Flink是新一代实时计算平台,采用原生的流处理系统,保证了低延迟性,在API和容错上也是做的相当完善,本文将从架构、组件栈、安装、入门程序等进行基础知识的分析,帮助大家快速对Flink有一个了解。

一.简介
1.是什么
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,提供支持流处理和批处理两种类型应用的功能。
2.来历
Apache Flink 的前身是柏林理工大学一个研究性项目,在 2014 被Apache 孵化器所接受,然后迅速地成为了Apache SoftwareFoundation的顶级项目之一。
3.特点
(1)现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型:流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理;
(2)Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的,批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
二.组件栈
Flink系统本身是一个分成的架构,如下图所示:

1.Deployment层
部署层,主要涉及了Flink的部署模式,Flink支持多种部署模式:本地、集群Standalone/Yarn)、云(GCE/EC2),一般生成环境中常使用Yarn模式。
1)什么是yarn?
Apache Hadoop YARN(Yet AnotherResource Negotiator,另一种资源协调者),是一种新的 Hadoop 资源管理器,它是个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
2)Flink&Yarn简图如下:

Flink yarn Client直接与Yarn Resource Manager进行通讯,Yarn Resource Manager是用来向Flink集群申请资源,从而启动应用服务,当Yarn Resource Manager申请好了资源后,Flink可以直接提交Job在Yarn上面运行,也就是说资源调用这个工作完全交给Yarn去处理。
2.Runtime层
核心层,Runtime层提供了支持Flink计算的全部核心实现,比如:支持分布式Stream处理、JobGraph到ExecutionGraph的映射、调度等等为上层API层提供基础服务。
3.API层
API层,主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API,API层对于开发者开说只最核心的,开发者都是通过调用Flink暴露出来的API进行代码编写;
4.Libaries层
在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。
1)流处理:
a.CEP(Event Processing):提供事件处理模型;
b.Table(Relational):提供类似于SQL的操作。
2)批处理:
a.FlinkML(Machine Learning):提供机器学习库;
b.Gelly(Graph Processing):提供图处理模型;
c.Table(Relational):提供类似于SQL的操作。
三.自身优势
1.优点
1)支持高吞吐(通过测算,跑同样的业务代码,Flink比spark和SparkStreaming的吞吐量都要高)、低延迟(支持毫秒级延迟)、高性能的流处理;
2)支持高度灵活的窗口(Window)操作(窗口操作是流处理的核心,Flink支持多种窗口操作,比如滑动窗口、滚动窗口、会话窗口等);
3)支持有状态计算的Exactly-once语义(什么是有状态?假如说代码是搜索特定的事件,比如用户的点击或购买行为,那么状态就会保存截至到目前为止遇到的所有事件的顺序;再比如说程序计算每一分钟事件的聚合,那么状态会保存已经挂起的聚合;再比如说程序是训练机器模型,状态就可以保存当前模型的一些版本参数等);
4)提供DataStream API和DataSet API。
2.区别

(1)Flink本身没有实现exactly-once,需要开发者去实现这个功能;
(2)Flink和SparkStreaming都支持流式计算,Fink是一行一行处理,是基于操作符的连续流模型,而SparkStreaming是基于数据片集合(RDD)进行小批量处理,所以SparkStreaming在流式处理方面会增加一些延迟;
(3)Flink可以支持毫秒级计算,而Spark则只能支持秒级计算,如果是要求对实时性要求非常高的场景(如高频实时交易),Spark是难以满足的,可以考虑Flink或Storm。
四.基本概念&编程模型
1.基本概念
(1)Flink程序的基础构建模块是流(streams)与转换(transformations);
(2)每一个数据流起始于一个或多个 source,并终止于一个或多个sink。
一个典型的Flink程序映射成Streaming Dataflow的示意图:

Soure:通过Flink消费Kafka作为我们的数据输入;
Transformation:将输入的数据转换为程序中的需要的实体类或者结果;
Sink:将处理完的数据进行落地,比如写入Redis、Mysql、Hbase等。
并行流示意图如下:

Flink中所有的Soure、Transformation、Sink都是可以并行进行的,Soure是可以进行分区的,对每个分区进行map(),map()完以后再进行其他逻辑处理,最后再及进行Sink。
2.编程模型
时间窗口:
(1)流上的聚合需要由 窗口 来划定范围,比如“计算过去的5分钟!或者“最后100个元素的和';
(2)窗口通常被区分为不同的类型,比如滚动窗口(没有重叠 )、滑动窗口(有重叠),以及会话窗口(由不活动的间隙所打断)。
典型的Flink支持的窗口示意图如下:

1)滚动时间窗口:按固定时间设置窗口,如图就是1分钟设置为一个窗口,窗口大小就是1分钟。
2)滑动时间窗口:需要指定一个sliding size,举个例子:如果要计算过去30秒钟出现的数字,对它进行求和运算,每个30秒之间希望停顿5秒,这个就是slinging size,这就代表同一个数字可能属于上一个窗口,也属于下一个窗口,会出现数据的重复。
3)滚动数量窗口:每个窗口涉及到的数量是需要自己指定的,上图表示一个滚动窗口中需要三条数据,每当一个窗口的三条数据达到以后,就需要进行下一次的计算;
4)会话窗口:需要指定空档期时间,比如可以规定用户访问,10秒钟不操作,任务一次操作结束。
五.分布式运行环境
1.基本架构
(1)Flink是基于Master-Slave风格的架构;
(2)Flink集群启动时,会启动一个JobManager进程、至少一个TaskManager进程。
2.架构示意图
详细架构图:

简略架构图:

(1)JobManager
1)Flink系统的协调者,它负责接收FlinkJob,调度组成Job的多个Task的执行;
2)收集Job的状态信息,并管理Flink集群中从节点TaskManager。
(2)TaskManager
1)实际负责执行计算的Worker,在其上执行FlinkJob的一组Task;
2)TaskManager负责管理其所在节点上的资源信息,如内存、磁盘网络,在启动的时候将资源的状态向JobManager汇报。
(3)Client
1)用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群(代码由客户端获取并做转换,之后提交给JobManger);
3)Client会将用户提交的Flink程序组装一个JobGraph,并且是以JobGraph的形式提交的。
六.下载和安装
注意:Flink是一个非常灵活的处理框架,它支持多种不同的部署场景,还可以和不同的资源管理平台方便地集成,由于本文直做入门,所以按照最基本的集群方式部署。
1.准备环境
(1)Vmware安装三台Centos7.5的服务器,并且安装JDK1.8的环境。
| IP | HOSTNAME | 性质 |
|---|---|---|
| 192.168.100.101 | hadoop001 | master |
| 192.168.100.102 | hadoop002 | slave |
| 192.168.100.103 | hadoop003 | slave |
三台服务器均需要修改hosts:vi /etc/hosts
192.168.100.101 hadoop001
192.168.100.102 hadoop002
192.168.100.103 hadoop003
(2)下载Flink1.20版本:https://dlcdn.apache.org/flink/flink-1.20.0/flink-1.20.0-bin-scala_2.12.tgz,并且上传到三台服务器/home目录下,并解压:tar -zxvf flink-1.20.0-bin-scala_2.12.tgz
2.修改配置
1)hadoop001配置
a.config.yaml
env:java:opts:all: --add-exports=java.base/sun.net.util=ALL-UNNAMED --add-exports=java.rmi/sun.rmi.registry=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.api=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.file=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.parser=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.tree=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.util=ALL-UNNAMED --add-exports=java.security.jgss/sun.security.krb5=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.net=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/java.lang.reflect=ALL-UNNAMED --add-opens=java.base/java.text=ALL-UNNAMED --add-opens=java.base/java.time=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.base/java.util.concurrent=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.atomic=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.locks=ALL-UNNAMEDjobmanager:bind-host: 0.0.0.0rpc:address: hadoop001port: 6123memory:process:size: 1600mexecution:failover-strategy: regiontaskmanager:bind-host: 0.0.0.0host: haoop001numberOfTaskSlots: 1memory:process:size: 1728mparallelism:default: 1rest:address: hadoop001bind-address: 0.0.0.0b.masters
hadoop001:8081c.workers
hadoop001
hadoop002
hadoop0032)hadoop002配置
a.config.yaml
env:java:opts:all: --add-exports=java.base/sun.net.util=ALL-UNNAMED --add-exports=java.rmi/sun.rmi.registry=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.api=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.file=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.parser=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.tree=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.util=ALL-UNNAMED --add-exports=java.security.jgss/sun.security.krb5=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.net=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/java.lang.reflect=ALL-UNNAMED --add-opens=java.base/java.text=ALL-UNNAMED --add-opens=java.base/java.time=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.base/java.util.concurrent=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.atomic=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.locks=ALL-UNNAMEDjobmanager:bind-host: 0.0.0.0rpc:address: hadoop001port: 6123memory:process:size: 1600mexecution:failover-strategy: regiontaskmanager:bind-host: 0.0.0.0host: haoop002numberOfTaskSlots: 1memory:process:size: 1728mparallelism:default: 1rest:address: hadoop001bind-address: 0.0.0.0b.masters
hadoop001:8081c.workers
hadoop001
hadoop002
hadoop0033)hadoop003配置
a.config.yaml
env:java:opts:all: --add-exports=java.base/sun.net.util=ALL-UNNAMED --add-exports=java.rmi/sun.rmi.registry=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.api=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.file=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.parser=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.tree=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.util=ALL-UNNAMED --add-exports=java.security.jgss/sun.security.krb5=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.net=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/java.lang.reflect=ALL-UNNAMED --add-opens=java.base/java.text=ALL-UNNAMED --add-opens=java.base/java.time=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.base/java.util.concurrent=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.atomic=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.locks=ALL-UNNAMEDjobmanager:bind-host: 0.0.0.0rpc:address: hadoop001port: 6123memory:process:size: 1600mexecution:failover-strategy: regiontaskmanager:bind-host: 0.0.0.0host: haoop003numberOfTaskSlots: 1memory:process:size: 1728mparallelism:default: 1rest:address: hadoop001bind-address: 0.0.0.0b.masters
hadoop001:8081c.workers
hadoop001
hadoop002
hadoop003说明:
(1)config.yaml文件中,hadoop002、hadoop003的配置,仅taskmanager.host各自填自己的主机名,不修改rest.address,其他与hadoop001保持一致即可,masters、workers文件全部相同;
(2)三台服务需要配置免密登录,否则后续启动集群的时候需要输入三次密码,本人不做免密登录的说明。
3.启动集群
(1)进入bin目录下:/home/flink-1.20.0/bin;
(2)执行启动脚本:./start-cluster.sh;
(3)输入每台服务器对应的密码,完成启动;
(4)访问WebUI:http://192.168.100.101:8081,出现如下页面即集群启动成功:

七.入门程序
1.环境要求
(1)Maven 3.0+;
(2)Java 1.8;
(3)Flink 1.20.0。
2.创建工程
(1)创建一个普通maven工程;
(2)导入依赖:
<properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><flink.version>1.20.0</flink.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency></dependencies>(3)数据准备:在工程目录下创建input文件夹,在该文件夹下创建word.txt文件,如下
hello flink
hello java
hello work3.代码编写
需求:统计每个单词出现的次数
(1)批处理实现WordCount(有界)
/*** DataSet ApI 有界 实现 wordcount(过时,不推荐)*/
public class WordCountBatchDemo {public static void main(String[] args) throws Exception {// 1.创建执行环境ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 2.读取数据:从文件中读服envDataSource<String> lineDs = env.readTextFile("input/word.txt");// 3.切分、转换(word,1)FlatMapOperator<String, Tuple2<String, Integer>> wordAndOne = lineDs.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {// 3.1 按照空格切分单词String[] words = value.split(" ");// 3.2 将单词转换为(word,1)for (String word : words) {Tuple2<String, Integer> wordTuple2 = Tuple2.of(word, 1);// 3.3 使用collector向下游发送数据out.collect(wordTuple2);}}});// 4.按照word分组(参数代表的是位置,按照单词分组,word在0索引位置,表示第一个元素)UnsortedGrouping<Tuple2<String, Integer>> wordAndOneGroupby = wordAndOne.groupBy(0);// 5.各分组内聚合(参数代表的是位置,1代表数值1,表示第二个元素)AggregateOperator<Tuple2<String, Integer>> sum = wordAndOneGroupby.sum(1);// 6.输出sum.print();}
}// 控制台输出
// (java,1)
// (flink,1)
// (work,1)
// (hello,3)
// 一次性输出所有结果,这就是批处理注意:此方法在1.17版本以后已经不推荐使用了。
(2)流处理实现WordCount(有界)
/*** DataStream ApI 有界 实现 wordcount*/
public class WordCountStreamDemo {public static void main(String[] args) throws Exception {// 1.创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2.读取数据: 从文件读DataStreamSource<String> lineDs = env.readTextFile("input/word.txt");// 3.处理数据:切分、转换、分组、聚合// 3.1 切分、转换SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lineDs.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {// 3.1 按照空格切分单词String[] words = value.split(" ");// 3.2 将单词转换为(word,1)for (String word : words) {Tuple2<String, Integer> wordTuple2 = Tuple2.of(word, 1);// 3.3 使用collector向下游发送数据out.collect(wordTuple2);}}});// 3.2分组KeyedStream<Tuple2<String, Integer>, String> wordAndOneKS = wordAndOne.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}});// 3.3聚合SingleOutputStreamOperator<Tuple2<String, Integer>> sum = wordAndOneKS.sum(1);// 4.输出数据sum.print();// 5.执行:类似 sparkstreaming最后ssc.start()env.execute();}
}// 控制台输出
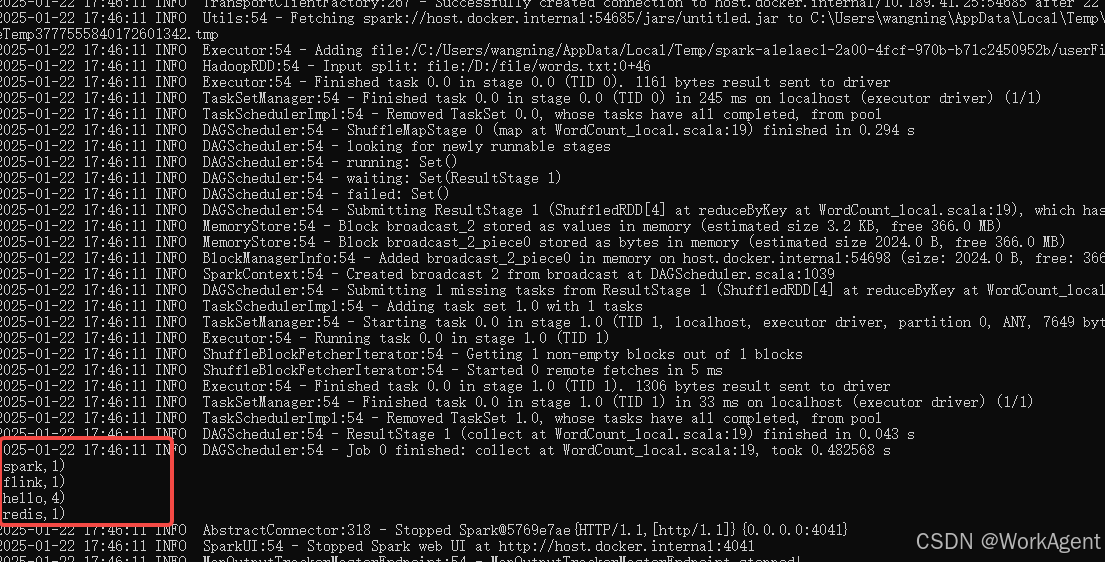
// 10> (flink,1)
// 2> (java,1)
// 9> (work,1)
// 4> (hello,1)
// 4> (hello,2)
// 4> (hello,3)
// 来一条数据,处理一条数据,这就是流处理,所以hello有1 2 3,这也是"有状态"的体现
// 最前面的编号就是并行度,本机是12线程的,所以这个编码不对大于12,并且每次执行都不一样区别:
1)执行环境不一样:批处理是ExecutionEnvironment,流处理是StreamExecutionEnvironment;
2)分组操作不一样:批处理是groupBy,流处理是keyBy;
3)流出来必须调用env.execute(),不然不会执行,批处理不需要调用。
(3)流处理实现WordCount(无界)
/*** DataStream ApI 无界 实现 wordcount*/
public class WordCountstreamUnboundedDemo {public static void main(String[] args) throws Exception {// 1.创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2.读战数据:socketDataStreamSource<String> socketDs = env.socketTextStream("hadoop102", 7777);// 3、处理数据:切换、转换、分组、聚合SingleOutputStreamOperator<Tuple2<String, Integer>> sum = socketDs.flatMap((String value, Collector<Tuple2<String, Integer>> out) -> {String[] words = value.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1));}}).keyBy(value -> value.f0).sum(1);// 4.输出sum.print();// 5.执行env.execute();env.execute();}
}执行报错:
Caused by: org.apache.flink.api.common.functions.InvalidTypesException: The generic type parameters of 'Collector' are missing. In many cases lambda methods don't provide enough information for automatic type extraction when Java generics are involved. An easy workaround is to use an (anonymous) class instead that implements the 'org.apache.flink.api.common.functions.FlatMapFunction' interface. Otherwise the type has to be specified explicitly using type information.at org.apache.flink.api.java.typeutils.TypeExtractionUtils.validateLambdaType(TypeExtractionUtils.java:371)at org.apache.flink.api.java.typeutils.TypeExtractionUtils.extractTypeFromLambda(TypeExtractionUtils.java:188)at org.apache.flink.api.java.typeutils.TypeExtractor.getUnaryOperatorReturnType(TypeExtractor.java:560)at org.apache.flink.api.java.typeutils.TypeExtractor.getFlatMapReturnTypes(TypeExtractor.java:177)at org.apache.flink.streaming.api.datastream.DataStream.flatMap(DataStream.java:611)at com.lsy.WordCountstreamUnboundedDemo.main(WordCountstreamUnboundedDemo.java:18)说明:
1)Flink 还具有一个类提取系统,可以分析函数的输人和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器,但是,由于Java中泛型擦除的存在,在某些特殊情况下(比如 Lambda 表达式中,嵌套的泛型就会出现该问题),自动提取的信息是不够精细的--只告诉 Flink 当前的元素由“船头、船身、船尾”构成,根本无法重建出“大船”的模样,这时就需要显式地提供类型信息,才能使应用程序正常工作或提高其性能。
2)因为对于 fatMap里传入的Lambda表达式,系统只能推断出返回的是 Tuple2 类型,而无法得到 Tuple2<String,Long>,只有显式地告诉系统当前的返回类型,才能正确地解析出完整数据。
修改后代码:
/*** DataStream ApI 无界 实现 wordcount*/
public class WordCountstreamUnboundedDemo {public static void main(String[] args) throws Exception {// 1.创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2.读战数据:socketDataStreamSource<String> socketDs = env.socketTextStream("hadoop102", 7777);// 3、处理数据:切换、转换、分组、聚合SingleOutputStreamOperator<Tuple2<String, Integer>> sum = socketDs.flatMap((String value, Collector<Tuple2<String, Integer>> out) -> {String[] words = value.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1));}})// 明确显示类型.returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy(value -> value.f0).sum(1);// 4.输出sum.print();// 5.执行env.execute();env.execute();}
}启动后,程序会一直运行,当socket有数据过来时,控制台就会打印对应的内容,这就是无界的意思,没输入就不打印,输入一条数据就打印一条,没数据就一直等待,这也就是事件驱动型。
有界流执行完后程序就退出了,无界流程序会一直执行,除非手动退出程序,工作中一般会使用无界流的方式。
4.命令行提交作业
在Flink的bin目录下执行:./flink run -m hadoop002 -c com.ls.WordCountstreamUnboundedDemo /home/task/flinkdemo-1.0-SNAPSHOT.jar ,提交成功后如下:

八.API简介
下面介绍部分常用API的作用
1.DataSet API

2.DataStream API

3.DataStream API & DataSet API

这是两者共有的API,唯一的却别是DataStream是一个无线的流,DataSet是一个有限的流。