目录
- 数据集的获得
- 使用工具
- 项目流程
数据集的获得
进入该网址:https://grouplens.org/datasets/movielens/
找到如下part:

点击ml-100k.zip进行数据集的下载
在本地解压后,将会看到如下内容:

但我们目前只需要三个文件,即:
u.data u.item u.user,为便于后续操作,可以找到这三个文件,将其放入新建文件夹。
u.data的内容是评分数据
u.item的内容是电影数据
u.user的内容是观众数据
随意用编辑器打开即可查看。
使用工具
个人使用的是PyCharm Community Edition 2020.3.3
项目流程
创建好新的project后,创建新的python file,需要用到的包是pandas,提前下载好后将其导入;
首先读取数据

read_table()的数据参数分别是:
数据文件
一行记录不同列分隔符
第一列是否为行标题
映射关系
由于真实数据设计数据量较大,暂时先读取较少量数据,例如:

效果展示:

读取评分数据,并与观众数据进行连接:

效果展示:
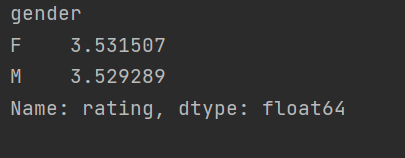
可以看到,女性观众的评分平均值高于男性,但差别不明显;
接下来,通过年龄段看评分:

效果展示:

可以看到,随着年龄的增长,对电影的评分大体上呈现出一种不断增长的趋势,60岁时达到峰值;
接下来分析不同年龄段分性别对电影评分的情况:

效果展示:

可以看出,在30岁,男女评分差异不大,而在70岁,女性对电影的评分更低,在40岁,男性对电影的评分更低,可以看出,在不同年龄段,不同性别,人们对电影的偏好有所不同。
接下来再引入电影信息:

由于编码方式可能不同,可能会出错,则进行编码方式改变:
File->Settings->Editor->File Encoding
点击Apply成功改变,同时,在代码中强制指定编码方式:

输出测试:

连接三个文件信息并测试输出:


以电影标题作为分组依据,便于直观观察,真正有效的电影标识列是电影ID。按照性别、电影标题展示,并对结果平均评分进行倒序排序输出:

效果展示:

然而,所有数据不一定是有效的,有可能某一部5分电影只有一位观众评分,那么,这时就要改进方法,我们不仅要考虑平均分,还要考虑参与评分人数,故调用agg()方法进行分组,通过列表指定多个聚合函数,将多个不同聚合函数一起进行运算:

可以看出,该方法提供了平均值和评价人数的统计:

但因为没有排序,无法得到最有价值的数据,接下来对数据进行排序:
先按照平均分排序,假如平均分相同,按照个数进行排序:


先按照个数进行排序,再按照平均分进行排序:
为了看到全部结果,使用pd.set_option('display.max_row', None)显示全部结果:

结果展示:

(其余不列出)
可以看出,男性观众对经典电影的观看率与评分率较高,女性观众与男性观众的差异较为明显,然而这种方法又有弊端,例如排序中女性观众观看电影第一位,因为评分人数较多而不是评分较高:

进行过滤,过滤掉评分人数小于100的电影,再按照平均分进行排序:


(其余不列出)
还可以使用透视图进行展示:(依然以性别和电影分析)


(其余不列出)


但出现的问题依然是可能评分高但评分人数较少,此时可以再次进行数据过滤:
先获得评分人数大于100的电影:




获取评分差异较大的电影:


为了避免出现过于小的值,应当使用绝对值处理:


(未完待续···)