云智慧有幸邀请到精硕科技运维总监顾凯先生,为大家带来《从几台到几千台的运维经历》精彩分享。
AdMaster精硕世纪科技(北京)有限公司是领先的营销数据技术公司,利用先进的大数据技术帮助品牌指导营销策略并预先量化营销效果。 AdMaster架起了品牌、广告主与消费者之间的桥梁,是贯穿各行业和领域的数据枢纽。我们与国际、国内超百家媒体及上下游合作伙伴保持长期合作关系,保证了AdMaster作为数据枢纽的多方数据源对接和融合。 通过监测和分析不同行业的品牌在多种平台上的数字营销投放,AdMaster已经建立了行业标准、媒介规划工具,并积累了丰富的实践案例,帮助品牌实现数字营销投资收益的最大化。 AdMaster成立于2006年。发展至今,现已为超过80%的国际、国内品牌提供数据服务,品牌范围覆盖各行各业。我们在北京、上海、广州有2个研发中心和3个办公室。我们的竞争优势来源于技术的不断创新,并拥有多项研发专利技术,技术研发人才占公司总人数的一半。 我们是AdMaster,用数据科技创造快乐世界!。
入职AdMaster五年多,经历了公司从几十台到几千台服务器的飞速增加阶段,目前AdMaster每天增长量数据量超过5T,每天请求数超过100亿,每天计算超过1000亿条记录,每天计算任务数超过10万个,1000亿记录的秒级查询,100万级的QPS。
多年以来一直以稳定运行为前提,确保业务永不掉线,带领运维团队自主开发了运维系统,包含,资产管理,工单管理,监控系统,域名管理,公有云管理,私有云管理等平台,并将运维数据进行分析整理,将运维工作透明化,可视化。
这次主要给大家介绍一下从几十台到几千台服务器的运维过程中,监控系统的变迁经历。常说一千个人心中有一千个哈姆雷特,一千个运维的心中有一千种运维的方法,没有一个方法是万能的、可以适用所有的场景,具体问题还得具体分析,我将这五年的经历大致分了三个阶段:
第一阶段:200台以下
第二阶段:200~1000台
第三阶段:1000+(1000以上和2000以上没啥区别了)
每个阶段的分界点也不是那么精确的,就是一个大概的时期,变化都是一个逐渐的过程。
一、 机器数量小于200台的阶段
这个时期需求简单,主要用于通知问题、快速定位解决问题,大致总结一下,主要需求就三点:
1. 简单,易用;
2. 稳定运行;
3. 能够报警,邮件,短信。
基于以上需求,可以使用比较流行开源的监控软件Nagios,Cacti,Zabbix,Ganglia,etc。流行的开源产品有较多的文档,可快速上手,并且有大量的前人使用经验,可以避免许多问题,即使遇到问题也容易找到解决办法。其中邮件报警一般是都支持的,短信需要自己对接一下短信平台。
我们在早期的时候选择了Nagios和Cacti,选择Nagios主要是个人原因,我最熟悉,使用Cacti是因为对交换机的监控特别方便,几乎是傻瓜式的。其实在这个阶段,不管是哪一个监控产品,基本都可以满足需求,选择的因素还是看个人喜好,这个时期运维同学是可以偶尔任性一下的。
二、机器数量200到1000的阶段
这个时期,需求开始变得复杂,不过主要还是用于通知、告警,避免同样的问题再次发生,我在这个时期主要做了以下事情:
1. 统一监控内容:将基础监控进行统一,默认每个机器都包含CPU,内存,磁盘空间等基础信息监控;
2. 覆盖式监控:将所有机器均纳入监控,除去基础监控以外,最重要的当属业务监控,尽可能的覆盖业务流程,通过自定义监控减少和去除重复的问题,保障业务稳定运行。
3. 及时通知,确保无漏报:将所有监控分类,根据重要程度、紧急程度等,分别用邮件,微信,短信,电话等不同级别的方式通知,确保每个监控都有人处理,并且对于重要的业务采用call死你的方式,不处理就一直通知。
在这个时期对Nagios进行了深入的研究,编写自定义脚本、大量增加各种监控项,将Nagios大部分的插件如nrpe、nsca和功能充分使用。
随着机器越来越多,需要监控的服务也越来越多,告警信息出现爆发式增长,每天收到上千封报警邮件。有个小插曲,我应该是第一个将腾讯企业邮箱撑爆的人,不是容量撑爆了,是邮件的数量超过了他们数据库的最大值,导致我在一周内没办法收发邮件,也没办法删除。
这个阶段的后期,也就是快接近1000台机器的时候,Nagios的监控功能已经无法满足需求了,并且Nagios图形功能总是捉襟见肘,于是开始思考超过1000台的情况了,摆在面前的路有两条:
1. 根据自己的需求继续深度开发Nagios;
2. 自建监控。
这时候有些朋友会想:换一个别的开源监控就能解决了。使用开源软件的最大问题就是,这个软件有什么功能你才能用什么功能,没有的功能要么自己开发,要么放弃使用,大量报警只是一个改变的转折点,经过长时间的使用和积累,通用的、普适的开源监控产品已经不能完全满足庞大复杂的需求了。
经过很长一段时间的慎重考虑,我决定自己搞一套监控系统,其实也是因为之前深入了解Nagios的整体架构和运作模式,觉得自己做一套也不是不可能的。
三、机器数量超过1000台的阶段
经过前期的思索和准备,到这个阶段开始开发自己的监控系统,解决痛点,完成需求,主要有几个事情:
1. 具备目前在用的Nagios所有功能:比照Nagios去做,覆盖原来的功能,并针对Nagios的问题进行优化改进,然后在替代了Nagios之后再升级。(第一步最重要了,如果连之前的Nagios的功能都不能替代,自建之路只能在这里就停下了。)
2. 将告警进行整理,化繁为简,减少重复告警:当出现轰炸式告警信息之后,如果不进行及时整理势必会将真正需要处理的事情耽误,并且由于某些原因,比如线路问题,会发生重复告警,所以必需要将告警信息进行处理再发出,预警信息由之前的每天3000+,下降到现在每天300以内。
3. 分离告警和显示:前面的监控系统,基本上告警功能和显示功能均在一起,不同机房的信息也需要汇总在中心节点后统一显示和告警。重要的告警的处理是分秒必争的,也跟界面显示无关,所以我在设计的时候将显示和告警功能进行了一次分离,在本地机房进行报警,然后再集中展示。
4. 分布式部署,避免单点:每个机房设置一个分节点,就是上面说的报警节点,设置一个中心节点,先在各个机房告警,然后汇总在中心展示。分节点与中心节点互备,通过智能DNS进行切换,如中心节点宕机,DNS自动切换到一个分中心节点,分节点升级为中心节点。
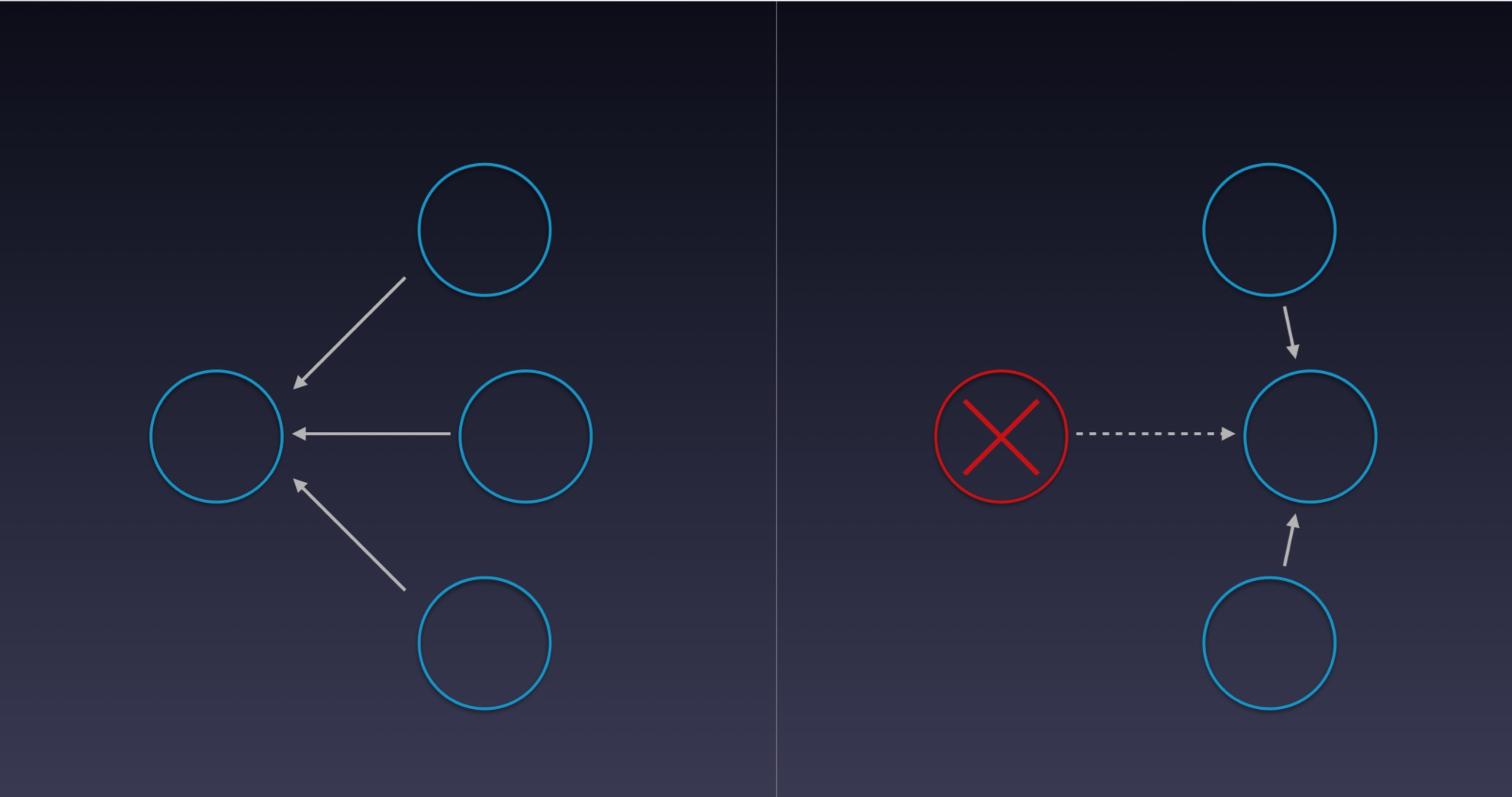
分布式节点切换示意图
总结
自建监控系统的好处就是可以充分利用数据、组合数据、分析数据、解释数据,将晦涩难懂的数据解读成人人能懂的数据,让产品人员、销售人员、老板统统明白当前的业务状态是怎么样的。最后给大家展示两个我们自建监控系统中分析后展示的数据:
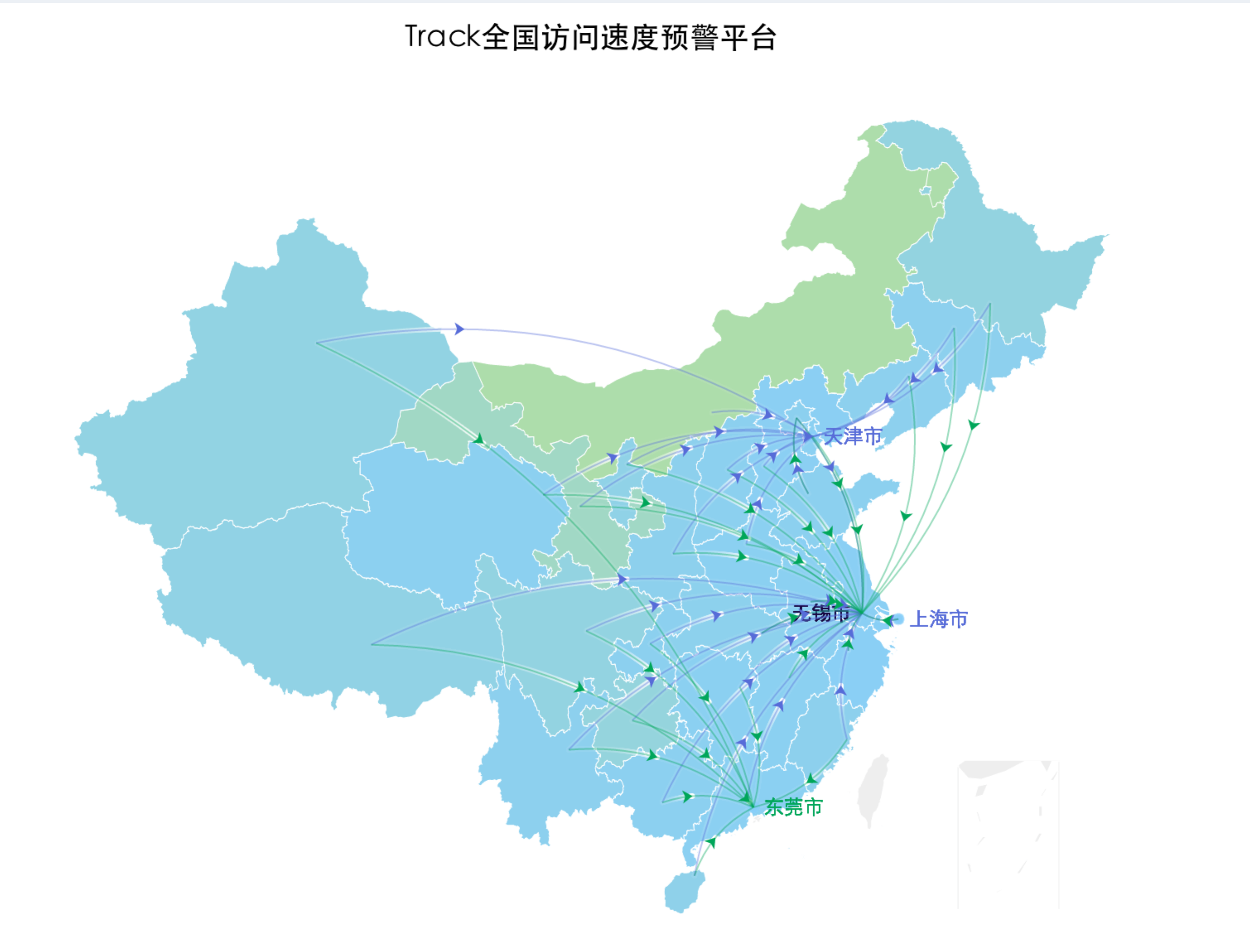
这个图显示了全国各省访问Track系统的情况,不仅包含了速度,访问的数据中心,还能显示是否出现域名劫持等信息。当然靠自己的监测节点是得不到这么多这么全的监控数据的,这时候需要云智慧的“监控宝”出面帮忙了,我们使用监控宝的全国200多个节点,将检测数据通过API回传,再整理分析、反馈在图上。
交换机的流量之前使用的是Cacti,交换机多了之后查找起来简直是个庞大的任务,针对这个需求痛点,我们的监控系统支持了交换机监控,除了基础的CPU等信息外,专门在流量上花了点心思。
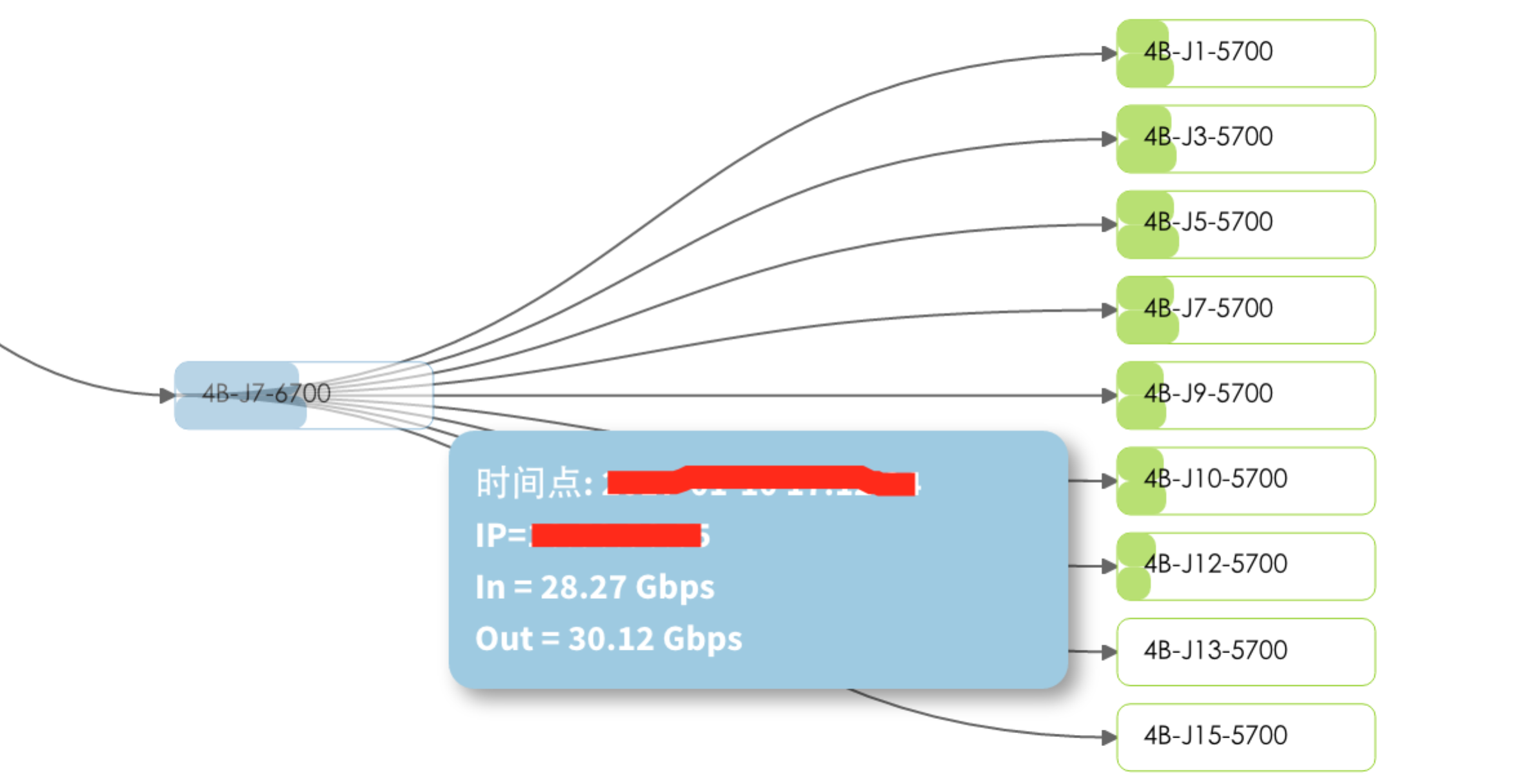
通过上图可以一目了然的看到当前交换机之间的速度情况,流量都来自哪里,有多少。
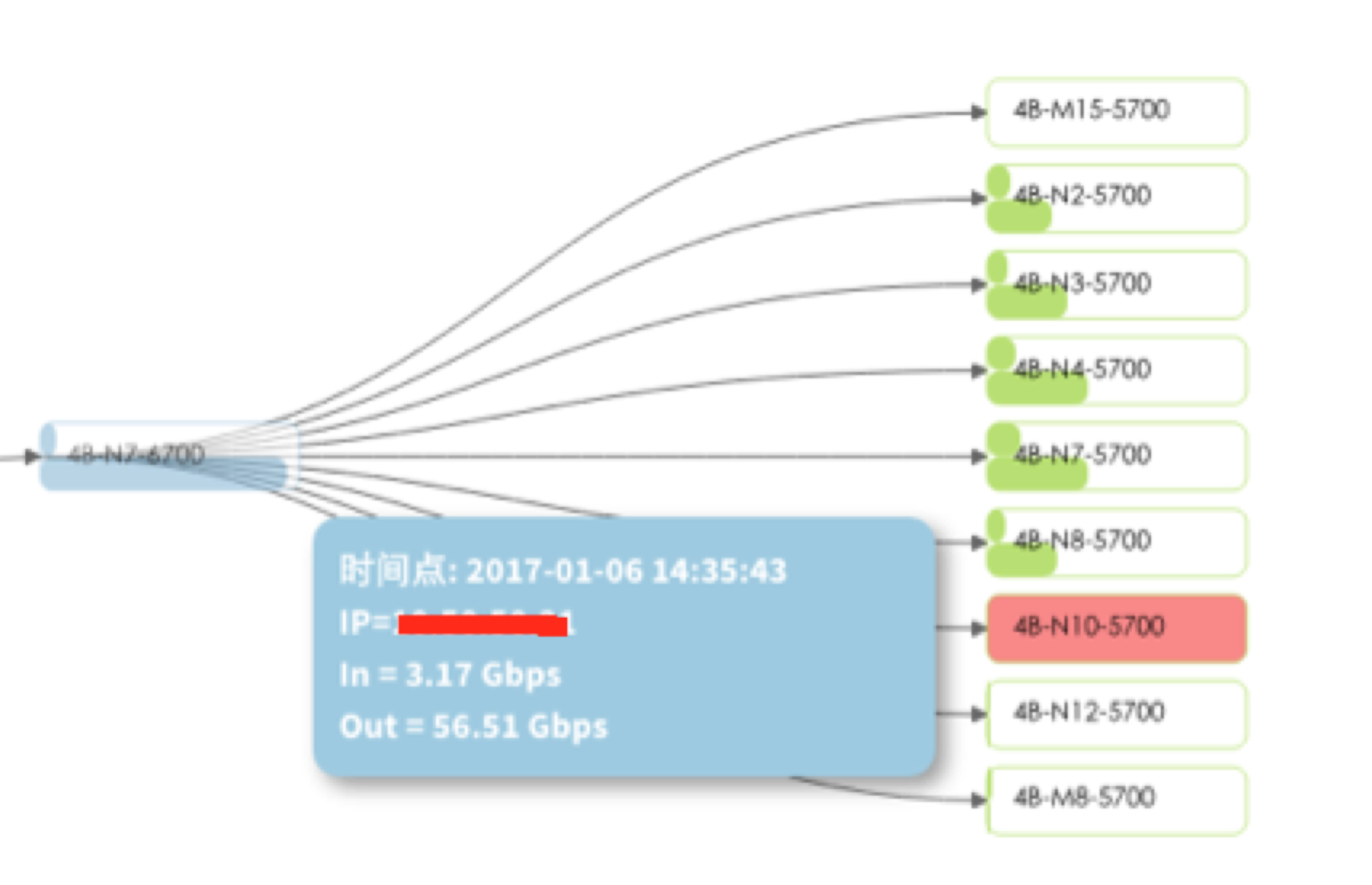
这张图可以看到哪里流量达到了预警值,哪个交换机出现了问题,在快速定位处理上提供了很大的便利。
最后,每个公司的需求不一样,每个运维面对的痛点也不尽相同,不管有多少变化,万变不离其宗,有了机器上的各种监控数据,就可以组合分析出你想要的结果,自建的路上,我们才刚刚开始,keep moving!谢谢大家!
QA部分
问:这个底层还是nagios吗?
答:不是了,完全都是自己从头写的,借鉴了nagios的思路,但是采集的方法,汇总处理的方法不一样了。
问:你们在业务监控上都做了那些工作?
答:业务监控我们也有一些,给大家发个图:
这个是我们的业务监控,将所有的监控数据用文字进行描述,让产品、业务同学以及老板都知道现在是什么情况。
问:这个监控对资源的消耗有多大?
答:还好,集中展示处理数据的时候遇到过一些瓶颈,不断在优化。
问:智能DNS系统是自己开发的吗?
答:智能DNS我们用了第三方的,自己的也有作为备份。
问:请问下你们数据库是MySQL集群么?
答:MySQL的主从,将报警和展示分开还有一个原因,就是担心性能问题。展示可以慢几秒钟、几分钟,但报警不可以,所以报警是即时的,并且不用担心监控机器挂了就会变成瞎子。我们目前有6个节点分布在全国,全挂掉的几率很小,只要有一台活着就可以报警。
问:这个精确值是秒吗?
答:秒级的,最慢的通知是电话,需要十几秒。
问:你们现在只用了监控宝吗?透视宝有没有在用呢?
答:透视宝正在研究。
问:交换机获取的什么指标?
答:CPU,内存,警告信息,流量,端口。
问:业务监控怎么做的?
答:业务监控其实跟透视宝类似,只不过没有做到那么细粒度。
问:是在程序里埋点吗?
答:不在程序里埋点,就是利用监控数据实现的,所以只能做到现象级别,不能做到代码级。
问:公司有几个运维?
答:算上我一共8个人。
问:运维每天工作怎么划分的,分产品吗?
答:早期分产品,第二阶段自动化作完之后,基本上随意了,都通过工单系统来完成,常规的上线,通过自建的工单系统审批结束之后自动上线,不需要运维参与。
问:你们物理机都大概什么配置?
答:最低配也是双6核,64G。
问:有没有碰到过服务器正常、中间件和数据库也正常,而线上业务突然失效的情况?
答:你这个可能需要透视宝。
问:透视宝可以监控网络出口带宽的拥堵吗?
答: 透视宝主要是做应用性能监控的,透视宝就像是应用系统的CT扫描仪,能够采集实际用户移动端和浏览器端体验性能数据、服务器上运行的应用环境、数据库访问、应用代码的执行性能数据,然后利用大数据技术把采集到的数据进行快速诊断分析,发现影响应用性能的“病灶”,并给出诊断建议,网络环节的监控是由监控宝完成的,二者结合可以真正实现从用户端到服务端的全链路服务监控和问题诊断。
问:大家有没有碰到过内网问题导致的业务失效?
答:透视宝应该可以帮到你,透视宝做的很细。透视宝是可解决内部的问题,监控宝可以解决外部的问题,结合起来就ok了,可以检查下交换机,看是不是有SFP网络震荡,这个我遇到过。
问:sfp网络震荡是什么?如果网络问题,那应该其他所有都有影响吧?
答:网络上的交换机,由于报文变化或者定时器超时,反复触发重计算,会一直持续在根桥选择、端口角色切换、端口状态迁移三个过程,这个过程如果持续进行多次,简称为STP震荡
问:网络震荡是什么原因引起的?
答:链路故障:网络上某个端口的链路属性,如端口状态、速率和双工模式等持续变化;
节点故障:单个交换机CPU较高,无法在定时间隔内发送或处理STP报文;
网络故障:网络发送拥塞,导致根端口方向的STP报文在转发过程中被丢弃;L2PT透传了其他网络的STP报文,造成本端STP误收敛;网络上错误的配置了组播抑制功能,偶尔丢弃STP报文。针对不同的故障原因,需要修改配置或者优化网络设计,解决震荡问题。
简单的说,一个模块出现问题、一根网线出现问题,导致频繁的up down几次,就会出现网络震荡。
原文:https://my.oschina.net/cloudwise/blog/826234