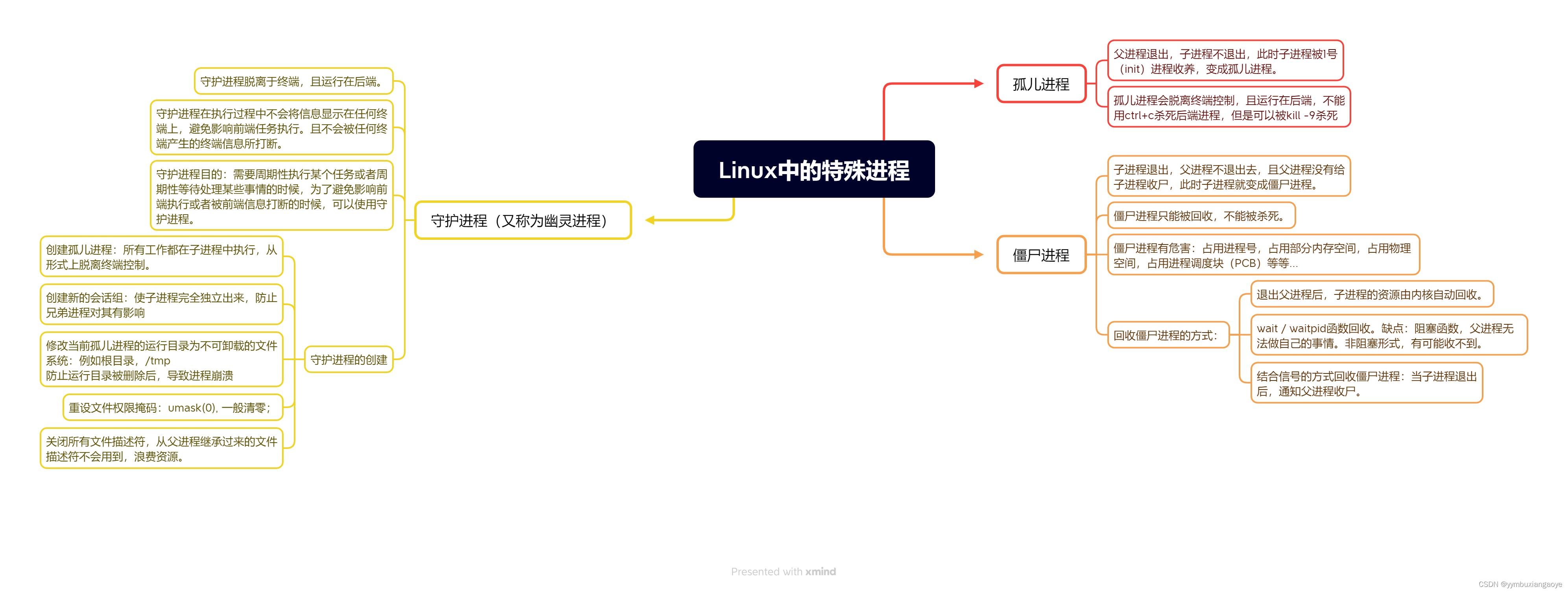
CPU压力
Batching
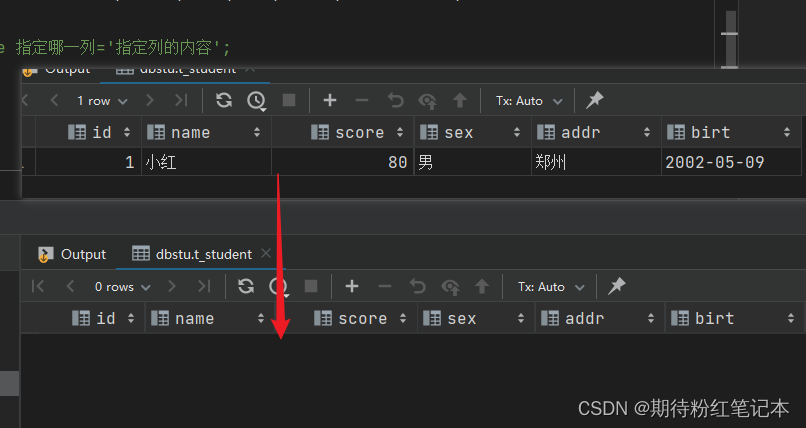
在GPU渲染前,CPU会把数据按batch发送给GPU,每发送一次,都是一个drawcall,GPU在渲染每个batch的时候,会切换渲染状态,这里的渲染状态指的是:影响对象在屏幕上的外观的渲染属性或材质,比如:材质球,贴如,颜色,渲染模式(透明、半透明)等
unity中的合批方式:
优先级:
SRP Batcher / Static Batching
GPU Instancing
Dynamic Batching
Draw Call Batching的使用条件
1. 支持Mesh Renderers、Trail Renderers、Line Renderers、Particle Systems
和Sprite Renderers,且只能批量处理相同类型的Renderer,不支持skin renderers
2. 需要使用相同的材质,因此在脚本中要使用Renderer.sharedMaterial而不是
Render.material,后者生成的是材质的副本,会打断合批
3. 使用MaterialPropertyBlock也会打断合批,不过它还是比使用多个材质要快
4. 透明物体的渲染严格按照先后顺序执行,合批很容易被打断
5. 尽量不要使用负的缩放值
StaticBatching:
static batching 的目的不是减少drawcall ,而是减少渲染状态的改变,因为在渲染之前,要设置该物体的各种渲染属性,如果是同一个批次,只设置一次就好了。
static batching 之所以不会减少drawcall,是因为静态合批的物体是可以被裁剪的,它只是合并了顶点数组,但是顶点索引还是单独的,这样就可以根据索引值来决定绘制哪些submesh,比如10个网格 static batch 成了一个网格,但是第5个网格没在视锥体内,则有2个drawcall,第1-4个submesh,第6-10个submesh,第5个是被裁剪了,虽然是2个drawcall,但是渲染状态只设置1次
如果不静态合批,虽然这10个mesh 的材质球、贴图都是一样的,也会分10个drawcall 去绘制,也就是10个batch ,要设置10次渲染状态。
细节补充:
1. 在编辑器中静态合批,Unity不会使用任何运行时的CPU资源来生成网格数据
2. 运行时进行静态合批会有一次较高的CPU峰值,可能会造/成一次卡顿
3. 完成静态合批后,对象成为一个整体,且为静态,无法修改Transform属性
4. 运行时可以对合批后的根对象staticBatchRoot进行Transfform属性的修改,
5. 不过运行时合批的对象需要开启Read/Write选项
手动网格合并
手动合并网格,和静态合批差不多,但是它不能裁剪submesh,如果视野中只有单个submesh,也会绘制整个mesh
Dynamic Batching
它在Unity中有两种类型,一种针对网格,一种针对动态生成的几何体,比如粒子系统
动态合批的目的是为了减少CPU的耗时,但是合批本身就消耗CPU,所以它里合批的条件比较严格
GPU Instance
原理:
Unity对于所有符合要求的对象,将其位置、缩放、uv偏移、lightmappindex等相关信息一次性存到Constant Buffer常量缓冲区中,当一个对象作为实例进入渲染流程时,会根据传入的Instance ID来从显存中取出对应的信息,用于后续的渲染阶段,不用每次都发送数据到GPU,以此实现优化的效
使用方法
1. 在材质的Inspector面板中勾选Enable Instancing的选项
2. 使用Graphics.DrawMeshInstanced或Graphics.DrawMeshInstancedirdirect 手动调用GPU instance
MaterialPropertyBlock
使用MaterialPropertyBlock设置随机颜色,不会打断合批,如果直接用material.setcolor 则会打断合批,因为那是一个单独的材质球,它和GPU Instance 最适配,和SRP Batcher最不适配
缺点:优先级比较低、提交一次drawcall 耗时比平常要多一点
优点:
- 相比静态合批不会带来额外的内存压力
- 相比动态合批没有严格的顶点限制
- 与MaterialPropertyBlock很适配,不会打断合批
适用场景:
需要画大批相同Mesh的场景,如草海、树林之类的
SRP Batcher
对于使用相同的着色器变体的材质,也就是对shader合批,即使材质球不一致,只要shader一致,就可以,当项目切换到SRP管线后,通过UniformBuffer传递信息,开启SRP Batcher后,会预先生成Uniform Buffer,批量传递信息,SRP Batcher以Shader为单位进行合批,可以有效降SetPassCall(设置渲染状态)的数目,用于CPU性能优化
原理:
对于未开启SPR Batcher的渲染流程是:每一个物体的属性都会在GPU上存在一个CBuffer,这里面包括Gameobject 属性,比如transform,material 属性,比如材质,光照贴图等。当其中属性更新时,就要重新设置数据,每增加一个material ,就会设置一遍对应的cbuffer,耗费CPU
开启了之后,流程发生了变化,相同的shader,对于那些不同的属性,比如transform,会生成一个大的buffer,对于相同的属性,比如光照贴图等,每一个都生成一个小的permaterial,当有状态改变时,才会修改该buffer,如果只是修改了transform,只会通过偏移写入相同位置的数据。
而对于新增的material,它的shader没变,则合批就不会变
传统上,人们倾向于减少Draw Call的数量来优化CPU,Draw Call本身只是推入GPU命令缓冲区的一些字节,真正的CPU成本来自于DrawCall之前的许多设置,SRP Batcher不会减少DrawCall的数量,它只是降低了Draw Call之间的设置成本
渲染管线要求:
支持URP、HDRP、SRP,不支持Built-in管线
游戏对象要求:
必须包含一个Mesh或者Skinned Mesh,不能是粒子
不能使用MaterialPropertyBlock
Shader必须兼容SRP Batcher
优点:
节省UniformBuffer的写入操作,支持动态物体,支持的范围要比静态合批更广泛,同时内存上的代价会小很多,材质多的情况也适用
适用场景:
Shader重复率高,但是要控制Shader变体的数量
四种方法的对比
优先级:
SRP Batcher / Static Batching > GPU Instancing > Dynamic Batching
适用情况:
Static Batching+SRP Batcher:主城,副本建筑
SRP BatcherOnly:种类繁多的植被
GPU Instancing:种类单一的植被
Dynamic Batching:Ul,粒子,Sprite等
Culling
在GPU进行渲染之前,需要CPU传递渲染数据给GPU,因此需要先将一部分不需要进行渲染的对象进行剔除,也就是Culling。Unity引擎原生就支持了视椎体剔除,即将视域体范围外的对象进行剔除,这部分对象的数据就不用传给GPU进行处理。
在Unity中,所有的可视内容都继承自Renderer,比如MeshRenderfer、SpriteRenderer、LineRenderer、SkinnedMesh Renderer、TrailRenderer等在Unity进行渲染的过程中会它们进行筛选,自动执行视锥体剔限的操作
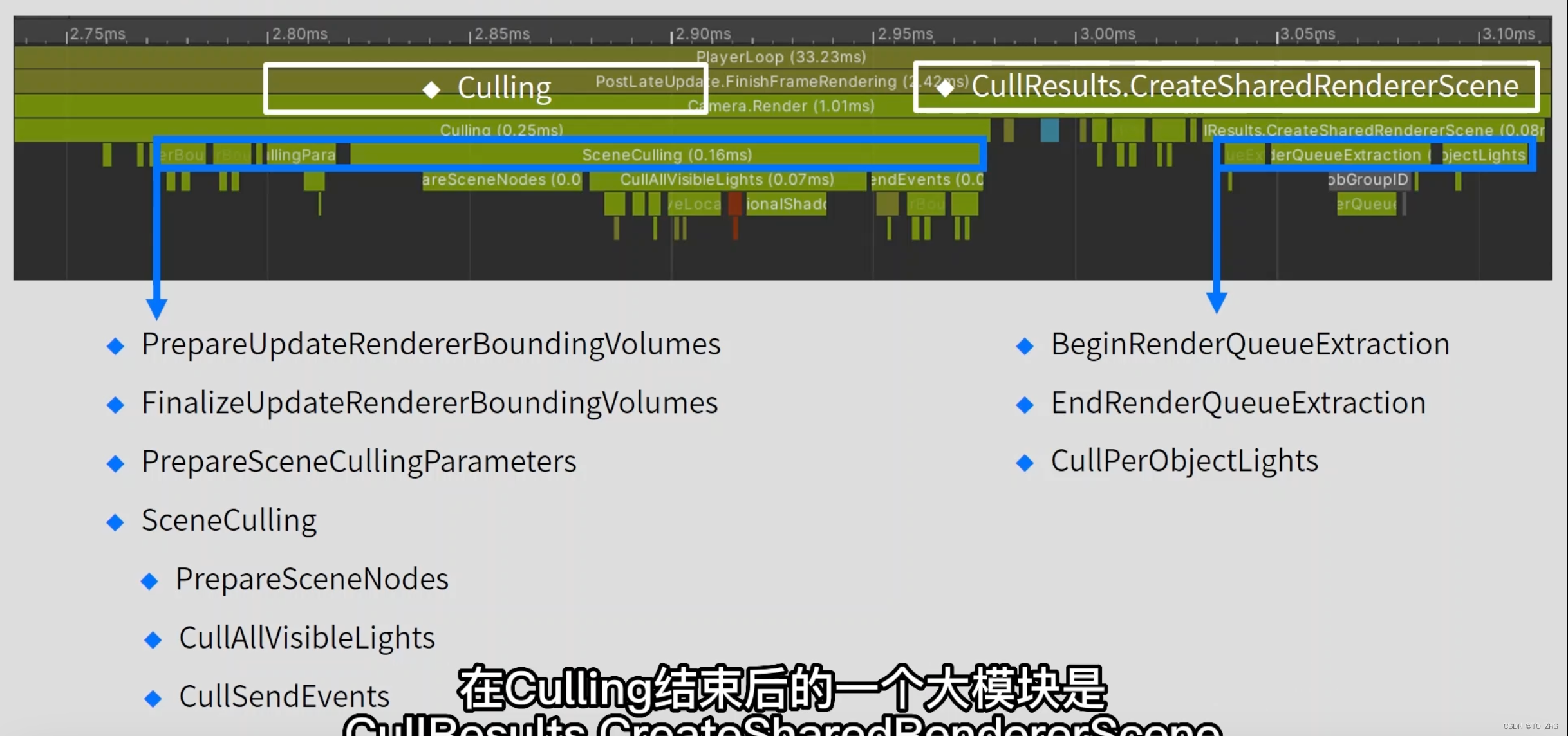
如果场景中激活的相机数量多,那么Cullling的总耗时也相应增高,即使没有用来显示物体,也会执行culling 耗时,函数体现在 Render 线程中的->Camera.Renderer
CullingGroup
CullingGroup是Unity提供的一个API接口,它本身和Unity自己的Cu系统以及LOD是同一体系,相当于开放了一些Cull底层的功能供用户使用
Unity - Manual: CullingGroup API
Occlusion
基本介绍
摄像机在每一帧中执行剔除操作,这些操作会检查场景中的渲染器,并排除
(剔除)那些不需要绘制的渲染器
默认情况下,摄像机执行视锥体剔除
工作原理
在Unity Editor中生成有关场景的数据,然后在运行时使用该数据确定摄像机可以看到的内容,生成数据的过程称为烘焙.
在对遮挡剔除数据进行烘焙时,Unity将场景划分为多个单元,并生成描述单元内几何体以及相邻单元之间可见性的数据,然后,Unity尽可能合并单元,以减小生成的数据的大小,在运行时,Unity会将这些烘焙的数据加载到内存中,并且对于每个启用了Occlusion Culling属性的摄像机,将会对数据执行查询以确定该摄像机可以看到的内容
在CullSendEvents的子线程下方会出现CullQueryPortalVisibilitylJmbra函数
测试中该函数也会出现在工作线程中
使用建议
遮挡物:
- 大的遮挡物具有良好的遮挡质量,比如山
- 组合起来大的遮挡物并不合适,因为遮挡无法累计,如森林
- 不要有太多的缝隙,如奶酪
- 建模时要注意避免无意造成的缝隙
- 尽量不要让相机能进入遮挡物内部,可通过碰撞实现
被遮挡物:
- 可以将大部分都设置为被遮挡物,便于被剔除
- 非常大的物体不适合作为被遮挡物,因为它总会被看到,如地形,可以考虑将其分割为多个部分