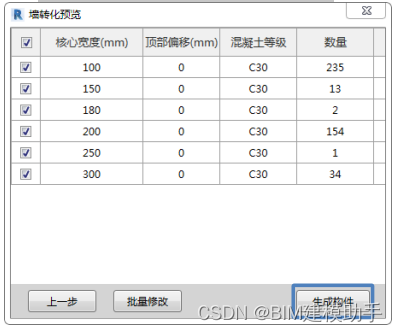
目录
- 模型量化原理
- 注意事项
- 一、2023/4/11更新
- 二、2023/4/13更新
- 三、2023/4/16更新
- 四、2023/4/24更新
- 前言
- 1.前情回顾
- 2.动态范围的常用计算方法
- 3.Histogram
- 3.1 定义
- 3.2 histogram实现
- 3.3 思考
- 3.4 拓展
- 4.Entropy
- 4.1 定义
- 4.2 示例代码
- 4.3 流程实现
- 4.4 思考
- 4.5 实际应用
- 4.6 TRT Entropy Calibration
- 4.6.1 伪代码
- 4.6.2 示例代码
- 5. 代码分析
- 总结
模型量化原理
注意事项
一、2023/4/11更新
新增Entropy方法计算动态范围
二、2023/4/13更新
新增Entropy方法在实际应用场景中的使用
三、2023/4/16更新
新增P和Q分布bin不能整除的情形处理以及工程实践中tensorRT的Entropy Calibration方法
四、2023/4/24更新
和别人交流之后发现自己对 Entropy 选取动态范围的计算方法依旧是似懂非懂,结合 chatGPT 重新 debug 撸了一遍代码,新增对 TRT Entropy Calibration 示例代码的简单分析(第 5 节内容)
前言
手写AI推出的全新TensorRT模型量化课程,链接。记录下个人学习笔记,仅供自己参考。
本次课程为第三课,主要讲解动态范围的常用计算方法。
课程大纲可看下面的思维导图

1.前情回顾
在之前的课程中我们学习了对称量化和非对称量化的知识,在tensorRT中的INT8量化使用的方法就是对称量化。上节课提出在对称量化中存在一个问题,就是当数据中存在极端值时,会对量化精度造成不利影响,这节课我们就一起来学习相关解决方案。
2.动态范围的常用计算方法
首先来看下本次课程的题目,动态范围的常用计算方法,之前似乎没有提过呀,有点抽象(🤔)。
动态范围(Dynamic Range)指的是输入数据中数值的范围,计算动态范围是为了确定量化时使用的比特位数(还是抽象😂)。个人理解计算动态范围就是为了获得更好的Scale,毕竟Scale会影响到整个量化的精度,而Scale的计算和输入数据的值域范围息息相关(即值域的动态范围),在上节课中非对称量化过程中Scale计算为 S c a l e = ( R m a x − R m i n ) ( Q m a x − Q m i n ) Scale = \frac{(Rmax-Rmin)}{(Qmax-Qmin)} Scale=(Qmax−Qmin)(Rmax−Rmin),而对称量化过程中的Scale计算为 S c a l e = ∣ R m a x ∣ Q m a x Scale = \frac{|Rmax|}{Qmax} Scale=Qmax∣Rmax∣,都与输入数据的数值范围相关。
现在来看看动态范围的计算方法,动态范围的计算方法与量化的方式相关,对称量化和非对称量化使用的计算方法略有不同。在对称量化中,通常采用的是
输入数据的绝对值的最大值作为动态范围的计算方法;而在非对称量化中,通常采用最小值和最大值的差作为动态范围的计算方法。经过上面分析就不难理解题目动态范围的常用计算方法,在之前对称量化中的动态范围的计算方法就是
Max方法即采取输入数据的绝对值的最大值,但是这种计算方法存在问题,就是容易受到离散点即噪声的干扰,我们的考虑改进,或者说采取其它的动态范围计算方法,也就是本节课程的Histogram以及Entropy方法。
常用的动态范围计算方法包括:(from chatGPT)
- Max方法:在对称量化中直接取输入数据中的绝对值的最大值作为量化的最大值。这种方法简单易用,但容易受到噪声等异常数据的影响,导致动态范围不准确。
- Histogram方法:统计输入数据的直方图,根据先验知识获取某个范围内的数据,从而获得对称量化的最大值。这种方法可以减少噪声对动态范围的影响,但需要对直方图进行统计,计算复杂度较高。
- Entropy方法:将输入数据的概率密度函数近似为一个高斯分布,以最小化熵作为选择动态范围的准则。这种方法也可以在一定程度上减少噪声对动态范围的影响,但需要对概率密度函数进行拟合和计算熵,计算复杂度较高。
对称量化和非对称量化的选择与动态范围的计算方法有一定的关系。对称量化要求量化的最大值和最小值的绝对值相等,可以采用Max方法或Histogram方法进行计算。非对称量化则可以采用Entropy方法进行计算,以最小化量化后的误差。
3.Histogram
3.1 定义
直方图(histogram)是统计学中常用的一种图形,它将数据按照数值分组并统计每组数据的出现频率,然后将频率用柱状图的方式表示出来。直方图通常用于描述一组数据的分布情况,可以帮助人们了解数据的特征,例如数据的中心位置、离散程度、对称性、峰态等(from chatGPT)
下面是一张直方图的示例:

下面是该直方图生成的示例代码:
import numpy as np
import matplotlib.pyplot as pltdata = np.random.randn(1000)plt.hist(data, bins=50)plt.title("histgram")
plt.xlabel("value")
plt.ylabel("freq")
# plt.savefig("histgram.png", bbox_inches="tight")
plt.show()
在上述代码中首先使用numpy生成了一组包含1000个随机数的数据,然后调用matplotlib库中的plt.hist()函数生成该数据的直方图。其中data参数表示要绘制的数据,bins表示直方图的柱子数量,这里设置为50个。
3.2 histogram实现
histogram方法为什么能克服Max方法中离散点即噪声干扰问题呢?主要在于直方图统计了数据出现的频率,它可以将数据按照一定的区间进行离散化处理,并计算每个区间中数据点的数量。这种方法相对于Max方法来说,能够更好地反映数据的分布情况,从而更准确地评估数据的动态范围。我们假设数据服从正态分布,即离散点在两边,我们可以通过从两边向中间靠拢的方法,去除离散点,类似于双指针的方法,算法具体流程如下:
- 首先,统计输入数据的直方图和范围
- 然后定义左指针和右指针分别指向直方图的左边界和右边界
- 计算当前双指针之间的直方图覆盖率,如果小于等于设定的覆盖率阈值,则返回此刻的左指针指向的直方图值,如果不满足,则需要调整双指针的值,向中间靠拢
- 如果当前左指针所指向的直方图值大于右指针所指向的直方图值,则右指针左移,否则左指针右移
- 循环,直到双指针覆盖的区域满足要求
下面是该算法流程的一个简单示例:

其中0~5代表算法执行的步骤,首先双指针位于直方图的左右区间,然后计算其覆盖率发现不满足设定的阈值要求,计算此时的左指针的直方图值小于右指针的直方图值,左指针右移即步骤1,继续上述步骤发现覆盖率还是不满足,且此时右指针值小故右指针左移即步骤2,以此类推到步骤3、步骤4,到步骤4计算发现覆盖率满足阈值要求,故将此时的双指针的直方图值的绝对值返回即可。
通过上面的分析,示例代码如下:
def scale_cal(x):max_val = np.max(np.abs(x))return max_val / 127def histogram_range(x):hist, range = np.histogram(x, 100)total = len(x)left = 0right = len(hist) - 1limit = 0.99while True:cover_percent = hist[left:right].sum() / totalif cover_percent <= limit:breakif hist[left] > hist[right]:right -= 1else:left += 1left_val = range[left]right_val = range[right]dynamic_range = max(abs(left_val), abs(right_val))return dynamic_range / 127if __name__ == "__main__":np.random.seed(1)data_float32 = np.random.randn(1000).astype('float32')# print(f"input = {data_float32}")scale = scale_cal(data_float32)scale2 = histogram_range(data_float32)print(f"scale = {scale} scale2 = {scale2}")
上述代码中histogram_range函数是基于数据直方图计算缩放因子的,该函数先将数据进行直方图统计,然后使用双指针算法去除数据直方图中的离散点,最后通过剩余数据的动态范围计算出缩放因子。
3.3 思考
Histogram方法虽然能够解决Max方法中的离散点噪声问题,但是使用数据直方图进行动态范围的计算,要求数据能够比较均匀地覆盖到整个动态范围内。如果数据服从类似正态分布,则直方图的结果具有参考价值,因为此时的数据覆盖动态范围的概率较高。但如果数据分布极不均匀或出现大量离散群,则直方图计算的结果可能并不准确。此时可考虑其它的动态范围计算方法。
3.4 拓展
np.histogram是用于生成直方图的函数,其参数和返回值如下:
参数:
a:待处理的数据,可以是一维或者多维数组,多维数组将会被展开成一维数组bins:表示数据分成的区间数range:表示数据的取值范围,可以是一个元组或数组density:是否将直方图归一化。如果为True,直方图将归一化为概率密度函数。默认Falseweights:每个数据点的权重,可以是一维数组或与a数组相同的形状的数组。默认为None,表示所有的数据点权重相同。
返回值:
hist:一个长度为bins的一维数组,表示每个区间中数据点的数量或者归一化后的概率密度值。bin_edges:长度为bins + 1的一维数组,表示每个区间的边界。
4.Entropy
4.1 定义
Entropy方法是一种基于概率分布的动态范围计算方法,通过计算概率分布之间的KL散度来选择合适的动态范围。
在量化领域中,通常所用的熵(Entropy)是指量化后的输出值的熵,即量化后的概率分布。因此,使用熵方法计算动态范围就是在计算量化后的概率分布。那么我们该如何度量量化前后的误差呢?可以使用KL散度。
在概率论或信息论中,KL散度(Kullback-Leibler divergence)又称为相对熵(relative entropy),是描述两个概率分布P和Q差异的一种方法。
D K L = ∑ i P ( x i ) l o g ( P ( x i ) Q ( x i ) ) D_{KL}=\sum_i P(x_i)log(\dfrac{P(x_i)}{Q(x_i)}) DKL=i∑P(xi)log(Q(xi)P(xi))
KL散度值越小,代表两种分布越相似,量化误差越小;反之,KL散度值越大,代表二种分布差异越大,量化误差越大。
4.2 示例代码
下面是通过生成的两组随机数据使用Entropy方法估计数据的动态范围的示例代码:
import numpy as np
import matplotlib.pyplot as pltdef cal_kl(p, q):KL = 0for i in range(len(p)):KL += p[i] * np.log(p[i]/q[i])return KLdef kl_test(x, kl_threshod = 0.01):y_out = []while True:y = [np.random.uniform(1, size+1) for i in range(size)]y /= np.sum(y)kl_result = cal_kl(x, y)if kl_result < kl_threshod:print(kl_result)y_out = yplt.plot(x)plt.plot(y)breakreturn y_outif __name__ == "__main__":np.random.seed(1)size = 10x = [np.random.uniform(1, size+1) for i in range(size)]x /= np.sum(x)y_out = kl_test(x, kl_threshod = 0.01)plt.show()print(x, y_out)
在上述示例代码中,具体实现过程如下:
- 首先定义了一个计算KL散度的函数
cal_kl,用于计算两个概率分布P和Q之间的KL散度 - 然后定义了一个
kl_test函数,用于使用Entropy方法来估计数据的动态范围。在kl_test中,先随机生成概率分布y,将其归一化后计算与输入的概率分布x之间的KL散度,如果小于阈值,则认为当前的概率分布y最优,结束迭代。否则继续生成一个新的随机概率分布y,重复KL散度计算,直到找到满足条件的最优概率分布 - 最后返回找到的最优概率分布y,并可视化原始数据分布x和最优概率分布y的差异
下面是KL散度阈值为0.01时原始数据x(蓝色)和最优概率分布y(橙色)的可视化图,可以看到此时的x和y的分布比较接近:

4.3 流程实现
利用Entropy来计算动态范围的流程如下:
1.统计直方图分布。首先,对于待量化的数据,统计其数值分布情况,得到数据的直方图
2.生成 p p p分布。
3.计算 q q q分布。
4.归一化 p p p和 q q q的分布。将 p p p和 q q q的概率分布进行归一化,使其满足概率分布的性质
5.计算 p p p和 q q q的KL散度。使用KL散度方法,计算 p p p和 q q q两个概率分布之间的距离,作为衡量量化误差的指标。KL散度越小表示两个分布越相似,因此在动态范围的选择中,KL散度越小的分布更加合适
Entropy方法中使用了直方图和概率分布的方法来简化计算。
4.4 思考
疑问:Entropy方法是怎么选取动态范围的呢?好像只是在计算KL散度来描述量化前后分布的差异🤔
对于使用Entropy方法选择动态范围,其一般流程是先统计原始数据的分布直方图,并将直方图转化为概率分布 p p p。然后通过计算KL散度,寻找最优的量化分布 q q q,最后根据 q q q的范围确定量化后的动态范围。
在计算KL散度时,如果 q q q的范围是 [ q m i n , q m a x ] [q_{min},q_{max}] [qmin,qmax],则可以通过搜索在这个范围内的分布 p p p来寻找最优的量化后分布 q q q。具体来说,可以枚举 q q q的分布区间内的分布概率,并计算与 p p p的KL散度,最后选取KL散度最小的分布作为 q q q。根据 q q q的范围,则可以得到最优的动态范围。
在量化中,动态范围通常指的是量化前的数据范围。在选择合适的量化参数(比如量化比特数)时,需要对原始数据的动态范围进行估计,以保证量化后的数据精度尽可能地高。
在量化操作中,动态范围通常是由P和Q两个概率分布的取值范围决定的。P分布表示原始数据在浮点数表示下的取值范围,Q分布则表示对应的量化数据的取值范围。因此,Entropy方法计算P和Q的KL散度,是为了得到最优的Q分布,而最优的Q分布代表量化数据的最优取值范围,量化数据的最优取值范围和原始数据的取值范围都知道了,那么最优的Scale就确定下来了。不论是非对称量化的 S c a l e = ( R m a x − R m i n ) ( Q m a x − Q m i n ) Scale = \frac{(Rmax-Rmin)}{(Qmax-Qmin)} Scale=(Qmax−Qmin)(Rmax−Rmin),还是对称量化的 S c a l e = ∣ R m a x ∣ Q m a x Scale = \frac{|Rmax|}{Qmax} Scale=Qmax∣Rmax∣
4.5 实际应用
在之前的分析中我们通过Entropy方法计算P和Q的KL散度来计算动态范围,其计算公式为:
D K L = ∑ i P ( x i ) l o g ( P ( x i ) Q ( x i ) ) D_{KL}=\sum_i P(x_i)log(\dfrac{P(x_i)}{Q(x_i)}) DKL=i∑P(xi)log(Q(xi)P(xi))
我们可以发现求取KL散度有一个大前提,那就是通过直方图统计的P和Q分布的bin要保持一致,而实际情况又不是这样的,比如说现实情况下假设P是FP32的概率分布,而Q是INT8的概率分布,由于FP32的数据量大,我们可以划分很细(如2048个bin),而INT8的bin数量固定,二者bin并不一致。
我们来看看TensorRT的解决方案,通过下面的示例说明:
假设我们的输入为[1,0,2,3,5,1,7]为8个bin,但Q只能用4个bin来表达,怎么操作才能让Q拥有和P一样的bin来描述呢?
- 1.数据划分:按照合并后的bin将输入划分为4份即[1,0],[2,3],[5,3],[1,7]
- 2.对划分的数据求和:sum = [1],[5],[8],[8]
- 3.统计划分的数据的非0个数:count = [1],[2],[2],[2]
- 4.求取平均:avg = sum / count = [1],[2.5],[4],[4]
- 5.反映射:非零区域用对应的均值区域填充即[1,0],[1,1],[1,1],[1,1] * [1],[2.5],[4],[4] = [1,0,2.5,2.5,4,4,4,4]
现在我们通过编写简单的代码进行实验验证,示例代码如下:
def smooth_data(p, eps = 0.0001):is_zeros = (p==0).astype(np.float32)is_nonzeros = (p!=0).astype(np.float32)num_zeros = is_zeros.sum()num_nonzeros = p.size - num_zeroseps1 = eps * num_zeros / num_nonzeroshist = p.astype(np.float32)hist += eps * is_zeros + (-eps1) * is_nonzerosreturn histdef smooth_data(p, eps = 0.0001):is_zeros = (p==0).astype(np.float32)is_nonzeros = (p!=0).astype(np.float32)num_zeros = is_zeros.sum()num_nonzeros = p.size - num_zeroseps1 = eps * num_zeros / num_nonzeroshist = p.astype(np.float32)hist += eps * is_zeros + (-eps) * is_nonzerosreturn histif __name__ == "__main__":p = [1, 0, 2, 3, 5, 3, 1, 7]bin = 4split_p = np.array_split(p, bin)q = []for arr in split_p:avg = np.sum(arr) / np.count_nonzero(arr)print(avg)for item in arr:if item != 0:q.append(avg)continueq.append(0)print(q)p /= np.sum(p)q /= np.sum(q)print(p)print(q)p = smooth_data(p)q = smooth_data(q)print(p)print(q)print(cal_kl(p, q))
有几个值得注意的点:
- 我们假设p是直方图统计的频次,其概率计算直接使用
p /= sum(p) - 在计算KL散度时,要保证
q(i) != 0,需要加上一个很小的正数eps - 由于p和q都是直方图统计的概率分布,它们的和始终为1,因此,单纯的在
q(i)==0时加上eps是行不通的,要在其他时刻同时减去一个数,确保最终的概率和为1。smooth_data就是帮我们干这么一件事情。
在之前我们讲解了通过Entropy方法计算P和Q的KL散度从而来计算动态范围,我们可以发现求取KL散度有一个大前提,那就是通过直方图统计的P和Q分布的bin要保持一致,而实际情况是不一致的,上节课分析了P和Q分布的bin虽然不同但是可以被整除,这节课我们来分析不能被整除的情况。来看下如何解决的:
第一个示例(不能整除):
假设input_p=[1,0,2,3,5] dst_bis=4
1.计算stride
- stride = input.size / bin 取整
2.按照stride划分
- [1] [0] [2] [3]
[5](多余位)
3.判断每一位是否非零
- [1,0,1,1,1]
4.将多余位累加到最后整除的位置上,在上面多余位是[5],最后整除的位置上是[3],因此[5+3=8]进行替换
- [1] [0] [2] [8]
5.进行位扩展从而得到output_q
- 将4的结果和3的非零位进行一个映射得到最终的结果
- [1] [0] [2] [4] [4]
第二个示例(不能整除):
假设input_p=[1,0,2,3,5,6] dst_bins=4
1.计算stride
- stride = input.size / bin 取整
2.按照stride划分
- [1] [0] [2] [3]
[5][6](多余位)
3.判断每一位是否非零
- [1,0,1,1,1,1]
4.将多余位累加到最后整除的位置上,在上面多余位是[5]和[6],最后整除的位置上是[3],因此[5+6+3=14]进行替换
- [1] [0] [2] [14]
5.进行位扩展从而得到output_q
- 将4的结果和3的非零位进行一个映射得到最终的结果
- [1] [0] [2] [4.67] [4.67] [4.67]
第三个示例(能整除):
假设input_p=[1,0,2,3,5,6,7,8] dst_bins=4
1.计算stride
- stride = input.size / bin 取整
2.按照stride划分
- [1,0] [2,3] [5,6] [7,8]
3.判断每一位是否非零
- [1,0,1,1,1,1,1,1]
4.将多余位累加到最后整除的位置上,在上面无多余位,最后整除的位置上是[8],因此[0+8=8]进行替换
- [1,0] [2,3] [5,6] [7,8]
5.进行位扩展从而得到output_q
- 将4的结果和3的非零位进行一个映射得到最终的结果
- [1,0] [2.5,2.5] [5.5,5.5] [7.5,7.5]
4.6 TRT Entropy Calibration
4.6.1 伪代码
tensorRT的Entropy Calibration的伪代码可看下图,参考自8-bit-inference-with-tensorrt以及Entropy Calibration,具体分析如下:(from chatGPT)
- for循环:遍历所有可能的分割点,从128到2048
- reference_distribution_P:将原始直方图bins按照当前分割点i进行切割,得到左侧的i个bin。
- outliers_count:将原始直方图bins按照当前分割点i进行切割,得到右侧的2048-i个bin。
- reference_distribution_P[ i-1 ] += outliers_count:将outliers_count加入到reference_distribution_P中,得到新的概率分布。
- P /= sum§:将reference_distribution_P进行归一化。
- candidate_distribution_Q:将当前的i个bin分成128个level,得到candidate_distribution_Q,表示我们将reference_distribution_P进行量化。
- Q /= sum(Q):将candidate_distribution_Q进行归一化。
- KL_divergence( reference_distribution_P, candidate_distribution_Q):计算当前量化方法下的KL散度,并将其保存在divergence中。
- 循环结束后,divergence中记录了每个分割点i下的KL散度。我们选取KL散度最小的分割点i作为最优的分割点,并将其作为最终的量化参数。

总的来说,Entropy Calibration的过程就是将概率分布量化成少量的level,并寻找最优的level,使得量化后的分布和原始分布的KL散度最小。
有一个问题需要讨论,既然是INT8量化(2^8=256),为什么我们量化的是128个bins而不是256个bins?
回答:因为量化中针对的数据是激活函数ReLU后的,即经过ReLU后的值均为正数,所以负数就不用考虑了,而原来INT8的取值范围是在[-128,127]之间,因此[-128,0]就不用考虑了,而原始的分布[0,127]就能够表达,因此for循环就是从[128,2048]
4.6.2 示例代码
完整的示例代码如下:
import random
import numpy as np
import matplotlib.pyplot as plt
def generator_P(size):walk = []avg = random.uniform(3.000, 600.999)std = random.uniform(500.000, 1024.959)for _ in range(size):walk.append(random.gauss(avg, std))return walkdef smooth_distribution(p, eps=0.0001):is_zeros = (p == 0).astype(np.float32)is_nonzeros = (p != 0).astype(np.float32)n_zeros = is_zeros.sum()n_nonzeros = p.size - n_zerosif not n_nonzeros:raise ValueError('The discrete probability distribution is malformed. All entries are 0.')eps1 = eps * float(n_zeros) / float(n_nonzeros)assert eps1 < 1.0, 'n_zeros=%d, n_nonzeros=%d, eps1=%f' % (n_zeros, n_nonzeros, eps1)hist = p.astype(np.float32)hist += eps * is_zeros + (-eps1) * is_nonzerosassert (hist <= 0).sum() == 0return histimport copy
import scipy.stats as stats
def threshold_distribution(distribution, target_bin=128):distribution = distribution[1:]length = distribution.size # 获取概率分布的大小threshold_sum = sum(distribution[target_bin:]) # 计算概率分布从target_bin位置开始的累加和,即outliers_countkl_divergence = np.zeros(length - target_bin) # 初始化一个numpy数组,用来存放每个阈值下计算得到的KL散度for threshold in range(target_bin, length):sliced_nd_hist = copy.deepcopy(distribution[:threshold])# generate reference distribution Pp = sliced_nd_hist.copy()p[threshold - 1] += threshold_sum # 将后面outliers_count加到reference_distribution_P中,得到新的概率分布 threshold_sum = threshold_sum - distribution[threshold] # 更新threshold_sum的值# is_nonzeros[k] indicates whether hist[k] is nonzerois_nonzeros = (p != 0).astype(np.int64) # 判断每一位是否非零quantized_bins = np.zeros(target_bin, dtype=np.int64)# calculate how many bins should be merged to generate# quantized distribution qnum_merged_bins = sliced_nd_hist.size // target_bin # 计算stride# merge hist into num_quantized_bins binsfor j in range(target_bin):start = j * num_merged_binsstop = start + num_merged_binsquantized_bins[j] = sliced_nd_hist[start:stop].sum()quantized_bins[-1] += sliced_nd_hist[target_bin * num_merged_bins:].sum() # 将多余位累加到最后整除的位置上# expand quantized_bins into p.size binsq = np.zeros(sliced_nd_hist.size, dtype=np.float64) # 进行位扩展for j in range(target_bin):start = j * num_merged_binsif j == target_bin - 1:stop = -1else:stop = start + num_merged_binsnorm = is_nonzeros[start:stop].sum()if norm != 0:q[start:stop] = float(quantized_bins[j]) / float(norm)# 平滑处理,保证KLD计算出来不会无限大p = smooth_distribution(p)q = smooth_distribution(q)# calculate kl_divergence between p and qkl_divergence[threshold - target_bin] = stats.entropy(p, q) # 计算KL散度min_kl_divergence = np.argmin(kl_divergence) # 选择最小的KL散度threshold_value = min_kl_divergence + target_binreturn threshold_valueif __name__ == '__main__':# 获取KL最小阈值size = 20480P = generator_P(size)P = np.array(P)P = P[P>0]print("最大的激活值", max(np.absolute(P)))hist, bins = np.histogram(P, bins=2048)threshold = threshold_distribution(hist, target_bin=128)print("threshold 所在组:", threshold)print("threshold 所在组的区间范围:", bins[threshold])# 分成split_zie组,density表示是否要normedplt.title("Relu activation value Histogram")plt.xlabel("Activation values")plt.ylabel("Normalized number of Counts")plt.hist(P, bins=2047)plt.vlines(bins[threshold], 0, 30, colors='r', linestyles='dashed')plt.show()
输出如下:
最大的激活值 3878.868170933664
threshold 所在组: 1777
threshold 所在组的区间范围: 3365.600012434412

上述示例代码主要是实现了一种量化方法——基于熵的量化(Entropy-based Quantization)。该方法的基本思路是通过统计神经网络中激活值的分布情况,并通过一些数学模型和技巧将其分解为多个区间,最终实现对神经网络模型中权重和激活值进行有损压缩的目的,从而减少模型的存储和计算开销。(from chatGPT)
其中,generator_P函数是用来生成随机激活值的函数;smooth_distribution函数则是用来平滑处理神经网络中激活值分布的函数;threshold_distribution函数则是主要函数,用来计算熵量化中的最小KL散度阈值,它采用的是一种从右向左搜索的策略,对激活值分布进行分组,并通过KL散度来度量每个分组的误差,从而找到使得误差最小的最优分组。最后,该代码通过matplotlib.pyplot将激活值分布和最小KL散度阈值可视化展示出来。
总的来说,该示例代码实现了一种用于神经网络量化的基本思路和方法,同时也给出了一些关键的计算细节和实现方法。
5. 代码分析
先对代码总体把握下
generator_P()函数:用于生成一个随机的概率分布 P
smooth_distribution()函数:对概率分布 P 和 Q 进行平滑处理,避免 KL 散度计算时出现分母为0的情形
threshold_distribution()函数:核心函数,主要用于计算每个阈值下的 KL 散度,最后选择 KL 散度最小的阈值作为最终的阈值
main()函数:主函数,主要生成概率分布 P,并计算出阈值然后明确我们的目的
我们的目的是获得分布 P 的动态范围,我们是通过不断地取修改阈值,得到新的概率分布,然后计算 KL 散度值,我们将遍历整个直方图,然后获得一个 KL 散度数组,获取数组中最小的 KL 散度所对应的阈值即我们想要的结果。
threshold_distribution() 核心函数的简要说明如下:
- 1.首先,我们将输入数据分成一定数量的 bins(本例为2048)
- 2.然后,我们选定一个阈值位置(本例选的是128),计算从该位置开始的后面所有 bin 内数据的概率之和,这个和就是所谓的 outlier count ,即被认为是离散群点的数据个数
- 3.接下来,我们将 outlier count 加到 reference distribution P 中,得到新的概率分布,并且用这个新的概率分布来计算 KL 散度
- 确保生成的概率分布是一个合法的概率分布
- 减小量化误差造成的影响
- 4.计算完 KL 散度后,我们将阈值位置向后移动一个位置,重复以上步骤,直到计算完所有可能的阈值位置,得到了一个 KL 散度数组
- 5.最后,我们找到 KL 散度数组中最小的那个值,即最小的 KL 散度,并记录对应的阈值位置,这个位置就是 threshold_value
在这个过程中,我们通过计算 KL 散度来找到一个最佳的阈值位置,以使得动态范围最优化。threshold_value 就是这个最佳的阈值位置,我们可以利用它来确定最终的动态范围。
我们来通过图例方法说明,首先来看第一次循环
- 1.对于 distribution 我们会首先选择前 128 个 bin 作为一个新的概率分布
- 2.值得注意的是,我们会后面的所有 bin 进行累加求和然后加到新的概率分布的最后一个 bin 上,即步骤1
- 3.得到了概率分布 P 以及量化后 Q 的 bin 后,我们就可以通过之前的分析求解 Q 了,具体有三种情况即P 和 Q 的分布的 bin 保持一致;P 和 Q 分布的 bin 不一致但是可以被整除;P 和 Q 分布的 bin 不一致且不能被整除,第一次循环对应第一种最简单的情况,即 P 和 Q 的 bin 相同即步骤2
- 4.拿到 P 和 Q 的分布之和需要对其进行平滑即步骤3和步骤4
- 5.最后通过平滑的 P 和 Q 便可进行 KL 散度的计算即步骤5

然后我们来看第二次循环,与第一次循环总体过程无区别,有以下几点注意
- 阈值位置向后移动一个位置,新的概率分布 P 应该是前 129 个 bin
- 在计算 Q 分布时出现 P 和 Q 的 bin 不一致且不能整除的情况,根据之前的分析计算非零状态位,通过步长来求解即可

依此类推重复以上步骤,将每次的KL散度记录下来,同时将阈值位置向后移动,直到移动到最后的第2046个bin。这时会得到一个KL散度数组,求取其最小值所对应的索引,然后通过这个索引可以求出对应的threshold_value,最后利用threshold_value即可确定我们最终的动态范围
总结
本次课程学习了动态范围计算中的直方图计算,该方法可解决Max方法中离散点问题,但同时要求数据的分布要均匀,不能出现过多的离散群。还学习了Entropy这种基于概率分布的动态范围计算方法,通过计算P和Q分布的KL散度来选择合适的动态范围,并分析了bins能整除和不能整除两种情形,最后对实际工程中tensorRT的Entropy Calibration的算法进行了一个分析。那么动态范围的三种常见计算算法都已经讲解完毕了,期待下次的QAT😄