引言
本文主要关注生成式闲聊对话系统的进阶技术。
基于Transformer的对话生成模型
本节主要介绍GPT系列文章,这是由OpenAI团队推出的,现在大火的ChatGPT也是它们推出的。
GPT : Improving Language Understanding by Generative Pre-Traini ng
在自然语言理解中有很多不同的任务,虽然我们有很多无标签文本文件,但是有标签的文本相对较少。使得难以在这些少量的数据集上训练出具有分辨能力的模型。
GPT的解决方法是现在无标签数据上训练一个预训练语言模型,然后在子任务上训练一个具有分辨能力的微调模型。这就是预训练+微调范式,当时在NLP还是比较新颖的。在微调的时候构建和任务相关的数据,仅需要稍微调整模型的架构。
作者在使用无标签数据的时候遇到了两个困难:1)不知道使用怎样的优化目标函数 2)如何有效地把学到的文本表示传递到下游子任务上。GPT提出使用半监督的方法,在无监督的文本上面训练大的语言模型,然后在子任务上进行微调。后来人们称这种方法为自监督学习。
GPT使用了基于Transformer的架构,因为作者发现该模型在迁移学习的时候学到的特征更加稳健一些。在迁移的时候使用了和任务相关的表示。
那么如何在无标签文本上做预训练呢?给定一个无标签数据集 U = { μ 1 , ⋯ , μ n } \mathcal{U} =\{\mu_1,\cdots, \mu_n\} U={μ1,⋯,μn},使用一个标准的语言模型任务去最大化下面的似然:
L 1 ( U ) = ∑ i log P ( μ i ∣ μ i − k , ⋯ , μ i − 1 ; Θ ) L_1(\mathcal{U}) = \sum_i \log P(\mu_i|\mu_{i-k},\cdots,\mu_{i-1};\Theta) L1(U)=i∑logP(μi∣μi−k,⋯,μi−1;Θ)
即根据前面的 k k k个连续toke去预测当前的token。具体用到的是Transformer解码器:
h 0 = U W e + W p h l = transformer_block ( h l − 1 ) ∀ i ∈ [ 1 , n ] P ( u ) = softmax ( h n W e T ) h_0= UW_e + W_p\\ h_l = \text{transformer\_block}(h_{l-1}) \forall i \in [1,n] \\ P(u) = \text{softmax}(h_nW_e^T) h0=UWe+Wphl=transformer_block(hl−1)∀i∈[1,n]P(u)=softmax(hnWeT)
这里 U = ( u − k , ⋯ , u − 1 ) U=(u_{-k},\cdots,u_{-1}) U=(u−k,⋯,u−1)是token的上下文向量; n n n是层数; W e W_e We是token嵌入矩阵; W p W_p Wp是位置嵌入矩阵。
基于前面的一段话来预测后面的token任务比BERT中的完形填空要难。这导致GPT在训练和效果上比BERT要差一些。反过来说,如果你的模型能较好地完成预测token任务的话,那么效果也会比BERT要强大很多。这也是我们在更大的模型,更多的数据集上训练的GPT3看到的。
那么如何进行微调呢?
在用上面的目标函数训练好模型后,将模型的参数迁移到目标任务。此时的数据集是有标号的,假设数据集为 C \mathcal{C} C,每个包含一个输入token序列 x 1 , ⋯ , x m x^1,\cdots,x^m x1,⋯,xm,以及对应的标签 y y y。将该输入喂给我们的预训练模型得到最终的transformer块的表示 h l m h_l^m hlm,将它喂给一个额外的线性层来预测 y y y:
P ( y ∣ x 1 , ⋯ , x m ) = softmax ( h l m W y ) P(y|x^1,\cdots,x^m)=\text{softmax}(h^m_l W_y) P(y∣x1,⋯,xm)=softmax(hlmWy)
基于下面的目标函数去优化:
L 2 ( C ) = ∑ ( x , y ) log P ( y ∣ x 1 , ⋯ , x m ) L_2(\mathcal{C}) = \sum_{(x,y)} \log P(y|x^1,\cdots,x^m) L2(C)=(x,y)∑logP(y∣x1,⋯,xm)
如果把这两个目标函数一起训练效果是最好的:
L 3 ( C ) = L 2 ( C ) + λ ∗ L 1 ( C ) L_3(\mathcal{C}) = L_2(\mathcal{C}) + \lambda * L_1(\mathcal{C}) L3(C)=L2(C)+λ∗L1(C)
下面的问题是如何把下游任务表示成序列和对应的标号。
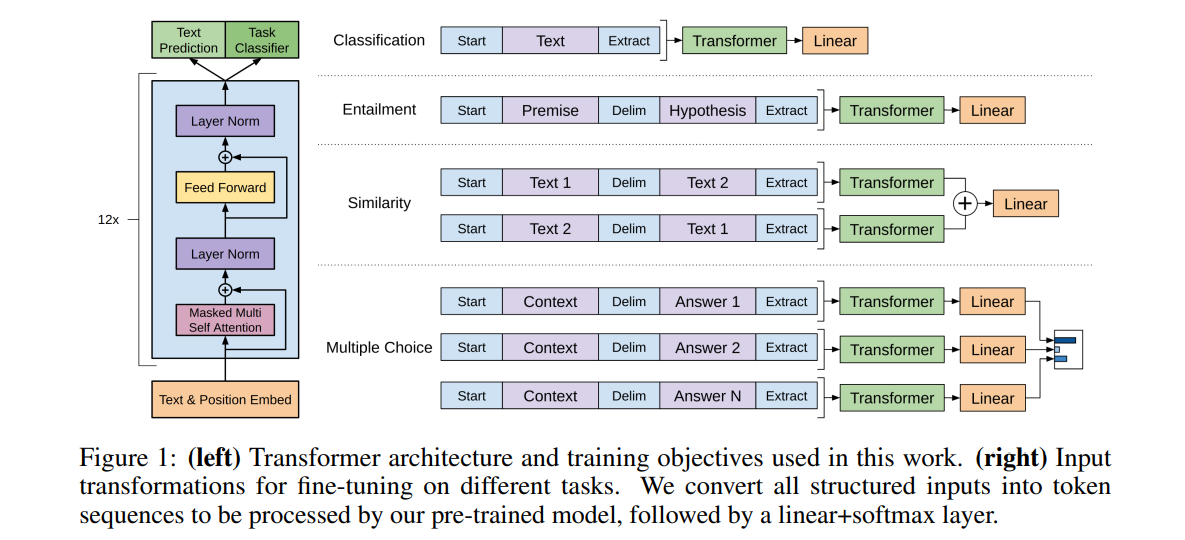
上图是NLP四大常见应用。
- 分类任务
- 把要分类的文本放到开始token和抽取token之间,拼接成一个序列
- 该输入喂给Transformer的解码器,得到最后一个抽取token的特征
- 放到一个线性层中进行分类
- 蕴含任务:给定一段话(前提)和一个假设,判断这段话有没有蕴含(支持)假设
- 实际上有三个结果:支持、反对、既不支持也不反对
- 把前提和假设用分隔符token拼接成一段话放到开始token和抽取token之间
- 后面的做法和分类任务一样,这里的类别只有三个
- 文本相似度:搜索词和文档/文档和文档是否相似
- 虽然相似是对称的,但在语言中是有先后顺序的,所以这里用了两个序列
- 和蕴含任务结构类似,第一个序列将文本1放到文本2之前;第二个反之
- 分别喂给Transformer,得到的输出表示进行求和
- 最后喂给一个线性层得到一个二分类架构
- 多项选择:给定问题(上下文)和多个答案,从中选择出正确的答案
- 类似蕴含的架构,有N个答案就构建N个序列
- 问题放在前面,答案放在后面
- 分别喂给Transformer
- 然后接一个输出大小为1的线性层,得到答案的置信度
可以看到这种任务中,虽然输入和输出的架构有些不同,但中间的Transformer还是一样的。
GPT-2 : Language Models are Unsupervised Multitask Learners
当GPT发表后不久,BERT就问世了,并且更大的模型(3.5亿参数)BERT把GPT当成了背景板。
GPT2对此做出了回应,它的标题是语言模型就是无监督多任务学习器。
GPT2做了一个更大的百万级文本的WebText数据集,然后训练了一个15亿参数的模型。但可惜的是和BERT对比优势并没有那么大。因此作者提出了zero-shot(零样本)这个新的角度(优势)。
当时NLP主流的做法是在对一个任务收集一个数据集,然后训练模型做预测。因此当时的模型泛化性不好,在一个数据集一个任务上训练好的模型很难直接用到下一个模型上面。
之前的预训练+微调的范式虽然好用,但对于每个下游任务还是需要重新去训练你的模型。而GPT-2能做到的是零样本学习,即在应用到下游任务时,不需要任何训练。在这种设定下,得到了一个看起来还不错的结果。
回忆一下GPT,在预训练的时候是在自然的文本上训练的,但在做下游任务时,对输入结构进行了修改,加入了一些特殊字符。这些符号是之前预训练模型没有见到过的,通过微调的环节让模型去认识这些符号。在零样本的前提下,模型不能再被微调了,如果还引入一些模型没见过的符号,效果得不到保障。那么此时构建下游任务的输入时,输入的形式应该要和之前模型看到的一样,即输入应该更像自然语言。
这里作者给了两个例子,一个是机器翻译,假如想把英语翻译成法语,那么要写成 (translate to french, english text, french text)。先是翻译成法语,然后是英语对应的文本,最后可以得到法语对应的文本。前面的这三个词translate to french后来被称为提示(prompt)。另一个例子是阅读理解,(answer the question, document,question, answer)。这里给的提示是answer the question,后面接文档和问题,最后模型生成回答。
作者抓取了Reddit这个新闻聚合网页,每个人都可以提交新闻,然后被分类,接着每个用户都可以投票(喜欢/不喜欢),还可以进行评论。作者爬取了喜欢票居多的新闻链接,得到了40GB的文本。
作者在表1中暂时,爬下来的文本中,对于英语翻译法语,其实也有很多样例。默认是英文文本,后面的In French接翻译后的法语文本。这可能是为什么零样本有效的一种解释。

当有了更大的数据集就可以把模型做得更大。
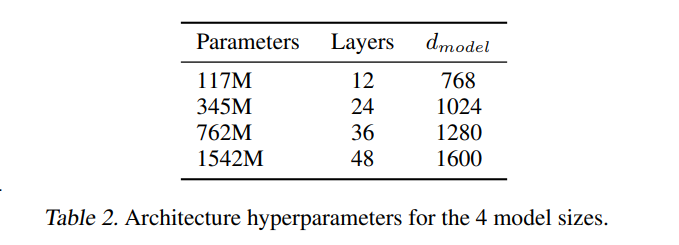
最大的有15亿参数量48层的超大模型。
GPT3 : Language Models are Few-Shot Learners
作者从GPT-2中看到了一种趋势,模型参数量和模型的表现几乎是一种线性增长关系。
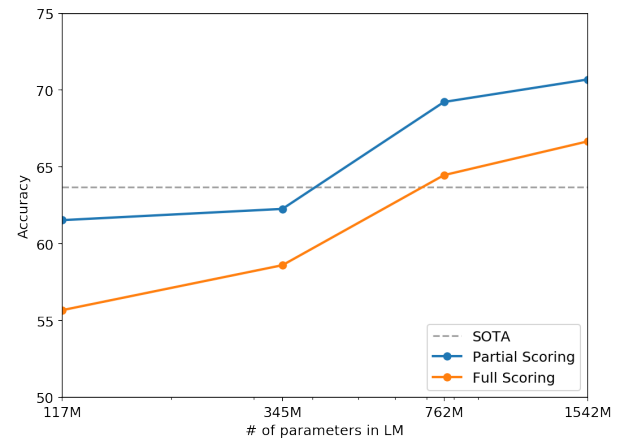
那么GPT-3就基于这样的思想,训练了一个更大的模型,同时考虑到GPT-2的有效性一般,作者又回到GPT-1考虑的few-shot少样本设置,不再追求极致的零样本。
GPT-3有1750亿个可学习的参数,在基于少量(10-100个)样本的情况下,GPT-3也不是通过微调的方式,因为参数量太大。
GPT-3考虑了三种设定下的表现:
- 少样本
- 1样本(仅1个样本)
- 零样本
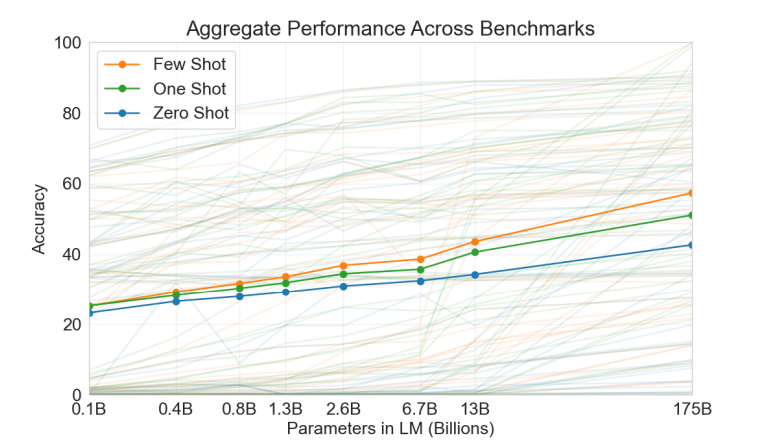
横轴表示参数量,比如1.3B可以认为是GPT-2,而175B对应的是GPT-3;纵轴表示准确率。
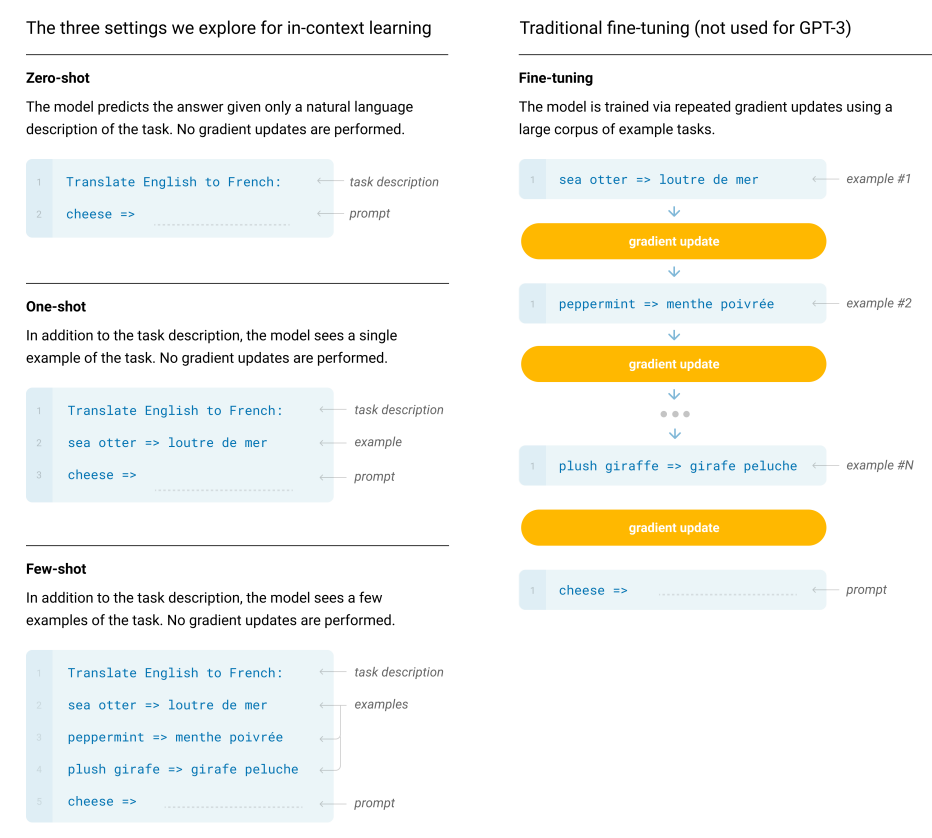
作者还给出了这三种设定下英语翻译法语的例子。在零样本学习中,给出任务描述,再加一个要翻译的文本,这里是cheeze,再加一个箭头=>(提示,prompt),就让模型生成翻译的结果。
在1样本情况下,和零样本相比,插入了一个样本(sea otter => loutre de mer)。希望模型看到这个样本后能提取出有用的信息来帮你做后面的翻译。这里要注意的是,虽然放入了一个训练样本,但只做预测,不做训练。即也不会计算梯度更新模型的参数。这也是为什么作者称为上下文学习(in-context learning),即学习只是限定于你的上下文。
那么少样本就是多1样本的拓展,在少样本中给出了多个样本,而不只是一个。
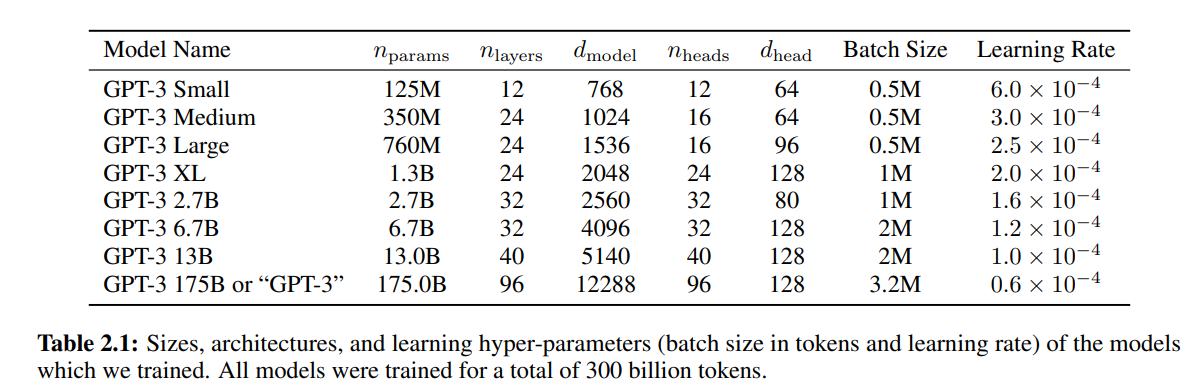
GPT-3模型架构和GPT-2是一样的,GPT-2对比GPT-1的改动类似Sparse Transformer做的工作,比如修改了初始化,pre-normalization,反转了token。
在推理(评估)时用到的提示是Answer: 或A:。
融合检索和生成的闲聊对话系统
我们知道检索和闲聊各有利弊,能否结合它们两的优点得到一个可控且带有随机性的对话系统呢。下面我们来看一种尝试。
Retrieval augmented generation
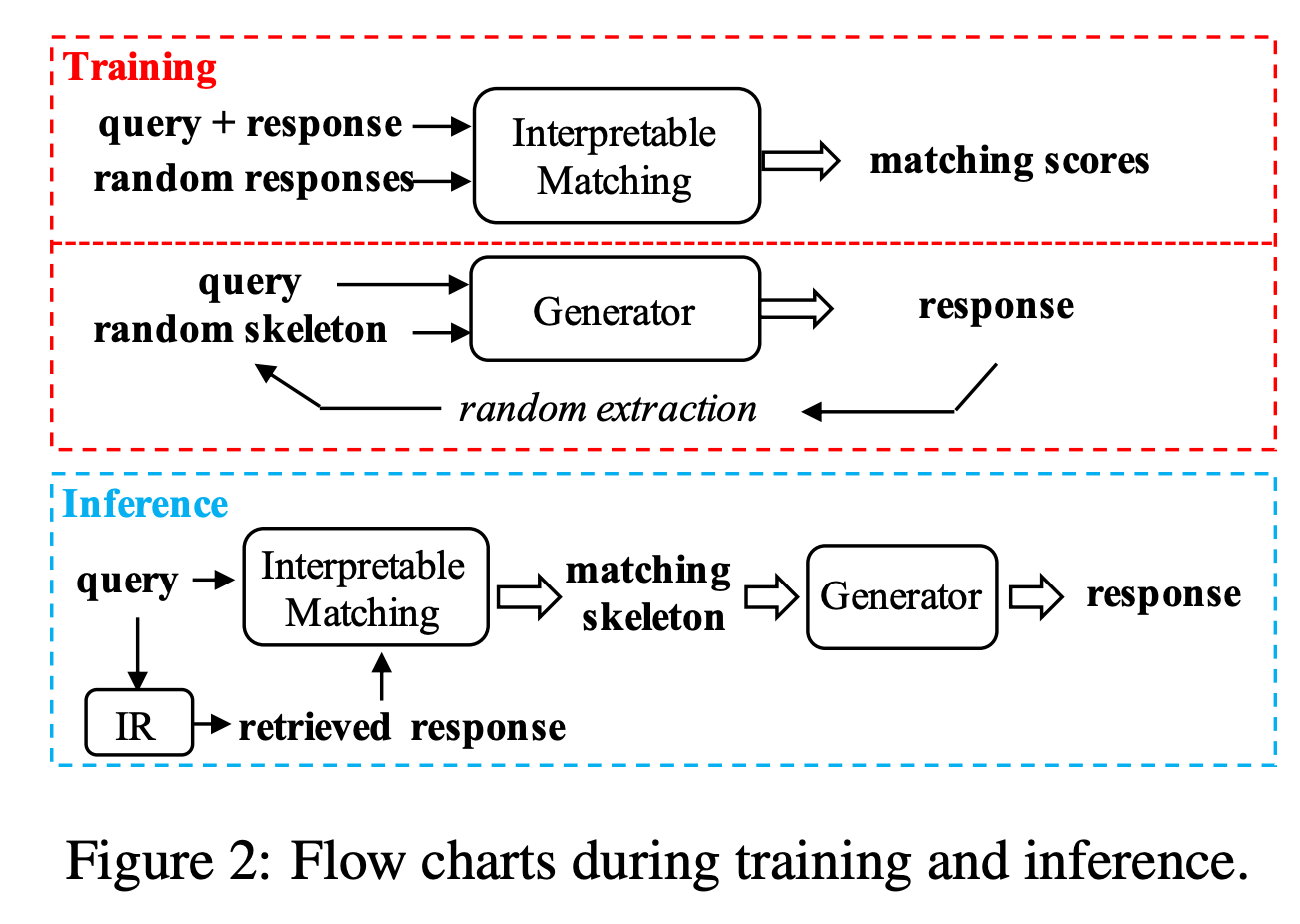
来自论文 Retrieval-guided Dialogue Response Generation via a Matching-to-Generation Framework
传统的seq2seq模型根据用户的query去生成response,这篇工作的创新点是根据query和一个template取生成response。这个template是一个回复的骨架,把一句话移除某些关键词得到。
首先作者训练了一个匹配模型,给定query+response和一些随机response,用一个模型计算它们的匹配得分。这里用的是一个可解释的匹配模型,在比较query和response中的token时,把它们的attention权重拿出来分析。这个可解释的模型达到的效果是,可以知道query和response中哪两个token之间是起决定性作用的。
然后我们可以拿到对response生成最重要的那些token,把它们移除掉,把剩下那些token当成回复的模板。
接着试图让模型根据模板去生成相应的回复。在生成回复的过程中,模型接收两个输入,分别是query和随机的模板,去生成response。
通过上面的训练方法,我们就可以得到一个可解释的匹配模型和一个生成器模型。
在推理时,首先接收用户的query,然后使用检索系统查询检索到的(候选)response,然后用匹配模型计算候选response和query中每个单词的匹配度,去掉匹配得分较高的那些单词得到匹配模板,最后喂给生成器模型得到response。
除了上面介绍的把检索的结果和生成融合起来的方法之外,还有各种各样的其他做法。
其中值得一提的一种做法是
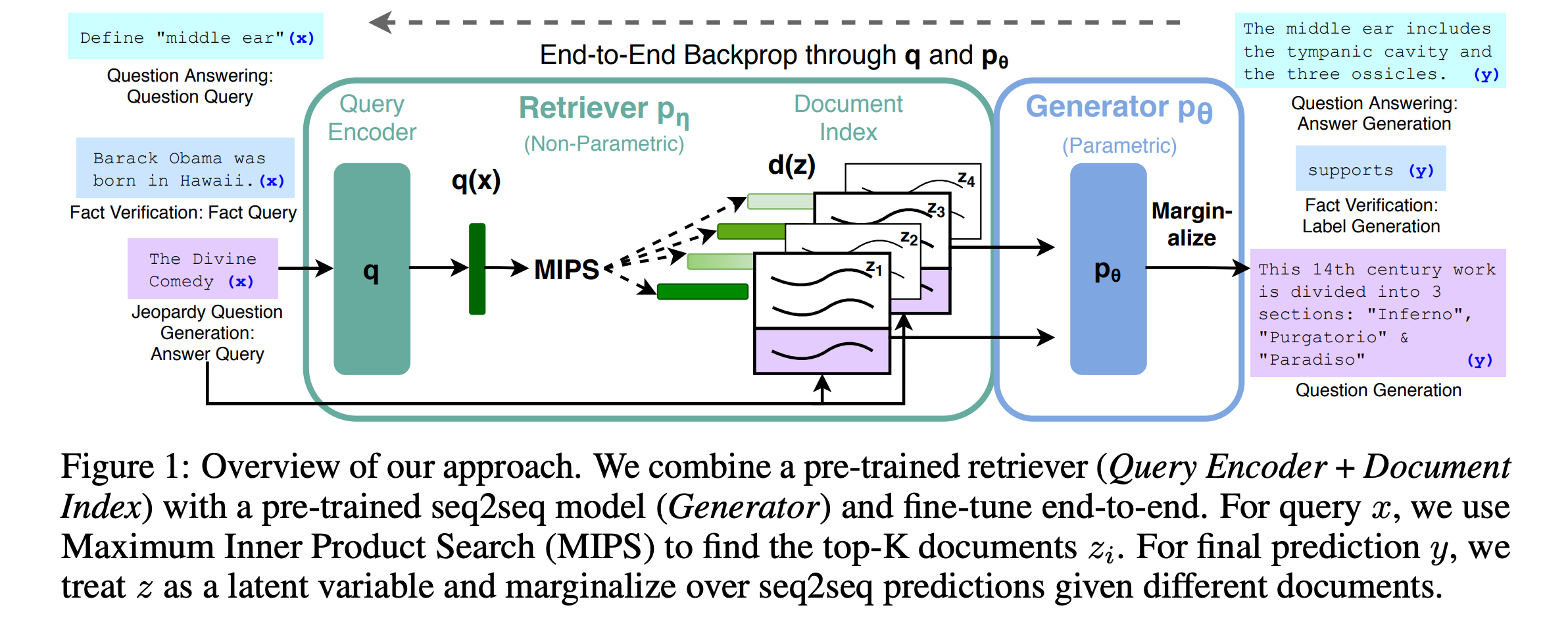
来自论文: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks。
作者试图去做一个问答生成(QA)任务。
首先根据用户的query,喂给Encoder得到query的表示,然后把该表示喂给一个检索模型,检索出来和这个表示相近的一些文档,这些文档就是检索式模型的结果。接下来做生成,生成模型会接收两个输入,分别是query和检索出来的一个文档doc,去生成response。然后得到一个loss,对于检索出来的多个文档,分别计算出多个loss,把这些loss进行加权平均就得到最终loss。加权用的权重时检索时得到的。
融合检索和生成实际上是非常有前景的一个工作,生成式模型最致命的一点在于无法得到外界知识,而检索式模型刚好可以解决这个问题。
如果检索操作不是在我们给定的文档,而是从互联网检索,那岂不是更厉害?

来自论文 Internet-Augmented Dialogue Generation (BlenderBot2.0)
基于用户的query,模型要执行两个动作,是否网上搜索和生成回复。如果需要网上搜索,可以把网络上检索到的外部知识用在回复生成的过程中。
OpenAI基于GPT-3也提出了类似的WebGPT:

来自论文 WebGPT: Browser-assisted question-answering with human feedback
作者试图解决的问题是目前QA模型生成的回复太呆板,在开放领域的QA问题,很多答案可以在网上找到。作者试图构建一个模型,让模型模仿人类上网找答案的过程,去完成QA任务。

作者设计了人类在上网找答案过程的操作,像搜索、点击链接、引用文本、上下滑动等。然后外部了一些人员去回答给定的问题,要求他们上网搜索,并记录他们搜索的过程(上面对应的命令),转换成文本的形式。让模型学习这个过程,基于给定的上下文去生成下面的动作,可能是点击链接、滚动滑轮、返回等。这些动作也会带来一些结果,比如得到引用过的文本,把动作和结果更新到上下文中。基于更新后的上下文继续让模型生成后续的动作,直到返回答案。
个性化对话系统
首先给出两个对话者个性化的描述,然后希望对话模型能生成出来符合对话描述的回复。

这种相关的数据集有Personalized Dialogue Generation with Diversified Traits
有了这些数据集,如何训练模型去生成个性化的回复呢。

来自论文 A Persona-Based Neural Conversation Model
那么模型的输入应该包含两部分:对话历史和个性描述。一种解决方法是在解码的过程中将个性化描述当成嵌入向量,插入到解码的过中。
但个性化对话系统的数据集容易出现对话个性稀疏问题,在生成个性化对话数据集的时候,会对两个参与对话的工作人员提供一些个性约束,但可能聊着聊着就会出现和个性无关的句子。
如果用这种数据集去训练我们的个性化对话系统,也会存在个性稀疏的问题。
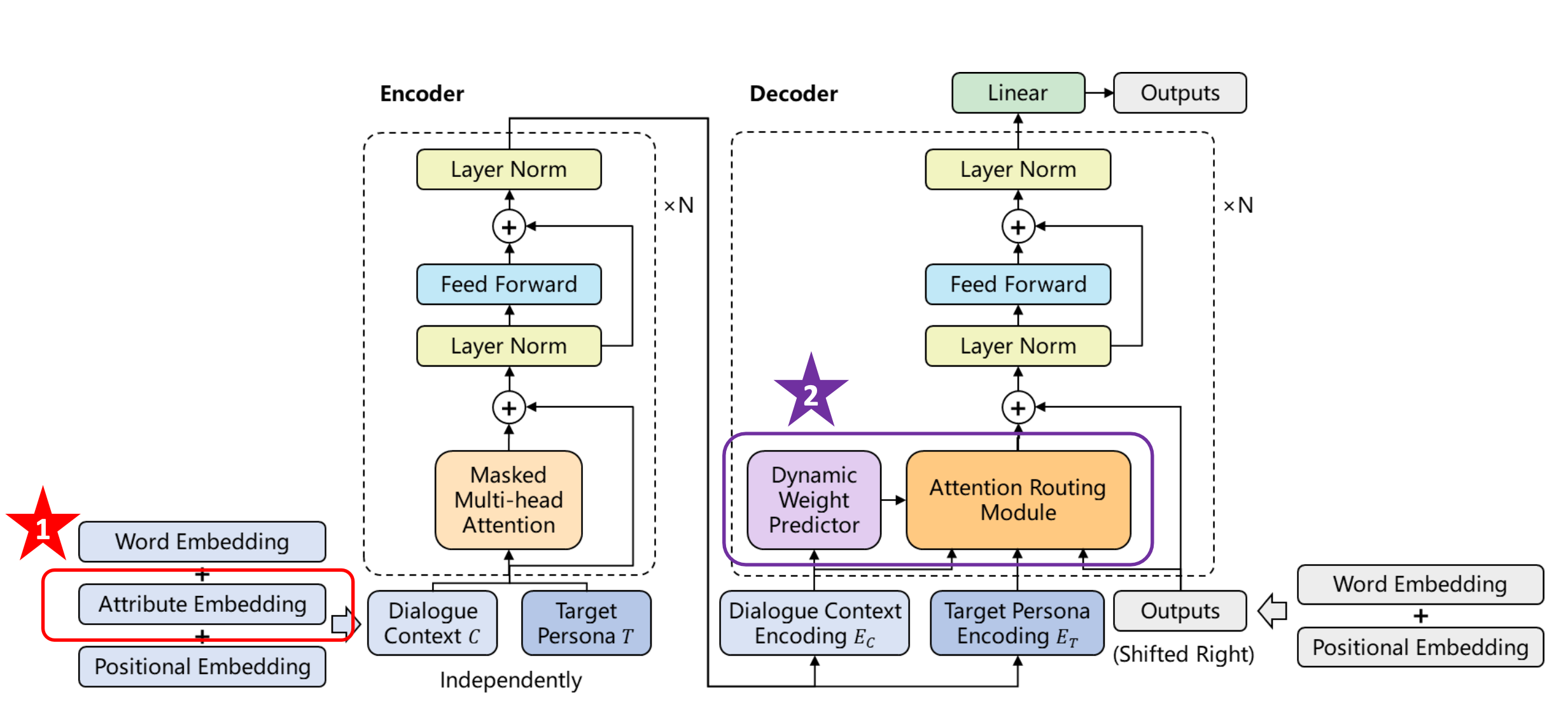
那么如何解决这个问题呢?我们知道可以在词嵌入层加入和个性化相关的嵌入,这里叫Attribute Embedding。
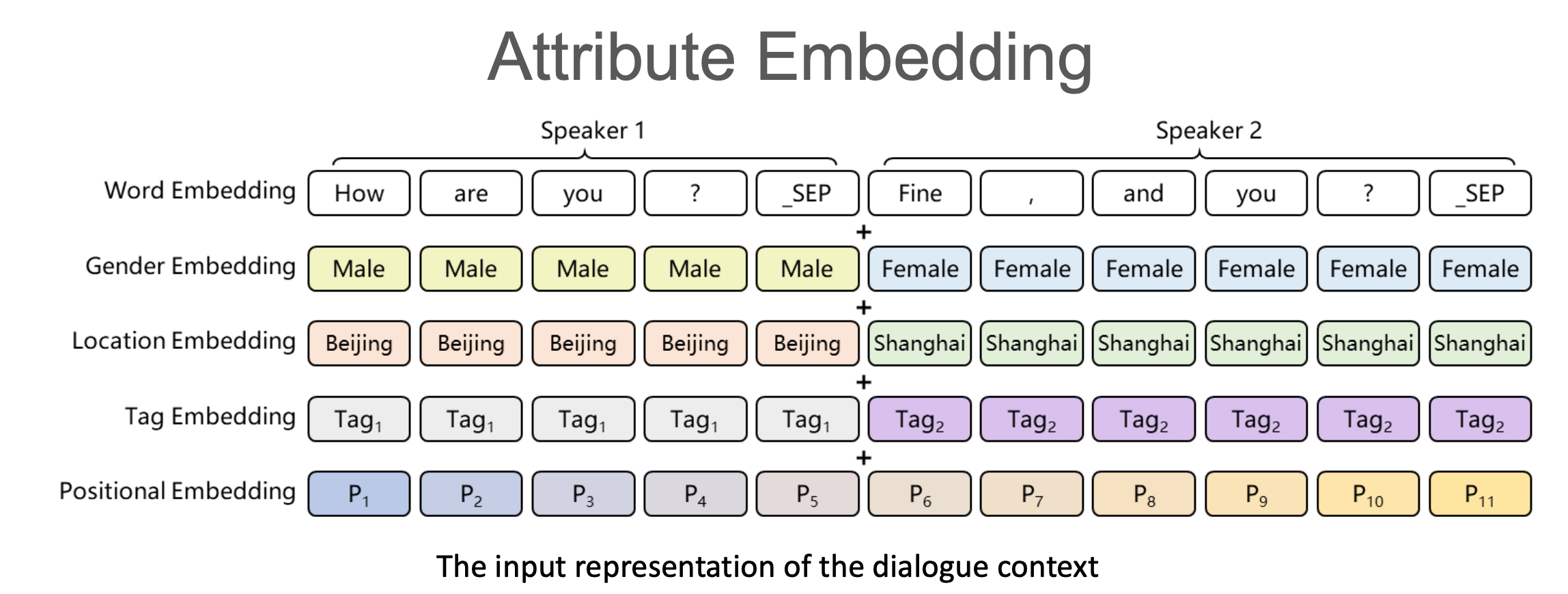
比如上面是描述来自哪里,还有性别嵌入和标签嵌入。最终输入嵌入就是这些嵌入的累加。
这个改进可以一定程度的带来性能提升,但有限。
还有一个改进是增加一个新的权重预测器,它可以根据当前的对话上下文判断对话是否在谈论和个性相关的东西。如果没有在谈论和个性相关的内容,那么尝试让个性化所对应Attention的结果在做平均的时候,给它一个比较小的权重。
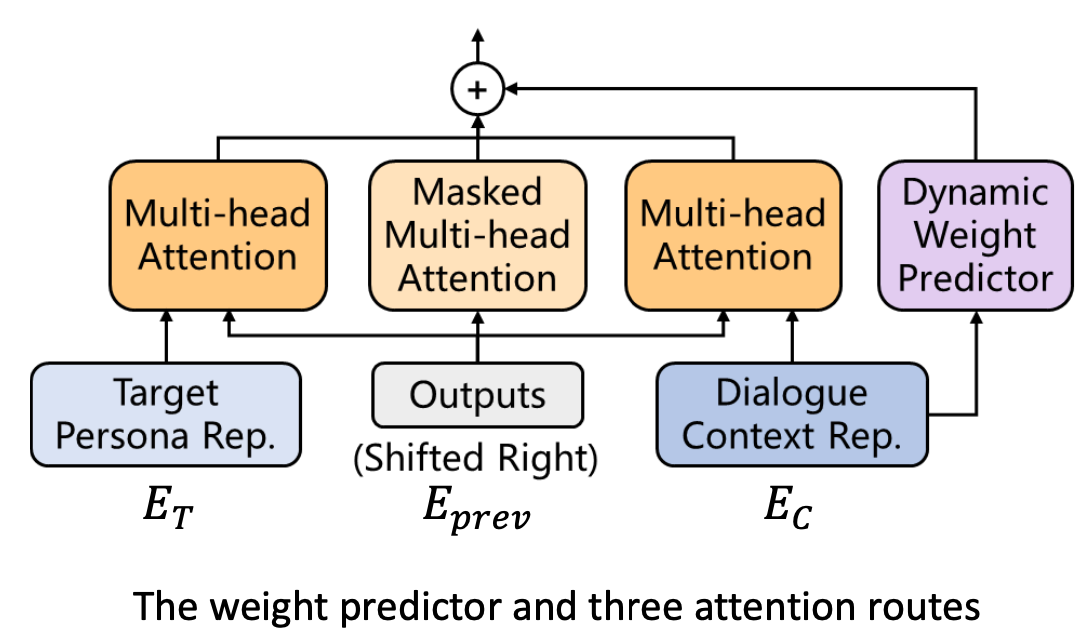
这里修改了Attention的结构,可以看到这里有三个Attention的平均。通过这种方式我们可以控制是否需要个性化的信息。
风格化对话生成
在个性化对话的基础上,另一个想法是风格化对话生成。比如用李白的风格写一首诗。
风格化对话系统也有两个输入,对话历史和风格标签。

但是这种场景有一个问题是缺乏训练数据。那么我们只能想办法生成这种具有风格的对话。
一种方法是反向操作,即给定回复生成问句。
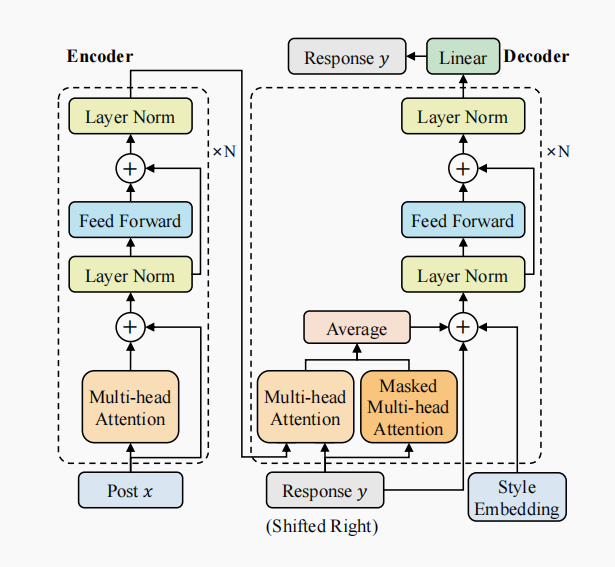
模型的结构也是类似的。除了有多头注意力、掩码多头注意力之外,还有一个风格嵌入进行累加。
对话回复的多样性
最简单的提升对话回复多样性的方法叫做Label Smoothing(标签平滑)的方法。

假设我们再回复中预测出下一个词的概率分布如上所示,以one-hot形式编码的真实标签是human这个词,也称为硬标签,因为它只有human上为1,其他都为0,是一种类似非黑即白的方式。
这种方式的缺点是训练出来的模型杜绝了生成其他词的可能,因为在one-hot情况下,预测其他词的损失为0。而标签平滑把one-hot这种分布更加平滑,比如从1中拿出0.1平分到其他词上,这样模型可以一定程度上去生成其他合法的词。
但标签平滑这种做法还是太简单粗暴了,因为它平分到其他词上时,有些词是不合法的,比如上面的bank。而fun这个词应该分配更大的概率,而不是和它等同。而AdaLabel就考虑了这一点更加动态地去分配概率。但实际上大家只会采用标签平滑的做法。
参考
- 贪心学院课程
- 李沐读论文
- Improving Language Understanding by Generative Pre-Training
- Language Models are Unsupervised Multitask Learners
- Generating Long Sequences with Sparse Transformers
- Language Models are Few-Shot Learners
- Retrieval-guided Dialogue Response Generation via a Matching-to-Generation Framework
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks ⭐️
- Internet-Augmented Dialogue Generation
- WebGPT: Browser-assisted question-answering with human feedback ⭐️
- A Persona-Based Neural Conversation Model