目录
1、前言
2、readTextFile(已过时,不推荐使用)
3、readFile(已过时,不推荐使用)
4、fromSource(FileSource) 推荐使用
1、前言
思考: 读取文件时可以设置哪些规则呢?
1. 文件的格式(txt、csv、二进制...)
2. 文件的分隔符(按\n 分割)
3. 是否需要监控文件变化(一次读取、持续读取)
基于以上规则,Flink为我们提供了非常灵活的 读取文件的方法
2、readTextFile(已过时,不推荐使用)
语法说明:
定义:def readTextFile(filePath: String): DataStream[String]def readTextFile(filePath: String, charsetName: String)功能:1.读取文本格式的文件2.按行读取(\n为分隔符),每行数据被封装为 DataStream 的一个元素3.可以指定字符集(默认为UDF-8)4.文件只会读取一次源码分析:public DataStreamSource<String> readTextFile(String filePath, String charsetName) {// 初始化 TextInputFormat对象TextInputFormat format = new TextInputFormat(new Path(filePath)); // 指定路径过滤器(使用默认过滤器)format.setFilesFilter(FilePathFilter.createDefaultFilter()); // 指定Flink中的数据类型 TypeInformation<String> typeInfo = BasicTypeInfo.STRING_TYPE_INFO; // 指定字符集format.setCharsetName(charsetName); // 调用 readFile 方法return readFile(format, filePath, FileProcessingMode.PROCESS_ONCE, -1, typeInfo); }代码示例:
public static void readTextFile() throws Exception {/** TODO 功能说明* readTextFile(path) - 读取文本文件(一次读取),例如遵守 TextInputFormat 规范的文件,逐行读取并将它们作为字符串返回。* */// 1.获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2.将文本文件作为数据源env.readTextFile("data/1.txt").setParallelism(4).print();// 3.触发程序执行env.execute();}
3、readFile(已过时,不推荐使用)
语法说明:
定义:def readFile[T: TypeInformation](inputFormat: FileInputFormat[T],filePath: String,watchType: FileProcessingMode,interval: Long): DataStream[T] = {val typeInfo = implicitly[TypeInformation[T]] // 隐私转换(将java 数据类型 转换为 Flink数据类型)asScalaStream(javaEnv.readFile(inputFormat, filePath, watchType, interval, typeInfo))}参数:inputFormat : 指定 FileInputFormat 实现类(根据文件类型 选择相适应的实例)filePath : 指定 文件路径watchType : 指定 读取模式(提供了2个枚举值)PROCESS_ONCE :只读取一次PROCESS_CONTINUOUSLY :按照指定周期扫描文件interval : 指定 扫描文件的周期(单位为毫秒)功能:按照 指定的 文件格式 和 读取方式 读取数据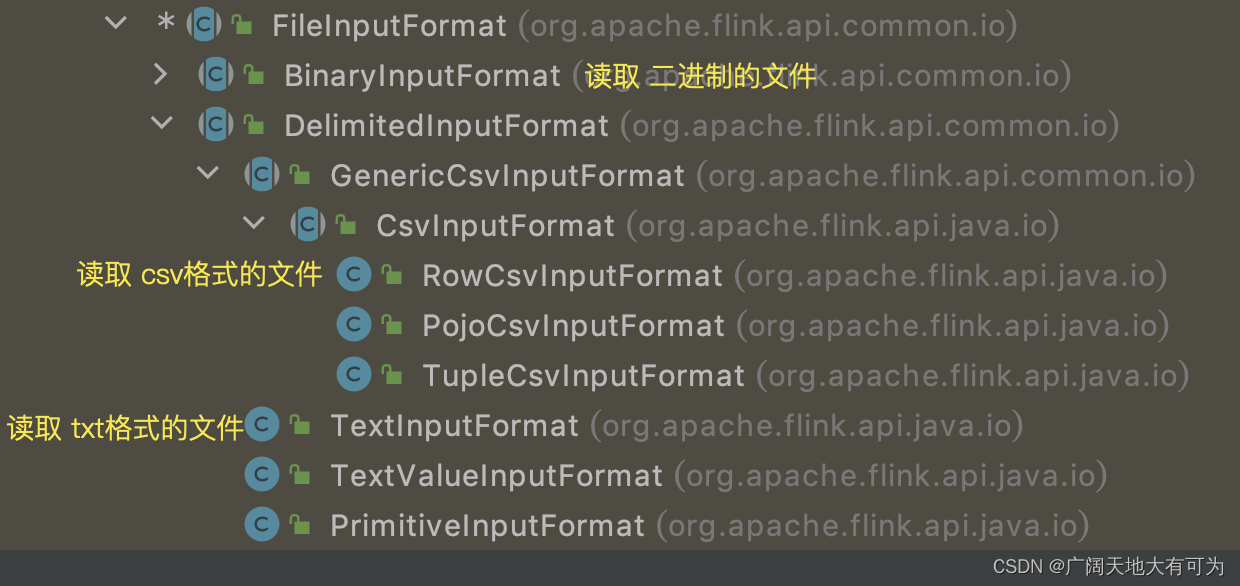
代码示例:
public static void readFile() throws Exception {/** TODO 功能说明* readFile(fileInputFormat, path) - 按照指定的文件输入格式读取(一次)文件。* readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo)* 按照指定的文件输入格式读取(持续的读取)文件* */// 1.获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2.将文本文件作为数据源String filePath = "data/1.txt";TextInputFormat textInputFormat = new TextInputFormat(new Path(filePath));textInputFormat.setFilesFilter(FilePathFilter.createDefaultFilter()); // 指定过滤器textInputFormat.setCharsetName("UTF-8"); // 指定编码格式/** readFile(inputFormat: FileInputFormat[OUT], filePath: String, watchType: FileProcessingMode, interval: Long)* 参数说明:* @inputFormat : 指定文件输入格式* @filePath : 指定文件路径* @watchType : 指定监控类型,提供了两种读取策略* PROCESS_ONCE : 只读取一次* PROCESS_CONTINUOUSLY :持续读取,监控新增数据* @interval : 指定连续扫描文件的周期(毫秒)* 重点提示:* 1.如果watchType设置为PROCESS_CONTINUOUSLY时,当一个文件被修改时,将会导致重新读取该* 文件的全部内容,这将会打破`精确一次`的语义* */env.readFile(textInputFormat, filePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 1000).print();// 3.触发程序执行env.execute();}
4、fromSource(FileSource) 推荐使用
public static void FileSource() throws Exception {// 1.获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2.将文本文件作为数据源FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat(), new Path("data/1.txt")).build();env.fromSource(fileSource, WatermarkStrategy.noWatermarks(), "read fileSource").print();// 3.触发程序执行env.execute();}