这篇文章主要介绍协同分组coGroup的使用,先讲解API代码模板,后面会结图解介绍coGroup是如何将流中数据进行分组的.
1 API介绍
- 数据源
# 左流数据 ➜ ~ nc -lk 6666 101,Tom 102,小明 103,小黑 104,张强 105,Ken 106,GG小日子 107,小花 108,赵宣艺 109,明亮# 右流数据 ➜ ~ nc -lk 7777 101,男,本科,程序员 102,男,本科,程序员 103,女,本科,会计 104,男,大专,安全工程师 105,男,硕士,律师 106,未知,小本,挖粪使者 108,女,本科,人事 110,男,本科,算法工程师 - 代码
import org.apache.flink.api.common.functions.CoGroupFunction; import org.apache.flink.api.common.typeinfo.TypeHint; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.api.java.tuple.Tuple4; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.util.Collector;/*** @Author: J* @Version: 1.0* @CreateTime: 2023/8/10* @Description: 协同分组**/ public class FlinkCoGroup {public static void main(String[] args) throws Exception {// 构建流环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置并行度env.setParallelism(2);// 数据源1(socket数据源),为了方便测试,根据实际情况自行选择DataStreamSource<String> sourceStream1 = env.socketTextStream("localhost", 6666);// 将数据进行切分返回Tuple2(id,name)SingleOutputStreamOperator<Tuple2<String, String>> mapStream1 = sourceStream1.map(value -> {String[] split = value.split(",");return Tuple2.of(split[0], split[1]);}).returns(new TypeHint<Tuple2<String, String>>() {});// 数据源2(socket数据源),为了方便测试,根据实际情况自行选择DataStreamSource<String> sourceStream2 = env.socketTextStream("localhost", 7777);// 将数据进行切分返回Tuple4(id,gender,education,job)SingleOutputStreamOperator<Tuple4<String, String, String, String>> mapStream2 = sourceStream2.map(value -> {String[] split = value.split(",");return Tuple4.of(split[0], split[1], split[2], split[3]);}).returns(new TypeHint<Tuple4<String, String, String, String>>() {});// 数据流协同DataStream<Tuple4<String, String, String, String>> coGrouped = mapStream1.coGroup(mapStream2).where(tup -> tup.f0) // 左流协同分组字段(mapStream1).equalTo(tup -> tup.f0) // 右流协同分组字段(mapStream2).window(TumblingProcessingTimeWindows.of(Time.seconds(20))) // 开窗口,以处理时间划分(每20秒一个窗口).apply(new CoGroupFunction<Tuple2<String, String>, Tuple4<String, String, String, String>, Tuple4<String, String, String, String>>() {@Overridepublic void coGroup(Iterable<Tuple2<String, String>> first, Iterable<Tuple4<String, String, String, String>> second, Collector<Tuple4<String, String, String, String>> out) throws Exception {/***first 代表左流的迭代器* second 代表右流的迭代器* out 则是返回的数据形式* 具体方法中两个迭代器存数据的原理后续会通过图结合进行解析**/// 这里的逻辑模拟sql中left join// 遍历左流数据(first)for (Tuple2<String, String> left : first) {// 定义右流是否为NULL判断标识boolean flag = false;// 遍历右流数据(second)for (Tuple4<String, String, String, String> right : second) {// 返回left(id, name) + right(gender, education)Tuple4<String, String, String, String> tup4 = Tuple4.of(left.f0, left.f1, right.f1, right.f2);// 输出out.collect(tup4);// 修改判断标识flag = true;}// 如果右流为NULL,则输出左流的数据if (!flag) {// 这里用字符串"NULL"代替null值,方便观察Tuple4<String, String, String, String> tup4 = Tuple4.of(left.f0, left.f1, "NULL", "NULL");// 输出out.collect(tup4);}}}});// 打印结果coGrouped.print();env.execute("Flink CoGroup");} } - 结果
从数据源和结果数据可以看到和代码逻辑是完全吻合的.2> (102,小明,男,本科) 1> (106,GG小日子,未知,小本) 2> (109,明亮,NULL,NULL) 1> (107,小花,NULL,NULL) 2> (105,Ken,男,硕士) 2> (103,小黑,女,本科) 2> (101,Tom,男,本科) 2> (108,赵宣艺,女,本科) 2> (104,张强,男,大专)
2 原理解析
我这我们先看一下图解,如下
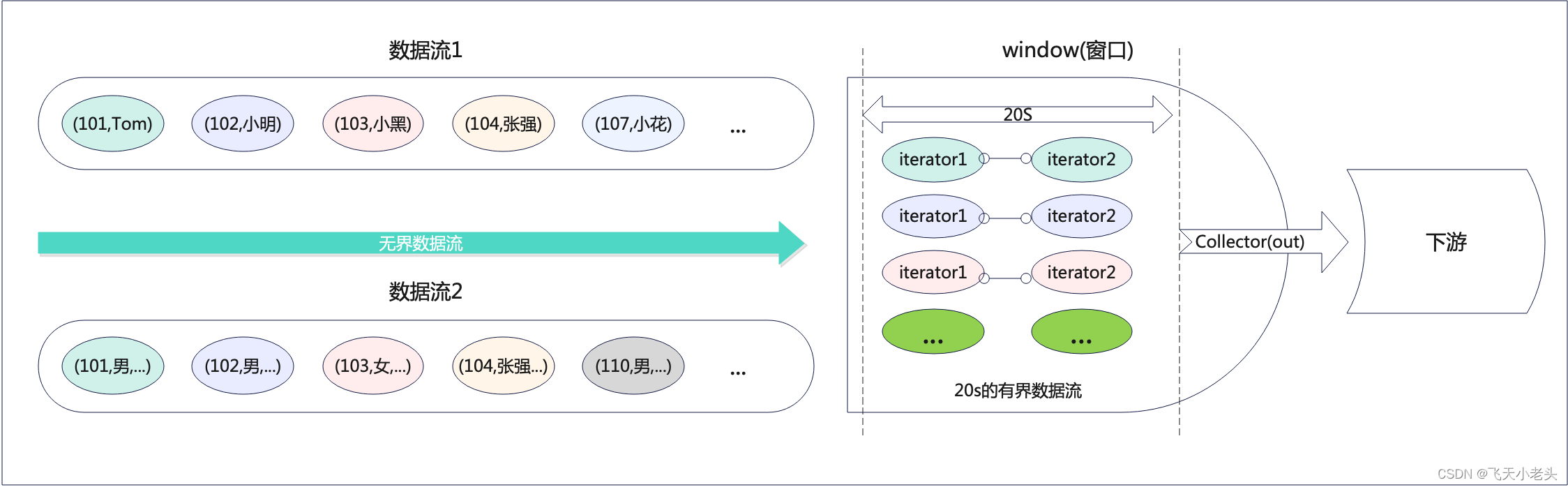
- 无界转有界
在代码中我们开启window,这也是使用coGroup的必要条件,开启window后实际上就是将我们原本的无界数据流转变成一个以20S为界限的有界数据流. - 迭代器分组
将数据进入到窗口内后,就会根据经我们前面设定的条件也就是.where和.equalTo中的内容将mapStream1和mapStream2中的数据根据key进行分组存储到不同的iterator中. - 逻辑计算
上面已经将数据根据key都存储到iterator中了,这里就会根据我们在new CoGroupFunction<...>(){...}中的写的逻辑将mapStream1和mapStream2中具有相同key的iterator进行计算. - 输出
当一个window结束后,就会将数据按照计算后的结果(在代码中就是Tuple4<String, String, String, String>)输出到下游.