文章目录
- 1. 第一章 简介
- 1.1 机器学习(Machine Learning)
- 1.2 有监督学习(Supervised Learning)
- 1.3 无监督学习(Unsupervised Learning)
- 2. 第二章 线性回归(Linear Regression)
- 2.1 假设函数(hypothesis)
- 2.2 代价函数(cost function)
- 2.3 简化(Simplified)
- 2.4 重新加入 θ 0 {\theta _0} θ0分析
- 2.5 梯度下降(Gradient descent)
- 2.6 梯度下降总结
- 2.7 线性回归梯度下降
- 3. 第三章 线性代数基础
- 3.1 矩阵和向量(Matrices and vectors)
- 3.2 矩阵加减与标量(scalar)运算
- 3.3 矩阵向量乘法
- 3.4 矩阵乘法
- 3.5 矩阵乘法特征
- 3.6 逆和转置
- 4. 第四章 多元线性回归
- 4.1 多元特征
- 4.2 多元变量梯度下降
- 4.3 多元变量梯度下降:特征缩放(Feature Scaling)
- 4.4 多元变量梯度下降:学习率 α \alpha α
- 4.5 特征和多项式回归
- 4.6 正规方程(Normal equation)解析解法
- 4.7 正规方程:不可逆矩阵
- 5. 第五章 Octave基础
1. 第一章 简介
1.1 机器学习(Machine Learning)
机器学习:研究能够从经验中自动提升自身性能的计算机算法。
从数学角度:机器学习就是从数据中学习一个函数𝑓 。
机器学习:能过从针对任务T的一些经验E和性能指标P中学习的计算机程序。同时它在任务T上的表现可以通过性能指标P来提高。
1.2 有监督学习(Supervised Learning)
给出“正确答案”。
回归(Regression):输出连续的值。
分类(Classification):输出离散的值。
1.3 无监督学习(Unsupervised Learning)
不给出任何标签,找到数据中暗含的结构或信息。
聚类算法(Clustering):
- 组织计算集群
- 社交网络分析
- 市场分割
- 天文数据分析
2. 第二章 线性回归(Linear Regression)
2.1 假设函数(hypothesis)
h:hypothesis假设函数: h θ ( x ) = θ 0 + θ 1 x {h_\theta }(x) = {\theta _0} + {\theta _1x} hθ(x)=θ0+θ1x,其中 θ 0 , θ 1 {\theta _0},{\theta _1} θ0,θ1表示要学习的参数。
2.2 代价函数(cost function)
cost function代价函数
目标:选出 θ 0 , θ 1 {\theta _0},{\theta _1} θ0,θ1使得在训练集上,给出 x x x能够合理准确地预测出 y y y的值。
学习目标:
m i n i m i z e θ 0 θ 1 1 2 m ∑ i = 1 m ( h θ ( x i ) − y i ) 2 \mathop {minimize}\limits_{{\theta _0}{\theta _1}} {1 \over {2m}}\sum\limits_{i = 1}^m {{{({h_\theta }({x_i}) - {y_i})}^2}} θ0θ1minimize2m1i=1∑m(hθ(xi)−yi)2
其中 ( x i , y i ) ({x_i},{y_i}) (xi,yi)表示第 i i i个样本; m m m表示样本总数。(之所以乘以 1 2 {1 \over 2} 21是为了方便求导)
令: J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( h θ ( x i ) − y i ) 2 J({\theta _0},{\theta _1}) = {1 \over {2m}}\sum\limits_{i = 1}^m {{{({h_\theta }({x_i}) - {y_i})}^2}} J(θ0,θ1)=2m1i=1∑m(hθ(xi)−yi)2
目标函数简写为: m i n i m i z e θ 0 θ 1 J ( θ 0 , θ 1 ) \mathop {minimize}\limits_{{\theta _0}{\theta _1}} J({\theta _0},{\theta _1}) θ0θ1minimizeJ(θ0,θ1)
m i n i m i z e \mathop {minimize} minimize:表示使得后面式子最小时, θ 0 , θ 1 {\theta _0},{\theta _1} θ0,θ1的取值。
J ( θ 0 , θ 1 ) J({\theta _0},{\theta _1}) J(θ0,θ1)称为:代价函数(cost function),优化目标(optimization objective)。
小提示: 损失函数“(Loss Function )是定义在单个样本上的,算的是一个样本的误差,而代价函数(Cost Function )是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。
2.3 简化(Simplified)
h θ ( x ) = θ 1 x {h_\theta }(x) = {\theta _1}x hθ(x)=θ1x假设 θ 0 = 0 {\theta _0}=0 θ0=0
J ( θ 0 , θ 1 ) → J ( θ 1 ) J({\theta _0},{\theta _1}) \to J({\theta _1}) J(θ0,θ1)→J(θ1)
2.4 重新加入 θ 0 {\theta _0} θ0分析
假设函数: h θ ( x ) = θ 0 + θ 1 x {h_\theta }(x) = {\theta _0} + {\theta _1}x hθ(x)=θ0+θ1x
可学习参数: θ 0 , θ 1 {\theta _0},{\theta _1} θ0,θ1
损失函数: J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( h θ ( x i ) − y i ) 2 J({\theta _0},{\theta _1}) = {1 \over {2m}}\sum\limits_{i = 1}^m {{{({h_\theta }({x_i}) - {y_i})}^2}} J(θ0,θ1)=2m1i=1∑m(hθ(xi)−yi)2
目标: m i n i m i z e θ 0 θ 1 J ( θ 0 , θ 1 ) \mathop {minimize}\limits_{{\theta _0}{\theta _1}} J({\theta _0},{\theta _1}) θ0θ1minimizeJ(θ0,θ1)
2.5 梯度下降(Gradient descent)
问题描述:
有一些函数如: J ( θ 0 , θ 1 ) J({\theta _0},{\theta _1}) J(θ0,θ1),想要 m i n i m i z e θ 0 θ 1 J ( θ 0 , θ 1 ) \mathop {minimize}\limits_{{\theta _0}{\theta _1}} J({\theta _0},{\theta _1}) θ0θ1minimizeJ(θ0,θ1)。
解决步骤:
- 设置 θ 0 , θ 1 {\theta _0},{\theta _1} θ0,θ1初值通常为 0 0 0
- 改变 θ 0 , θ 1 {\theta _0},{\theta _1} θ0,θ1(通常以较小值改变)减少 J ( θ 0 , θ 1 ) J({\theta _0},{\theta _1}) J(θ0,θ1)直到我们希望的最小值(可以找到一个局部最小值)
梯度下降算法:
repeat until convergence{ θ j : = θ j − α ∂ ∂ θ j J ( θ 0 , θ 1 ) {\theta _j}: = {\theta _j} - \alpha {\partial \over {\partial {\theta _j}}}J({\theta _0},{\theta _1}) θj:=θj−α∂θj∂J(θ0,θ1)(for j=0 and j=1)}
α \alpha α:学习率(learning rate)
注意:同时更新参数 θ 0 , θ 1 {\theta _0},{\theta _1} θ0,θ1
2.6 梯度下降总结
θ j : = θ j − α ∂ ∂ θ j J ( θ 0 , θ 1 ) {\theta _j}: = {\theta _j} - \alpha {\partial \over {\partial {\theta _j}}}J({\theta _0},{\theta _1}) θj:=θj−α∂θj∂J(θ0,θ1)
α \alpha α:过小,收敛慢;过大,可能发散,不收敛。
梯度下降可以收敛到局部最小值,即使学习率 α \alpha α固定。
当我们接近局部最小值,梯度下降将要自动得到一个较小的步长。所以,不需要随时间减少学习率 α \alpha α。
2.7 线性回归梯度下降
最小化线性回归中的平方损失函数。
∂ ∂ θ j J ( θ 0 , θ 1 ) = ∂ ∂ θ j 1 2 m ∑ i = 1 m ( h θ ( x i ) − y i ) 2 = ∂ ∂ θ j 1 2 m ∑ i = 1 m ( θ 0 + θ 1 x i − y i ) 2 {\partial \over {\partial {\theta _j}}}J({\theta _0},{\theta _1}) = {\partial \over {\partial {\theta _j}}}{1 \over {2m}}\sum\limits_{i = 1}^m {{{({h_\theta }({x_i}) - {y_i})}^2}}= {\partial \over {\partial {\theta _j}}}{1 \over {2m}}\sum\limits_{i = 1}^m {{{({\theta _0} + {\theta _1}{x_i} - {y_i})}^2}} ∂θj∂J(θ0,θ1)=∂θj∂2m1i=1∑m(hθ(xi)−yi)2=∂θj∂2m1i=1∑m(θ0+θ1xi−yi)2
θ 0 {{\theta _0}} θ0: j = 0 j=0 j=0, ∂ ∂ θ 0 J ( θ 0 , θ 1 ) = 1 m ∑ i = 1 m ( h θ ( x i ) − y i ) {\partial \over {\partial {\theta _0}}}J({\theta _0},{\theta _1}) = {1 \over m}\sum\limits_{i = 1}^m {{{({h_\theta }({x_i}) - {y_i})}^{}}} ∂θ0∂J(θ0,θ1)=m1i=1∑m(hθ(xi)−yi)
θ 1 {{\theta _1}} θ1: j = 1 j=1 j=1, ∂ ∂ θ 1 J ( θ 0 , θ 1 ) = 1 m ∑ i = 1 m ( h θ ( x i ) − y i ) x i {\partial \over {\partial {\theta _1}}}J({\theta _0},{\theta _1}) = {1 \over m}\sum\limits_{i = 1}^m {{{({h_\theta }({x_i}) - {y_i})}^{}}} {x_i} ∂θ1∂J(θ0,θ1)=m1i=1∑m(hθ(xi)−yi)xi
同时更新:
θ 0 : = θ 0 − α 1 m ∑ i = 1 m ( h θ ( x i ) − y i ) {\theta _0}: = {\theta _0} - \alpha {1 \over m}\sum\limits_{i = 1}^m {{{({h_\theta }({x_i}) - {y_i})}^{}}} θ0:=θ0−αm1i=1∑m(hθ(xi)−yi)
θ 1 : = θ 1 − α 1 m ∑ i = 1 m ( h θ ( x i ) − y i ) x i {\theta _1}: = {\theta _1} - \alpha {1 \over m}\sum\limits_{i = 1}^m {{{({h_\theta }({x_i}) - {y_i})}^{}}} {x_i} θ1:=θ1−αm1i=1∑m(hθ(xi)−yi)xi
小提示:凸函数(convex function):只要一个全局最优
批量梯度下降:每次梯度下降使用所有的训练样本(虽然名字有点歧义)。
3. 第三章 线性代数基础
3.1 矩阵和向量(Matrices and vectors)
矩阵(Matrix)是一个按照长方阵列排列的复数或实数集合。
矩阵维数:行数*列数
A A A:矩阵, A i j {A_{ij}} Aij:表示第 i i i行第 j j j列的元素。
向量: n ∗ 1 n*1 n∗1的矩阵
y y y:向量,n-dimension 向量
3.2 矩阵加减与标量(scalar)运算
两个行列相等的矩阵才可以相加减:对应元素相加减
标量同一个矩阵相加减乘除:标量与每个元素分别运算,矩阵维数不变
3.3 矩阵向量乘法
A m × n × x n × 1 = y m × 1 {A_{m \times n}} \times {x_{n \times 1}} = {y_{m \times 1}} Am×n×xn×1=ym×1
y i {y_{i}} yi通过 A A A的第 i i i行与向量 x x x对应元素相乘再相加得到。
3.4 矩阵乘法
A m × n × B n × o = C m × o {A_{m \times n}} \times {B_{n \times o}} = {C_{m \times o}} Am×n×Bn×o=Cm×o
矩阵 C C C的第 i i i列是通过矩阵 A A A和矩阵 B B B的第 i i i列相乘得到的。
3.5 矩阵乘法特征
- A B = B A AB=BA AB=BA
- A × B × C = ( A × B ) × C = A × ( B × C ) A \times B \times C = (A \times B) \times C = A \times (B \times C) A×B×C=(A×B)×C=A×(B×C)
- 单位矩阵( I o r I n × n I or {I_{n \times n}} IorIn×n)满足 I i i = 1 {I_{ii}}=1 Iii=1, I I I可以根据需要取不同的维数,如 A m × n × I n × n = I m × m × A m × n = A {A_{m \times n}} \times {I_{n \times n}} = {I_{m \times m}} \times {A_{m \times n}} = A Am×n×In×n=Im×m×Am×n=A
3.6 逆和转置
矩阵的逆:方阵才有逆,满足 A m × m {A_{m \times m}} Am×m A A − 1 = A − 1 A = I A{A^{ - 1}} = {A^{ - 1}}A = I AA−1=A−1A=I
没有逆的矩阵:奇异矩阵(singular),退化矩阵(degenerate)
矩阵的转置:
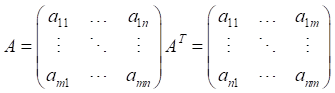
4. 第四章 多元线性回归
4.1 多元特征
多元特征:特征数大于2
n n n表示特征数量; x ( i ) {x^{(i)}} x(i)表示第 i i i个训练样本的所有输入特征; x j ( i ) x_j^{(i)} xj(i)表示第 i i i个训练样本的第 j j j个输入特征。
假设函数: h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n {h_\theta }(x) = {\theta _0} + {\theta _1}{x_1} + {\theta _2}{x_2} + ... + {\theta _n}{x_n} hθ(x)=θ0+θ1x1+θ2x2+...+θnxn
令 X ∈ R n + 1 X \in {R^{n + 1}} X∈Rn+1, θ ∈ R n + 1 \theta \in {R^{n + 1}} θ∈Rn+1, X 0 = 1 {X_0} = 1 X0=1则化简公式为: h θ ( x ) = θ 0 x 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n = θ T x {h_\theta }(x) = {\theta _0}{x_0} + {\theta _1}{x_1} + {\theta _2}{x_2} + ... + {\theta _n}{x_n} = {\theta ^T}x hθ(x)=θ0x0+θ1x1+θ2x2+...+θnxn=θTx
4.2 多元变量梯度下降
假设函数: h θ ( x ) = θ 0 x 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n = θ T x {h_\theta }(x) = {\theta _0}{x_0} + {\theta _1}{x_1} + {\theta _2}{x_2} + ... + {\theta _n}{x_n} = {\theta ^T}x hθ(x)=θ0x0+θ1x1+θ2x2+...+θnxn=θTx
可学习参数: θ 0 , θ 1 , . . . θ n {\theta _0},{\theta _1},...{\theta _n} θ0,θ1,...θn,其中 θ ∈ R n + 1 \theta \in {R^{n + 1}} θ∈Rn+1
损失函数: J ( θ 0 , θ 1 , . . . θ n ) = 1 2 m ∑ i = 1 m ( h θ ( x i ) − y i ) 2 = J ( θ ) J({\theta _0},{\theta _1},...{\theta _n}) = {1 \over {2m}}\sum\limits_{i = 1}^m {{{({h_\theta }({x_i}) - {y_i})}^2}} =J({\theta }) J(θ0,θ1,...θn)=2m1i=1∑m(hθ(xi)−yi)2=J(θ)
参数更新: θ j : = θ j − α ∂ ∂ θ j J ( θ ) 其 中 ( j = 0 , 1 , . . . , n ) {\theta _j}: = {\theta _j} - \alpha {\partial \over {\partial {\theta _j}}}J({\theta})其中(j=0,1,...,n) θj:=θj−α∂θj∂J(θ)其中(j=0,1,...,n)
- 当 n > = 1 n>=1 n>=1时, θ j : = θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) {\theta _j}: = {\theta _j} - \alpha {1 \over m}\sum\limits_{i = 1}^m {{{({h_\theta }({x^{(i)}}) - {y^{(i)}})}^{}}} x_j^{(i)} θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i)
- 当 n = = 1 n==1 n==1时, θ 0 : = θ 0 − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) {\theta _0}: = {\theta _0} - \alpha {1 \over m}\sum\limits_{i = 1}^m {{{({h_\theta }({x^{(i)}}) - {y^{(i)}})}^{}}} θ0:=θ0−αm1i=1∑m(hθ(x(i))−y(i))
4.3 多元变量梯度下降:特征缩放(Feature Scaling)
思想:确保所有特征数值在相似地范围。这样可以走一条相对简单的路径到最优解,要求特征值组之间取值范围相差不大,默认 − 1 ≤ x i ≤ 1 -1 \le {x_i} \le 1 −1≤xi≤1。
做法:均值归一化(Mean normalization)。使用 x i − μ i {x_i} - {\mu _i} xi−μi代替 x i {x_i} xi 确保 0 0 0均值。
x i ← x i − μ i S i {x_i} \leftarrow {{{x_i} - {\mu _i}} \over {{S_i}}} xi←Sixi−μi,其中 μ i {{\mu _i}} μi表示该特征均值, S i {{S_i}} Si表示取值范围(最大值减去最小值)
4.4 多元变量梯度下降:学习率 α \alpha α
如何判断梯度下降算法是否正确工作?
若正常工作在每次迭代后, J ( θ ) J(\theta ) J(θ)都应该减少,可以绘制 J ( θ ) J(\theta ) J(θ)随迭代次数变化的函数判断。
自动收敛测试(automatic convergence test):每次迭代后 J ( θ ) J(\theta ) J(θ)下降的值超过 ε ( 小 正 数 如 : 1 0 − 3 ) \varepsilon (小正数如:{10^{ - 3}}) ε(小正数如:10−3)。
如果未正常工作可以使用更小的 α \alpha α。
对于足够小的 α \alpha α, J ( θ ) J(\theta ) J(θ)应该每次迭代均会下降,但是如果 α \alpha α太小,则会导致收敛速度太慢。
如何选择 α \alpha α?
. . . , 0.001 , 0.003 , 0.01 , 0.03 , 0.1 , 0.3 , 1... ...,0.001,0.003,0.01,0.03,0.1,0.3,1... ...,0.001,0.003,0.01,0.03,0.1,0.3,1...,采用3倍策略(经验)
4.5 特征和多项式回归
例: θ 0 + θ 1 x + θ 2 x 2 + θ 3 x 3 {\theta _0} + {\theta _1}x + {\theta _2}{x^2} + {\theta _3}{x^3} θ0+θ1x+θ2x2+θ3x3映射到多元线性回归 h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + θ 3 x 3 {h_\theta }(x) = {\theta _0} + {\theta _1}{x_1} + {\theta _2}{x_2} + {\theta _3}{x_3} hθ(x)=θ0+θ1x1+θ2x2+θ3x3可以用少量特征学习更加复杂的关系。
x 1 = ( s i z e ) , x 2 = ( s i z e ) 2 , x 3 = ( s i z e ) 3 {x_1} = (size),{x_2} = {(size)^2},{x_3} = {(size)^3} x1=(size),x2=(size)2,x3=(size)3,这时特征缩放更为重要。
4.6 正规方程(Normal equation)解析解法
自觉:对于一维的情况,好像在 J ( θ ) J(\theta ) J(θ)导数为0时可以取得最优解。
J ( θ 0 , θ 1 , . . . , θ n ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 , θ ∈ R n + 1 J({\theta _0},{\theta _1},...,{\theta _n}) = {1 \over {2m}}\sum\limits_{i = 1}^m {{{({h_\theta }({x^{(i)}}) - {y^{(i)}})}^2}} ,\theta \in {R^{n + 1}} J(θ0,θ1,...,θn)=2m1i=1∑m(hθ(x(i))−y(i))2,θ∈Rn+1
∂ ∂ θ j J ( θ ) = . . . = 0 {\partial \over {\partial {\theta _j}}}J(\theta ) = ... = 0 ∂θj∂J(θ)=...=0
对于 θ 0 , θ 1 , . . . , θ n {\theta _0},{\theta _1},...,{\theta _n} θ0,θ1,...,θn,可得 θ = ( X T X ) − 1 X T y \theta = {({X^T}X)^{ - 1}}{X^T}y θ=(XTX)−1XTy,其中 X ∈ R m × ( n + 1 ) X \in {R^{m \times (n + 1)}} X∈Rm×(n+1)
无需特征缩放。
梯度下降 V S VS VS正规方程
梯度下降 :
- 需要学习率 α \alpha α
- 需要多次迭代
- 当 n n n很大时工作的好
正规方程:
- 不需要学习率 α \alpha α
- 不需要迭代
- 需要计算矩阵 X T X {X^T}X XTX的逆,而该矩阵是 n × n n \times n n×n维的。对于大多数计算机来说,逆矩阵的计算是 o ( n 3 ) {\rm{o}}({n^3}) o(n3)的
- 当 n n n很大时很慢( 1 0 4 {10^4} 104)
4.7 正规方程:不可逆矩阵
如果 θ = ( X T X ) − 1 X T y \theta = {({X^T}X)^{ - 1}}{X^T}y θ=(XTX)−1XTy无法求逆,则可以求伪逆(大多数求逆矩阵的库,在矩阵不可逆时,自动返回伪逆)。
为什么 X T X {X^T}X XTX不可逆?
- 多余的特征:存在特征间的线性依赖
- 太多的特征( m ≤ n m \le n m≤n)
X T X {X^T}X XTX不可逆的解决方案:删除一些特征,或者进行正则化。
5. 第五章 Octave基础
主要讲解 Octave语言,但是人生苦短,我选python,跳过!!!