文章目录
- 引言
- ChatGPT生成测试数据:
- 今天给大家带来一个Spark综合练习案例--电影评分
- 补充: 采用DSL编程的详尽注释版
- 总结
引言
大家好,我是ChinaManor,直译过来就是中国码农的意思,俺希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,一个平凡而不平庸的人。
ChatGPT生成测试数据:
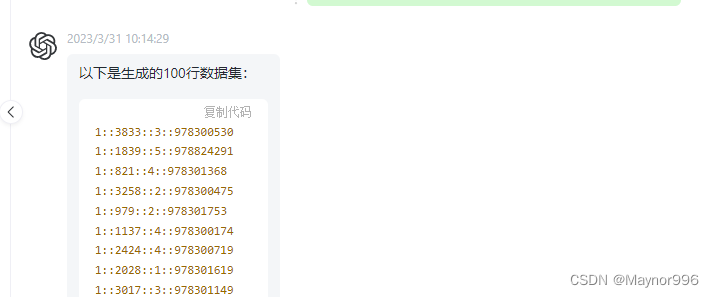
请根据如下格式生成100行数据集:
1::1287::5::978302039
1::2804::5::978300719
1::594::4::978302268
chatpgt注册:https://github.com/xianyu110/awesome-chatgpt-project
今天给大家带来一个Spark综合练习案例–电影评分
老师:给定需求统计评分次数>200的电影平均分Top10,并写入Mysql数据库中
我:所有字我都认识,怎么连在一起我就不认识了

不管了先new个实例对象,总没错吧
val sparkSession = SparkSession.builder().config("spark.sql.shuffle.partitions", "4").appName("电影数据分析").master("local[2]").getOrCreate()
然后大数据无非输入,转换,输出,我再弄个spark读取文件?

val lines: RDD[String] = sparkSession.read.textFile("E:\\xx\\SparkDemo\\input\\ratings.dat").rdd再然后RDD转换成DF
val rdd: RDD[(Int, Int, Int, Long)] = lines.mapPartitions { item => {item.map { line => {val strings: Array[String] = line.trim.split("::")(strings(0).toInt, strings(1).toInt, strings(2).toInt, strings(3).toLong)}}}}import sparkSession.implicits._val reusltDF: DataFrame = rdd.toDF("user_id", "item_id", "rating", "timestamp")
测试一下行不行

// 查看约束reusltDF.printSchema()//查看数据reusltDF.show()
好像跑通了!!笑容逐渐放肆~什么SQL不整了,上来直接DSL

val resultDS: Dataset[Row] = reusltDF//a.对数据按电影id进行分组.groupBy($"item_id")//b.对聚合数据求平均值和评分次数.agg(round(avg($"rating"), 2).as("avg_rating"),count($"user_id").as("cnt_rating"))//c.过滤出评分大于2000的.filter($"cnt_rating" > 2000)//d.按照评分的平均值进行降序排序.orderBy($"avg_rating".desc)//e.取前十条数据.limit(10)
最后最后保存到Mysql
SaveToMysql(resultDF);
/*** 保存数据至MySQL数据库,使用函数foreachPartition对每个分区数据操作,主键存在时更新,不存在时插入*/def saveToMySQL(dataFrame: DataFrame): Unit = {dataFrame.rdd.coalesce(1).foreachPartition{ iter =>// a. 加载驱动类Class.forName("com.mysql.cj.jdbc.Driver")// 声明变量var conn: Connection = nullvar pstmt: PreparedStatement = nulltry{// b. 获取连接conn = DriverManager.getConnection("jdbc:mysql://192.168.88.100:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true","root", //"123456")// c. 获取PreparedStatement对象val insertSql ="""|INSERT|O| db_test.demo| (item_id, avg_rating, cnt_rating)|VALUES (?, ?, ?)|""".stripMarginpstmt = conn.prepareStatement(insertSql)conn.setAutoCommit(false)// d. 将分区中数据插入到表中,批量插入iter.foreach{ row =>pstmt.setInt(1, row.getAs[Int]("item_id"))pstmt.setInt(2, row.getAs[Int]("avg_rating"))pstmt.setInt(3, row.getAs[Int]("cnt_rating"))// 加入批次pstmt.addBatch()}// TODO: 批量插入pstmt.executeBatch()conn.commit()}catch {case e: Exception => e.printStackTrace()}finally {if(null != pstmt) pstmt.close()if(null != conn) conn.close()} }

大功告成了!

补充: 采用DSL编程的详尽注释版
package cn.itcast.spark.metricsimport java.sql.{Connection, DriverManager, PreparedStatement}import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.spark.sql.functions._
import org.apache.spark.storage.StorageLevel/*** 电影评分数据分析,需求如下:* 需求1:查找电影评分个数超过50,且平均评分较高的前十部电影名称及其对应的平均评分* 电影ID 评分个数 电影名称 平均评分 更新时间* movie_id、rating_num、title、rating_avg、update_time* 需求2:查找每个电影类别及其对应的平均评分* 电影类别 电影类别平均评分 更新时间* genre、 rating_avg 、update_time* 需求3:查找被评分次数较多的前十部电影* 电影ID 电影名称 电影被评分的次数 更新时间* movie_id、title、rating_num、 update_time
*/
object MetricsAppMain {// 文件路径private val RATINGS_CSV_FILE_PATH = "D:\\Users\\Administrator\\Desktop\\exam0601\\datas\\ratings.csv"private val MOVIES_CSV_FILE_PATH = "D:\\Users\\Administrator\\Desktop\\exam0601\\datas\\movies.csv"def main(args: Array[String]): Unit = {// step1、创建SparkSession实例对象val spark: SparkSession = createSparkSession(this.getClass)import spark.implicits._/*分析需求可知,三个需求最终结果,需要使用事实表数据和维度表数据关联,所以先数据拉宽,再指标计算TODO: 按照数据仓库分层理论管理数据和开发指标- 第一层(最底层):ODS层直接加CSV文件数据为DataFrame- 第二层(中间层):DW层将加载业务数据(电影评分数据)和维度数据(电影基本信息数据)进行Join关联,拉宽操作- 第三层(最上层):DA层/APP层依据需求开发程序,计算指标,进行存储到MySQL表*/// step2、【ODS层】:加载数据,CSV格式数据,文件首行为列名称val ratingDF: DataFrame = readCsvFile(spark, RATINGS_CSV_FILE_PATH, verbose = false)val movieDF: DataFrame = readCsvFile(spark, MOVIES_CSV_FILE_PATH, verbose = false)// step3、【DW层】:将电影评分数据与电影信息数据进行关联,数据拉宽操作val detailDF: DataFrame = joinDetail(ratingDF, movieDF)//printConsole(detailDF)// step4、【DA层】:按照业务需求,进行指标统计分析computeMetric(detailDF)Thread.sleep(1000000)// 应用结束,关闭资源spark.stop()}/*** 构建SparkSession实例对象,默认情况下本地模式运行*/def createSparkSession(clazz: Class[_], master: String = "local[2]"): SparkSession = {SparkSession.builder().appName(clazz.getSimpleName.stripSuffix("$")).master(master).config("spark.sql.shuffle.partitions", "2").getOrCreate()}/*** 读取CSV格式文本文件数据,封装到DataFrame数据集*/def readCsvFile(spark: SparkSession, path: String, verbose: Boolean = true): DataFrame = {val dataframe: DataFrame = spark.read// 设置分隔符为逗号.option("sep", ",")// 文件首行为列名称.option("header", "true")// 依据数值自动推断数据类型.option("inferSchema", "true").csv(path)if(verbose){printConsole(dataframe)}// 返回数据集dataframe}/*** 将事实表数据与维度表数据进行Join关联*/def joinDetail(df1: DataFrame, df2: DataFrame, joinType: String = "left_outer"): DataFrame = {df1// 采用leftJoin关联数据.join(df2, df1("movieId") === df2("movieId"), joinType)// 选取字段.select(df1("userId").as("user_id"), //df1("movieId").as("movie_id"), //df1("rating"), //df1("timestamp"), //df2("title"), //df2("genres") //)}/*** 按照业务需求,进行指标统计,默认情况下,结果数据打印控制台*/def computeMetric(dataframe: DataFrame): Unit = {// TODO: 缓存数据dataframe.persist(StorageLevel.MEMORY_AND_DISK)// 需求1:查找电影评分个数超过50,且平均评分较高的前十部电影名称及其对应的平均评分val top10FilesDF: DataFrame = top10Films(dataframe)//printConsole(top10FilesDF)upsertToMySQL(top10FilesDF, //"replace into db_metrics.top_10_files (id, movie_id, rating_num, title, rating_avg) values (null, ?, ?, ?, ?)", //(pstmt: PreparedStatement, row: Row) => {pstmt.setInt(1, row.getAs[Int]("movie_id"))pstmt.setLong(2, row.getAs[Long]("rating_num"))pstmt.setString(3, row.getAs[String]("title"))pstmt.setDouble(4, row.getAs[Double]("rating_avg"))})// 需求2:查找每个电影类别及其对应的平均评分val genresRatingDF: DataFrame = genresRating(dataframe)//printConsole(genresRatingDF)
// upsertToMySQL(
// genresRatingDF, //
// "replace into db_metrics.genres_rating (id, genre, rating_avg) values (null, ?, ?)", //
// (pstmt: PreparedStatement, row: Row) => {
// pstmt.setString(1, row.getAs[String]("genre"))
// pstmt.setDouble(2, row.getAs[Double]("rating_avg"))
// }
// )// 需求3:查找被评分次数较多的前十部电影val best10FilesDF: DataFrame = best10Files(dataframe)//printConsole(best10FilesDF)
// upsertToMySQL(
// best10FilesDF, //
// "replace into db_metrics.best_10_films (id, movie_id, title, rating_num) values (null, ?, ?, ?)", //
// (pstmt: PreparedStatement, row: Row) => {
// pstmt.setInt(1, row.getAs[Int]("movie_id"))
// pstmt.setString(2, row.getAs[String]("title"))
// pstmt.setLong(3, row.getAs[Long]("rating_num"))
// }
// )// 释放资源dataframe.unpersist()}/*** 需求:查找电影评分个数超过50,且平均评分较高的前十部电影名称及其对应的平均评分* 电影ID 评分个数 电影名称 平均评分 更新时间* movie_id、rating_num、title、rating_avg、update_time*/def top10Films(dataframe: DataFrame): DataFrame = {import dataframe.sparkSession.implicits._dataframe.groupBy($"movie_id", $"title").agg(count($"movie_id").as("rating_num"), // 统计电影被评分的个数round(avg($"rating"), 2).as("rating_avg") // 统计电影被评分的平均分)// 过滤评分个数大于50.where($"rating_num" > 50)// 降序排序,按照平均分.orderBy($"rating_avg".desc)// 获取前10电影.limit(10)// 添加日期字段.withColumn("update_time", current_timestamp())}/*** 需求:查找每个电影类别及其对应的平均评分* 电影类别 电影类别平均评分 更新时间* genre、 rating_avg 、update_time*/def genresRating(dataframe: DataFrame): DataFrame = {import dataframe.sparkSession.implicits._dataframe// 将每个电影类别字段:genres,按照|划分,使用爆炸函数进行行转列.select(explode(split($"genres", "\\|")).as("genre"), //$"rating" //)// 按照类别分组,计算平均评分.groupBy($"genre").agg(round(avg($"rating"), 2).as("rating_avg"))// 对统计值降序排序.orderBy($"rating_avg".desc)// 添加日期字段.withColumn("update_time", current_timestamp())}/*** 需求:查找被评分次数较多的前十部电影* 电影ID 电影名称 电影被评分的次数 更新时间* movie_id、title、rating_num、 update_time*/def best10Files(dataframe: DataFrame): DataFrame = {import dataframe.sparkSession.implicits._dataframe.groupBy($"movie_id", $"title").agg(count($"movie_id").as("rating_num") // 统计电影被评分的个数)// 降序排序,按照平均分.orderBy($"rating_num".desc)// 获取前10电影.limit(10)// 添加日期字段.withColumn("update_time", current_timestamp())}/*** 将DataFrame数据集打印控制台,显示Schema信息和前10条数据*/def printConsole(dataframe: DataFrame): Unit = {// 显示Schema信息dataframe.printSchema()// 显示前10条数据dataframe.show(10, truncate = false)}/*** 将数据保存至MySQL表中,采用replace方式,当主键存在时,更新数据;不存在时,插入数据* @param dataframe 数据集* @param sql 插入数据SQL语句* @param accept 函数,如何设置Row中每列数据到SQL语句中占位符值*/def upsertToMySQL(dataframe: DataFrame, sql: String,accept: (PreparedStatement, Row) => Unit): Unit = {// 降低分区数目,对每个分区进行操作dataframe.coalesce(1).foreachPartition{iter =>// step1. 加载驱动类Class.forName("com.mysql.cj.jdbc.Driver")// 声明变量var conn: Connection = nullvar pstmt: PreparedStatement = nulltry{// step2. 创建连接conn = DriverManager.getConnection("jdbc:mysql://192.168.88.100:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true","root","123456")pstmt = conn.prepareStatement(sql)// step3. 插入数据iter.foreach{row =>// 设置SQL语句中占位符的值accept(pstmt, row)// 加入批次中pstmt.addBatch()}// 批量执行批次pstmt.executeBatch()}catch {case e: Exception => e.printStackTrace()}finally {// step4. 关闭连接if(null != pstmt) pstmt.close()if(null != conn) conn.close()}}}}总结
以上便是电影评分数据分析spark版,愿你读过之后有自己的收获,如果有收获不妨一键三连一下~