在前面的两篇博文中,主要是考虑基于之前以往的人脸识别项目经历结合最近使用到的faiss来构建更加高效的检索系统,感兴趣的话可以自行移步阅读即可:
《基于facenet+faiss开发构建人脸识别系统》
Facenet算法的优点:高准确率:Facenet模型在人脸识别和人脸验证任务上取得了非常出色的准确率,甚至在大规模人脸识别数据集上也表现优异。基于嵌入向量的表示:Facenet将人脸图像转换为紧凑的嵌入向量,使得不同人的人脸之间能够得到有效的分离,并且嵌入向量具有良好的可比性。大规模训练:Facenet模型可以通过使用大规模的人脸图像数据集进行训练,从而获得更好的泛化能力。Facenet算法的缺点:高计算资源需求:由于Facenet模型的深度和复杂性,需要大量的计算资源来进行训练和推理。这使得在某些设备或场景下应用Facenet模型变得困难。影响因素敏感:Facenet模型对输入图像的光照、角度和尺度等因素敏感。在实际应用中,需要考虑这些因素对人脸识别或验证的影响。《基于arcFace+faiss开发构建人脸识别系统》
ArcFace模型优点:准确性高:ArcFace在常见的人脸识别任务中取得了非常好的性能,能够实现高准确性的人脸匹配和识别。抗干扰能力强:ArcFace模型在面对光照变化、表情变化、遮挡等干扰因素时,仍能保持较高的稳定性和可靠性,对人脸图像的变化有较好的适应性。特征嵌入明显:ArcFace模型通过学习得到的人脸特征向量在高维空间中有较明显的嵌入效果,同一个人的人脸特征向量距离较近,不同人的特征向量距离较远,增加了模型的判别力。ArcFace模型缺点:复杂性高:ArcFace模型相比其他简单的人脸识别模型,比如FaceNet,模型结构更加复杂,需要更大的计算资源和更长的训练时间。数据依赖性强:ArcFace模型的性能与训练数据的质量和数量密切相关,需要大规模的人脸数据集进行训练,从而使模型具有更好的泛化能力。隐私问题:由于ArcFace模型具有较强的人脸识别能力,潜在的隐私问题也随之出现。在应用和部署过程中,需要遵循隐私保护的原则和规定。
在前面两篇博文中整体的计算流程是一致的,只不过是模型使用有不同区分而已,在后端向量检索的时候都用到的faiss这个框架,没有很直观地对其性能进行测试评估,本文的主要目的就是考虑基于已有的数据来完成对faiss的评估计算。
我将前文中faiss检索部分的实现封装为experiment方法,之后编写训练测试,对结果进行可视化评估,如下所示:
def show():"""实验评估可视化"""C,A=[],[]for one in [1,10,100,1000,10000,100000,100000]:count,avg=experiment(nums=one)C.append(count)A.append(avg)print("C: ", C)print("A: ", A)plt.clf()plt.figure(figsize=(20,8))x_list=list(range(len(C)))plt.subplot(121)plt.xticks(x_list,['1','10','100','1000','10000','100000','100000'])plt.plot(x_list,C,c='b')plt.title("Total Time Trend Cruve")plt.subplot(122)plt.xticks(x_list,['1','10','100','1000','10000','100000','100000'])plt.plot(x_list,A,c='g')plt.title("Average Time Trend Cruve")plt.savefig("time.png")结果输出如下所示:
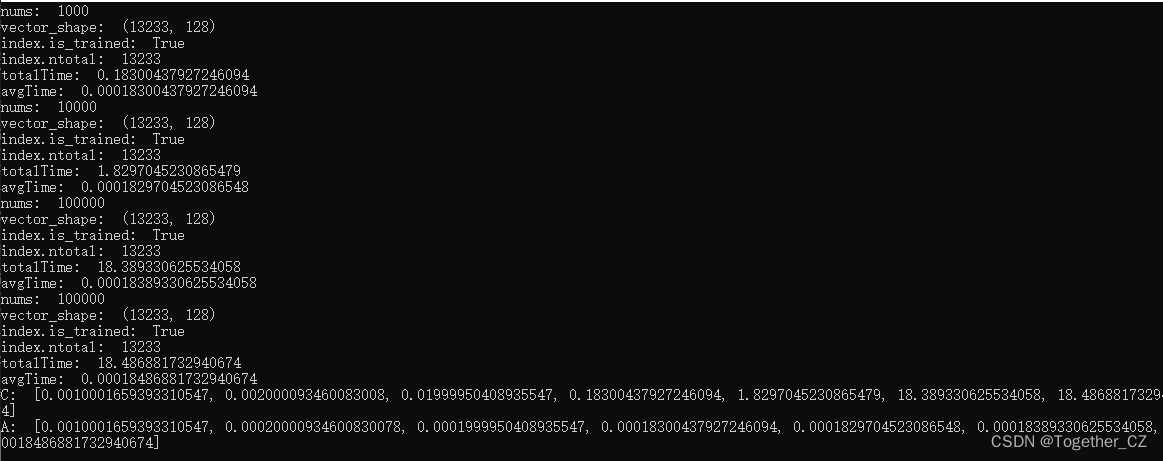
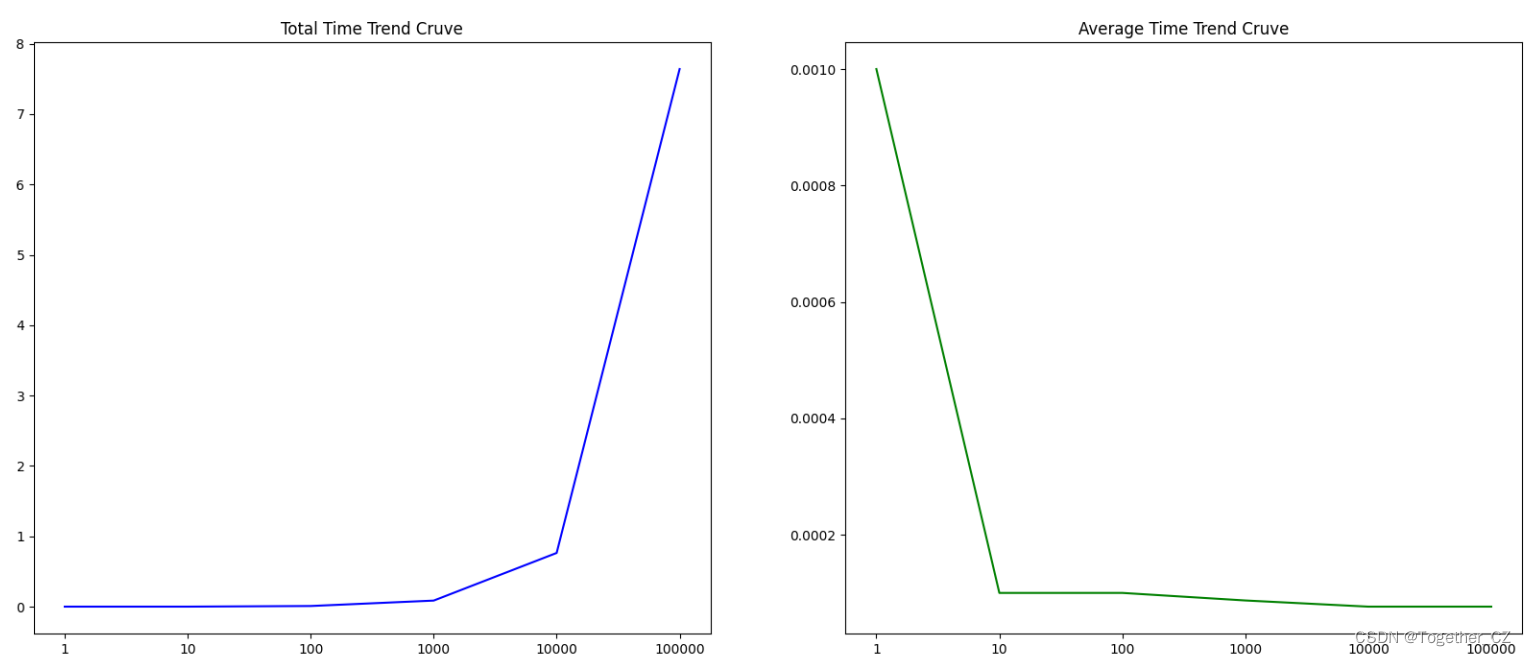
可视化对比结果如下所示:

左边蓝色曲线表示的是单次实验总的查询时耗,右边绿色曲线表示的是单次实验单次查询的平均时耗,从图像呈现出来的走势来看,单次平均时耗随着查询次数的增加保持着相对的稳定。我这里使用的是lfw数据集构建的向量数据库,样本量为13233,并不大,资源消耗占用如下:
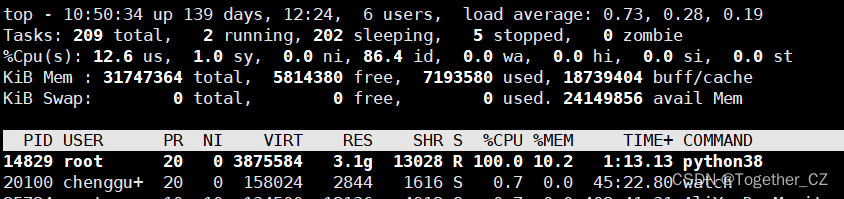
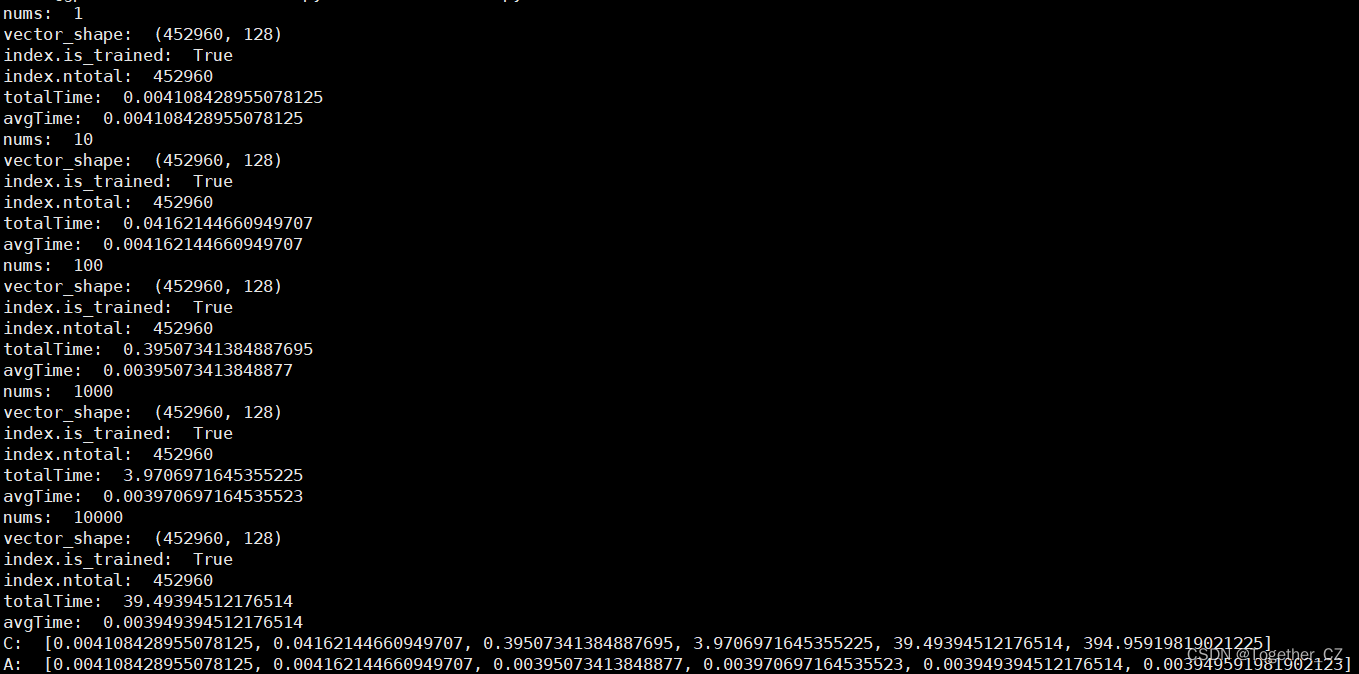
接下来我换用另一个大的数据集来构建向量数据集,进而评估测试在大数据量情况下faiss的性能。这个大数据集共有45w+的样本数据量,整体计算日志输出如下所示:
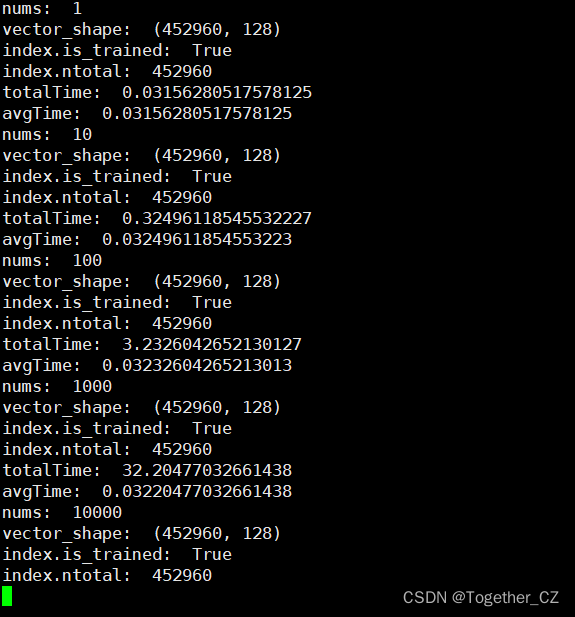
总样本数据量为:452960
完整输出如下所示:
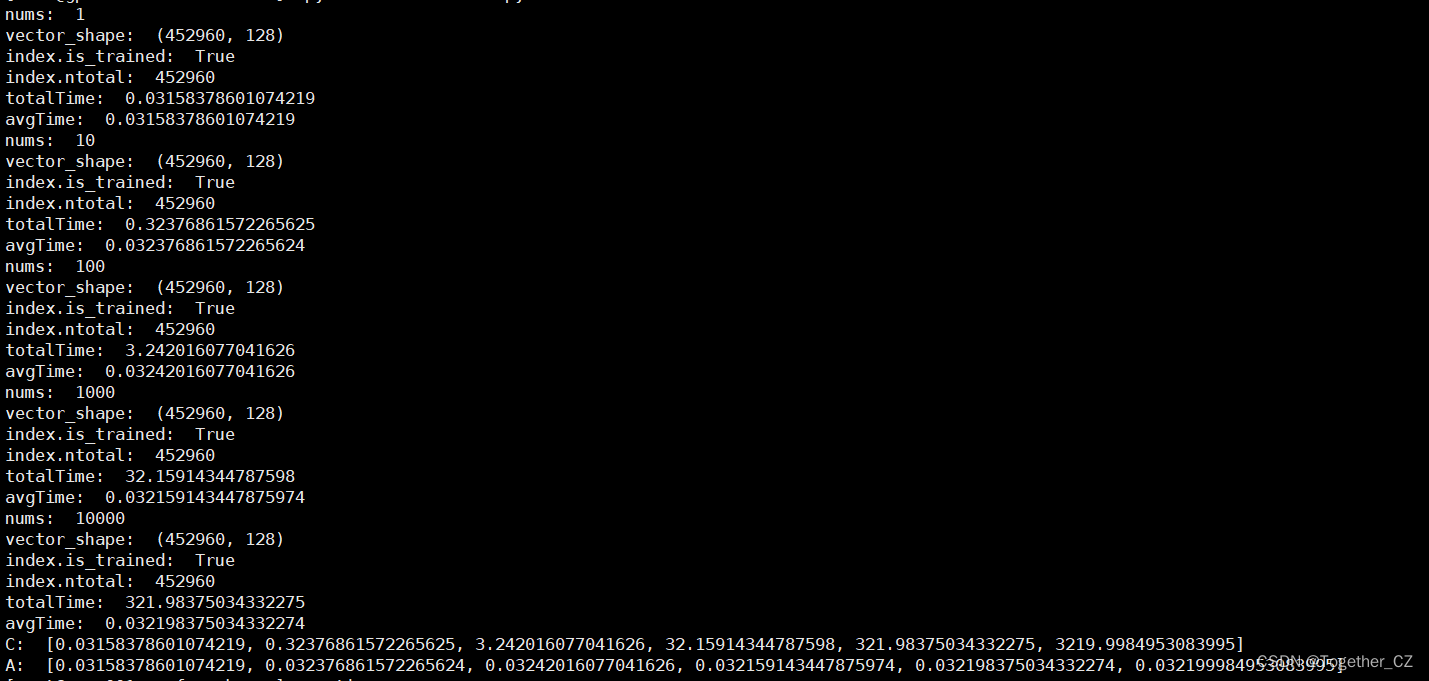
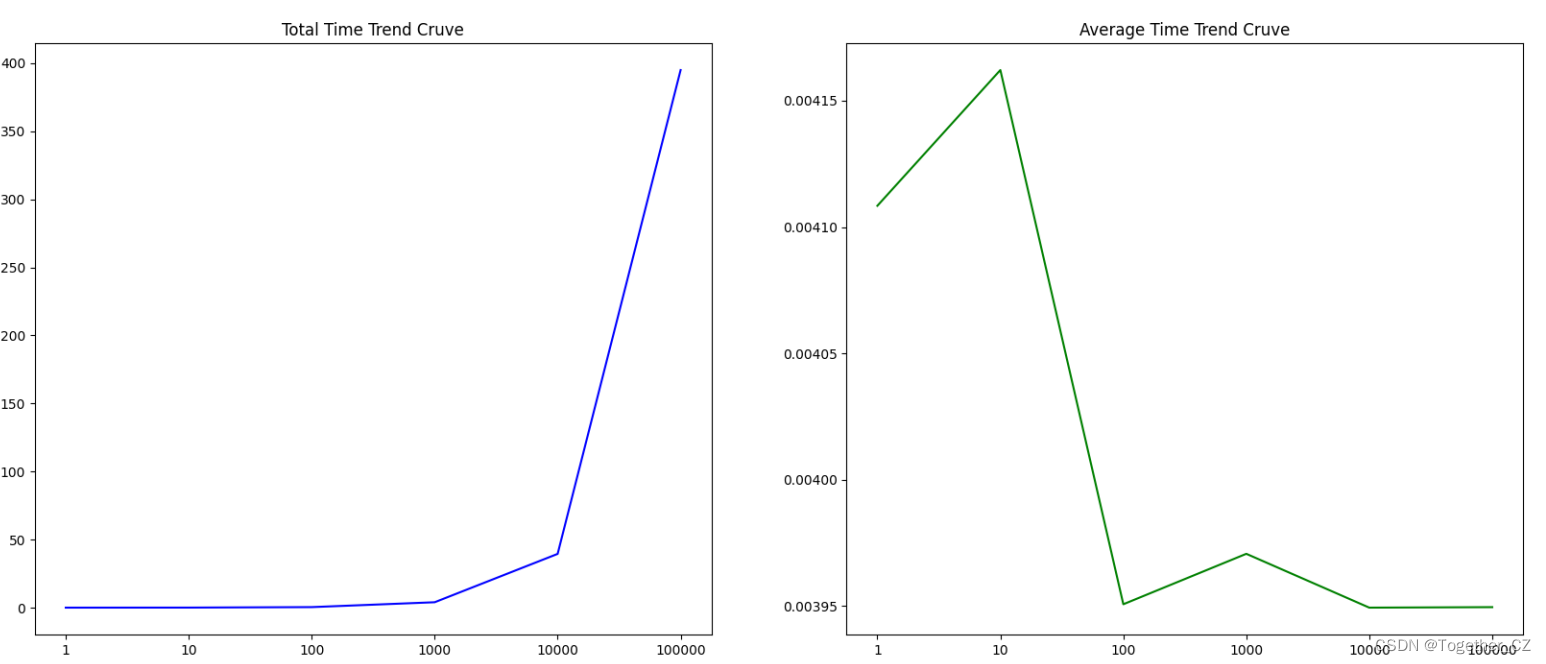
结果对比可视化如下所示:
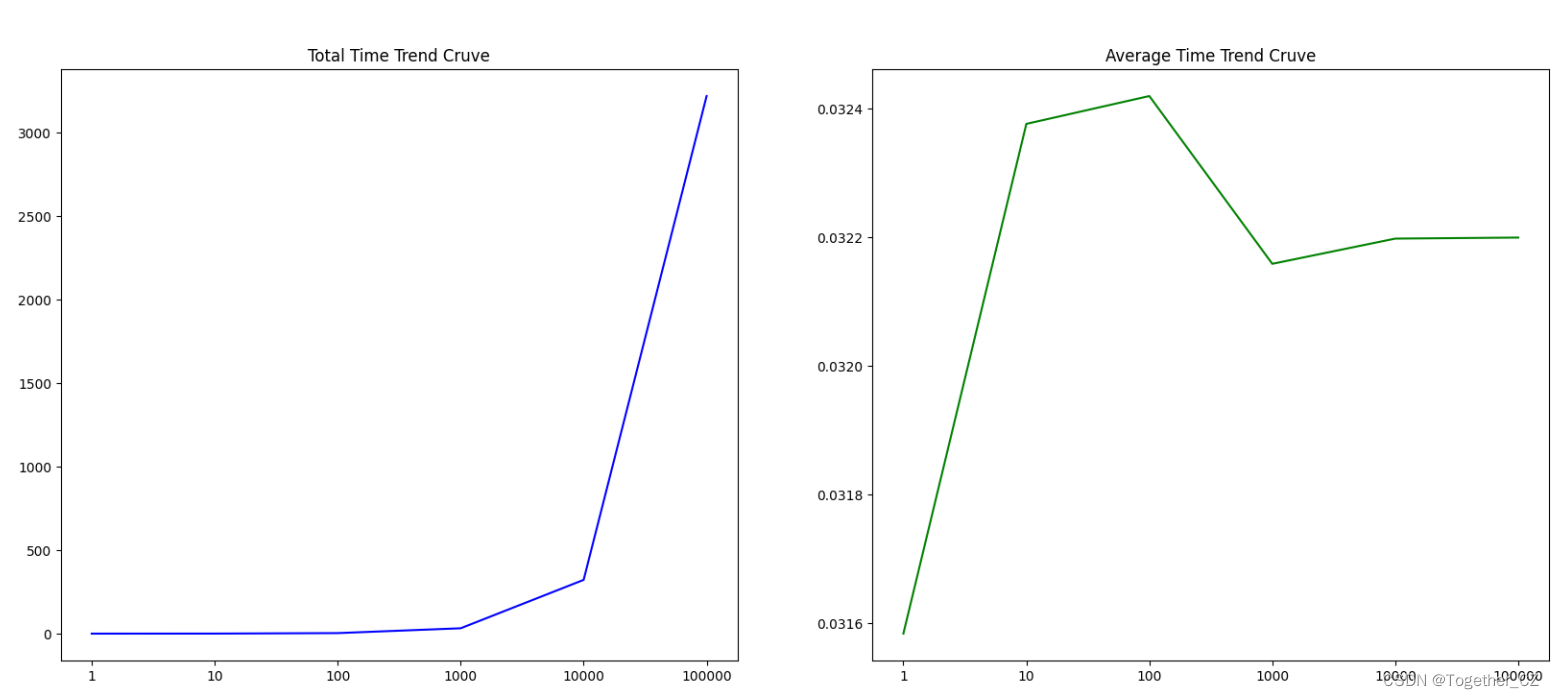
可以看到:随着数据量的增大单次查询时耗也是增加不少的。
在第一组实验中lfw数据集上1w+的样本数据量,单次查询时耗如下:
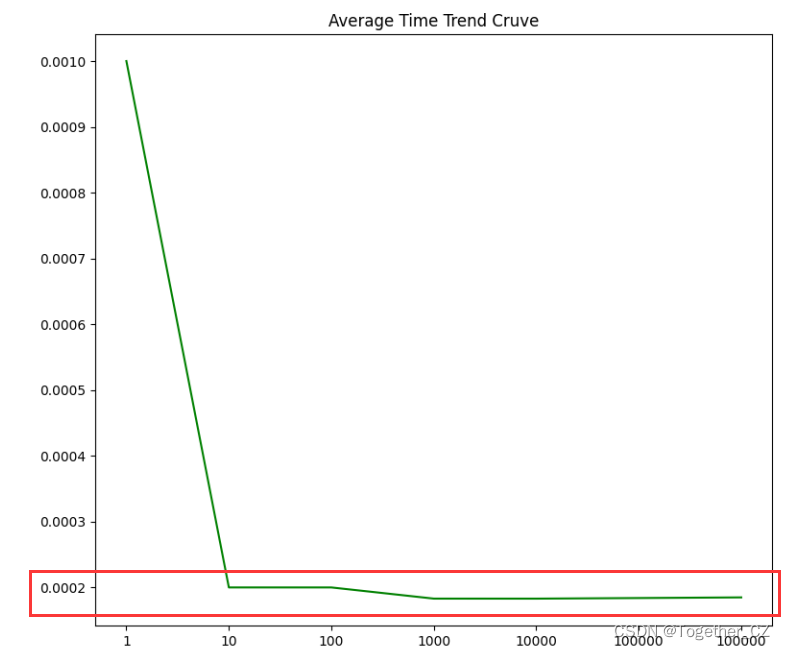
基本维持在0.0002s的水平。
在大数据集45w+的向量检索条件下,实验结果单次查询时耗如下所示:

基本维持在0.0322s的水平。
这两组实验整体对比来看,数据量增大了45倍左右,单次查询时耗增大了161倍。
当然了,这只是粗浅直观地对比分析,只是简单直接地通过实际实验数据来探索分析数据量-时耗的关系,我的实验条件是cpu环境,并没有用faiss-gpu的版本,如果是使用gpu的话应该会更快一下。
另外这里的index使用的是精准的查询也就是暴力搜索IndexFlatL2,这种方法本身在数据量很大的情况下就会是很慢的。
接下来我们来尝试使用其他类型的index方法——PQx :乘积量化来通过实验分析对应的性能。这里依旧是使用lfw数据集。计算结果输出如下所示:
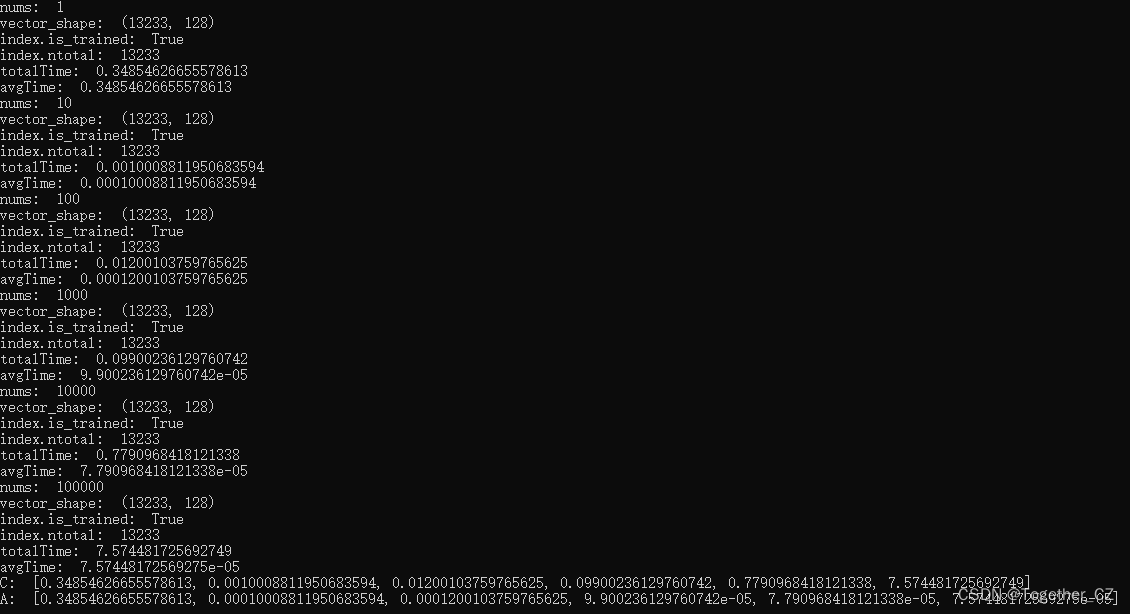
结果对比可视化如下所示:

在大数据量条件下测试结果输出如下所示:
结果对比可视化如下所示:
粗略来看,大数据集上面的性能至少比暴力搜索快了一个数量级。
接下来我们基于IVFxPQy 倒排乘积量化来对faiss进行测试评估分析,以lfw数据集为例,看下结果输出:
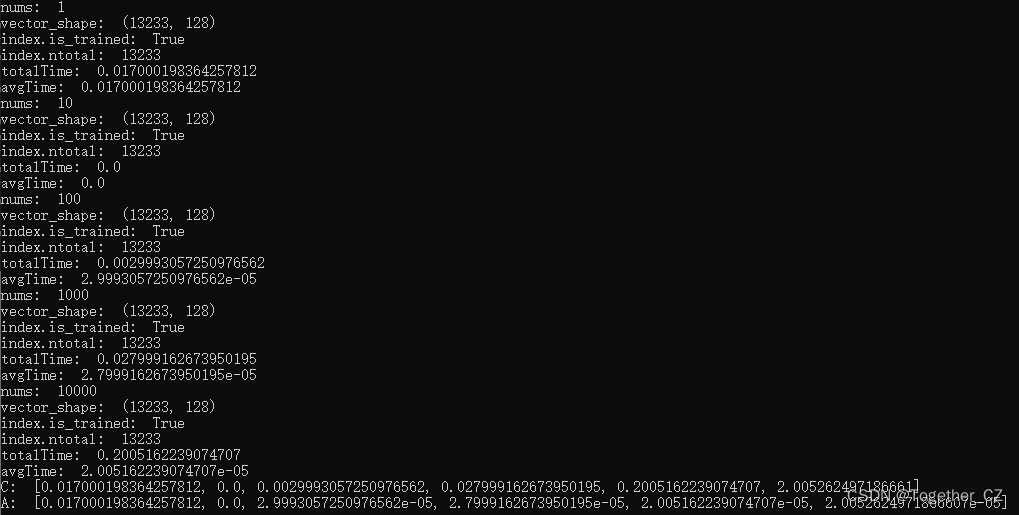
结果对比可视化如下所示:
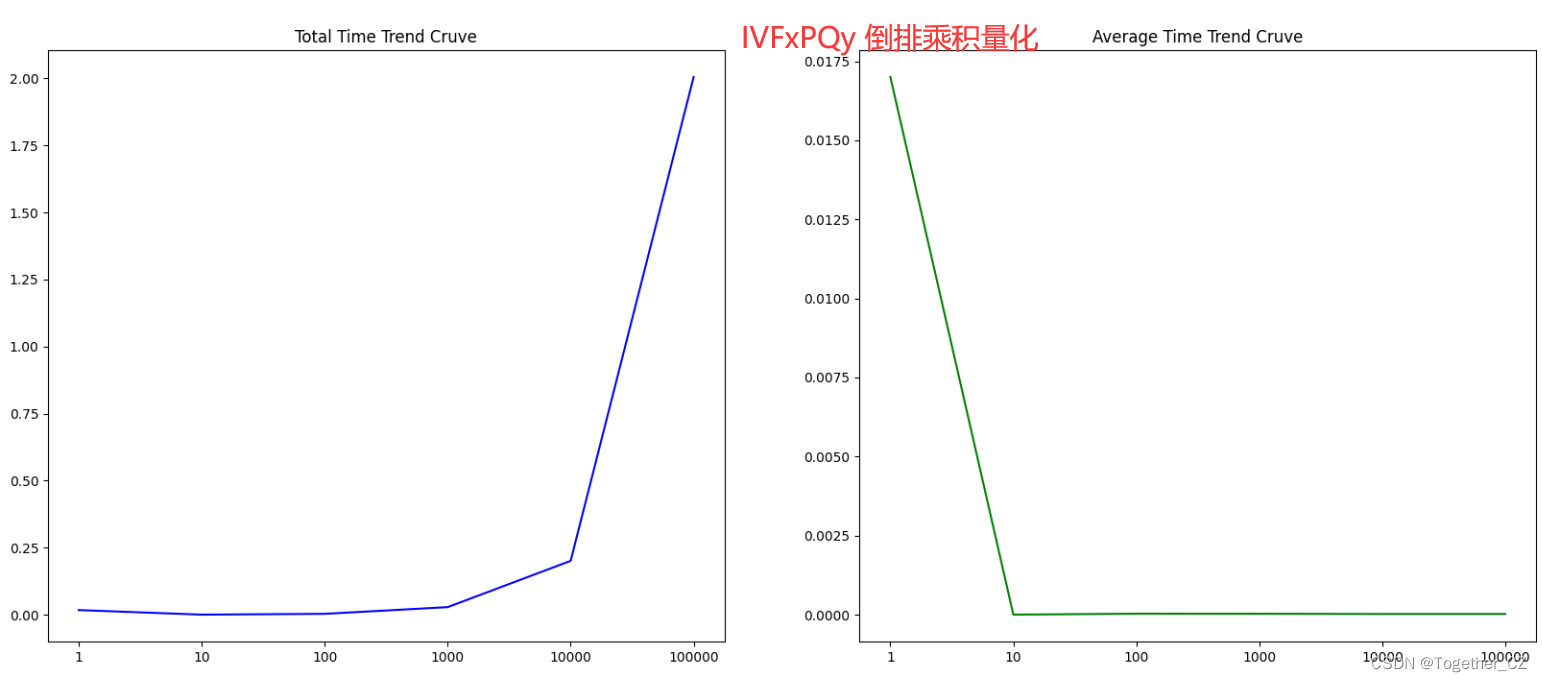
在大数据量条件下测试结果输出如下所示:
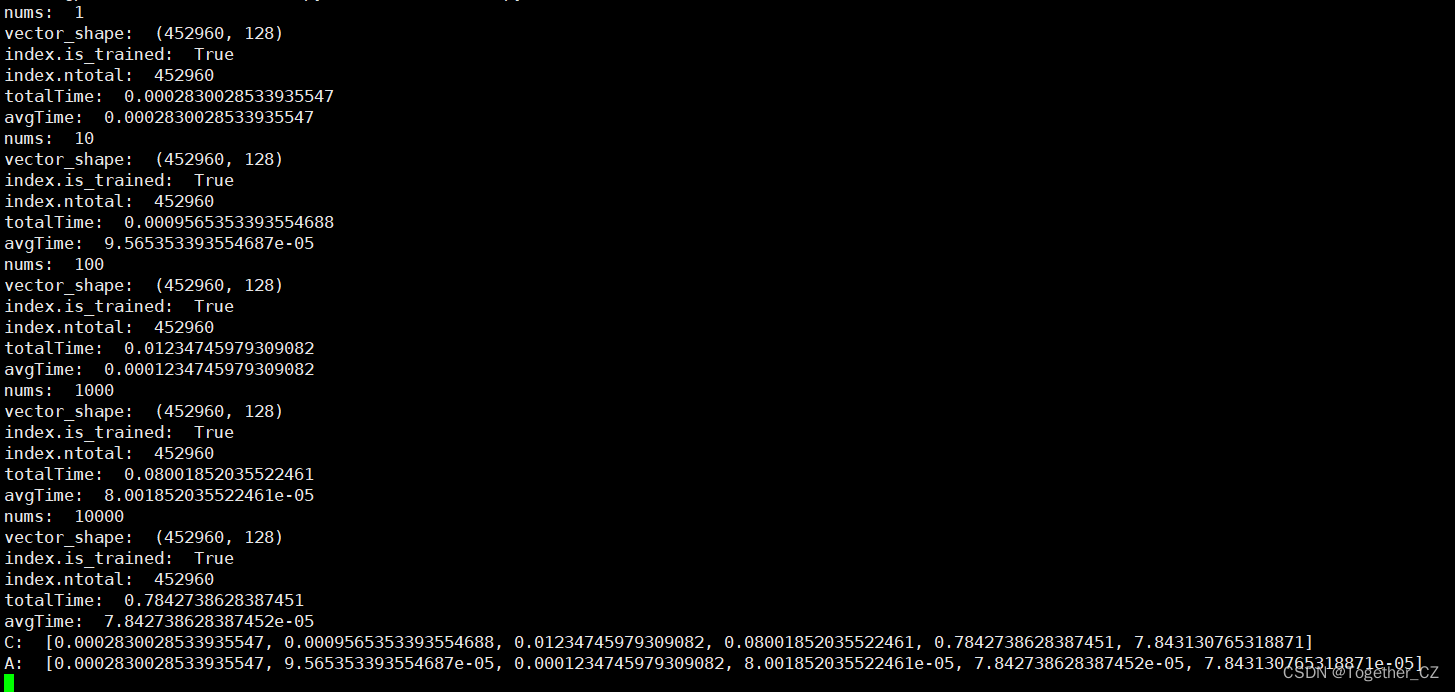
结果对比可视化如下所示:
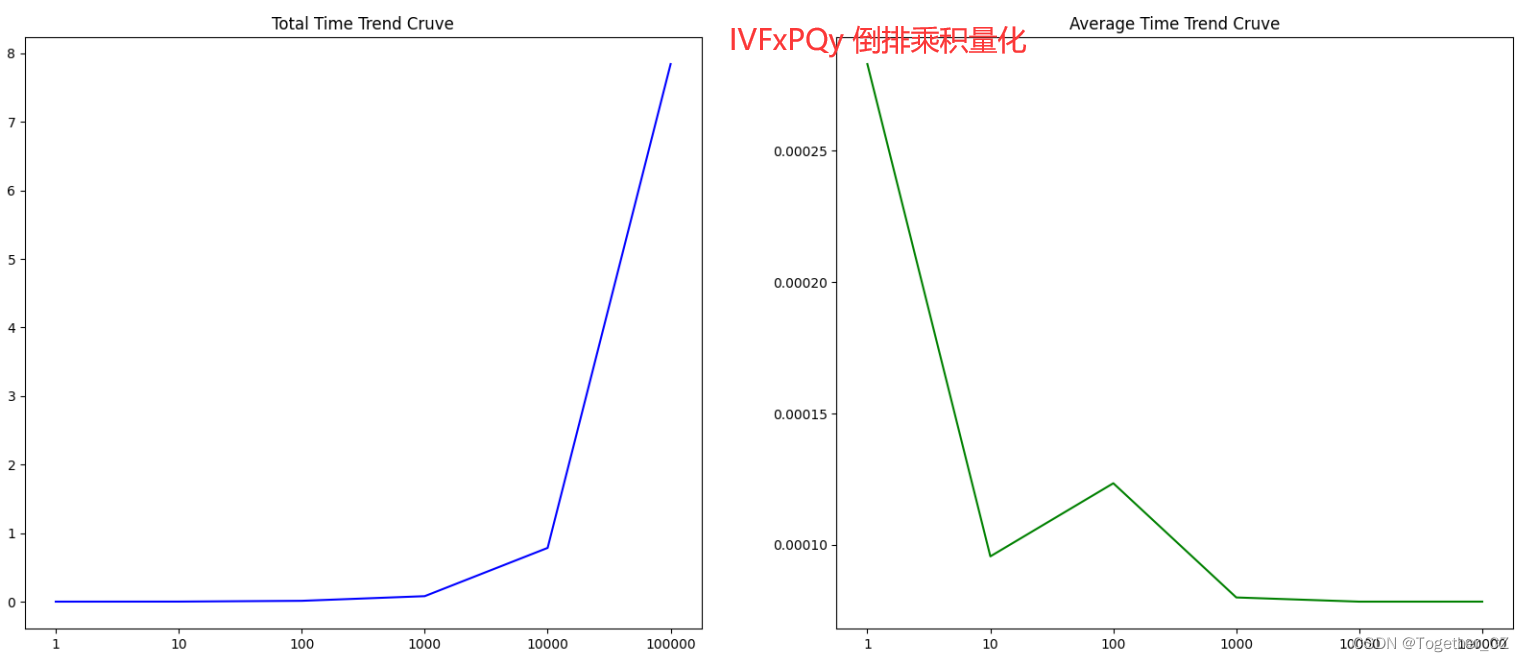
接下来我们使用LSH 局部敏感哈希来对faiss进行测试评估分析,以lfw数据集为例,看下结果输出:

结果对比可视化如下所示:
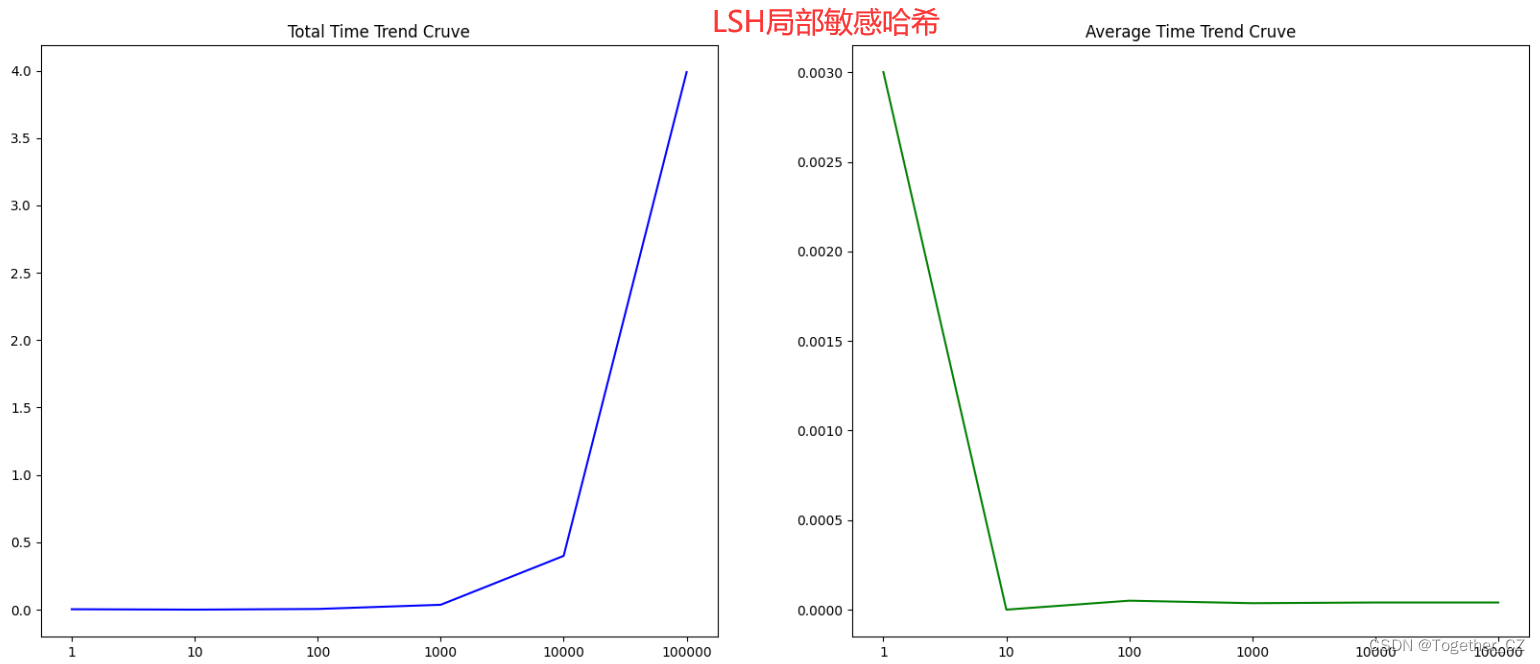
在大数据量条件下测试结果输出如下所示:
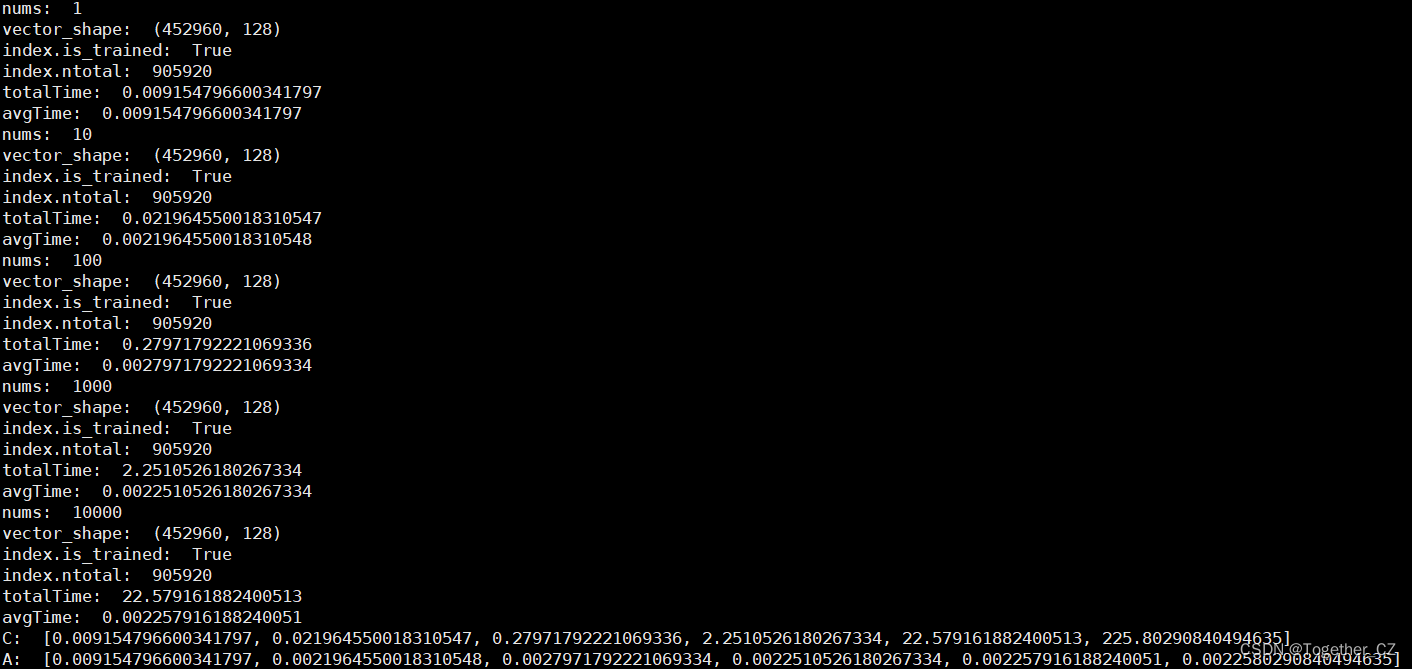
结果对比可视化如下所示:

最后我们基于HNSWx图检测来对faiss进行测试评估分析,以lfw数据集为例,看下结果输出:

结果对比可视化如下所示:
资源消耗如下:
在大数据量条件下测试结果输出如下所示:

结果对比可视化如下所示:
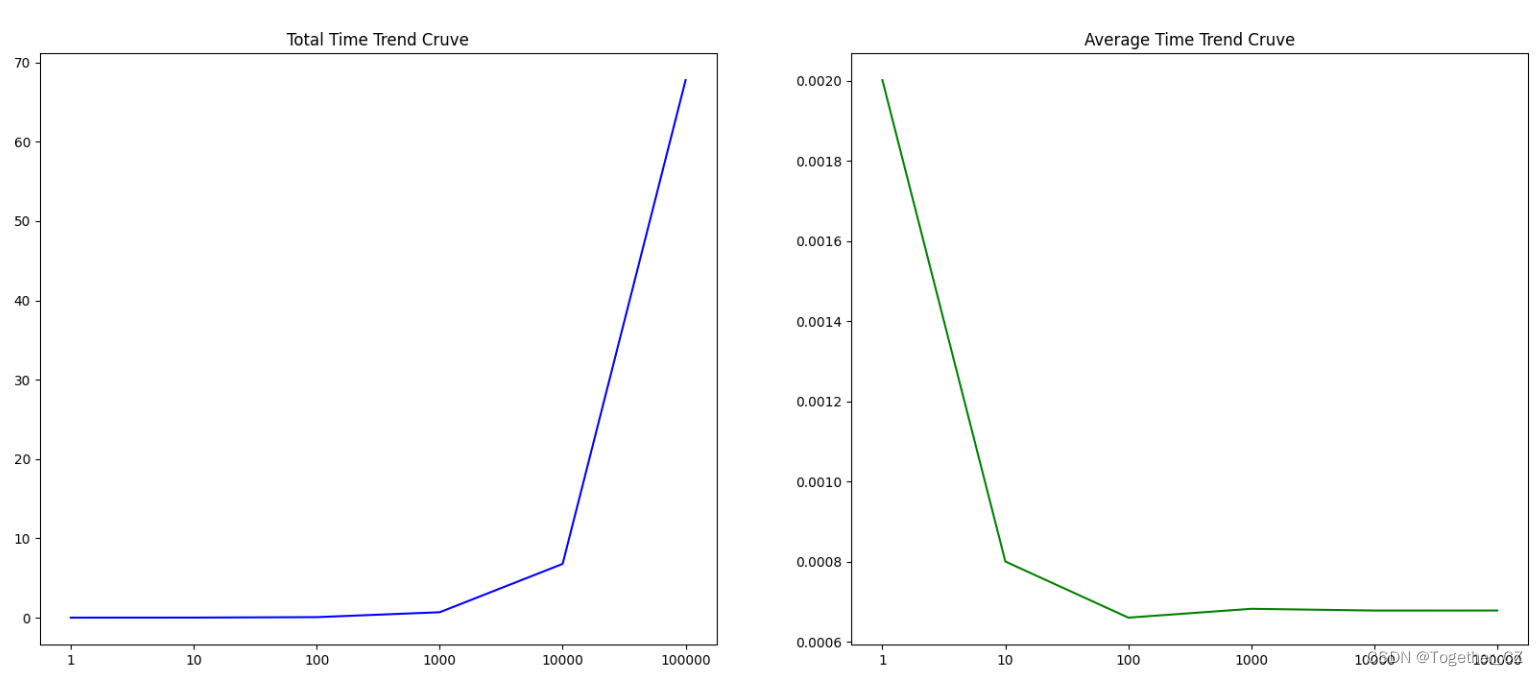
检索速度相较于暴力搜索方法来说至少提高了两个数据级,通过本文系列的实验对比测试评估不难发现,数据量、index方法对于检索性能的影响是非常大的。
我这里45w+的样本量其实并不算大的,我这里只是为了做实验,上亿级别的数据可能才算得上是大数据量,那样级别的数据一方面构建难度是很大的,另一方面实验成本是比较高的,感兴趣的话可以尝试下更大的数据量下的性能,欢迎交流!