文章目录
- 一、导读
- 二、比赛背景
- 三、比赛任务
- 四、比赛数据
- 五、评价指标
- 六、Baseline
- 6.1 Training part
- 6.2 Submission part
一、导读

比赛名称:Google Research - Identify Contrails to Reduce Global Warming
https://www.kaggle.com/competitions/google-research-identify-contrails-reduce-global-warming
训练 ML 模型以识别卫星图像中的尾迹
比赛类型:计算机视觉、语义分割
二、比赛背景
Contrails 是“凝结轨迹”的缩写,是在飞机发动机排气中形成的线状冰晶云,由飞机飞过大气中的超潮湿区域时产生。持续的尾迹对全球变暖的贡献与它们为飞行所燃烧的燃料一样多。
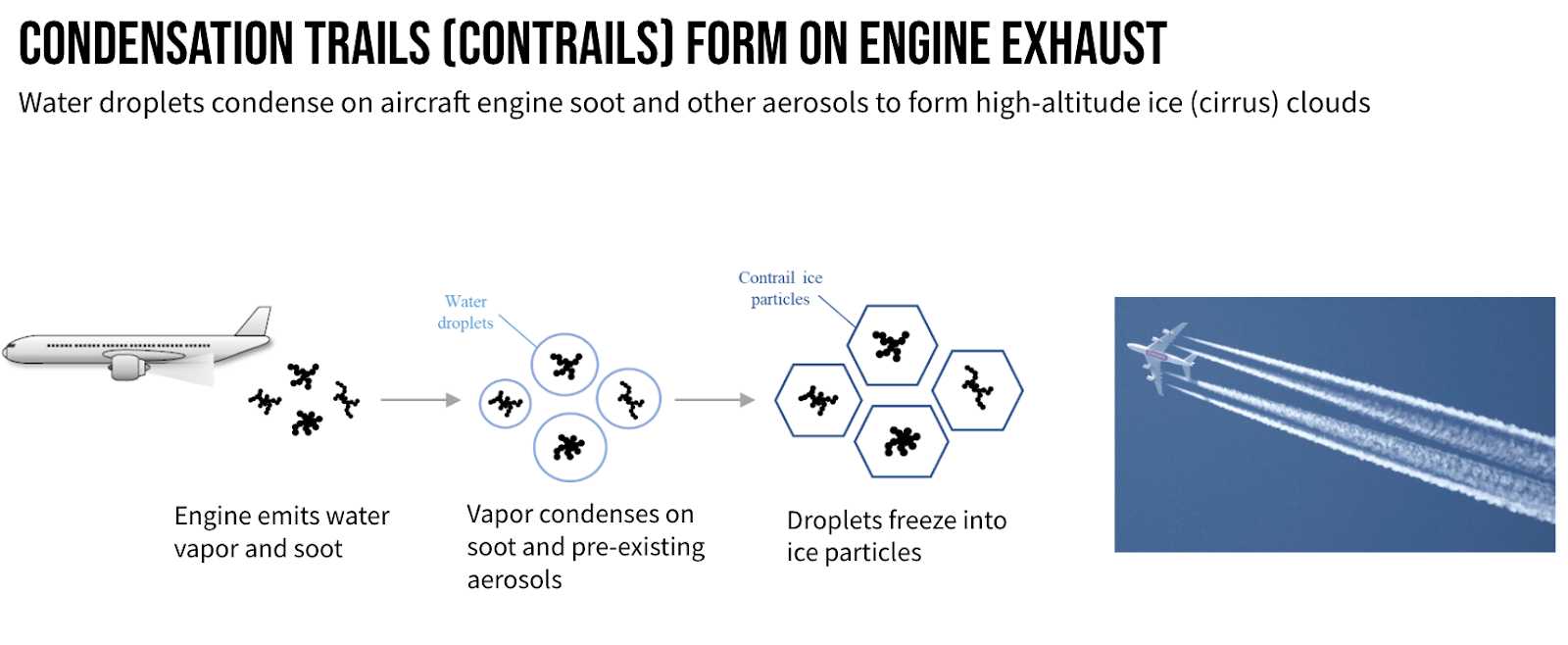
凝结尾迹占人类造成的全球变暖的大约 1%,使用卫星图像的目的是确认已有的模型的预测效果。凝结尾迹是飞机发动机排气中形成的冰晶云。它们可以通过在大气中吸收热量来促进全球变暖。研究人员已经开发出模型来预测凝结尾迹何时形成以及它们将导致多少变暖。但是,他们需要使用卫星图像来验证这些模型。
三、比赛任务
在本次比赛中,您将使用地球静止卫星图像来识别航空轨迹。原始卫星图像是从GOES-16 Advanced Baseline Imager (ABI)获得的,它在Google Cloud Storage上公开可用。
- 轨迹必须包含至少 10 个像素
- 轨迹必须至少比宽度长 3 倍
- 轨迹应至少在两个图像中可见

四、比赛数据
- train/ - 训练集;每个文件夹代表一个record_id
- validation/ 与训练集相同,没有单独的标签注释
- test/ - 测试集
- sample_submission.csv - 格式正确的样本提交文件
五、评价指标
为了减小提交文件的大小,我们的指标对像素值使用游程编码。评价指标为 Dice coefficient:
2 ∗ ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ \frac{2 * |X \cap Y|}{|X| + |Y|} ∣X∣+∣Y∣2∗∣X∩Y∣
赛题是一个典型语义分割比赛,需要构建语义分割的模型。相比与常规的语义分割比赛,本次比赛有两个难点:
- 比赛数据集比较大,450GB
- 包含时序图片,并且标签和时序相关
六、Baseline
6.1 Training part
import sys
sys.path.append("../input/pretrained-models-pytorch")
sys.path.append("../input/efficientnet-pytorch")
sys.path.append("/kaggle/input/smp-github/segmentation_models.pytorch-master")
sys.path.append("/kaggle/input/timm-pretrained-resnest/resnest/")
import segmentation_models_pytorch as smp
具体来说,代码做了以下几个操作:
- 导入 sys 模块,用于添加新的路径到 Python 搜索路径中。
- 使用
sys.path.append将 “…/input/pretrained-models-pytorch”、“…/input/efficientnet-pytorch”、“/kaggle/input/smp-github/segmentation_models.pytorch-master” 和 “/kaggle/input/timm-pretrained-resnest/resnest/” 这四个路径添加到 Python 搜索路径中。 - 导入了
segmentation_models_pytorch模块,并使用别名smp。
通过以上导入操作,你可以使用 smp 这个别名来调用 segmentation_models_pytorch 库中的函数和类,例如图像分割模型。
这样做的目的是为了方便在 Kaggle 环境中使用预训练的 PyTorch 模型和相关的图像分割工具,以便更轻松地进行图像分割任务的开发和实验。
%%writefile config.yamldata_path: "/kaggle/input/contrails-images-ash-color"
output_dir: "models"folds:n_splits: 4random_state: 42
train_folds: [0, 1, 2, 3]seed: 42train_bs: 48
valid_bs: 128
workers: 2progress_bar_refresh_rate: 1early_stop:monitor: "val_loss"mode: "min"patience: 999verbose: 1trainer:max_epochs: 20min_epochs: 20enable_progress_bar: Trueprecision: "16-mixed"devices: 2model:seg_model: "Unet"encoder_name: "timm-resnest26d"loss_smooth: 1.0image_size: 384optimizer_params:lr: 0.0005weight_decay: 0.0scheduler:name: "cosine_with_hard_restarts_schedule_with_warmup"params:cosine_with_hard_restarts_schedule_with_warmup:num_warmup_steps: 350num_training_steps: 3150num_cycles: 1
这段代码是一个 YAML 格式的配置文件,用于配置一个图像分割任务的参数。YAML 是一种简单的数据序列化语言,用于配置和存储数据。
这份配置文件中包含了以下内容:
- 数据路径和输出目录:定义了数据集的路径和输出模型的目录。
- 交叉验证的折数:
folds部分指定了交叉验证的折数和随机种子,以便将数据集划分为训练集和验证集。 - 训练和验证的批次大小:
train_bs和valid_bs分别指定了训练和验证时的批次大小。 - 训练的其他参数:包括随机种子
seed、工作线程数量workers、进度条刷新率progress_bar_refresh_rate等。 - 提前停止策略:
early_stop部分指定了提前停止的相关参数,例如监测的指标、模式(最小化或最大化)、耐心值等。 - 训练器(Trainer)参数:包括最大训练周期数
max_epochs、最小训练周期数min_epochs、是否启用进度条等。 - 模型参数:
model部分定义了图像分割模型的相关参数,如分割模型的类型seg_model、编码器的名称encoder_name、图像大小image_size、优化器参数等。
这样的配置文件可以让你在运行图像分割任务时轻松地修改参数和配置,以便快速尝试不同的设置和调整超参数,提高模型性能和训练效率。
# Dataset
import torch
import numpy as np
import torchvision.transforms as Tclass ContrailsDataset(torch.utils.data.Dataset):def __init__(self, df, image_size=256, train=True):self.df = dfself.trn = trainself.normalize_image = T.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))self.image_size = image_sizeif image_size != 256:self.resize_image = T.transforms.Resize(image_size)def __getitem__(self, index):row = self.df.iloc[index]con_path = row.pathcon = np.load(str(con_path))img = con[..., :-1]label = con[..., -1]label = torch.tensor(label)img = torch.tensor(np.reshape(img, (256, 256, 3))).to(torch.float32).permute(2, 0, 1)if self.image_size != 256:img = self.resize_image(img)img = self.normalize_image(img)return img.float(), label.float()def __len__(self):return len(self.df)
这段代码定义了一个 PyTorch 数据集类 ContrailsDataset,用于加载和处理图像分割任务的数据。
数据集类的主要功能包括:
- 初始化:在初始化过程中,数据集类接收一个数据帧(DataFrame)
df,以及一个布尔值train,用于标识数据集是用于训练还是验证。同时,它也接收一个整数image_size,表示图像的大小,若该值不等于 256,则会使用T.transforms.Resize将图像调整为指定大小。 __getitem__方法:这是数据集类的核心方法,在使用索引来获取数据样本时会调用。在这个方法中,根据索引获取数据帧中的一行,从中提取出图像和标签,并对其进行处理。具体地,它会将读取的 numpy 数组转换为 PyTorch 张量,并进行大小和通道维度的调整,最后返回处理后的图像和标签。__len__方法:这个方法返回数据集的样本数量,以便在训练和验证时知道数据集的总样本数。
该数据集类适用于加载存储在 numpy 格式中的图像和标签数据,并将其转换为 PyTorch 张量,供神经网络模型使用。注意,在使用该数据集类之前,你需要根据实际数据的存储方式和结构来适配数据帧 df,以确保正确读取图像和标签数据。
self.normalize_image 是一个 torchvision 的数据转换(transform),用于对图像数据进行归一化操作。在深度学习中,归一化是一个重要的预处理步骤,可以将图像的像素值缩放到特定的范围,以便更好地训练模型并提高模型的收敛性和稳定性。
在 torchvision 中,T.Normalize(mean, std) 是一个常用的数据转换,它将输入的图像数据进行归一化。它接受两个参数:
mean:这是一个包含三个元素的元组或列表,表示图像数据在每个通道上的均值。通常,这些均值是在大规模图像数据集上计算得到的。在这里,(0.485, 0.456, 0.406) 是对应于 ImageNet 数据集的 RGB 通道均值。std:这也是一个包含三个元素的元组或列表,表示图像数据在每个通道上的标准差。同样,这些标准差也是在大规模图像数据集上计算得到的。在这里,(0.229, 0.224, 0.225) 是对应于 ImageNet 数据集的 RGB 通道标准差。
T.Normalize 的作用是将图像数据的每个通道减去均值,然后除以标准差,这样处理后的图像数据会具有零均值和单位方差,从而使数据的分布更稳定。
在 ContrailsDataset 类中,self.normalize_image 这个数据转换被用于对图像数据进行归一化处理。在 __getitem__ 方法中,将加载的图像数据转换为 PyTorch 张量后,会应用 self.normalize_image 来进行归一化处理,以便更好地输入神经网络模型。这样做可以有效地将数据缩放到合适的范围,以加快训练速度和提高模型性能。
__getitem__ 方法的完整实现。该方法用于获取数据集中的一个样本。
row = self.df.iloc[index]:从数据帧df中根据索引index获取相应行的数据。con_path = row.path:从该行数据中获取路径信息,该路径指向一个数据文件,其中包含图像数据和标签数据。con = np.load(str(con_path)):使用 NumPy 的np.load()方法加载数据文件,将其读取为一个 NumPy 数组con。img = con[..., :-1]:从con数组中获取图像部分,...表示所有维度的索引,:-1表示除了最后一个维度之外的所有维度。label = con[..., -1]:从con数组中获取标签部分,...表示所有维度的索引,-1表示最后一个维度。label = torch.tensor(label):将标签数据转换为 PyTorch 张量。img = torch.tensor(np.reshape(img, (256, 256, 3))).to(torch.float32).permute(2, 0, 1):将图像数据转换为 PyTorch 张量,并进行一系列预处理操作。np.reshape(img, (256, 256, 3))将图像的通道维度移到最后,然后使用torch.tensor()将其转换为张量,to(torch.float32)将数据类型转换为 float32,最后使用permute(2, 0, 1)将通道维度移到最前面,使其符合 PyTorch 的张量格式要求。if self.image_size != 256::检查图像的尺寸是否需要进行调整。img = self.resize_image(img):如果需要,将图像大小调整为self.image_size。img = self.normalize_image(img):对图像数据进行标准化处理,将像素值缩放到固定的范围内,以适应模型的输入要求。return img.float(), label.float():返回处理后的图像和标签作为元组,并将它们转换为 float 类型的张量。
在 PyTorch 中,permute() 是一个张量的操作函数,用于重新排列张量的维度顺序。它的作用是改变张量的维度排列,不改变张量中的元素值。
permute() 函数的输入参数是一个表示新维度顺序的整数元组。例如,对于一个四维张量 tensor,可以使用 tensor.permute(0, 2, 3, 1) 来将原先的维度排列 [0, 1, 2, 3] 调整为 [0, 2, 3, 1]。
下面是一个示例:
import torch# 创建一个四维张量
tensor = torch.randn(2, 3, 4, 5)
# 打印原始维度排列
print("Original tensor shape:", tensor.shape) # Output: (2, 3, 4, 5)
# 使用 permute() 调整维度排列
tensor_permuted = tensor.permute(0, 2, 3, 1)
# 打印调整后的维度排列
print("Permuted tensor shape:", tensor_permuted.shape) # Output: (2, 4, 5, 3)
在上面的示例中,原始张量的维度排列是 [2, 3, 4, 5],使用 tensor.permute(0, 2, 3, 1) 调整为 [2, 4, 5, 3]。可以看到,张量的维度顺序被重新排列,但张量中的元素值保持不变。permute() 函数是一种非常便捷的方式来进行维度转换,特别是在神经网络的数据处理过程中,经常需要调整张量的维度以适应模型的输入要求。
# Lightning moduleimport torch
import pytorch_lightning as pl
import segmentation_models_pytorch as smp
from torch.optim.lr_scheduler import CosineAnnealingLR, ReduceLROnPlateau
from torch.optim import AdamW
import torch.nn as nn
from torchmetrics.functional import dice
from transformers import get_cosine_with_hard_restarts_schedule_with_warmupseg_models = {"Unet": smp.Unet,"Unet++": smp.UnetPlusPlus,"MAnet": smp.MAnet,"Linknet": smp.Linknet,"FPN": smp.FPN,"PSPNet": smp.PSPNet,"PAN": smp.PAN,"DeepLabV3": smp.DeepLabV3,"DeepLabV3+": smp.DeepLabV3Plus,
}class LightningModule(pl.LightningModule):def __init__(self, config):super().__init__()self.config = configself.model = model = seg_models[config["seg_model"]](encoder_name = config["encoder_name"],encoder_weights = "imagenet",in_channels = 3,classes = 1,activation = None,)self.loss_module = smp.losses.DiceLoss(mode="binary", smooth=config["loss_smooth"])self.val_step_outputs = []self.val_step_labels = []def forward(self, batch):imgs = batchpreds = self.model(imgs)return predsdef configure_optimizers(self):optimizer = AdamW(self.parameters(), **self.config["optimizer_params"])if self.config["scheduler"]["name"] == "CosineAnnealingLR":scheduler = CosineAnnealingLR(optimizer,**self.config["scheduler"]["params"]["CosineAnnealingLR"],)lr_scheduler_dict = {"scheduler": scheduler, "interval": "step"}return {"optimizer": optimizer, "lr_scheduler": lr_scheduler_dict}elif self.config["scheduler"]["name"] == "ReduceLROnPlateau":scheduler = ReduceLROnPlateau(optimizer,**self.config["scheduler"]["params"]["ReduceLROnPlateau"],)lr_scheduler = {"scheduler": scheduler, "monitor": "val_loss"}return {"optimizer": optimizer, "lr_scheduler": lr_scheduler}elif self.config["scheduler"]["name"] == "cosine_with_hard_restarts_schedule_with_warmup":scheduler = get_cosine_with_hard_restarts_schedule_with_warmup(optimizer,**self.config["scheduler"]["params"][self.config["scheduler"]["name"]],)lr_scheduler_dict = {"scheduler": scheduler, "interval": "step"}return {"optimizer": optimizer, "lr_scheduler": lr_scheduler_dict}def training_step(self, batch, batch_idx):imgs, labels = batchpreds = self.model(imgs)if self.config["image_size"] != 256:preds = torch.nn.functional.interpolate(preds, size=256, mode='bilinear')loss = self.loss_module(preds, labels)self.log("train_loss", loss, on_step=True, on_epoch=True, prog_bar=True, batch_size=16)for param_group in self.trainer.optimizers[0].param_groups:lr = param_group["lr"]self.log("lr", lr, on_step=True, on_epoch=False, prog_bar=True)return lossdef validation_step(self, batch, batch_idx):imgs, labels = batchpreds = self.model(imgs)if self.config["image_size"] != 256:preds = torch.nn.functional.interpolate(preds, size=256, mode='bilinear')loss = self.loss_module(preds, labels)self.log("val_loss", loss, on_step=False, on_epoch=True, prog_bar=True)self.val_step_outputs.append(preds)self.val_step_labels.append(labels)def on_validation_epoch_end(self):all_preds = torch.cat(self.val_step_outputs)all_labels = torch.cat(self.val_step_labels)all_preds = torch.sigmoid(all_preds)self.val_step_outputs.clear()self.val_step_labels.clear()val_dice = dice(all_preds, all_labels.long())self.log("val_dice", val_dice, on_step=False, on_epoch=True, prog_bar=True)if self.trainer.global_rank == 0:print(f"\nEpoch: {self.current_epoch}", flush=True)
这段代码定义了一个 PyTorch Lightning 模块 LightningModule,用于训练图像分割模型。
主要功能包括:
- 初始化:在初始化过程中,接收一个配置参数
config,用于配置模型的参数和优化器。 - 构建图像分割模型:根据配置中的
seg_model和encoder_name,从seg_models字典中选择合适的图像分割模型,并初始化该模型。 - 定义损失函数:使用
smp.losses.DiceLoss作为损失函数,并根据配置中的loss_smooth参数初始化 Dice Loss。 - 前向传播:在
forward方法中,接收一个批次的图像数据batch,将其输入模型中进行前向传播,并返回预测结果preds。 - 配置优化器和学习率调度器:通过
configure_optimizers方法配置优化器和学习率调度器。根据配置中的scheduler,选择对应的学习率调度器,例如CosineAnnealingLR、ReduceLROnPlateau或cosine_with_hard_restarts_schedule_with_warmup。 - 训练步骤:在
training_step方法中,接收一个批次的图像数据batch和批次索引batch_idx,执行模型的训练步骤。计算模型的预测结果preds和损失函数的值loss,并输出训练的损失值和学习率。 - 验证步骤:在
validation_step方法中,接收一个批次的图像数据batch和批次索引batch_idx,执行模型的验证步骤。计算模型的预测结果preds和损失函数的值loss,并输出验证的损失值。 - 验证轮结束时操作:在
on_validation_epoch_end方法中,进行每个验证轮结束后的操作。计算 Dice 指标,并打印当前的训练轮数。
该 LightningModule 类为图像分割任务提供了整体的训练和验证流程,包括模型的初始化、损失函数的定义、前向传播、优化器和学习率调度器的配置,以及训练和验证的具体步骤。它是 PyTorch Lightning 框架中的一个核心组件,可以大大简化训练过程,并提供了丰富的功能和回调函数来定制化训练过程。
初始化的步骤:
__init__方法:初始化函数,在创建类实例时被调用,用于定义模型的结构和其他初始化操作。config: 是一个字典,包含了模型的配置参数。model: 初始化语义分割模型,通过seg_models字典中指定的seg_model和encoder_name来选择特定的语义分割模型。loss_module: 定义了用于计算损失的 DiceLoss,参数mode="binary"表示计算二值分割的 Dice Loss。val_step_outputs和val_step_labels: 这是用于保存验证步骤中的模型输出和真实标签的列表,以便在validation_step方法中使用和跟踪验证指标。
接下来,这个 LightningModule 类还包含其他几个方法,用于实现模型的前向传播、优化器和学习率调度器的配置,以及训练和验证步骤的定义。
前向传播过程:
forward 方法定义了模型的前向传播过程。它接收一个批次的输入数据 batch,其中 batch 是一个包含图像数据的张量。在这里,imgs 表示输入的图像数据。
然后,self.model 表示定义的语义分割模型,根据 config["seg_model"] 和 config["encoder_name"] 来选择相应的模型结构。self.model 接收 imgs 作为输入,进行前向传播,得到预测的语义分割结果 preds。
最后,forward 方法返回预测结果 preds,这个结果将在训练过程中用于计算损失和优化模型。
配置优化器和学习率调度器:
在这个方法中,首先根据配置参数 self.config["optimizer_params"] 创建一个 AdamW 优化器对象 optimizer,其中使用了模型的参数 self.parameters()。
然后,根据配置参数 self.config["scheduler"]["name"] 来选择相应的学习率调度器。
- 如果选择的调度器是
CosineAnnealingLR,则创建一个 CosineAnnealingLR 调度器对象scheduler,并使用self.config["scheduler"]["params"]["CosineAnnealingLR"]中的参数来配置调度器。 - 如果选择的调度器是
ReduceLROnPlateau,则创建一个 ReduceLROnPlateau 调度器对象scheduler,并使用self.config["scheduler"]["params"]["ReduceLROnPlateau"]中的参数来配置调度器。 - 如果选择的调度器是
cosine_with_hard_restarts_schedule_with_warmup,则创建一个使用get_cosine_with_hard_restarts_schedule_with_warmup函数生成的调度器对象scheduler,并使用self.config["scheduler"]["params"][self.config["scheduler"]["name"]]中的参数来配置调度器。
最后,根据选择的调度器返回一个字典,其中包含了优化器和学习率调度器的配置信息。这样,在训练过程中,Lightning 就会自动地根据这些配置来进行优化和学习率调整。
在训练集上的一个前向传播和损失计算的步骤:
这个方法接收一个批次的输入数据 batch 和批次的索引 batch_idx。
首先,从输入批次 batch 中解包得到图像数据 imgs 和对应的标签 labels。然后,通过 self.model 对图像数据进行前向传播,得到预测的语义分割结果 preds。
如果配置中的 image_size 不等于 256,那么会对预测结果 preds 进行插值,将其调整为大小为 256x256 的分辨率。
接着,使用 self.loss_module 计算预测结果 preds 和真实标签 labels 之间的 Dice Loss。这里使用 Dice Loss 作为损失函数来度量预测结果和真实标签之间的相似度。
然后,通过 self.log 方法记录训练损失 train_loss,并设置 on_step=True 和 on_epoch=True,这样在训练过程中会每个步骤和每个 epoch 都打印损失,并显示在进度条中。
接下来,获取当前优化器的学习率 lr,并使用 self.log 方法记录学习率 lr,设置 on_step=True 和 on_epoch=False,这样在训练过程中会每个步骤打印学习率,并显示在进度条中。
最后,返回计算得到的损失值 loss,这个值将用于进行反向传播和模型的优化。
模型在验证集上的一个前向传播和损失计算的步骤:
这个方法接收一个批次的输入数据 batch 和批次的索引 batch_idx。
首先,从输入批次 batch 中解包得到图像数据 imgs 和对应的标签 labels。然后,通过 self.model 对图像数据进行前向传播,得到预测的语义分割结果 preds。
如果配置中的 image_size 不等于 256,那么会对预测结果 preds 进行插值,将其调整为大小为 256x256 的分辨率。
接着,使用 self.loss_module 计算预测结果 preds 和真实标签 labels 之间的 Dice Loss。这里使用 Dice Loss 作为损失函数来度量预测结果和真实标签之间的相似度。
然后,通过 self.log 方法记录验证损失 val_loss,设置 on_step=False 和 on_epoch=True,这样在每个 epoch 结束时打印验证损失,并显示在进度条中。
接下来,将预测结果 preds 和标签 labels 添加到列表 self.val_step_outputs 和 self.val_step_labels 中,这样在每个 epoch 结束时可以使用这些数据来计算整个验证集上的评估指标。
注意,这里没有返回任何值,因为在 Lightning 中,在验证阶段只需要计算验证指标,不需要进行反向传播和优化,因此不需要返回损失值。
完成了一个完整的验证阶段后进行的操作:
该方法在每个 epoch 结束时被调用,用于对整个验证集的预测结果进行评估和记录。
首先,将所有验证步骤中得到的预测结果 self.val_step_outputs 和标签 self.val_step_labels 拼接起来,形成一个完整的预测结果和对应的标签,分别存储在 all_preds 和 all_labels 中。
然后,对预测结果 all_preds 进行 sigmoid 函数的转换,将其转换为概率值在 0 到 1 之间。
接着,使用 torchmetrics.functional.dice 函数计算预测结果 all_preds 和真实标签 all_labels 之间的 Dice 系数。Dice 系数是用于评估语义分割任务的一种指标,用于衡量预测结果与真实标签之间的相似度。
接下来,通过 self.log 方法记录验证集上的 Dice 系数 val_dice,设置 on_step=False 和 on_epoch=True,这样在每个 epoch 结束时打印验证集上的 Dice 系数,并显示在进度条中。
最后,如果当前进程是全局排名为 0 的进程(通常是主进程),则打印当前 epoch 的信息,例如显示当前 epoch 的编号,这里使用 self.current_epoch 来获取当前的 epoch 编号,并使用 print 函数打印该信息。
# Actual training
import warnings
warnings.filterwarnings("ignore")
import gc
import os
import torch
import yaml
import pandas as pd
import pytorch_lightning as pl
from pytorch_lightning.callbacks import ModelCheckpoint, EarlyStopping, TQDMProgressBar
from torch.utils.data import DataLoader
from sklearn.model_selection import KFold
from pytorch_lightning.loggers import CSVLoggertorch.set_float32_matmul_precision("medium")
with open("config.yaml", "r") as file_obj:config = yaml.safe_load(file_obj)
pl.seed_everything(config["seed"])
gc.enable()
contrails = os.path.join(config["data_path"], "contrails/")
train_path = os.path.join(config["data_path"], "train_df.csv")
valid_path = os.path.join(config["data_path"], "valid_df.csv")train_df = pd.read_csv(train_path)
valid_df = pd.read_csv(valid_path)train_df["path"] = contrails + train_df["record_id"].astype(str) + ".npy"
valid_df["path"] = contrails + valid_df["record_id"].astype(str) + ".npy"df = pd.concat([train_df, valid_df]).reset_index()Fold = KFold(shuffle=True, **config["folds"])
for n, (trn_index, val_index) in enumerate(Fold.split(df)):df.loc[val_index, "kfold"] = int(n)
df["kfold"] = df["kfold"].astype(int)for fold in config["train_folds"]:print(f"\n###### Fold {fold}")trn_df = df[df.kfold != fold].reset_index(drop=True)vld_df = df[df.kfold == fold].reset_index(drop=True)dataset_train = ContrailsDataset(trn_df, config["model"]["image_size"], train=True)dataset_validation = ContrailsDataset(vld_df, config["model"]["image_size"], train=False)data_loader_train = DataLoader(dataset_train,batch_size=config["train_bs"],shuffle=True,num_workers=config["workers"],)data_loader_validation = DataLoader(dataset_validation,batch_size=config["valid_bs"],shuffle=False,num_workers=config["workers"],)checkpoint_callback = ModelCheckpoint(save_weights_only=True,monitor="val_dice",dirpath=config["output_dir"],mode="max",filename=f"model-f{fold}-{{val_dice:.4f}}",save_top_k=1,verbose=1,)progress_bar_callback = TQDMProgressBar(refresh_rate=config["progress_bar_refresh_rate"])early_stop_callback = EarlyStopping(**config["early_stop"])trainer = pl.Trainer(callbacks=[checkpoint_callback, early_stop_callback, progress_bar_callback],logger=CSVLogger(save_dir=f'logs_f{fold}/'),**config["trainer"],)model = LightningModule(config["model"])trainer.fit(model, data_loader_train, data_loader_validation)del (dataset_train,dataset_validation,data_loader_train,data_loader_validation,model,trainer,checkpoint_callback,progress_bar_callback,early_stop_callback,)torch.cuda.empty_cache()gc.collect()
这段代码实际上是执行图像分割模型的训练过程。它使用了 PyTorch Lightning 框架来简化训练过程,并采用 K 折交叉验证的方式来训练多个模型。
主要步骤如下:
- 读取配置文件:首先,代码通过读取 “config.yaml” 配置文件来加载训练的参数设置。
- 数据准备:代码读取数据集文件并构建训练集和验证集的数据帧(DataFrame)。然后,根据 K 折交叉验证的要求,将数据划分为 K 份,其中 (K-1) 份作为训练集,1 份作为验证集。
- 开始训练:通过
for循环,对每个折(fold)进行训练。 - 构建数据集和数据加载器:对于每个折,代码通过构建
ContrailsDataset数据集类和数据加载器来加载训练和验证数据。将数据集传递给数据加载器,以便进行批量数据加载。 - 配置回调函数:为训练过程配置回调函数,包括模型保存回调、早停回调和进度条回调。这些回调函数在训练过程中会根据设定的条件执行相应的操作。
- 配置
pl.Trainer:通过配置pl.Trainer类,指定训练过程中的一些设置,例如使用的 GPU 数量、最大训练周期数、最小训练周期数等。 - 创建
LightningModule模型:创建一个LightningModule模型,将配置文件中的参数传递给模型。 - 训练模型:使用
trainer.fit方法进行模型的训练。在训练过程中,模型会自动执行前向传播、反向传播、优化器更新等操作。 - 清理资源:每完成一个折的训练后,代码会释放一些资源,如数据集、数据加载器、模型、回调函数等,以便于下一个折的训练。
整个训练过程会持续多个周期,每个周期(epoch)会对训练集进行迭代训练,然后在验证集上进行验证,并根据验证结果选择是否早停或保存模型。最终,通过多次 K 折交叉验证,可以得到多个训练好的模型,并从中选择最好的模型进行后续使用。
import seaborn as sn
import matplotlib.pyplot as pltfor fold in config["train_folds"]:metrics = pd.read_csv(f"/kaggle/working/logs_f{fold}/lightning_logs/version_0/metrics.csv")del metrics["step"]del metrics["lr"]del metrics["train_loss_step"]metrics.set_index("epoch", inplace=True)g = sn.relplot(data=metrics, kind="line")plt.title(f"Fold {fold}")plt.gcf().set_size_inches(15, 5)plt.grid()plt.show()
这段代码用于绘制图像分割模型训练过程中的一些指标随着训练周期的变化情况。它通过读取每个折(fold)的训练日志文件,提取相应的指标数据,并使用 seaborn 和 matplotlib 库进行可视化。
主要步骤如下:
- 通过
for循环遍历每个折(fold)。 - 读取训练日志:使用
pd.read_csv读取每个折训练的日志文件,该日志文件保存了训练过程中的指标数据。 - 数据预处理:删除不需要的列,并将 “epoch” 列设置为数据帧的索引,以便后续绘图。
- 绘制折(fold)的指标曲线:使用
sn.relplot绘制每个折的指标随着训练周期的变化情况。这里使用了 seaborn 中的relplot函数来绘制折线图。 - 设置图像属性:设置图像的标题、尺寸和网格等属性。
- 显示图像:使用
plt.show()显示绘制好的图像。
通过以上步骤,代码将绘制每个折的训练过程中指标的变化曲线,以便观察模型的训练情况、收敛性和性能。这样的可视化有助于了解训练的进展情况,并可以发现模型是否过拟合或欠拟合,以及在哪些周期达到了最佳性能等信息。
6.2 Submission part
import warnings
warnings.filterwarnings("ignore")
import gc
import os
import glob
import numpy as np
import pandas as pd
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
import pytorch_lightning as pl
import torchvision.transforms as T
import yaml
这段代码导入了一系列的 Python 库和模块,用于进行图像分割任务的实验和开发。
具体的导入内容包括:
warnings:用于忽略警告信息,以便在实验过程中不显示警告。gc:Python 的垃圾回收模块,用于处理内存管理和垃圾回收。os:用于与操作系统进行交互,比如文件路径的操作和系统命令的执行。glob:用于查找符合特定规则的文件路径。numpy:用于处理数值计算和数组操作。pandas:用于数据处理和分析,特别是用于处理结构化数据,如 DataFrame。torch:PyTorch 深度学习框架的核心模块。torch.nn:PyTorch 中的神经网络模块,包含各种层和损失函数。Dataset和DataLoader:PyTorch 中用于处理数据的模块,用于加载数据集并构建数据加载器。pytorch_lightning:PyTorch Lightning 是一个轻量级的 PyTorch 框架扩展,用于简化深度学习的训练和开发流程。torchvision.transforms:用于定义图像数据的预处理和数据增强的模块。yaml:用于读取和解析 YAML 格式的配置文件。
这些导入语句为后续的图像分割任务实验提供了必要的基础库和模块,可以方便地进行数据处理、模型定义、训练和验证等操作。同时,通过 PyTorch Lightning 的使用,还能进一步简化训练流程,并提供丰富的功能和回调函数来进行定制化的实验和调试。
batch_size = 32
num_workers = 1
THR = 0.5
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
data = '/kaggle/input/google-research-identify-contrails-reduce-global-warming'
data_root = '/kaggle/input/google-research-identify-contrails-reduce-global-warming/test/'
submission = pd.read_csv(os.path.join(data, 'sample_submission.csv'), index_col='record_id')
这段代码设置了一些变量和路径,为进行图像分割任务的预测和提交结果做准备。
具体的设置包括:
batch_size = 32:定义每个批次中的样本数量。num_workers = 1:定义数据加载器的工作线程数量。THR = 0.5:定义一个阈值(threshold),用于在进行预测时对模型输出进行二值化,以得到最终的分割结果。device:定义计算设备,如果可用,则使用 CUDA 加速,否则使用 CPU 进行计算。data:设置数据集的根路径,此处指向 “/kaggle/input/google-research-identify-contrails-reduce-global-warming”,该路径可能包含训练集和测试集等数据。data_root:设置测试集数据的路径,指向 “/kaggle/input/google-research-identify-contrails-reduce-global-warming/test/”,该路径是测试集数据存放的目录。submission:读取测试集的样本提交文件 “sample_submission.csv”,并将 “record_id” 列作为数据帧的索引,该文件用于提交最终的预测结果。
通过上述设置,代码为后续的测试数据加载、模型预测和结果提交做好了准备。具体的预测和提交过程可能会在后续的代码中进行。
filenames = os.listdir(data_root)
test_df = pd.DataFrame(filenames, columns = ['record_id'])
test_df['path'] = data_root + test_df['record_id'].astype(str)
这段代码用于构建测试集的数据帧(DataFrame),以便在进行图像分割模型的预测时使用。
具体步骤如下:
- 使用
os.listdir(data_root)获取测试集数据目录data_root中的所有文件名列表filenames。os.listdir()函数会返回指定目录下的所有文件和子目录的名称。 - 创建一个新的数据帧
test_df,并将filenames列表作为一列 “record_id” 加入数据帧。 - 构建 “path” 列:将 “record_id” 列中的每个文件名转换为完整的文件路径,并添加为 “path” 列。这样,“path” 列中保存了测试集数据文件的完整路径。
通过以上步骤,代码将测试集数据的文件名和完整路径保存在数据帧 test_df 中,方便后续加载数据和进行模型的预测。每行数据表示测试集中的一个样本,其中 “record_id” 列保存了样本的文件名,“path” 列保存了样本的完整文件路径。
class ContrailsDataset(torch.utils.data.Dataset):def __init__(self, df, image_size=256, train=True):self.df = dfself.trn = trainself.df_idx: pd.DataFrame = pd.DataFrame({'idx': os.listdir(f'/kaggle/input/google-research-identify-contrails-reduce-global-warming/test')})self.normalize_image = T.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))self.image_size = image_sizeif image_size != 256:self.resize_image = T.transforms.Resize(image_size)def read_record(self, directory):record_data = {}for x in ["band_11", "band_14", "band_15"]:record_data[x] = np.load(os.path.join(directory, x + ".npy"))return record_datadef normalize_range(self, data, bounds):"""Maps data to the range [0, 1]."""return (data - bounds[0]) / (bounds[1] - bounds[0])def get_false_color(self, record_data):_T11_BOUNDS = (243, 303)_CLOUD_TOP_TDIFF_BOUNDS = (-4, 5)_TDIFF_BOUNDS = (-4, 2)N_TIMES_BEFORE = 4r = self.normalize_range(record_data["band_15"] - record_data["band_14"], _TDIFF_BOUNDS)g = self.normalize_range(record_data["band_14"] - record_data["band_11"], _CLOUD_TOP_TDIFF_BOUNDS)b = self.normalize_range(record_data["band_14"], _T11_BOUNDS)false_color = np.clip(np.stack([r, g, b], axis=2), 0, 1)img = false_color[..., N_TIMES_BEFORE]return imgdef __getitem__(self, index):row = self.df.iloc[index]con_path = row.pathdata = self.read_record(con_path) img = self.get_false_color(data)img = torch.tensor(np.reshape(img, (256, 256, 3))).to(torch.float32).permute(2, 0, 1)if self.image_size != 256:img = self.resize_image(img) img = self.normalize_image(img)image_id = int(self.df_idx.iloc[index]['idx']) return img.float(), torch.tensor(image_id)def __len__(self):return len(self.df)
这是一个名为 ContrailsDataset 的 PyTorch 数据集类,用于处理图像分割任务中的数据加载和预处理。
类中包含以下方法:
__init__(self, df, image_size=256, train=True):初始化方法,用于指定数据集的相关设置和参数。df是包含样本信息的数据帧,image_size是图像的尺寸,默认为 256,train是一个布尔值,用于标识是否是训练集,如果为 True,则表示是训练集,否则表示是测试集。read_record(self, directory):用于从指定目录directory读取记录数据。这个方法从不同文件中加载 “band_11”、“band_14” 和 “band_15” 数据,然后返回这些数据组成的字典。normalize_range(self, data, bounds):用于将数据映射到指定范围 [0, 1] 的方法。data是要映射的数据,bounds是目标范围的上下界。get_false_color(self, record_data):用于生成伪彩色图像的方法。该方法从记录数据字典record_data中获取 “band_11”、“band_14” 和 “band_15” 数据,并通过归一化和组合生成伪彩色图像。__getitem__(self, index):用于获取数据集中特定索引处的数据样本。根据索引index,读取数据帧df中对应的样本信息,调用read_record方法读取记录数据,并通过get_false_color方法生成伪彩色图像。然后,对图像进行大小调整、标准化处理,并返回图像和样本的 ID。__len__(self):用于获取数据集的长度,即样本的数量。
通过这个自定义的数据集类,可以方便地加载数据、对图像进行预处理,并在训练和预测过程中使用 PyTorch 的数据加载器来加载批次数据。这样,可以方便地将数据送入模型进行训练和推理。
get_false_color 方法用于生成伪彩色图像,主要是通过计算不同波段之间的像元值差异来构造一张伪彩色图像。在这里,该方法接受一个包含多个波段数据的字典 record_data 作为输入,然后根据不同波段之间的范围进行归一化,构造伪彩色图像并返回。
具体的步骤如下:
_T11_BOUNDS、_CLOUD_TOP_TDIFF_BOUNDS和_TDIFF_BOUNDS是用来指定不同波段的范围。这些值用于将不同波段数据映射到 [0, 1] 范围内。N_TIMES_BEFORE是一个常量,用于指定取伪彩色图像的哪个时间点。在这里,根据img = false_color[..., N_TIMES_BEFORE]选择取第 N_TIMES_BEFORE 个时间点的伪彩色图像。r、g和b是分别对应于红、绿、蓝通道的像素值。计算这些通道的方法是通过对不同波段之间的像元值进行差异计算,然后将差异值映射到指定的范围内。- 使用
np.clip函数将归一化后的像素值限制在 [0, 1] 范围内,然后通过np.stack函数将三个通道的像素值堆叠在一起,构成一张伪彩色图像false_color。 - 最后,根据选定的时间点
N_TIMES_BEFORE,从false_color中提取出对应时间点的伪彩色图像img并返回。
这样,get_false_color 方法可以根据给定的波段数据构造一张伪彩色图像,用于在深度学习模型中进行处理和训练。
def rle_encode(x, fg_val=1):"""Args:x: numpy array of shape (height, width), 1 - mask, 0 - backgroundReturns: run length encoding as list"""dots = np.where(x.T.flatten() == fg_val)[0] # .T sets Fortran order down-then-rightrun_lengths = []prev = -2for b in dots:if b > prev + 1:run_lengths.extend((b + 1, 0))run_lengths[-1] += 1prev = breturn run_lengthsdef list_to_string(x):"""Converts list to a string representationEmpty list returns '-'"""if x: # non-empty lists = str(x).replace("[", "").replace("]", "").replace(",", "")else:s = '-'return s
这段代码定义了两个辅助函数 rle_encode 和 list_to_string,用于对图像分割结果进行 Run Length Encoding (RLE) 编码和字符串转换的操作。
rle_encode(x, fg_val=1):该函数用于对图像进行 RLE 编码。输入参数x是一个 NumPy 数组,表示一个二值化的图像掩码(mask),其中 1 表示目标区域(前景),0 表示背景区域。函数会将前景区域的像素位置编码成一串 RLE 格式的列表,返回的是一个包含像素位置和长度的列表。这个编码方法常用于图像分割任务的结果提交,以便减少提交文件的大小和计算量。list_to_string(x):该函数用于将列表转换为字符串表示。输入参数x是一个列表,函数会将列表转换为一个不包含方括号和逗号的字符串表示。如果列表为空,则返回'-'字符串。这个函数在对 RLE 编码结果进行字符串表示时很有用,方便保存到提交文件或其他输出中。
通过使用这两个辅助函数,可以将图像分割结果进行编码和转换为指定格式的字符串表示,方便提交预测结果或保存到文件中。这在进行图像分割任务的评估和结果输出时非常有用。
class LightningModule(pl.LightningModule):def __init__(self, config):super().__init__()self.model = smp.Unet(encoder_name=config["encoder_name"],encoder_weights=None,in_channels=3,classes=1,activation=None,)def forward(self, batch):return self.model(batch)
这是一个 PyTorch Lightning 的子类 LightningModule,它定义了一个简单的图像分割模型。
该类包含以下方法:
__init__(self, config):初始化方法,接受一个配置字典config,并使用该配置创建 Unet 模型。encoder_name指定了使用的编码器名称,encoder_weights为 None 表示不使用预训练权重,in_channels=3表示输入图像的通道数为 3(RGB 彩色图像),classes=1表示输出的通道数为 1(二值化的分割掩码),activation=None表示不使用激活函数。forward(self, batch):前向传播方法,接受一个批次的图像batch,并将其传递给 Unet 模型进行前向计算,返回模型的输出。
该类继承了 PyTorch Lightning 的 pl.LightningModule,因此它具有 Lightning 模型所需的必要功能,如 training_step、validation_step、configure_optimizers 等方法。在实际的训练和验证过程中,可以使用此 Lightning 模型类,以更简洁的方式定义和管理模型,并进行训练和推理。
MODEL_PATH = "/kaggle/working/models/"
#with open(os.path.join(MODEL_PATH, "config.yaml"), "r") as file_obj:
# config = yaml.safe_load(file_obj)
test_ds = ContrailsDataset(test_df,config["model"]["image_size"],train = False)
test_dl = DataLoader(test_ds, batch_size=batch_size, num_workers = num_workers)
这部分代码用于创建测试集的数据加载器(DataLoader),以便在模型推理(预测)阶段使用。
ContrailsDataset是之前定义的用于加载测试数据的自定义数据集类,通过传入测试数据的信息test_df和其他相关参数,创建了test_ds对象。test_ds:是通过ContrailsDataset类创建的测试数据集对象,用于加载测试集的图像数据并进行预处理。config["model"]["image_size"]:通过访问配置字典config中的 “model” 部分,并获取 “image_size” 参数的值,即测试数据的图像尺寸。train=False:将train参数设为 False,表示test_ds是测试数据集,以便在数据集类中进行相应处理。DataLoader是 PyTorch 提供的数据加载器,用于批量加载数据。通过传入test_ds数据集对象、batch_size和num_workers参数,创建了test_dl数据加载器。batch_size=batch_size:指定每个批次中的样本数量,这里使用之前设定的batch_size值。num_workers=num_workers:指定数据加载器的工作线程数量,这里使用之前设定的num_workers值。
通过创建测试数据加载器 test_dl,我们可以方便地批量加载测试数据,然后将数据输入到模型进行预测,最终得到测试集的分割结果。
gc.enable()
all_preds = {}for i, model_path in enumerate(glob.glob(MODEL_PATH + '*.ckpt')):print(model_path)model = LightningModule(config["model"]).load_from_checkpoint(model_path, config=config["model"])model.to(device)model.eval()model_preds = {}for _, data in enumerate(test_dl):images, image_id = dataimages = images.to(device)with torch.no_grad():predicted_mask = model(images[:, :, :, :])if config["model"]["image_size"] != 256:predicted_mask = torch.nn.functional.interpolate(predicted_mask, size=256, mode='bilinear')predicted_mask = torch.sigmoid(predicted_mask).cpu().detach().numpy() for img_num in range(0, images.shape[0]):current_mask = predicted_mask[img_num, :, :, :]current_image_id = image_id[img_num].item()model_preds[current_image_id] = current_maskall_preds[f"f{i}"] = model_predsdel model torch.cuda.empty_cache()gc.collect()
这段代码使用已经训练好的多个模型对测试集进行预测,并将预测结果保存在 all_preds 字典中。
gc.enable():启用 Python 的垃圾回收,这有助于及时释放不再使用的内存。all_preds = {}:创建一个空字典all_preds,用于存储所有模型的预测结果。for i, model_path in enumerate(glob.glob(MODEL_PATH + '*.ckpt'))::使用glob.glob()函数获取所有以 “.ckpt” 结尾的文件路径,即训练好的模型的路径。然后,通过循环遍历所有的模型文件。model = LightningModule(config["model"]).load_from_checkpoint(model_path, config=config["model"]):加载指定路径model_path的训练好的模型,并根据配置config["model"]创建 Lightning 模型。这里使用.load_from_checkpoint()方法来加载模型。model.to(device):将模型移动到指定的计算设备device(GPU 或 CPU)上。model.eval():将模型设置为评估模式,即关闭 BatchNormalization 和 Dropout 层,以便在推理阶段保持一致的行为。model_preds = {}:创建一个空字典model_preds,用于存储当前模型的预测结果。for _, data in enumerate(test_dl)::使用test_dl数据加载器循环遍历测试集的数据。images, image_id = data:从test_dl中获取当前批次的图像数据images和图像 IDimage_id。images = images.to(device):将图像数据移动到指定的计算设备上。with torch.no_grad()::使用torch.no_grad()上下文管理器,关闭梯度计算,加速推理过程。predicted_mask = model(images[:, :, :, :]):对图像进行预测,得到模型输出predicted_mask。if config["model"]["image_size"] != 256::根据配置中的图像尺寸,对模型输出进行大小调整。predicted_mask = torch.sigmoid(predicted_mask).cpu().detach().numpy():将模型输出进行sigmoid激活,并将结果转换为NumPy数组。这里得到了每个图像的预测掩码。for img_num in range(0, images.shape[0])::遍历当前批次中的每张图像。current_mask = predicted_mask[img_num, :, :, :]:获取当前图像的预测掩码。current_image_id = image_id[img_num].item():获取当前图像的图像 ID。model_preds[current_image_id] = current_mask:将当前图像的预测掩码加入model_preds字典中,以图像 ID 为键,掩码为值。all_preds[f"f{i}"] = model_preds:将当前模型的预测结果加入all_preds字典中,以模型编号f{i}为键,当前模型的预测结果为值。del model、torch.cuda.empty_cache()和gc.collect():释放模型占用的内存并进行垃圾回收,以便在下一次循环中使用新的模型。
通过上述循环,代码对测试集中的所有图像使用多个训练好的模型进行预测,并将每个模型的预测结果保存在 all_preds 字典中。每个模型的预测结果都是一个字典,其中每个图像 ID 对应一个预测掩码,即每张图像的分割预测结果。
for index in submission.index.tolist():for i in range(len(glob.glob(MODEL_PATH + '*.ckpt'))):if i == 0:predicted_mask = all_preds[f"f{i}"][index]else:predicted_mask += all_preds[f"f{i}"][index]predicted_mask = predicted_mask / len(glob.glob(MODEL_PATH + '*.ckpt'))predicted_mask_with_threshold = np.zeros((256, 256))predicted_mask_with_threshold[predicted_mask[0, :, :] < THR] = 0predicted_mask_with_threshold[predicted_mask[0, :, :] > THR] = 1submission.loc[int(index), 'encoded_pixels'] = list_to_string(rle_encode(predicted_mask_with_threshold))
这段代码使用多个模型的预测结果来生成提交文件的 Run Length Encoding (RLE) 编码。
for index in submission.index.tolist()::对提交文件中的每个图像 ID 进行遍历。for i in range(len(glob.glob(MODEL_PATH + '*.ckpt')))::遍历之前训练好的多个模型的索引i。if i == 0::如果是第一个模型的索引,将预测掩码初始化为all_preds[f"f{i}"][index]。else::对于其他模型的索引,将预测掩码累加上all_preds[f"f{i}"][index],以获得多个模型的预测结果之和。predicted_mask = predicted_mask / len(glob.glob(MODEL_PATH + '*.ckpt')):将预测掩码除以模型的总数,以得到平均预测结果。predicted_mask_with_threshold = np.zeros((256, 256)):创建一个大小为 (256, 256) 的全零数组,用于存储阈值化后的预测结果。predicted_mask_with_threshold[predicted_mask[0, :, :] < THR] = 0和predicted_mask_with_threshold[predicted_mask[0, :, :] > THR] = 1:根据阈值THR,将预测掩码中小于阈值的像素设置为0,大于阈值的像素设置为1,得到二值化的分割结果。submission.loc[int(index), 'encoded_pixels'] = list_to_string(rle_encode(predicted_mask_with_threshold)):使用 RLE 编码函数对二值化的分割结果进行编码,并将编码后的结果保存在提交文件的相应行中。
通过上述步骤,代码将使用多个模型的预测结果进行投票或平均,然后根据阈值 THR 进行二值化处理,并最终将结果保存在提交文件中,用于在 Kaggle 上提交图像分割任务的预测结果。




![SSM(Vue3+ElementPlus+Axios+SSM前后端分离)--功能实现[五]](https://img-blog.csdnimg.cn/img_convert/03f3626d0f23d9487a6dbe9c6ade6cda.png)