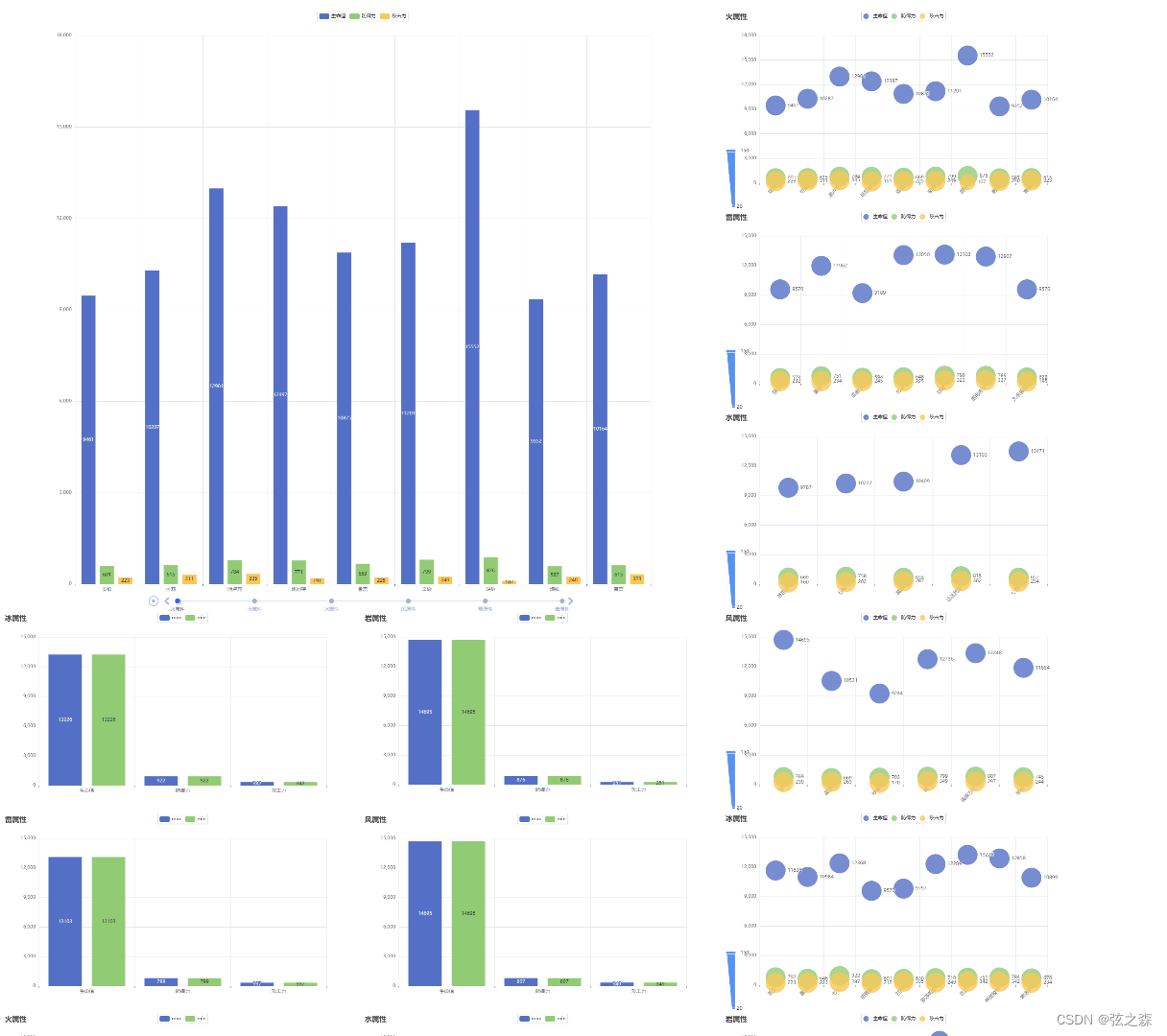
算法拾遗三十七资源限制类题目
- 资源限制技巧汇总
- 32位无符号整数的范围是0~4,294,967,295,现在有一个正好包含40亿个无符号整数的文件,可以使用最多1GB的内存,怎么找到出现次数最多的数
- 32位无符号整数的范围是0~4294967295,现在又一个正好包含40亿个无符号整数的文件,所以在正哥范围中必然存在没出现过的数,可以使用最多1GB的内存,怎么找到所有未出现的数?
- 【进阶】内存限制为3KB,但是只用找到一个没出现过的数即可
- 有一个包含100亿个URL的大文件,假设每个URL占用64B,请找出其中所有重复的URL
- 32位无符号整数,现在有40亿个无符号整数,可以使用最多1GB的内存,找出所有出现了两次的数
- 现在有40亿个无符号整数,可以使用最多3K的内存,怎么找到10亿个整数的中位数(找上中位数)
- 有一个10G大小的文件,每一行都装着这种类型的数字,整个文件是无序的,给你5G的内存空间,请你输出一个10G大小的文件,就是原文件所有数字排序的结果
资源限制技巧汇总
1)布隆过滤器用于集合的建立与查询,并可以节省大量空间
2)一致性哈希解决数据服务器的负载管理问题
3)利用并查集结构做岛问题的并行计算
4)哈希函数可以把数据按照种类均匀分流
5)位图解决某一范围上数字的出现情况,并可以节省大量空间
6)利用分段统计思想、并进一步节省大量空间7)利用堆、外排序来做多个处理单元的结果合并
32位无符号整数的范围是0~4,294,967,295,现在有一个正好包含40亿个无符号整数的文件,可以使用最多1GB的内存,怎么找到出现次数最多的数
如果将数全拿到内存,40亿个无符号整数占用空间大概为16GB,如果使用hash表估算,hash表使用多少内存和数字的个数无关,和到底出现了多少个不同的数字有关系。(如果40亿个数全是1,那么这个hash只占用8字节的空间,但是如果40亿个数都不一样,那么占用空间为32G,那么hash表空间会爆掉的)
如果1G的内存都来做hash表那么能装下多少记录?
基本上是一亿两千五百万条记录,可能还有一些其他的代价,那么就假设hash表只能装下一千万条记录。
假设40亿个数有四十亿种数。
步骤:
1、首先让40亿个数除以1千万,得到400
2、这40亿个数每一个数得到一个hash值然后让它模400,利用hash函数的性质让数据几乎均分的放到各自的hash槽中
3、hash函数的性质,同一种数字只会进入同一个文件
4、这样一来搞出了400个文件,每个文件数字的种数均分差不多一千万
5、然后则需要对0号文件使用hash表求出出现次数最多的数字,然后释放掉hash表,对1号文件使用hash表求出出现次数最多的数字,依次类推找出400个文件中出现次数最多的数字。
32位无符号整数的范围是0~4294967295,现在又一个正好包含40亿个无符号整数的文件,所以在正哥范围中必然存在没出现过的数,可以使用最多1GB的内存,怎么找到所有未出现的数?
应该使用位图来解决这类问题,定义一个bit数组那么我数组八位才占用一个字节,那么就准备2的32次方个长度的bit数组,那么一个才占用2的32次方除以八个字节,1G内存能解决当前问题,但是前提是bit数组,如何实现bit数组,拿基础类型去拼接。
当我申请一个长度为10的bit数组的时候,那么就等同于我申请了320长度的bit,具体第i号bit设置方式,用i除以32(知道i在arr中的哪个位置)然后再用i对32取模(看看是这个数字中的第几位)
解法:
准备好一个大位图,1G内存可以拿下,遍历整个文件,将数字在整个大位图上面将数字对应的位图表示做标记,最后找没被标记的则解决问题。
【进阶】内存限制为3KB,但是只用找到一个没出现过的数即可
3Kb的空间都拿来做无符号的整型数组的话,则数组最大长度为750(300/4),那么我最终申请512长度的空间,将2的32次方范围均分512份,每一份统计一个范围,就必然能找到不满的范围,则只需要在不满的小范围里面去找那个数字没出现就ok了,在小范围里面再将数字范围划分为512份,一直划分下去最终找到一个没出现的次数。
如果只能申请有限几个变量?
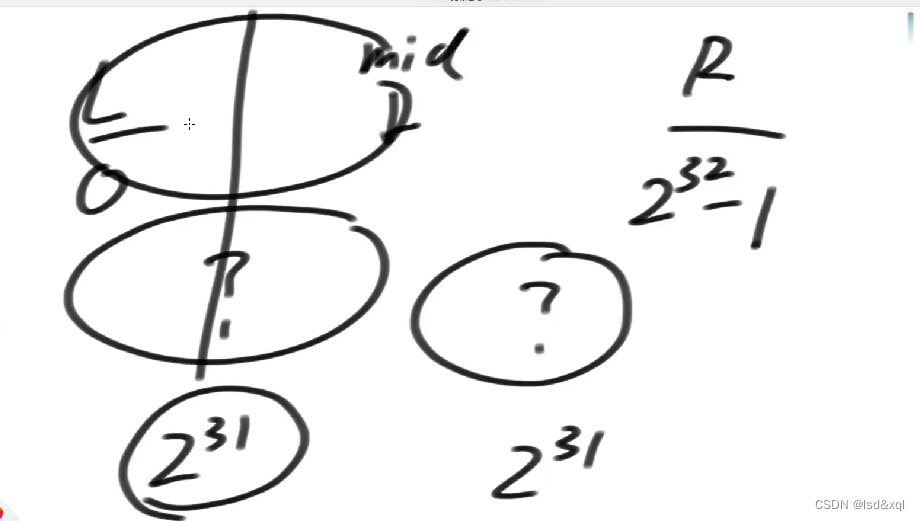
则可以通过2分的方式将数字范围逐渐划分变小,最终把没出现的数给2分找出来。
有一个包含100亿个URL的大文件,假设每个URL占用64B,请找出其中所有重复的URL
先把大文件通过hash函数分割成小文件(如果小文件再大则继续hash分流到更小的文件),再从这些小文件里面去找有没有重复的URL(hash有相同的输入一定有相同的输出)
32位无符号整数,现在有40亿个无符号整数,可以使用最多1GB的内存,找出所有出现了两次的数
用两bit位信息表示一个数的出现次数,就是找数对应的两位bit位就解决了(0,1两个bit位的数字表示数字0出现的次数),
现在有40亿个无符号整数,可以使用最多3K的内存,怎么找到10亿个整数的中位数(找上中位数)
1,2,3,4 中2就是上中位数。
只要3KB,取512长度的无符号整数数组,所以将整个范围分成512份,每一份都能均分,然后统计每个范围出现了多少个数,一共40亿个数要找第20亿个数出现在哪个范围,比如说第一个范围a只有1亿个数,那么可以排除中位数绝对不在范围a,如果某个范围区间刚到20亿或者刚超过20亿,那么这个上中位数一定在那个范围区间。
(分段统计思想)
有一个10G大小的文件,每一行都装着这种类型的数字,整个文件是无序的,给你5G的内存空间,请你输出一个10G大小的文件,就是原文件所有数字排序的结果
利用大根堆结构处理,维持了一个门槛,大根堆里面维护一个数字,然后再维护那个数字出现的次数,当新来的数大于大根堆的根节点时则弹出大根堆的头节点,然后让新的数字进来,当堆空间不满足5G的内存空间大小时,将堆中元素输出,再通过临时变量t记录当前堆中最大的节点是哪个,再重新遍历10G的文件跳过小于等于t的元素重新构建新的大根堆从而解决问题。