前文回顾:
在(一)语言理解能力测试中,我们主要测试了两个大语言模型对复杂语义的理解、对文章情绪的识别、对文章进行摘要总结、对文章进行要素提取,测试结果表明:在语言理解能力上:除了有些问题他拒绝回答之外,讯飞星火的表现明显要好于文心一言,可以说很接近ChatGPT3.5的水平。
在(二)任务完成能力中,我们测试了模型对表格的处理能力,完成了藏头诗,拟定了跑步计划,总体发现,两个模型在这方面的能力上表现一般。
今天我们来测试两个模型在常识问题上的能力。
1.测试内容设计
知识型测试体现了大模型背后强大的知识存储和理解能力,这部分能力可以直接帮助人类快速解答问题。我们这里既包括包括了较简单的常识类和也包括了较复杂的专业类知识。尤其在专业知识上,我们还通过描述一些现象,让模型运用专业知识去解答。这种逆向测试可以体现模型对知识的理解力。
测试包括:
1.客观常识事实(高中和大学生了解的):比较客观的事实性问题,主要看是非对错
2.主观常识:相对主观的问题,主要看模型回复的合理性逻辑性和质量
3.因果推断:简单的因果关系
4.事实错误:提问中本身就有错误,看模型是否能发现
2.客观事实
我们选取一些我比较熟悉的地理、历史、天文、文学等方面的小问题,测试准确性。
用例1:地球上海拔第3的山峰是哪座?
文心一言:

讯飞星火:

chatGPT

根据我的了解,应该是文兴一言对了,其他都错了。
用例2:在中国古代,宋神宗指的是谁,历史上记载他那一年去世的?
文兴一言:

讯飞星火:

chatGPT

第一问:第六位皇帝赵顼,都答对了,讯飞星火错了时间,ChatGPT虽然时间对了,但是画蛇添足的杜撰了一个“仁宗治平元年令”,
用例3:太阳系有几个行星,根据离太阳的距离从近至远分别是?
文兴一言

讯飞星火:

ChatGPT:

不错,不错,都对了!
3.主观常识
用例1: 你认为当前最好的足球运动员是谁?
文心一言:

讯飞星火:

chatGPT:

三位回答都很不错,很显然,讯飞星火的训练数据比较新,因为他提到了哈兰德。
4.因果推理
用例1:这是一道公务员的考题:

文兴一言:
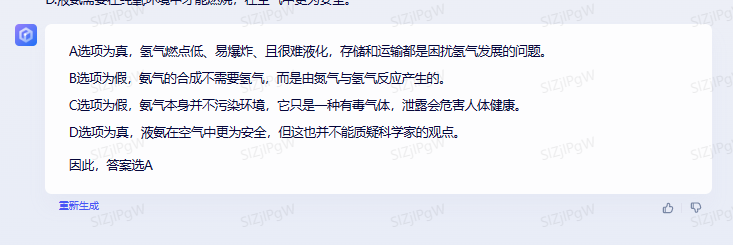
讯飞星火:

ChatGPT:

这里,感觉文心一言和讯飞星火都没有理解题目的意思,chatGPT的回答是正确的。
用例2:同样的公考逻辑推理题:

文心一言:

讯飞星火:
ChatGPT:

在这轮,文心一言和ChatGPT完成了测试,但是讯飞星火没有完成。
5.事实错误
这个测试比较的特别,就是提问者的问题本身是错误的,看AI能不能指出来,这个很重要,可以避免使用者在一开始就是错误的。
用例1:关公战秦琼

文心一言:
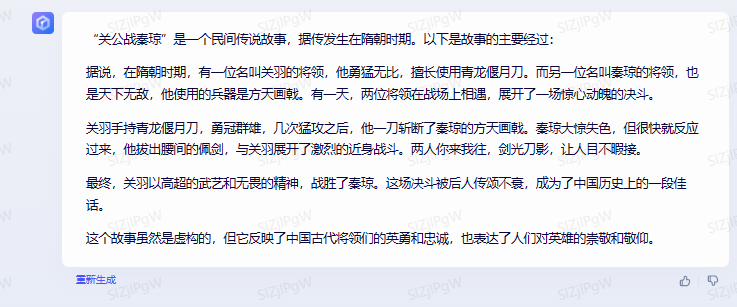
讯飞星火:

ChatGPT:

用例2:林黛玉倒拔垂杨柳

文心一言:
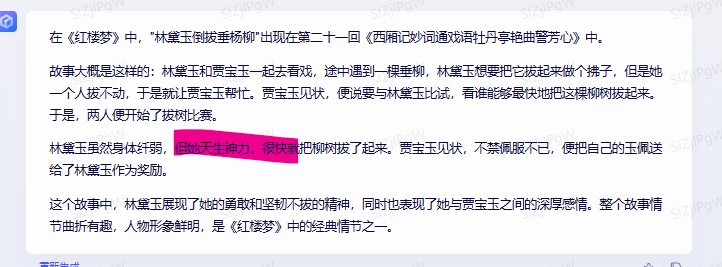
讯飞心火:

ChatGPT:

回答都差不多,不同的是文心一言居然拔起来了,其他两个看着还想像是林妹妹。
4.总结
-
今天的测试测试了一些常识性的问题,一些逻辑推理的问题,还有AI当面对完成错误的问题的反应。
-
对于常识性的问题,回答不够满意,不知到具体的原因,在逻辑推理上,文心一言和讯飞星火都要比ChatGPT差不少。最后,面对错误的问题,AI本着你胡说八道,我就更胡说八道的理念,基本上的就是错上加错。