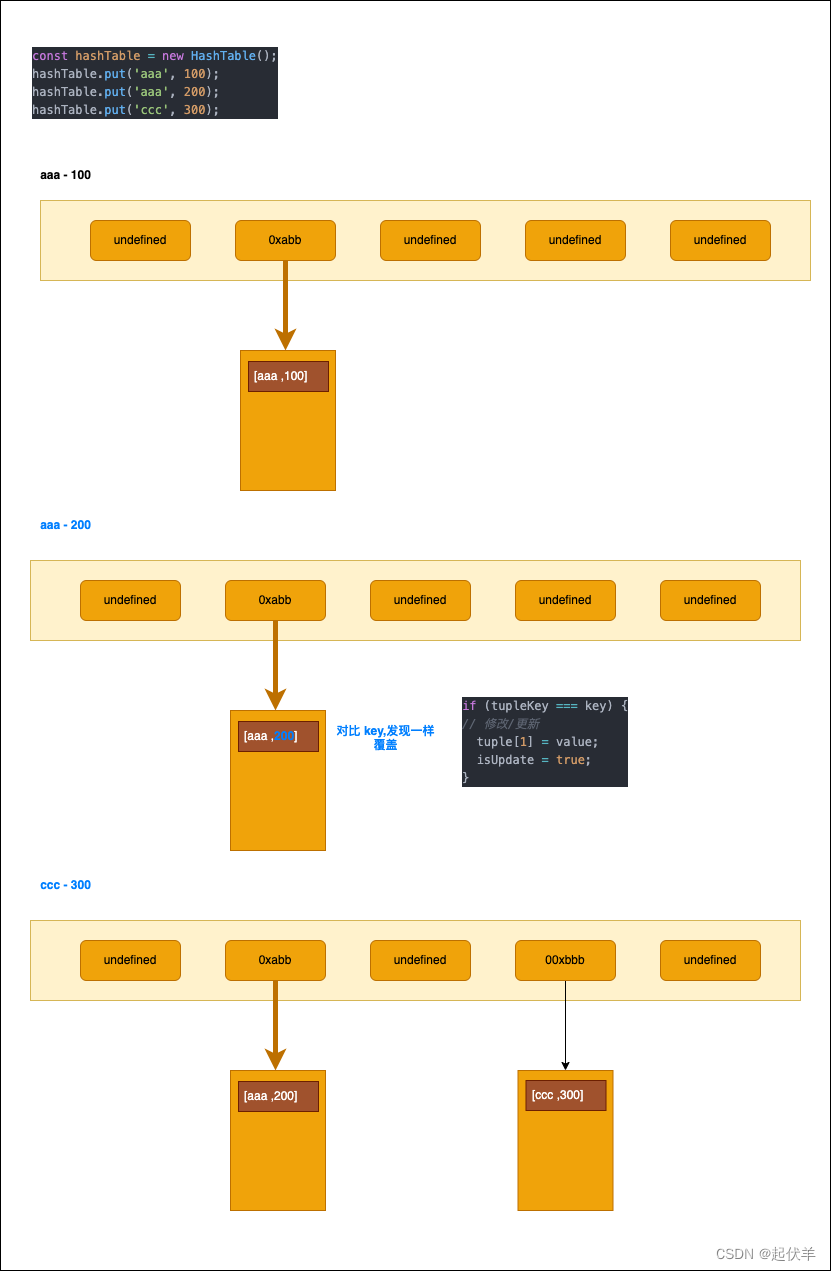
Python:Spider爬虫工程化入门到进阶系列:
- Python:Spider爬虫工程化入门到进阶(1)创建Scrapy爬虫项目
- Python:Spider爬虫工程化入门到进阶(2)使用Spider Admin Pro管理scrapy爬虫项目
目录
- 1、使用scrapyd运行爬虫
- 2、部署Scrapy爬虫项目
- 2.1、修改配置文件
- 2.2、部署项目
- 3、使用Spider Admin Pro定时执行爬虫
- 3.1、安装Spider Admin Pro
- 3.2、添加定时任务
- 3.3、查看调度日志
- 4、收集爬虫数据
- 4.1、返回Item对象
- 4.2、收集Item数据
- 5、总结
本文需要用到上文提到的scrapy-project 目录文件,需要提前创建
Python:Spider爬虫工程化入门到进阶(1)创建Scrapy爬虫项目
本文涉及3个文件目录,可以提前创建好
$ tree -L 1
.
├── scrapy-project
├── scrapyd-project
└── spider-admin-project
1、使用scrapyd运行爬虫
scrapyd可以管理scrapy爬虫项目
安装环境准备
# 创建目录,并进入
$ mkdir scrapyd-project && cd scrapyd-project# 创建虚拟环境,并激活
$ python3 -m venv venv && source venv/bin/activate
安装scrapyd
# 安装 scrapyd
$ pip install scrapyd$ scrapyd --version
Scrapyd 1.4.2
启动scrapyd服务
$ scrapyd
浏览器访问:http://127.0.0.1:6800/
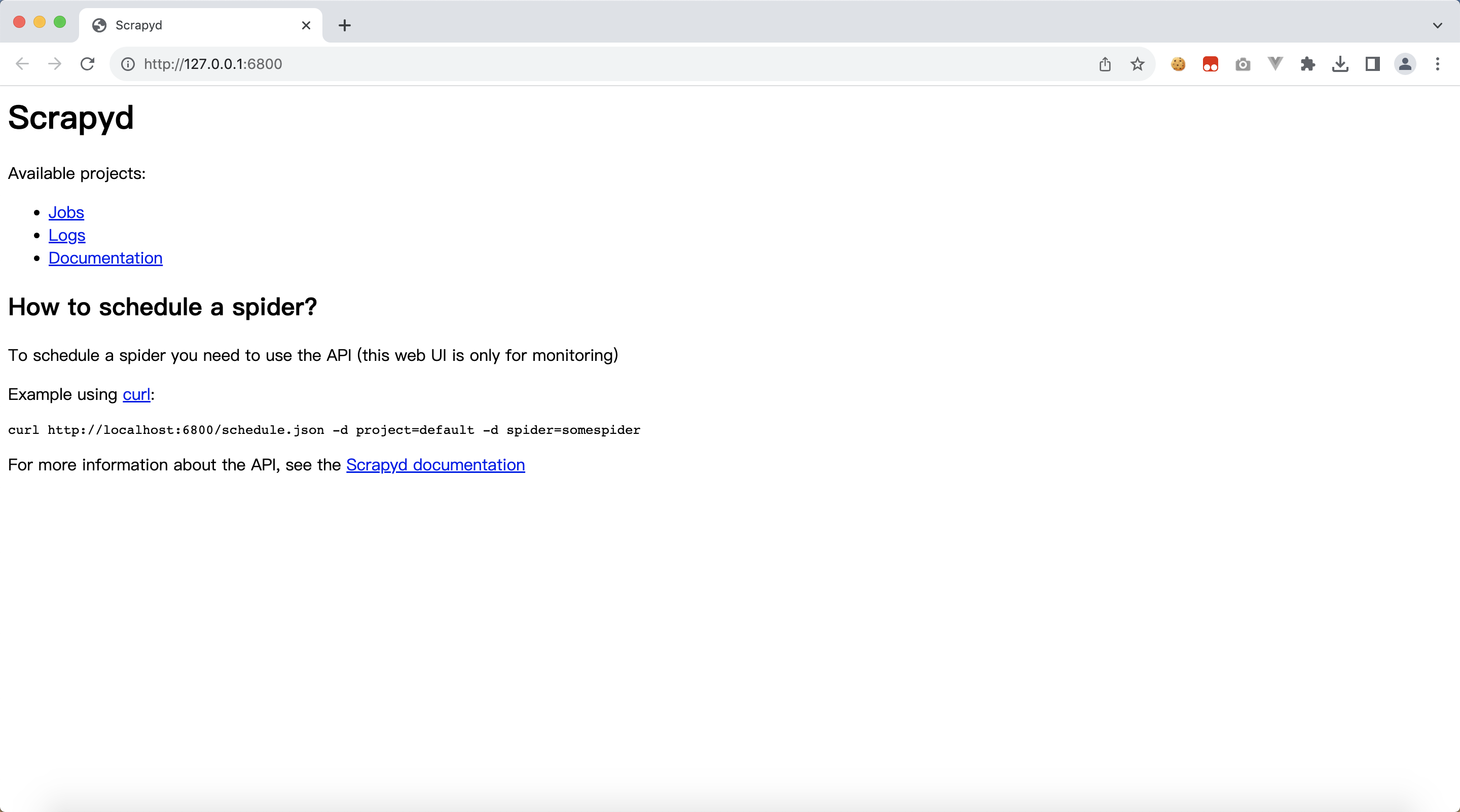
2、部署Scrapy爬虫项目
2.1、修改配置文件
回到爬虫项目目录scrapy-project,修改配置文件 scrapy.cfg
将 deploy.url的注释去掉,6800 端口就是上面我们启动的scrapyd 端口
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html[settings]
default = web_spiders.settings[deploy]
# url = http://localhost:6800/
url = http://localhost:6800/
project = web_spiders2.2、部署项目
安装 scrapyd-client
pip install scrapyd-client
部署项目
$ scrapyd-deployPacking version 1691131715
Deploying to project "web_spiders" in http://localhost:6800/addversion.json
Server response (200):
{"node_name": "bogon", "status": "ok", "project": "web_spiders", "version": "1691131715", "spiders": 1}看到返回"status": "ok" 就是部署成功
3、使用Spider Admin Pro定时执行爬虫
Spider Admin Pro项目利用了scrapyd提供的api接口实现了一个可视化的爬虫管理平台,便于我们管理和调度爬虫
3.1、安装Spider Admin Pro
此时,我们需要再新建一个目录:spider-admin-project
# 创建目录,并进入
$ mkdir spider-admin-project && cd spider-admin-project# 创建虚拟环境,并激活
$ python3 -m venv venv && source venv/bin/activate
安装 spider-admin-pro
pip3 install spider-admin-pro
启动 spider-admin-pro
gunicorn 'spider_admin_pro.main:app'
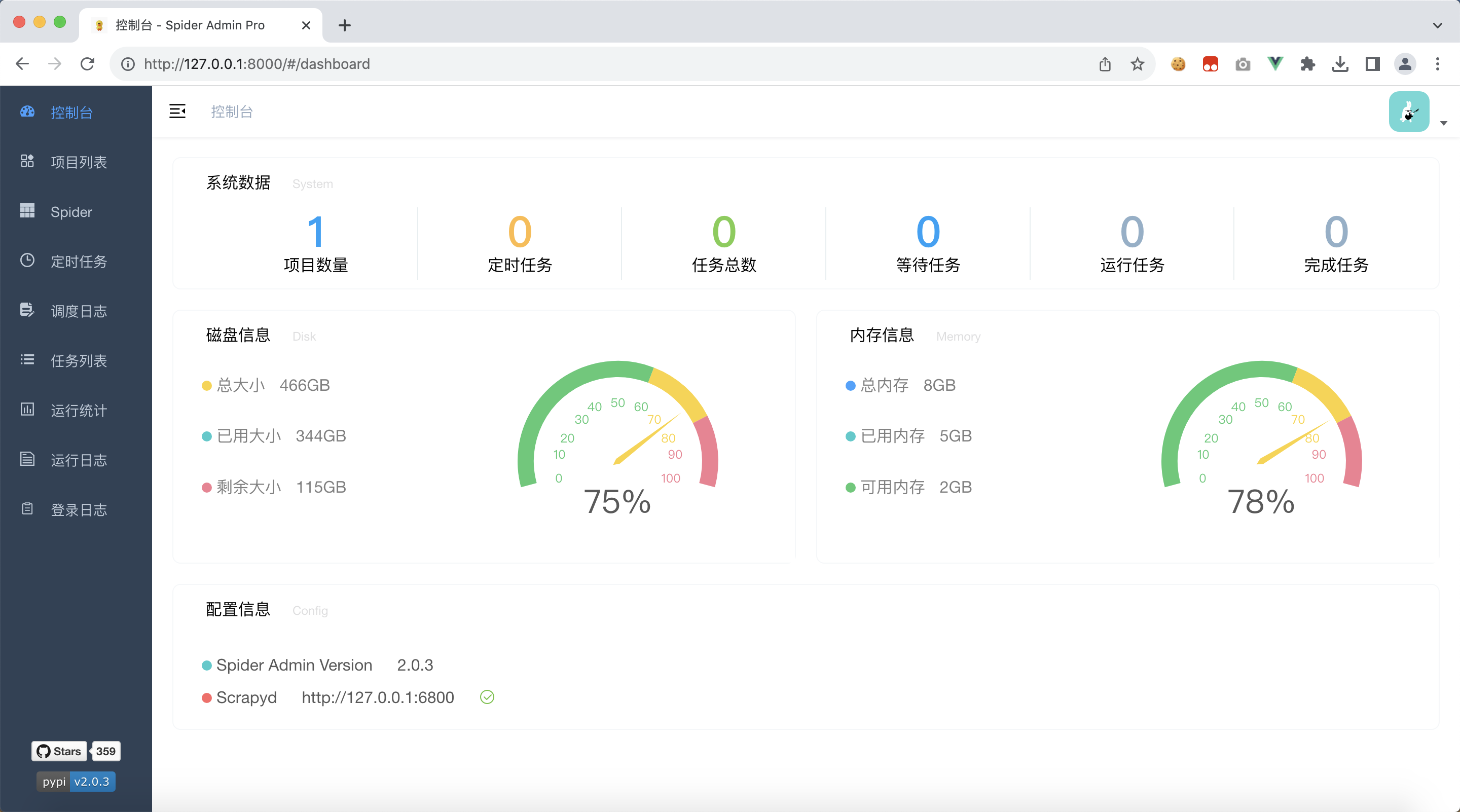
浏览器访问:http://127.0.0.1:8000/
默认的
- 账号 admin
- 密码 123456
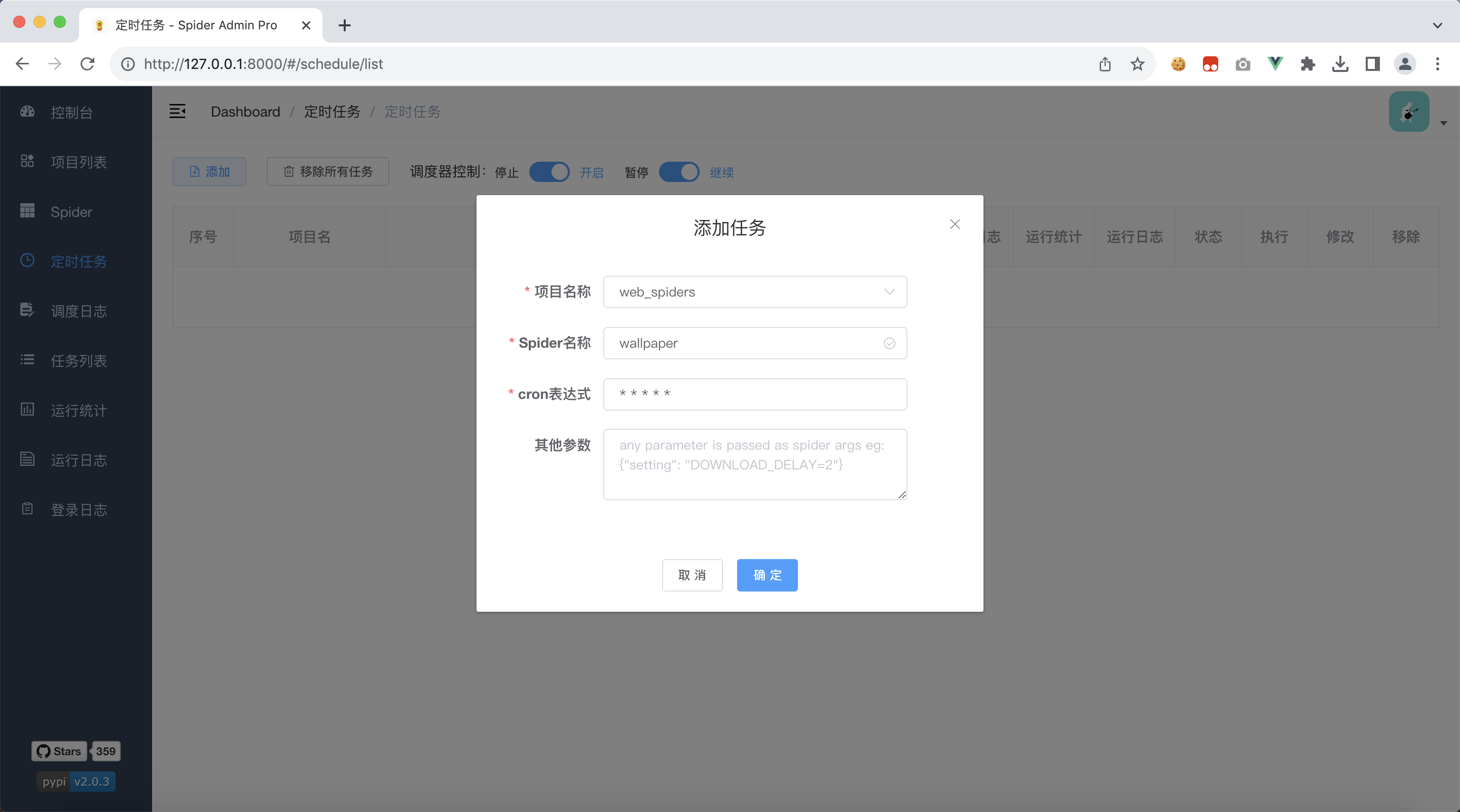
3.2、添加定时任务
我们点击左边tab栏:定时任务, 添加一个任务
我们的项目只有一个爬虫,默认会选中我们的爬虫名字
cron表达式表示的是每分钟执行一次
全部都是默认的,我们只需要点击确定 即可,因为现在还没有运行,所以日志都是空的,我们需要等待一会
3.3、查看调度日志
点击左侧tab栏:调度日志,过一会就能看到爬虫项目被执行了,可以在这里查看调度日志
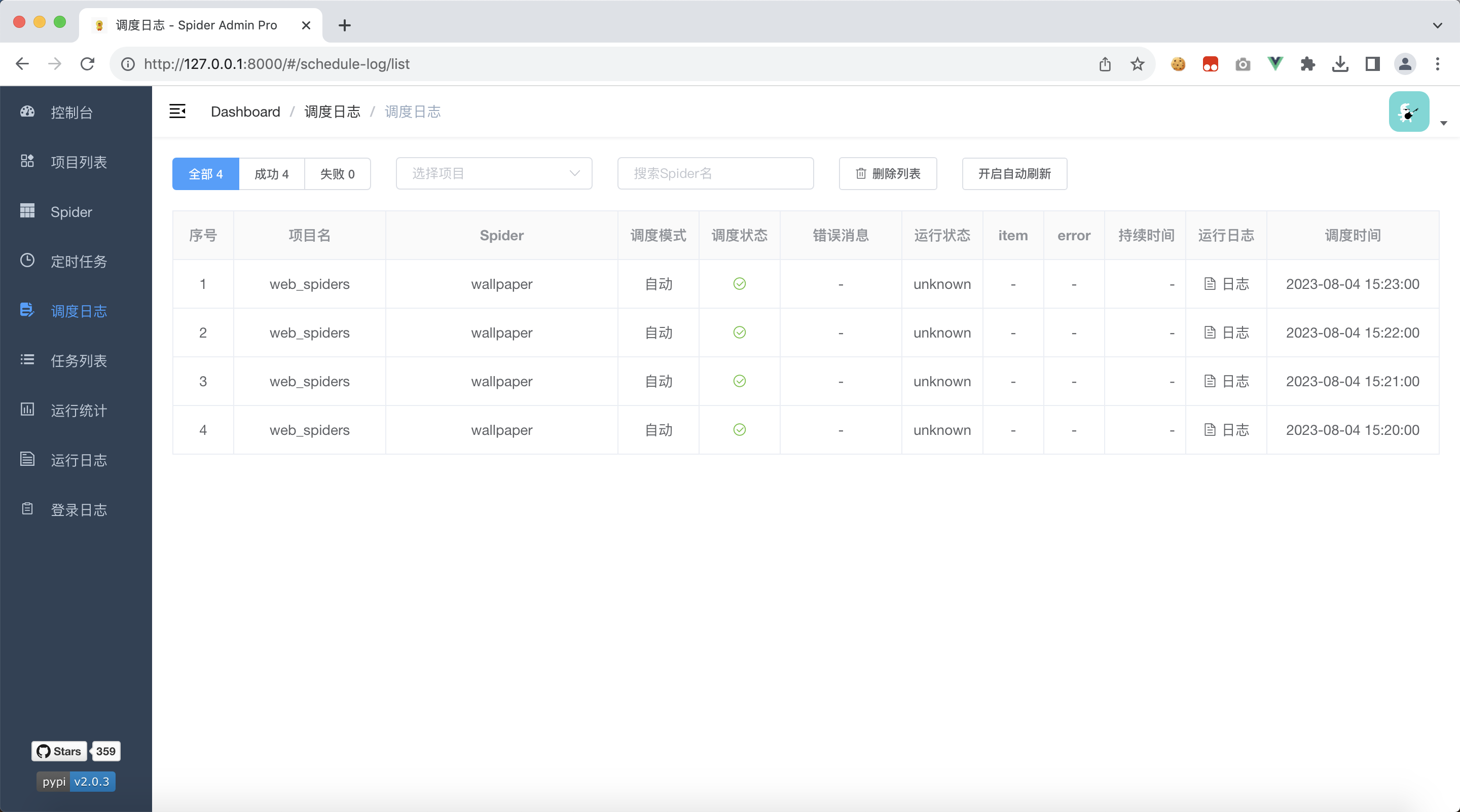
需要注意的是,我们代码中使用 print 打印的内容,并不会出现在日志文件中
我们修改代码文件,将print修改为self.logger.debug
web_spiders/spiders/wallpaper.py
import scrapy
from scrapy.http import Responseclass WallpaperSpider(scrapy.Spider):name = "wallpaper"allowed_domains = ["mouday.github.io"]# 替换爬虫开始爬取的地址为我们需要的地址# start_urls = ["https://mouday.github.io"]start_urls = ["https://mouday.github.io/wallpaper-database/2023/08/03.json"]# 将类型标注加上,便于我们在IDE中快速编写代码# def parse(self, response):def parse(self, response: Response, **kwargs):# 我们什么也不做,仅打印爬取的文本# 使用 `print` 打印的内容,并不会出现在日志文件中# print(response.text)self.logger.debug(response.text)重新部署
$ scrapyd-deploy
等待刚刚部署的爬虫运行结束,就可以看到日志了
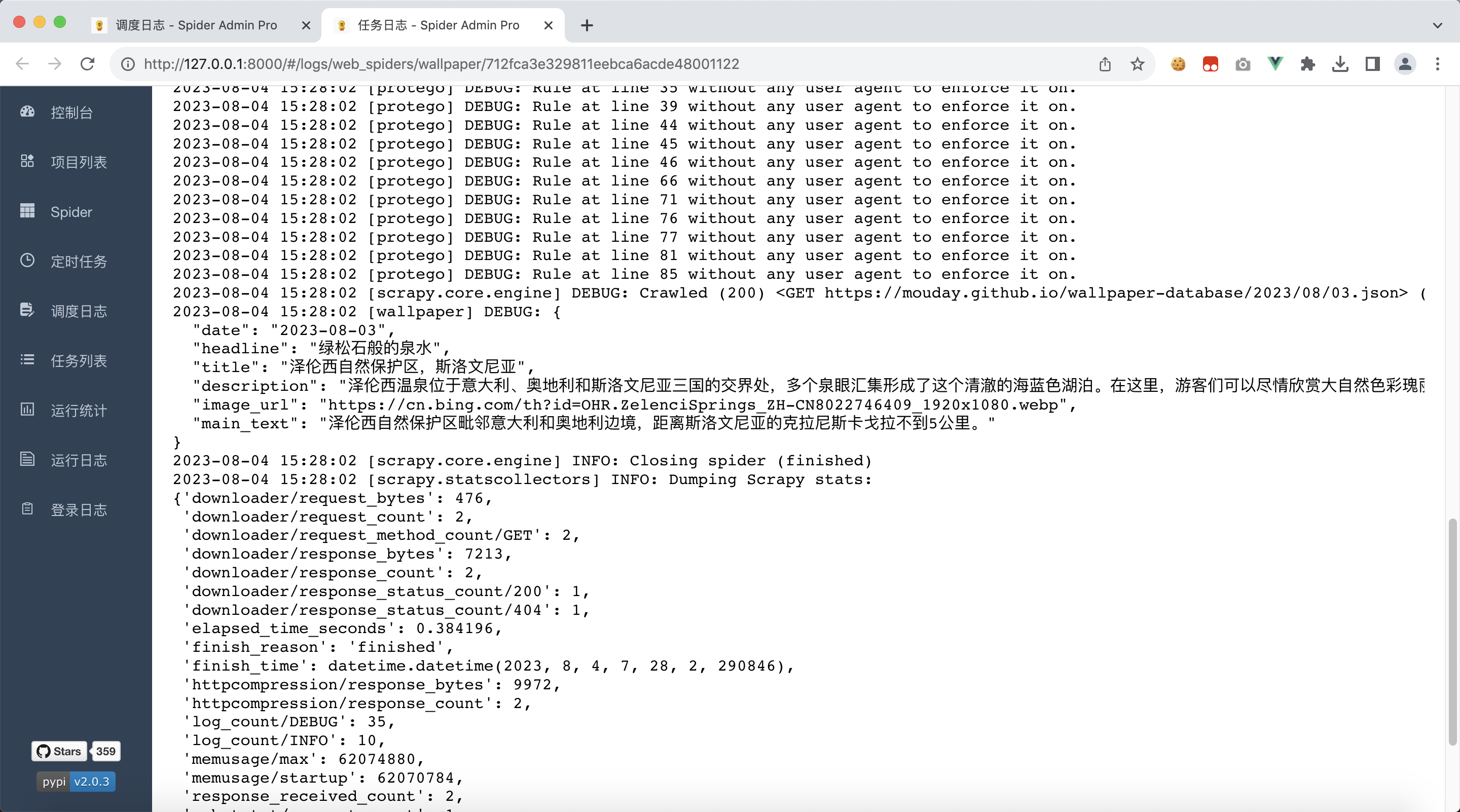
4、收集爬虫数据
4.1、返回Item对象
我们的目标网站返回的数据结构如下
{"date":"2023-08-03","headline":"绿松石般的泉水","title":"泽伦西自然保护区,斯洛文尼亚","description":"泽伦西温泉位于意大利、奥地利和斯洛文尼亚三国的交界处,多个泉眼汇集形成了这个清澈的海蓝色湖泊。在这里,游客们可以尽情欣赏大自然色彩瑰丽的调色盘。","image_url":"https://cn.bing.com/th?id=OHR.ZelenciSprings_ZH-CN8022746409_1920x1080.webp","main_text":"泽伦西自然保护区毗邻意大利和奥地利边境,距离斯洛文尼亚的克拉尼斯卡戈拉不到5公里。"
}所以,根据对应字段建立如下的Item对象
web_spiders/items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass WebSpidersItem(scrapy.Item):# define the fields for your item here like:date = scrapy.Field()headline = scrapy.Field()title = scrapy.Field()description = scrapy.Field()image_url = scrapy.Field()main_text = scrapy.Field()同时,修改爬虫文件,将数据包装到Item的子类 WebSpidersItem 对象上,并返回
web_spiders/spiders/wallpaper.py
import jsonimport scrapy
from scrapy.http import Responsefrom web_spiders.items import WebSpidersItemclass WallpaperSpider(scrapy.Spider):name = "wallpaper"allowed_domains = ["mouday.github.io"]# 替换爬虫开始爬取的地址为我们需要的地址# start_urls = ["https://mouday.github.io"]start_urls = ["https://mouday.github.io/wallpaper-database/2023/08/03.json"]# 将类型标注加上,便于我们在IDE中快速编写代码# def parse(self, response):def parse(self, response: Response, **kwargs):# 我们什么也不做,仅打印爬取的文本# 使用 `print` 打印的内容,并不会出现在日志文件中# print(response.text)self.logger.debug(response.text)# 使用json反序列化字符串为dict对象data = json.loads(response.text)# 收集我们需要的数据item = WebSpidersItem()item['date'] = data['date']item['headline'] = data['headline']item['title'] = data['title']item['description'] = data['description']item['image_url'] = data['image_url']item['main_text'] = data['main_text']return item重新部署
$ scrapyd-deploy
可以看到,除了打印的日志外,还多打印了一份数据,这就是我们刚返回的Item对象
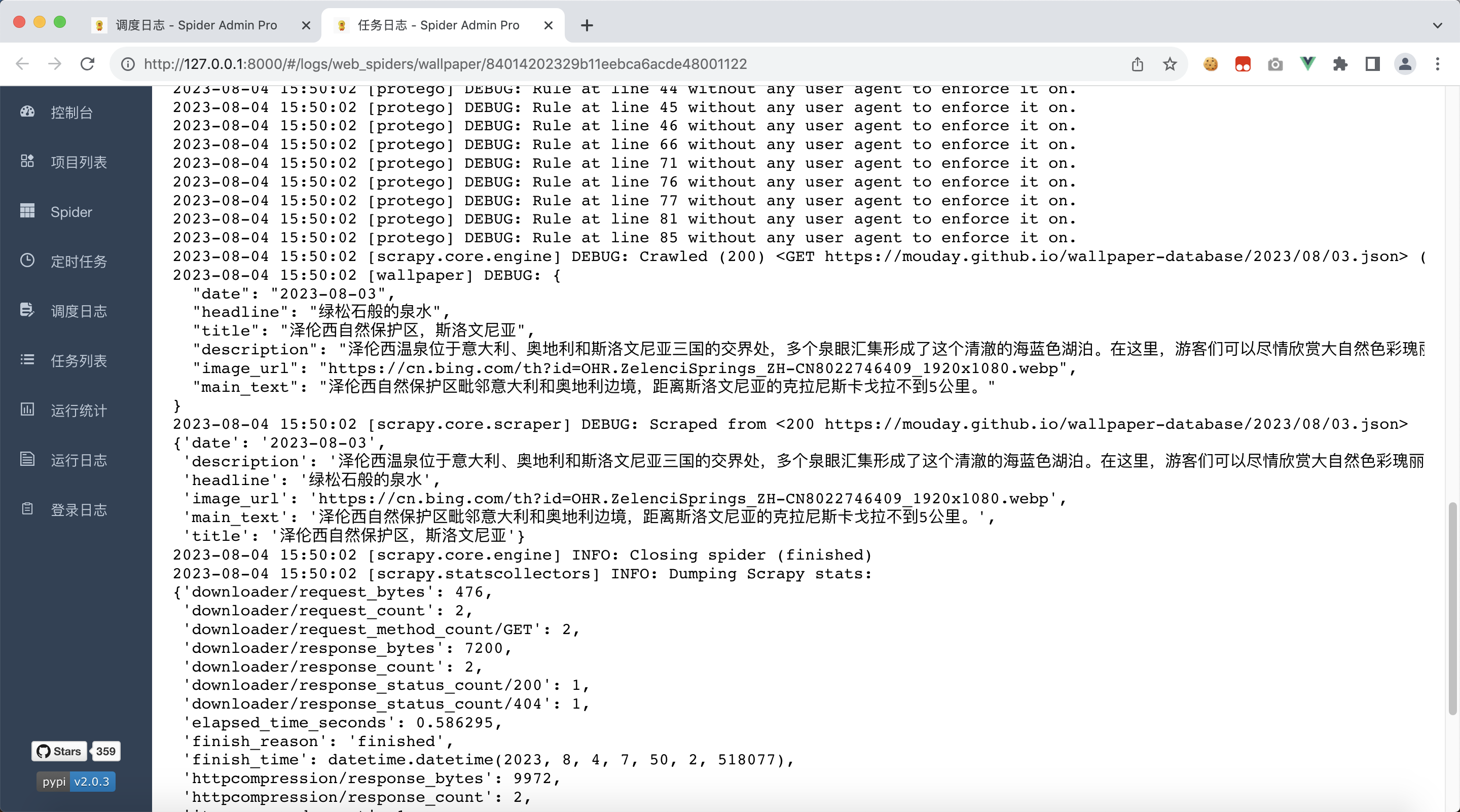
4.2、收集Item数据
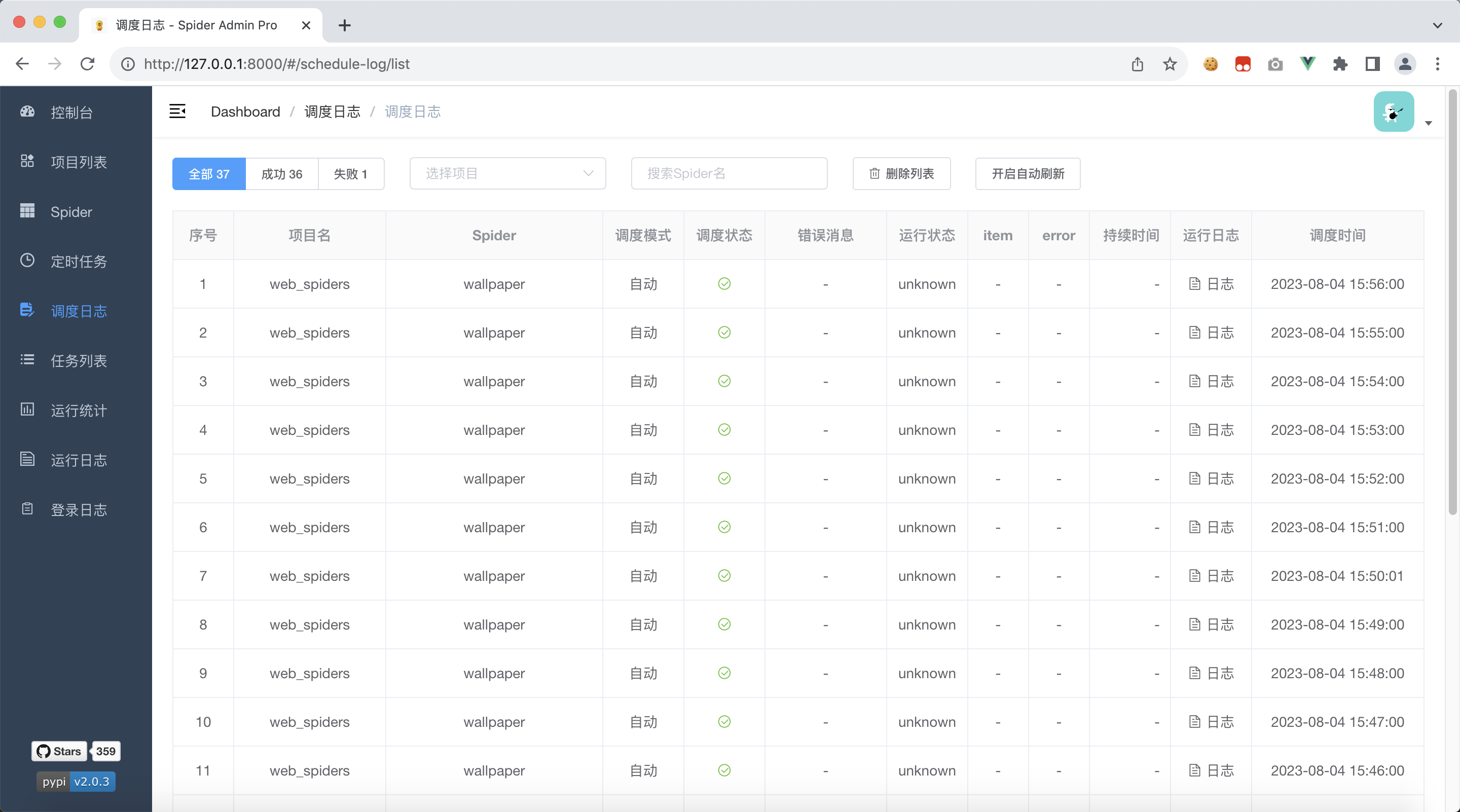
我们可以看到,运行状态一列,都是unknown,我们需要知道爬虫的运行状态,是成功还是失败
scrapy-util 可以帮助我们收集到程序运行的统计数据
返回项目scrapy-project
安装scrapy-util
pip install scrapy-util
修改配置文件 web_spiders/settings.py
将以下配置添加到配置文件中,端口号改为 spider-admin-pro 的实际端口号,这里是8000
# 设置收集运行日志的路径,会以post方式向 spider-admin-pro 提交json数据
# 注意:此处配置仅为示例,请设置为 spider-admin-pro 的真实路径
# 假设,我们的 spider-admin-pro 运行在http://127.0.0.1:8000
STATS_COLLECTION_URL = "http://127.0.0.1:8000/api/statsCollection/addItem"# 启用数据收集扩展
EXTENSIONS = {# ===========================================# 可选:如果收集到的时间是utc时间,可以使用本地时间扩展收集'scrapy.extensions.corestats.CoreStats': None,'scrapy_util.extensions.LocaltimeCoreStats': 0,# ===========================================# 可选,打印程序运行时长'scrapy_util.extensions.ShowDurationExtension': 100,# 启用数据收集扩展'scrapy_util.extensions.StatsCollectorExtension': 100
}
重新部署
$ scrapyd-deploy
我们看到scrapyd的控制台输出了如下信息
ModuleNotFoundError: No module named 'scrapy_util'
说明有问题,因为我们没有给scrapyd的运行环境安装依赖scrapy-util
停掉scrapyd,安装scrapy-util
pip install scrapy-util
安装完毕后,重新启动 scrapyd
让爬虫执行一会,我们就可以看到,调度日志列表多了一些信息,可以看到
- 运行状态:finished,而不是unknown
- item数量是1,我们返回了1个item对象
- error错误时空的,说明程序没有报错
- 持续时间是1秒,运行时间很短,很快就结束了

5、总结
本文用到了很多的第三方模块,将这些模块整合进我们的项目能极大提高工作效率
| 第三方库 | 说明 | 文档资料 |
|---|---|---|
| scrapy | 创建工程化的爬虫项目 | github |
| scrapyd | 运行scrapy爬虫 | github、docs |
| scrapyd-client | 部署scrapy爬虫 | github |
| spider-admin-pro | 调度scrapy爬虫 | github |
| scrapy-util | 收集爬虫运行结果 | github |
| gunicorn | 执行spider-admin-pro应用 | docs |