwlockattr_t rwlockattr;/*读写锁属性初始化*/
int pthread_rwlockattr_init(pthread_rwlockattr_t* attr);/*读写锁属性销毁*/
int pthread_rwlockattr_destroy(pthread_rwlockattr_t* attr);//返回值:成功返回0;失败返回错误编码/*设置读写锁的进程共享属性(和互斥锁是一样的)*/
int pthread_rwlockattr_setshared(pthread_rwlockattr_t* attr,int pshared);/*获取读写锁的进程共享属性*/
int pthread_rwlockattr_getshared(const pthread_rwlockattr_t* restrict attr,int* restrict pshared);//返回值:成功返回0;失败返回错误编码5.带有超时属性的读写锁

/*带有超时属性的读写锁*/
#include <pthread.h>
#include <time.h>
int pthread_rwlock_timedrdlock(pthread_rwlock_t * restrict rwlock,const struct timespec *restrict tsptr);
int pthread_rwlock_timedwrlock(pthread_rwlock_t *restrict rwlock,const struct timespec *restrict tsptr);两个函数的返回值:
若成功,返回0;否则,返回错误编号
生产者消费者模型
在学习线程同步之前我们先了解以下生产者消费者模型
基本概念
提到生产者和消费者,我们最有可能想到的是商店卖东西,顾客在货架上(缓冲区)买东西。
生产者消费者问题,其实是一个多线程同步问题的经典案例。该问题描述了两个共享固定大小缓冲区的线程—即所谓的“生产者”和“消费者”–在实际运行时会发生的问题。生产者的主要作用是生成一定量的数据放在缓冲区中,消费者在缓冲区消耗这些数据。但是,要保证生产者不会在缓冲区满时还往缓冲区写数据,消费者也不会在缓冲区为空时读数据。
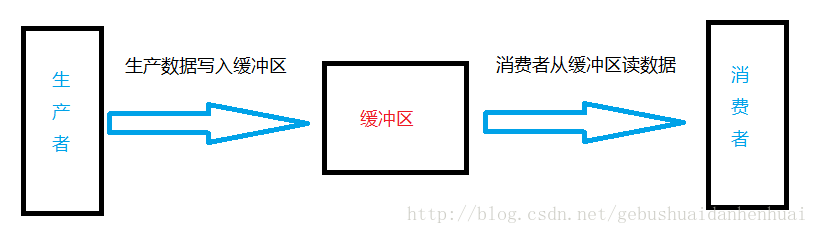

三种关系
- 生产者与消费者之间是供求关系(互斥和同步)
- 生产者与生产者之间是竞争关系(互斥)
- 消费者与消费者之间是竞争关系(互斥)
我们简单解释一下三种关系。假如我们现在在一家超市,我们们想要买一箱牛奶。牛奶生产商(生产者)生产了牛奶,经超市工作人员把牛奶摆放在了货架上,在这个过程过我们(消费者)不能买牛奶,要等待工作人员摆好货物,所以此时生产者与消费者是互斥关系。工作人员摆好货物后,我们(消费者)去购买,此时生产者与消费者是同步关系。
一个货架上只能摆一个品牌的货物,怒能摆其他的,此时生产者与生产者之间是互斥关系。
两个或多个顾客不能同时买一个货物,此时消费者与消费者之间是互斥关系。
为什么需要生产者与消费者模型?
生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生成完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列中取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费解耦的。
生产者消费者模型优点
- 解耦
- 支持高并发
- 支持忙闲不均
线程同步
为什么要线程同步?
因为当我们有多个线程要同时访问一个变量或对象时,如果这些线程中既有读又有写操作时,就会导致变量值或对象的状态出现混乱,从而导致程序异常。举个例子,如果一个银行账户同时被两个线程操作,一个取100块,一个存钱100块。假设账户原本有0块,如果取钱线程和存钱线程同时发生,会出现什么结果呢?取钱不成功,账户余额是100.取钱成功了,账户余额是0.那到底是哪个呢?很难说清楚。因此多线程同步就是要解决这个问题。
为了加深理解,下面举几个例子。
有两个采购员,他们的工作内容是相同的,都是遵循如下的步骤:
(1)到市场上去,寻找并购买有潜力的样品。
(2)回到公司,写报告。
这两个人的工作内容虽然一样,他们都需要购买样品,他们可能买到同样种类的样品,但是他们绝对不会购买到同一件样品,他们之间没有任何共享资源。所以,他们可以各自进行自己的工作,互不干扰。
这两个采购员就相当于两个线程;两个采购员遵循相同的工作步骤,相当于这两个线程执行同一段代码。
下面给这两个采购员增加一个工作步骤。采购员需要根据公司的“布告栏”上面公布的信息,安排自己的工作计划。
这两个采购员有可能同时走到布告栏的前面,同时观看布告栏上的信息。这一点问题都没有。因为布告栏是只读的,这两个采购员谁都不会去修改布告栏上写的信息。
下面增加一个角色。一个办公室行政人员这个时候,也走到了布告栏前面,准备修改布告栏上的信息。
如果行政人员先到达布告栏,并且正在修改布告栏的内容。两个采购员这个时候,恰好也到了。这两个采购员就必须等待行政人员完成修改之后,才能观看修改后的信息。
如果行政人员到达的时候,两个采购员已经在观看布告栏了。那么行政人员需要等待两个采购员把当前信息记录下来之后,才能够写上新的信息。
上述这两种情况,行政人员和采购员对布告栏的访问就需要进行同步。因为其中一个线程(行政人员)修改了共享资源(布告栏)。而且我们可以看到,行政人员的工作流程和采购员的工作流程(执行代码)完全不同,但是由于他们访问了同一份可变共享资源(布告栏),所以他们之间需要同步。
线程同步的方式
条件变量
信号量
条件变量
浅谈条件变量为什么需要和互斥锁配合使用
互斥量(锁)有mutex等待队列 类似的条件变量也有cond_wait等待队列
在Linux 内核中,有两个队列,分别是cond_wait队列和mutex_lock队列, cond_signal只是让线程从cond_wait队列移到mutex_lock队列
互斥量是用于上锁,条件变量用于等待
mutex体现的是一种竞争,我离开了,通知你进来。cond体现的是一种协作,我准备好了,通知你开始吧。
互斥锁一个明显的缺点是它只有两种状态:锁定和非锁定。而条件变量通过允许线程阻塞和等待另一个线程发送信号的方法弥补了互斥锁的不足,它常和互斥锁一起配合使用。使用时,条件变量被用来阻塞一个线程,当条件不满足时,线程往往解开相应的互斥锁并等待条件发生变化。一旦其他的某个线程改变了条件,他将通知相应的条件变量唤醒对应的等待队列中一个或多个正被此条件变量阻塞的线程。这些线程将重新锁定互斥锁并重新测试条件是否满足。一般说来,条件变量被用来进行线程间的同步。
两个线程操作同一临界区时,通过互斥锁保护,若A线程已经加锁,B线程再加锁时候会被阻塞,直到A释放锁,B再获得锁运行,进程B必须不停的主动获得锁、检查条件、释放锁、再获得锁、再检查、再释放,一直到满足运行的条件的时候才可以(而此过程中其他线程一直在等待该线程的结束),这种方式是比较消耗系统的资源的。而条件变量同样是阻塞,还需要通知才能唤醒,线程被唤醒后,它将重新检查判断条件是否满足,如果还不满足,该线程就休眠了,应该仍阻塞在这里,等待条件满足后被唤醒,节省了线程不断运行浪费的资源。这个过程一般用while语句实现。当线程B发现被锁定的变量不满足条件时会自动的释放锁并把自身置于等待状态,让出CPU的控制权给其它线程。其它线程 此时就有机会去进行操作,当修改完成后再通知那些由于条件不满足而陷入等待状态的线程。这是一种通知模型的同步方式,大大的节省了CPU的计算资源,减少了线 程之间的竞争,而且提高了线程之间的系统工作的效率。这种同步方式就是条件变量。
以上说明可能有点抽象,考虑这样的简单场景:通过伪代码说明。
/************************************/
使用条件变量的例子:
A线程从B队列中取元素,B线程往队列中存放元素。不考虑无锁的实现。需要一个mutex用来保护队列的一致性,避免两个线程同时操作队列破坏数据结构。
当队列为空的时候,A需要不断的探测队列状态 :
A:
while(1)
{
if(B队列为空)
{
休 眠 10s
}
else
{
加锁取元素
解锁
}
}
这就有一个问题,可能在刚进入休眠时,B放入元素了,但仍然需要休眠完整个10s的时间。造成不必要的延迟。当然如果不sleep,也可以,但会造成不必要的CPU开销。
使用基于条件变量的事件通知唤醒机制,就可以避免这些问题。
一旦B放入元素完成后就执行pthread_cond_signal(),当前阻塞的线程就会立即被唤醒开始干活儿。
A:
while(1) {
pthread_mutex_lock();
while(B队列为空)
{
pthread_cond_wait(); //B没元素时调用这个函数进入等待队列 等待唤醒
}
取元素;
pthread_mutex_unlock();
}
上面代码在B队列为空的时候第一次调用pthread_cond_wait()(该函数会帮我们解锁互斥锁)后该线程会进入等待队列 当B中有元素之后 改变B元素的线程会调用 pthread_cond_signal()/pthread_cond_boardcast() 会唤醒等待队列中的一个或全部线程 我们假设上面代码在被唤醒之后抢到了锁 就会再次进入 while(B队列为空)的判断 然后发现B有元素了就退出该循环 执行下面的代码 取元素
被唤醒后获得锁 最后不要忘记解锁!
可以看出如果我们轮询判断 “ B队列为空 ”的话可以看出会非常耗费cpu的资源;但是如果我们使用条件变量 我们在B队列为空的时候会在休眠 当B队列非空的时候就会被唤醒执行后续的代码,这样看我们使用条件变量可以很节省CPU的资源
可以看出条件变量就像是一种通知机制,当不满足执行条件时就休眠 等待别人(别的线程)通知;被通知也就是被唤醒且抢到锁后 就再次判断是否满足执行条件 发现此时满足了就往下执行。
就类似于你在煮饭如果使用轮询就是时不时看看饭煮好没 等饭好了就 吃饭(操作临界资源),使用条件变量就是你在睡觉 饭煮好了别人(别的线程)会告诉你 你再去看是不是好了 发现好了就 吃饭(操作临界资源)。
有个问题:为什么条件变量要和锁一起使用 就像上面的伪代码一开始是先获取锁?
这是因为我们上面的代码是临界区的代码 如果B队列非空 我们就回去操作临界资源了 也就是直接执行下面的代码了!所以需要锁!
从这也可以看出为什么条件变量要和锁一起使用了,这是因为通常我们使用条件变量通常会伴随着操作临界资源 就像是我们上面举的例子 被通知去看饭煮好没 发现饭煮好了 通常伴随着吃饭,所以在使用条件变量的时候不要忘记使用锁了!
同时 这也是为什么在 pthread_cond_wait();的内部实现中会解锁 这是因为你饭没煮好你睡觉了 你得把锁给别人用啊 一直占着不用你还休眠了 这不就死锁了吗!
/************************************/
条件变量都用互斥锁进行保护,条件变量状态的改变都应该先锁住互斥锁,pthread_cond_wait()需要传入一个已经加锁的互 斥锁,该函数把调用线程加入等待条件的调用列表中,然后释放互斥锁,在条件满足从而离开pthread_cond_wait()时,mutex 将被重新加锁,这两个函数是原子操作。可以消除条件发生和线程睡眠等待条件发生间的时间间隙。其他线程在获得互斥量之前不会察觉到这种改变,因为必须锁定互斥量才能计算条件。
总而言之,为了避免因条件判断语句与其后的正文或wait语句之间的间隙而产生的漏判或误判,所以用一个mutex来保证: 对于某个cond的包括(判断,修改)在内的任何有关操作某一时刻只有一个线程在访问。也就是说条件变量本身就是一个竞争资源, 这个资源的作用是对其后程序正文的执行权,于是用一个锁来保护。这样就关闭了条件检查和线程进入休眠状态等待条件改变这两个操作之间的时间通道,这样线程就不会有任何变化。
可以总结为:条件变量用于某个线程需要在某种条件成立时才去保护它将要操作的临界区,这种情况从而避免了线程不断轮询检查该条件是否成立而降低效率的情况,这是实现了效率提高。在条件满足时,自动退出阻塞,再加锁进行操作。
以上是关于效率问题,此外互斥锁还有一个缺点就是会造成死锁。
例如线程A和线程B都需要独占使用2个资源,但是他们都分别先占据了一个资源,然后又相互等待另外一个资源的释放,这样就形成了一个死锁。
条件变量起到了阻塞和唤醒线程的作用,所以通常互斥锁要和条件变量配合。
为了解决以上问题,条件变量常和互斥锁一起使用,条件变量通过允许线程阻塞和等待另一个线程发送信号的方法弥补了互斥锁的不足。使用时,条件变量被用来阻塞一个线程,当条件不满足时,线程往往解开相应的互斥锁并等待条件发生变化。一旦其它的某个线程改变了条件变量,它将通知相应的条件变量唤醒一个或多个正被此条件变量阻塞的线程。这些线程将重新锁定互斥锁并重新测试条件是否满足。
条件变量本质
**条件变量本质上是: 条件变量等待队列 + 条件变量等待接口 (pthread_cond_wait)+ 条件变量唤醒接口(pthread_cond_signal/pthread_cond_broadcast ) + 互斥锁等待队列**。
**一个条件变量对应一个条件变量等待队列和锁等待队列**
条件变量是机制,而条件是一个抽象的概念 其实满不满足条件是一个抽象的概念。
条件变量的精妙之处就在于和互斥锁的配合 互斥量是用于上锁,条件变量用于等待
条件变量和普通的互斥锁的区别就在于多了个等待队列和唤醒机制
调用了pthread_cond_wait()就会进入等待队列等待被唤醒
进入等待队列后 只有被唤醒后 抢锁成功 才会返回 否则一直在等待队列中等待
条件变量都是需要和互斥锁一起使用的
可以从这一点理解条件变量的机制
是否满足条件其实是我们自己定义的
举个生产者消费者的例子:
使用条件变量cond1和cond2
a)对于cond1:
1.当资源>0时 生产者线程就没必要再生产了 那这时候生产者线程就应该进入cond1对应的等待队列
2.当资源<=0时 生产者就需要生产 这时就由消费者线程调用cond_signal唤醒cond1对应的等待队列中的一个或全部生产者线程 当某个生产者线程获取到互斥量后将不再阻塞继续生产资源
对于条件变量cond1 资源数<=0就是条件 。
b)对于cond2
1.当资源数<0 时 消费者线程就应该调用wait进入cond2对应的等待队列 。
2.当资源数>0 也就是生产者线程生产了资源后调用cond_signal(&cond2)唤醒cond2对应的等待队列中的消费者线程 ,让消费者消费资源
对于条件变量cond2 所谓条件就是 资源数>0
可以看出cond1对应的是生产者线程的等待队列,cond2对应的是消费者线程的等待队列
至于为什么要分成两个等待队列后面的实战例子会详细讲
为什么需要条件变量?
我们在前面学习了互斥量(锁),那为什么还需要条件变量呢?
我们在前面学习了生产者消费者模型那我们就用这个模型来举个没有条件变量的例子:

所以在上面的生产者消费者模型中使用条件变量就可以节省cpu资源
什么是条件变量?
条件变量是线程间同步的一种方法,是一种机制。要区分条件变量和条件。
在互斥锁中,线程等待flag为0才能进入临界区;信号量中P操作也要等待sem不为0......在多线程中,一个线程等待某个条件是很常见的,互斥锁实现一节中,我们采用自旋来实现,但这效率非常低效,是否有一个更专门、更高效的方式实现条件的等待?
它就是条件变量!条件变量(condition variable)是利用线程间共享的全局变量进行同步的一种机制,主要包括两个动作:一个线程等待某个条件为真,而将自己挂起直到被唤醒;另一个线程设置条件为真,并通知等待的线程继续。
由于某个条件是全局变量,因此条件变量常使用互斥锁以保护(这是必须的,是被强制要求的)。
条件变量与互斥量一起使用时,允许线程以无竞争的方式等待特定的条件发生。
线程可以使用条件变量来等待某个条件为真,注意理解并不是等待条件变量为真,条件变量(cond)是在多线程程序中用来实现 "等待-->唤醒" 逻辑常用的方法,用于维护一个条件(条件与条件变量是不同的概念)。
线程用条件变量用以等待条件成立,并不是说等待条件变量为真或为假,而是利用条件变量去等待某条件。
**条件变量是一个显式的队列,当条件不满足时,线程将自己加入等待队列,同时释放持有的互斥锁;当一个线程改变条件时,可以唤醒一个或多个等待线程(注意此时条件不一定为真)。
在条件变量上有两种基本操作:
- 等待(wait):一个线程处于等待队列中休眠,此时线程不会占用互斥量,当线程被唤醒后,重新获得互斥锁(可能是多个线程竞争),并重新获得互斥量。
- 通知(signal/notify):当条件更改时,另一个线程发送通知以唤醒等待队列中的线程。
如果条件不满足, 它能做的事情就是等待, 等到条件满足为止。 通常条件的达成, 很可能取决于另一个线程, 比如生产者-消费者模型。 当另外一个线程发现条件符合的时候, 它会选择一个时机去通知等待在这个条件上的线程。 有两种可能性:
1) 一种是唤醒一个线程(pthread_cond_signal)
2) 一种是广播, 唤醒其他线程(pthread_cond_broadcast)。
则在这个情况下,需要做到:
- 线程在条件不满足的情况下, 主动让出互斥量, 让其他线程去折腾, 线程在此处等待, 等待条件的满足;
- 一旦条件满足, 线程就可以立刻被唤醒。
- 线程之所以可以安心等待, 依赖的是其他线程的协作, 它确信会有一个线程在发现条件满足以后, 将向它发送信号(这里信号是术语和进程里学的信号不是一回事,可以理解为是通知), 并且让出互斥量。

条件变量相关函数
在使用条件变量前当然要定义条件变量
定义条件变量对象
pthread_cond_t cond;1.条件变量的初始化
1.静态初始化
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;2.动态初始化
pthread_cond_init(pthread_cond_t *cond,const pthread_condattr_t *attr);
参数cond:待初始化的条件变量attr:条件变量的属性(传入NULL为默认属性)
返回值:
成功 0
失败 错误码尽管POSIX标准中为条件变量定义了属性,但在LinuxThreads中没有实现,因此cond_attr值通常为NULL,且被忽略。
2.等待条件
int pthread_cond_wait(pthread_cond_t *restrict cond, pthread_mutex_t *restric mutex);
int pthread_cond_timedwait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex, const struct timespec *restrict timeout);
//成功则返回0, 出错则返回错误编号.pthread_cond_wait()和pthread_cond_timewait()函数只能由拥有互斥量的线程来调用!!!!
这两个函数分别是阻塞等待和超时等待,阻塞等待进入等待队列休眠直到条件修改而被唤醒;超时等待在休眠一定时间后自动醒来。进入等待时线程释放互斥锁,而在被唤醒时线程重新获得锁。
调用 pthread_cond_wait ()会自动解锁互斥量(如同执行了 pthread_unlock_mutex),并等待条件变量触发。这时线程挂起进入等待队列,不占用 CPU 时间,直到条件变量被触发。pthread_cond_wait 函数返回前,自动重新对互斥量加锁(如同执行了 pthread_lock_mutex)。 互斥量的解锁和在条件变量上挂起都是自动进行的
pthread_cond_wait()函数只能由拥有互斥量的线程来调用, 当该函数返回的时候, 系统会确保该线程再次持有互斥量, 所以这个接口容易给人一种误解, 就是该线程一直在持有互斥量。 事实上并不是这样的。 这个接口向系统声明了我在cond_wait等待队列中之后, 就把互斥量给释放了。 这样其他线程就有机会持有互斥量,操作共享数据, 触发变化, 使线程等待的条件得到满足。
也就是说pthread_cond_wait():1)条件不成立则加入cond_wait队列休眠,并释放锁。
2)条件成立后Pthread_cond_wait()返回进入mutex_lock队列且尝试获取锁
*等待条件函数pthread_cond_wait( ) 内部逻辑分析:
我们先来猜测一下pthread_cond_wait( ) 的内部逻辑实现:
实现1:
pthread_mutex_lock(&m)
while(condition_is_false)
{pthread_mutex_unlock(&m);//解锁之后, 等待之前, 可能条件已经满足, 信号已经发出, 但是该信号可能会被错过cond_wait(&cv);//注册等待队列pthread_mutex_lock(&m);
}
上面的解锁和等待不是原子操作。 解锁以后, 调用cond_wait之前,如果已经有其他线程获取到了互斥量, 并且满足了条件, 同时发出了通知信号, 那么cond_wait将错过这个信号, 可能会导致线程永远处于阻塞状态。 所以解锁加等待必须是一个原子性的操作, 以确保已经注册到 事件的等待队列之前, 不会有其他线程可以获得互斥量。
实现2:
那先注册等待事件, 后释放锁不行吗?
注意, 条件等待是个阻塞型的接口, 不单单是注册在事件的等待队列上, 线程也会因此阻塞于此, 从而导致互斥量无法释放, 其他线程获取不到互斥量, 也就无法通过改变共享数据使等待的条件得到满足, 因此这就造成了死锁。
总结:
所以pthread_cond_wait()内部的解锁和注册cond_wait等待队列必须是是原子操作
pthread_cond_wait()使用方法:
pthread_mutex_lock(&m);
while(condition_is_false)
{pthread_cond_wait(&v,&m);//此处会阻塞
}
/*如果代码运行到此处, 则表示我们等待的条件已经满足了,
*并且在此持有了互斥量
*/
/*在满足条件的情况下, 做你想做的事情。
*/
pthread_mutex_unlock(&m);
上面的代码其实很妙 先让线程获取锁 锁保证了 此时此刻只有这个线程访问临界区 如果该线程没达到进入等待队列的条件 也就是需要这个线程干活 也就是不会进入while 直接执行下面的代码 也就是上面的注释说的等待的条件已经满足。
如果该线程进入了等待队列 也就是进入了while 调用了pthread_cond_wait 会自动释放锁 也就是此时不需要该线程工作 就会阻塞等待被唤醒
pthread_cond_wait函数只能由拥有互斥量的线程来调用, 当该函数返回的时候, 系统会确保该线程再次持有互斥量, 所以这个接口容易给人一种误解, 就是该线程一直在持有互斥量。 事实上并不是这样的。 这个接口向系统声明了我在cond_wait等待队列中之后, 就把互斥量给释放了。 这样其他线程就有机会持有互斥量,操作共享数据, 触发变化, 使线程等待的条件得到满足。pthread_cond_wait内部会进行解锁逻辑,则一定要先放到cond_wait等待队列,再进行解锁
**pthread_cond_wait()内部实现逻辑:
- 将调用pthread_cond_wait函数的执行流放入到cond_wait等待队列当中
- 解锁
- 等待被唤醒
- 被唤醒之后:
a) 从cond_wait等待队列中移除出来
b) 抢占互斥锁
情况1:拿到互斥锁,pthread_cond_wait就返回了
情况2:没有拿到互斥锁,阻塞在pthread_cond_wait内部抢锁的逻辑中 当阻塞在pthread_cond_wait函数抢锁逻辑中时,一旦执行流时间耗尽,意味着线程就被切换出来了,程序计数器就保存的是抢锁的指令,上下文 信息保存的就是寄存器的值当再次拥有CPU资源后 恢复抢锁逻辑 直到抢锁成功,pthread_cond_wait函数才会返回
条件变量的虚假唤醒
上面将互斥量和条件变量配合使用的示例代码中有个很有意思的地方,就是用了 while 语句,醒来 之后要再次判断条件是否满足。也就是说当pthread_cond_wait返回后 还会试着while循环一次 当循环条件不满足再退出循环 也就是说会再判断一次条件
while(condition_is_false)
{pthread_cond_wait(&v,&m);//此处会阻塞
}
为什么不写成:
if(condition_is_false)
{pthread_cond_wait(&v,&m);//此处会阻塞
}唤醒以后, 再次检查条件是否满足, 是不是多此一举?
答案是不得不如此。因为可能某次操作系统唤醒 pthread_cond_wait 时condition_is_false可能仍然为 true,言下之意就是操作系统可能会在一些情况下唤醒条件变量,即使没有其他线程向条件变量发送信号,等待此条件变量的线程也有可能会醒来。我们将条件变量的这种行为称之为 虚假唤醒 (spurious wakeup)。因此将条件(判断 condition_is_false为 true)放在一个 while 循环中意味着光唤醒条件变量不行,还必须条件满足程序才能继续执行正常的逻辑。
这看起来这像是个 bug,但它在 Linux 系统中是实实在在存在的。为什么会存在虚假唤醒呢?
1)一个原因是:pthread_cond_wait 是 futex 系统调用,属于阻塞型的系统调用,当系统调用被信号中断的时候,会返回 ﹣1,并且把 errno 错误码置为 EINTR。很多这种系统调用为了防止被信号中断都会重启系统调用(即再次调用一次这个函数),代码如下:
pid_t r_wait(int *stat_loc)
{int retval;//wait 函数因为被信号中断导致调用失败会返回 ﹣1,错误码是 EINTR//注意:这里的 while 循环体是一条空语句while(((retval = wait(stat_loc)) == -1 && (errno == EINTR));return retval;
}但是 pthread_cond_wait 用途有点不一样,假设 pthread_cond_wait 函数被信号中断了,在 pthread_cond_wait 返回之后,到重新调用之前,pthread_cond_signal 或 pthread_cond_broadcast 可能已经调用过。一旦错失,可能由于条件信号不再产生,再次调用 pthread_cond_wait 将导致程序无限制地等待下去。为了避免这种情况,宁可虚假唤醒,也不能再次调用 pthread_cond_wait,以免陷入无穷的等待中。
2)除了上面的信号因素外,还存在以下情况:条件满足了发送信号,但等到调用 pthread_cond_wait 的线程得到 CPU 资源时,条件又再次不满足了。
好在无论是哪种情况,醒来之后再次测试条件是否满足就可以解决虚假等待的问题。这就是使用 while 循环来判断条件,而不是使用 if 语句的原因。
3.唤醒条件
int pthread_cond_signal(pthread_cond_t *cond);
int pthread_cond_broadcast(pthread_cond_t *cond);
//成功则返回0, 出错则返回错误编号.
注意:要先发送信号,再解锁互斥量!!!!!!
这两个函数用于通知线程条件已被修改,调用这两个函数向线程或条件发送信号。
pthread_cond_signal负责唤醒等待在条件变量上的一个线程。(只唤醒等待队列中的一个线程 这样就可以避免竞争)
pthread_cond_broadcast,就是广播唤醒等待在条件变量上的所有线程。(唤醒等待队列所有线程,让等待队列中的所有线程一起竞争锁)
由于pthread_cond_broadcast函数唤醒所有阻塞在某个条件变量上的线程,这些线程被唤醒后将再次竞争相应的互斥锁,所以必须小心使用pthread_cond_broadcast函数。
**pthread_cond_signal的两种写法
1.
lock(&mutex);
//一些操作
pthread_cond_signal(&cond);
//一些操作
unlock(&mutex);
缺点:在某些线程的实现中,会造成等待线程从内核中唤醒(由于cond_signal)回到用户空间,然后pthread_cond_wait返回前需要加锁,但是发现锁没有被释放,又回到内核空间所以一来一回会有性能的问题。
***但是在LinuxThreads或者NPTL里面,就不会有这个问题,因为在Linux 内核中,有两个队列,分别是cond_wait队列和mutex_lock队列, cond_signal只是让线程从cond_wait队列移到mutex_lock队列,而不用返回到用户空间,不会有性能的损耗。所以Linux中这样用没问题***
2.
lock(&mutex);
//一些操作
unlock(&mutex);
pthread_cond_signal(&cond);
优点:不会出现之前说的那个潜在的性能损耗,因为在signal之前就已经释放锁了
缺点:如果unlock之后signal之前,发生进程交换,另一个进程(不是等待条件的进程)拿到这把梦寐以求的锁后加锁操作,那么等最终切换到等待条件的线程时锁被别人拿去还没归还,只能继续等待。
先发送信号,然后解锁互斥量,这个顺序是必须的嘛?
现在再来说这个问题 如果是在Linux中 这个顺序那就是必须了的
先通知条件变量、 后解锁互斥量, 效率会比先解锁、 后通知条件变量低。 因为先通知后解锁, 执行pthread_cond_wait的线程可能在互斥量已然处于加锁状态的时候醒来, 发现互斥量仍然没有解锁, 就会再次休眠, 从而导致了多余的上下文切换。
唤醒丢失问题
在线程未获得相应的互斥锁时调用pthread_cond_signal或pthread_cond_broadcast函数可能会引起唤醒丢失问题。
如果一个条件变量信号条件产生时(调用 pthread_cond_signal 或 pthread_cond_broadcast),没有相关的线程调用 pthread_cond_wait捕获该信号,那么该信号条件就会永久性地丢失了,再次调用pthread_cond_wait 会导致永久性的阻塞。这种情况在设计那些条件变量信号条件只会产生一次的逻辑中尤其需要注意,例如假设现在某个程序有一批等待条件变量的线程,和一个只产生一次条件变量信号的线程。为了让你的等待条件变量的线程能正常运行不阻塞,你的逻辑中,一定要确保等待的线程在产生条件变量信号的线程发送条件信号之前调用 pthread_cond_wait 。
这和生活中的很多例子一样,即许多事情你只有一次机会,必须提前准备好再去尝试这次机会,这个机会不会等待你的准备,一旦错过,就不会再有第二次机会了。
唤醒丢失往往会在下面的情况下发生:
一个线程调用pthread_cond_signal或pthread_cond_broadcast函数;
另一个线程正处在测试条件变量和调用pthread_cond_wait函数之间;
没有线程正在处在阻塞等待的状态下。4.条件变量的销毁
int pthread_cond_destroy(pthread_cond_t *cond);
//成功则返回0, 出错则返回错误编号.注意:
- 永远不要用一个条件变量对另一个条件变量赋值, 即pthread_cond_t cond_b = cond_a不合法, 这种行为是未定义的。
- 使用PTHREAD_COND_INITIALIZE静态初始化的条件变量, 不需要被销毁。
- 要调用pthread_cond_destroy销毁的条件变量可以调用pthread_cond_init重新进行初始化。
- 不要引用已经销毁的条件变量, 这种行为是未定义的。
**条件变量的用法模板与思考
pthread_cond_t cond1; //条件变量
pthread_cond_t cond2;
mutex_t mutex; //互斥锁//A线程
void threadA() {Pthread_mutex_lock(&mutex); //保护临界资源,因为线程会修改全局条件flagwhile(1){while ( !flag1 ){ Pthread_cond_wait(&cond1, &mutex); //flag1不成立则加入队列休眠,并释放锁} //flag1条件成立后也就是被唤醒 Pthread_cond_wait()返回且尝试获取锁 获取成功执行下列代码....dosomthing....flag2这个条件达到了 Pthread_cond_signal(&cond2); //发送信号唤醒cond2对应的等待队列中的线程Pthread_mutex_unlock(&mutex); //放松信号后尽量快速释放锁,因为被唤醒的线程会尝试获得锁}
}//B线程
void threadB() {Pthread_mutex_lock(&mutex); //保护临界资源while(1){while ( !flag2 ){ Pthread_cond_wait(&cond2, &mutex); //flag2不成立则加入队列休眠,并释放锁} //条件成立后也就是被唤醒Pthread_cond_wait()返回且尝试获取锁 获取成功执行下列代码....dosomthing.... flag1这个条件达到了 Pthread_cond_signal(&cond1);//发送信号唤醒cond1对应的等待队列中的线程Pthread_mutex_unlock(&mutex);}
}
一些注意点:
1)通过上面的一个例子,应该很好理解条件变量与条件的区别,条件变量是一个机制,它并不是while循环里的bool语句,我相信很多初学者都有这么一个误区,即条件变量就是线程需要等待的条件。条件是条件,线程等待条件而不是等待条件变量,条件变量使得线程更高效的等待条件成立,是一组等待 — 唤醒 的逻辑机制。
2)注意这里仍然要使用while循环等待条件,你可能会认为明明已经上锁了别的线程无法强入。事实上当线程A陷入等待队列休眠时会释放锁(这是条件函数pthread_cond_wait( ) 的实现原理),而当其被唤醒时,会尝试获得锁,而正在其尝试获得锁时,另一个线程B现在尝试获得锁,并且抢到锁进入临界区,然后修改条件,使得线程A的条件不再成立,线程B返回,此时线程A终于获得锁了,并进入临界区,但此时线程A的条件根本已经不成立,他不该进入临界区!此外,被唤醒也不代表条件成立了,线程陷入休眠时可能会因为超时而返回,这种情况下条件并不会成立
4)此外上述代码线程B下面的代码变为实现了flag 3,并且唤醒线程A,这里线程A的条件根本不符合,所以必须重复判定条件(这是糟糕的情况)。互斥锁和条件变量的例子告诉我们:在等待条件时,总是使用while而不是if!
陷入休眠的线程必须释放锁也是有意义的,如果不释放锁,其他线程根本无法修改条件,休眠的线程永远都不会醒过来!
条件变量实战演练
先举个最简单的例子:下面的代码目的是使用条件变量 让线程2先运行
void *thread_1(void *data)
{pthread_mutex_lock(&lock);pthread_cond_wait(&cond, &lock);printf("%s\n", __func__);pthread_mutex_unlock(&lock);
}void *thread_2(void *data)
{pthread_mutex_lock(&lock);printf("%s\n", __func__);pthread_cond_signal(&cond);pthread_mutex_unlock(&lock);
}
我们再来看看这个例子:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/syscall.h>
#define NUMBER 2int g_bowl = 0;
pthread_mutex_t mutex;//定义互斥锁
pthread_cond_t cond1;//条件变量
pthread_cond_t cond2;//条件变量void *WorkProduct(void *arg)
{int *p = (int*)arg;while(1){pthread_mutex_lock(&mutex);while(*p > 0){pthread_cond_wait(&cond2,&mutex);//条件等待,条件不满足,陷入阻塞}++(*p);printf("i am workproduct :%d,i product %d\n",(int)syscall(SYS_gettid),*p);pthread_cond_signal(&cond1);//通知消费者pthread_mutex_unlock(&mutex);//释放锁}return NULL;
}void *WorkConsume(void *arg)
{int *p = (int*)arg;while(1){pthread_mutex_lock(&mutex);while(*p <= 0){pthread_cond_wait(&cond1,&mutex);//条件等待,条件不满足,陷入阻塞}printf("i am workconsume :%d,i consume %d\n",(int)syscall(SYS_gettid),*p);--(*p);pthread_cond_signal(&cond2);//通知生产者pthread_mutex_unlock(&mutex);//释放锁}return NULL;
}
int main()
{pthread_t cons[NUMBER],prod[NUMBER];pthread_mutex_init(&mutex,NULL);//互斥锁初始化pthread_cond_init(&cond1,NULL);//条件变量初始化pthread_cond_init(&cond2,NULL);//条件变量初始化int i = 0;for(;i < NUMBER;++i){int ret = pthread_create(&prod[i],NULL,WorkProduct,(void*)&g_bowl);if(ret != 0){perror("pthread_create");return -1;}ret = pthread_create(&cons[i],NULL,WorkConsume,(void*)&g_bowl);if(ret != 0){perror("pthread_create");return -1;}}for(i = 0;i < NUMBER;++i){pthread_join(cons[i],NULL);//线程等待pthread_join(prod[i],NULL);}pthread_mutex_destroy(&mutex);//销毁互斥锁pthread_cond_destroy(&cond1);pthread_cond_destroy(&cond2);while(1){printf("i am main work thread\n");sleep(1);}return 0;
}在这里为什么有两个条件变量呢?
我们在之前知道一个条件变量对应一个等待队列
所以采用两个PCB等待序列,一个放生产者,一个放消费者,生产者唤醒消费者,消费者唤醒生产者。不然如果在多个生产者和多个消费者的情况下只使用一个条件变量 这样在这个条件变量的等待队列中同时存在生产者和消费者,这样在使用pthread_cond_signal唤醒等待队列中的一个线程时,生产者和消费者线程都有可能被唤醒 这样就容易出现错误
互斥量和条件变量和信号量
条件变量:同步,一个线程完成了某一个动作就通过条件变量发送信号告诉别的线程,别的线程再进行某些动作。条件变量必须和互斥锁配合使用。
信号量:同步,一个线程完成了某一个动作就通过信号量告诉别的线程,别的线程再进行某些动作。而且信号量有一个更加强大的功能,信号量可以用作为资源计数器,把信号量的值初始化为某个资源当前可用的数量,使用一个之后递减,归还一个之后递增。
条件变量是线程可用的另一种同步机制。互斥量用于上锁,条件变量则用于等待,并且条件变量总是需要与互斥量一起使用,运行线程以无竞争的方式等待特定的条件发生。
条件变量本身是由互斥量保护的,线程在改变条件变量之前必须首先锁住互斥量。其他线程在获得互斥量之前不会察觉到这种变化,因为互斥量必须在锁定之后才能计算条件。
另外还有以下几点需要注意:
1、信号量可以模拟条件变量,因为条件变量和互斥量配合使用,相当于信号量模拟条件变量和互斥量的组合。在生产者消费者线程池中,生产者生产数据后就会发送一个信号 pthread_cond_signal通知消费者线程,消费者线程通过pthread_cond_wait等待到了信号就可以继续执行。这是用条件变量和互斥锁实现生产者消费者线程的同步,用信号量一样可以实现!
2、信号量可以模拟互斥量,因为互斥量只能为加锁或解锁(0 or 1),信号量值可以为非负整数,也就是说,一个互斥量只能用于一个资源的互斥访问,它不能实现多个资源的多线程互斥问题。信号量可以实现多个同类资源的多线程互斥和同步。当信号量为单值信号量时,就完成一个资源的互斥访问。前面说了,信号量主要用做多线程多任务之间的同步,而同步能够控制线程访问的流程,当信号量为单值时,必须有线程释放,其他线程才能获得,同一个时刻只有一个线程在运行(注意,这个运行不一定是访问资源,可能是计算)。如果线程是在访问资源,就相当于实现了对这个资源的互斥访问。
3、互斥锁是为上锁而优化的;条件变量是为等待而优化的; 信号量既可用于上锁,也可用于等待,因此会有更多的开销和更高的复杂性。
4、互斥锁,条件变量都只用于同一个进程的各线程间,而信号量(有名信号量)可用于不同进程间的同步。当信号量用于进程间同步时,要求信号量建立在共享内存区。
5、互斥量必须由同一线程获取以及释放,信号量和条件变量则可以由一个线程释放,另一个线程得到。
6、信号量的递增和减少会被系统自动记住,系统内部的计数器实现信号量,不必担心丢失,而唤醒一个条件变量时,如果没有相应的线程在等待该条件变量,此次唤醒会被丢失。
公交车司机与公交车售票员模型
如下图,公共汽车上,司机和售票员各司其职。司机需要等售票员关好门之后才能启动车,售票员只有等司机停好车后才能开车门,两者必须配合默契,协调一致。

司机售票员问题是一个同步问题。
问题背景:
司机开车,售票员售票。
当售票员将门关上的时候司机才可以开车,
当司机将车到站停下的时候,售票员才可以打开车门。
分析:
此问题属于同步问题还是互斥问题?
同步问题。司机和售票员共享资源——车门,以及车的状态。通过状态传递才能进行下一步的操作。因此是同步问题。
在汽车行驶过程中,司机活动与售票员活动之间的同步关系为:
① 售票员关车门后,向司机发开车信号,司机接到开车信号后启动车辆。② 在汽车正常行驶过程中售票员售票,到站时司机停车,售票员在车停后开车门让乘客上下车。因此司机启动车辆的动作必须与售票员关车门的动作取得同步,售票员开车门的动作也必须与司机停车取得同步。
这个问题可以自己用条件变量和信号量自己试试。
如果是信号量
在本题中,应设置两个信号量:S1、S2。
S1表示是否允许司机启动汽车,初值为0;
S2表示是否允许售票员开门,其初值为0。
用PV操作解题如下:
semaphore Sl=0; //司机启动汽车
semaphore S2=0; //售票员开门
main()
{ cobegindriver();busman();coend
}
driver()
{ while(1) { P(S1); //初始S1=0,P(S1)后S1=-1,司机无法启动车辆,需等待售票员执行关门操作(V(S1)),需售票员关好门,唤醒司机,司机才能启动车辆 启动车辆; 正常行车;到站停车;V(S2); //汽车到站,唤醒售票员开车门}
}
busman()
{while(1){关车门;V(S1); //售票员已关好车门,执行V(S1),唤醒司机启动车辆售票;P(S2); //售票员打开车门,需S2>0时。初始S2=0,售票员不能打开车门,需等司机执行V(S2)操作,唤醒售票员开门,售票员才能打开车门开车门;乘客上下车;}
}
信号量基本概念
1.Linux信号量(semaphore)机制
什么是信号量?
信号量的使用主要是用来保护共享资源。
信号量的值为正的时候,说明它空闲。所测试的线程可以锁定而使用它。若为0,说明 它被占用,测试的线程要进入睡眠队列中,等待被唤醒。
原理:信号量在创建时需要设置一个初始值,表示同时可以有几个任务可以访问该信号量保护的共享资源,初始值为1就变成互斥锁(Mutex),即同时只能有一个任务可以访问信号量保护的共享资源。
一个任务要想访问共享资源,首先必须得到信号量,获取信号量的操作将把信号量的值减1,若当前信号量的值为负数,表明无法获得信号量,该任务必须挂起在该信号量的等待队列等待该信号量可用;若当前信号量的值为非负数,表示可以获得信号量,因而可以立刻访问被该信号量保护的共享资源。
当任务访问完被信号量保护的共享资源后,必须释放信号量,释放信号量通过把信号量的值加1实现,如果信号量的值为非正数,表明有任务等待当前信号量,因此它也唤醒所有等待该信号量的任务。
P操作(通过):对信号量减1,若结果大于等于0,则进程继续,否则(小于0)执行P操作的进程被阻塞等待释放
V操作(释放):对信号量加1,若结果小于等于0,则唤醒队列中一个因为P操作而阻塞的进程,否则不必唤醒进程
//由于Dijkstra教授使用荷兰语,在荷兰语中,“通过”叫“passeren”,“释放”叫“vrijgeven”,PV操作因此得名,这是极少数的在计算机科学中不使用英语表达的例子之一
一般情况下,对于同一信号量,先执行P操作,然后执行V操作。PV操作成对出现。
注意:P、V原语必须成对使用,否则可能会出现死循环。如果出现多个分支,需要认真检查PV操作是否成对。
2. 信号量的分类

在学习进程时的信号量通信之前,我们知道—— Linux提供两种信号量 :
(1) 内核信号量,由内核控制路径使用
(2) 用户态进程使用的信号量 ,这种信号量又分为POSIX信号量和SYSTEM V信号量。
3.POSIX 信号量与SYSTEM V信号量的比较:
1. 对POSIX来说,信号量是个非负整数。常用于线程间同步。而SYSTEM V信号量则是一个或多个信号量的集合,它对应的是一个信号量结构体,这个结构体是为SYSTEM V IPC服务的,信号量只不过是它的一部分。常用于进程间同步。
2.POSIX信号量的引用头文件是“<semaphore.h>”,而SYSTEM V信号量的引用头文件是“<sys/sem.h>”。
3.从使用的角度,System V信号量是复杂的,而Posix信号量是简单。比如,POSIX信号量的创建和初始化或PV操作就很非常方便。在《UNIX网络编程 卷2:进程间通信》的前言第二页与第1版的区别中作者提到“POSIX IPC函数时大势所趋,因为他们比System V中的相应部分更具有优势”所以我们重点学习Posix信号量
| Systm V信号量 | POSIX信号量 |
| semctl() | sem_getvalue() |
| semget() | sem_post() |
| semop() | sem_timedwait() |
| sem_trywait() | |
| sem_wait() | |
| sem_init() //无名信号量 | |
| sem_destroy() //无名信号量 | |
| sem_open() //有名信号量 | |
| sem_close() //有名信号量 | |
| sem_unlink() //有名信号量 | |
其中SYSTEM V信号量在进程通信学过了 很复杂。我们重点学习POSIX信号量
4.POSIX 信号量与SYSTEM V信号量使用上的区别
1、system V的信号量是信号量集,可以包括多个信号灯(有个数组),每个操作可以同时操作多个信号灯。
posix是单个信号灯,POSIX有名信号灯支持进程间通信,无名信号灯放在共享内存中时可以用于进程间通信。
2、POSIX信号量在有些平台并没有被实现,比如:SUSE8,而SYSTEM V大多数LINUX/UNIX都已经实现。两者都可以用于进程和线程间通信。但一般来说:system v信号量用于进程间同步;
POSIX有名信号灯既可用于线程间的同步,又可以用于进程间的同步、posix无名用于同一个进程的不同线程间,如果无名信号量要用于进程间同步,信号量要放在共享内存中。
3、POSIX有两种类型的信号量,有名信号量和无名信号量。有名信号量像system v信号量一样由一个名字标识。
4、POSIX通过sem_open(or sem_init)单一的调用就完成了信号量的创建、初始化和权限的设置,而system v要两步(semget、semctl)。也就是说posix 信号是多线程,多进程安全的,而system v不是,可能会出现问题。
5、system V信号量通过一个int类型的值来标识自己(类似于调用open()返回的fd),而sem_open函数返回sem_t类型(长整形)作为posix信号量的标识值。
6、对于System V信号量你可以控制每次自增或是自减的信号量计数,而在Posix里面,信号量计数每次只能自增或是自减1。
7、Posix无名信号量提供一种非常驻的信号量机制。
8、相关进程: 如果进程是从一已经存在的进程创建,并最终操作这个创建进程的资源,那么这些进程被称为相关的。
5.注意事项
1、Posix有名信号灯的值是随内核持续的。也就是说,一个进程创建了一个信号灯,这个进程结束后,这个信号灯还存在,并且信号灯的值也不会改变。当持有某个信号灯锁的进程没有释放它就终止时,内核并不给该信号灯解锁
2、posix有名信号灯是通过内核持续的,一个进程创建一个信号灯,另外的进程可以通过该信号灯的外部名(创建信号灯使用的文件名)来访问它。posix基于内存的无名信号灯的持续性却是不定的,如果基于内存的信号灯是由单个进程内的各个线程共享的,那么该信号灯就是随进程持续的,当该进程终止时它也会消失。如果某个基于内存的信号灯是在不同进程间同步的,该信号灯必须存放在共享内存区中,这要只要该共享内存区存在,该信号灯就存在。
6.总结
1、System V的信号量一般用于进程同步, 且是内核持续的, api为:semget、semctl、semop
2、Posix的有名信号量一般用于进程同步, 有名信号量是内核持续的. 有名信号量的api为:sem_open、sem_close、sem_unlink
3、Posix的无名信号量一般用于线程同步, 无名信号量可以是进程持续的也可以是内核持续的, 无名信号量的api为:sem_init、sem_destroy
POSIX信号量
进程间通信——POSIX 有名信号量与无名信号量_u014426028的博客-CSDN博客原文地址:blogof33.com/post/9/Systm VPOSIXsemctl()sem_getvalue()semget()sem_post()semop()sem_timedwait()sem_trywait()sem_wait()sem_init() ...https://blog.csdn.net/u014426028/article/details/105628740/
| Systm V信号量 | POSIX信号量 |
| semctl() | sem_getvalue() |
| semget() | sem_post() |
| semop() | sem_timedwait() |
| sem_trywait() | |
| sem_wait() | |
| sem_init() //无名信号量 | |
| sem_destroy() | |
| sem_open() //有名信号量 | |
| sem_close() | |
| sem_unlink() | |
理解信号量
在学习POSIX信号量之前先复习一下信号量概念:
信号量并不用来传送资源,而是用来保护共享资源,理解这一点是很重要的,信号量 s 的表示的含义为同时允许访问资源的最大线程数量,它是一个全局变量。
信号量 s 是具有非负整数值的全局变量,由两种特殊的原子操作来实现,这两种原子操作称为 P 和 V :
- P(s):如果 s 的值大于零,就给它减1,然后立即返回,进程继续执行。;如果它的值为零,就挂起该进程的执行,等待 s 重新变为非零值。
- V(s):V操作将 s 的值加1,如果有任何进程在等在 s 值变为非0,那么V操作会重启这些等待进程中的其中一个(随机地),然后由该进程执行P操作将 s 重新置为0,而其他等待进程将会继续等待。
在进程中也可以使用信号量,对于信号量的理解进程中与线程中并无太大差异,都是用来保护资源
POSIX信号量的基本概念
通过前面的学习 我们知道POSIX信号量分为
1)无名信号量
2)有名信号量
它们的区别和管道及命名管道的区别类似,无名信号量则直接保存在内存中,而有名信号量要求创建一个文件 有名信号量一般保存在/dev/shm/ 目录下。像文件一样存储在文件系统中。
区别:
有名信号量和无名信号量的差异在于创建和销毁的形式上,但是其他工作一样。1)无名信号量只能存在于内存中,要求使用信号量的进程必须能访问信号量所在的这一块内存,所以无名信号量只能应用在:
a) 同一进程内的线程之间(共享进程的内存)
b) 或者不同进程中已经映射相同内存内容到它们的地址空间中的线程(即信号量所在内存被通信的进程共享)。意思是说无名信号量只能通过共享内存访问。
2)相反,有名信号量可以通过名字访问,因此可以被任何知道它们名字的进程中的线程使用。有名信号量以文件的形式存在,即时是不同进程间的线程也可以访问该信号量,因此可以用于不同进程间的多线程间的互斥与同步。单个进程中的线程间使用 POSIX 信号量时,无名信号量更简单。多个进程中的线程间使用 POSIX 信号量时,有名信号量更简单。
相反,有名信号量可以通过名字访问,因此可以被任何知道它们名字的进程中的线程使用。可以简单总结为:
1)无名信号量:常用于同一进程的线程间
2)有名信号量:常用于不同进程的线程间
3)POSIX有名信号量既可用于线程间的同步,又可以用于进程间的同步、posix无名信号量用于同一个进程的不同线程间,如果无名信号量要用于进程间同步,信号量要放在共享内存中。
POSIX信号量持续性
有名信号量是随内核持续的。当有名信号量创建后,即使当前没有进程打开某个信号量它的值依然保持。直到内核重新自举或调用sem_unlink()删除该信号量。
无名信号量的持续性要根据信号量在内存中的位置:
- 如果无名信号量是在单个进程内部的数据空间中,即信号量只能在进程内部的各个线程间共享,那么信号量是随进程的持续性,当进程终止时它也就消失了。
- 如果无名信号量位于不同进程的共享内存区,因此只要该共享内存区仍然存在,该信号量就会一直存在。所以此时无名信号量是随内核的持续性。
POSIX信号量的操作
POSIX信号量有两种:有名信号量和无名信号量,无名信号量也被称作基于内存的信号量。有名信号量通过IPC名字进行进程间的同步,而无名信号量如果不是放在进程间的共享内存区中,是不能用来进行进程间同步的,只能用来进行线程同步。
POSIX信号量有三种操作:
(1)创建一个信号量。创建的过程还要求初始化信号量的值。
根据信号量取值(代表可用资源的数目)的不同,POSIX信号量还可以分为:
a) 二值信号量:信号量的值只有0和1,这和互斥量很类型,若资源被锁住,信号量的值为0,若资源可用,则信号量的值为1;
b) 计数信号量:信号量的值在0到一个大于1的限制值(POSIX指出系统的最大限制值至少要为32767)。该计数表示可用的资源的个数。
(2)等待一个信号量(wait)。该操作会检查信号量的值,如果其值小于或等于0,那就阻塞(也可以使用trywait非阻塞),直到该值变成大于0,然后等待进程将信号量的值减1,进程获得共享资源的访问权限。这整个操作必须是一个原子操作。该操作还经常被称为P操作(荷兰语Proberen,意为:尝试)。(3)挂出一个信号量(post)。该操作将信号量的值加1,如果有进程阻塞着等待该信号量,那么其中一个进程将被唤醒。该操作也必须是一个原子操作。该操作还经常被称为V操作(荷兰语Verhogen,意为:增加)
POSIX信号量函数
POSIX信号量函数它们都声明在头文件 semaphore.h中。
有名信号量和无名信号量的差异在于创建和销毁的形式上,但是其他工作一样;也既PV操作是一样的。
有名信号量和无名信号量通用的函数:
1.wait(P操作)
wait 为信号量值减一操作,总共有三个函数,函数原型如下:
#include <semaphore.h>
int sem_wait(sem_t *sem);
int sem_trywait(sem_t *sem);
int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout);返回值:若成功,返回 0 ;若出错,返回-1
其中,第一个函数的作用是,若 sem 小于 0 ,则线程阻塞于信号量 sem ,直到 sem 大于 0 ;否则信号量值减1。
第二个函数作用与第一个相同,只是此函数不阻塞线程,如果 sem 小于 0,直接返回一个错误(错误设置为 EAGAIN )。
第三个函数作用也与第一个相同,第二个参数表示阻塞时间,如果 sem 小于 0 ,则会阻塞,参数指定阻塞时间长度。 abs_timeout 指向一个结构体,这个结构体由从 1970-01-01 00:00:00 +0000 (UTC) 开始的秒数和纳秒数构成。结构体定义如下:
struct timespec {time_t tv_sec; /* Seconds */long tv_nsec; /* Nanoseconds [0 .. 999999999] */};
复制代码如果指定的阻塞时间到了,但是 sem 仍然小于 0 ,则会返回一个错误 (错误设置为 ETIMEDOUT )。
2.post(V操作)
post 为信号量值加一操作,函数原型如下:
#include <semaphore.h>int sem_post(sem_t *sem);返回值:若成功,返回 0 ;若出错,返回-1注意:信号量的函数中,只有sem_post是信号安全的函数,它是可重入函数
3.获取信号量的值
获取对应的信号量的值 将其放在sval中
int sem_getvalue(sem_t *sem, int *sval);//成功返回0,失败返回-1该函数返回当前信号量的值,通过sval输出参数返回,如果当前信号量已经上锁(即同步对象不可用),那么返回值为0,或为负数,其绝对值就是等待该信号量解锁的线程数。
有名信号量
有名信号量就像有名管道一样 是类似于文件来实现的 有名信号量一般保存在/dev/shm/ 目录下。像文件一样存储在文件系统中。
1.创建有名信号量或打开已有信号量
有名信号量创建或打开可以调用 sem_open 函数,函数说明如下:
sem_t *sem_open(const char *name, int oflag);
sem_t *sem_open(const char *name, int oflag, mode_t mode, unsigned int value); 返回值:若成功,返回指向信号量的指针;若出错,返回SEM_FALLED其中第一种函数是当使用已有的有名信号量时调用该函数,flag 参数设为 0 。
如果要调用第二种函数,flag 参数应设为 O_CREAT ,如果有名信号量不存在,则会创建一个新的,如果存在,则会被使用并且不会再初始化。
当我们使用 O_CREAT 标志时,需要提供两个额外的参数:
mode 参数指定谁可以访问信号量,即权限组,mode 的取值和打开文件的权限位相同,比如
0666表示 所有用户可读写 。因为只有读和写访问要紧,所以实现经常为读和写打开信号量。(要注意这个参数 这会决定有名信号量的访问权限)建议使用0777 就是权限拉满不然可能出现段错误
value 指定信号量的初始值,取值范围为 0~SEM_VALUE_MAX 。
如果信号量存在,则调用第二个函数会忽略后面两个参数(即 mode 和 value )。
该函数返回一个指向创建的有名信号量的指针 既:sme_t * 所以在使用该函数前需要定义一个信号量指针 来指向 我们创建的信号量或者已有的信号量:
sem_t * sem;
2.释放有名信号量
类似于关闭文件
当完成信号量操作以后,可以调用 sem_close 函数来释放任何信号量的资源。函数说明如下:
int sem_close(sem_t *sem);返回值:若成功,返回 0 ;若出错,返回-1如果进程没有调用该函数便退出了,内核会自动关闭任何打开的信号量。无论是调用该函数还是内核自动关闭,都不会改变释放之前的信号量值。
3.销毁有名信号量
类似于删除文件 注意传参传的是 有名信号量名 也就是文件名
可以使用 sem_unlink 函数销毁一个有名信号量。函数说明如下:
int sem_unlink(const char *name);返回值:若成功,返回 0 ;若出错,返回-1sem_unlink 函数会删除信号量的名字。如果没有打开的信号量引用,则该信号量会被销毁,否则,销毁会推迟到最后一个打开的引用关闭时才进行。
**一旦你使用了一信号量,销毁它们就变得很重要。
在做这个之前,要确定所有对这个有名信号量的引用都已经通过sem_close()函数
关闭了,然后只需在退出或是退出处理函数中调用sem_unlink()去删除系统中的信号量,
注意如果有任何的处理器或是线程引用这个信号量,sem_unlink()函数不会起到任何的作
用。
也就是说,必须是最后一个使用该信号量的进程来执行sem_unlick才有效。因为每个
信号灯有一个引用计数器记录当前的打开次数,sem_unlink必须等待这个数为0时才能把
name所指的信号灯从文件系统中删除。也就是要等待最后一个sem_close发生。
无名信号量
sem_init()用于无名信号量的初始化。无名信号量在初始化前一定要在内存中分配一个sem_t信号量类型的对象,这就是无名信号量又称为基于内存的信号量的原因。
既:
sem_t sem;注意不能直接定义一个 sem_t * sem=NULL类型的指针作为 sem_init函数的第一个参数 否则会段错误 这是因为sem_init会对sem解引用 对NULL解引用会段错误 所以
1)直接定义sme_t sem 取sem的地址作为sem_init的第一个参数 既sem_init(&sem,..,..)
2)如果是进程间共享的sem那就让sem_t *sem指向共享地址 既sem_t *sem=shmat()
(其实就是让sem_t *sem指向一个可以解引用的地址)
sem_init()第一个参数是指向一个已经分配的sem_t变量。第二个参数pshared表示该信号量是否由于进程间通步,当pshared = 0,那么表示该信号量只能用于进程内部的线程间的同步。当pshared != 0,表示该信号量存放在共享内存区中,使使用它的进程能够访问该共享内存区进行进程同步。第三个参数value表示信号量的初始值。
这里需要注意的是,无名信号量不使用任何类似O_CREAT的标志,这表示sem_init()总是会初始化信号量的值,也就是说每次使用一次sem_init就会初始化一次该无名信号量,所以对于特定的一个信号量,我们必须保证只调用sem_init()进行初始化一次,对于一个已初始化过的信号量调用sem_init()的行为是未定义的。如果信号量还没有被某个线程调用还好,否则基本上会出现问题。
使用完一个无名信号量后,调用sem_destroy摧毁它。这里要注意的是:摧毁一个有线程阻塞在其上的信号量的行为是未定义的。
1.无名信号量创建
无名信号量可以通过 sem_init 函数创建,函数说明如下:
int sem_init(sem_t *sem, int pshared, unsigned int value);返回值:若成功,返回 0 ;若出错,返回-1
pshared 参数指示该信号量是被一个进程的多个线程共享还是被多个进程共享。
如果 pshared 的值为 0 ,那么信号量将被单进程中的多线程共享,并且应该位于某个地址,该地址对所有线程均可见(例如,全局变量或变量在堆上动态分配)。
如果 pshared 非零,那么信号量将在进程之间共享,并且信号量应该位于共享内存区域(既sem_t* sem=shmat() 这样信号量就位于共享内存了)。
既:1)pshared==0 用于同一进程中的多线程的同步
2)pshared>0 用于多个相关进程的同步(既由fork产生的)
2.无名信号量销毁
如果无名信号量使用完成,可以调用 sem_destory 函数销毁该信号量。函数说明如下:
int sem_destroy(sem_t *sem);返回值:若成功,返回 0 ;若出错,返回-1注意:
销毁其他进程或线程当前被阻塞的信号量会产生未定义的行为。 使用已销毁的信号量会产生未定义的结果,除非使用 sem_init 重新初始化信号量。 一个无名信号量应该在它所在的内存被释放前用 sem_destroy 销毁。如果不这样做,可能会导致某些实现出现资源泄漏。
实战演练:
有名信号量例子:
pthread_t pthreaddirve,pthreadwaiter;
sem_t* namesem;
sem_t* namesem2;void * dirvefun(void *arg)
{while(1){sem_post(namesem2);//对信号量2执行v操作sem_wait(namesem); //对信号量1执行p操作printf("司机开车\n");printf("汽车行驶中.....\n");sleep(2);printf("司机停车\n");sem_post(namesem2);}}void * waiterfun(void *arg)
{while(1){sem_wait(namesem2);//对信号量2执行p操作printf("卖票员关门\n");sem_post(namesem);//对信号量1执行v操作 让司机开车sleep(1);sem_wait(namesem2);printf("卖票员开门\n");}}int main(int argc,char *argv[]){namesem= sem_open("namesem",O_CREAT,0777,0);namesem2= sem_open("namesem2",O_CREAT,0777,0);if(pthread_create(&pthreaddirve,NULL,dirvefun,NULL)<0){printf("创建线程失败!\n");}if(pthread_create(&pthreadwaiter,NULL,waiterfun,NULL)<0){printf("创建线程失败!\n");}pthread_join(pthreaddirve,NULL);pthread_join(pthreadwaiter,NULL);sem_close(namesem);sem_close(namesem2);sem_unlink("namesem");sem_unlink("namesem2");printf("...");}注意信号量初始化函数要在创建线程函数之前 否则会段错误 这是因为创建线程函数会执行线程函数 里面用到信号量 但是此时还没有初始化信号量 所以会段错误 所以要这样
无名信号量例子:
#include "test.h"pthread_t pthreaddirve,pthreadwaiter;
sem_t namesem;
sem_t namesem2;void * dirvefun(void *arg)
{while(1){sem_post(&namesem2);//对信号量2执行v操作sem_wait(&namesem); //对信号量1执行p操作printf("司机开车\n");printf("汽车行驶中.....\n");sleep(2);printf("司机停车\n");sem_post(&namesem2);}}void * waiterfun(void *arg)
{while(1){sem_wait(&namesem2);//对信号量2执行p操作printf("卖票员关门\n");sem_post(&namesem);//对信号量1执行v操作 让司机开车sleep(1);sem_wait(&namesem2);printf("卖票员开门\n");}}int main(int argc,char *argv[]){if( sem_init(&namesem,0,0)==0&&sem_init(&namesem2,0,0)==0){printf("创建无名信号量成功!\n");}else{printf("创建无名信号量失败!\n");}if(pthread_create(&pthreaddirve,NULL,dirvefun,NULL)<0){printf("创建线程失败!\n");}if(pthread_create(&pthreadwaiter,NULL,waiterfun,NULL)<0){printf("创建线程失败!\n");}pthread_join(pthreaddirve,NULL);pthread_join(pthreadwaiter,NULL);sem_destroy(&namesem);sem_destroy(&namesem2);printf("...");}线程常用函数总结
/**********线程创建,控制,删除相关**********/
/*定义用户线程标识符*/
pthread_t thread;/*创建线程函数*/
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine) (void *), void *arg);/*退出线程函数*/
void pthread_exit(void *retval);/*阻塞等待可分离线程退出且回收其资源函数*/
int pthread_join(pthread_t thread, void **thread_result);/*将非分离线程变为分离线程函数*/
int pthread_detach(pthread_t thread);/*线程取消函数*/
int pthread_cancel(pthread_t thread);/**********线程创建,控制,删除相关**********//***************线程属性相关**************/
/*创建线程属性变量*/
pthread_attr_t attr;/*初始化线程属性*/
int pthread_attr_init(pthread_attr_t *attr);
/*销毁线程属性所占用的资源*/
int pthread_attr_destroy(pthread_attr_t *attr); /*设置线程属性,分离or非分离*/
int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);/*获取程属性,分离or非分离*/
int pthread_attr_getdetachstate(pthread_attr_t *attr, int *detachstate);/*设置栈位置*/
int pthread_attr_setstack(pthread_attr_t *attr,void *stackaddr, size_t stacksize); /*获取栈位置*/
int pthread_attr_getstack(pthread_attr_t *attr,void **stackaddr, size_t *stacksize);/***************线程属性相关**************//***********互斥量(互斥锁相关)************/pthread_mutex_t mutex;/*初始化互斥量(静态)*/
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
/*初始化互斥量(动态)*/
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr);
/*销毁互斥量(删除互斥锁)*/
int pthread_mutex_destroy(pthread_mutex_t *mutex);/*阻塞加锁(既上锁不成功就阻塞等待 这是造成死锁的原因之一)*/
int pthread_mutex_lock(pthread_mutex_t *mutex);
/*非阻塞加锁(既上锁不成功就失败返回,这是造成活锁的原因之一)*/
int pthread_mutex_trylock(pthread_mutex_t *mutex);/*带有超时的互斥锁*/
#include <pthread.h>
#include <time.h>
int pthread_mutex_timedlock(pthread_mutex_t *restrict mutex,const struct timespec *restrict tsptr);/*解锁*/
int pthread_mutex_unlock(pthread_mutex_t *mutex);所有函数返回值:
若成功,返回0;
否则,返回错误编号/***********互斥量(互斥锁相关)************//************互斥量属性相关**************/
pthread_mutexattr_t mutexattr;/* 初始化互斥量属性对象 */
int pthread_mutexattr_init (pthread_mutexattr_t *__attr);
/* 销毁互斥量属性对象 */
int pthread_mutexattr_destroy (pthread_mutexattr_t *__attr);/*获取进程共享属性*/
int pthread_mutexattr_getpshared(const pthread_mutexattr_t *restrict attr, int *restrict pshared);
//修改进程共享属性
int pthread_mutexattr_setpshared(pthread_mutexattr_t *attr, int pshared); //返回值:成功,返回0 否则返回错误编号 /*获取类型属性*/
int pthread_mutexattr_gettype(const pthread_mutexattr_t *restrict attr, int *restrict type);
/*修改类型属性 */
int pthread_mutexattr_settype(pthread_mutexattr_t *attr, int type); //返回值:成功,返回0 否则返回错误编号 /***********互斥量(互斥锁相关)************//***********自旋锁相关************/// 声明一个自旋锁变量
pthread_spinlock_t spinlock;// 初始化
int pthread_spin_init(&spinlock, int pshared);第一个参数为一个指向一个自旋锁变量的指针第二个参数名为pshared(int类型)。表示的是是否能进程间共享自旋锁。这被称之为Thread Process-Shared Synchronization。互斥量的通过属性也可以把互斥量设置成进程间共享的。pshared有两个枚举值:PTHREAD_PROCESS_PRIVATE:仅同进程下读线程可以使用该自旋锁
PTHREAD_PROCESS_SHARED:不同进程下的线程可以使用该自旋锁// 自旋加锁 (既获取不到锁就一直自旋)
int pthread_spin_lock(&spinlock);//非自旋加锁(获取不到锁就返回EBUSY错误)
int pthread_spin_trylock(&spinlock);// 解锁
int pthread_spin_unlock(&spinlock);// 销毁
int pthread_spin_destroy(&spinlock);所有函数的返回值
成功:0
失败:错误编号/***********自旋锁相关************//***********读写锁相关************//*定义读写锁变量*/
pthread_rwlock_t rwlock;a.静态初始化:pthread_rwlock_t rwlock = PTHREAD_RWLOCK_INITIALIZER;b.动态初始化:int pthread_rwlock_init(pthread_rwlock_t *rwlock, const pthread_rwlockattr_t *attr); 第二个参数为NULL时则为默认读写锁属性返回值:成功:0,读写锁的状态将成为已初始化和已解锁。失败:非 0 错误码。/*销毁读写锁*/int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);/*阻塞申请读锁*/int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock ); /*非阻塞申请读锁*/int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock); /*阻塞申请写锁*/int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock ); /*非阻塞申请写锁*/int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock); /*带有超时属性的读写锁*/
#include <pthread.h>
#include <time.h>
int pthread_rwlock_timedrdlock(pthread_rwlock_t * restrict rwlock,const struct timespec *restrict tsptr);
int pthread_rwlock_timedwrlock(pthread_rwlock_t *restrict rwlock,const struct timespec *restrict tsptr);/*销毁读写锁(解锁)*/
int pthread_rwlock_unlock (pthread_rwlock_t *rwlock); 全部函数返回值:
成功:0失败:非 0 错误码。/***********读写锁相关************//***********读写锁属性相关************//*定义读写锁变量*/
pthread_rwlockattr_t rwlockattr;/*读写锁属性初始化*/
int pthread_rwlockattr_init(pthread_rwlockattr_t* attr);/*读写锁属性销毁*/
int pthread_rwlockattr_destroy(pthread_rwlockattr_t* attr);/*设置读写锁的进程共享属性(和互斥锁是一样的)*/
int pthread_rwlockattr_setshared(pthread_rwlockattr_t* attr,int pshared);/*获取读写锁的进程共享属性*/
int pthread_rwlockattr_getshared(const pthread_rwlockattr_t* restrict attr,int* restrict pshared);全部函数返回值:
成功:返回0
失败:返回错误编码/***********读写锁属性相关************//****************条件变量*****************/pthread_cond_t cond=PTHREAD_COND_INITIALIZER; int pthread_cond_init(pthread_cond_t *cond, pthread_condattr_t *cond_attr); //成功返回0,失败返回错误码.int pthread_cond_destroy(pthread_cond_t *cond) ;
//成功返回0,失败返回错误码.int pthread_cond_wait(pthread_cond_t *cond,pthread_mutex_t *mutex);
int pthread_cond_timedwait(pthread_cond_t *cond, pthread_mutex_t *mutex,const struct timespec *abstime);
//成功返回0,失败返回错误码.int pthread_cond_signal(pthread_cond_t *cptr);
int pthread_cond_broadcast (pthread_cond_t * cptr);
//成功返回0,失败返回错误码./****************条件变量*****************//********************信号量*******************//*******有名信号量******/sem_t *sem_open(const char *name, int oflag);
sem_t *sem_open(const char *name, int oflag,mode_t mode, unsigned int value);//成功返回信号量指针,失败返回SEM_FAILEDint sem_close(sem_t *sem);
int sem_unlink(const char *name);//成功返回0,失败返回-1/*******有名信号量******//*******无名信号量******/
int sem_init(sem_t *sem, int pshared, unsigned int value);返回值:若成功,返回 0 ;若出错,返回-1
int sem_destroy(sem_t *sem);返回值:若成功,返回 0 ;若出错,返回-1/*******无名信号量******//*******PV操作******/int sem_wait(sem_t *sem);
int sem_trywait(sem_t *sem);
int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout);返回值:若成功,返回 0 ;若出错,返回-1int sem_post(sem_t *sem);返回值:若成功,返回 0 ;若出错,返回-1
/*******PV操作******//********获取信号量的值*******/
获取信号量的值保存在value中
sem_getvalue(sem_t * sem,int* sval);
/********获取信号量的值*******//********************信号量*******************/