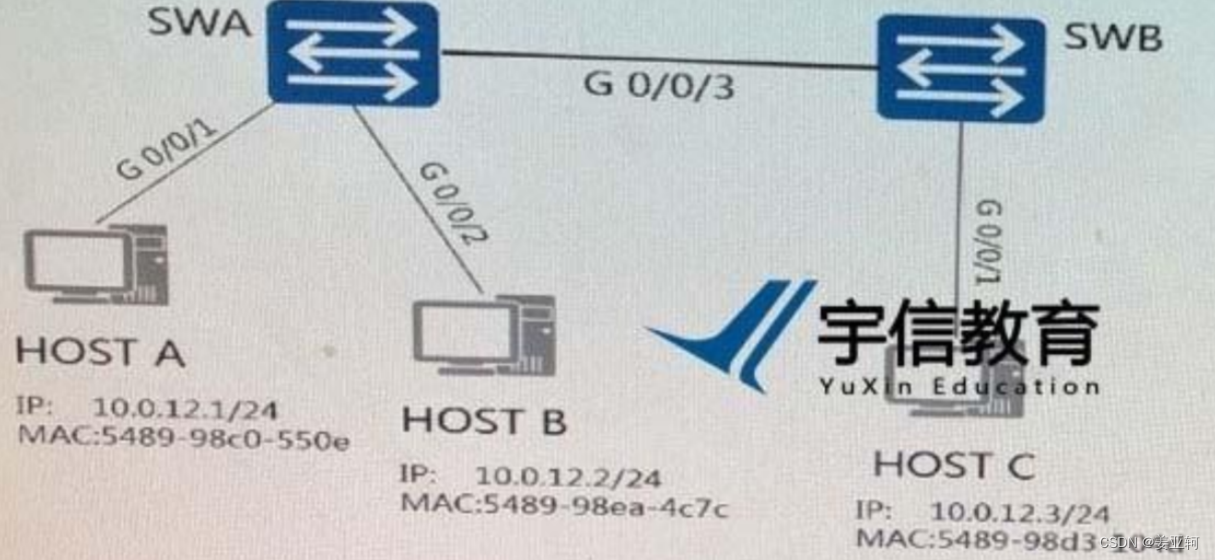
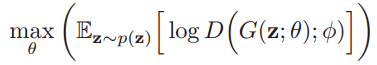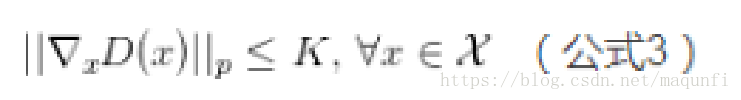作者:xg123321123 - 时光杂货店
出处:http://blog.csdn.net/xg123321123/article/details/78034859
声明:版权所有,转载请联系作者并注明出处
网上已经贴满了关于GAN的博客,写这篇帖子只是梳理下思路,以便以后查阅。
关于生成对抗网络的第一篇论文是Generative Adversarial Networks
0 前言
GAN(Generative Adversarial Nets)是用对抗方法来生成数据的一种模型。和其他机器学习模型相比,GAN引人注目的地方在于给机器学习引入了对抗这一理念。
回溯地球生物的进化路线就会发现,万物都是在不停的和其他事物对抗中成长和发展的。
生成对抗网络就像我们玩格斗游戏一样:学习过程就是不断找其他对手对抗,在对抗中积累经验,提升自己的技能。

GAN 是生成模型的一种,生成模型就是用机器学习去生成我们想要的数据,正规的说法是,获取训练样本并训练一个模型,该模型能按照我们定义的目标数据分布去生成数据。
比如autoencoder自编码器,它的decoding部分其实就是一种生成模型,它是在生成原数据。又比如seq2seq序列到序列模型,其实也是生成另一个我们想要的序列。Neural style transfer的目标其实也是生成图片。

上图涵盖了基本的生成式模型的方法,主要按是否需要定义概率密度函数分为:
Explicit density models
这之中又分为tractable explicit models和approximate explicit model,tractable explicit model通常可以直接通过数学方法来建模求解,而approximate explicit model通常无法直接对数据分布进行建模,可以利用数学里的一些近似方法来做数据建模, 通常基于approximate explicit model分为确定性(变分方法:如VAE的lower bound)和随机性的方法(马尔科夫链蒙特卡洛方法, MCMC)。Implicit density models
无需定义明确的概率密度函数,代表方法包括马尔科夫链、生成对抗式网络,该系列方法无需定义数据分布的描述函数。GAN能够有效地解决很多生成式方法的缺点,主要包括:
- 并行产生samples;
- 生成式函数的限制少,比如无需合适马尔科夫采样的数据分布(Boltzmann machines),生成式函数无需可逆、latent code无需与sample同维度(nonlinear ICA);
- 无需马尔科夫链的方法(Boltzmann machines, GSNs);
- 相对于VAE的方法,无需variational bound;
- GAN比其他方法一般来说性能更好。
1 基本思想
GAN 的核心思想源于博弈论的纳什均衡。
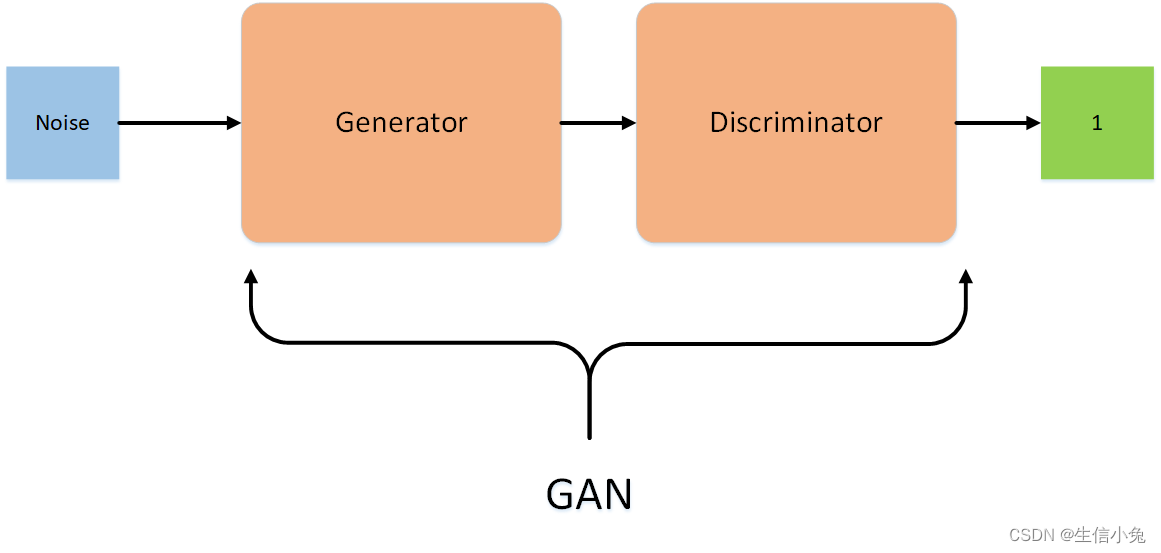
设定参与游戏的双方分别为一个生成器(Generator)和一个判别器(Discriminator), 生成器捕捉真实数据样本的潜在分布, 并生成新的数据样本; 判别器是一个二分类器, 判别输入是真实数据还是生成的样本。
为了取得游戏胜利, 这两个游戏参与者需要不断优化, 各自提高自己的生成能力和判别能力, 这个学习优化过程就是寻找二者之间的一个纳什均衡。
GAN是一种二人零和博弈思想(two-player game),博弈双方的利益之和是一个常数。

GAN的计算流程与结构如上图所示。
其中的生成器和判别器可以用任意可微分的函数, 这里我们用可微分函数D 和G 来分别表示判别器和生成器, 它们的输入分别为真实数据x 和随机变量z。
G(z) 为由G 生成的尽量服从真实数据分布 pdata 的样本。
如果判别器的输入来自真实数据, 标注为1.如果输入样本为G(z), 标注为0。
这里D 的目标是实现对数据来源的二分类判别: 真(来源于真实数据x 的分布) 或者伪(来源于生成器的伪数据G(z))。
而G 的目标是使自己生成的伪数据G(z) 在D 上的表现D(G(z)) 和真实数据x 在D 上的表现D(x)一致。
这是一个图片栗子:

生成器和判别器都采用神经网络。
这个栗子中,我们有的只是真实采集而来的人脸样本数据集,值得一提的是我们连人脸数据集的类标签都没有,也就是我们不知道那个人脸对应的是谁。
最原始的GAN目的是想通过输入一个噪声,模拟得到一个人脸图像,这个图像可以非常逼真以至于以假乱真。(不同的任务想得到的东西不一样)
上图右半部分的判别模型,是一个简单的神经网络结构,输入一幅图像,输出是一个概率值,用于判断真假使用(概率值大于0.5那就是真,小于0.5那就是假,人们定义的概率)
左半部分的生成模型也是神经网络结构,输入是一组随机数Z,输出是一个图像,不再是一个数值。
从图中可以看到,会存在两个数据集,一个是真实数据集,另一个是假的数据集,由生成网络生成的数据集。
判别模型的目的:能判别出来属于的一张图它是来自真实样本集还是假样本集。假如输入的是真样本,网络输出就接近1,输入的是假样本,网络输出接近0。
生成网络的目的:使得自己生成样本的能力尽可能强,强到判别网络没法判断自己生成的样本是真还是假。
由此可见,生成模型与判别模型的目的正好相反,一个说我能判别得好,一个说我让你判别不好,所以叫做对抗,叫做博弈。
而最后的结果到底是谁赢,就要归结于模型设计者希望谁赢了。作为设计者的我们,如果是要得到以假乱真的样本,那么就希望生成模型赢,希望生成的样本很真,判别模型能力不足以区分真假样本。
2 训练过程
- 在噪声数据分布中随机采样,输入生成模型,得到一组假数据,记为 D(z) ;
- 在真实数据分布中随机采样,作为真实数据,记做 x ;
- 将前两步中某一步产生的数据作为判别网络的输入(因此判别模型的输入为两类数据,真/假),判别网络的输出值为该输入属于真实数据的概率,real为1,fake为0.
- 然后根据得到的概率值计算损失函数;
- 根据判别模型和生成模型的损失函数,可以利用反向传播算法,更新模型的参数。(先更新判别模型的参数,然后通过再采样得到的噪声数据更新生成器的参数)

还是以前面那张图为栗子:

这里需要注意的是:生成模型与对抗模型是完全独立的两个模型,他们之间没有什么联系。那么训练采用的大原则是单独交替迭代训练。
因为是2个网络,不方便一起训练,所以才交替迭代训练。
先是判别网络:
假设现在有了生成网络(当然可能不是最好的),那么给一堆随机数组,就会得到一堆假的样本集(因为不是最终的生成模型,现在生成网络可能处于劣势,导致生成的样本不太好,很容易就被判别网络判别为假)。
现在有了这个假样本集(真样本集一直都有),我们再人为地定义真假样本集的标签,很明显,这里我们默认真样本集的类标签为1,而假样本集的类标签为0,因为我们希望真样本集的输出尽可能为1,假样本集为0。
现在有了真样本集以及它们的label(都是1)、假样本集以及它们的label(都是0)。这样一来,单就判别网络来说,问题变成了有监督的二分类问题了,直接送进神经网络中训练就好。
判别网络训练完了。
继续来看生成网络:
对于生成网络,我们的目的是生成尽可能逼真的样本。
而原始的生成网络生成的样本的真实程度只能通过判别网络才知道,所以在训练生成网络时,需要联合判别网络才能达到训练的目的。
所以生成网络的训练其实是对生成-判别网络串接的训练,像上图显示的那样。因为如果只使用生成网络,那么无法得到误差,也就无法训练。
当通过原始的噪声数组Z生成了假样本后,把这些假样本的标签都设置为1,即认为这些假样本在生成网络训练的时候是真样本。因为此时是通过判别器来生成误差的,而误差回传的目的是使得生成器生成的假样本逐渐逼近为真样本(当假样本不真实,标签却为1时,判别器给出的误差会很大,这就迫使生成器进行很大的调整;反之,当假样本足够真实,标签为1时,判别器给出的误差就会减小,这就完成了假样本向真样本逐渐逼近的过程),起到迷惑判别器的目的。
现在对于生成网络的训练,有了样本集(只有假样本集,没有真样本集),有了对应的label(全为1),有了误差,就可以开始训练了。
- 在训练这个串接网络时,一个很重要的操作是固定判别网络的参数,不让判别网络参数更新,只是让判别网络将误差传到生成网络,更新生成网络的参数。
在生成网络训练完后,可以根据用新的生成网络对先前的噪声Z生成新的假样本了,不出意外,这次生成的假样本会更真实。
有了新的真假样本集(其实是新的假样本集),就又可以重复上述过程了。
- 整个过程就叫单独交替训练。可以定义一个迭代次数,交替迭代到一定次数后停止即可。不出意外,这时噪声Z生成的假样本就会很真实了。
GAN设计的巧妙处之一,在于假样本在训练过程中的真假变换,这也是博弈得以进行的关键之处。
3 目标函数
上面提到,我们想要将一个随机高斯噪声z通过一个生成网络G得到一个和真的数据分布
我们从真实数据分布 Pdata(x) 中取样m个点, x1,x2,⋯,xm ,根据给定的参数 θ 我们可以计算如下的概率
我们要做的就是找到 θ^∗ 来最大化这个似然估计(关于最大似然估计,可见我这篇博客)
这里多减去 ∫xPdata(x)logPdata(x)dx 没有影响,因为这相当于一个常数
这里在前面添加一个负号,将log里面的分数倒一下,就变成了KL divergence(关于KL散度,可见我这篇博客)
那 PG(x;θ) 该如何计算?
里面的 I 表示示性函数,也就是
尽管这样我们根本没办法求出这个 PG(x) ,但这就是生成模型的基本想法。
进一步地
G是生成器,给定先验分布 Pprior(z) , 我们希望得到的生成分布是 Pz(z) ,这里很难通过极大似然估计得到结果;
D是一个函数,可以衡量 Pz(z) 与 Pdata(x) 之间的差距,被用来取代极大似然估计;
定义函数V(G, D)如下:
我们可以通过下面的式子求得最优的生成模型
下面是论文中的目标函数:
这是一个最大最小优化问题,先优化D,然后再优化G,本质上是两个优化问题,拆解后得到下面两个公式:
优化D:
优化G:
优化D(判别网络)时,不关生成网络的事,后面的G(z)相当于已经得到的假样本。优化D的公式的第一项,使的真样本x输入时,得到的结果越大越好,因为需要真样本的预测结果越接近于1越好。对于假样本,需要优化使其结果越小越好,也就是D(G(z))越小越好,因为它的标签为0。但是第一项越大,第二项就越小,这就矛盾了,所以把第二项改成1-D(G(z)),这样就是越大越好,两者合起来就是越大越好。
优化G(生成网络)时,不关真样本的事,所以把第一项直接去掉,只剩下假样本,这时希望假样本的标签是1,所以D(G(z))越大越好,但为了统一成1-D(G(z))的形式,就变成最小化1-D(G(z)),本质上没有区别,只是为了形式的统一。
这两个优化模型合并起来,就成了上面的最大最小目标函数了,里面既包含了判别模型的优化,同时也包含了生成模型的以假乱真的优化。
4 探讨
GAN强大之处在于能自动学习原始真实样本集的数据分布,不管这个分布多么的复杂,只要训练的足够好就可以学出来。
传统的机器学习方法,一般会先定义一个模型,再让数据去学习。
比如知道原始数据属于高斯分布,但不知道高斯分布的参数,这时定义高斯分布,然后利用数据去学习高斯分布的参数,得到最终的模型。
再比如定义一个分类器(如SVM),然后强行让数据进行各种高维映射,最后变成一个简单的分布,SVM可以很轻易的进行二分类(虽然SVM放松了这种映射关系,但也给了一个模型,即核映射),其实也是事先知道让数据该如何映射,只是映射的参数可以学习。
以上这些方法都在直接或间接的告诉数据该如何映射,只是不同的映射方法能力不一样。
而GAN的生成模型最后可以通过噪声生成一个完整的真实数据(比如人脸),说明生成模型掌握了从随机噪声到人脸数据的分布规律。GAN一开始并不知道这个规律是什么样,也就是说GAN是通过一次次训练后学习到的真实样本集的数据分布。
拿原论文中的一张图来解释:

上图表明的是GAN的生成网络如何一步步从均匀分布学习到正太分布的。
黑色的点状线代表真实的数据分布,绿色的线代表生成模型G模拟的分布,蓝色的线代表判别模型D。
- a图表示初始状态
- b图表示,保持G不动,优化D,直到判别模型的准确率最高
- c图表示保持D不动,优化G,直到混淆程度最高
- d图表示,多次迭代后,终于使得G生成的数据分布能够完全与真实的数据分布一致,而D再也鉴别不出是原始数据还是由生成模型所产生的数据,从而认为G就是真实的。
GAN的另一个强大之处在于可以自动定义潜在损失函数,即判别网络可以自动学习到一个好的判别方法(损失函数),来比较好或者不好的判别出来结果。
虽然大的loss函数是模型设计者人为定义的,基本上对于多数GAN都这么定义就可以了,但是判别网络潜在学习到的损失函数隐藏在网络之中,不同的问题这个函数就不一样,所以说可以自动学习这个潜在的损失函数。
5 优点 vs. 缺点
优点:
模型只用到了反向传播,而不需要马尔科夫链
训练时不需要对隐变量做推断
理论上,只要是可微分函数都可以用于构建D和G,因为能够与深度神经网络结合做深度生成式模型
G的参数更新不是直接来自数据样本,而是使用来自D的反向传播(这也是与传统方法相比差别较大的)
从实际结果来看,GAN看起来能产生更好的生成样本
GAN框架可以训练任何一种生成器网络(理论上,然而在实践中,很难使用增强学习去训练有离散输出的生成器),大多数其他架构需要生成器有一些特定的函数形式,就像输出层必须是高斯化的.另外所有其他框架需要生成器整个都是非零权值(put non-zero mass everywhere),然而,GANs可以学习到一个只在靠近真实数据的地方(神经网络层)产生样本点的模型( GANs can learn models that generate points only on a thin manifold that goes near the data.)【指的是GAN学习到的分布十分接近真实分布,这里把分布密度函数看作高维流行当中的点,某个类型的真实分布,可能是这个高维空间中的低维流行,想象三维空间中一张卷曲的纸。GAN学习的G能够尽量的“收敛”到这张纸上,而别的生成模型不行,总是在真实的流行之外有一定的分布,不够收敛。非零的mass指的是分布的“密度”,或者分布的“微元”】
没有必要遵循任何种类的因式分解去设计模型,所有的生成器和判别器都可以正常工作
相比PixelRNN, GAN生成采样的运行时间更短,GANs一次产生一个样本,然而PixelRNNs需要一个像素一个像素的去产生样本
相比VAE, GANs没有变分下界,如果鉴别器训练良好,那么生成器可以完美的学习到训练样本的分布.换句话说,GANs是渐进一致的,但是VAE是有偏差的
相比深度玻尔兹曼机, GANs没有变分下界,也没有棘手的配分函数,样本是一次生成的,而不是重复的应用马尔科夫链来生成的
相比GSNs, GANs产生的样本是一次生成的,而不是重复的应用马尔科夫链来生成的
相比NICE和Real NVE,GANs没有对潜在变量(生成器的输入值)的大小进行限制
GANs是一种以半监督方式训练分类器的方法.在你没有很多带标签的训练集的时候,你可以不做任何修改的直接使用我们的代码,通常这是因为你没有太多标记样本
GANs可以比完全明显的信念网络(NADE,PixelRNN,WaveNet等)更快的产生样本,因为它不需要在采样序列生成不同的数据
GANs不需要蒙特卡洛估计来训练网络,人们经常抱怨GANs训练不稳定,很难训练,但是他们比训练依赖于蒙特卡洛估计和对数配分函数的玻尔兹曼机简单多了.因为蒙特卡洛方法在高维空间中效果不好,玻尔兹曼机从来没有拓展到像ImgeNet任务中.GANs起码在ImageNet上训练后可以学习去画一些以假乱真的狗
相比于变分自编码器, GANs没有引入任何决定性偏置( deterministic bias),变分方法引入决定性偏置,因为他们优化对数似然的下界,而不是似然度本身,这看起来导致了VAEs生成的实例比GANs更模糊
相比非线性ICA(NICE, Real NVE等,),GANs不要求生成器输入的潜在变量有任何特定的维度或者要求生成器是可逆的
相比玻尔兹曼机和GSNs,GANs生成实例的过程只需要模型运行一次,而不是以马尔科夫链的形式迭代很多次
缺点:
可解释性差,生成模型的分布 Pg(G)没有显式的表达
比较难训练,D与G之间需要很好的同步(例如D更新k次而G更新一次),GAN模型被定义为极小极大问题,没有损失函数,在训练过程中很难区分是否正在取得进展。GAN的学习过程可能发生崩溃问题(collapse problem),生成器开始退化,总是生成同样的样本点,无法继续学习。当生成模型崩溃时,判别模型也会对相似的样本点指向相似的方向,训练无法继续。
网络难以收敛,目前所有的理论都认为GAN应该在纳什均衡上有很好的表现,但梯度下降只有在凸函数的情况下才能保证实现纳什均衡。
训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到.还没有找到很好的达到纳什均衡的方法,所以训练GAN相比VAE或者PixelRNN是不稳定的,但在实践中它还是比训练玻尔兹曼机稳定的多
它很难去学习生成离散的数据,就像文本
相比玻尔兹曼机,GANs很难根据一个像素值去猜测另外一个像素值,GANs天生就是做一件事的,那就是一次产生所有像素, 你可以用BiGAN来修正这个特性,它能让你像使用玻尔兹曼机一样去使用Gibbs采样来猜测缺失值
6 应用与改进
先看几个GAN的应用:
字体生成 zi2zi-github
图像生成 pixel2pixel-github
文字生成图片 Text to Image Synthesis



照片动漫化 domain-transfer-network-github
iGAN


再记录几个GAN的分支:
CGAN
CGAN首次提出为GAN增加限制条件,从而增加GAN的准确率。原始的GAN产生的数据模糊不清,为了解决GAN太过自由这个问题,一个很自然的想法就是给GAN加一些约束,于是便有了这篇Conditional Generative Adversarial Nets,这篇工作的改进非常straightforward,在生成模型和判别模型分别为数据加上标签,也就是加上了限制条件。实验表明很有效。DCGAN
DCGAN全称为Deep convolutional generative adversarial networks,即将深度学习中的卷积神经网络应用到了对抗神经网络中,这篇文章在工程领域内的意义及其大,解决了很多工程性的问题,再加上其源码的开放,将其推向了一个高峰。这个模型为工业界具体使用CNN的对抗生成网络提供了非常完善的解决方案,并且生成的图片效果质量精细,为之后GAN的后续再应用领域的发展奠定了很好的基础,当然也可以说提供了一个标杆。
iGAN
iGAN完美地将DCGAN和manifold learning融合在一起,很好的展现了一个DCGAN在实践应用方面的具体案例,将交互这种可能性实现,这对将来类似的应用提供了很好的模板。LAPGAN
江湖人称拉普拉斯对抗生成网络,主要致力于生成更加清晰,更加锐利的数据。LAPGAN事实上受启发与CGAN,同样在训练生成模型的时候加入了conditional variable,这也是本案例成功的一大重要原因。
SimGAN
Apple出品的SimGAN本质地利用了GAN可以产生和训练数据质量一样的生成数据这个特性,通过GAN生成大量的和训练数据一样真实的数据,从而解决当前大规模的精确标注数据难以获取,人工标注成本过高等一系列问题。InfoGAN
InfoGAN是一种能够学习disentangled representation的GAN,比如人脸数据集中有各种不同的属性特点,如脸部表情、是否带眼镜、头发的风格眼珠的颜色等等,这些很明显的相关表示, InfoGAN能够在完全无监督信息(是否带眼镜等等)下能够学习出这些disentangled representation,而相对于传统的GAN,只需修改loss来最大化GAN的input的noise和最终输出之间的互信息。AC-GAN
AC-GAN即auxiliary classifier GAN。
这里有个大神把各种GAN的paper都做了一个统计AdversarialNetsPapers
另外还有大神用tensorflow实现了GAN和VAE的各种分支tensorflow-generative-model-collections
和generative-models
7 WGAN-GP代码栗子
数据集:MNIST
环境:tensorflow 1.2.0
模型:WGAN-GP
注:GPU加速,CPU也行,但很慢,把batchsize改小后用cpu比较好训练,batchsize为64,save_images的参数是[8,8],如果batchsize为16,就相应改为[4,4];代码结尾是实验结果图。
实验心得:开始用DCGAN,但怎么调都不收敛,DCGAN需要小心的平衡生成器和判别器的训练程度,换了好几个学习率,效果都不太理想,使用WGAN-GP后,头也不疼了,腰也不酸了,后者好训练很多,完全不用担心训练失衡的问题,用着很顺手。
#coding:utf-8
import os
import numpy as np
import scipy.misc
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data #as mnist_datadef conv2d(name, tensor,ksize, out_dim, stddev=0.01, stride=2, padding='SAME'):with tf.variable_scope(name):w = tf.get_variable('w', [ksize, ksize, tensor.get_shape()[-1],out_dim], dtype=tf.float32,initializer=tf.random_normal_initializer(stddev=stddev))var = tf.nn.conv2d(tensor,w,[1,stride, stride,1],padding=padding)b = tf.get_variable('b', [out_dim], 'float32',initializer=tf.constant_initializer(0.01))return tf.nn.bias_add(var, b)def deconv2d(name, tensor, ksize, outshape, stddev=0.01, stride=2, padding='SAME'):with tf.variable_scope(name):w = tf.get_variable('w', [ksize, ksize, outshape[-1], tensor.get_shape()[-1]], dtype=tf.float32,initializer=tf.random_normal_initializer(stddev=stddev))var = tf.nn.conv2d_transpose(tensor, w, outshape, strides=[1, stride, stride, 1], padding=padding)b = tf.get_variable('b', [outshape[-1]], 'float32', initializer=tf.constant_initializer(0.01))return tf.nn.bias_add(var, b)def fully_connected(name,value, output_shape):with tf.variable_scope(name, reuse=None) as scope:shape = value.get_shape().as_list()w = tf.get_variable('w', [shape[1], output_shape], dtype=tf.float32,initializer=tf.random_normal_initializer(stddev=0.01))b = tf.get_variable('b', [output_shape], dtype=tf.float32, initializer=tf.constant_initializer(0.0))return tf.matmul(value, w) + bdef relu(name, tensor):return tf.nn.relu(tensor, name)def lrelu(name,x, leak=0.2):return tf.maximum(x, leak * x, name=name)DEPTH = 28
OUTPUT_SIZE = 28
batch_size = 64
def Discriminator(name,inputs,reuse):with tf.variable_scope(name, reuse=reuse):output = tf.reshape(inputs, [-1, 28, 28, 1])output1 = conv2d('d_conv_1', output, ksize=5, out_dim=DEPTH)output2 = lrelu('d_lrelu_1', output1)output3 = conv2d('d_conv_2', output2, ksize=5, out_dim=2*DEPTH)output4 = lrelu('d_lrelu_2', output3)output5 = conv2d('d_conv_3', output4, ksize=5, out_dim=4*DEPTH)output6 = lrelu('d_lrelu_3', output5)# output7 = conv2d('d_conv_4', output6, ksize=5, out_dim=8*DEPTH)# output8 = lrelu('d_lrelu_4', output7)chanel = output6.get_shape().as_list()output9 = tf.reshape(output6, [batch_size, chanel[1]*chanel[2]*chanel[3]])output0 = fully_connected('d_fc', output9, 1)return output0def generator(name, reuse=False):with tf.variable_scope(name, reuse=reuse):noise = tf.random_normal([batch_size, 128])#.astype('float32')noise = tf.reshape(noise, [batch_size, 128], 'noise')output = fully_connected('g_fc_1', noise, 2*2*8*DEPTH)output = tf.reshape(output, [batch_size, 2, 2, 8*DEPTH], 'g_conv')output = deconv2d('g_deconv_1', output, ksize=5, outshape=[batch_size, 4, 4, 4*DEPTH])output = tf.nn.relu(output)output = tf.reshape(output, [batch_size, 4, 4, 4*DEPTH])output = deconv2d('g_deconv_2', output, ksize=5, outshape=[batch_size, 7, 7, 2* DEPTH])output = tf.nn.relu(output)output = deconv2d('g_deconv_3', output, ksize=5, outshape=[batch_size, 14, 14, DEPTH])output = tf.nn.relu(output)output = deconv2d('g_deconv_4', output, ksize=5, outshape=[batch_size, OUTPUT_SIZE, OUTPUT_SIZE, 1])# output = tf.nn.relu(output)output = tf.nn.sigmoid(output)return tf.reshape(output,[-1,784])def save_images(images, size, path):# 图片归一化img = (images + 1.0) / 2.0h, w = img.shape[1], img.shape[2]merge_img = np.zeros((h * size[0], w * size[1], 3))for idx, image in enumerate(images):i = idx % size[1]j = idx // size[1]merge_img[j * h:j * h + h, i * w:i * w + w, :] = imagereturn scipy.misc.imsave(path, merge_img)LAMBDA = 10
EPOCH = 40
def train():# print os.getcwd()with tf.variable_scope(tf.get_variable_scope()):# real_data = tf.placeholder(dtype=tf.float32, shape=[-1, OUTPUT_SIZE*OUTPUT_SIZE*3])path = os.getcwd()data_dir = path + "/train.tfrecords"#准备使用自己的数据集# print data_dir'''获得数据'''z = tf.placeholder(dtype=tf.float32, shape=[batch_size, 100])#build placeholderreal_data = tf.placeholder(tf.float32, shape=[batch_size,784])with tf.variable_scope(tf.get_variable_scope()):fake_data = generator('gen',reuse=False)disc_real = Discriminator('dis_r',real_data,reuse=False)disc_fake = Discriminator('dis_r',fake_data,reuse=True)#下面这三句话去掉也没有影响t_vars = tf.trainable_variables()d_vars = [var for var in t_vars if 'd_' in var.name]g_vars = [var for var in t_vars if 'g_' in var.name]'''计算损失'''gen_cost = tf.reduce_mean(disc_fake)disc_cost = -tf.reduce_mean(disc_fake) + tf.reduce_mean(disc_real)alpha = tf.random_uniform(shape=[batch_size, 1],minval=0.,maxval=1.)differences = fake_data - real_datainterpolates = real_data + (alpha * differences)gradients = tf.gradients(Discriminator('dis_r',interpolates,reuse=True), [interpolates])[0]slopes = tf.sqrt(tf.reduce_sum(tf.square(gradients), reduction_indices=[1]))gradient_penalty = tf.reduce_mean((slopes - 1.) ** 2)disc_cost += LAMBDA * gradient_penaltywith tf.variable_scope(tf.get_variable_scope(), reuse=None):gen_train_op = tf.train.AdamOptimizer(learning_rate=1e-4,beta1=0.5,beta2=0.9).minimize(gen_cost,var_list=g_vars)disc_train_op = tf.train.AdamOptimizer(learning_rate=1e-4,beta1=0.5,beta2=0.9).minimize(disc_cost,var_list=d_vars)saver = tf.train.Saver()# os.environ['CUDA_VISIBLE_DEVICES'] = str(0)#gpu环境# config = tf.ConfigProto()# config.gpu_options.per_process_gpu_memory_fraction = 0.5#调用50%GPU资源# sess = tf.InteractiveSession(config=config)sess = tf.InteractiveSession()coord = tf.train.Coordinator()threads = tf.train.start_queue_runners(sess=sess, coord=coord)init = tf.global_variables_initializer()# init = tf.initialize_all_variables()sess.run(init)mnist = input_data.read_data_sets("data", one_hot=True)# mnist = mnist_data.read_data_sets("data", one_hot=True, reshape=False, validation_size=0)for epoch in range (1, EPOCH):idxs = 1000for iters in range(1, idxs):_, g_loss = sess.run([gen_train_op, gen_cost])img, _ = mnist.train.next_batch(batch_size)# img2 = tf.reshape(img, [batch_size, 784])for x in range (0,5):_, d_loss = sess.run([disc_train_op, disc_cost], feed_dict={real_data: img})# print "fake_data:%5f disc_real:%5f disc_fake:%5f "%(tf.reduce_mean(fake_data)# ,tf.reduce_mean(disc_real),tf.reduce_mean(disc_fake))print("[%4d:%4d/%4d] d_loss: %.8f, g_loss: %.8f"%(epoch, iters, idxs, d_loss, g_loss))with tf.variable_scope(tf.get_variable_scope()):samples = generator('gen', reuse=True)samples = tf.reshape(samples, shape=[batch_size, 28,28,1])samples=sess.run(samples)save_images(samples, [8,8], os.getcwd()+'/img/'+'sample_%d_epoch.png' % (epoch))if epoch>=39:checkpoint_path = os.path.join(os.getcwd(),'my_wgan-gp.ckpt')saver.save(sess, checkpoint_path, global_step=epoch)print '********* model saved *********'coord.request_stop()coord.join(threads)sess.close()
if __name__ == '__main__':train()

第1个epoch生成结果 第39个epoch生成结果
当然,这里还有一篇对代码讲解比较详细的帖子GAN入门教程|从0开始,手把手教你学会最火的神经网络
本篇博客整理自以下博客:
深入探索生成对抗网络
tensorflow学习之最简单的GAN 实现
简单理解与实验生成对抗网络GAN
对抗生成网络详解
tensorflow 实现wgan-gp mnist图片生成
火热的生成对抗网络(GAN),你究竟好在哪里
GAN生成对抗网络
GAN理解与TF实现
Gan的数学推导