文章目录
- 1. 代码
- 2. 数据可视化
- 2.1 读取数据
- 2.2 各年份上映电影数量柱状图(纵向)
- 2.3 各地区上映电影数量前十柱状图(横向)
- 2.4 电影评价人数前二十柱状图(横向)
- 可视化项目源码+数据
大家好,我是 👉【Python当打之年(点击跳转)】
本期向大家展示如何用python分析电影相关信息,并对其进行可视化处理,希望对小伙伴们有所帮助。
1. 代码
# 获取每页电影链接
def getonepagelist(url,headers):try:r = requests.get(url, headers=headers, timeout=10)r.raise_for_status()r.encoding = 'utf-8'soup = BeautifulSoup(r.text, 'html.parser')lsts = soup.find_all(attrs={'class': 'hd'})for lst in lsts:href = lst.a['href']time.sleep(0.5)getfilminfo(href, headers)except:print('getonepagelist error!')# 获取每部电影具体信息
def getfilminfo(url,headers):filminfo = []r = requests.get(url, headers=headers, timeout=10)r.raise_for_status()r.encoding = 'utf-8'soup = BeautifulSoup(r.text, 'html.parser')# 片名name = soup.find(attrs={'property': 'v:itemreviewed'}).text.split(' ')[0]# 上映年份year = soup.find(attrs={'class': 'year'}).text.replace('(','').replace(')','')# 评分score = soup.find(attrs={'property': 'v:average'}).text# 评价人数votes = soup.find(attrs={'property': 'v:votes'}).textinfos = soup.find(attrs={'id': 'info'}).text.split('\n')[1:11]# 导演director = infos[0].split(': ')[1]# 编剧scriptwriter = infos[1].split(': ')[1]# 主演actor = infos[2].split(': ')[1]# 类型filmtype = infos[3].split(': ')[1]# 国家/地区area = infos[4].split(': ')[1]if '.' in area:area = infos[5].split(': ')[1].split(' / ')[0]# 语言language = infos[6].split(': ')[1].split(' / ')[0]else:area = infos[4].split(': ')[1].split(' / ')[0]# 语言language = infos[5].split(': ')[1].split(' / ')[0]if '大陆' in area or '香港' in area or '台湾' in area:area = '中国'if '戛纳' in area:area = '法国'# 时长times0 = soup.find(attrs={'property': 'v:runtime'}).texttimes = re.findall('\d+', times0)[0]filminfo.append(name)filminfo.append(year)filminfo.append(score)filminfo.append(votes)filminfo.append(director)filminfo.append(scriptwriter)filminfo.append(actor)filminfo.append(filmtype)filminfo.append(area)filminfo.append(language)filminfo.append(times)filepath = 'TOP250.xlsx'insert2excel(filepath,filminfo)# 保存数据
def insert2excel(filepath,allinfo):try:if not os.path.exists(filepath):tableTitle = ['片名','上映年份','评分','评价人数','导演','编剧','主演','类型','国家/地区','语言','时长(分钟)']wb = Workbook()ws = wb.activews.title = 'sheet1'ws.append(tableTitle)wb.save(filepath)time.sleep(3)wb = load_workbook(filepath)ws = wb.activews.title = 'sheet1'ws.append(allinfo)wb.save(filepath)return Trueexcept:return False
2. 数据可视化
2.1 读取数据
用pandas模块读取:
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bardata = pd.read_excel('TOP250.xlsx')
2.2 各年份上映电影数量柱状图(纵向)
代码:
def getzoombar(data):year_counts = data['上映年份'].value_counts()year_counts.columns = ['上映年份', '数量']year_counts = year_counts.sort_index()c = (Bar().add_xaxis(list(year_counts.index)).add_yaxis('上映数量', year_counts.values.tolist()).set_global_opts(title_opts=opts.TitleOpts(title='各年份上映电影数量'),yaxis_opts=opts.AxisOpts(name='上映数量'),xaxis_opts=opts.AxisOpts(name='上映年份'),datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_='inside')],).render('各年份上映电影数量.html'))
效果:
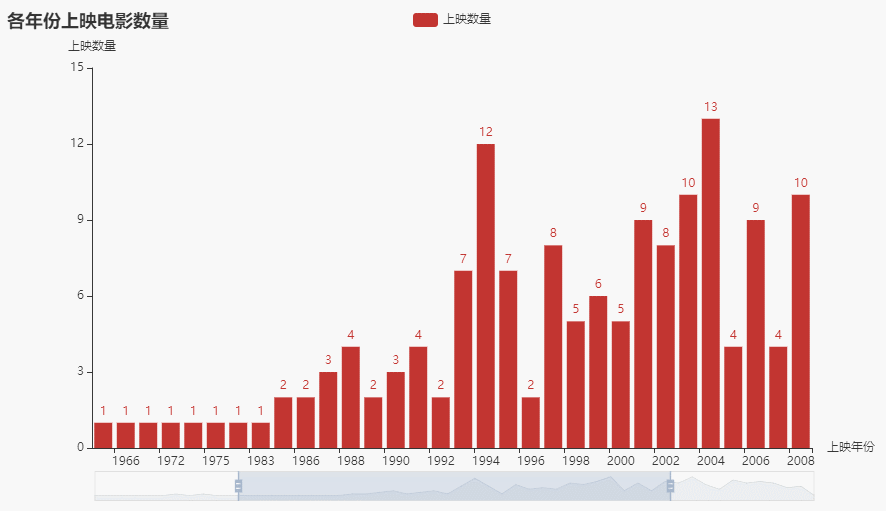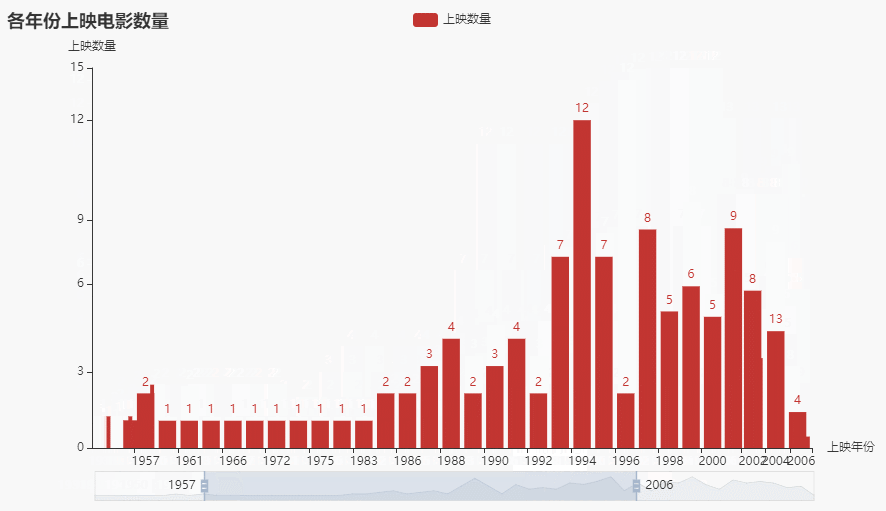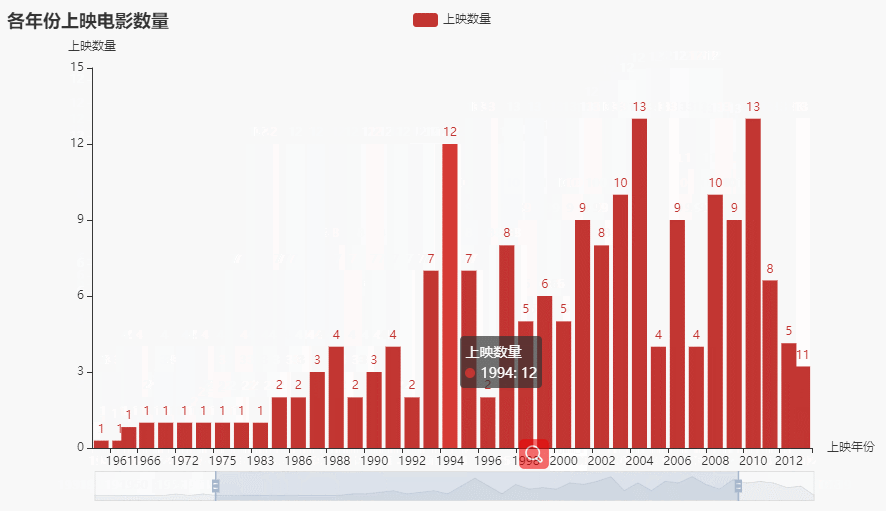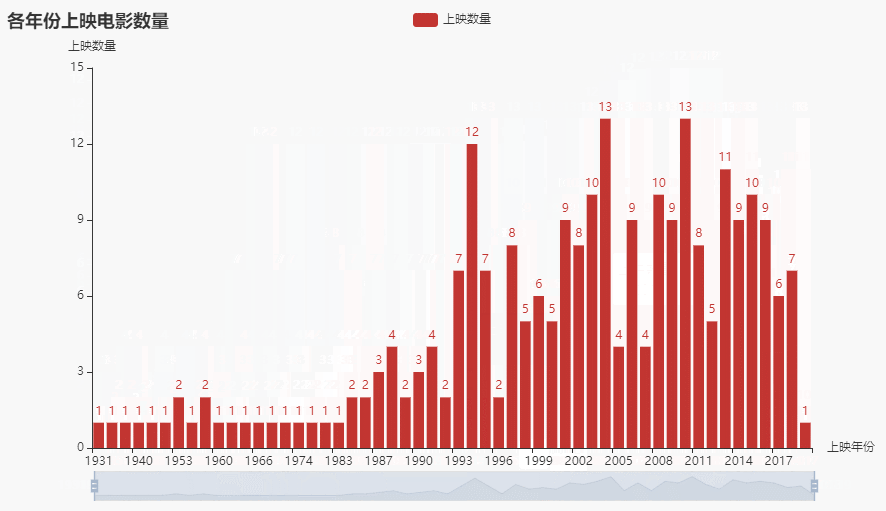
2.3 各地区上映电影数量前十柱状图(横向)
代码:
def getcountrybar(data):country_counts = data['国家/地区'].value_counts()country_counts.columns = ['国家/地区', '数量']country_counts = country_counts.sort_values(ascending=True)c = (Bar().add_xaxis(list(country_counts.index)[-10:]).add_yaxis('地区上映数量', country_counts.values.tolist()[-10:]).reversal_axis().set_global_opts(title_opts=opts.TitleOpts(title='地区上映电影数量'),yaxis_opts=opts.AxisOpts(name='国家/地区'),xaxis_opts=opts.AxisOpts(name='上映数量'),).set_series_opts(label_opts=opts.LabelOpts(position="right")).render('各地区上映电影数量前十.html'))
效果:

2.4 电影评价人数前二十柱状图(横向)
代码:
def getscorebar(data):df = data.sort_values(by='评价人数', ascending=True)c = (Bar().add_xaxis(df['片名'].values.tolist()[-20:]).add_yaxis('评价人数', df['评价人数'].values.tolist()[-20:]).reversal_axis().set_global_opts(title_opts=opts.TitleOpts(title='电影评价人数'),yaxis_opts=opts.AxisOpts(name='片名'),xaxis_opts=opts.AxisOpts(name='人数'),datazoom_opts=opts.DataZoomOpts(type_='inside'),).set_series_opts(label_opts=opts.LabelOpts(position="right")).render('电影评价人数前二十.html'))
效果:

可视化项目源码+数据
网盘: https://pan.baidu.com/doc/share/Olj4d~aKuXT7AF0cq01MrQ-437060019167360
提取码: pyra
以上就是本期为大家整理的全部内容了,赶快练习起来吧,原创不易,喜欢的朋友可以点赞、收藏也可以分享让更多人知道哦










![2021年中国游戏行业发展现状及行业发展趋势分析[图]](https://img-blog.csdnimg.cn/img_convert/55d0d2a4faa6476b0864409b0a89268b.png)


