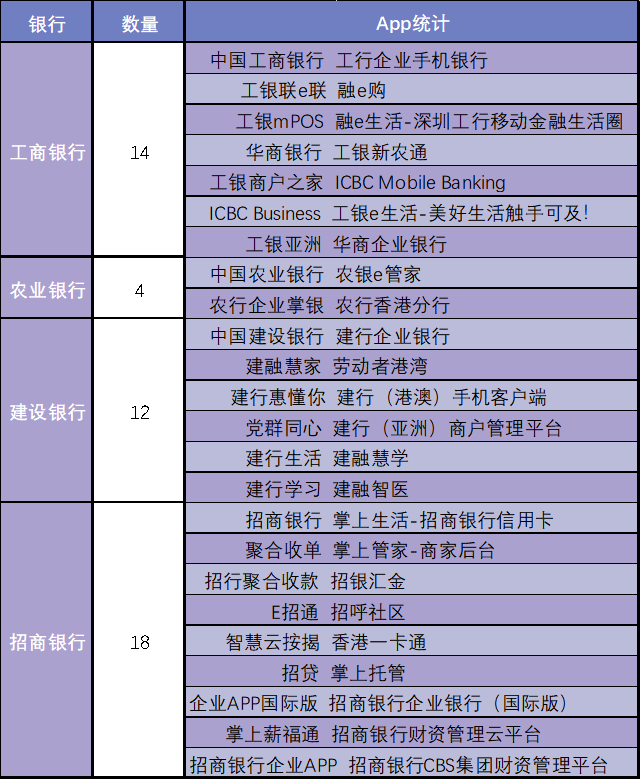
matplotlib和pyecharts绘制图表
- pyecahrts
- 漏斗图
- 核心代码
- 地图
- 核心代码
- 柱状图
- 核心代码
- 组合图表
- 核心代码
- 数据大屏
- 核心代码
- matplotlib
- 棉棒图
- 核心代码
- 饼图
- 核心代码
- 词云图
- 核心代码
- 组合图表
- 核心代码
| 开发语言及版本 | Python3.7 |
|---|---|
| 第三方库及版本号 | jieba 0.42.1 |
| matplotlib | 3.3.4 |
| imageio | 2.9.0 |
| numpy | 1.19.5 |
| pyecharts | 1.9.0 |
| wordcloud | 1.8.1 |
| 系统环境 | Windows10 |
| 开发工具 | PyCharm 2021.2 |
本文章主要对2012年至2018年广东省地区普通高等学校含本科、专科学校的招生和毕业情况和对2013年和2017年各类教育经费的可视化展示。
pyecahrts
漏斗图

核心代码
funnel = (Funnel(init_opts=opts.InitOpts(width='1200px', height='600px',# 设置主题背景theme=ThemeType.MACARONS)).add("", data_fun, sort_='descending',# 设置提示框显示的内容tooltip_opts=opts.TooltipOpts(formatter="{b} : {c} 所")).set_global_opts(title_opts=opts.TitleOpts(title="2018年广东省各级学校数量",pos_left='center'),legend_opts=opts.LegendOpts(pos_top='30px'))
)
地图

核心代码
map = (Map(init_opts=opts.InitOpts(width='1200px',height='600px')).add('本科', data1, "广东").add('专科', data2, "广东").add('本、专科', data_map, '广东').set_global_opts(title_opts=opts.TitleOpts(title='广东省各城市高等学校分布',pos_left='center'),# 设置只显示单个图例,不能同时多选legend_opts=opts.LegendOpts(selected_mode='single', pos_top='30px'),# 设置视觉映射组件visualmap_opts=opts.VisualMapOpts(max_=81, min_=1,range_text=['数量'],orient='horizontal',pos_bottom='100px',pos_right='center'))# 设置提示框内容.set_series_opts(tooltip_opts=opts.TooltipOpts(formatter='截止2020年6月30日<br/> {b}<br/> {a} : {c} 所<br/> '))
)
柱状图

核心代码
bar.set_global_opts(title_opts=opts.TitleOpts(title='2012年至2018年普通高等学校在校生人数',pos_left='center'),# y轴标签yaxis_opts=opts.AxisOpts(name='人数(万人)', name_location='center',name_gap=30),# 提示框内容显示tooltip_opts=opts.TooltipOpts(formatter='{b} <br/> {a} : {c} 万人'),# 设置图例位置legend_opts=opts.LegendOpts(pos_top='30px'),# 设置区域缩放datazoom_opts=opts.DataZoomOpts(type_='slider'),# 设置工具箱toolbox_opts=opts.ToolboxOpts(is_show=True,feature=opts.ToolBoxFeatureOpts(save_as_image=opts.ToolBoxFeatureSaveAsImageOpts(type_="jpeg", title="保存为jpeg", pixel_ratio=2),# 打开还原data_view数据视图restore=opts.ToolBoxFeatureRestoreOpts(),# 关闭查看数据集data_view=opts.ToolBoxFeatureDataViewOpts(is_show=False),# 关闭区域缩放data_zoom=opts.ToolBoxFeatureDataZoomOpts(is_show=False),# # 关闭选框组件brush=opts.ToolBoxFeatureDataZoomOpts(is_show=False),)))
bar.set_series_opts(label_opts=opts.LabelOpts(position='inside'))
// 设置柱子圆角和渐变色"itemStyle": {"emphasis": {"barBorderRadius": 15},"normal":{"barBorderRadius": 15,"color": new echarts.graphic.LinearGradient(0, 0, 1, 0,[{"offset" : 0, "color":'#77f9a6'},{"offset": 1, color: '#b3dafa'}])}
组合图表

核心代码
tl_pie = Timeline(init_opts=opts.InitOpts(theme=ThemeType.MACARONS))
for i in range(5):pie = (Pie(init_opts=opts.InitOpts(theme=ThemeType.MACARONS))# 显示数据和百分比.add(years[i], data[i], radius=[80, 120],label_opts=opts.LabelOpts(formatter="{b} : {d}%", is_show=True))# 设置提示框显示内容.set_series_opts(tooltip_opts=opts.TooltipOpts(formatter="{a}<br/>{b} : {c}万元")).set_global_opts(title_opts=opts.TitleOpts(title='{}\n\n教育经费种类\n'.format(years[i]),pos_left='center',pos_top='120px'),legend_opts=opts.LegendOpts(is_show=False)))tl_pie.add(pie, "{}".format(years[i]))tl_pie.add_schema(is_timeline_show=False, # 不显示时间轴is_auto_play=True, # 自动播放)
tl_radar = Timeline(init_opts=opts.InitOpts(theme=ThemeType.MACARONS))
# 循环添加数据
for i in range(5):radar = (Radar(init_opts=opts.InitOpts(theme=ThemeType.MACARONS)).add_schema(schema=[opts.RadarIndicatorItem(name=kinds[0], max_=40000000),opts.RadarIndicatorItem(name=kinds[1], max_=30000000),opts.RadarIndicatorItem(name=kinds[2], max_=1000000),opts.RadarIndicatorItem(name=kinds[3], max_=150000),opts.RadarIndicatorItem(name=kinds[4], max_=10000000),opts.RadarIndicatorItem(name=kinds[5], max_=10000000),opts.RadarIndicatorItem(name=kinds[6], max_=1000000),],# 显示网格分区(蜘蛛网)splitarea_opt=opts.SplitAreaOpts(is_show=True, areastyle_opts=opts.AreaStyleOpts(opacity=1)),# 设置文本标签颜色textstyle_opts=opts.TextStyleOpts(color='#09a1c3'),).add(series_name=years[i],data=data[i],areastyle_opts=opts.AreaStyleOpts(color=color[i],opacity=0.2), # 区域颜色,透明度)# 设置标签不显示.set_series_opts(label_opts=opts.LabelOpts(is_show=False)).set_global_opts(title_opts=opts.TitleOpts(# 设置标题位于雷达图的中央以及字体大小title="{}".format(years[i]),pos_top='center', pos_left='center',title_textstyle_opts=opts.TextStyleOpts(font_size=15)),legend_opts=opts.LegendOpts(is_show=False)))tl_radar.add(radar, "{}".format(years[i]))tl_radar.add_schema(is_timeline_show=False,is_auto_play=True)
数据大屏

核心代码
# 页面布局。调用已经封装好的绘制各种类型图的函数
page = Page()
page.add(title(), # 调用函数绘制标题“基于pyecharts的数据大屏”funnel(), # 调用函数绘制漏斗图maps(), # 调用函数绘制地图bar(), # 调用函数绘制柱状图pie(), # 调用函数绘制圆环图rader(), # 调用函数绘制雷达图timeline() # 调用函数绘制时间线轮播柱形图)
page.render("./chart10/数据大屏.html")# 调整布局结构
from bs4 import BeautifulSoup
with open("./chart10/数据大屏.html", "r+", encoding='utf-8') as html:html_bf = BeautifulSoup(html, 'lxml')divs = html_bf.select('.chart-container')# 中上方divs[0]["style"] = "width:40%;height:10%;position:absolute;top:0;left:30%;"# 中中位置divs[1]["style"] = "width:40%;height:45%;position:absolute;top:10%;left:30%;"# 中下方divs[2]["style"] = "width:40%;height:50%;position:absolute;top:50%;left:30%;"# 左上divs[3]["style"] = "width:30%;height:50%;position:absolute;top:0;left:0;"# 左下divs[4]["style"] = "width:30%;height:50%;position:absolute;top:50%;left:0;"# 右上divs[5]["style"] = "width:30%;height:50%;position:absolute;top:0;left:70%;"# 右下divs[6]['style'] = "width:30%;height:50%;position:absolute;top:50%;left:70%;"body = html_bf.find("body")html_new = str(html_bf)html.seek(0, 0)html.truncate()html.write(html_new)html.close()
matplotlib
棉棒图

核心代码
fig: plt.Figure = plt.figure(figsize=(8, 6), dpi=300)
axes: plt.Axes = fig.add_subplot(111)
markerline, stemline, baseline = axes.stem(x, y, linefmt='-', markerfmt='or' )
# 设置棉棒图线段的属性
plt.setp(markerline, lw=0.5, markersize=4)
plt.setp(baseline, lw=1, color='k')
plt.setp(stemline, lw=1, color=['g','r','skyblue','pink','y','m','orange'])
axes.set_title("2012年至2018年普通高等学校数量变化", fontsize=14, pad=15)
axes.set_xticks(x)
axes.set_xticklabels(x_label, fontsize=12)
axes.set_ylabel("数量/所", fontsize=12, labelpad=10)
axes.set_ylim(0, 200)
# 显示y轴网格线
axes.grid(axis='y', alpha=0.5, ls=':')
# 隐藏上下边和右边轴脊
axes.spines['top'].set_color('none')
axes.spines['left'].set_color('none')
axes.spines['right'].set_color('none')
axes.spines['bottom'].set_color('none')
# 隐藏x轴y轴的刻度
axes.xaxis.set_ticks_position('none')
axes.yaxis.set_ticks_position('none')
# 注释文本
for temp_x, temp_y in zip(x, y):axes.text(temp_x, temp_y+5, s='{}'.format(temp_y), ha='center', va='bottom', fontsize=14)
饼图

核心代码
fig: plt.Figure = plt.figure(figsize=(8,4),dpi=300)
# 自定义布局
gs = fig.add_gridspec(6,2)
ax:plt.Axes = fig.add_subplot(gs[:1,:])
# 隐藏全部轴脊
ax.axis('off')
# 显示主标题
ax.set_title('2018年本科、专科招生和毕业人数比例')
# 绘制饼图
ax_pie1:plt.Axes = fig.add_subplot(gs[1:6,0])
ax_pie1.pie(data1, labels=kinds1, radius=1, autopct='%.2f%%', startangle=90)
ax_pie2:plt.Axes = fig.add_subplot(gs[1:6,1])
ax_pie2.pie(data2, labels=kinds2, radius=1, autopct='%.2f%%', startangle=90)
# 显示子图标题
ax_pie1.set_title('招生比例')
ax_pie2.set_title('毕业比例')
# 添加表格
ax_table1:plt.Axes = fig.add_subplot(gs[:,0])
ax_table1.axis('off')
ax_table1.table(cellText=[['28.28 万人', '29.04 万人']],cellLoc='center',colLabels=kinds1,loc='bottom')
ax_table2:plt.Axes = fig.add_subplot(gs[:,1])
ax_table2.axis('off')
ax_table2.table(cellText=[['25.39 万人', '26.99 万人']],cellLoc='center',colLabels=kinds2,loc='bottom')
# 自动调整布局
plt.tight_layout()
词云图

核心代码
import jieba
import wordcloud
from imageio import imread
mask = imread("./chart10/猴子.png") # 背景图片
file = open("./chart10/意见.txt","r",encoding="utf-8")
t = file.read() # 读取文本内容
file.close()
ls = jieba.lcut(t) # 分词
txt = " ".join(ls) # 词之间用空格间隔开
txt = txt.replace("和","") # 去掉 “和”, 无意义文字
txt = txt.replace("的","xxx") # 一般情况下,“的” 数量最多,可替换成姓名,用于显示最大
w = wordcloud.WordCloud(font_path="C:\\Windows\\Fonts\\msyh.ttc",mask=mask,background_color="white")
w.generate(txt)
组合图表

核心代码
fig: plt.Figure = plt.figure(figsize=(8, 6), dpi=300)
axes: plt.Axes = fig.add_subplot(111)
# 绘制柱状图
axes.bar(x, y1, color='orange', label='本科招生人数', alpha=0.7, width=0.4)
axes.bar(x, y2, bottom=y1, color='g',label='专科招生人数', alpha=0.7, width=0.4)
axes.set_title('2012年至2018年高等学校招生人数及增长情况', fontsize=14, pad=15)
axes.set_xticks(x)
axes.set_ylim(0, 80)
axes.set_xticklabels(x_label)
axes.set_ylabel('人数(万人)', labelpad=10)
# 设置左边 y轴的刻度方向
axes.tick_params(axis='y', direction='in')
# 添加网格显示
axes.grid(b=True, ls=':', lw=1, alpha=0.8)
# 使用右边另一个y轴,绘制折线
ax_right = axes.twinx()
line = ax_right.plot(np.arange(1,7), ls, 'mo-.',label='增长率',)
ax_right.set_ylabel('招生增长率(%)',labelpad=10)
ax_right.set_ylim(-0.5, 0.1)
# 设置右边 y轴的刻度方向
ax_right.tick_params(axis='y', direction='in')
# 添加注释文本
for temp_x, temp_y in zip(np.arange(1,7), ls):ax_right.text(temp_x, temp_y+0.01, s='{}'.format(temp_y), ha='center',va='bottom', fontsize=10)
# 添加平均水平线
average1 = y1.mean()
average2 = y2.mean()
axes.axhline(average1, ls='--',label='本科招生人数平均线', lw=1, color='orange')
axes.text(6.7, average1+2, s='{}万人'.format(np.round(average1, 2)),ha='center', va='center', fontsize=12, color='orange')
axes.axhline(average1 + average2, ls='-.',label='专科招生人数平均线', lw=1, color='g')
axes.text(6.7, average1+average2+2, s='{}万人'.format(np.round(average2, 2)),ha='center', va='center', fontsize=12, color='g')
# 显示图例
axes.legend(loc='lower right')
ax_right.legend()