最近在学习研发QA系统,本人单纯想记录一下。项目源码和思路主要参考知乎专栏:
PyTorch搭建聊天机器人(一)词表与数据加载器 - 知乎
PyTorch搭建聊天机器人(二)定义seq2seq网络前向逻辑 - 知乎
PyTorch搭建聊天机器人(三)训练与评估 - 知乎
知乎大佬的思路还是很清晰的。词表和数据加载器使用的数据集本人改用json格式的sogou和web的数据集,这个数据还需要自己处理一下,有些问题没有答案,但是有问答的相关信息(这个文本太长了),为了方便训练,而筛除没有答案的问题,然后做好标签。
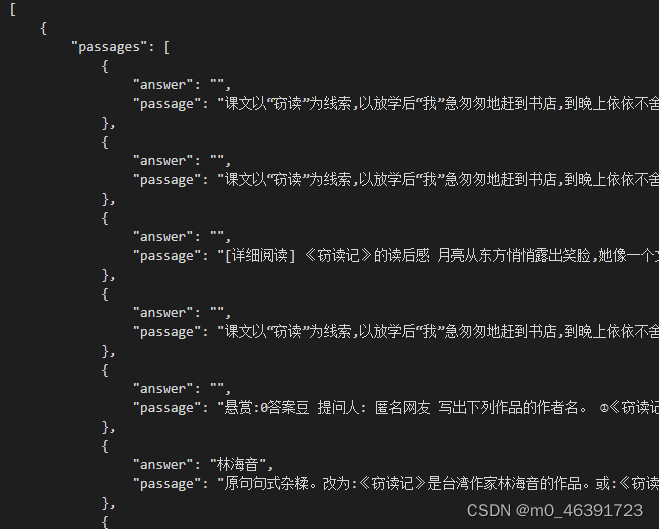
json数据获取
#读取json文件内容
sogou_data = json.load(open("qa_datasets/SogouQA.json", 'r', encoding='utf-8'))
web_data = json.load(open("qa_datasets/WebQA.json", 'r', encoding='utf-8'))
question_list = []
answer_list = []
#获取json字段的相应内容
for i in range(len(sogou_data)):if sogou_data[i]['passages'][0]['answer'] != "":question_str = ""answer_str = ""for j in range(len(sogou_data[i]['question'])):question_str += sogou_data[i]['question'][j] + " "question_list.append(question_str)for j in range(len(sogou_data[i]['passages'][0]['answer'])):answer_str += sogou_data[i]['passages'][0]['answer'][j] + " "answer_list.append(answer_str)
for i in range(len(web_data)):if web_data[i]['passages'][0]['answer'] != "":question_str = ""answer_str = ""for j in range(len(web_data[i]['question'])):question_str += web_data[i]['question'][j] + " "question_list.append(question_str)for j in range(len(web_data[i]['passages'][0]['answer'])):answer_str += web_data[i]['passages'][0]['answer'][j] + " "answer_list.append(answer_str)
for i in range(len(question_list)):self.addSentence(question_list[i].strip())self.addSentence(answer_list[i].strip())pairs.append([question_list[i], answer_list[i]])词表和数据加载器和参考知乎大佬的源代码!