本帖训练一个可以根据姓名判断性别的CNN模型;我使用自己爬取的35万中文姓名进行训练。
使用同样的数据集还可以训练起名字模型,参看:
- TensorFlow练习7: 基于RNN生成古诗词
- https://github.com/tensorflow/models/tree/master/namignizer
- TensorFlow练习13: 制作一个简单的聊天机器人
准备姓名数据集
我上网找了一下,并没有找到现成的中文姓名数据集,额,看来只能自己动手了。
我写了一个简单的Python脚本,爬取了上万中文姓名,格式整理如下:
- 姓名,性别
- 安镶怡,女
- 饶黎明,男
- 段焙曦,男
- 苗芯萌,男
- 覃慧藐,女
- 芦玥微,女
- 苏佳琬,女
- 王旎溪,女
- 彭琛朗,男
- 李昊,男
- 利欣怡,女
- # 貌似有很多名字男女通用
数据集:https://pan.baidu.com/s/1hsHTEU4。
训练模型
- import tensorflow as tf
- import numpy as np
- name_dataset = 'name.csv'
- train_x = []
- train_y = []
- with open(name_dataset, 'r') as f:
- first_line = True
- for line in f:
- if first_line is True:
- first_line = False
- continue
- sample = line.strip().split(',')
- if len(sample) == 2:
- train_x.append(sample[0])
- if sample[1] == '男':
- train_y.append([0, 1]) # 男
- else:
- train_y.append([1, 0]) # 女
- max_name_length = max([len(name) for name in train_x])
- print("最长名字的字符数: ", max_name_length)
- max_name_length = 8
- # 数据已shuffle
- #shuffle_indices = np.random.permutation(np.arange(len(train_y)))
- #train_x = train_x[shuffle_indices]
- #train_y = train_y[shuffle_indices]
- # 词汇表(参看聊天机器人练习)
- counter = 0
- vocabulary = {}
- for name in train_x:
- counter += 1
- tokens = [word for word in name]
- for word in tokens:
- if word in vocabulary:
- vocabulary[word] += 1
- else:
- vocabulary[word] = 1
- vocabulary_list = [' '] + sorted(vocabulary, key=vocabulary.get, reverse=True)
- print(len(vocabulary_list))
- # 字符串转为向量形式
- vocab = dict([(x, y) for (y, x) in enumerate(vocabulary_list)])
- train_x_vec = []
- for name in train_x:
- name_vec = []
- for word in name:
- name_vec.append(vocab.get(word))
- while len(name_vec) < max_name_length:
- name_vec.append(0)
- train_x_vec.append(name_vec)
- #######################################################
- input_size = max_name_length
- num_classes = 2
- batch_size = 64
- num_batch = len(train_x_vec) // batch_size
- X = tf.placeholder(tf.int32, [None, input_size])
- Y = tf.placeholder(tf.float32, [None, num_classes])
- dropout_keep_prob = tf.placeholder(tf.float32)
- def neural_network(vocabulary_size, embedding_size=128, num_filters=128):
- # embedding layer
- with tf.device('/cpu:0'), tf.name_scope("embedding"):
- W = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
- embedded_chars = tf.nn.embedding_lookup(W, X)
- embedded_chars_expanded = tf.expand_dims(embedded_chars, -1)
- # convolution + maxpool layer
- filter_sizes = [3,4,5]
- pooled_outputs = []
- for i, filter_size in enumerate(filter_sizes):
- with tf.name_scope("conv-maxpool-%s" % filter_size):
- filter_shape = [filter_size, embedding_size, 1, num_filters]
- W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1))
- b = tf.Variable(tf.constant(0.1, shape=[num_filters]))
- conv = tf.nn.conv2d(embedded_chars_expanded, W, strides=[1, 1, 1, 1], padding="VALID")
- h = tf.nn.relu(tf.nn.bias_add(conv, b))
- pooled = tf.nn.max_pool(h, ksize=[1, input_size - filter_size + 1, 1, 1], strides=[1, 1, 1, 1], padding='VALID')
- pooled_outputs.append(pooled)
- num_filters_total = num_filters * len(filter_sizes)
- h_pool = tf.concat(3, pooled_outputs)
- h_pool_flat = tf.reshape(h_pool, [-1, num_filters_total])
- # dropout
- with tf.name_scope("dropout"):
- h_drop = tf.nn.dropout(h_pool_flat, dropout_keep_prob)
- # output
- with tf.name_scope("output"):
- W = tf.get_variable("W", shape=[num_filters_total, num_classes], initializer=tf.contrib.layers.xavier_initializer())
- b = tf.Variable(tf.constant(0.1, shape=[num_classes]))
- output = tf.nn.xw_plus_b(h_drop, W, b)
- return output
- # 训练
- def train_neural_network():
- output = neural_network(len(vocabulary_list))
- optimizer = tf.train.AdamOptimizer(1e-3)
- loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(output, Y))
- grads_and_vars = optimizer.compute_gradients(loss)
- train_op = optimizer.apply_gradients(grads_and_vars)
- saver = tf.train.Saver(tf.global_variables())
- with tf.Session() as sess:
- sess.run(tf.global_variables_initializer())
- for e in range(201):
- for i in range(num_batch):
- batch_x = train_x_vec[i*batch_size : (i+1)*batch_size]
- batch_y = train_y[i*batch_size : (i+1)*batch_size]
- _, loss_ = sess.run([train_op, loss], feed_dict={X:batch_x, Y:batch_y, dropout_keep_prob:0.5})
- print(e, i, loss_)
- # 保存模型
- if e % 50 == 0:
- saver.save(sess, "name2sex.model", global_step=e)
- train_neural_network()
- # 使用训练的模型
- def detect_sex(name_list):
- x = []
- for name in name_list:
- name_vec = []
- for word in name:
- name_vec.append(vocab.get(word))
- while len(name_vec) < max_name_length:
- name_vec.append(0)
- x.append(name_vec)
- output = neural_network(len(vocabulary_list))
- saver = tf.train.Saver(tf.global_variables())
- with tf.Session() as sess:
- # 恢复前一次训练
- ckpt = tf.train.get_checkpoint_state('.')
- if ckpt != None:
- print(ckpt.model_checkpoint_path)
- saver.restore(sess, ckpt.model_checkpoint_path)
- else:
- print("没找到模型")
- predictions = tf.argmax(output, 1)
- res = sess.run(predictions, {X:x, dropout_keep_prob:1.0})
- i = 0
- for name in name_list:
- print(name, '女' if res[i] == 0 else '男')
- i += 1
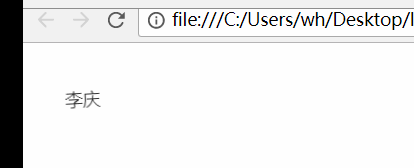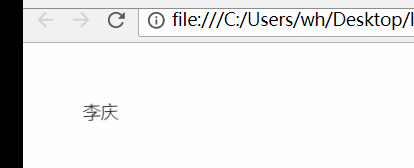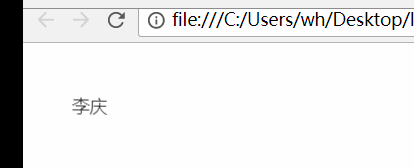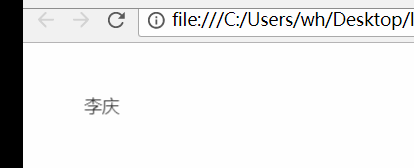
- detect_sex(["白富美", "高帅富", "王婷婷", "田野"])
执行结果:

本文已获原作者授权转载,附上链接: http://blog.csdn.net/u014365862/article/details/53869732