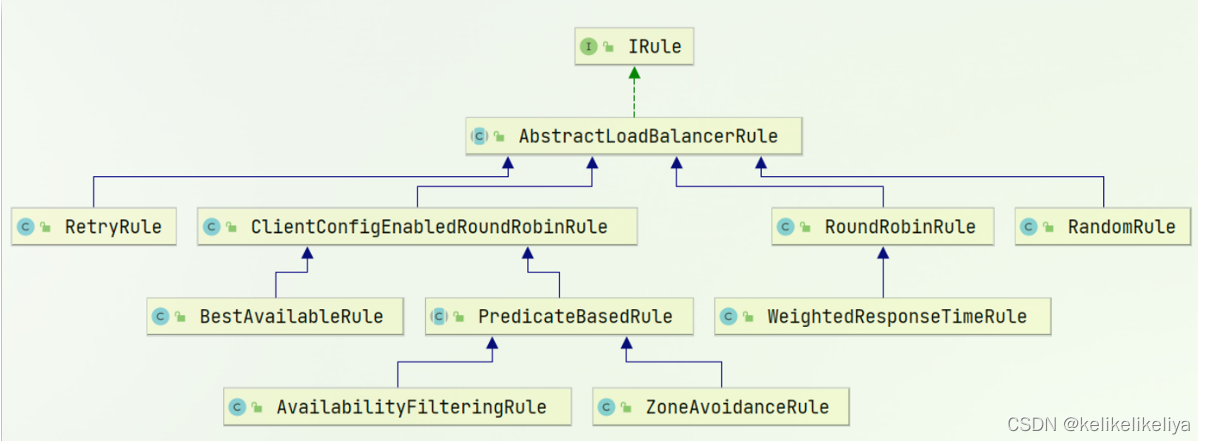
一、说明
我如何使用一个 Python 脚本抓取大量网站,在第 2 部分使用 Docker ,“我如何使用一个python脚本抓取大量网站”统计数据。在本文中,我将与您分享:
- Github存储库,您可以从中克隆它;
- 链接到 docker 容器,可以帮助您使用一个命令抓取内容;
- 一些用例以及如何处理它们;
您可以从我关于实用网页抓取的其他博客文章中以易于查看的格式找到代码。
二、Repo 和Updates
进行版本控制对于对重构过程进行适当的控制是必要的。这也是一种比 Gist 脚本更方便的共享代码库的方式。参考地址:
GitHub - destilabs/webtric
通过在 GitHub 上创建一个帐户来为目标/网站开发做出贡献。
github.com
默认情况下,此存储库允许您解析著名的抓取sandbox(沙盒) quotes.toscrape.com。为了更好地理解脚本以及如何根据自己的目的修改它,请阅读第 1 部分。
您可以通过 shell 脚本执行立即在本地开始使用它:
./scripts/quotes.sh ./outputs/quotes local 或
./scripts/quotes.sh ./outputs/quotes remote 我鼓励您阅读此脚本的列表并附上注释,以更好地了解它的作用:参考地址:
网站/语录.sh在主·Destilabs/webtric
此文件包含双向 Unicode 文本,其解释或编译方式可能与下面显示的内容不同...
github.com
三、Docker登场
虽然这个解决方案似乎对许多读者很有帮助,但我可以想象它在安装过程中并非无痛。Chromedriver 是一个令人讨厌的工具,需要定期更新和对操作系统配置细微差别的“初学者+”理解。另一方面,Docker 只需要知道运行容器的正确命令。
描述这个容器可能没有比只显示它的 docker-compose 文件更好的方法了:参考地址:
webtric/docker-compose.yml at main ·Destilabs/webtric
此时无法执行此操作。您使用其他选项卡或窗口登录。您在另一个选项卡中注销或...
github.com
让我们也一步一步地看一遍:
Chromedriver 和 Selenium Hub 是独立的服务。它们将在其相应的端口上启动并运行。在剧本中等待他们起床至关重要。
Webtric服务(帖子的主人公)将在飞行中构建,然后等待上面的两个服务。您会在日志中看到一些错误,但它应该赶上并开始解析。

Webtric 的预期输出
要运行 docker-compose 文件,请执行两个命令:
export APP=./scripts/quotes.sh
docker-compose up Jupyter 服务将被提升为可以立即访问解析的数据。输入 http://localhost:8888/lab?token=webtric 并创建新笔记本:

Pick Python 3 (ipykernel)
这是一个简洁的脚本,用于访问“/home/webtric”卷中最后一个抓取的文件:
import pandas as pd
from os import listdir
from os.path import isfile, joinVOLUME = "/home/webtric"
files = [f for f in listdir(VOLUME) if isfile(join(VOLUME, f))]print('List of all parsed files')
print('\n'.join(files))df = pd.read_csv(join(VOLUME, files[-1]))
df.head()这是它最终应该的样子
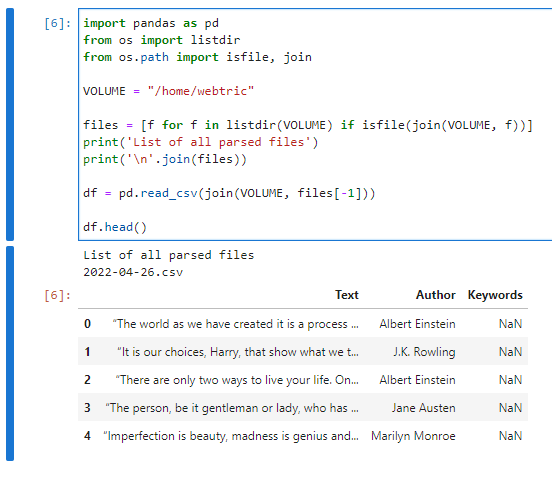
表明你成功了!
四、使用案例
首先,我做这个项目只是为了好玩和学习,你也可以。从实际的角度来看,在 docker 中使用 Webtric 对于扩展很有用,因为现在可以通过生成越来越多的容器来并行抓取。不过,请记住刮擦的黄金法则:
对要解析的网站保持温和
现在托管您的蜘蛛也更容易,因为大多数现代云托管服务提供商对容器都很友好。我将准备一个关于如何在不久的将来使其工作的教程,敬请期待。



![[系统安全] 五十二.DataCon竞赛 (1)2020年Coremail钓鱼邮件识别及分类详解](https://img-blog.csdnimg.cn/b71225e4e2d9432a99ab095c7cec4831.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBARWFzdG1vdW50,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)