目录
第一部分:介绍爬虫项目
1、微信好友的爬虫
2、拉勾网的数据那么多的招聘信息有用吗?
3、豆瓣的图书、电影信息有用吗?
4、美团和大众点评的数据有用吗?
5、伯乐在线的文章数据有用吗?
6、腾讯NBA的用户评论数据有用吗?
7、链家网的数据有用吗?
8、知乎的数据如何用呢?
第二部分:对知乎的数据分析
1.0 简介
1.1 数据
1.2 玩的不是同一个知乎:均值、中位数与标准差
1.3 当雪球滚到最后:长尾和幂律分布
1.4 论如何滚成人生赢家:赞同与关注
2.0 社交网络是什么?
2.1 分析对象和分析方法
2.2 抱团的大V们:网络总体特征
2.3 给大V排个位:网络连接分析
2.4 不均衡中的均衡:Closeness和Betweenness中心度
2.5 大V都在关注什么:热门话题分析
第三部分: 抓取各类项目数据汇总
0、IT桔子和36Kr
1、知乎
2、汽车之家
3、天猫、京东、淘宝等电商网站
4、58同城的房产、安居客、Q房网、搜房等房产网站
5、大众点评、美团网等餐饮及消费类网站
6、58同城等分类信息网站
7、拉勾网、中华英才网等招聘网站
9、应用宝等App市场
10、携程、去哪儿及12306等交通出行类网站
11、雪球等财经类网站
12、58同城二手车、易车等汽车类网站
13、神州租车、一嗨租车等租车类网站
14、各类信托网站
15 简单来分析一下知乎的数据
附加
第四部分:提供几个API网站
一、生活服务
二、金融数据
1.股票
2.大宗商品
3.美股等综合类
4.财经数据
5.网贷数据
6.公司年报
6.创投数据
7.社交平台
8.就业招聘
餐饮食品
9.交通旅游
10.电商平台
11.影音数据
12.房屋信息
13.购车租车
14.新媒体数据
15.分类信息
16.网络指数(可能需用图像识别)
第五部分:详细数据分析
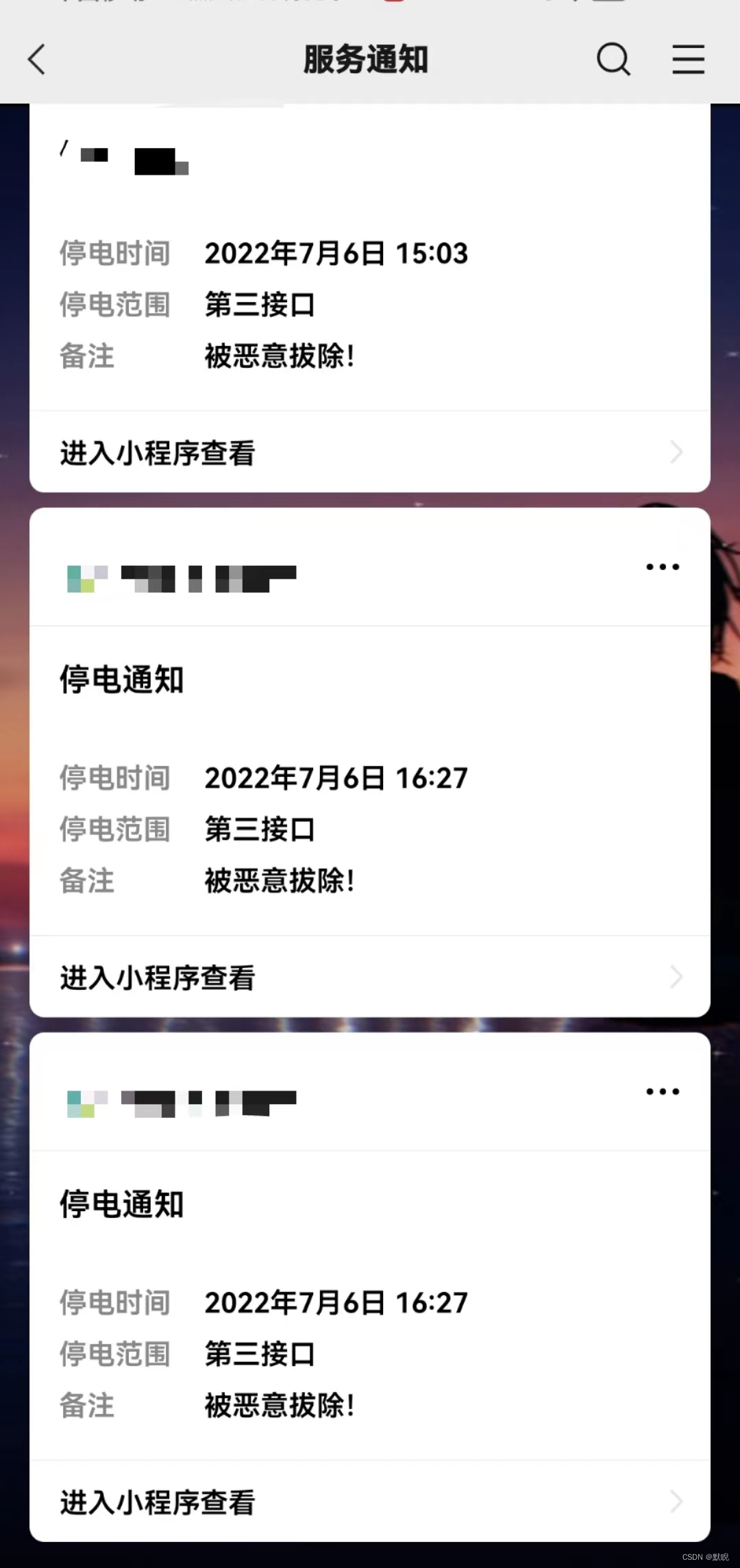
1.享一实验-获取QQ好友或QQ群里爆了照再撤回全部图片
1.统计一下图片文件所携带的信息
2. 拉勾网上的技术类的招聘信息
3.对拉勾网上面的职位信息进行爬取
爬虫系统
分析报告
4.职位印象
1.这是抓取的所有详情页数据
2.这是分析结果
5.留学论坛的数据分析:
1.利用D3.js做了一个拓扑图草图
2. 之后增加了筛选,按照投资次数多少来筛选投资机构
3. 增加了点击气泡查看被投资公司列表,
4. 增加line chart和bar chart查看全部投资机构或者各投资机构的投资趋势变化及在各轮次的投资次数变化。
第六部分:专爬知乎下的精华回答,作统计分析
一.代码
二.算法简述
1.爬虫算法
2.收集数量
3.分析内容
三.统计结果
1.匿名答主
2.答主性别
3.答主受教育情况
4.雇主
5.精华回答的赞同数
6.回答字数
后记
第七部分:从某处爬到的某美国著名高校170000+份研究生申请文件。
第八部分:爬过有趣的有用的有意义的网站
1.教务网站(涉及模拟登录)
2.小游戏网站
3.亚文化与小清新网站
4.微信公众号
5.股票数据
6.音乐网站
7.自己写的可配置爬虫
什么是可配置爬虫?
可配置爬虫Python
一、爬虫抓到的数据的分析方式设想
二.分析的主题:《基于新浪微博的京东白条发展建议》
第九部分:哪些数据比较有价值?
微信公众号数据
哪些数据比较有价值?
一、我们先拿企业和事业单位来分析
二、我们再来拿个人分析。
数据如何转换成回报--盈利模式探讨?
第十部分:爬取张佳玮138w+知乎关注者:数据可视化
一、前言
二、数据可视化
1、关注人数
2、性别情况
3、10w+大V
4、居住地分布
5、Top20 系列
6、认证信息
7、优秀回答者
三、小结
第十一部分:拉勾招聘网站爬取了532条数据分析师岗位的招聘数据
一、数据分析师需求现状
(1)城市分布
(2)行业分布
(3)学历要求
(4)经验要求
(5)公司规模分布
(6)公司融资阶段
二、数据分析师工作简述
(1)岗位职责
(2)岗位要求
三、数据分析师薪资影响因素
(1)城市因素
(2)领域因素
(3)学历因素
(4)经验因素
(5)公司规模因素
(6)公司发展阶段因素
(7)技能因素
五、结论
(1)可选择北京和上海入职,并且选择移动互联网和金融行业。
(2)可选择公司规模较大、发展较为成熟的公司
(3)至少需要积累1年的相关工作经验,至少要掌握2个以上的数据分析工具
第十二部分:爬虫采集知乎的粉丝情况
分为两步,获取数据和分析数据
粉丝数排行
回答与发文量
简单总结,个人感觉、取决下面几点
第十四部分:用八爪鱼去采集
玩法
玩法一:收集最新热门新闻事件
玩法二:三分钟爬取QQ号码
玩法三:寻觅团购优惠和美食
玩法四:协助豆瓣打造个性化交友圈
玩法五:在百度地图上快速定位
玩法六:收集电商平台产品信息
玩法七:采集赶集网房源信息
玩法八:实时分析股票行情
玩法九:采集招聘网站职位信息
玩法十:高效收罗法律判决文书
实战
一、数据来源
二、分析部分
1、什么样的公司爱招数据产品经理(数据PM需求现状)
2、什么样的求职者更符合企业期望 (企业对数据PM要求)
3、 什么样的企业最壕(数据PM待遇)
3.2学历
3.3城市
三、总结
回顾之前,我用爬虫做了很多事情。
第一部分:介绍爬虫项目
1、微信好友的爬虫
了解一下你的好友全国分布,男女比例,听起来似乎是一个不错的想法,当然你还可以识别一下你的好友有多少人是用自己照片作为头像的,详细的内容可以点击这里:Python对微信好友进行简单统计分析
2、拉勾网的数据那么多的招聘信息有用吗?
当然有用,你想了解一下你所在城市的各种主流语言(Java、PHP、JavaScript、Python、C++)的薪资水平吗?这或许对你的学习决策是一个很大的帮助:
- Java/Python/PHP/C#/C++各大城市招聘状况分析
- web前端开发各大城市招聘状况分析
3、豆瓣的图书、电影信息有用吗?
当然有,你想了解一下哪位小说作家的作品质量最高吗?是否想了解豆瓣上最热门的书记都有哪些,有没有你错过的好书籍呢?豆瓣的电影评论有水军吗?
- 爬取6.6w+豆瓣电影之后的分析故事
- 豆瓣5.6分的《西游伏妖篇》评论有水军吗?
4、美团和大众点评的数据有用吗?
有呀,你真的了解周黑鸭和绝味吗?你知道在哪些城市周黑鸭比绝味火,哪些城市绝味比周黑鸭火呢?如果你都不知道,你就不算是鸭脖控!你所不知道的周黑鸭和绝味鸭脖
5、伯乐在线的文章数据有用吗?
有啊,作为技术人员如何写一篇受欢迎的技术文章,作为一名Python初学者如何快速找到Python全面的学习资料,一个爬虫就够了:抓取1400篇Python文章后的故事(内附高质量Python文章推荐)
6、腾讯NBA的用户评论数据有用吗?
你用会员看一场NBA,我用爬虫也能看完一场精彩的NBA:用弹幕看一场NBA(公牛 - 老鹰),甚至我还能看到很多你看不到的东西,不信你点进链接看一看。
7、链家网的数据有用吗?
当然有啦,我能快速地找到我想租的房子,当然我还有一项特殊的技能,我还能用这些数据画出城市的地铁交通路线,是否很想知道如何做:如何拿链家网的租房数据做些有意思的事情?
8、知乎的数据如何用呢?
如何判断一场知乎live的质量,如何发现知乎中有趣的东西,知乎中最厉害的粉丝最多的都有哪些人?你想知道吗?
- 不交智商税,如何判断一场知乎live的质量?
接下来详细介绍下对知乎的数据分析
第二部分:对知乎的数据分析
当初就是因为看到他在专栏上发的两篇知乎数据分析的文章,觉得知乎非常有分析的价值,于是在一个Course Project里提出了这个题目。正如文中已提到的,这个小项目其实远远没达到令人满意的程度,挖得太浅,实际处理的数据量也很小,我其实是还想继续做下去的。如有任何问题敬请指正,如有朋友想要在此基础上继续做点啥的也请让我知道。
1.0 简介
本文主要语言为Python。项目的原始材料为英文撰写,内容包括了从爬取知乎数据一直到结果分析的整个过程。在本文中我打算略去数据爬取和数据库I/O的部分,重点在分享一些有趣的结论。分析过程若有不周之处,还望指正。
为保证可读性,本文将分为上下两篇,一篇只涉及数据介绍及基本的统计分析,另一篇是基于用户关注网络和关注话题进行的分析。
如果对这个小项目的全貌感兴趣,甚至想要自己fork过来玩玩,这里是项目的Github传送门。数据的压缩包可以在这里下载(使用请注明来源为本答案页面)。
1.1 数据
虽说不讲数据爬取,但要说清楚我们所使用的数据到底是啥,还是得简单提一下的。2015年10月,我们使用了本人的知乎账号作为种子,先获得了所有我关注的用户的数据,再获得了这些用户所关注的用户的数据,所以算上种子的话一共是3层的广度遍历(注意其实这个数据可能是存在严重bias的,毕竟seed是一个逗逼,逗逼关注的人呢...咦怎么感觉脖子一凉)。这里的用户数据包括:用户的回答数,用户获得的赞同数、感谢数,用户关注的人和关注用户的人,用户回答过的问题以及每个问题的话题标签。这里给出数据的简要统计信息:
- 数据库文件: 688 MB(SQLite)
- 数据包含:2.6万名用户, 461万条关注连接, 72万个问题
这里是一张数据全貌的图示:
下面将着重介绍我们所做的分析。
1.2 玩的不是同一个知乎:均值、中位数与标准差
要告诉别人我们在知乎上混得怎样,最基础的几个指标是什么呢?一定是关注、回答、赞同、感谢。所以我们首先对用户的关注数(followee)、关注者数(follower,粉丝数)、回答数(answer)、收到赞同数(agree)和收到感谢数(thanks)的平均数、中位数以及标准差进行了计算,结果如下表:
里其实就有许多有趣的结论了。
首先我们看平均值,哇,平均每个人有三千多粉丝,三千多赞同,再看看可怜的我,306个粉和837个赞,而且他们回答的问题也并不多啊,却有那么多赞和粉丝,还让不让人玩知乎了?再看看中位数,顿时心里好受一些了,原来我混得挺不错嘛,五个指标都是我比较大,真开心(你是不是傻)。
究竟是什么原因造成平均值和中位数差异这么大呢,也许我们能从标准差看出来一些端倪——太大了,粉丝数和赞同数的标准差甚至超过了两万。
这意味着什么呢?我们知道,标准差其实衡量了数据个体之间的离散程度,也可以解释为大部分的数值和其平均值之间的差异。因此这么大的标准差可以说明知乎用户之间的差距可能略大于整个银河系(雾),同时也说明绝大部分用户的数值和平均值有很大的差距,要么大得离谱(比如),要么小得可怜(比如我)。
有人可能会不服气,说标准差严重依赖于数据本身的scale,不能充分说明问题。那么这里使用标准离差率(标准差除以平均值)来算算赞同数,21951.4/3858.4 = 568.9%。我~就~问~你~服~不~服~
以上现象还可以导出一个猜测,那就是知乎用户的这五个指标的值分布,都不大可能是正态分布及其近似。让我们回想正态分布的样子:
(图片来源:https://zh.wikipedia.org/zh-cn/%E6%AD%A3%E6%80%81%E5%88%86%E5%B8%83)
如果是正态分布,中位数(最中间的值)、众数(最多的值)以及平均值三者至少应该是非常接近的,然而我们这里却是地月距离(怎么一下缩水那么多)。
1.3 当雪球滚到最后:长尾和幂律分布
为了进一步验证1.2的猜测,我们绘制了五个指标的分布图(Distribution Graph)。
这里说明一下这五张分布图的含义,横轴表示指标的具体数值,纵轴表示有多少用户具有该指标值。需要注意的是横轴值和纵轴值都取了以10为底的log,这是研究中一种常见的处理办法,能够使图所表达的信息更清晰。以感谢数分布图为例,那个最左上方的点表示在这两万多知乎用户里面,有大于10的三次方也就是1000的人没有获得一个感谢(摸摸大);而最下面那一排点则是说,感谢数是x1,x2,..., xn (反正都不小)的用户,都只有一个人——注意仅这一排点并不能形成什么有效的结论,因为可能感谢数100的只有一个人,101的就有好多人了,这一定程度上大概是因为数据量小,采样不足。但是如果把下面几排点放到一起考虑,也许会更有启发一些。
顺便提一句,其实关注数和粉丝数的分布图分别还有另外一个名字,它们其实是知乎用户关注网络的出度(out-degree)分布图和入度(in-degree)分布图,这点在下篇中还会有所提到。
如果是对这种分布图比较熟悉的童鞋,应该一眼就能看出,这绝壁不是正态分布,而极有可能是幂律(power law)分布(不过因为懒我们并没有做拟合去验证),这种分布在许多有人参与其中的网络中都会出现。此外,仔细比较这五条曲线的整体形状,有没有觉得有两条与另外三条略有不同?一条是关注数,一条是答案数,这两条曲线向外的弯曲程度似乎更明显,也就是说随着横轴值的增大,纵轴值减小的趋势相对较慢,而恰好五个指标里只有这两个是某个用户自己可以控制的,而其他三个指标则是由其他用户形成的群体所控制,这是很奇妙的一点,我觉得其实还有深挖的可能性。
现在让我们以感谢数为例,再画另外一种分布图。横轴表示每个用户的index也就是0,1, 2, 3...,顺序由感谢数大小决定,纵轴则是该用户收到感谢数的具体数值:
看到那个突破天际的点了吗,二十七八万的感谢(其实这个点在前面那张感谢数分布图中也出现了,你还认得仅在几个自然段以外的它吗)!再看看下面那条长长的尾巴,人艰莫拆。再来看一个更夸张的,赞同数:
其他三个指标的图的形状也基本如此。
苏莉安曾使用远大于我们的数据量做了类似的分析,结论是一致的。总结一下就是:大多数人小得可怜,却有极少数人大得可怕,一点也不正(可)态(爱)。前几年不是有本书很火吗,叫做《长尾理论》?所谓长尾,指的就是这样一种现象(附送我对该现象的一些解释:什么是「长尾效应」 ? - 赵澈的回答)
到这里不由得让人提到另外一个东西:马太效应。所谓穷的人越来越穷,富的人越来越富,感觉上其实就是长尾效应的动态解释(最近打算看看有没有相关的文献)。富的人掌握大量资源,因此更可能攫取更多资源,而穷的人则相反;大V因为有名而得到更多关注,同时因此变得更加有名;玩游戏carry从而得到更多钱,有了钱买装备又更可能carry。这是典型的正(滚)反(雪)馈(球)。最后造成的结果,就是长尾现象。
1.4 论如何滚成人生赢家:赞同与关注
这一节可以算是对上一节结论的一个支撑。下面这张图同时包含了用户的赞同数和粉丝数两个指标:
(!密集恐惧症高能预警!)
我想不需要我们再做个回归什么的了,一看就是赤裸裸的正相关啊。
2.0 社交网络是什么?
在上篇所述的基本的统计分析之后,我们已经对知乎用户的赞答谢关四个方面的总体情况有了一些了解。现在,让我们先来考虑这样一个问题:我们平常所说的社交网络或者说社会网络,到底是什么意思?也许你会讲,这还不简单,只要一个事情有多人参与,自然就会具有社交的性质,从而产生社交网络。那么让我们思考思考,维基百科算不算具有社交性质?
维基百科确实有很多人参与编辑词条啊,但是这些人之间有没有更直接的互动呢?假设编辑者们通过QQ、微博之类进行互动,那产生出的社交性质算不算是维基百科本身所具有的社交属性呢?即使维基百科提供评论区之类的功能,可以使编辑者之间直接互动,这些互动仍然是基于某个词条的,只要这个词条没什么大问题了,互动基本上也就随着编辑的停止而停止了。我认为这种临时建立起来的关系,并无法得到一个较为稳定的社交网络。
让我们再来思考一个例子。我们知道,一门科学源自跨越时代的许多人的共同贡献,那么这许多人,能够构成社交网络吗?当然不能。所谓牛顿和爱因斯坦的对话只是一种修辞,一篇已经发出的论文,如何能引用一篇未来的论文?但是当我们考虑到同一时代的同一学科,情况就有所不同,学者之间确实存在着各种交流合作的可能,因此我们可以认为学术领域的共同作者关系(Co-authorship)形成的网络其实是带有社交性质的。
从以上粗略的思考中我们或许可以总结形成社交网络的几个条件:多主体的直接互动、互动的长期性、互动的近同时性。
现在让我们重新回到知乎上面来。赞同、感谢、回答、关注,哪一种用户行为最满足以上三个条件?回答是基于问题的,知乎的产品设计并不突出是谁提出了某个问题,并且一个问题可以被不同的人进行编辑(类似维基百科的权限设计),也就是说回答者一般不大在意是谁提出了问题,所以回答连互动都称不上;赞同、感谢以及我们之前没有提到的评论,相对来说互动得稍微直接一点,但是鼠标一点了事,不具有长期性;只有关注关系,同时满足了三个条件。这里可能会有一个疑问,关注也只是鼠标那么一点,这能算长期的吗?不要忘记知乎的时间线(Timeline)机制,这使得关注者有更大的概率看到被关注者的活动并与之进行互动,并且只要关注不取消,这种对时间线的影响就是长期的。
到此,我们可以认为,如果想要对知乎从社交网络的角度上进行分析,首先就可以考虑知乎用户之间的关注关系。接下来开始介绍我们对此进行的具体分析。
2.1 分析对象和分析方法
首先来了解一些网络的基本知识:
一个网络可以被表示为一种图(graph),其中包含点(vertex / node)与边(edge / link)两种基本要素。边可以具有方向性,也就是说对于一个点来说,可以有外连边(out-link)和内连边(in-link)两种边。如果边是具有方向性的,那么这种图称为有向图(directed graph),反之称为无向图(undirected graph)。图反映了点与点之间的某种相关关系,这种关系由边表现。
回到知乎上,我们知道关注和被关注实际上是一件事情的两个角度。A关注了B,等价于B被A关注。在我们所爬取的数据中(见1.1中的数据全貌图),我们知道这2.6万用户中的每个人都关注了哪些人。也就是说,我们知道了2.6万用户点的所有外连边。从另一个角度想,我们其实也知道在这2.6万用户之间谁关注了谁(蓝圈以内的部分),加上他们关注了其他什么人(蓝圈以外的部分)。因此我们只能分析这2.6万用户(红色实心圆),因为我们并不知道其他的人(红色空心圆)的所有连接,这是由我们的广度优先爬取机制所导致的,不爬完知乎整站,不会有真正完整的数据(那些没人关注的账号应该可以忽略)。
此外,即使剔除了蓝圈以外的部分,涉及的连边数仍然具有很大的量级,计算量会是一个问题,所以在这个项目中,我们仅仅选取了这2.6万用户的两个有趣的子集进行分析:获得赞同数大于1万的用户(共1895人)、获得赞同数大于5万的用户(共375人)。方便起见,我们将他们分别命名为Net10k和Net50k,其实可以说就是两个不同级别的知乎大V群体了。
接下来讲讲分析方法。一个网络图,别看里面只有点和边两种东西,其实可以包含复杂到极点的各种现象与性质。网络分析,或者进一步说复杂网络领域之中,存在大量人们为了描述网络的现象而定义的概念、以及为了量化网络的特征而设计的指标。后文将要涉及的分析建立在其中最基本的一些概念和指标上,如果对它们逐个详细介绍,那么本文篇幅会大大加长,而且会多出不少数学公式,这不符合我对本文的写作预期。因此我打算尽量从直觉(intuition)上来解释它们分别表达了什么的含义,即使给出定义也不求严格(数学公式才可带来最清晰严格的定义),重点仍在对分析的思考。此外,由于我们所讨论的知乎关注网络是有向图,后面所有的指标和算法都只讨论有向图的。当然,如果读者已有一定的基础,可以直接跳过相关的段落。
2.2 抱团的大V们:网络总体特征
一直以来知乎就给人一种印象,那就是大V们喜欢抱团。你关注我、我关注他、他又关注你,形成了紧密的圈子。那么我们怎样来量化这种特征?
假设有A、B、C三个用户组成的关注网络,其中唯一的边是A->B,那么你觉得这个网络是否紧密?我们可以这样想,三个人之间最多可以有6条边,那么我们可以用1除以6来表示这个网络的紧密程度。如果6条边都存在,那么紧密程度是1,都不存在则为0。这就是所谓图的密度(density)。Net10k和Net50k的密度分别是0.064和0.195,到这我们可以猜测,获得赞同更多的大V之间,关注关系也更为紧密。
接下来我们从另一个角度考虑这个猜测,先补充几个定义:
-
点的度(degree):与一个点通过边相连的其他点的数量和,被称为这个点的度。有向图中一个点存在出度和入度两个度,一个只看它能到达哪个点,一个只看哪些点能到达它。对于知乎的关注关系而言,我们很容易就能看到出度就是你关注的人数,入度就是关注你的人数;
-
点与点之间的路径(path):假如从点A出发,经过一条或更多条边,到达了点B,那么我们称这些边按顺序相连形成了一条A与B之间的路径。两点间的路径数量一定是大于等于0的。假设每条边的长度相等,那么包含边数最少的路径,便是所谓最短路径(shortest path),最短路径的长度一般被认为是两点之间的距离(distance);
-
图的平均最短路径长度(average shortest path length):对于一个网络而言,将所有点两两之间的最短路径长度进行算术平均,得到的就是所谓平均最短路径,可以用来衡量网络中点之间的平均距离。传说中的六度分隔(Six Degree Seperation),其实指的就是一个网络的平均最短路径长度为6(这里大家可以想想边、度和路径三者间的联系);
-
点的偏心率(eccentricity):对于图中的任意一点P,算出它与其他各个点的最短路径长度(距离),其中最大的距离称作点P的偏心率。
-
图的半径(radius)与直径(diameter):图的半径、直径分别是图中最小的、最大的点偏心率。注意图的直径不必然是半径的两倍。
-
图的强连通子图(strongly connected subgraph):设想一个网络图G的一个子图G'(意味着G'中的点和边都只能从G中挑),其中每一个点都能通过某条路径到达另一个点,则我们说G'具备强连通性,而且是G的一个强连通子图。这里注意,单独一个点我们也认为是强连通子图,虽然单个点并没有值得研究的;
-
图的强连通分量(strongly connected component):G的一个极大的强连通子图G''(意味着再往G''加任何G中剩下的点,都会破坏其强连通性)被称为G的一个强连通分量。这里需要注意,极大并不代表很大;
字好多看烦了吧,终于可以上图啦,下面分别是Net10k和Net50k的强连通分量示意图:
其中每一个红色圆圈都代表一个强连通分量,每条线(其实是很抽象的箭头orz)代表一条路径。光看这个我们还不清楚情况,我们来看二者对应的一些指标数据:
总结一下我们知道了什么:
- 基本上Net10k和Net50k这两个图就是强连通的,别说抱团了,这已经根本就是挤成一坨(好吧,一个圈子)。
- 除了一个巨大的圈子,群体里就剩几个特立独行的高冷大V(都是只包含一个点的强连通分量),他们受到了其他大V的关注,但却没有任何回粉。在网络中,这种点也被称为悬挂点(dangling nodes);
现在我们重点分析两个最大的强连通分量,连通倒是连通,但是如果A要经过100个人才能到B,那估计光凭关注关系,他们是没有缘分了。将Net10k和Net50k的最大强连通分量分别命名为Net10k-C和Net50k-C,以下是两者对应的指标数据:
如果你就是Net50k-C中的一个大V,还不认识其中的另一个大V?没关系,你关注的关注的关注...总会有他,所以你们总有机会看到彼此。强连通保证了总会有一条路径,平均最短路径向你保证平均来讲这条路径很短,只有2左右。直径和半径则告诉你在最坏情况下(你们碰巧是整个圈子里相距最远的两位),这条面基道路的长度在2到5(4)之间。What a small world,喜鹊们(雾)如是说。
再来对比Net10k-C和Net50k-C的平均最短路径长度和直径,后者都比前者要小,从另一个角度说明后者的关注圈子更紧密。而且注意一点,这些大V是来自各个不同的专业领域,但都紧抱在一起,这也是很有趣的现象,有进一步分析的价值。
2.3 给大V排个位:网络连接分析
上节侧重于对知乎大V关注网络的整体进行分析,这固然很有趣;但或许更有趣的是这个整体之中的每个个体,同样是赞同数很高的大V,他们彼此之间是否能一较高下呢?他们在关注这种社交行为上是否具有差异,如何衡量这种差异?这是本节涉及的问题。
让我们先来设想一个简单的关注网络,其中只有A、B、C三个人。A关注了B,B关注了A,A、B同时关注了C,而C谁也不关注,如下图所示:
那么你觉得光凭关注关系来看,A,B,C谁更“牛”?从直觉上来说当然是C,因为C在三人之中得到了最多的关注。但是否只要粉丝更多就能说明更“牛”呢?下面我们在这个网络的基础上,来考虑几种很有趣的情况:
- 多了10个自己粉丝数为0的用户,同时关注A
- 多了10个用户,他们彼此全部互相关注,除此之外都没有其他粉丝
- 多了10个自己粉丝数为1的用户,同时关注A,并且每个人还分别关注了10000个其他用户
那我们能说1里的A,或者2里的10个用户比C更牛吗?前两种情况明显不合道理,可以说是较为典型的作弊行为。作弊利用了单纯粉丝数排序的漏洞:没有考虑到每个关注连接的质量差异。第三种情况算是一种正常现象,但是你会觉得,这些用户一个是只有1个粉丝,几乎等于0,另一个是他们关注了那么多用户,那么他们关注A,真是因为A很重要吗?
既然发现了漏洞,那么假如不考虑赞同数等其他因素,我们是否有可能通过关注网络本身来予以解决呢?从直觉上来说,我们可以想到的是,用粉丝自己的粉丝的质量来衡量这个粉丝的质量,但粉丝的粉丝的质量又需要粉丝的粉丝的粉丝的质量来衡量...那么到底最后是个什么情况?到这里我们看到了日常语言结构所能承载的思维深度之浅薄,当一个问题到达这个复杂度,语言已然苍白无力,不得不将它托付给数学。
PageRank算法(其与Google的关系我就不赘述了)就是一个数学上非常优美的答案,不仅考虑到前述的连接质量问题,还解决了所有特殊情况——无论关注网络是什么样子的,都保证能得到一个满意的用户重要程度排序。
下面是我们对Net10k和Net50k分别计算PageRank值,注意这里只考虑大V们内部的连接,此外圈子里所有大V的PageRank值相加等于1。最后得到排名前五的知乎大V用户如下:
这些便是站在知乎大V巅峰的大V们了,是否觉得有一定道理呢?注意比较Net10k和Net50k前五用户的PageRank值,前者比后者小,这主要是因为总和为1的PageRank资源被更多的大V们分掉了。
下面让我们再考虑一点,所谓的“重要”,其实要看我们的目的是什么。假如我们是要看更多的好答案或者想要找人出书约稿,那么直接找到好答案的答主就好,而这些答主往往吸引了最多的关注,所以我们仅仅需要知道谁受到的关注最强(比如下图中的C)。
但是光是通过关注,我们会漏掉那些暂时没有得到太强关注的好答主(可能是刚刚加入知乎的大V潜力股),然而我们又不可能自己去一个一个挖掘这些好答主,如何是好?简单,假如你能找到几个类似牵线人的用户(比如下图中的D)你相信只要是他们关注的用户,质量都不会差,都合你口味,事情就简单了。你只需要不时看看他们都关注了谁,就能发现更大的世界。这其实也算是一种用户推荐系统的可行思路,这里就不展开了。
HITS算法便能做到只使用关注网络,通过权威度(Authority)和枢纽度(Hub)为我们分别挑出好的答主,和好的牵线人。
上面的基于直觉的分析是否说得通呢?让我们看看Net10k和Net50k的权威度和枢纽度前五名:
Auth(好答主)方面,我相信大家应该能认同这样的结果名单。值得一提的是在两个大V群体之中,
@张佳玮
(顺便提一下,张佳玮张公子就是上篇中那个在各条曲线中高高在上的闪亮极点)和
@梁边妖
调换了位置,很有趣。另外在Net50k中,
@采铜
老师一跃进入前五,
@马伯庸
马亲王(祥瑞御免)上升一名,黄继新则掉了出去。这些现象或许反映了不同大V群体的一种喜好倾向的差异。
Hub(牵线人)方面,说实话我个人只认识
@徐湘楠
一个人,其中还有一位目前处于账号停用状态,这里便不做过多分析。只有一点比较有趣,作为大V,粉丝数很大很正常,然而这些用户关注的人数也算是很多的,好几个甚至达到了几千,不可不谓之具有某种交际花属性。另外提一下,Net10k Hub的第五名,叫干脆面的用户,我已经无法知道是谁了,原来的用户ID是wang-wang-wang-08-18,现在改掉了,总觉得跟徐湘楠(ID:miaomiaomiao)之间存在着某种联系...
综合来看,HITS和PageRank有不少相同的用户入榜,这是为什么呢?我给一个直觉上我认为对的解释,其实PageRank的值是Hub值和Authority值的一种叠加(其实感觉更像是乘的关系)后的结果,这样Hub或Auth中的一种很强,另一种也不弱时,PageRank便相应比较高,这样两种算法得到部分相同的结果便很正常了。
@黄继新
是一个典型的例子,他的Auth值和Hub值在Net10k和Net50k中虽然都不是最高,但都排到前20名,而他的PageRank则是第一。既有内容,又能充当渠道。
2.4 不均衡中的均衡:Closeness和Betweenness中心度
到此先让我们总结一下,如果要衡量一个用户在关注网络中的“重要程度”,我们可以利用这几种指标:
- 该用户的粉丝数,即入度(In-degree)
- 该用户的PageRank值
- 该用户的HITS值
它们在网络分析中也可被归为同一类指标:点的中心度(Centrality)。但我们发现,其实三种指标所表达的“重要”,其含义是不完全一样的,同一个网络,同一个节点,可能不同的中心度排名会有不小的差距。接下来请允许我介绍本项目中涉及到的最后两种点的中心度:
-
点的近性中心度(Closeness Centrality):一个点的近性中心度较高,说明该点到网络中其他各点的距离总体来说较近,反之则较远。假如一个物流仓库网络需要选某个仓库作为核心中转站,需要它到其他仓库的距离总体来说最近,那么一种方法就是找到近性中心度最高的那个仓库。
-
点的介性中心度(Betweenness Centrality):一个点的介性中心度较高,说明其他点之间的最短路径很多甚至全部都必须经过它中转。假如这个点消失了,那么其他点之间的交流会变得困难,甚至可能断开(因为原来的最短路径断开了)。因此假如要hack一个网络的话,对哪个结点下手你懂的。从另一个角度想,这些点简直就像是等在丝绸之路上必经关口的强盗。不留下买路钱?让你无路可走,生意就别做了。
这两种中心度我目前并未找到很公认的中文翻译,姑且自己翻译了。另外同PageRank和HITS一样,由于指标的计算稍显复杂,这里就不详细叙述了。但是我们都使用的是网络分析库Networkx中的算法实现,对详细算法有兴趣的读者可自行查阅其文档。
本项目中我们分别计算了Net10k和Net10k的近性中心度和介性中心度,并画出了分布图。由于我们当时考虑欠周,算出的近性中心度是基于外连接而不是内连接的,我认为意义不大(你总是可以让自己关注更多人,从而得到更大的近性中心度),所以本文决定略过。下面主要说一下介性中心度,其于Net10k和Net50k的分布图分别如下:
我们又得到了两条长长的尾巴。图中横坐标表示每一个特定的大V,纵坐标是大V相应的介性中心度。长长的尾巴表明大部分大V的介性中心度接近0,即使长尾以外有少数几个人远超其他人,但介性中心度的值依然很小。这说明什么?说明这些大V即使退出知乎,也几乎不会影响其他大V之间建立关注关系。没了你,我还有许多其他最短路径到达另外一个大V。这进一步说明什么?说明大V的关注网络是如此健壮,健壮到即使失去许多结点,对整个圈子的连通几乎毫无影响。
再横向比较一下Net50k和Net10k,可以看到这种随着圈子增大,幂律变得更强,除了少数点,大部分的人介性中心度都更趋近于0,人数的增加进一步稀释了大多数人的“独特性”,直觉上我相信继续扩大这个圈子,到Net5k、Net1k甚至知乎全体用户,这种健壮性只会越来越强,虽然人与人相比存在指数级的差异,但对整个网络本身而言,每个人几乎同等重要,也同等不重要。这或许可以称之为知乎关注网络所具有的一种不均衡中的均衡吧。
2.5 大V都在关注什么:热门话题分析
最后,我们尝试了一种获得知乎上热门话题的办法(本项目中唯一涉及内容的分析),先取得Net10k和Net50k的支配集(Dominant set,这里由于我认为实际上不用这个子集结果也不会有显著区别,所以就不解释这个概念了),然后统计集合中所有用户的回答所对应的问题标签,最后对各个话题标签按出现次数排序。以下分别是二者的前20名:
Top 20 from Net10k:
调查类问题 3792, 生活 3096, 历史 1713, 恋爱 1464, 心理学 1432
电影 1419, 人际交往 1404, 社会 1332, 互联网 1214, 情感 1197
政治 1028, 两性关系 994, 教育 897, 中国 823, 人生 815
游戏 805, 文学 772, 知乎 772, 法律 750, 音乐 738
爱情 699, 文化 659,创业 628, 大学 621, 程序员 619
心理 617, 你如何评价 X 609, 女性 604, 编程 585, X 是种怎样的体验 582
Top 20 from Net50k:
生活 1435, 调查类问题 1365, 政治 1285, 历史 1204, 电影 1084
健康 996, 社会 984, 医学 941, 恋爱 717, 中国 695
两性关系 688, 英语 678, 人际交往 640, 心理学 634, 互联网 595
法律 587, 微软(Microsoft) 555, 美国 552, 健身 538, 编程 511
我个人认为大V们回答的问题所对应的话题,能够从一定程度上反映了知乎这个平台总体的话题领域热门程度。另外,我觉得排在最前的一些热门话题也在一定程度上解释了为什么不同领域的大V会抱团,因为不论处于什么专业领域,人们对于生活、历史、电影等人文和泛娱乐话题总是会感兴趣的,一旦都感兴趣,又都有不错的见解和分享,自然更容易惺惺相惜。
到此,本文终于可以画上句号了
第三部分: 抓取各类项目数据汇总
0、IT桔子和36Kr
在专栏文章中(http://zhuanlan.zhihu.com/p/20714713),抓取IT橘子和36Kr的各公司的投融资数据,试图分析中国各家基金之间的互动关系。
1、知乎
沧海横流,看行业起伏(2015年) - 数据冰山 - 知乎专栏,抓取并汇总所有的答案,方便大家阅读,找出2015年最热门和最衰落的行业
有空的时候,准备写爬虫分析知乎的关系链。
2、汽车之家
大数据画像:宝马车主究竟有多任性? - 数据冰山 - 知乎专栏,利用论坛发言的抓取以及NLP,对各种车型的车主做画像。
3、天猫、京东、淘宝等电商网站
超越咨询顾问的算力,在用户理解和维护:大数据改变管理咨询(三) - 数据冰山 - 知乎专栏,抓取各大电商的评论及销量数据,对各种商品(颗粒度可到款式)沿时间序列的销量以及用户的消费场景进行分析。
甚至还可以根据用户评价做情感分析,实时监控产品在消费者心目中的形象,对新发布的产品及时监控,以便调整策略。
4、58同城的房产、安居客、Q房网、搜房等房产网站
下半年深圳房价将如何发展 - 数据冰山 - 知乎专栏,抓取房产买卖及租售信息,对热热闹闹的房价问题进行分析。
5、大众点评、美团网等餐饮及消费类网站
黄焖鸡米饭是怎么火起来的? - 何明科的回答,抓取各种店面的开业情况以及用户消费和评价,了解周边变化的口味,所谓是“舌尖上的爬虫”。
以及各种变化的口味,比如:啤酒在衰退,重庆小面在崛起。
6、58同城等分类信息网站
花10万买贡茶配方,贵不贵? - 何明科的回答,抓取招商加盟的数据,对定价进行分析,帮助网友解惑。
7、拉勾网、中华英才网等招聘网站
互联网行业哪个职位比较有前途? - 数据冰山 - 知乎专栏,抓取各类职位信息,分析最热门的职位以及薪水。
8、挂号网等医疗信息网站
如何评价挂号网? - 何明科的回答,抓取医生信息并于宏观情况进行交叉对比。
9、应用宝等App市场
你用 Python 做过什么有趣的数据挖掘/分析项目? - 何明科的回答,对各个App的发展情况进行跟踪及预测。(顺便吹一下牛,我们这个榜单很早就发现小红书App的快速增长趋势以及在年轻人中的极佳口碑)
10、携程、去哪儿及12306等交通出行类网站
你用 Python 做过什么有趣的数据挖掘/分析项目? - 何明科的回答,对航班及高铁等信息进行抓取,能从一个侧面反映经济是否正在走入下行通道。
11、雪球等财经类网站
抓取雪球KOL或者高回报用户的行为,找出推荐股票
12、58同城二手车、易车等汽车类网站
一年当中买车的最佳时间为何时? - 何明科的回答和什么品牌或者型号的二手车残值高?更保值?反之,什么类型的贬值较快? - 二手车,找出最佳的买车时间以及最保值的汽车。
13、神州租车、一嗨租车等租车类网站
抓取它们列举出来的租车信息,长期跟踪租车价格及数量等信息
14、各类信托网站
通过抓取信托的数据,了解信托项目的类型及规模
15 简单来分析一下知乎的数据
抓取了知乎24W+的用户详细信息,以及他们之间的关注关系204W+(没抓完)。
数据量不算大,但是,这些样本用户应该算是比较高质量的用户了。(此处质量指的是活跃度,关注度等指标,而非道德层面上的质量)。
之所以这么说,还是有些依据的,看下面分析:
@芈十四
为种子用户,依次抓取各用户关注的人信息(是用户所关注的人,而不是用户的粉丝)。因为许多大V动辄十数万粉丝,然而这些粉丝大多是不活跃用户,对最终数据分析的意义不大。
下面进入一个分析的过程。可以进行许多维度的分析。例如:
性别分布:
地域分布:
学校分布:
专业分布:
公司分布:
由于数据没有做后期的处理,因此上面的统计只能体现一个大概的分布。比如地域分布中,帝都和北京,魔都和上海,其实是一个地方;学校分布中,五道口,五角场之类的叫法也没有与其所代表的学校合并统计。
然后,我比较感兴趣的是那些只关注了一个人的用户。统计如下:
可以看到,在这24W+的样本用户中:
- 只关注了一个人的有6205个
- 只关注了一个人,且粉丝数大于100的,有699个
- 只关注了一个人,且粉丝数大于1,000的,有161个
- 只关注了一个人,且粉丝数大于5,000的,有46个
- 只关注了一个人,且粉丝数大于10,000的,有26个
通常来说,一个用户如果只关注了一个人,那么很有可能这个人对他来说有着非比寻常的意义。但是要考虑到有些用户是新用户或者不活跃用户,那么他可能只是懒得关注人。所以,接下来的分析,选取只关注了一个人,且粉丝数大于1000的用户,一共161个。
那么,被这161个人所关注的人,是不是也只关注了一个人,并且他们两个人之间是互相关注的呢?对这161个用户进行分析,筛选出符合以下条件的用户组:
- 两个人之间互相关注,且都是只关注了对方一个人
- 其中至少一个人在这161个用户样本中
一共筛选出以下10组用户。姑且称之为“完美默契用户”(或者“完美情侣”?抱歉我暂时没想到更好的词o(╯□╰)o):
-
@Jo Jo
和@Peng Bo
-
@天璇真人
和@天枢真人
-
@野合菌
和@野合菌的女朋友
-
@Zongyuan Wang
和@siyu
-
@Arthur C
和@Mingke Luo
-
@暴脾气的李淑女
和@苏破蛮
-
@薇薇安
和@Vivianstyle123
-
@郑亚旗
和@NinaRicciJj
-
@崔冕
和@RobinChia
-
@CIH Hacker
和@Joseph Ku
最后,你们都是彼此的唯一,祝福你们O(∩_∩)O~
附加
在这24W+个样本用户中,查询那些关注了500+然而自己却只有一个粉丝的用户(由于我的抓取策略,粉丝数为0的用户不会被我抓取到):
(由于数据是前几天抓取的,可能与最新的数据有少许出入,但是影响不大。)
他们分别是(知乎的@ 太难用,有些就不@ 了,直接放个人主页):
-
@关山月
-
@鸡莫洛托夫
-
@莫筱木
- 小聪
-
@hill1357
-
@你说
-
@梅西小贝
- qiyuan zhu
- 啊啦啦
- 李梦
- 难得做梦
鉴于评论里有求源码的,是用Node.js写的,爬虫基于GitHub - syaning/zhihu-api: Unofficial API for zhihu
上面的项目对获取知乎数据的过程进行了封装,但是只提供了基础的数据接口,因此如果你要构建爬虫的话,需要在此基础上实现自己的抓取逻辑。
至于我自己的爬虫代码,因为时间仓促,写的比较烂,稳定性什么的都有待完善,就不拿出来丢人现眼了。
如果是对上面提到的那些指标进行可视化,无非是一些柱状图、条形图、饼图等,没什么意思。下面是对用户网络的可视化,使用Gephi来分析的。
首选选取粉丝数大于10,000的用户,一共1,888个用户,关注关系182,284条(可能不完整)。
很丑吧o(╯□╰)o 可以看到周围的点和线。中间黑乎乎的一大片,其实是密密麻麻的点和线,还在动态调整位置。这已经是我等了好久之后的布局。
然后选择粉丝数大于1,000的用户,一共10,757个,关注关系713,855条(只是抓取到的部分关注关系,还有很大一部分没有抓取到)。
这已经是我等了好久好久,电脑都能煎蛋之后的布局了,中间的点和线还在动态调整位置。我已经不想等了。刚开始的时候特么的就是个黑乎乎的球啊(抱歉我没有设置颜色参数)!
那么,这24W用户样本的整体网络结构是什么样的呢?别问我,我也不想知道,电脑已经卡死了/(ㄒoㄒ)/~~
更新神器:
1.下面提到的Quandl网站有一个他们自己的Python库,叫Quandl,可惜也是收费的。
pip install Quandl
2.TuShare -财经数据接口包 国内好心人做的开源财经数据接口(觉得好的可以捐助一下)。这里几乎可以获取到A股的所有信息了,还包括一些经济数据。重点是他不仅免费,还提供了一个Python库tushare。
pip install tushare
import tushare as ts
这样一来你便可以通过这个库方便地获取大量A股信息了。
第四部分:提供几个API网站
一、生活服务
1.手机话费充值。手机话费充值数据服务
2.天气查询。天气查询数据服务
3.快递查询。快递查询服务数据服务
4.健康食谱。健康食谱数据服务
5.查医院。医院大全数据服务
6.水电煤缴费。水电煤缴费数据服务
7.电影大全。电影大全数据服务
8.谜语、歇后语、脑筋急转弯。猜一猜数据服务
9.音乐搜索。音乐搜索接口数据服务
10.健康知识。健康知识数据服务
11.百度糯米、团购等信息。糯米开放api数据服务
12.彩票开奖。彩票开奖查询数据服务
以上接口都来自网站:
APIX_国内领先的云数据服务平台_API接口服务平台
细心 的人会发现,这些功能简直是遍地都是啊,支付宝、微信什么的一大堆,哪用那么麻烦!
是的,但我相信这些可能为一些不太了解相关信息的人提供了帮助。不过,虽然这些功能很多APP都有,如果自己有空闲时间又懂得编程,不喜欢别人的UI设计,自己做一做也是挺好玩的。比如:
生活枯燥了,把这些谜语歇后语等根据个人喜好定时推送到自己的手机,放松身心;
把一些健康小知识在空闲时间推送给自己,提醒自己;
……
国内类似的网站还有:
API数据接口_开发者数据定制
API Store_为开发者提供最全面的API服务
API数据接口_免费数据调用-91查|91cha.com
除此之外还有一些门户网站提供了一些API接口,比如豆瓣、新浪、百度等等。
二、金融数据
1.股票
①新浪财经
最多人用的就是新浪财经了,因为它是免费的,并且使用起来也不难。以下是网上找的教程:
获取历史和实时股票数据接口
②东方财富网
网站提供了大量信息,也是基本面投资者的好去处。可以查看财务指标或者根据财务指标选股(如净资产收益率):选股器 _ 数据中心。这些都是很好的投资参考,当然还有其它功能有对应的API,可以自己分析一下。
③中财网
http://data.cfi.cn/cfidata.aspx提供各种产品的数据
(国内很多功能类似网站,如和讯、网易财经、雪球等等,具体的我没有一一试验就不放上来了,各位可以自己去试试,下同。)
2.大宗商品
①黄金头条——用资讯帮你赚钱!炒黄金,看黄金头条!黄金价格
这里提供了各种大宗商品的行情,也可以分析获取。包括技术分析方面。
②当然还有外国网站:Investing.com
3.美股等综合类
①Wind资讯。很多机构用的都是这里的数据,当然普通个人是拿不到的,不过如果你是财经院校的学生,他们会提供免费的数据。详见官网。
②Market Data Feed and API
外国网站,提供了大量数据,付费。有试用期。
③Quandl Financial and Economic Data
同上。部分免费。
④96 Stocks APIs: Bloomberg, NASDAQ and E*TRADE
外国网站整合的96个股票API合集,可以看看。
⑤雅虎财经
http://www.finance.yahoo.com/
https://hk.finance.yahoo.com/
香港版
4.财经数据
(1)新浪财经:免费提供接口,这篇博客教授了如何在新浪财经上获取获取历史和实时股票数据。
(2)东方财富网:可以查看财务指标或者根据财务指标选股。
(3)中财网:提供各类财经数据。
(4)黄金头条:各种财经资讯。
(5)StockQ:国际股市指数行情。
(6)Quandl:金融数据界的维基百科。
(7)Investing:投资数据。
(8)整合的96个股票API合集。
(9)Market Data Feed and API:提供大量数据,付费,有试用期。
5.网贷数据
(1)网贷之家:包含各大网贷平台不同时间段的放贷数据。
(2)零壹数据:各大平台的放贷数据。
(4)网贷天眼:网贷平台、行业数据。
(5)76676互联网金融门户:网贷、P2P、理财等互金数据。
6.公司年报
(1)巨潮资讯:各种股市咨询,公司股票、财务信息。
(2)SEC.gov:美国证券交易数据
(3)HKEx news披露易:年度业绩报告和年报。
6.创投数据
(1)36氪:最新的投资资讯。
(2)投资潮:投资资讯、上市公司信息。
(3)IT桔子:各种创投数据。
7.社交平台
(1)新浪微博:评论、舆情数据,社交关系数据。
(2)Twitter:舆情数据,社交关系数据。
(3)知乎:优质问答、用户数据。
(4)微信公众号:公众号运营数据。
(5)百度贴吧:舆情数据
(6)Tumblr:各种福利图片、视频。
8.就业招聘
(1)拉勾:互联网行业人才需求数据。
(2)中华英才网:招聘信息数据。
(3)智联招聘:招聘信息数据。
(4)猎聘网:高端职位招聘数据。
餐饮食品
(1)美团外卖:区域商家、销量、评论数据。
(2)百度外卖:区域商家、销量、评论数据。
(3)饿了么:区域商家、销量、评论数据。
(4)大众点评:点评、舆情数据。
9.交通旅游
(1)12306:铁路运行数据。
(2)携程:景点、路线、机票、酒店等数据。
(3)去哪儿:景点、路线、机票、酒店等数据。
(4)途牛:景点、路线、机票、酒店等数据。
(5)猫途鹰:世界各地旅游景点数据,来自全球旅行者的真实点评。
类似的还有同程、驴妈妈、途家等
10.电商平台
(1)亚马逊:商品、销量、折扣、点评等数据
(2)淘宝:商品、销量、折扣、点评等数据
(3)天猫:商品、销量、折扣、点评等数据
(4)京东:3C产品为主的商品信息、销量、折扣、点评等数据
(5)当当:图书信息、销量、点评数据。
类似的唯品会、聚美优品、1号店等。
11.影音数据
(1)豆瓣电影:国内最受欢迎的电影信息、评分、评论数据。
(2)时光网:最全的影视资料库,评分、影评数据。
(3)猫眼电影专业版:实时票房数据,电影票房排行。
(4)网易云音乐:音乐歌单、歌手信息、音乐评论数据。
12.房屋信息
(1)58同城房产:二手房数据。
(2)安居客:新房和二手房数据。
(3)Q房网:新房信息、销售数据。
(4)房天下:新房、二手房、租房数据。
(5)小猪短租:短租房源数据。
13.购车租车
(1)网易汽车:汽车资讯、汽车数据。
(2)人人车:二手车信息、交易数据。
(3)中国汽车工业协会:汽车制造商产量、销量数据。
14.新媒体数据
新榜:新媒体平台运营数据。
清博大数据:微信公众号运营榜单及舆情数据。
微问数据:一个针对微信的数据网站。
知微传播分析:微博传播数据。
15.分类信息
(1)58同城:丰富的同城分类信息。
(2)赶集网:丰富的同城分类信息。
16.网络指数(可能需用图像识别)
(1)百度指数:最大中文搜索数据,观测网络热点趋势。
(2)阿里指数:商品搜索和交易数据,基于淘宝、天猫和1688平台的交易数据,分析国内商品交易的概况。
(3)友盟指数:移动互联网应用数据,包含下载量、活跃度、用户情况等多维度数据。
(4)爱奇艺指数:涉及到播放趋势、播放设备、用户画像、地域分布、等多个方面数据。
(5)微指数:通过关键词的热议度,以及行业/类别的平均影响力,来反映微博舆情或账号的发展走势。
第五部分:详细数据分析
1.享一实验-获取QQ好友或QQ群里爆了照再撤回全部图片
有时候有了数据就想分析一下,跟大家分享一下我的实验。
这是我去年十一回来遍开始计划的实验,重装系统之后将QQ存储文件的文件夹放到了我的备份盘里, QQ会把你的聊天记录和图片分开存储,而且群组和好友也是分开存放在两个文件夹里的,好友G:\Tencent file\<your qq number>\Image\C2C,群组G:\Tencent file\<your qq number>\Image\Group。尽量保证电脑长时间开机,并且保证QQ一直在线,这样,每当QQ群里接受到消息之后,图片就被保存在了你的本地硬盘上。所以有人在群里爆了照再撤回其实是可以找到的,偷笑偷笑,只要找到Group文件夹里最新的照片就好了。
随着图片越来越多,QQ会把近期缓存的图片整理到一个新的文件夹里去,每到4000张图的时候就整理一次。我加了90多个QQ群,一半以上是千人群,6个月之后我的文件夹就变成了这个样子。
缓存了将近7个G的图片,一共十万五千张。
1.统计一下图片文件所携带的信息
我们简单的统计一下直接从图片文件所携带的信息。
这些图片一共有三种主要的格式, JPEG,PNG,GIF,通常就是,照片,截图,表情包~~
比例如下:
除了简单的类型统计呢,我们还可以根据图片的创建时间来统计信息,当然在登录QQ的一开始,也会因为大量的接受图片而导致一个时间序列上图片数量出现极值。
时间序列尺度在周,分钟,和天的变化情况就显而易见了。
哦,周末人们在网上竟然比平时少活跃了一半,可能是活跃的人少了,也可能是活跃的时间少了,但是我认为,大家在家睡到12点的可能性更大一点,谁叫我加的都是工科群,23333.
在看每天的数据,天哪,竟然到了1点多才算全睡觉,本宝宝突然觉得好心塞,这个行业是怎么了。然后第二天6点多陆续起床,12点又开始去吃饭去了。等等等等,图上都显示的清清楚楚。
再看一年中的数据,唔~~~,好像周期性很强烈, 一到周末大家就睡觉了嘛?哎,二月五号左右我们在干吗?怎么那么低?原来是在过年,大家都在家里浪着呢。怎么有两天是0?好吧,我在往返的火车上,好心塞。
等等,如果PNG代表截图,那可能表示大家在讨论问题。如果GIF多一些,可能表示大家在斗图水群啊!我好像找到了你们不工作偷懒的秘密!让我们来分别看一下三种图片的动态变化。
看到了吧,过年的时候大家拍了好多照片分享到群里!
那么周的呢?
左侧是总数,右侧是百分比,大家在周末,更少讨论工作,也很少斗图,竟然都出去玩拍照片去了!让我很是诧异,只有我一个人会自然醒么?
对了我们还有图片的宽高信息:
加了对数之后的分布情况,呃,貌似看不出什么,那直接用散点吧
几点线若隐若现的样子,连起来看看好了
这下知道那些线是什么了,是手机屏幕大小和电脑屏幕大小。斜线就是屏幕的长宽比啦。也很容易看出那些屏幕占了市场的主流。那1:1的?有这种屏幕??应该是截图的时候截的图长宽比在1左右浮动吧,看到条线也是最粗的。
顺便看了一下那些图是最常用的。腾讯为了减少图片在网络流上的浪费,对于md5一样的图片,他们在聊天记录里的名字是一样的!值得一提的是,一张gif动图的第一帧如果和某个静态的jpge图片一样的话,那么他们的名字也是一样的,基于这个原理,统计了一下29个文件夹下出现次数最多的图片前三名,竟然是这个:
果然还是表情包~~~~,最容易反应大家当时的心情么23333,帧数最多的是~~~~~
贪吃蛇~~,你们是有多无聊。
对了,本宝宝滤了一套表情包出来,哈哈哈
好了,就这样,这次不讨论过多的模式识别和监督学习之类的东西,希望大家也能在想不到的地方得到想不到的结果,希望能对各位有所启发。看完后希望你们也能给个这样的表情。
2. 拉勾网上的技术类的招聘信息
趁着五一有假有时间,写了这个爬虫把所有技术类的招聘信息爬了下来,闲着折腾一下。
用的是scrapy,总共约十万条数据(103167条数据),数据更新至4月30号。
如果有时间再把其他的数据都抓取下来。
分析结果页面:Crawllagou by ScarecrowFu
github:GitHub - ScarecrowFu/crawllagou
从结果来看,北京的需求量真的很大,几乎是排在第二的上海的两倍。同时也吸引了相应行业的人聚集,人的聚集又相应带动公司的聚集,两者相互影响使得北京成了互联网的主力军。广州的互联网行业比起北上深需求量低了不少。
需求最大的是本科以上,其次是大专。学历对于这行虽然不是决定性因素,但要入门还是必须的。
对经验要求,1-3年的占了大数,个人认为一来是这个阶段的人跳槽最多,二来是目前创业公司较多,两者造就这个比例。
阿里巴巴,这个不用说了。 良诺科贸不太清楚,位置在北京。而联想利泰则是联想集团成员企业,其前身是成立于1996年的联想集团研发部软件开发团队。
职位描述中,“团队”这个词出现的比重最大,我们的工作中离不开团队。与技能有关的依次是设计,测试,数据库,java,linux等等。
行业领域情况,移动互联网真的很火。
PHP是最好的语言??既然比java还多出20个?其实很多人都应该会python,可能是工作上作为主要开发语言的需求量不大,导致python的职位数量是倒数。
看情况北京的公司规模比其他城市都要大,总体来看,创业公司还是居多。
技术类工作薪酬普遍都比较高,这里没有做一个区间分析,有兴趣的可以分析一下,以后有时间我在重新做一做。
职位诱惑中,五险一金被提到的次数最多,这应该是标配才对,不是诱惑。。。
因为我在广州,所以把广州对python的经验要求和薪酬比例分析出来看看。
3.对拉勾网上面的职位信息进行爬取
爬虫系统
这是部分职位.....
这是爬下来的数据...
这是生成的Excel...
分析报告
4.职位印象
对于每一个职位而言,如何能迅速了解其背景呢?
简单来说呢,就是在抓取每一个职位职位数据,对其进行一系列的分析,分词、统计词频,生成排名前20的热度词...
这是拉勾网的职位要求...
下面以[数据挖掘]岗位为例进行试验...
1.这是抓取的所有详情页数据
2.这是分析结果
[职位印象]
深度学习:
可以看到,“深度学习”、“机器学习”、“算法”是最热门词汇,而Deep Learning常常使用的语言为C++和Python,应用领域最多的是计算机视觉。常被提及的是卷积神经网络(CNN),框架方面则为Caffe(虽说框架用什么无所谓,但还是有点好奇2017年了为什么不该是TensorFlow).
自然语言处理:
对于NLP岗位,“算法”和“机器学习”依然是最热门词汇,编程语言则提及最多的是Python和C++。
数据挖掘:
在综合了所有“数据挖掘”岗位招聘要求数据之后,经过分析,“数据挖掘”、“机器学习”、“算法”是常被提及的热度词。数据挖掘岗位对编程语言的要求则为Python和Java。毕竟有Hadoop/Spark等成熟的生态体系。
人工智能:
推荐系统:
作为算法岗,数据、算法、数据挖掘、个性化理所应当是热门词汇。
机器学习:
严格意义上来说,NLP/Computer Vision/Data Mining/AI 等都是Machine Learning的应用领域,但此处还是单独将该职位拆分出来分析。
Android:
移动开发则更偏向经验、架构、项目、设计模式。
5.留学论坛的数据分析:
这是托福总分的成绩分布图,我们专门把录取与被拒的数据分开做了统计,同时把申 请常春藤学校(Harvard, Yale, Cornell, Columbia, Princeton, Brown, Dartmouth, Upenn) 的同学的托福成绩单独做了统计对比。从图上看出,托福 100-106 分是分数集中区, 托福越低,被拒的概率越高,低托福逆袭常春藤的例子也比较少...托福越高,被录取 的概率也相对更高。托福在 102 分及以下时,被拒的人几乎都比录取的人多,但托福 大于 102 分时,录取的人几乎都被被拒的人多。而想申请藤校的同学也可以看出,托 福大于 102 时,藤校申请者的托福分数远高于平均水平。从数据上看,申请藤校的同 学托福过 104 就已经高于其他申请者的平均水平了。
接下来我们来分析托福单科分数。这是托福听力分数的分布图,我们特地把 Econ/MFE, 法学与常春藤申请者的托福听力分数做了单独分析。经济金融类专业的同 学托福听力最多的竟然是...竟然是...满分!在高分段(27-30)也是常春藤申请同学保 持领先。听力大于 26 分就比很多人更有优势了。
而托福的阅读水平,经济金融类的同学也是遥遥领先,满分 30 分依旧成为了众数。而 中国申请者托福阅读水平不得不说真的是高,大量集中在(28-30)范围内。中国学生 的英语阅读看了不是大问题...毕竟是做完形填空长大的...
藤校申请者还是都是高分狂魔呢...
我们来看中国学生最头疼的托福口语成绩分布。刚开始看到这图的时候吓一跳,以为 用了假的数据。然后在网上翻看托福口语评分标准我才发现,原来托福口语评分标准 里,就没有 21 分与 25 分这两个分数。(source: http://toefl.koolearn.com/20131230/784726.html)
在确认了数据的有效性后,我们发现(22-23)是大部分申请者的众数,口语平均水平 确实需要加强。不过 Econ/MFE 的同学口语成绩众数是 24 分,因此口语成绩的进步空 间还是很大。也看得出常春藤申请者的口语水平十分强势,高分段大有人在。一般口 语大于 22 分录取就具有优势了,Offer 数也会比 Reject 数多。口语大于 23 分就比很多 人领先了。
写作分数相对比较分散,集中在(24-28)之间。Econ/MFE 类的同学们受我一膜,众 数在 28 分。Ivy League 在高分段也是保持领先。写作大于 26 分就是一个不错的成绩 了。所以写作也是中国学生考托的刷分大坎,一定要过啊。
我们对 GRE 总分也进行了分析,把常春藤大学的申请成绩单独做了分析,并把 Offer 与 Reject 的 GRE 总分进行了对比。GRE 的众数是 320...这次意外的是无论是 Offer 还 是 Reject 还是 Ivy League,众数都是 320。高分段(329-340)的规律是:常春藤>Offer > Reject。而申请成绩只要大于 322 分就已经大于平均水平了。
如果想了解投资数据,IT桔子绝对是一个很好的选择。和朋友一起合作了这个小项目,利用python爬取IT桔子上的投资公司数据,包含第一层的投资公司名称,投资公司介绍,投资次数,投资领域,及第二层的投资组合等字段。先上个临时域名Data Visualization,数据挂在了这个上面,感兴趣的朋友可以去玩一下。感谢远在伦敦的
@温颖
提供爬虫支持,感谢@piupiu(他知乎是个空号,直接放他的个人网站了http://www.wuyue54.com)和我一起把这个项目做完。整个项目从0-1进行设计,纯手写,涉及html、angularjs、d3.js等语言,数据获取为python。
数据截止至2016.4.23,共获取投资公司2063个。
1.利用D3.js做了一个拓扑图草图
先利用D3.js做了一个拓扑图草图,把所有的投资机构关系理顺,投资次数越多代表该机构的气泡半径越大,具有共同投资关系的投资公司之间会存在连线,共同投资次数越多连线越宽。很明显的国内投资机构和国外投资机构自然分成两个聚类。
2. 之后增加了筛选,按照投资次数多少来筛选投资机构
3. 增加了点击气泡查看被投资公司列表,
为增加交互性添加了网页端的slider,可以直接滑动筛选投资次数大于一定数值的投资机构,界面颜色第一次做了统一调整。
4. 增加line chart和bar chart查看全部投资机构或者各投资机构的投资趋势变化及在各轮次的投资次数变化。
同时决定把这个项目做到用户友好,调整了整个颜色风格,并添加简单文案。
因为三个人在不同的国家,时间比较碎片化,目前line chart还存在一些小bug,不过不影响整体使用,之后会继续完善。临时域名http://www.benranfan.com/,感兴趣的朋友可以去随便玩一下。
第六部分:专爬知乎下的精华回答,作统计分析
以下,即是此项目的分析结果,希望能从另一个角度呈现出不一样的知乎。
一.代码
"talk is cheap, show me the code!" --屁话少说,放码过来。心急的朋友可以直接戳链接看源码,用的是Python3:
GitHub - SmileXie/zhihu_crawler
二.算法简述
1.爬虫算法
以根话题的话题树为启始,按广度优先遍历各子话题。话题的遍历深度为3。解析各话题下的精华回答。
2.收集数量
目前收集的信息共计50539个精华回答。
3.分析内容
- 精华回答的点赞数,答案长度等;
- 答题用户的id,点赞数,地区,性别,学历,学校,专业等;
三.统计结果
1.匿名答主
50539篇精华回答中,有3308篇的回答者选择了匿名发布答案。
2.答主性别
男15740,女5749.是否从一个侧面印证了知乎上程序员占了很大的比例.
3.答主受教育情况
按答主的所在(毕业)学校统计,TOP10的学校是:
可以看出,中国的顶尖高校对知乎的精华回答贡献颇多。
按答主所在的专业统计,TOP10专业是:
果然是程序猿的天堂。(上面的数据,我针对“计算机”和“金融”的数据做了处理,把“计算机”“计算机科学”“计算机科学与技术”合并为“计算机”,把“金融”和“金融学”合并为“金融”)
4.雇主
精华回答答主的雇主统计,互联网行业占了大多数。
5.精华回答的赞同数
按精华回答所获得的赞同数落在的区间,做统计
可见,大多数精华回答获得的赞同数是处于0~4999范围内的。
6.回答字数
如果按以下标准将精华回答按字数分类:
0~99:短篇
100~999:中篇
1000~9999:长篇
10000以上:超长篇
那么,精华回答的字数分布如下:
后记
作为一个对Python和C都有使用的程序员,在开发的过程中不断地领略着这两种语言的巨大差异。
Python把对开发者友好做到了极致,牺牲了性能。
C把性能做到了极致,牺牲了对开发者的友好。
这个项目只用了500行Python,如果换作500行C,估计只能完成上述功能的1/10吧。
第七部分:从某处爬到的某美国著名高校170000+份研究生申请文件。
因为显而易见的原因,我不能公布它的具体来源……
但是获取这些文件(或者从各种各样的pdf里提取文字)真的只是这件事的一小部分,重要的都在如何分析这些数据。比如遇到的第一个问题就是没有标注,也就是我们完全不知道这些申请者的录取结果如何,这样不能直接训练一个分类器。当然,某些系的网站上会有PhD学生的名单,那么如果我们想知道怎样的学生被录取,实际遇到的是一个半监督学习当中的不完全先验信息聚类问题。
这和我毕业论文大概处理的是相同的情况,虽然用的肯定不是这样来路不明的数据。因为毕业论文还没写完,暂时没有对这些文件处理。
我们也可以换个思路,做一些其他量的统计或者回归。例如,考虑学生GPA的分布,与学校的世界排名等的关系,那么至少可以为其他申请者提供一种参考:“申请该学校的有86.75%都比你优秀哦!”
最后,放几张图片,是我在随手翻这些文件时找到的亮点。
(我们最专业)
(这个学生被坑惨了啊)
(虽然大家都是自己写的推荐信,你们也不能太高调嘛)
(这是pdf属性里的文件标题,如果直接从word转换或打印,可能就会显示出文件名)
不知道p站(http://pixiv.net)的数据算不算。
一共爬了600w的高收藏图片,10w收藏以上8张,1w收藏以上1w2,1000收藏35w至36w,100收藏以上未计数。
自认为1000以上的漏网之鱼应该不超过200张吧。
看看有没有人赞,有的话我考虑下放出数据库文件(1.5G左右)。
补俩图
考虑到侵权问题,数据库我就不发了,以后可能会发一些基于这个数据库的数据分析和“带你逛p站”之类的。
赶出来个数据分析: 让数据告诉你在Pixiv什么最受欢迎
第八部分:爬过有趣的有用的有意义的网站
1.教务网站(涉及模拟登录)
很多高校在入学时的教务系统登录密码是一样的,而且50%的学生到大四都不改:)(123456)
当年写的第一个爬虫,用的php,因为php的curl库做模拟登录简单暴力,代码很简单,创建递归模拟登录,解析成绩页面。(南理工的同学应该还记得当初风格极简的教务系统,没有验证码,没有浏览器拦截,cookie不加密)。
硬盘里存着懒得改密码同学的姓名学号成绩在当时是一种可怕的成就感:|
2.小游戏网站
在CSTO上接了一个爬小游戏的单子,细聊后了解到他们在做针对低龄青少年的游戏网站(类似4399)。
也是从那个时候才知道原来小游戏网站的swf文件都是赤裸裸的对外开放,仍然记得交付的时候对方的表情,哦,原来这个网站的文件都是不加密的啊,那挺简单的。最后不得不悻悻地给钱走人。
由于对方站点"当时"没有做相关声明与技术拦截,原则上讲通过手动方式能够获取的文件都不算违法。
爬取京东,亚马逊商城的数据违法吗? - 互联网
3.亚文化与小清新网站
在做饥饿(StarvingTime)的时候调研过相关小众网站,这些网站都是土豪外包,法律条款基本没有,而且有些现在已经挺火了。大家没事可以爬爬,数据存下来总没有坏处。
VICE 中国 | 全球青年文化之声:世界在下沉,我们在狂欢
公路商店_为你不着边际的企图心
ChokStick 骚货
豆瓣东西
4.微信公众号
无意间发现饥饿公众号的文章出现在林子聪头像旁边,好奇微信有做加密怎么会被爬,民间高手也太强了。后来调研了一下,原来是搜狗将微信的接口买了下来造福大众。
如何利用爬虫爬微信公众号的内容? - 移动互联网
5.股票数据
前年暑假做神经网络,需要大量的个股数据用来训练,于是爬了A股1997-2014的所有数据。当时雅虎,新浪等都有api,先使用雅虎,资料太旧不成功。大家可以试试。
雅虎股票接口
新浪没有历史数据接口。
新浪实时股票数据接口http://hq.sinajs.cn/list=code
google的中国股票数据当时也调用的新浪接口,所以最终方案就是爬新浪页面,当时新浪财经的UI有展示历史数据,现在依然存在。
西宁特钢(sh600117)历史成交明细(对于个股也可以直接用同花顺等软件下载。)
6.音乐网站
落网 - 独立音乐推荐
硬盘里有它六千多首歌,一辈子都够听了
7.自己写的可配置爬虫
基于python3.4,有了异步访问后爬虫的效率简直了。
什么是可配置爬虫?
可以设置爬取深广度,爬取规则(正则直接写在xml里),爬取对象,爬取站点,爬取模式(主要是静态。动态爬取还在测试)
如图是一个从某用户开始深度爬取知乎的 config DEMO,稍微改几个字段就可以爬取别的站点,使用起来非常方便。
代码松耦合。数据存储用的是MongoDB,所以使用的话需要先安装mongodb,支持分布式,配合django+nginx开发系统工程效率可观。
可配置爬虫Python
1已经爬取了58整个网站的数据
数据主要是联系人 手机号码 登陆时间 注册时间
然后统计每个人的发帖量
最后挖掘潜在客户
软件按月收费
我来简单介绍下怎么挖掘潜在客户
首先我们能发现的信息只有那么几个字段
最主要的是登陆时间 和发帖次数
根据登陆时间来判断客户关注程度 如果客户这段时间每天都登陆你的网站说明他对你的网站的关注程度比较高
发帖次数能够说明客户的参与度
综合这两个因素 对所有的客户进行排序
把排序考前的信息展现出来
……………………………………………………
一、爬虫抓到的数据的分析方式设想
第一,在分析数据之前我们总是带有某些特殊的目的、需求和预期想要得到的结论的。这往往是一个实际的问题,可能是商业性的,当然也可能是学术性的。举个栗子,我们都知道,百度贴吧中总是存在各种各样的信息,有一些是水军,有一些是有用的等等。我的需求是,我想要写一个爬虫获取某贴吧里每天所有的帖子及其评论,但是希望过滤到垃圾信息(这样可以大大提高我的阅读效率,逛过吧的应该知道,某些吧里一堆水军)。于是,爬虫就是我首先要写的程序了。爬虫写好了,问题来了。问题是,每天24:00我抓完数据之后要怎么过滤掉垃圾信息及水军信息呢? 这是需要一种能力的,我觉得这是题主想要获得的能力。就是将商业性或者学术性的问题转化成一个可用数据分析解决的问题这是数据分析的一种能力。我觉得这需要三个方面的能力:1、领域知识,就是你对要分析的问题的领域的熟悉程度;2、数据挖掘、分析算法的了解程度,对于常用的分类、聚类、回归、关联等算法了解一些把;还有一些统计的方法;3、sense。这个就比较玄乎了,一眼看出问题是什么。。可能跟前两个方面存在共线性,但不得不承认,有些人确实存在特殊的天赋。。。
在此不展开说了。比如,在这个栗子里,我们可以采用分类的方式来解决问题,算法那就是一些分类算法了,SVM、KNN、Decision Tree等等。训练一个二值分类器,垃圾与非垃圾。
第二,抓取到的数据不可能涵盖到我们想要知道的所有方面,而且数据的清洁性也不见得能达到所有字段都可以用于分析的程度。还是举个栗子,小明想研究abcde,5个问题。但是,观察数据之后,小明发现数据只能支持他要分析的abc,3个问题(sign。。);但是在观察数据的过程中,小明又得到了启发,f问题也可以分析。于是,最终,小明分析的可能是abcf,4个问题。
所以,数据分析也是一个trade-off的问题。我们抓取到得数据和要进行的分析之间的trade-off。
trade-off的过程就是这样,产生预期→收集、处理、观察数据→部分预期满足、部分预期受挫、数据启发产生新的预期→开始进行分析;甚至在分析的过程中,还会发现前面预期的不合理性,或者收到了进一步的启发,这些都是有可能的。
最后来一个大栗子。抓取了新浪微博的数据,其实前后抓取了两次,keyword分别是“iphone”和“京东白条”。 两次分析的思路类似,抓取的字段类似,两个放在一起说啦,以“京东白条”为例来描述。
二.分析的主题:《基于新浪微博的京东白条发展建议》
一、数据来源:新浪微博。
二、抓取策略:在新浪微博搜索框进行检索,获取检索结果。
三、开发环境:python3
四、数据维度及特征:
1. 关于微博博文。(正文、点赞数、转发数、评论数、发布设备、发表日期、博主主页url)
2. 关于博主。(历史博客书、粉丝数、关注数、性别、生日,地区、描述)
五、大家停下来,想想你们认为可以做的统计与分析的维度有哪些???
六、当时做的统计与分析。
1. 基本统计学:每天微博有多少的趋势图(解析趋势,还原到历史事件);性别分布;地区分布(省份级别的分析,与GDP密切相关,但存在异常省份,可进一步分析为何这些省份对于京东白条的关注有异常,为进一步的营销和白条策略做参考);累计分布(总点赞数、总转发数、总评论数排名前20%,1%的博主占总博主的人数)
2. 情感分析。 对微博正文切词,然后进行情感判别。 我想了两个思路,第一个基于切词、情感词典和极性词的情感判别;第二个是基于机器学习的(与垃圾分类类似,进行情感分类;可以训练个分类器试试)。当时实现了第一个,判别了每条微博正文的情感value。然后与性别、省份做了交叉分析。。。比较性别和省份上对于京东白条情感值的差别。我认为,这个对于营销和产品设计是有意义的。发现特定群体对于某些产品的特定情感情况。 然后为进一步的营销或者产品设计作参考把。
3. 回归分析,以微博的点赞数、转发数、评论数为因变量(营销效果);以博主粉丝数、微博数、关注数、情感值和性别为自变量。做回归。主要是想得到营销方面的结论,大家都知道,微博营销各种存在,水军、大V等等。那么如果京东白条要找水军,应该找怎样的水军呢?
结论:低调的又富有正能量的男神;
低调是说发的微博比较少的人,营销效果好一些;男生好于女生;情感值高的微博好于情感值低得微博;粉丝多的优于粉丝少的。 这四条是统计学上显著的结论。
第九部分:哪些数据比较有价值?
微信公众号数据
如果你用过新榜或者西瓜数据你就觉得微信公众号的数据太有价值了,因为微信公众号是个封闭的体系,如果你是广告主,你需要全面评估一个公众号才敢投放广告,否则一个几十万的广告打水漂后悔莫及
如果你能对公众号进行全面的诊断,分析公众号最近的发文次数、阅读量、评论、点赞等数据,还有公众号阅读监控,因为有些公众号喜欢通过刷阅读来蒙骗广告主。
比如某篇文章的阅读增量曲线在凌晨的时候突然猛增,你说正不正常
比如公众号的全面诊断
如果这些数据你能爬下来,当然非常有价值了。
没有技术思维的销售不是好财务
看过了回答前几名的答案,感觉都挺高大上的,不过有点过于粗暴,直接图文并茂就来了,并没有认真看题主关切的点。一:应该搜集哪方面的数据,也就是说哪些数据会比较有价值(方向、方向、方向);二:数据分析出来了,该如何创造价值,也就是带来回报(回报、回报、回报)。
哪些数据比较有价值?
一、我们先拿企业和事业单位来分析
一个企业,不管是实体企业还是互联网企业,大都会有这几个方面的数据,企业基本信息、招聘、网站、股东结构、管理层结构、借贷情况、专利情况、诉讼、信用记录等。围绕这些都可以做文章,比如说在信息需求还没有被像现在这么大的时候,一本黄页拿在手上,都如获至宝。它解决了企业基本信息和联系方式的不对称。所以最早做黄页的人赚到钱了,比如我们的马云先生。到今天,信息已经很丰富了,只要你存在互联网上,多多少少都会留下痕迹,不管是情缘不情愿、有意无意。这个时候,信息整合就变得非常重要,也满足了很多的需求。比如投行的客户经理要调查企业的资质、信用、股东结构等。都需要深度的数据分析带来支撑。再譬如市场经理跟一个项目,在没有跟对方接口人联系的情况下,自己完全可以在网上摸查一下企业的最新动态。比如招聘、比如股权变更、注资扩大、经营范围变更、有败诉、有不动产抵押等等。都可以为接下来的跟踪和进一步的谈判增加筹码,以及做到知己知彼。
当然,这方面价值的挖掘已经有很多先行者在做了,而且做得很好。比如企查查、企信宝、天眼查,目前就我个人而言,企信宝用的最顺心应手,不仅免费,而且层层筛选的功能强大,最良心的是企信宝的数据更新非常快。企查查作为先行者,在信息更新速度上,落后了。
这个是企业层面的数据价值挖掘。当然还有很多,我没有想到的细分领域,比如“采购、招标、保险缴纳、员工福利”等。
ps:企业或者事业单位对数据的需求是永远都在的,好的深度分析的数据那更是有价值的。如何做的比同行更好,我觉得有这么几点。1:更新速度一定要快;2、细分别人尚未开发的领域;3、产品设计一定要人性化,比如筛选智能,比如移动端app的使用体验等。
二、我们再来拿个人分析。
个人不同于企业,个人的数量级比企业那是大得多得多的,个人的需求一旦上来,那将是井喷式的。我们可以想象下,国内有很多电商平台,面对企业的面对个人的都有很多。比如化工行业领头羊“中国化工网”,它做的再牛逼,做的再品牌悠久,毕竟面对的客户群体狭窄决定了上限不高。反观国内某宝,每天产生多少利润。就可以理解个人的数据需求一旦被打开,那将是无法想象的。
我们再来看个人都有哪些需求,高考填自愿时,家长苦苦思考,该给孩子抱一个什么有“钱”途的专业,通常情况下,都是根据自己的人生经验或者亲戚朋友的建议拍脑袋决定的,假如有一个数据它搜集了各大招聘网站的信息。分析出来了,近3年最热门的岗位,以及平均薪水最高的岗位,以及分别要求雇员会哪些技能。我想家长做决定肯定会更快一点的。同样,在我天朝股民朋友那是很多的,假如有大数据能分析出整体股市的规律以及个股的特点,那也是件振奋人心的事。当然,在我天朝,股票从来都是拿不住规律的。被你找到规律了,游戏还怎么玩~ 依靠这个逻辑赚钱的,比如同花顺、大智慧等。再比如旅游行业,很多人都会想,什么时候出行性价比最高,同样可以根据近3年各大旅游网站的数据来分析。甚至可以根据下方的评论分析出哪些景点符合你的预期。
数据如何转换成回报--盈利模式探讨?
有流量和粘度,网站就不怕没有盈利。这个观点到今天依然没有过时。说到底如何盈利,一直是很多网站和平台的困惑点。如“新浪微博”,数亿级别的流量,没有很好的研究出盈利模式,到现在依然不温不火。也如我们的“知乎”,到今天依然不敢大肆的接入广告。客户培养起来难,得罪客户确实很快的。
当然,基础服务+付费增值服务。这是个很成熟的盈利方式,也是可以预见的到的能成功的模式,只要你的数据分析的精炼,能达到客户的需求,自然就会有人买单,你的数据成功的帮投行经理做出了是否要投10亿项目的重大决定。你每年向他收取500元的年费,过分吗 ?跟同花顺的业务员信心满满的推荐你10万的软件套餐比,你做的就是慈善项目。真的~
还有就是一定要深挖,别人尚未发现或重视的细分领域。未来的互联网一定是细分,精耕细作的时代。
结语:兄弟你如果想通过爬虫技术做的网站,成为google、苹果那样的科技巨头,我暂时还没想到辣么大的可能,但是你技术成熟,用心做一件事,发现了好的领域需求。我想你轻松实现年入100万,迎娶白富美是完全可能的。更好的情况 到时候有投行排队要给你注资的时候,那你就真的成功了。加油吧!大中午的舍弃午休时间一口气打这么多字,键盘敲的噼里啪啦响,隔壁同事都差点跟我急了。
第十部分:爬取张佳玮138w+知乎关注者:数据可视化
一、前言
作为简书上第一篇文章,先介绍下小背景,即为什么爬知乎第一大V张公子的138w+关注者信息?
其实之前也写过不少小爬虫,按照网上各种教程实例去练手,“不可避免”的爬过妹子图、爬过豆瓣Top250电影等等;也基于自身的想法,在浙大120周年校庆前,听闻北美帝国大厦首次给大陆学校亮灯,于是爬取2016-2017年官网上每日的亮灯图并用python的PIL库做了几个小logo,算是一名吃瓜群众自发的庆贺行为;(更多照片见于:Deserts-X 我的相册-北美帝国大厦亮灯图:ZJU_120 logo)
也因为喜欢鲁迅的作品,爬过在线鲁迅全集的全部文章标题和链接;另外听说太祖的某卷书是禁书,于是顺带也爬了遍毛选;还帮老同学在某票据网站下线前爬了大部分机构、人员信息,说是蛮值钱,然而也还在留着落灰......
再是知道百度Echarts开源的可视化网站里面的图很酷炫,比如使我着迷的:微博签到数据点亮中国,于是想着可以爬取微博大明星、小鲜肉的粉丝的居住地,然后搞搞怎么画出全国乃至全球分布情况。但发现几年前微博就限制只能查看200左右粉丝数(具体忘了),蛮扫兴的,于是将目光转向了知乎......
而既然要爬,那就爬关注人数最多的张公子吧,数据量也大,这方面是之前小项目所不及的,此前也看过不少爬知乎数据与分析的文章,因此也想练练手,看看大量访问与获取数据时会不会遇到什么封IP的反爬措施,以及数据可视化能搞成什么样。
不过此文在爬虫部分不做过多展开,看情况后续再另写一文。思路如下:抓包获取张佳玮主页关注者api,然后改变网址中offset参数为20的倍数,一直翻页直到获取138w+关注者信息,其中返回的json数据主要有:关注者的昵称、主页id(即url_token)、性别、签名、被关注人数等,也就是说需要访问所有主页id,才能获取更多信息(个人主页api:以黄继新为例):居住地、所在行业、职业经历、教育经历、获赞数、感谢数、收藏数等等。鉴于还不怎么会多进程爬取,如果把所有id再爬一遍会非常耗时间,于是筛选被关注数100+的id,发现只剩了4.1w+,之后较完整提取了这部分的信息,后续可视化也多基于此。
二、数据可视化
1、关注人数
大V总是少数的,而小透明到底有多少、分布情况如何呢?将关注人数划分成不同区间,绘制成如下金字塔图:
作为一只小透明,在此过程中发现自己处于前2w的位置,即图中红色区域,还是蛮吃惊的。上文已提到100+关注就超过了134w的用户,而1k+、1w+、10w+就越来越接近塔尖,越来越接近张公子的所在,看上图10w+以上的区域,如同高耸入云,渺然不可见,“乱山合沓,空翠爽肌,寂无人行,止有鸟道”,令小透明很是神往。
上升之路虽然崎岖,但也同样说明只要多增几个关注,就胜过了数以万计的用户,这对于有志于成为大V的人,或许能在艰难的前行之路上,靠此数据透露的信息,拾得些许信心。
细看底部的区间,0关注有40.2w+,1-10关注有76.6w+,区分度已赫然形成,但小透明可能感受不出,那怕有几百的关注,何尝不会觉得自己依旧是个小透明呢?有谁会相信斩获10人关注,就超过了100w+的用户,数据能告知人经验之外的事实,在此可见一斑。当然知乎大量用户涌入且多数人并不产生优质或有趣的回答,也是一二原因。
继续看100+以上的数据,底部占比依旧明显,塔尖依然很小。
2、性别情况
接着对100+关注人群的性别组成进行分析,发现男女比例基本维持在2:1,与138w+用户的男女比例差别不大。当然10w+关注由于人数较少,比例超过3:1,是否能得出男性在这方面更为优秀就不得而知了。
3、10w+大V
前文已多次提到10w+大V,那么这190人里到底都有谁呢?这里以关注人数为权重,生成词云如下:
大家上知乎的话应该也有关注一些大V,许多名字应该并不陌生,比如马伯庸、动机在杭州、葛巾、朱炫、丁香医生等等,当然也会发现并不是所有大V都关注了张公子,哪怕他是知乎第一人,目前已交出了3026个回答,135个知乎收录回答的傲人成绩(据说也是豆瓣和虎扑第一人)。
4、居住地分布
终于到了我最初开始这个项目时,最想获取的的信息了。虽然由于爬取效率而筛选掉了100关注以下的id共134w,数据量方面不如标题所示的那么多,略有遗憾,但其实真的拿到4.1w+条较优质数据时,发现处理起来也并不容易。
比如这里的居住地信息,有乱填水星、火星、那美克星,也有填国家、省份、县市、街道格式不一的,还有诸如老和山之类外行人不明白的“哑谜”等等,数据之脏令人头疼,且纯文本的数据又不像数字类可以筛选、排序,还没想到好的方式应对。再者Echarts官网虽然有不少可以套用的模板,但有很多地方的经纬度需要重新获取,这样就在数据处理和地图上定位有两处难题需要解决。
由于第一次处理这类数据并可视化,第一次用Echarts就打算画这个酷炫的地图,因此最终先缩小数据量,还是以1w+大V的数据来可视化,目前先完成国内分布情况,以后看情况再扩大数据量和绘制全球分布情况。
其中出现次数排名前几的城市依次为:北京 360,上海 183,深圳 55,杭州 52,广州 47,成都 26,南京 20......应该算是意料之中的。考虑到并不是每个人对这些点所代表的城市都熟悉,加上城市名,效果如下,重叠较为严重,显示效果不够好,仍需解决。
5、Top20 系列
接下来分别对所在行业、职业经历、教育经历等进行分析,结果如下(注:用户有多条职业经历或教育经历的,仅爬取了最新的一条数据):
学校方面几乎全为985、211高校,当然拿得出手的会乐于写上,略微差些的可能不会填写,而且涌入用户多了后,这类数据也就只是调侃知乎人人都是985高校,年薪百万的点了。所在行业方面,互联网遥遥领先,计算机软件、金融、高等教育位居前四。
Top20 公司中BAT、网易、华为、小米科技、美团网以及谷歌、Facebook、微软等大厂都悉数在列。再看Top20 职业里除了各种名号的程序员、产品经理、运营等互联网职业,创始人、CEO等占据前排,不可谓不令人大惊从早到晚失色。
6、认证信息
原本只知道博士可以提供信息得到认证,知乎也会给予其回答更好的显示途径,使其更容易成长为大V,以此作为对高学历人群、优质用户的奖励。
此次抓取的100+关注4.1w+条数据中有208条认证信息。除却各种专业的博士、博士后外,还有37家公司、机构,9条医师,11条教授/讲师/研究员,13条CFA、CPA持证人或工程师、建筑师,以及28条其他类:副总裁、创始人、记者、律师、WCG2005-2006魔兽争霸项目世界冠军、职业自行车手、主持人、作家、歌手等等。看来还是有不少优质用户可以后续去了解下的。
7、优秀回答者
除了认证信息外,优秀回答者这是鉴别某用户是否为优质用户,是否值得关注的一个重要指标。包含张佳玮在内,共有468位优秀回答者,涉及257个话题,共出现768人次优秀回答者标签。
而所有优秀回答者贡献的回答和知乎收录回答情况如下:
最右上角的便是张佳玮的贡献情况,令人望尘莫及。也有不少用户贡献了上千个回答,可以说是非常高产。但大部分用户回答数<1000,收录数<50。密集区域放大后如图:
有不少数据收录回答为0,因为还不知道知乎优秀回答者的评判标准,所以此处还需进一步了解。另外这些数据点,对应的加上一些大V名字可能显示起来能好,但一直在摸索,还不得要领。
三、小结
本项目是个人第一次百万级数据的爬取,当然由于爬取效率方面需要改进,所以详细用户信息选择性的只爬了100+关注人数共4.1w+的id。另外也是第一次数据可视化,从完全不懂Echarts的各种参数,硬刚配置项,到勉强获得了上述还算能看的一些数据图,不少地方还需进一步学习、改进,以求获得更合乎要求的、理想的、自定义的可视化图。
另外,除却上述数据外,还有点赞数、感谢数、收藏数、关注数和被关注数、签名、个人简介等等数据并未处理,但基本想要获取的图都得到了,算是完成了此项目,也学到了很多东西。
每天自动获取深圳上海北京的新房二手房的成交量
代码: http://30daydo.com/article/106
把数据写入数据库:
自己写个python 爬虫,把喜欢的知乎答案自动推送的kindle上看。 平时上网太多干扰,喜欢静下来断网看。
代码:
python爬虫 推送知乎文章到kindle电子书
github: GitHub - Rockyzsu/zhihuToKindle
python 获取 中国证券网 的公告
代码:http://www.30daydo.com/article/59
中国证券网: 公告解读-高含金量的上市公司公告解读产品
私货:
这个网站的公告会比同花顺东方财富的早一点,而且还出现过早上中国证券网已经发了公告,而东财却拿去做午间公告,以至于可以提前获取公告提前埋伏。
生成的公告保存在stock/文件夹下,以日期命名。 下面脚本是循坏检测,如果有新的公告就会继续生成。
默认保存前3页的公告。(一次过太多页会被网站暂时屏蔽几分钟)。 代码以及使用了切换header来躲避网站的封杀。
公司的网络太差,还有监控,领导同事就坐在边上,为了方便上班时间炒股,我从很多网站爬取了实时的各种股票数据并加以大数据统计分析,做了个网站,http://www.kaixinlc.com,如果您是上班族,不妨试用一下。
很多朋友问我概率是怎么计算出来的,统一回复:
- 每日收盘后分析股票的当天的特征,按照价格、成交金额、与历史价格对比、连续一段时间的表现等等来进行分类。举例:股票A当天的特征是:价格创100日新低,成交额创100日新高,对比20天前下跌了20%,连续下跌7天等等
- 一只股票每日目前可以分析出大概30个特征,大家多补充啊,登录系统后点击股票的名称可以查看股票满足的特征。
- 设定一个目标,如希望股票5天后价格上涨3%
- 分析一段时间的历史数据,如20天,40天,100天,200天 等等,将满足条件的股票的特征进行汇总,如统计了100天数据,发现连续下跌10天的股票(假设共100只)5天后价格上涨3%的有50只,5天后价格下跌的有30只,5天后价格上涨但是幅度小于3%的20只,则统计100日数据股票3日后价格上涨3%的概率是 50/(50+30)=62.5%,不考虑能够保本但是又达不到目标的股票
- 考虑概率的同时也需考虑统计股票样本的数量,查询列表中第一列是满足条件的股票数量,第二列是价格下跌的股票数量。
概率分布这个功能的作用是:
- 每只股票可能有多个特征,举例:股票A当天的特征是:价格创100日新低,成交额创100日新高,对比20天前下跌了20%,连续下跌7天
- 根据一段时间的统计结果(如100天内数据统计5天后上涨3%)的概率,发现 价格创100日新低符合条件的概率是70%,成交额创100日新高符合条件的概率是60%,对比20天前下跌了20%符合条件的概率是50%,连续下跌7天符合条件的概率是40%
- 则当天股票A的概率分布情况是概率大于60%的特征1个,大于50%的特征2个,小于50%的特征1个
- 该功能的作用就是将股票所有特征的概率分布情况列出,让您对股票有一个整体的认识。
http://pan.baidu.com/s/1jI4ihN4 (点击下载爬虫程序)
爬知乎上的图(mei)片(nv),可以修改配置,填写自己感兴趣的关键字。
项目源码地址:Joynet/SpiderZhihu.lua at master · IronsDu/Joynet · GitHub
运行结果截图:
某数据公司前员工,去爬私募排排网基金净值的数据跟雪球讨论个股的数据,爬下来1家公司1年卖个10万问题不大。
其他参考TuShare -财经数据接口包
数据商城
另外他们旗下有个量化社区,你看用户提问哪些API最多,说明最有价值。
第十一部分:拉勾招聘网站爬取了532条数据分析师岗位的招聘数据
本文通过爬虫形式,从拉勾招聘网站爬取了532条数据分析师岗位的招聘数据,数据内容主要包含招聘岗位、公司、城市、薪资、学历、经验、职责和岗位要求等。本文将从3个部分来展开研究,即数据分析师需求现状、数据分析师工作简述和数据分析师薪酬影响因素。
一、数据分析师需求现状
(1)城市分布
结合下图可以看出,数据分析师招聘需求最多的5个城市分别是北京、上海、杭州、广州和深圳。北京的数据分析师岗位需求最多,远超上海、杭州和广州需求之和。同时北京招聘数据分析师的公司也是最多的,是上海的1.5倍,杭州的3.5倍。即使排除了拉勾网Base在北京中关村的地理优势,北京在数据分析师招聘需求上依然是遥遥领先的。
(2)行业分布
在拉勾网上发布职位的公司一般都会贴上1-2个标签,本文将这些标签重复计算,统计结果如下图。结合下图可以看出,移动互联网是数据分析师需求最多的领域,其次是金融、电子商务、数据服务。移动互联网、金融、电子商务这些领域是消费者数据集中的行业,并且需要通过大数据的分析,了解消费者的行为,构建用户画像。
(3)学历要求
在招聘岗位的学历要求上看,数据分析师对本科及以上的需求较多,“不限“或者硕士学历的要求的职位较少,大专学历特别优秀的人也可。可以看出数据分析师岗位对学历的要求较高,可能的原因是数据分析师会涉及到高等数学、代数、统计等专业知识和相关的行业知识。
(4)经验要求
结合下图,发现数据分析师岗位要求的工作经验主要是1-5年,1年以下或者经验不限的比较少,说明招聘公司希望招聘的是有相关经验的,入职后是能立马上手的。同时,也可以看出工作经验10年以上的岗位招聘数量较少,可以看出数据分析师一般的职业年限是1-10年,在超过10年后,可能会面型职业转型,向管理岗位、数据挖掘、数据架构等转变。
(5)公司规模分布
通过分析招聘公司的规模,可以看出公司规模在50人以上的公司对数据分析师的需求比较大,50人以下的公司对数据分析师的需求较少。50人以下的公司还处于创业的初期,业务发展还并未很成熟,最需要的人才应该是销售和营销人员,扩大市场份额、增加用户量,因此对偏向于后端的数据分析师的需求还不高。当公司发展到50人以上,尤其是150人以上的时候,公司已经进入了成熟期,业务发展较为成熟,对数据分析的需求逐渐增加。
再深入研究50人以下的企业,发现大部分需要数据分析需求的公司都归属于数据服务领域。数据服务领域是专门提供数据报告、数据分析服务的公司,数据分析师是第一生产力,因此对数据分析师的需求自然就多。
(6)公司融资阶段
从公司发展阶段来说,除了未融资和天使轮的公司外,其他阶段对数据分析的需求量较多,尤其是不需要融资的需求是最大的。
二、数据分析师工作简述
(1)岗位职责
通过下图对数据分析师岗位职责的分析,可以发现数据分析师岗位的关键词是数据分析、业务分析、运营分析、报告、策略、优化等。由此可见,数据分析师岗位的主要职责是针对公司业务和产品,通过建立数据模型,分析公司的业务指标、运营情况,输出业务分析报告、运营报告、用户行为报告等,为公司未来的业务发展和运营提供改进的建议和措施。
(2)岗位要求
从数据分析师岗位要求来看,公司对应聘者要求的关键词是数据分析、数据挖掘、相关经验、SQL、Excel、SPSS、SAS、Hadoop、Python等。由此可以看出,公司一方面是希望应聘者掌握数据分析的能力,并且掌握分析相关的软件如SQL、Excel、SPSS等,另一方面是公司要求应聘者是有相关工作经验的。
三、数据分析师薪资影响因素
薪资是反映职业未来发展潜力的一大因素之一,也是就业人员最看重的一大因素。结合下图,可以看出数据分析师的薪酬范围是2k到56k,平均薪酬是16.9k。整体呈现双高峰的偏左分布。薪资主要是集中在10-16k和20-24k,82%的岗位的薪资待遇超过10k。水平极差是52.5,薪资的水平悬殊较大。
本文将从城市、行业、学历、经验、公司、技能来研究影响薪资大小的因素。
(1)城市因素
本文选取招聘岗位数量最多的前10个城市来研究城市对数据分析师薪酬的影响作用。这10大城市招聘的岗位数量有497个,占了总数的93.4%。分析这10大城市的平均工资情况,如下图所示。可以看出北京和上海的最低工资是最高的,大约是6K,而北京所能达到的最高工资是最高的,约37k,遥遥领先其他城市。北京和上海薪资的中位数差异不大,大约是20k,远高于其他8个城市。整体来看,北京和上海有着更多的职位,起薪也最高,岗位发展所能获得薪资也是最高的。
(2)领域因素
本文选取招聘数量前10的领域进行分析,从下图可以看出,除了文化娱乐,其他领域的薪资中位数都差不多,薪资水平都集中在14k-16k。文化娱乐行业的薪资中位数和最低值都高于其他行业。结合现在知识付费、娱乐直播行业成为风口领域,说明文化娱乐行业是热门领域,也愿意花高薪来吸引人才。
从最高薪资上看,移动互联网、金融和教育行业所能提供的薪资是最高的。如果想要博取高薪资,可以考虑从移动互联网、金融或者教育行业中来找。
(3)学历因素
在岗位薪资上,硕士及以上的平均起薪是最高的,为6k,本科、大专和学历不限的平均起薪差不多,为3k-4k。但是硕士及以上和本科及以上的最高工资是差不多的,为38k,远高于大专和学历不限。从中可以得出,学历对数据分析职业发展是有一定影响的,学历低于本科的话,其上升通道和薪资增长是会受到一定的限制。
(4)经验因素
从下图我们可以看出,随着相关经验年限的增加,数据分析师的起薪、最高薪资和薪资中位数都是逐渐增加的,5-10年经验的起薪(12k)、最高薪资(45k)、薪资中位数(25k)都是最高。
由于1年以下和10年以上的招聘数量较少,分别为4和2,研究范本不够,波动性较大,暂不列为分析之列。究其1年以下和10年以上招聘数量少的原因可能是(1)公司希望招聘的员工至少是有1年相关经验;(2)10年以上工作经验的员工不需要通过招聘网站获取,可能是直接通过内部推荐等渠道被挖走;(3)10年以上工作经验的不再做数据分析了,可能从事更后端、更深的岗位,如架构师、人工智能,或是转向管理岗位。
(5)公司规模因素
鉴于少于15人的公司数量仅仅为2个,样板量太少,分析中不纳入考虑。结合下图可以看出,随着公司规模的增大,数据分析师的中位数薪资水平也是逐渐上升的,2000人以上的公司其中位数的薪资为17.5k。但在比较最高薪资时,可以看出500-2000人和2000人以上的公司所能达到的薪资是差不多的,约为38k。从中我们可以得出的结论,如果想要获得较大的薪资水平的话,可以去规模大的公司。规模小的公司,业务、体系还未成熟,所能提供的薪资水平也不是很高。
(6)公司发展阶段因素
由下图可以看出,随着工资的发展壮大,薪资水平也逐渐提升。企业在成长(A轮、B轮)到成熟阶段(C论、D轮及以上和不需要融资)阶段,薪资水平是高于其他阶段的,尤其是在D轮及以上阶段,最高薪资也是远超其他阶段。这可能是因为这个阶段的企业为了冲击上市,高新招揽良才。在上市后,由于有了上市公司这个title来吸引人才,反而在薪资上并不具备绝对的吸引力。
(7)技能因素
从每个岗位的职位描述,统计每种分析工具出现的频次。结合下图可以看出,公司对应聘者要求最多的分析工具是SQL、R、Python和Excel。以SQL为代表的关系型数据库、以R语言为代表的数据分析可视化、以Python为代表的语言和以Hadoop为代表的非关系型数据库成为工具的主流。同时我们也可以发现,Excel技能的掌握是大部分公司的普遍要求,也是常规数据分析常用的工具。应聘者在应聘数据分析相关职位的时候,至少是需要熟悉这4个软件中2个,尤其是对转行的人而言。
从下图可以看出,技能与薪资之间的关系,发现相比于其他工具,非关系型数据库工具Hadoop和HIVE的起薪、薪资的中位数和最高薪资都是最高的。要求掌握Hadoop和HIVE的岗位主要是偏向于数据仓库构建、数据架构,偏向数据挖掘,对技能要求比一般的数据分析要高。如果只是掌握Excel工具,个人的起始薪资和所能获得最高薪资都是受限的。因此应聘者在应聘数据分析师岗位时,需要根据岗位的需求,至少掌握两个分析工具。
五、结论
(1)可选择北京和上海入职,并且选择移动互联网和金融行业。
通过分析数据分析师的分布,北京和上海的岗位需求和招聘公司是最多的,并且北京和上海岗位的起薪、薪资中位数与最高薪资都是最高的。虽然北京和上海的消费水平较高,但是北京和上海的就业机会多,职业发展前景大。同时在数据分析行业,移动互联网和金融行业的需求做多,公司开的薪酬也是最高的。
(2)可选择公司规模较大、发展较为成熟的公司
对数据分析师需求较多的是公司规模在150人以上,发展在A轮以上的公司。公司规模越多,公司所开的起薪和最高薪资是最高。公司业务发展较为成熟后,数据分析的框架体系也较为成熟,数据分析师可发挥的空间也较大。
(3)至少需要积累1年的相关工作经验,至少要掌握2个以上的数据分析工具
数据分析师的岗位要求中最重要的2点是业务经验和数据分析能力,需要应聘者对公司的业务有一定的接触和认识,同时也掌握了数据分析所需的技能和分析框架。因此91%的岗位都是需要1年以上的相关工作经验,并且要求应聘者掌握相关的数据分析工具,尤其是SQL、Excel和R。对于转行人士而言,在应聘之前需要自行学习数据分析相关知识和技能,并且实际操作相关项目,从而积累相关的经验。
第十二部分:爬虫采集知乎的粉丝情况
知乎上面的数据很多,可以用爬虫来分析分析。
例如,造数君用爬虫来分析关注造数君的粉丝们。
先来看看结果是怎样的。
分为两步,获取数据和分析数据
首先,使用造数爬取所有关注者的信息。操作就是“点点点”
然后就拿到数据了
分析采用BDP和Jupyter Notebook
粉丝数排行
可以看到除了个别超级大V外,多数人粉丝还是挺少的,图片上只显示了前面的数据。如果画出函数图像来,应该是减函数吧。
回答与发文量
凭直观感觉来说,一个人的回答数与发文量应该是成正比的。看图说话,趋势图说明人们还是更偏爱去回答问题,按常理来说也说得通,知乎毕竟是一个问答平台
一个真实的网络问答社区,帮助你寻找答案,分享知识。
关注者与发文量
发现关注数与发文量并不是成正比关系,发文量为0的关注者仍然有很多,这还是和知乎有关系,毕竟主打问答社区,而不像简书是一个创作社区。
知乎开放写文章功能在一年前,发展速度的还是快的,详情看 每个人都可以在知乎写文章了,同时我们还发布了更强大的专栏
下面是Jupyter制作的图云。
关注者昵称
排在前面的是:wang、先生、世界、大大、zhang、Chen、leo、土豆、星星等等。
为什么“wang”出现频率如此之高
个人介绍图云
排在前面的是:学生、程序员、软件工程师、银行基层、管理者、IT咨询师、自由职业等等,看来大家喜欢在介绍里写明自己的职业。不过知乎上学生真的好多啊。
最后,你也可以对自己的关注者和关注的人做一个小分析,看看他们喜欢什么。不会代码也没关系,使用造数爬取信息,BDP来数据可视化。
赶紧试试吧!
简单总结,个人感觉、取决下面几点
1)兴趣:你的兴趣取向能体现你对感兴趣行业的了解程度,了解的越深,通过数据的方式能帮你解惑,作指导
2)数据敏感度:同样的数据,摆在不同人面前,能挖掘有价值的信息量完全可能不同,这和每个人经验,能力,天生对数据敏感度都有关系,需要多思考,多了解行业,多看书
3)技术能力,
先是分布式数据爬取如何构建
然后数据去重,清洗如何来做,数据如何来存储
再然后如何数据分析,数据如何呈现
等等,关联的点很多
在学习的时候,循序渐进,不断努力,思考就会有精进
对于爬取哪些站?举个简单例子
从最熟悉的站展开,比如知乎,
可以分析玩知乎人的行业分布
可以分析行业中困扰大家的一些共性问题
可以分析谁的关注度高,谁最近活跃
等等
不说有多大价值吧,只能说很好玩儿。爬过淘宝的文胸商品评价,搞了个简单展示的页面。只是大概分析了文胸都是A还是B还是C,还大概分析了一下什么颜色的文胸卖的最好。
展示链接:http://vps.kalen25115.cn/bra/
爬去下来的mysql数据,一共有两百多万评价,可以尝试分析分析。
链接: http://pan.baidu.com/s/1dDKmUyP 密码: 26av
代码前段时间试了一下,会被反爬虫,最近又拿代理ip搞了搞,还没有完善好,正在测试中,有兴趣可以看看。单机版的应该可以用了(集群的还没试),不过代理ip速度比较慢。
https://github.com/nladuo/taobao_bra_crawler
神箭大数据
不会搞产品的程序猿,不是真正的女汉子
写过爬虫爬取知乎、好搜、百度知道等上的问答,很有成就感 ( ̄▽ ̄)" 爬取下来之后可以发布到自己的网站上,女程序员不容易啊( ̄▽ ̄)"( ̄▽ ̄)"
好吧,我承认最近没什么意思,然后就做了 知乎的接口,根据知乎的个人来爬取他的内容
目前就三个,一个是爬取回答的问题,一个是爬取关注着,还有关注的人。当然只是一个底层api
但是你可以看到。
在没做异常处理,因为还没考虑好要做什么,只是做好了工具。
可以看到主逻辑只有20+行
使用起来,也只是把 用户的url_token 拿来,而且
爬来的用户是自带url_token的。
当然我不知道有多少会去看这个,py 做起来就是这么轻松吧。
我把地址 给大家,虽然不一定会有多少看。
bufubaoni/SimpleSpider
很简单的不算项目的项目,连html都没有解析。
第十四部分:用八爪鱼去采集
比起那些高大上看不太明白的各种散点图,会上网就会采集的入门案例也许更适合新手。以下玩法案例都是我尝试采集过觉得可行的。
玩法
玩法一:收集最新热门新闻事件
新闻是讲究时效性的,当你上一秒还在搜索查看的时候,下一秒这个热点香饽饽很可能就已经被抢了。八爪鱼能帮助媒体人实时监测各媒体网站的最新事件,将网站上每一篇报道的内容、阅读量、转发量、评论数等通通采集下来,形成一份数据报表。以网易新闻24小时娱乐为例:
玩法二:三分钟爬取QQ号码
QQ群,一个拥有精准用户的群体通讯平台,做推广销售的同学都知道其重要性,一般想要获得相关的资源协助,我们第一个想到的就是去加QQ群。假设你是一名销售人员,加了十几个相关的资源QQ群,但每个群都有上百人,你该如何把群里面一个个人的QQ号码导出来?人工摘录?太慢,写代码?太难。八爪鱼可以轻松帮你做到,数多多官网有现成的规则,下载,点击执行,你能扒下群里所有的QQ号码。
玩法三:寻觅团购优惠和美食
日常生活中,八爪鱼的使用也非常广泛。下班前夕与朋友约定聚餐,想在大众点评上寻觅周边的美食和优惠?想找麦当劳的优惠?可以!打开八爪鱼,输入大众点评网址,运行规则,相关美食团购信息、评论、团购套餐、商店地址、电话就整理好了。
玩法四:协助豆瓣打造个性化交友圈
豆瓣表面上看是一个评论(书评、影评、乐评)网站,但实际上它却提供了书目推荐和以共同兴趣交友等多种服务功能,可以说豆瓣圈子的成立是基于大数据的。八爪鱼可以快速搜集豆瓣上的相关评论信息,不仅如此,还能为豆瓣平台采下每一个用户的搜索、浏览、转发、交友记录,为用户制定个性化的内容、小组的推荐。举个栗子,八爪鱼曾为某款机器人采下了豆瓣上的所有信息,充当其语料库。
玩法五:在百度地图上快速定位
比如你想拍摄一组浪漫的婚纱照,却不知道怎么在一个偌大的城市里筛选摄影机构?这时候打开八爪鱼,输入百度地图网址,简单设置几步规则,就能迅速定位到该城市所有与影楼相关的店铺,将店铺电话、地址、距离时长等信息全部采集下来,助你在茫茫人海中快速定位目标。以大连城市的影楼店铺采集为例:
玩法六:收集电商平台产品信息
一名成功的剁手族,必备素质就是在琳琅满目的商品中快速定位最佳目标。八爪鱼帮助剁手族在最短时间内收集下店铺信息、商品信息、评价信息等等。如果你是店家,想要监控竞争对手店铺详细评分指标,所有宝贝信息、成交细节、评价等等,也可用八爪鱼生成一份详细的店铺分析报告。
玩法七:采集赶集网房源信息
楼市价格扶摇直上,不管是买房还是租房充分了解行情非常重要。打个比方,如果你想了解赶集网二手房的基本信息,先在上面设置你的房源要求,打开八爪鱼,执行规则,详细的房源信息包括售价、面积、小区等通通都能几分钟内采下来。
玩法八:实时分析股票行情
如果你想实时监测互联网财经媒体,得到最新财经资讯及全球金融市场报价,分析股票的走向与趋势。使用八爪鱼,上万条最新的股票名称、价格、跌涨幅、成交量、成交额、价格比等信息都能自动生成一份分析报表,使用云采集,还能帮你实时自动化更新。
玩法九:采集招聘网站职位信息
通过八爪鱼采集各大招聘网站最新招聘信息,每天实时监测查看心仪企业和职位的招聘动向,毕竟机会都是留给有所准备的人,你懂得,小八愿助你把握先机。
玩法十:高效收罗法律判决文书
前段时间,我们一位法律技术用户就做过分享,有兴趣的同学可以去回顾一下,看看我们的法律大神是如何运用八爪鱼去采集文书的。
简单来说,运用八爪鱼可以收集国内的大部分诉讼信息,将刑事判决书、民事判决书各种你们需要的文书通通呈现在excel表格,节省下宝贵时间,帮助你分析判决结果,深度学习法律案例。
网站成千上万的,采集不同的网站玩法甚多,在这里就不逐一列举了,各位看官要怎么玩转数据接下来还要靠自己发挥。总之就是一句话,关键你要想得到采集数据做什么用,如果使用专业的工具,采集本身从来都不难,难点在于数据应用场景。
实战
爬了拉勾的数据做了个分析,分析过程若有不周之处,还望指正
一、数据来源
拉勾网20170519根据“数据产品经理”关键字可以搜索到的职位。由于拉勾只展示符合搜索条件的前450个职位,为了获得更多的数据,设定不同的筛选条件分别爬取汇总,然后清洗了下,最后只剩下456个职位,296家公司。
二、分析部分
分析要点:
什么样的公司爱招数据产品经理(数据PM需求现状)
什么样的求职者更符合企业期望 (企业对数据PM要求)
什么样的企业最壕(数据PM待遇)
1、什么样的公司爱招数据产品经理(数据PM需求现状)
1.1行业
从行业上来看,移动互联网包揽了半壁江山,其次是数据服务,电子商务,金融和O2O。
但是,除了数据服务外,其余几个皆是近几年很火行业,这些行业公司数量本身偏多,不排除有这方面因素的影响。
此外,行业并没有明显表现出对不同经验人才需求的差异性,最喜欢3至五年,其实是1-3年和5-10年,1年以下和10年以上的凤毛菱角。(多个行业标签的公司重复计算)
1.2发展阶段
未融资和天使轮需求量远远小于其他类型,上市公司需求量远远高于其他类型。公司上市了,有一定的规模和资金实力,数据方面开始投入和重视起来。而成立不久的小公司,很多公司这个阶段产品方向还没确定下来,业务和产品先走通更为重要,而且数据系统的建设还是很花钱的。
听起来好像很有道理,不过以上分析没有考虑到不同阶段的公司数量,请大家酌情参考,像未融资的公司不一定是不爱招数据PM,而是很可能这种类型的公司本来就不多,从而造成整体职位偏少。
但是奇怪的是, A、B、C、D轮并没有很多差异。考虑到各阶段公司数量不同的影响,还是不往下分析了,因为很可能是错的。
从人才层次看,上市公司、不需要融资、未融资和天使轮公司对5至10年经验人才的需求占比明显高于其他。未融资和天使轮的样本量很小,暂且不看。上市公司和不需要融资的公司的确是很喜欢大咖级人才。
1.3城市
剔除职位数量在5以下的城市,只剩下图上几个城市。
不管是公司还是职位,北京遥遥领先。职位数量是232,占了职位总数的一半,职位数量这么多,除了北京互联网企业多的原因外,我们我看看到北京的平均招聘人数也是远远领先其他城市的,看来相对于其他城市,北京的公司更爱招数据PM。
上海几乎和深圳持平,杭州领超广州,远远甩开其他二线,紧追上海深圳,本来想探寻上海职位偏少的原因,按照我的理解,上海虽然少于北京,但是还是该超深圳些,我去看了下上海公司的行业和发展阶段分布,奈于爬取数据量偏小,没找到原因。我大胆猜测下,很可能是因为上海的初创型公司偏多,而这类公司对数据pm需求偏小些。
下图是每个城市对不同经验数据PM的需求占比,差异性不大。不管是哪个城市,工作年限要求并没有太大的不同。都是3至5年经验的人才需求量最大,其次是1至3年和5至10年。
不过,经验不限的这块,杭州明显高于其他城市,特别是深圳和广州,从这个角度,不知道可以解读为杭州对于人才的包容性更高些?
2、什么样的求职者更符合企业期望 (企业对数据PM要求)
2.1学历
本科占比90%左右,专科不到6%。这张图告诉我们:本科学历算是个门槛,相对于其他类型的PM,数据PM对逻辑能力要求更高些,专科学历在数据PM这块很艰难。不过还好,硕士要求占比不高,作为一个本科生,我舒了一口气。
此外,不同行业不同发展阶段的公司对学历的要求并没有表现出差异性,图表就不放出来了。
2.2工作经验
正如上文提到:3至5年经验的人才需求量最大,其次是1至3年和5至10年。然后不管工作经验多少,学历上要求还是一样的:本科大多数,专科很艰难。
2.3技能要求
对职位的详情说明做了词云,本来还是分了3年以下和3年以上,不过出来的东西并没有太大差别,3年以上的“管理”,“总监”出现的更高频些,这里也不放出来了。词云反应了各家公司对于数据PM的职责和能力要求:
总结招聘数据PM的主要要求:数据分析、逻辑思维、数学、统计学、BI、报表、画像、指标、数据模型、算法、数据仓库、SQL、spark、python、spass、excel、机器学习、数据挖掘、推荐、商业化。
3、 什么样的企业最壕(数据PM待遇)
3.1整体概况
薪资取最高值和最低值的平均数,1年以下及10年以上由于样本太少,暂不分析。随着工作经验的增加,薪资也是上升趋势,其中1至3年经验,多数公司愿意给10k至20k。25k以上的职位虽然少但是还是存在的,如果实力真的强,公司还是愿意花钱的。一旦超过3年,绝大多数都是15k+,一半在20k以上。而5年以后,25k+占到一半。
3.2学历
后面的分析对工作经验做了区分,分为经验小于3年和经验大于3年,经验不限职位不计入分析。硕士职位过少,暂且不看。对于工作经验不足3年的职位,如下图所示,本科以上学历出现20至25k的待遇,甚至25k+,而大专学历20k以上为0,即使存在专科样本偏少的原因,但也足以说明本科学历有一定优势。
再来看看经验超过3年的职位,如下图所示,这时候,学历好像就没有那么重要,高薪占比差不了多少。
3.3城市
3年以下经验,不管是一线还是二线,北京待遇远超其他城市,杭州在二线城市中也很不错,如下图所示。
3年以上经验,北京上海持平,广州成都差些,而杭州比深圳还要好一些。想想北上深的房价,杭州的表现非常不错。
3.4发展阶段
天使轮数量太少暂不分析。
不管是经验多少,D轮以上和上市公司待遇领先。而D轮以上待遇甚至好于上市公司,猜测一下:D轮以上的公司多数已经发展的比较生熟,离上市还差最后一步,这时候,公司是不是对于人才更舍得花钱?
3.5行业
如图,整体来看,O2O待遇稍好一些。3年经验以上,行业待遇差别不大,3年经验以下,电商待遇偏低,但不排除样本偏少造成的误差。
三、总结
1、上市公司、北京、移动互联网行业最爱招数据PM。
2、百分之九十都要求本科学历,数据分析必须精通。
3、北京待遇最好,杭州性价比高,D轮以上公司最舍得。
本来还想分析下各家hr的活跃时间,处理用时,处理率等问题,样本太少,想想还是算了。
- 电影和电视剧,爬优酷、腾讯视频、爱奇艺、搜狐视频、土豆等
- 技术博客,爬CSDN、cnblog、oschina等
- 科技新闻,爬36kr、geekpark、huxiu等
- 购物,爬淘宝、京东、聚美优品等
- 图书,爬京东、亚马逊、当当、孔夫子旧书网等
做过一些爬虫软件,个人认识爬虫最好使用基于浏览器的技术,即使用JavaScript,这样可以绕开绝大多数的反爬程序,也比较适合爬一些需要登录才能看的网站。
我最近做的 爱牛币-投资人的工具箱 就是使用了这样的技术,抓取各种股市资讯,帮助投资者做决策。
用 JavaScript 操作DOM再简单不过了。你可以参考以下技术。
GitHub - atom/electron: Build cross platform desktop apps with web technologies
GitHub - nwjs/nw.js: Call all Node.js modules directly from DOM and enable a new way of writing applications with all Web technologies.
PhantomJS | PhantomJS
基本原理是:
1) 使用脚本打开目录网页
2) 注入相应的JavaScript脚本,用CSS选择器获取内容
3) 在原网页新建一个 image 等 html 等元素,将目标抓取内容人发送到 http://anynb.com
4) 数据传送时会使用一些加密Token
PS: 在注入脚本抓取内容时,最好使用原生的 JavaScript 如 document.querySelectorAll 等命令,有些网站是没有 jQuery支持的。
很多高校的一卡通查询中心是可以利用公开信息推断出密码的甚至没有验证。。
爱用编程/软件/2B铅笔画画
作为一个b站鬼畜爱好者,在学校的时候做了一个简单的爬虫,调用b站提供的接口,获取了b站历史投稿视频的播放量以及视频分类。
目的是为了想获得两个东西,一是找出那些年我错过的(鬼畜)神作?二是b站哪一类投稿视频播放最多?
从av7号视频开始,小破笔记本单线程在寝室里没日没夜地一直爬啊爬,后来。终于爬不动了。做了个excel,忘了后来一共获取了多少万个视频的数据。当时1万的时候发了一条空间动态。
那个时候b站过百万的播放量的视频没有像现在的那么多。不过还是能看到番剧动画占了绝对的播放主力(现在也是)。播放量第一名是钢之炼金术师(当时)
通过这个爬虫发现了一些万恶之源,上古大坟,比如像真兄♂贵无双,蓝蓝路这些。
用爬虫爬了20000+的创业公司信息,做了简单的数据统计。结果如下
之前看过一篇文章,一个美国人用网上的社交数据确定ISIS恐怖分子位置,感觉这个比较有意义。
=================================================
爬阿里妈妈的鹊桥啊,买东西之前先在数据库里面查询下。很多商品佣金在50%以上呢。
爬了A站的数据
Acer分布http://www.ezlands.com/acm/from/
Acer活跃度http://www.ezlands.com/acm/
被引用邮件提醒http://www.ezlands.com/acm/atweb/
虽然没什么价值==
但是也练了练技术.
Acer几万个基佬的信息都被我收录了哈哈哈..
最近实验需要所以从知乎上爬了10000+用户的数据下来。爬取关系是通过关注的人爬取的。
正常的分析大家已经做了很多了,那么我就来做一些不正常的分析吧。但是由于数据集的规模不是很大,所以结果肯定有有失偏颇的地方。
性别比例
首先是一个用户性别的问题,因为是通过关注的人来爬取的,爬取结果是男性4692人,女性5814人,这倒不是说女性用户比男性多,只是可能反应了大家更倾向于关注妹子= =
性别影响
我一直觉得大家都更倾向于给妹子点赞,那么到底是不是这样呢,然而我也不知道应该如何衡量这个问题。
如果只是看赞同数的话,男性用户获得的赞同和感谢还是明显比女性用户多的。但是如果是看每个回答的平均赞同数的话,差距就并没有赞同总数那么明显了。
另外计算了一个叫做 赞同/粉丝比的东西,就是用每个回答的平均赞同数/粉丝数,其实我想衡量的值是在用户获得的赞同数中,来自非粉丝的赞同的比例,但是想计算这个值难度太大了,于是就算了这个不知道是什么的东西。这个值女性高于男性,想来是不是很多人看到回答是妹子写的时候更容易随手点赞= =。
用户擅长领域
由于用户擅长的领域有多个,在处理的时候一时想不到怎么处理好,暂时就把擅长的领域分成了两部分,就是用户选择的自己第一个擅长话题和第二个擅长话题。这个东西其实很多用户都没有设置,那么在设置了的用户中,按记录数排序如下
也就是说认为自己擅长回答生活类问题的用户是最多的。