开源聊天机器人ChatterBot
3.1 ChatterBot简介
ChatterBot是一个Python库,可以轻松生成对用户输入的自动响应。ChatterBot使用一系列机器学习算法来产生不同类型的响应。这使开发人员可以轻松创建聊天机器人并自动与用户进行对话。
ChatterBot的独立于语言的设计使其能够接受任何语言的培训。此外,ChatterBot的机器学习特性允许代理实例在与人类和其他信息数据源进行交互时提高自己对可能响应的知识。对话流程如图3.1所示。

图3.1 ChatterBot对话流程图
3.2 搭建聊天机器人
3.2.1 第一步:pip下载包
在命令行中输入命令。
sudo pip install chatterbot输入密码后,等待系统安装。安装完成后检测安装结果如图3.2所示。

图3.2 chatterbot安装结果
3.2.2 第二步:建立python工程、编码训练
在PyCharm中建立工程,创建python文件,编码,执行。执行结果如图3.3所示。

图3.3 执行结果
3.2.3 第三步:输入对话,得到回答
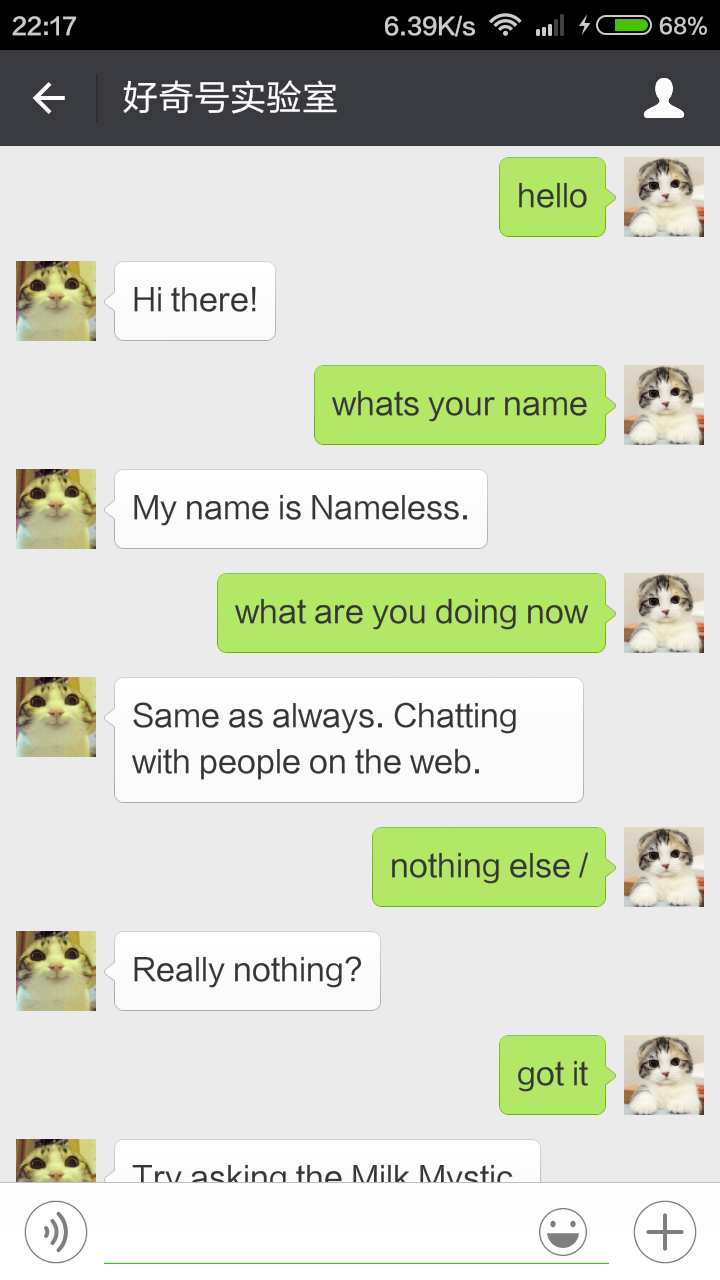
在控制台输入句子,得到对话系统的结果,如图3.4、图3.5所示。

图3.4 对话结果

图3.5 对话结果
3.3 ChatterBot对话流程分析
3.3.1 创建聊天机器人流程
通过创建ChatBot对象创建聊天机器人,在其构造方法中有多个属性可以进行配置:
1. 存储适配器:为ChatterBot提供连接到各种存储系统(如MongoDB或本地文件存储)的接口。
storage_adapter参数用来配置不同的数据库连接。
database参数用于指定聊天机器人将使用的数据库的路径。
2. 输入输出适配器:
input_adapter参数配置输入适配器,用于从命令行、Microsoft Bot、gitter、hipchat、Mailgun读取用户的输入。
output_adapter参数配置输出适配器,用于将输出打印到命令行、Microsoft Bot、gitter、hipchat、Mailgun。
3. 逻辑适配器:定义用来响应它接收到输入的ChatterBot
logic_adapters参数是一个list,可以有多个逻辑适配器,不同的逻辑适配器解决不同的问题。
(1)Time Logic Adapter解决时间相关的问题;
(2)Mathematical Evaluation Adapter适配器可解决使用基本计算的数学问题;
(3)Best Match Adapter使用函数将输入语句与已知语句进行比较,也就是最匹配方式,从训练的对话中找到最相似的语句,根据对话,提供回答;
(4)Low Confidence Response Adapter:如果无法确定具有高置信度的响应,此适配器会返回指定的默认响应;
(5)Specific Response Adapter如果聊天机器人接收到的输入与此适配器指定的输入文本匹配,则返回指定的响应。
4. 过滤器:
减少聊天机器人在选择响应时必须处理的语句数量。
5. name:名称是ChatBot类唯一必需的参数。
6. trainer:训练器。
3.3.2 聊天机器人训练过程
通过调用train方法,并将训练集作为参数。
ChatterBot的训练过程涉及将示例对话框加载到聊天机器人的数据库中。这可以构建代表已知语句和响应集的图数据结构。当一个聊天机器人训练师被提供一个数据集时,它会在聊天机器人的知识图中创建必要的条目,以正确表示语句输入和响应。
用上下句来构建一个statement ,statement相当于存储了一个上下对话的关系,在查找的时候,先找到最合适的上文,下文就是答案了。这就是一个训练的过程,训练的这一过程,主要是在构建statement,并把statement放到storage中。

图3.6 对话训练流程
3.3.3 获取答案
聊天机器人主要的过程是产生答案的过程,而答案的选择最关键的就是算法的实现,比较好的聊天机器人必须拥有不同的算法,对不同的聊天内容给出不一样的答案,根据输入选择最合适的算法,产生最好的答案。

图3.7 获取答案
3.4 ChatterBot源代分析
分析源代码需要有入手点,我的入手点就从自己的聊天机器人入手,我将聊天机器人的步骤分为三部分:创建chatterbot、训练语料、获取回答。
main.py实现了简单的对话流程,其代码如下:
# coding=utf-8from chatterbot import ChatBot# 第一步,创建chatterbotchatbot = ChatBot('Ron Obvious',trainer='chatterbot.trainers.ChatterBotCorpusTrainer')# 第二步,训练语料chatbot.train("chatterbot.corpus.english")# 第三步,输入对话得到答案while True:q = raw_input()print chatbot.get_response(q)
3.4.1 创建模块
创建模块负责创建对象,其相关方法如图3.8所示。

图3.8 ChatBot类
1. 创建ChatBot对象。
2. ChatBot 类的构造方法对聊天机器人的相关属性进行赋值,包括:聊天机器人的名字、存储适配器、逻辑适配器、输入输出适配器、过滤器、训练器、训练的数据集、是否要学习用户输入等。
3. 在赋值相关适配器的过程中,调用utils的validate_adapter_class方法对每个适配器进行检测,检测其是否为对应的父类的子类,也就是检测我们自己加载的适配器是否为规定的适配器,如果不是,则会抛出异常。
4. 检测完成后调用utils的initialize_class对适配器进行加载。
5. 加载过程中会调用utils的import_module,从而找到适配器。
6. 找到适配器之后,每个适配器分别调用各自的set方法,而所有的适配器都继承自Adapter类。
7. 最后还要对逻辑适配器进行一个初始化的处理,调用initialize方法。
8. 接着调用LogicAdapter类的get_initialization_functions 方法,获取所有初始化需要执行的方法,一一执行。
3.4.2 训练模块
训练模块开始于语句:chatbot.train()方法,在ChatBot类中,train方法由@property修饰,会根据不同的训练器执行不同的训练方法。虽然取名字中都带有train,其实只是把语料数据存入storage而已,不存在机器学习意义上的训练。在ChatterBot中提供了四种训练器。所有的训练器都继承了Trainer类。其继承结构如图3.9所示。

图3.9 训练器继承结构
3.4.2.1 ListTrainer
使用表示对话的list来训练聊天机器人。ListTrainer类如图3.10所示。

图3.10 ListTrainer类
1. 执行train方法,循环对参数list进行处理。
2. 由于处理需要一定的时间,因此在处理过程中会调用utils的print_progress_bar方法,显示处理的进度条。
3. 在处理对话的过程中,调用父类的get_or_create方法,如果statement已经存在,则利用已存在的statement,如果不存在,则会创建一个新的statement。
4. 为每一个Statement添加tag和response,将结果存储到storage中。
3.4.2.2 ChatterBotCorpusTrainer
ChatterBotCorpusTrainer使用来自ChatterBot对话语料库的数据训练聊天机器人。ChatterBotCorpusTrainer旨在处理yml格式的语料数据文件。

图3.11 ChatterBotCorpusTrainer
1. 在train方法中首先对参数进行判断,判断参数是否为list。接下来开始对每个语句和其对应的回答进行训练。
2. 调用Cropus类的load_corpus(corpus_path)方法,获取路径下所有谈话yml中对话内容的合集,数据集的排序方法按照python的默认方法。
3. 调用Cropus类的list_corpus_files(corpus_path)方法得到yml文件构成的列表 ,该方法会遍历目录下的所有文件,如果该文件以yml为后缀,那么该文件path就会存入list。
4. 进入循环,开始对每一条对话进行处理,目的是用上下句来构建一个statement ,statement相当于存储了一个上下对话的关系,在查找的时候,先找到最合适的上文,下文就是答案了。这就是一个训练的过程,训练的这一过程,主要是在构建statement,并把statement放到storage中。
5. 由于处理需要一定的时间,因此在处理过程中会调用utils的print_progress_bar方法,显示处理的进度条。
6. 在处理对话的过程中,调用父类的get_or_create方法,如果statement已经存在,则利用已存在的statement,如果不存在,则会创建一个新的statement。
7. 为每一个Statement添加tag和response,将结果存储到storage中。
3.4.2.3 TwitterTrainer
可以训练来自Twitter的语料。

图3.12 TwitterTrainer类
1. 执行train方法,循环调用get_statements方法获取statement。
2. 在get_statements方法中通过调用twitter提供的API,返回API中随机statement的列表。
3. 最后将statement存储到storage中。
3.4.2.4 UbuntuCorpusTrainer
使用来自Ubuntu Dialog Corpus的数据进行训练。UbuntuCorpusTrainer是在处理tsv格式的语料数据文件。

图3.13 UbuntuCorpusTrainer类
1. 执行train方法,首先会调用download方法下载语料,然后调用is_extracted判断语料是否解压,如果没有解压,那就对语料进行解压,下载提取ubuntu对话数据集,然后检查python的版本,python2.x的版本可能存在问题。
2. 采用循环对每个语料进行处理,处理每个语料的过程中循环处理tsv文件的每一行数据,接下来对循环处理的每一行代码进行分析。
for row in reader:
#row表示语料tsv文件中的每一行数据。 if len(row) > 0: text = row[3]
#这个是根据数据集的特性来决定写代码的,因为语料库的第四列是对话内容。所以这里是row[3]。statement = self.get_or_create(text) statement.add_extra_data('datetime', row[0])
#这个函数用来添加字典类型数据,例如此处添加的数据就是 {datetime,row[0]} statement.add_extra_data('speaker', row[1]) if row[2].strip():
#这个代码的意思是,对话发起时,是不知道哪个是听众的,因为是在论坛发帖子。因为语料数据来自论坛交谈,论坛发帖子是不知道谁会回复的,所以出事状态下,发了一个新帖子以后,在帖子还没有回复的情况下,row[2]默认是空,只有出现回复者以后,row[2]才会有值。#所以刚发完帖子后,由于row[2]是空,所以if下面的语句将不会被执行。上面的if语句中,Python strip() 方法用于移除字符串头尾指定的字符(默认为空格)所以上面的if语句的意思是,row[2]这个数据集合中的第三个属性,进行去除空格处理,得到的数据是否为空(即判断这是否是个新发的帖子) statement.add_extra_data('addressing_speaker', row[2])
#因为人们的交谈是一次只能有一个人说话,A说话时,B就只能听着,可用来增加字典类型数据,如果用法如上,则函数调用前后无变化。 所以row[1]和row[2]表示row[1]对row[2]讲话 if previous_statement_text:
#这个previous_statement在这里代表上一次某人说的话,因为语料库来自论坛对话,所以论坛帖子没发以前,这个变量肯定是空的。 statement.add_response( Response(previous_statement_text) ) previous_statement_text = statement.text
#为下一轮for循环做准备,方便取得此次回答的下一轮回答。这样进入下一轮循环的时候,就可以正常进入if语句。 self.storage.update(statement)
#最后将statement存入storage
3.4.3 获取回答模块
获取回答模块主要用于根据用户的输入,产生相应的回答。该调用流程如图3.14所示。

图3.14 回答流程
1. 执行ChatBot类中的get_response方法,该方法首先检测默认的会话id,如果该id不存在,则表明是新的会话,这时要给新会话赋予一个新的id。
2. 调用InputAdapter类的process_input_statement方法处理输入,将输入转化为statement,该方法会查询输入语句对应的statement是否存在,如果存在则返回statement,并记录日志,如果不存在则直接记录日志。InputAdapter是一个抽象类,所有的输入适配器必须实现。
3. 继续在get_response方法中执行preprocessor的过滤方法,得到过滤后的statement。
4. 调用ChatBot类中的generate_response方法,该方法根据输入的statement得到相应的回答。
5. 在产生回答的过程中会调用StorageAdapter类的generate_base_query方法修改storage的属性。
6. 由于逻辑适配器可能有多个,不同的适配器也可能产生不同的结果,调用proces方法的过程中会调用get_greatest_confidence方法找到最佳答案,如果多个适配器都赞同相同的statement,那么这个statement大概率是正确答案。
7. 最后通过输出适配器OutputAdapter,将结果返回给用户。
3.4.4 全局梳理
整个ChatterBot关键部分如图3.15所示。

图3.15 全局关键类






![真龙霸业服务器维护,真龙霸业进不去怎么办 游戏无法进入解决方法详解[多图]...](https://img-blog.csdnimg.cn/img_convert/eb1909e8936c5c31dd4998a8d0b1ea1a.png)