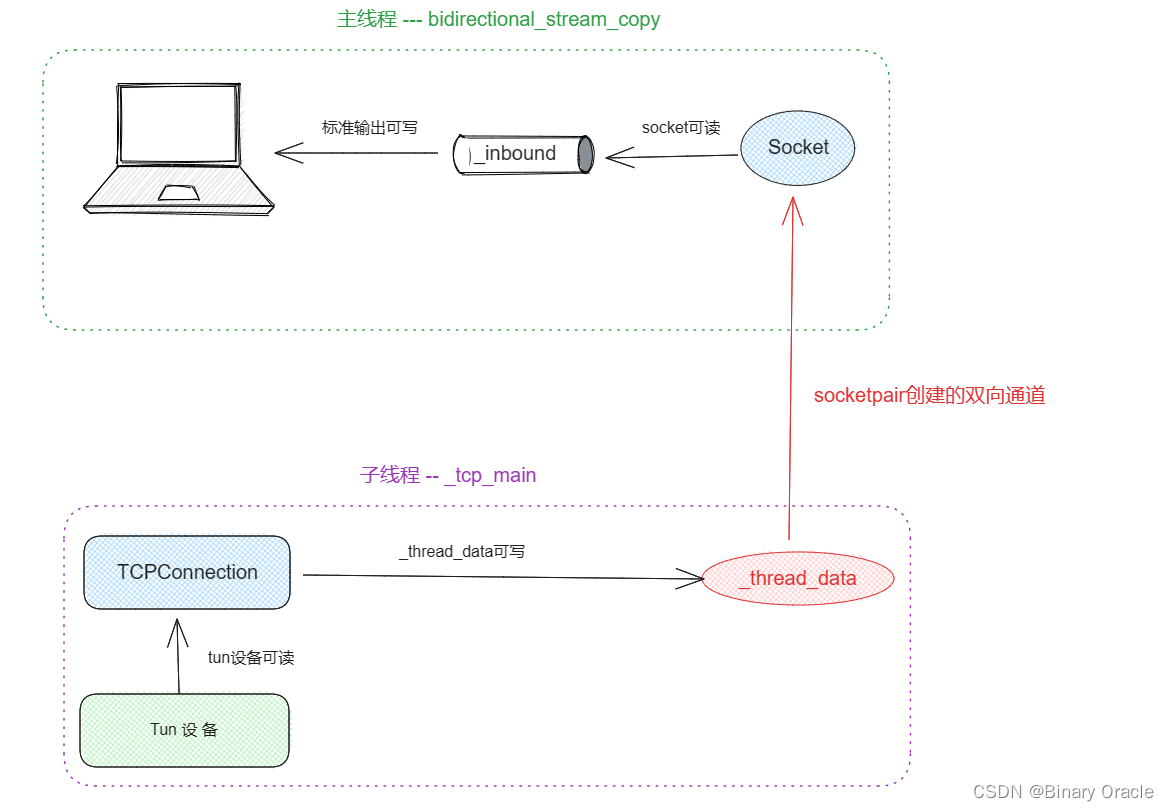
目录
1.切分算法
2.完全切分
3.正向最长匹配
4.逆向最长匹配
5.双向最长匹配
6.速度评测
1.切分算法
词典确定后,句子可能含有很多词典中的词语,他们有可能互相重叠,如何切分需要一些规则。常用规则为:正向匹配算法、逆向匹配算法以及双向匹配算法。但他们都是基于完全切分过程。
2.完全切分
完全切分指的是,找出一段文本中的所有单词。朴素的完全切分算法其实非常简单,只要遍历文本中的连续序列,查询该序列是否在词典中即可。定义词典为dic,文本为text,当前的处理位置为i,完全切分的python算法如下:
def fully_segment(text, dic):word_list = []for i in range(len(text)): # i 从 0 到text的最后一个字的下标遍历for j in range(i + 1, len(text) + 1): # j 遍历[i + 1, len(text)]区间word = text[i:j] # 取出连续区间[i, j]对应的字符串if word in dic: # 如果在词典中,则认为是一个词word_list.append(word)return word_listif __name__ == '__main__':dic = load_dictionary()print(fully_segment('商品和服务', dic))
运行结果:
![]()
输出了所有可能的单词。由于词库中含有单字,所以结果中也出现了一些单字。
3.正向最长匹配
完全切分的结果比较没有意义,我们更需要那种有意义的词语序列,而不是所有出现在词典中的单词所构成的链表。 所以需要完善一下处理规则,考虑到越长的单词表达的意义越丰富,于是我们定义单词越长优先级越高。具体说来,就是在以某个下标为起点递增查词的过程中,优先输出更长的单词,这种规则被称为最长匹配算法。扫描顺序从前往后,则称为正向最长匹配,反之则为逆向最长匹配。
def forward_segment(text, dic):word_list = []i = 0while i < len(text):longest_word = text[i] # 当前扫描位置的单字for j in range(i + 1, len(text) + 1): # 所有可能的结尾word = text[i:j] # 从当前位置到结尾的连续字符串if word in dic: # 在词典中if len(word) > len(longest_word): # 并且更长longest_word = word # 则更优先输出word_list.append(longest_word) # 输出最长词i += len(longest_word) # 正向扫描return word_listif __name__ == '__main__':dic = load_dictionary()print(forward_segment('就读北京大学', dic))print(forward_segment('研究生命起源', dic))结果:
['就读', '北京大学']
['研究生', '命', '起源']
第二句话就会产生误差了,我们是需要把“研究”提取出来,结果按照正向最长匹配算法就提取出了“研究生”,所以人们就想出了逆向最长匹配。
4.逆向最长匹配
def backward_segment(text, dic):word_list = []i = len(text) - 1while i >= 0: # 扫描位置作为终点longest_word = text[i] # 扫描位置的单字for j in range(0, i): # 遍历[0, i]区间作为待查询词语的起点word = text[j: i + 1] # 取出[j, i]区间作为待查询单词if word in dic:if len(word) > len(longest_word): # 越长优先级越高longest_word = wordbreakword_list.insert(0, longest_word) # 逆向扫描,所以越先查出的单词在位置上越靠后i -= len(longest_word)return word_listdic = load_dictionary()
print(backward_segment('研究生命起源', dic))
print(backward_segment('项目的研究', dic))输出:
['研究', '生命', '起源']
['项', '目的', '研究']
第一句正确了,但下一句又出错了,可谓拆东墙补西墙。另一些人提出综合两种规则,期待它们取长补短,称为双向最长匹配。
5.双向最长匹配
统计显示,正向匹配错误而逆向匹配正确的句子占9.24%。双向最长匹配规则集,流程如下:
(1)同时执行正向和逆向最长匹配,若两者的词数不同,则返回词数更少的那一个。
(2)否则,返回两者中单字更少的那一个。当单字数也相同时,优先返回逆向最长匹配的结果。
def count_single_char(word_list: list): # 统计单字成词的个数return sum(1 for word in word_list if len(word) == 1)def bidirectional_segment(text, dic):f = forward_segment(text, dic)b = backward_segment(text, dic)if len(f) < len(b): # 词数更少优先级更高return felif len(f) > len(b):return belse:if count_single_char(f) < count_single_char(b): # 单字更少优先级更高return felse:return b # 都相等时逆向匹配优先级更高print(bidirectional_segment('研究生命起源', dic))
print(bidirectional_segment('项目的研究', dic))结果:
['研究', '生命', '起源']
['项', '目的', '研究']
比较之后发现,双向最长匹配在2、3、5这3种情况下选择出了最好的结果,但在4号句子上选择了错误的结果,使得最终正确率3/6反而小于逆向最长匹配的4/6。由此,规则系统的脆弱可见一斑。规则集的维护有时是拆东墙补西墙,有时是帮倒忙。
6.速度评测
词典分词的规则没有技术含量,消除歧义的效果不好。词典分词的核心价值不在于精度,而在于速度。
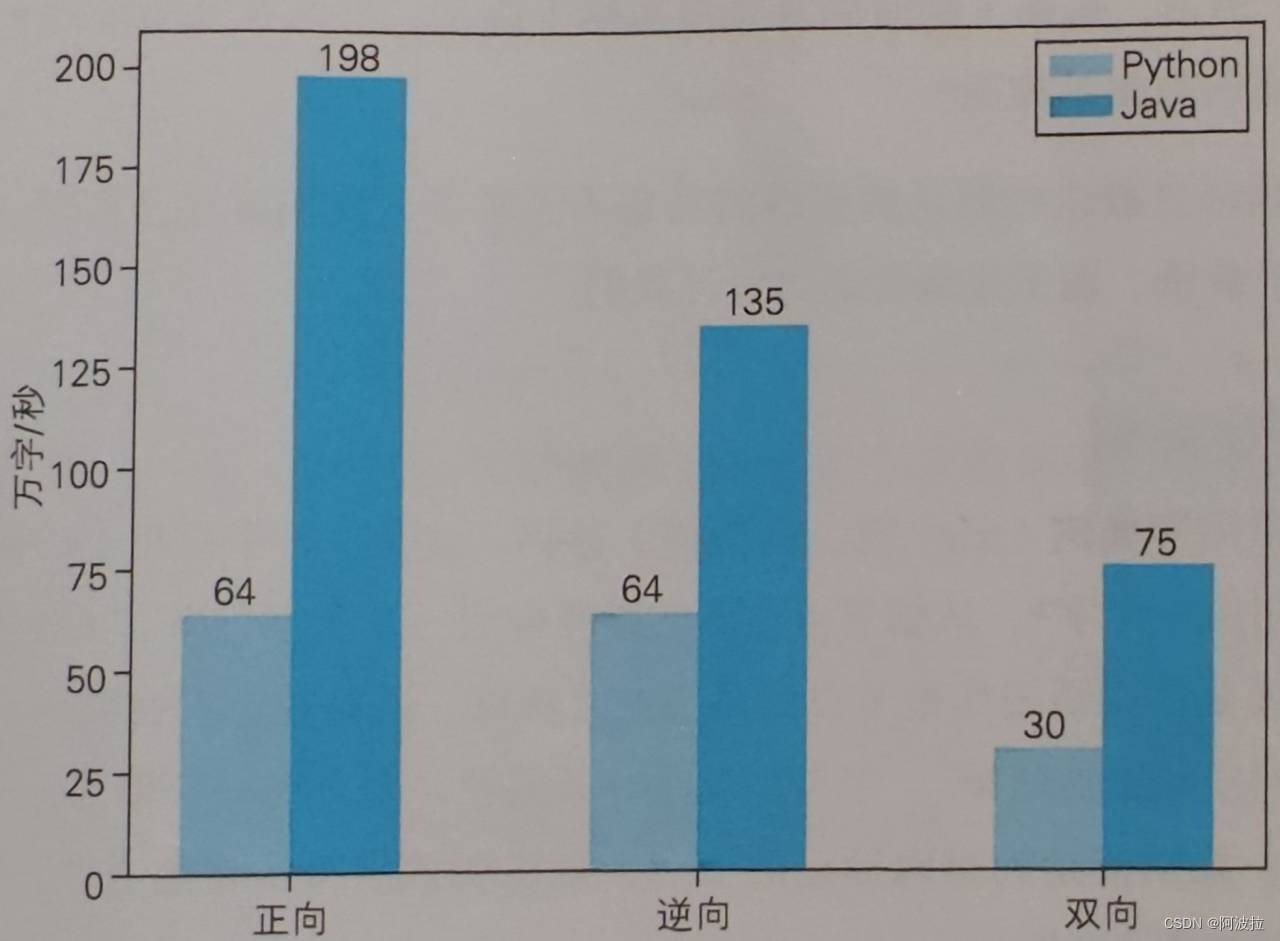
总结:
- Python的运行速度比Java慢,效率只有Java的一半不到
- 正向匹配与逆向匹配的速度差不多,是双向的两倍。因为双向做了两倍的工作
- Java实现的正向匹配比逆向匹配快

![LeetCode[207]课程表](https://img-blog.csdnimg.cn/6df6d3bf31f947939cfdaa6363ad7c1e.png)