目录
1.Jedis的使用
前置工作-ssh进行端口转发
JedisAPI的使用
Jedis连接池
2.SpringDataRedis的使用
1.创建项目
2.配置文件
3.注入RedisTemplate对象
4.编写代码
3.SpringRedisTemplate
哈希结构用法
总结
1.Jedis的使用
Jedis:以Redis命令作为方法名称,学习成本低,简单实用。但是Jedis实例 是线程不安全的,多线程环境下需要基于连接池来使用
lettuce:基于Netty实现,支持同步异步,响应式编程方式,并且是线程安全的,支持redis哨兵模式,集群模式和管道模式
前置工作-ssh进行端口转发
从本机远程访问redis服务器是需要通过云服务器的外网ip来访问linux服务器的
只修改成外网ip还不够,6379端口是被云服务器的防火墙给保护起来的,如果将该端口的防火墙
关闭,就很可能会遭到黑客攻击。每次开放一个端口,被攻击的几率就更大。
保护了之后,不开启防火墙,我们也无法访问,关闭防火墙,会遭受攻击;换成其他端口也不行,只要redis的端口被公开到公网上,就特别容易被入侵!
可以通过ssh进行端口转发
端口转发(Port Forwarding),也称为端口映射,是通过 SSH 协议在本地和远程主机之间建立一个安全的通道,将流量从一个端口转发到另一个端口的过程。
通常情况下,网络中的设备通过端口号来识别和区分不同的服务或应用程序。端口转发可以实现以下两种方式:
-
本地端口转发(Local Port Forwarding):在本地主机上建立一个监听端口,并将该端口上接收到的请求转发到远程主机的目标端口。这使得本地主机能够访问远程主机上的服务,就像这些服务在本地运行一样。
-
远程端口转发(Remote Port Forwarding):在远程主机上建立一个监听端口,并将该端口上接收到的请求转发到本地主机的目标端口。这使得远程主机能够访问本地主机上的服务,就像这些服务在远程主机运行一样。
解决方案:通过ssh端口转发,把云服务器上的redis端口,映射表到本地主机
描述:
通过windows访问云服务器的6379,访问不了,通过ssh数据报,将访问redis的请求放到ssh数据包中。通过ssh数据报来访问,服务器的ssh程序解析出上述请求,然后将数据报交给6379端口程序;
ssh也需要给多个端口传递数据,因此为了区分不同的端口,会把服务器的端口在本地用一个端口来进行表示
通过端口转发,可以绕过网络防火墙的限制,访问被阻止或限制的服务。
ssh协议是通过22端口进行的,这个端口不容易被攻破
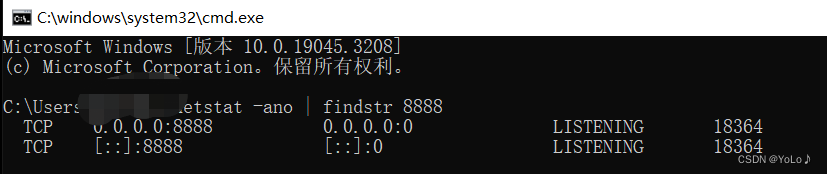
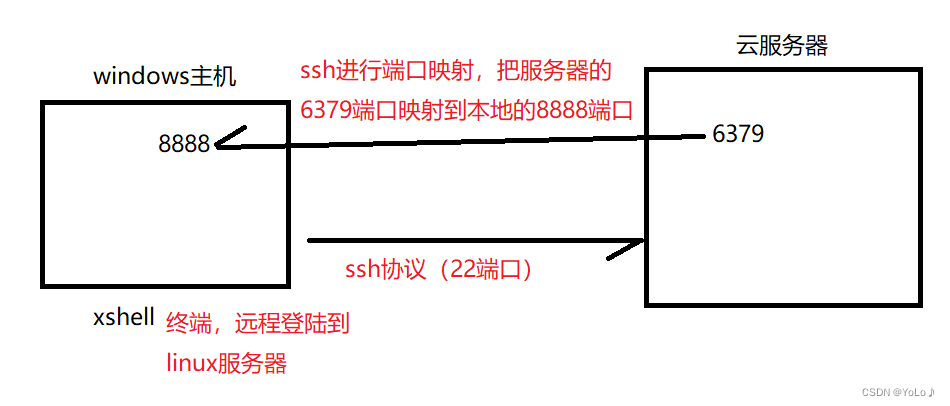 此时用户端程序访问127.0.0.1:8888等价于访问linux的6379端口了。同时也保障了安全性
此时用户端程序访问127.0.0.1:8888等价于访问linux的6379端口了。同时也保障了安全性
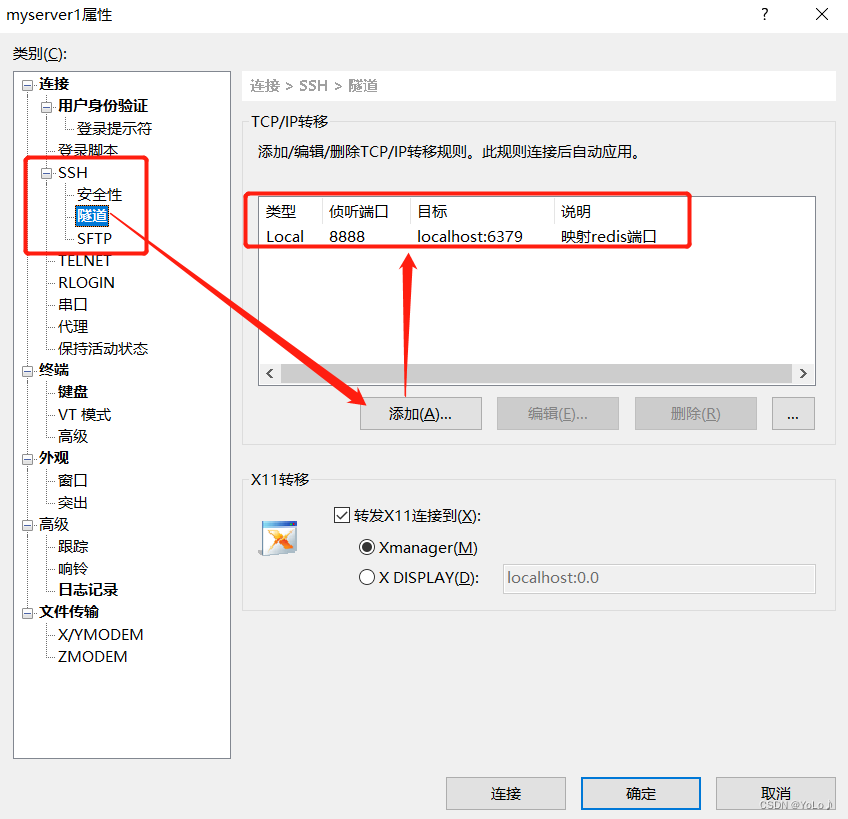
本机查看是否将8888端口绑定了 ,LISTEN状态就是绑定了
JedisAPI的使用
上述简单配置后,我们就能连接上redis了
1.创建Maven项目,导入jedis的依赖和单元测试依赖
<dependencies><!-- https://mvnrepository.com/artifact/redis.clients/jedis --><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.7.0</version></dependency><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter</artifactId><version>5.7.2</version><scope>test</scope></dependency></dependencies>编写代码
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;public class RedisTest {private Jedis jedis;
//前置工作,连接redis@BeforeEachvoid setUp(){jedis = new Jedis("127.0.0.1",8888);jedis.auth("123456");jedis.select(0);}
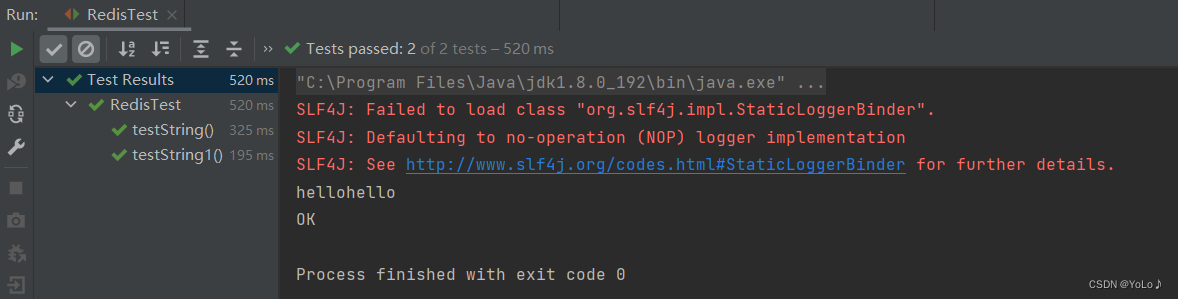
//使用@Testvoid testString1(){String res = jedis.set("hello3","hellohello");System.out.println(res);}@Testvoid testString(){String res = jedis.get("hello3");System.out.println(res);}
//后置工作,关闭资源@AfterEachvoid terDown(){if(jedis!=null){jedis.close();}}
}
Jedis连接池
Jedis是线程不安全的,并发环境下需要创建独立的jedis对象。频繁的创建和销毁对象会有很大的开销
因此推荐使用jedis连接池代替直连方式
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;public class JedisConnectionFactory {private static final JedisPool jedispoll;static {//配置连接池JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();jedisPoolConfig.setMaxTotal(8);//最大连接数,最多常见jedisPoolConfig.setMaxIdle(8);//最大空闲连接,最多预备的jedisPoolConfig.setMinIdle(0);//最小连接,一直没人访问,就释放jedisPoolConfig.setMaxWaitMillis(1000);//等待时长,没有连接池需要等待空闲连接吗,没有等待1000ms//创建对象jedispoll = new JedisPool(jedisPoolConfig,"127.0.0.1",8888,1000,"123456");}public static Jedis getJedis(){return jedispoll.getResource();}
}
修改测试代码
jedis = JedisConnectionFactory.getJedis();//不再new了,而是使用连接池中的jedis对象
public class RedisTest {private Jedis jedis;@BeforeEachvoid setUp(){
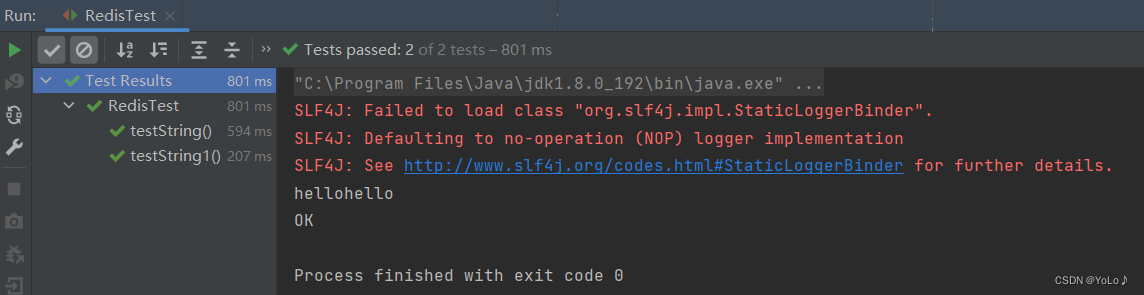
// jedis = new Jedis("127.0.0.1",8888);jedis = JedisConnectionFactory.getJedis();jedis.auth("123456");jedis.select(0);}@Testvoid testString1(){String res = jedis.set("hello5","hellohello");System.out.println(res);}@Testvoid testString(){String res = jedis.get("hello5");System.out.println(res);}@AfterEachvoid terDown(){if(jedis!=null){jedis.close();}}
}
2.SpringDataRedis的使用
Spring提供了一组API,SpringDataRedis,底层做了很多兼容。包含对各种数据库的集成,对redis集成模块叫做SpringDataRedis
特点:提供了对不同Redis客户端的整合(lettuce和jedis)
提供了RedisTemplate统一API来操作Redis
支持Redis的发布订阅模型、支持哨兵和集群、支持基于letuuce的响应式编程
支持基于JDK,JSON,字符串,Spring对象的数据序列化与反序列化
支持基于Redis的JDKCOLLECTION实现
使用 SpringDataRedis分三步:
1.创建项目,导入依赖
2.在配置文件中配置好信息
3.注入RedisTemplate对象
4.编写代码
1.创建项目
创建Maven项目,导入jedis的依赖和单元测试依赖
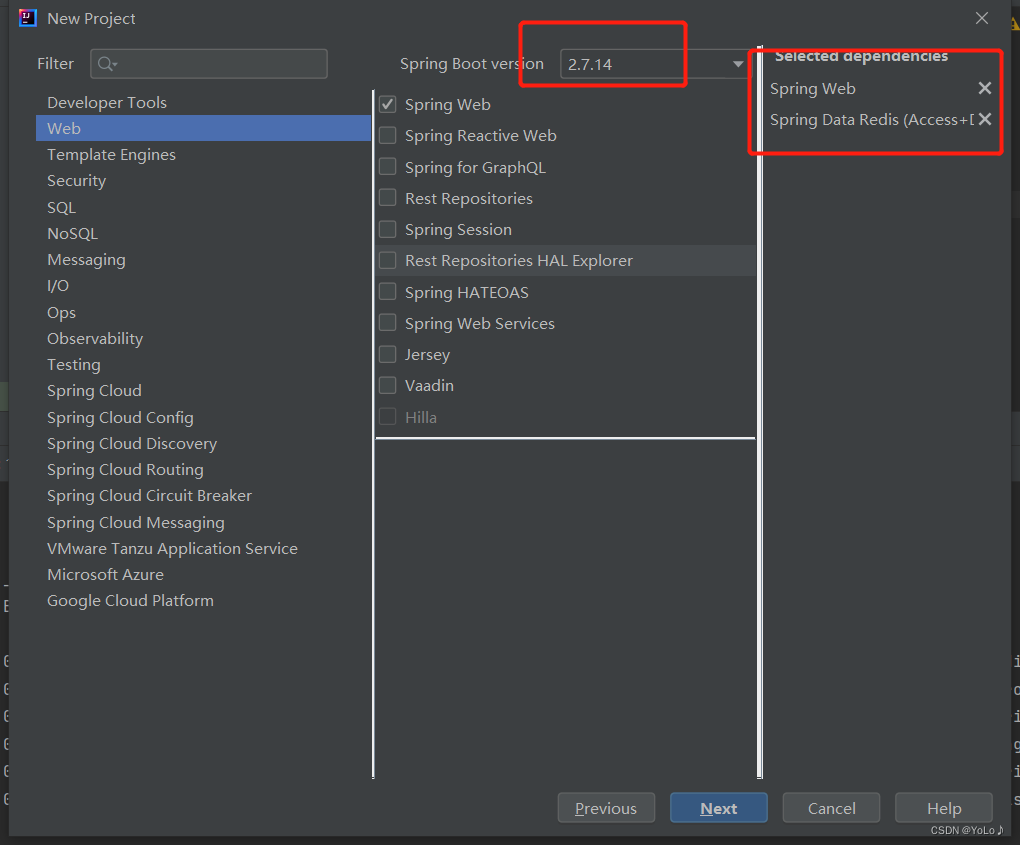
导入依赖,还要导入commons-pool2依赖
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId></dependency></dependencies>2.配置文件
spring.redis.host=127.0.0.1
#Redis服务器连接端口
spring.redis.port=8888
#Redis服务器连接密码(默认为空)
spring.redis.password=123456
#连接池最大连接数(使用负值表示没有限制)
spring.redis.pool.max-active=8
#连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.pool.max-wait=-1
#连接池中的最大空闲连接
spring.redis.pool.max-idle=8
#连接池中的最小空闲连接
spring.redis.pool.min-idle=0
#连接超时时间(毫秒)
spring.redis.timeout=300003.注入RedisTemplate对象
@Autowiredprivate RedisTemplate redisTemplate;4.编写代码
@SpringBootTest
class RedisDemo3ApplicationTests {@Autowiredprivate RedisTemplate redisTemplate;@Testvoid contextLoads() {redisTemplate.opsForValue().set("name","zhangsan");Object name = redisTemplate.opsForValue().get("name");System.out.println(name);}}运行
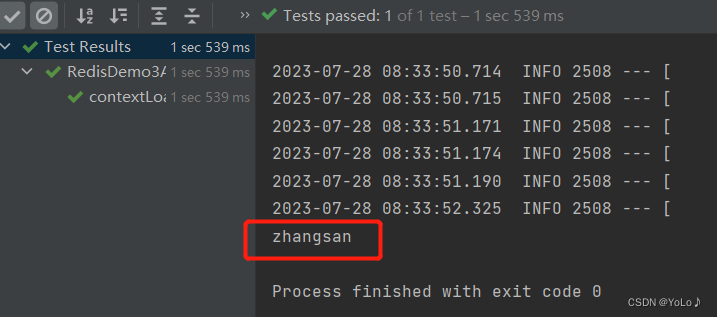
redis中的还没有修改 ,查询后发现乱码了
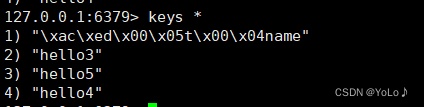
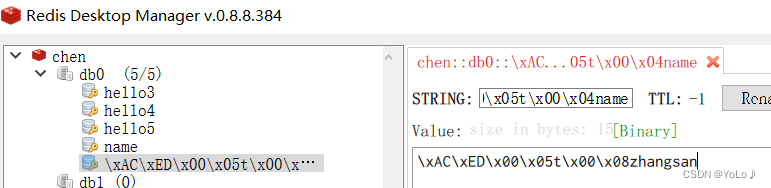
这与我们之前谈到的SpringDataRedis集成的redis支持序列化的特性
客户端传输数据时,将Object对象序列化为字节形式,默认采用的是jdk序列化,得到的结果自然不是正常字符串,可读性差并且占用内存
看一段RedisTemplate类的源码
public class RedisTemplate<K, V> extends RedisAccessor implements RedisOperations<K, V>, BeanClassLoaderAware {private boolean enableTransactionSupport = false;private boolean exposeConnection = false;private boolean initialized = false;private boolean enableDefaultSerializer = true;@Nullableprivate RedisSerializer<?> defaultSerializer;@Nullableprivate ClassLoader classLoader;@Nullableprivate RedisSerializer keySerializer = null;@Nullableprivate RedisSerializer valueSerializer = null;@Nullableprivate RedisSerializer hashKeySerializer = null;@Nullableprivate RedisSerializer hashValueSerializer = null;private RedisSerializer<String> stringSerializer = RedisSerializer.string();/省略......./public void afterPropertiesSet() {super.afterPropertiesSet();boolean defaultUsed = false;if (this.defaultSerializer == null) {this.defaultSerializer = new JdkSerializationRedisSerializer(this.classLoader != null ? this.classLoader : this.getClass().getClassLoader());}提供了各种数据结构的序列化,并且最后一个方法,当默认序列化设置为空时,首先会创建一个新的JdkSerializationRedisSerializer。这个不太好用,还有其他的序列化方式
查看RedisSerializer的层级结构
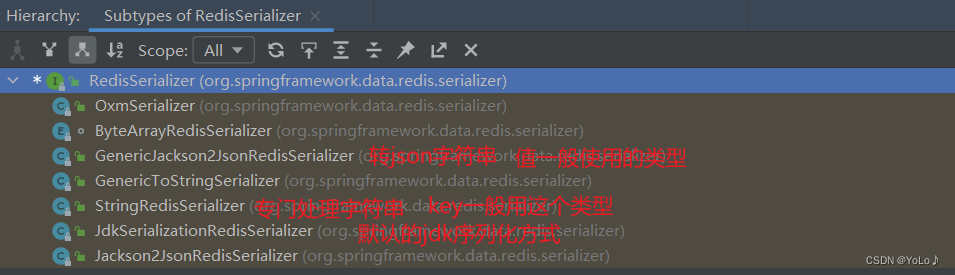
我们可以自定义 RedisTemplate的序列化 方式
值处理需要使用json,需要引入依赖
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId></dependency>编写序列化配置代码
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializer;@Configuration
public class RedisConfig {@Beanpublic RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory connectionFactory){//创建RedisTemplate对象RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>();//设置连接工厂redisTemplate.setConnectionFactory(connectionFactory);//创建JSON序列化工具GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();//设置key的序列化redisTemplate.setKeySerializer(RedisSerializer.string());redisTemplate.setHashKeySerializer(RedisSerializer.string());//设置value序列化redisTemplate.setValueSerializer(jsonRedisSerializer);redisTemplate.setHashValueSerializer(jsonRedisSerializer);//返回return redisTemplate;}
}@SpringBootTest
class RedisDemo3ApplicationTests {@Autowiredprivate RedisTemplate<String,Object> redisTemplate;@Testvoid contextLoads() {redisTemplate.opsForValue().set("name","慧怡");Object name = redisTemplate.opsForValue().get("name");System.out.println(name);}
}
我们使用Redis Desktop Manager查看
Redis Desktop Manager是一款简单快速、跨平台的Redis桌面管理工具,也被称作Redis可视化工具;支持命令控制台操作,以及常用,查询key,rename,delete等操作。
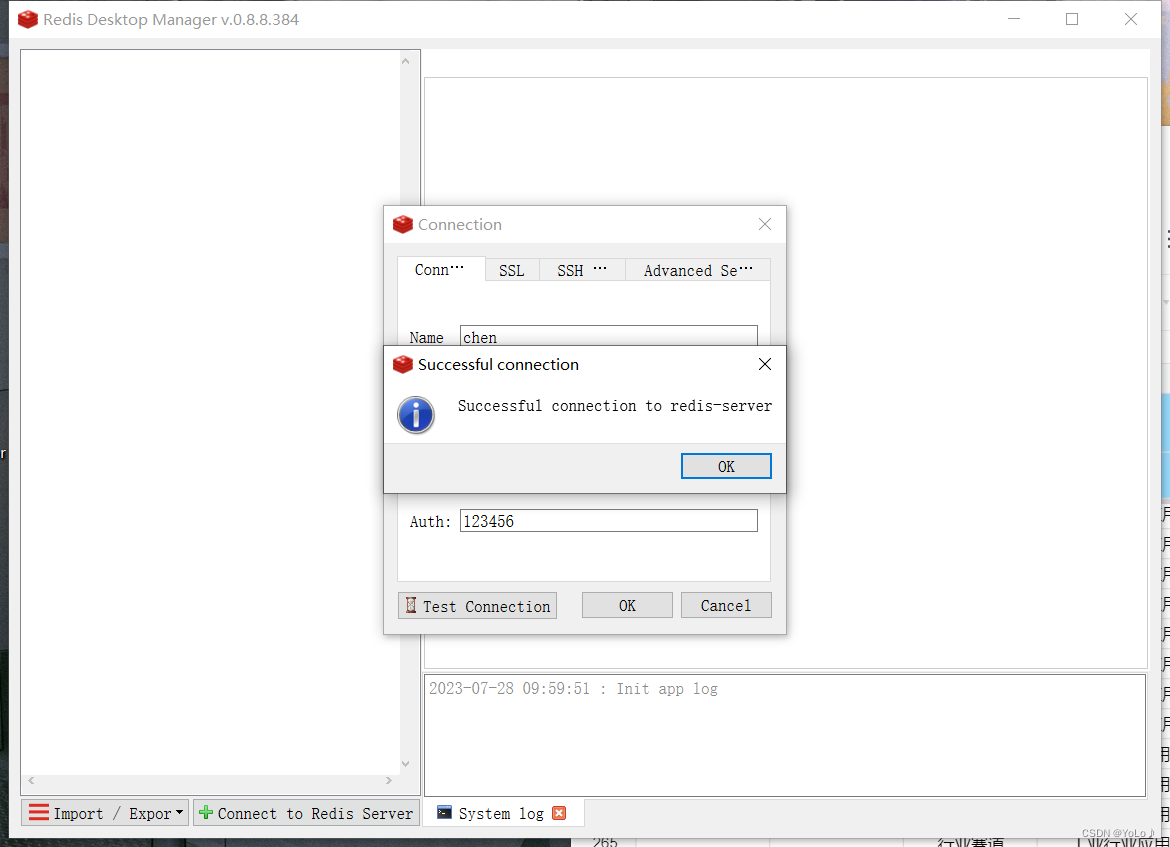
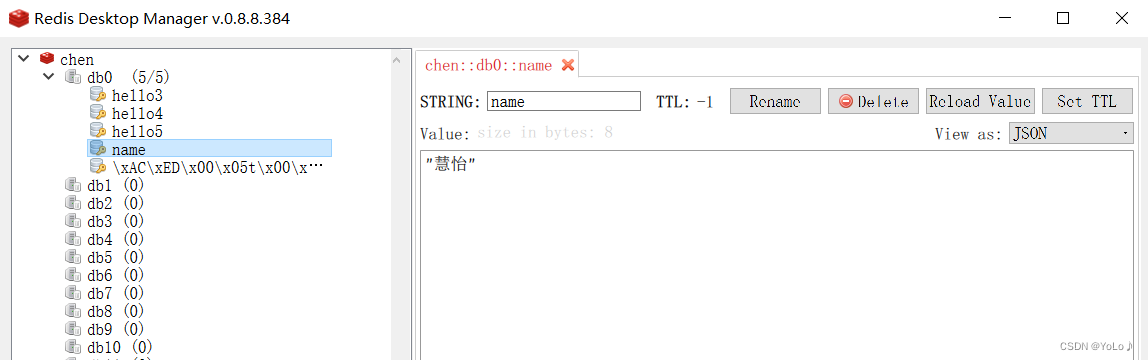
再看是否能传输对象
@Data@NoArgsConstructor@AllArgsConstructorpublic class User {private String name;private Integer age;}@Testvoid testSaveUser(){//写入数据redisTemplate.opsForValue().set("user:100",new User("慧怡",21));//获取数据User o = (User)redisTemplate.opsForValue().get("user:100");System.out.println("o = "+o);} 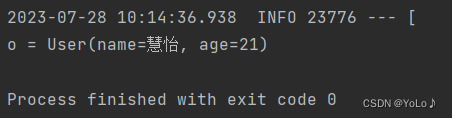
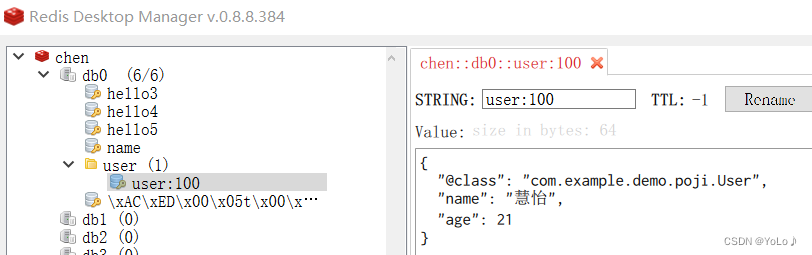
可以看到:将对象序列化后,存入了json的对象,获取结果时,控制台打印的时反序列化了的对象
3.SpringRedisTemplate
写入json对象的同时,还写入了一个"@class": "com.example.demo.poji.User",所以在反序列化的时候,才根据这个读取到字节码,类的名称,将json反序列化为User对象
所以无论是字符串,还是java对象,都可以进行存储了,我们只需要在config中配置好 key的序列化工具和 value 的序列化工具就好
同时也带来一个问题
可以看到第一行数据比下面的数据都长了,会带来额外的内存开销,如果数据量巨大,将是一笔不小的开销,但是为了能反序列化又不能不传入该字段
为了节省内存空间,并不会使用JSON序列化器处理VALUE,而是统一使用String序列化器,要求只存储String类型的KEY和VALUE,当存储Java对象时,手动完成对象的序列化和反序列化
转换过程:
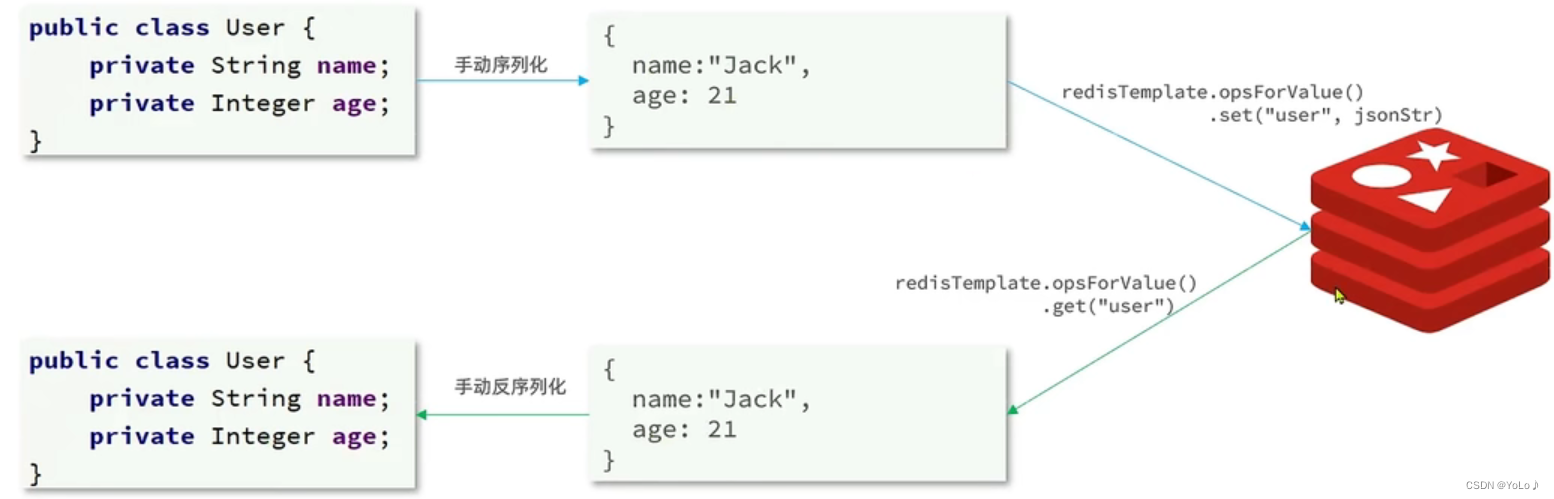
那么是否要重新将配置文件的序列化改动呢?是不用的, SpringRedisTemplate类的KEY与VALUE默认就是String方式,省去了我们自定义的过程
@SpringBootTest
public class RedisDemo3StringTests {@Autowiredprivate StringRedisTemplate stringRedisTemplate;@Testvoid testString(){stringRedisTemplate.opsForValue().set("name","慧怡");Object name = stringRedisTemplate.opsForValue().get("name");System.out.println(name);} 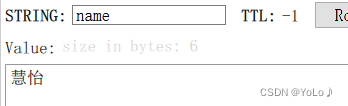
传对象时:
1.创建对象并手动序列化->写入数据
2.获取数据->手动反序列化
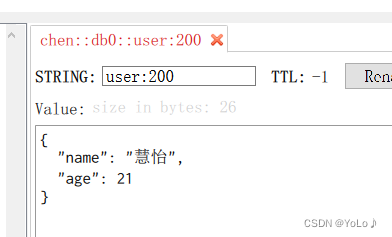
@Autowiredprivate static final ObjectMapper mapper = new ObjectMapper();@Testvoid testSaveUser() throws JsonProcessingException {//创建对象User user = new User("慧怡",21);//手动序列化String json = mapper.writeValueAsString(user);//写入数据stringRedisTemplate.opsForValue().set("user:200",json);//获取数据String jsonUser = stringRedisTemplate.opsForValue().get("user:200");//手动反序列化User user1 = mapper.readValue(jsonUser,User.class);System.out.println("user1 = "+user1);}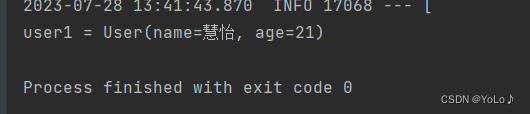
哈希结构用法
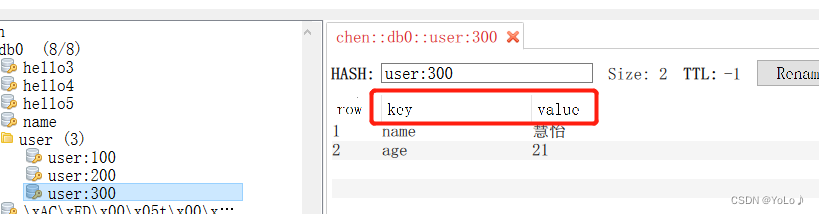
@Testvoid hsahTest(){//存储stringRedisTemplate.opsForHash().put("user:300","name","慧怡");stringRedisTemplate.opsForHash().put("user:300","age","21");//取值Map<Object,Object> entires = stringRedisTemplate.opsForHash().entries("user:300");System.out.println(entires);} 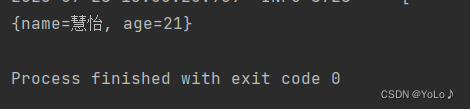
 总结
总结



![[NLP]LLM高效微调(PEFT)--LoRA](https://img-blog.csdnimg.cn/ca73a8eb85aa43b782100ca6210f34e9.png)