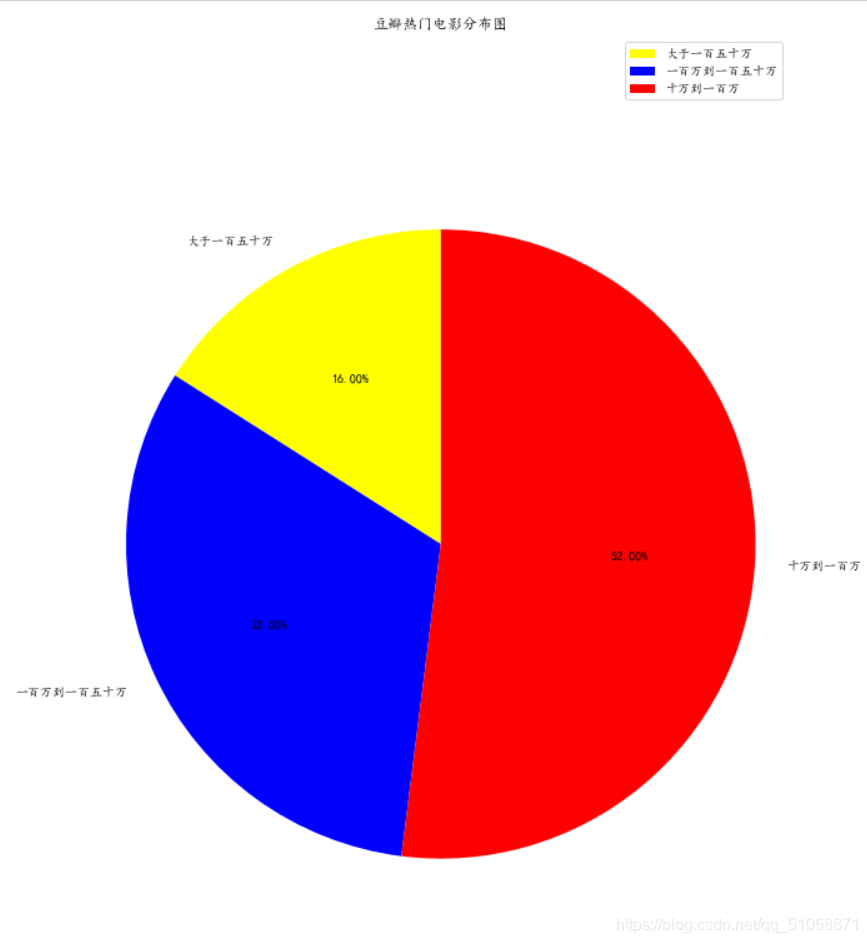
好久没有爬虫了,今天突然叫爬豆瓣,有点懵了,不过看了看以前爬的,一葫芦画瓢整了一个这个。bs4和requests yyds!
分析一波
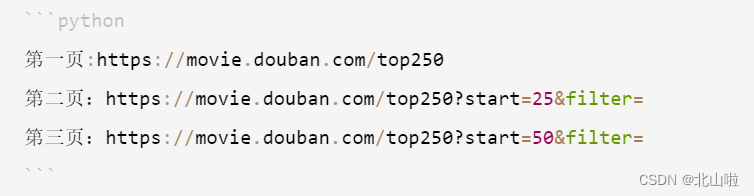
爬取的地址:https://movie.douban.com/subject/26588308/comments
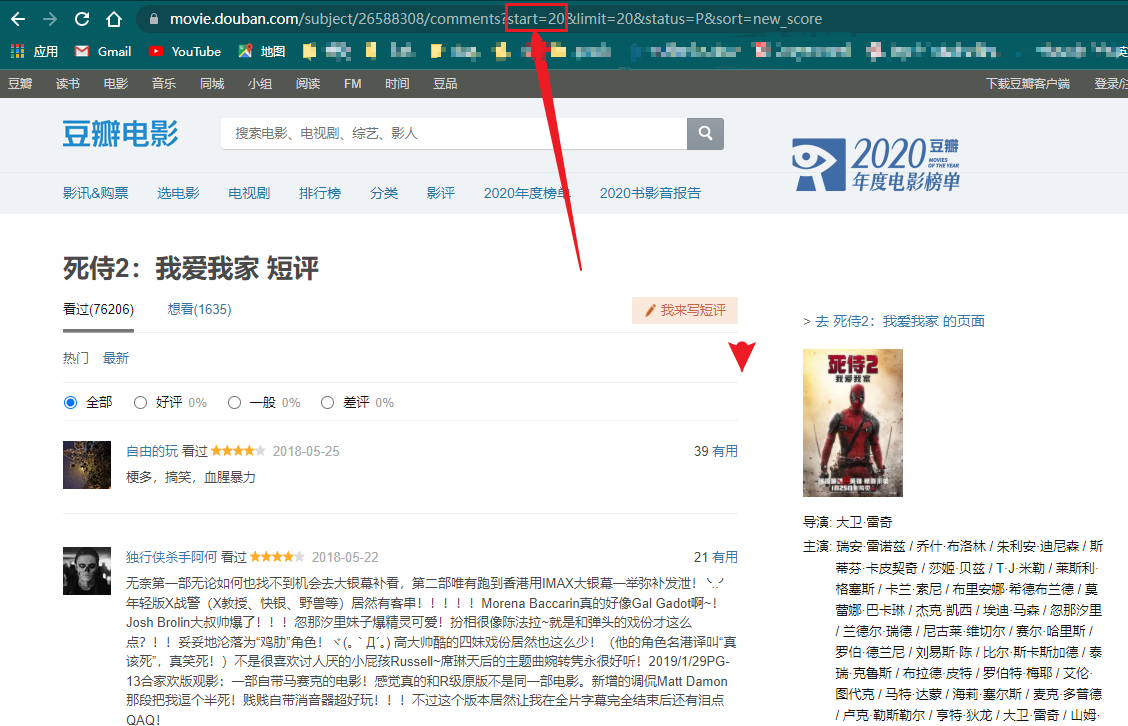
- 每次翻页可以看到只和start有关,一页展示20条评论
- 下图是第二页的url,故第一页的start就是0
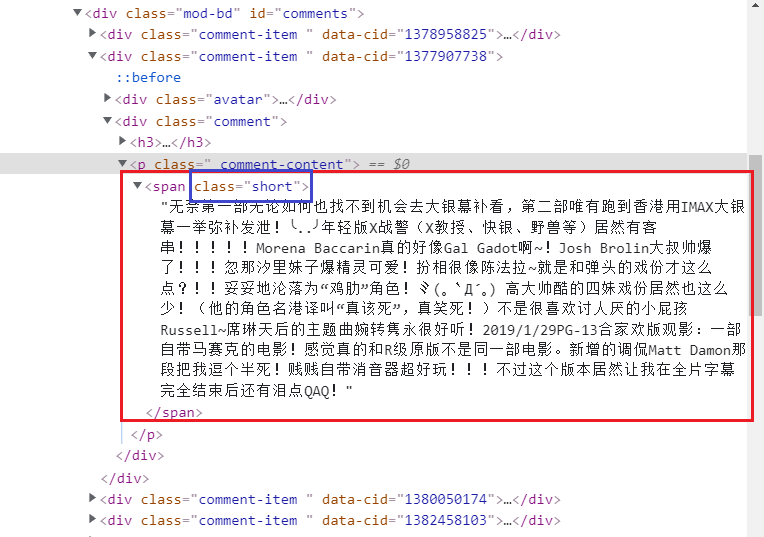
- 评论在span标签里面(class属性为short)
代码
import urllib.request
from bs4 import BeautifulSoup
import timeabsolute = "https://movie.douban.com/subject/26588308/comments"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36',
}
comment_list = []#解析html
def get_data(html):soup = BeautifulSoup(html,'lxml')if soup.string != None:return 0else:for each in soup.find_all(name="span",attrs={"class": "short"}): #获取class属性为short的span标签textword = each.textcomment_list.append(textword)#获取HTML
def get_html(url,i):url = absolute + '?start=' + str(i) + '&limit=20&status=P&sort=new_score'print(url)try:request = urllib.request.Request(url=url, headers=headers)html = urllib.request.urlopen(request).read().decode("UTF-8")flag = get_data(html)if flag == 0:return 0except Exception as result:print("错误原因",result)return 0#将数据写入文件
def save_txt(data):with open("comments.txt","w",newline='',encoding="utf-8") as f:j = 1for i in data:f.write('('+ str(j) + ')' +i)f.write("\n")j+=1if __name__ == '__main__':i = 0 #每次翻页加20for j in range(0,10000000): #为了翻页设置的flag = get_html(absolute,i)time.sleep(2)i += 20if flag==0: #标记,如果页面空白就跳出循环breaksave_txt(comment_list)
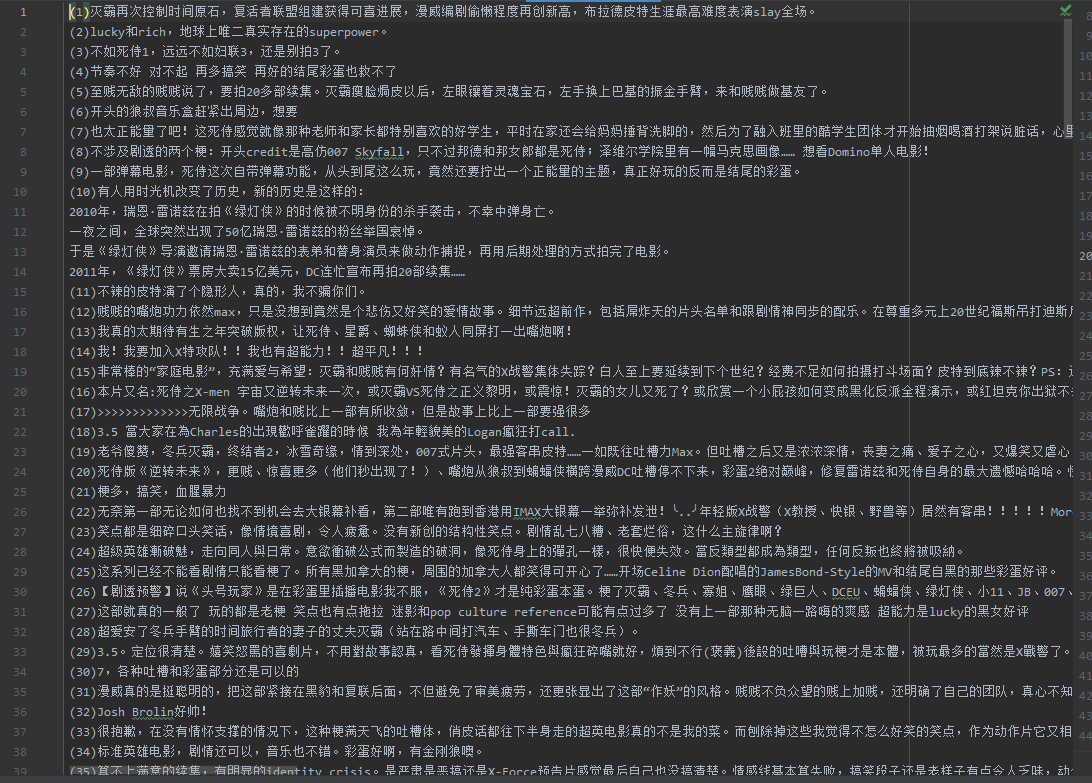
效果截图
- 上面这个错误的原因是因为最后爬取的页面的下一个页面为空,用户是访问不到的,故报错了,不过这个报错是自己设置的,也可以看成是爬取完毕的标志。